
StyleGAN2 with adaptive discriminator augmentation (ADA)
Github: https://github.com/NVlabs/stylegan2-ada
ArXiV: https://arxiv.org/abs/2006.06676
#StyleGAN #GAN #DL #CV
Github: https://github.com/NVlabs/stylegan2-ada
ArXiV: https://arxiv.org/abs/2006.06676
#StyleGAN #GAN #DL #CV
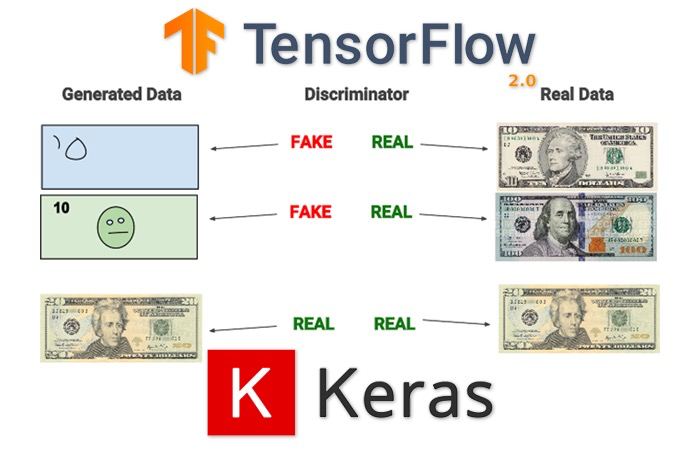
Tutorial on Generative Adversarial Networks (GANs) with Keras and TensorFlow
Nice tutorial with enough theory to understand what you are doing and code to get it done.
Link: https://www.pyimagesearch.com/2020/11/16/gans-with-keras-and-tensorflow/
#Keras #TensorFlow #tutorial #wheretostart #GAN
Nice tutorial with enough theory to understand what you are doing and code to get it done.
Link: https://www.pyimagesearch.com/2020/11/16/gans-with-keras-and-tensorflow/
#Keras #TensorFlow #tutorial #wheretostart #GAN
{kind=link}
MPG: A Multi-ingredient Pizza Image Generator with Conditional StyleGANs
Work on conditional image generation
ArXiV: https://arxiv.org/abs/2012.02821
#GAN #DL #food2vec
Work on conditional image generation
ArXiV: https://arxiv.org/abs/2012.02821
#GAN #DL #food2vec
{kind=link}
{kind=link}
🔥New breakthrough on text2image generation by #OpenAI
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
{kind=link}
JigsawGAN: Self-supervised Learning for Solving Jigsaw Puzzles with Generative Adversarial Networks
The authors suggest a GAN-based approach for solving jigsaw puzzles. JigsawGAN is a self-supervised method with a multi-task pipeline: classification branch classifies jigsaw permutations, GAN branch recovers features to images with the correct order.
The proposed method can solve jigsaw puzzles efficiently by utilizing both semantic information and edge information simultaneously.
Paper: https://arxiv.org/abs/2101.07555
#deeplearning #jigsaw #selfsupervised #gan
The authors suggest a GAN-based approach for solving jigsaw puzzles. JigsawGAN is a self-supervised method with a multi-task pipeline: classification branch classifies jigsaw permutations, GAN branch recovers features to images with the correct order.
The proposed method can solve jigsaw puzzles efficiently by utilizing both semantic information and edge information simultaneously.
Paper: https://arxiv.org/abs/2101.07555
#deeplearning #jigsaw #selfsupervised #gan
{kind=link}
Real-World Super-Resolution of Face-Images from Surveillance Cameras
Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors suggest using blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones.
Another suggested improvement is using ESRGAN and replacing VGG-loss with LPIPS-loss, as well as adding PatchGAN.
In addition, the authors show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods.
Paper: https://arxiv.org/abs/2102.03113
#deeplearning #superresolution #gan #facesuperresolution
Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors suggest using blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones.
Another suggested improvement is using ESRGAN and replacing VGG-loss with LPIPS-loss, as well as adding PatchGAN.
In addition, the authors show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods.
Paper: https://arxiv.org/abs/2102.03113
#deeplearning #superresolution #gan #facesuperresolution
{kind=link}
Forwarded from Gradient Dude
LatentCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions
A framework that learns meaningful directions in GANs' latent space using unsupervised contrastive learning. Instead of discovering fixed directions such as in previous work, this method can discover non-linear directions in pretrained StyleGAN2 and BigGAN models. The discovered directions may be used for image manipulation.
Authors use the differences caused by an edit operation on the feature activations to optimize the identifiability of each direction. The edit operations are modeled by several separate neural nets
📝 Paper
🛠 Code (next week)
#paper_tldr #cv #gan
A framework that learns meaningful directions in GANs' latent space using unsupervised contrastive learning. Instead of discovering fixed directions such as in previous work, this method can discover non-linear directions in pretrained StyleGAN2 and BigGAN models. The discovered directions may be used for image manipulation.
Authors use the differences caused by an edit operation on the feature activations to optimize the identifiability of each direction. The edit operations are modeled by several separate neural nets
∆_i(z) and learning. Given a latent code z and its generated image x = G(z), we seek to find edit operations ∆_i(z) such that the image x' = G(∆_i(z)) has semantically meaningful changes over x while still preserving the identity of x.📝 Paper
🛠 Code (next week)
#paper_tldr #cv #gan
Generating Furry Cars: Disentangling Object Shape and Appearance across Multiple Domains
This is an interesting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don't exist in a single domain.
The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
Paper: https://openreview.net/forum?id=M88oFvqp_9
Project link: https://utkarshojha.github.io/inter-domain-gan/
Code will be available here: https://github.com/utkarshojha/inter-domain-gan
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-furrycars
#cv #gan #deeplearning #contrastivelearning
This is an interesting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don't exist in a single domain.
The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
Paper: https://openreview.net/forum?id=M88oFvqp_9
Project link: https://utkarshojha.github.io/inter-domain-gan/
Code will be available here: https://github.com/utkarshojha/inter-domain-gan
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-furrycars
#cv #gan #deeplearning #contrastivelearning
OpenReview
Generating Furry Cars: Disentangling Object Shape and Appearance...
We consider the novel task of learning disentangled representations of object shape and appearance across multiple domains (e.g., dogs and cars). The goal is to learn a generative model that...