
Unsupervised Cross-lingual Representation Learning at Scale
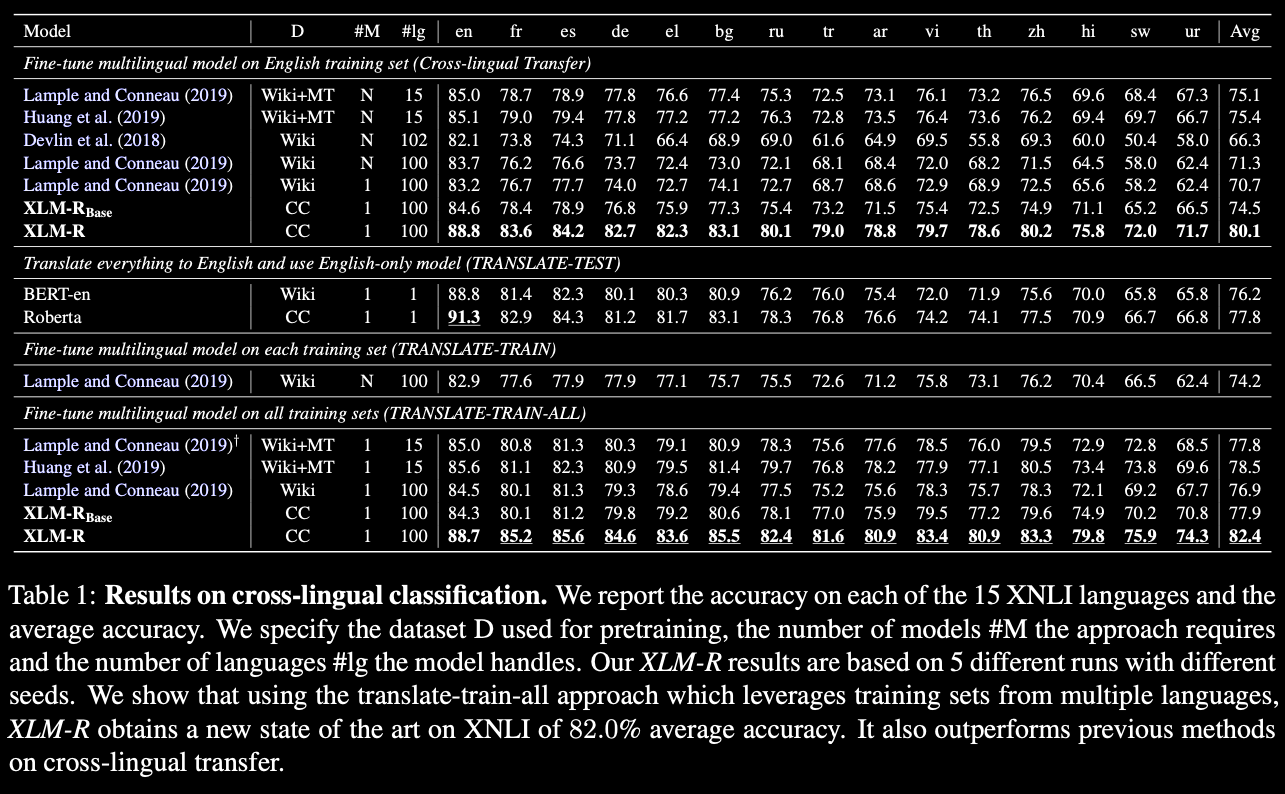
They release XLM-R, a Transformer MLM trained in 100 langs on 2.5 TB of text data! Which obtains state-of-the-art performance on cross-lingual classification, sequence labeling and question answering.
Introduced a comprehensive analysis of the capacity and limits of unsupervised multilingual masked language modeling at scale.
XLM-R especially outperforms mBERT and XLM-100 on low-resource languages, for which CommonCrawl data enables representation learning: +13.7% and +9.3% for Urdu, +21.6% and +13.8% accuracy for Swahili on XNLI.
Soon on transformers by huggingface repo & at tf.hub
paper: https://arxiv.org/abs/1911.02116
code: https://github.com/pytorch/fairseq/tree/master/examples/xlmr
#nlp #bert #xlu #transformer
They release XLM-R, a Transformer MLM trained in 100 langs on 2.5 TB of text data! Which obtains state-of-the-art performance on cross-lingual classification, sequence labeling and question answering.
Introduced a comprehensive analysis of the capacity and limits of unsupervised multilingual masked language modeling at scale.
XLM-R especially outperforms mBERT and XLM-100 on low-resource languages, for which CommonCrawl data enables representation learning: +13.7% and +9.3% for Urdu, +21.6% and +13.8% accuracy for Swahili on XNLI.
Soon on transformers by huggingface repo & at tf.hub
paper: https://arxiv.org/abs/1911.02116
code: https://github.com/pytorch/fairseq/tree/master/examples/xlmr
#nlp #bert #xlu #transformer
{kind=link}