
Forwarded from Machinelearning
🦩 OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
An open-source framework for training large multimodal models.
OpenFlamingo - семейство авторегрессионных моделей для обучения LMM в стиле Flamingo с параметрами от 3B до 9B.
OpenFlamingo можно использовать для создания подписи к изображению или для создания тейзисов на основе изображения. Преимуществом такого подхода является возможность быстрой адаптации к новым задачам с помощью внутриконтекстного обучения.
🖥 Github: https://github.com/mlfoundations/open_flamingo
📕 Paper: https://arxiv.org/abs/2308.01390
⭐️ Demo: https://huggingface.co/spaces/openflamingo/OpenFlamingo
☑️ Dataset: https://paperswithcode.com/dataset/flickr30k
ai_machinelearning_big_data
An open-source framework for training large multimodal models.
OpenFlamingo - семейство авторегрессионных моделей для обучения LMM в стиле Flamingo с параметрами от 3B до 9B.
OpenFlamingo можно использовать для создания подписи к изображению или для создания тейзисов на основе изображения. Преимуществом такого подхода является возможность быстрой адаптации к новым задачам с помощью внутриконтекстного обучения.
pip install open-flamingoai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from gonzo-обзоры ML статей
An interesting theoretical result on gradient descent complexity. I missed it before.
https://www.quantamagazine.org/computer-scientists-discover-limits-of-major-research-algorithm-20210817/
The Complexity of Gradient Descent: CLS = PPAD ∩ PLS
https://arxiv.org/abs/2011.01929
https://www.quantamagazine.org/computer-scientists-discover-limits-of-major-research-algorithm-20210817/
The Complexity of Gradient Descent: CLS = PPAD ∩ PLS
https://arxiv.org/abs/2011.01929
Quanta Magazine
Computer Scientists Discover Limits of Major Research Algorithm | Quanta Magazine
The most widely used technique for finding the largest or smallest values of a math function turns out to be a fundamentally difficult computational problem.
Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
In an effort to tackle the generation latency of large language models (LLMs), a new approach Skeleton-of-Thought (SoT) has been developed. Motivated by human thinking and writing processes, SoT guides LLMs to generate the "skeleton" of an answer first and then fills in the content in parallel. The result is a remarkable speed-up of up to 2.39x across 11 different LLMs without losing the integrity of sequential decoding.
What sets SoT apart is its potential to improve answer quality in terms of diversity and relevance, shedding light on an exciting avenue in AI. As an initial attempt at data-centric optimization for efficiency, SoT showcases the fascinating possibility of having machines that can think more like humans.
Paper link: https://arxiv.org/abs/2307.15337
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-sot
#deeplearning #nlp #llm
In an effort to tackle the generation latency of large language models (LLMs), a new approach Skeleton-of-Thought (SoT) has been developed. Motivated by human thinking and writing processes, SoT guides LLMs to generate the "skeleton" of an answer first and then fills in the content in parallel. The result is a remarkable speed-up of up to 2.39x across 11 different LLMs without losing the integrity of sequential decoding.
What sets SoT apart is its potential to improve answer quality in terms of diversity and relevance, shedding light on an exciting avenue in AI. As an initial attempt at data-centric optimization for efficiency, SoT showcases the fascinating possibility of having machines that can think more like humans.
Paper link: https://arxiv.org/abs/2307.15337
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-sot
#deeplearning #nlp #llm
{kind=link}
Forwarded from ml4se
PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback
In this paper, the authors introduce a novel framework, namely RRTF (Rank Responses to align Test&Teacher Feedback), and present a new Code LLM, namely PanGu-Coder2. Firstly, they adopt the Evol-Instruct technique to obtain a substantial amount of high-quality natural language instruction and code solution data pairs. Then, they train the base model by ranking candidate code solutions using feedback from test cases and heurstic preferences.
Through comprehensive evaluations on HumanEval, CodeEval, and LeetCode benchmarks, PanGu-Coder2 achieves new state-of-the-art performance among billion-parameter-level Code LLMs, surpassing all of the existing ones by a large margin.
In this paper, the authors introduce a novel framework, namely RRTF (Rank Responses to align Test&Teacher Feedback), and present a new Code LLM, namely PanGu-Coder2. Firstly, they adopt the Evol-Instruct technique to obtain a substantial amount of high-quality natural language instruction and code solution data pairs. Then, they train the base model by ranking candidate code solutions using feedback from test cases and heurstic preferences.
Through comprehensive evaluations on HumanEval, CodeEval, and LeetCode benchmarks, PanGu-Coder2 achieves new state-of-the-art performance among billion-parameter-level Code LLMs, surpassing all of the existing ones by a large margin.
AI Index: An opportunity for AI development
The National Centre for the Development of Artificial Intelligence has launched a nationwide study to determine the index of readiness of domestic organizations to implement artificial intelligence.
The AI Readiness Index will be calculated on several application areas: the use of AI in organizations, the level of maturity of infrastructure and data management, the availability of human resources and existing competencies, as well as a number of other areas that will show the availability of AI technologies for businesses.
The study is being conducted until 31 August 2023 and is confidential, the results in aggregated form will be posted on the National AI Portal: https://ai.gov.ru/.
At the moment, many SME companies do not have sufficient capabilities to implement AI. This study will help to influence support measures for businesses. We cannot claim that this study will make AI implementation available to all companies, but it is an opportunity to give an impetus to the strengthening and development of state support in the industry. Each of us can contribute to the common cause of AI development in Russia by taking the survey and participating in the research.
Here is the link: https://aibe.wciom.ru/.
The National Centre for the Development of Artificial Intelligence has launched a nationwide study to determine the index of readiness of domestic organizations to implement artificial intelligence.
The AI Readiness Index will be calculated on several application areas: the use of AI in organizations, the level of maturity of infrastructure and data management, the availability of human resources and existing competencies, as well as a number of other areas that will show the availability of AI technologies for businesses.
The study is being conducted until 31 August 2023 and is confidential, the results in aggregated form will be posted on the National AI Portal: https://ai.gov.ru/.
At the moment, many SME companies do not have sufficient capabilities to implement AI. This study will help to influence support measures for businesses. We cannot claim that this study will make AI implementation available to all companies, but it is an opportunity to give an impetus to the strengthening and development of state support in the industry. Each of us can contribute to the common cause of AI development in Russia by taking the survey and participating in the research.
Here is the link: https://aibe.wciom.ru/.
aibe.wciom.ru
ВЦИОМ ИИ
ВЦИОМ: опрос по теме ИИ
Forwarded from Machinelearning
🚀 AgentBench: Evaluating LLMs as Agents.
AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting.
Комплексный бенчмарк для оценки работы LLM агентов.
🖥 Github: https://github.com/thudm/agentbench
📕 Paper: https://arxiv.org/abs/2308.03688v1
☑️ Dataset: https://paperswithcode.com/dataset/alfworld
ai_machinelearning_big_data
AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting.
Комплексный бенчмарк для оценки работы LLM агентов.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
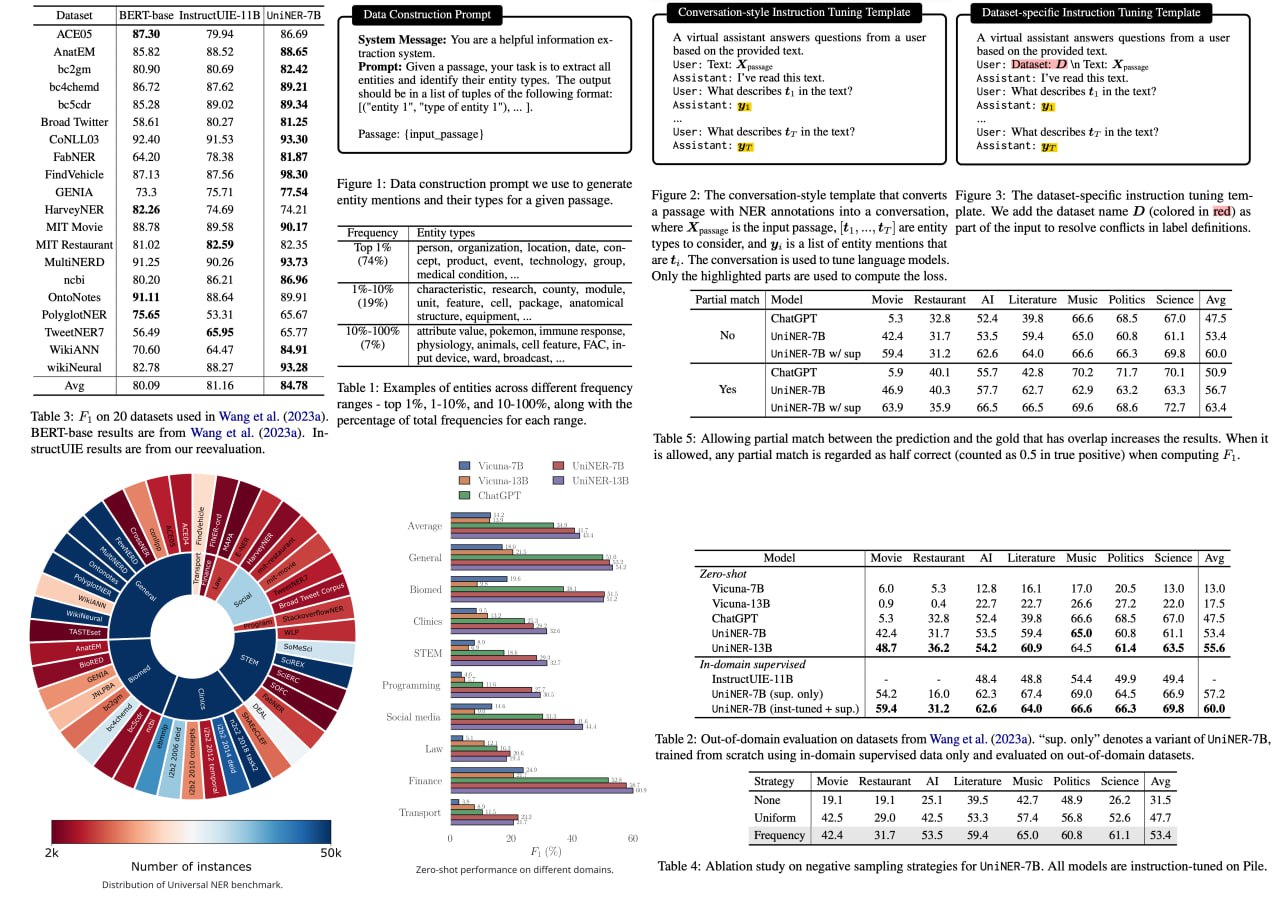
UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
{kind=link}
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF), the key method for fine-tuning large language models (LLMs), is placed under the microscope in this paper. While recognizing RLHF's central role in aligning AI systems with human goals, the authors boldly tackle the uncharted territory of its flaws and limitations. They not only dissect open problems and the core challenges but also map out pioneering techniques to augment RLHF. This insightful work culminates in proposing practical standards for societal oversight, marking a critical step towards a multi-dimensional and responsible approach to the future of safer AI systems.
Paper link: https://arxiv.org/abs/2307.15217
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-rlhf-overview
#deeplearning #nlp #llm #rlhf
Reinforcement Learning from Human Feedback (RLHF), the key method for fine-tuning large language models (LLMs), is placed under the microscope in this paper. While recognizing RLHF's central role in aligning AI systems with human goals, the authors boldly tackle the uncharted territory of its flaws and limitations. They not only dissect open problems and the core challenges but also map out pioneering techniques to augment RLHF. This insightful work culminates in proposing practical standards for societal oversight, marking a critical step towards a multi-dimensional and responsible approach to the future of safer AI systems.
Paper link: https://arxiv.org/abs/2307.15217
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-rlhf-overview
#deeplearning #nlp #llm #rlhf
{kind=link}
Forwarded from Machinelearning
Family of fine-tuned and merged LLMs that achieves the strongest performance and currently stands at first place in HuggingFace's
Cемейство точно настроенных больших языковых моделей (LLM), которое достигло самой высокой производительности и в настоящее время занимает первое место в открытой таблице лидеров LLM HuggingFace на момент выхода этой статьи
Модель 13B Platypus может быть обучена на одном GPU A100 на 25 тыс. вопросов за 5 часов!
git clone https://github.com/lm-sys/FastChat.git
cd FastChatai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
The fusion of transformer and convolutional architectures has ushered in a new era of enhanced model accuracy and efficiency, and FastViT is at the forefront of this revolution. This novel hybrid vision transformer architecture boasts an impressive latency-accuracy trade-off, setting new benchmarks in the field. Key to its success is the RepMixer, an innovative token mixing operator that utilizes structural reparameterization to slash memory access costs by doing away with traditional skip-connections.
In practical terms, FastViT's prowess is undeniable. Not only is it a staggering 3.5x faster than CMT on mobile devices for ImageNet accuracy, but it also leaves EfficientNet and ConvNeXt trailing in its wake, being 4.9x and 1.9x faster respectively. Additionally, when pitted against MobileOne at a similar latency, FastViT emerges triumphant with a 4.2% superior Top-1 accuracy. Across a spectrum of tasks, from image classification and detection to segmentation and 3D mesh regression, FastViT consistently outshines its competitors, showcasing both remarkable speed and robustness against out-of-distribution samples and corruptions.
Paper link: https://huggingface.co/papers/2303.14189
Code link: https://github.com/apple/ml-fastvit
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-fastvit
#deeplearning #cv
The fusion of transformer and convolutional architectures has ushered in a new era of enhanced model accuracy and efficiency, and FastViT is at the forefront of this revolution. This novel hybrid vision transformer architecture boasts an impressive latency-accuracy trade-off, setting new benchmarks in the field. Key to its success is the RepMixer, an innovative token mixing operator that utilizes structural reparameterization to slash memory access costs by doing away with traditional skip-connections.
In practical terms, FastViT's prowess is undeniable. Not only is it a staggering 3.5x faster than CMT on mobile devices for ImageNet accuracy, but it also leaves EfficientNet and ConvNeXt trailing in its wake, being 4.9x and 1.9x faster respectively. Additionally, when pitted against MobileOne at a similar latency, FastViT emerges triumphant with a 4.2% superior Top-1 accuracy. Across a spectrum of tasks, from image classification and detection to segmentation and 3D mesh regression, FastViT consistently outshines its competitors, showcasing both remarkable speed and robustness against out-of-distribution samples and corruptions.
Paper link: https://huggingface.co/papers/2303.14189
Code link: https://github.com/apple/ml-fastvit
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-fastvit
#deeplearning #cv
{kind=link}
Forwarded from Machinelearning
FLAIR: A Foundation LAnguage Image model of the Retina
🖥 Github: https://github.com/jusiro/flair
📕 Paper: https://arxiv.org/pdf/2308.07898v1.pdf
🔥 Dataset: https://paperswithcode.com/dataset/imagenet
@ai_machinelearning_big_data
🔥 Dataset: https://paperswithcode.com/dataset/imagenet
@ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
LISA: Reasoning Segmentation via Large Language Model
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
{kind=link}
Forwarded from Machinelearning
🪄WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
Model outperforms ChatGPT-3.5, Claude Instant-1, PaLM-2 and Minerva on GSM8k, simultaneously surpasses Text-davinci-002, PaLM-1 and GPT-3 on MATH.
Фреймворк WizardMath, который расширяет способности Llama-2 к математическому мышлению, применяя метод Reinforcement Learning from Evol-Instruct Feedback (RLEIF) к области математики.
WizardMath с существенным отрывом превосходит все остальные LLM с открытым исходным кодом в решение мат. задач.
🖥 Github: https://github.com/nlpxucan/wizardlm
📕 Paper: https://arxiv.org/abs/2308.09583v1
🤗 HF: https://huggingface.co/WizardLM
☑️ Dataset: https://paperswithcode.com/dataset/gsm8k
ai_machinelearning_big_data
Model outperforms ChatGPT-3.5, Claude Instant-1, PaLM-2 and Minerva on GSM8k, simultaneously surpasses Text-davinci-002, PaLM-1 and GPT-3 on MATH.
Фреймворк WizardMath, который расширяет способности Llama-2 к математическому мышлению, применяя метод Reinforcement Learning from Evol-Instruct Feedback (RLEIF) к области математики.
WizardMath с существенным отрывом превосходит все остальные LLM с открытым исходным кодом в решение мат. задач.
🤗 HF: https://huggingface.co/WizardLM
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
☄️Dataset Quantization
DQ is able to generate condensed small datasets for training unseen network architectures with state-of-the-art compression ratios for lossless model training.
Квантование наборов данных (DQ) - новая схема сжатия больших наборов данных в небольшие сабсеты, которые могут быть использованы для обучения любых нейросетевых архитектур.
🖥 Github: https://github.com/magic-research/dataset_quantization
📕 Paper: https://arxiv.org/abs/2308.10524v1
☑️ Dataset: https://paperswithcode.com/dataset/gsm8k
ai_machinelearning_big_data
DQ is able to generate condensed small datasets for training unseen network architectures with state-of-the-art compression ratios for lossless model training.
Квантование наборов данных (DQ) - новая схема сжатия больших наборов данных в небольшие сабсеты, которые могут быть использованы для обучения любых нейросетевых архитектур.
git clone https://github.com/vimar-gu/DQ.git
cd DQai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from ml4se
OWASP Top 10 for LLM
The OWASP Top 10 for Large Language Model Applications project aims to educate developers, designers, architects, managers, and organizations about the potential security risks when deploying and managing Large Language Models (LLMs). The project provides a list of the top 10 most critical vulnerabilities often seen in LLM applications, highlighting their potential impact, ease of exploitation, and prevalence in real-world applications. Examples of vulnerabilities include prompt injections, data leakage, inadequate sandboxing, and unauthorized code execution, among others. The goal is to raise awareness of these vulnerabilities, suggest remediation strategies, and ultimately improve the security posture of LLM applications.
1 Prompt Injection
2 Insecure Output Handling
3 Training Data Poisoning
4 Model Denial of Service
5 Supply Chain Vulnerabilities
6 Sensitive Information Disclosure
7 Insecure Plugin Design
8 Excessive Agency
9 Overreliance
10 Model Theft
PDF
The OWASP Top 10 for Large Language Model Applications project aims to educate developers, designers, architects, managers, and organizations about the potential security risks when deploying and managing Large Language Models (LLMs). The project provides a list of the top 10 most critical vulnerabilities often seen in LLM applications, highlighting their potential impact, ease of exploitation, and prevalence in real-world applications. Examples of vulnerabilities include prompt injections, data leakage, inadequate sandboxing, and unauthorized code execution, among others. The goal is to raise awareness of these vulnerabilities, suggest remediation strategies, and ultimately improve the security posture of LLM applications.
1 Prompt Injection
2 Insecure Output Handling
3 Training Data Poisoning
4 Model Denial of Service
5 Supply Chain Vulnerabilities
6 Sensitive Information Disclosure
7 Insecure Plugin Design
8 Excessive Agency
9 Overreliance
10 Model Theft