
XLNet: Generalized Autoregressive Pretraining for Language Understanding
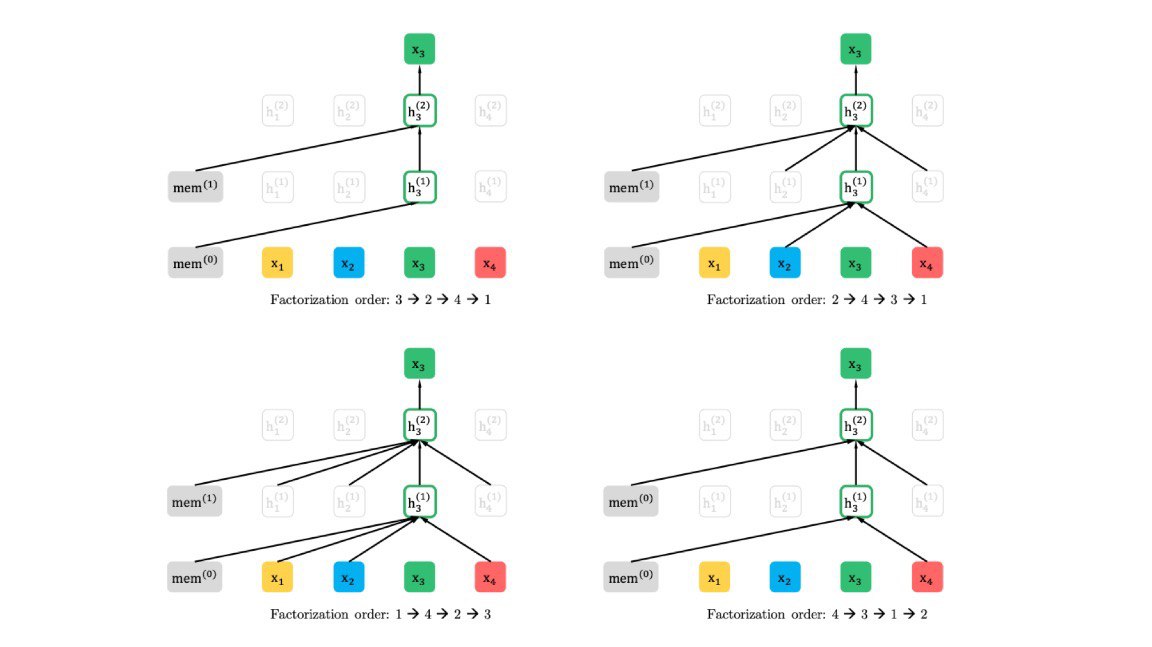
Researchers at Google Brain and Carnegie Mellon introduce #XLNet, a pre-training algorithm for natural language processing systems. It helps NLP models (in this case, based on Transformer-XL) achieve state-of-the-art results in 18 diverse language-understanding tasks including question answering and sentiment analysis.
Article: https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335
ArXiV: https://arxiv.org/pdf/1906.08237.pdf
#Google #GoogleBrain #CMU #NLP #SOTA #DL
Researchers at Google Brain and Carnegie Mellon introduce #XLNet, a pre-training algorithm for natural language processing systems. It helps NLP models (in this case, based on Transformer-XL) achieve state-of-the-art results in 18 diverse language-understanding tasks including question answering and sentiment analysis.
Article: https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335
ArXiV: https://arxiv.org/pdf/1906.08237.pdf
#Google #GoogleBrain #CMU #NLP #SOTA #DL
{kind=link}
What’s wrong with transformer architecture: an overview
How the Transformers broke NLP leaderboards and why that can be bad for industry.
Link: https://hackingsemantics.xyz/2019/leaderboards/
#NLP #overview #transformer #BERT #XLNet
How the Transformers broke NLP leaderboards and why that can be bad for industry.
Link: https://hackingsemantics.xyz/2019/leaderboards/
#NLP #overview #transformer #BERT #XLNet
Hacking semantics
How the Transformers broke NLP leaderboards
With the huge Transformer-based models such as BERT, GPT-2, and XLNet, are we losing track of how the state-of-the-art performance is achieved?
Baidu’s Optimized ERNIE Achieves State-of-the-Art Results in Natural Language Processing Tasks
#Baide developed ERNIE 2.0, a continual pre-training framework for language understanding. The model built on this framework has outperformed #BERT and #XLNet on 16 tasks in Chinese and English.
Link: http://research.baidu.com/Blog/index-view?id=121
#NLP #NLU
#Baide developed ERNIE 2.0, a continual pre-training framework for language understanding. The model built on this framework has outperformed #BERT and #XLNet on 16 tasks in Chinese and English.
Link: http://research.baidu.com/Blog/index-view?id=121
#NLP #NLU
spaCy meets PyTorch-Transformers: Fine-tune BERT, XLNet and GPT-2
Including pretrained models.
Link: https://explosion.ai/blog/spacy-pytorch-transformers
Pip:
#Transformers #SpaCy #NLP #NLU #PyTorch #Bert #XLNet #GPT
Including pretrained models.
Link: https://explosion.ai/blog/spacy-pytorch-transformers
Pip:
pip install spacy-pytorch-transformers#Transformers #SpaCy #NLP #NLU #PyTorch #Bert #XLNet #GPT
explosion.ai
spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2 · Explosion
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. You can now use these models in spaCy, via a new interface library we've developed that connects spaCy to Hugging Face's awesome implementations.