
TENER: Adapting Transformer Encoder for Named Entity Recognition
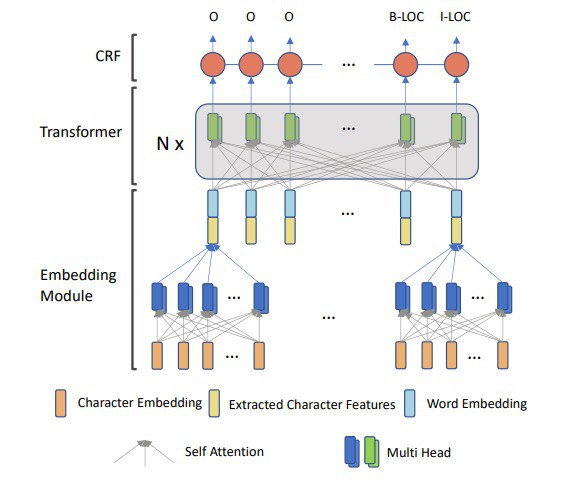
The authors suggest several modifications to Transformer architecture for NER tasks.
Recently Transformer architectures were adopted in many NLP tasks and showed great results. Nevertheless, the performance of the vanilla Transformer in NER is not as good as it is in other NLP tasks.
To improve the performance of this approach for NER tasks the following improvements were implemented:
– revised relative positional encoding to use both the direction and distance information;
– un-scaled attention, as few contextual words are enough to judge its label
– using both word-embeddings and character-embeddings.
The experiments show that this approach can reach SOTA results (without considering the pre-trained language models). The adapted Transformer is also suitable for being used as the English character encoder.
Paper: https://arxiv.org/abs/1911.04474
Code: https://github.com/fastnlp/TENER
#deeplearning #nlp #transformer #attention #encoder #ner
The authors suggest several modifications to Transformer architecture for NER tasks.
Recently Transformer architectures were adopted in many NLP tasks and showed great results. Nevertheless, the performance of the vanilla Transformer in NER is not as good as it is in other NLP tasks.
To improve the performance of this approach for NER tasks the following improvements were implemented:
– revised relative positional encoding to use both the direction and distance information;
– un-scaled attention, as few contextual words are enough to judge its label
– using both word-embeddings and character-embeddings.
The experiments show that this approach can reach SOTA results (without considering the pre-trained language models). The adapted Transformer is also suitable for being used as the English character encoder.
Paper: https://arxiv.org/abs/1911.04474
Code: https://github.com/fastnlp/TENER
#deeplearning #nlp #transformer #attention #encoder #ner
{kind=link}