
Uber AI Plug and Play Language Model (PPLM)
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
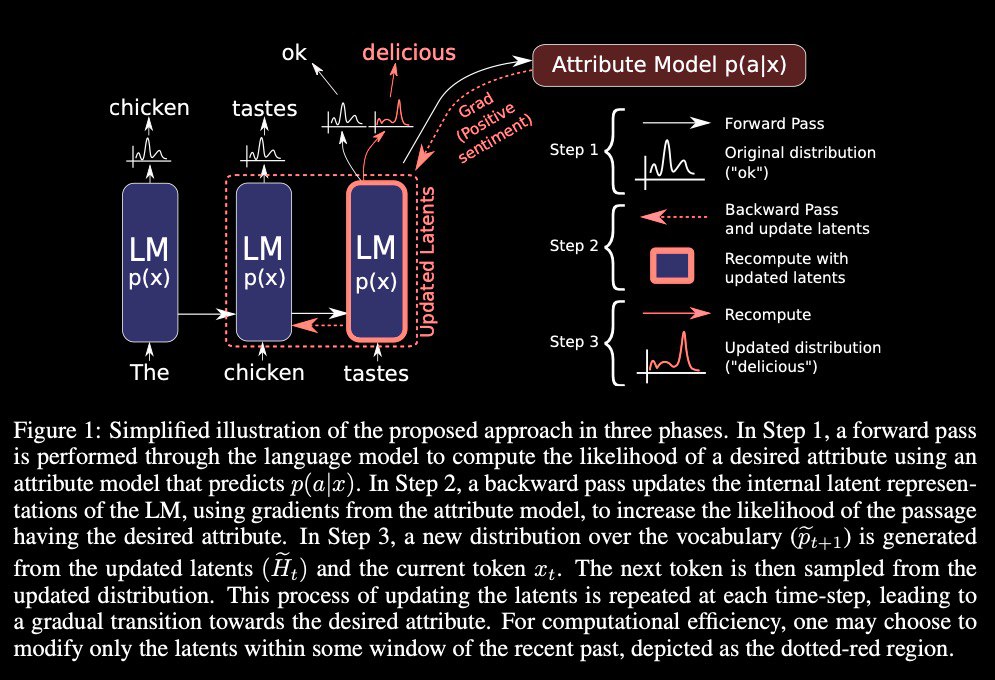
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
{kind=link}