
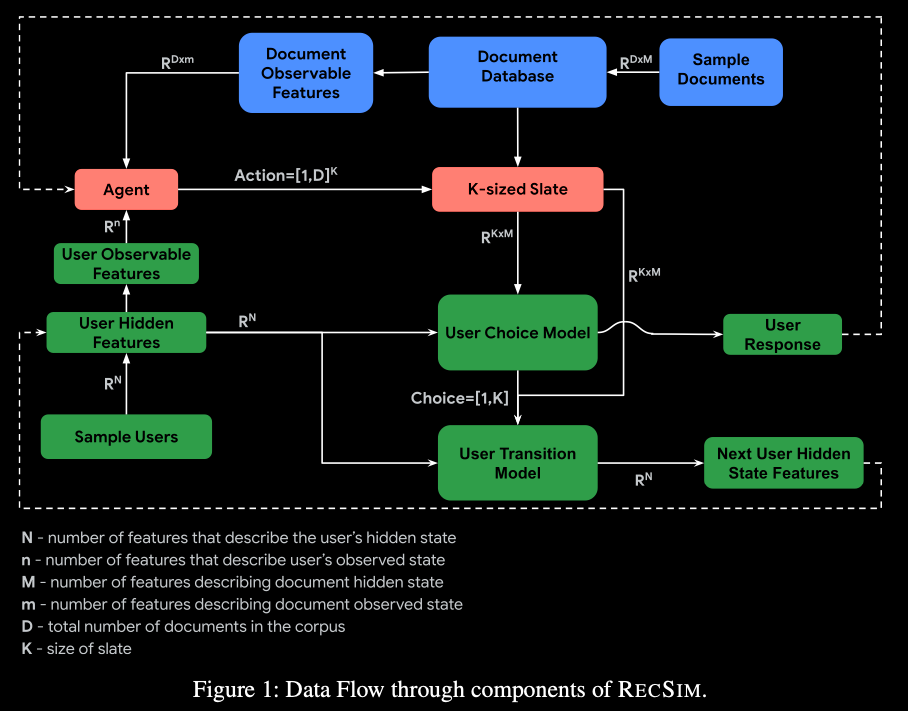
RecSim: A Configurable Simulation Platform for Recommender Systems
It's a configurable platform for authoring simulation environments to facilitate the study of RL algorithms in recommender systems (and CIRs in particular).
RᴇᴄSɪᴍ allows both researchers and practitioners to test the limits of existing RL methods in synthetic recommender settings. RecSim’s aim is to support simulations that mirror specific aspects of user behavior found in real recommender systems and serve as a controlled environment for developing, evaluating and comparing recommender models and algorithms, especially RL systems designed for sequential user-system interaction.
As an open-source platform, RᴇᴄSɪᴍ:
* facilitates research at the intersection of RL and recommender systems
* encourages reproducibility and model-sharing
* aids the recommender-systems practitioner, interested in applying RL to rapidly test and refine models and algorithms in simulation, before incurring the potential cost (e.g., time, user impact) of live experiments
* serves as a resource for academic-industry collaboration through the release of “realistic” stylized models of user behavior without revealing user data or sensitive industry strategies.
blog: https://ai.googleblog.com/2019/11/recsim-configurable-simulation-platform.html
paper: https://arxiv.org/abs/1909.04847
code: https://github.com/google-research/recsim
#rs #rl
It's a configurable platform for authoring simulation environments to facilitate the study of RL algorithms in recommender systems (and CIRs in particular).
RᴇᴄSɪᴍ allows both researchers and practitioners to test the limits of existing RL methods in synthetic recommender settings. RecSim’s aim is to support simulations that mirror specific aspects of user behavior found in real recommender systems and serve as a controlled environment for developing, evaluating and comparing recommender models and algorithms, especially RL systems designed for sequential user-system interaction.
As an open-source platform, RᴇᴄSɪᴍ:
* facilitates research at the intersection of RL and recommender systems
* encourages reproducibility and model-sharing
* aids the recommender-systems practitioner, interested in applying RL to rapidly test and refine models and algorithms in simulation, before incurring the potential cost (e.g., time, user impact) of live experiments
* serves as a resource for academic-industry collaboration through the release of “realistic” stylized models of user behavior without revealing user data or sensitive industry strategies.
blog: https://ai.googleblog.com/2019/11/recsim-configurable-simulation-platform.html
paper: https://arxiv.org/abs/1909.04847
code: https://github.com/google-research/recsim
#rs #rl
{kind=link}
Dream to Control: Learning Behaviors by Latent Imagination
Abstract: Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs are becoming feasible through deep learning, there are many potential ways for deriving behaviors from them. We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model. On 20 challenging visual control tasks, Dreamer exceeds existing approaches in data-efficiency, computation time, and final performance.
Dreamer learns long-horizon behaviors from images purely by latent imagination. For this, it backpropagates value estimates through trajectories imagined in the compact latent space of a learned world model. Dreamer solves visual control tasks using substantially fewer episodes than strong model-free agents.
Dreamer learns a world model from past experiences that can predict the future. It then learns action and value models in its compact latent space. The value model optimizes Bellman's consistency of imagined trajectories. The action model maximizes value estimates by propagating their analytic gradients back through imagined trajectories. When interacting with the environment, it simply executes the action model.
paper: https://arxiv.org/abs/1912.01603
github: https://github.com/google-research/dreamer
site: https://danijar.com/dreamer
#RL #Dreams #Imagination #DL #GoogleBrain #DeepMind
Abstract: Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs are becoming feasible through deep learning, there are many potential ways for deriving behaviors from them. We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model. On 20 challenging visual control tasks, Dreamer exceeds existing approaches in data-efficiency, computation time, and final performance.
Dreamer learns long-horizon behaviors from images purely by latent imagination. For this, it backpropagates value estimates through trajectories imagined in the compact latent space of a learned world model. Dreamer solves visual control tasks using substantially fewer episodes than strong model-free agents.
Dreamer learns a world model from past experiences that can predict the future. It then learns action and value models in its compact latent space. The value model optimizes Bellman's consistency of imagined trajectories. The action model maximizes value estimates by propagating their analytic gradients back through imagined trajectories. When interacting with the environment, it simply executes the action model.
paper: https://arxiv.org/abs/1912.01603
github: https://github.com/google-research/dreamer
site: https://danijar.com/dreamer
#RL #Dreams #Imagination #DL #GoogleBrain #DeepMind
Reinforcement Learning Upside Down: Don't Predict Rewards – Just Map Them to Actions by Juergen Schmidhuber
Traditional #RL predicts rewards and uses a myriad of methods for translating those predictions into good actions. ꓶꓤ shortcuts this process, creating a direct mapping from rewards, time horizons and other inputs to actions.
Without depending on reward predictions, and without explicitly maximizing expected rewards, ꓶꓤ simply learn by gradient descent to map task specifications or commands (such as: get lots of reward within little time) to action probabilities. Its success depends on the generalization abilities of deep/recurrent neural nets. Its potential drawbacks are essentially those of traditional gradient-based learning: local minima, underfitting, overfitting, etc.
Nevertheless, experiments in a separate paper show that even them initial pilot version of ꓶꓤ can outperform traditional RL methods on certain challenging problems.
A closely related Imitate-Imitator approach is to imitate a robot, then let it learn to map its observations of the imitated behavior to its own behavior, then let it generalize, by demonstrating something new, to be imitated by the robot.
more at paper: https://arxiv.org/abs/1912.02875
Traditional #RL predicts rewards and uses a myriad of methods for translating those predictions into good actions. ꓶꓤ shortcuts this process, creating a direct mapping from rewards, time horizons and other inputs to actions.
Without depending on reward predictions, and without explicitly maximizing expected rewards, ꓶꓤ simply learn by gradient descent to map task specifications or commands (such as: get lots of reward within little time) to action probabilities. Its success depends on the generalization abilities of deep/recurrent neural nets. Its potential drawbacks are essentially those of traditional gradient-based learning: local minima, underfitting, overfitting, etc.
Nevertheless, experiments in a separate paper show that even them initial pilot version of ꓶꓤ can outperform traditional RL methods on certain challenging problems.
A closely related Imitate-Imitator approach is to imitate a robot, then let it learn to map its observations of the imitated behavior to its own behavior, then let it generalize, by demonstrating something new, to be imitated by the robot.
more at paper: https://arxiv.org/abs/1912.02875
{kind=link}
Driverless DeLorean drifting
#Stanford researchers taught autonomous car driving AI to drift to handle hazardous conditions better.
Link: https://news.stanford.edu/2019/12/20/autonomous-delorean-drives-sideways-move-forward/
#Autonomous #selfdriving #RL #CV #DL #DeLorean
#Stanford researchers taught autonomous car driving AI to drift to handle hazardous conditions better.
Link: https://news.stanford.edu/2019/12/20/autonomous-delorean-drives-sideways-move-forward/
#Autonomous #selfdriving #RL #CV #DL #DeLorean
An autonomous AI racecar using NVIDIA Jetson Nano
Usually DS means some blue collar work. Rare cases suggest physical interactions. This set by #NVidia allows to build $400/$600 toy car capable of #selfdriving.
#JetRacer comes with a couple examples to get you up and running. The examples are in the format of Jupyter Notebooks, which are interactive documents which combine text, code, and visualization. Once you've completed the notebooks, start tweaking them to create your own racing software!
Github: https://github.com/NVIDIA-AI-IOT/jetracer
#autonomousvehicle #rl #jupyter #physical
Usually DS means some blue collar work. Rare cases suggest physical interactions. This set by #NVidia allows to build $400/$600 toy car capable of #selfdriving.
#JetRacer comes with a couple examples to get you up and running. The examples are in the format of Jupyter Notebooks, which are interactive documents which combine text, code, and visualization. Once you've completed the notebooks, start tweaking them to create your own racing software!
Github: https://github.com/NVIDIA-AI-IOT/jetracer
#autonomousvehicle #rl #jupyter #physical
The Ingredients of Real World Robotic Reinforcement Learning
Blog post describing experiments on applying #RL in real world.
Blog post: https://bair.berkeley.edu/blog/2020/04/27/ingredients/
Paper: https://openreview.net/forum?id=rJe2syrtvS
#DL #robotics
Blog post describing experiments on applying #RL in real world.
Blog post: https://bair.berkeley.edu/blog/2020/04/27/ingredients/
Paper: https://openreview.net/forum?id=rJe2syrtvS
#DL #robotics
🤖 The NetHack Learning Environment
#Facebook launched new Reinforcement Learning environment for training agents based on #NetHack game. Nethack has nothing to do with what is considered common cybersecurity now, but it is an early terminal-based Minecraft (as a matter of fact one might say «console NetHack game» to go ‘all in’ in a word pun game).
NetHack is a wonderful RPG adventure game, happening in dungeon. Players control
#NLE uses python and ZeroMQ and we are looking forward to interesting applications or showcases to arise from this release.
Github: https://github.com/facebookresearch/nle
NetHack official page: http://nethack.org
#RL
#Facebook launched new Reinforcement Learning environment for training agents based on #NetHack game. Nethack has nothing to do with what is considered common cybersecurity now, but it is an early terminal-based Minecraft (as a matter of fact one might say «console NetHack game» to go ‘all in’ in a word pun game).
NetHack is a wonderful RPG adventure game, happening in dungeon. Players control
@ sign moving in ASCII-based environment, fighting enemies and doing quests. If you haven’t played it you are missing a whole piece of gaming culture and our editorial team kindly cheers you on at least trying to play it. Though now there lots of wikis and playing guides, canonicial way to play it is to dive into source code for looking up the keys and getting the whole idea of what to expect from different situations.#NLE uses python and ZeroMQ and we are looking forward to interesting applications or showcases to arise from this release.
Github: https://github.com/facebookresearch/nle
NetHack official page: http://nethack.org
#RL
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
This paper introduces a new method that significantly improves the sample efficiency of RL algorithms when learning from raw pixel data.
CURL architecture consists of three models: Query Encoder, Key Encoder, and RL agent. Query Encoder outputs embedding which used in RL agent as state representation. Contrastive loss computed from outputs of Query Encoder and Key Encoder. An important thing is that Query Encoder learns to minimize both RL and contrastive losses which allow all models to be trained jointly.
The method was tested on Atari and DeepMind Control tasks with limited interaction steps. It showed SOTA results for most of these tasks.
Paper: https://arxiv.org/abs/2004.04136.pdf
Code: https://github.com/MishaLaskin/curl
#rl #agent #reinforcement #learning
This paper introduces a new method that significantly improves the sample efficiency of RL algorithms when learning from raw pixel data.
CURL architecture consists of three models: Query Encoder, Key Encoder, and RL agent. Query Encoder outputs embedding which used in RL agent as state representation. Contrastive loss computed from outputs of Query Encoder and Key Encoder. An important thing is that Query Encoder learns to minimize both RL and contrastive losses which allow all models to be trained jointly.
The method was tested on Atari and DeepMind Control tasks with limited interaction steps. It showed SOTA results for most of these tasks.
Paper: https://arxiv.org/abs/2004.04136.pdf
Code: https://github.com/MishaLaskin/curl
#rl #agent #reinforcement #learning
{kind=link}