
Under the Boot of Google and Facebook and How to Crack it for better Performance
In this video, Alex Farseev from SoMin.ai will shed the light into the complex Digital Advertising ecosystem and will show you techniques, such as Long-Tail targeting, that we use in to crack the Ad Performance.
Link: https://youtu.be/p7wT_4Lf3Ks
In this video, Alex Farseev from SoMin.ai will shed the light into the complex Digital Advertising ecosystem and will show you techniques, such as Long-Tail targeting, that we use in to crack the Ad Performance.
Link: https://youtu.be/p7wT_4Lf3Ks
YouTube
Alex Farseev | Under the Boot of Google and Facebook and How to Crack it for better Performance
Data Fest Online 2021 https://fest.ai/2021/
ML in Marketing track https://ods.ai/tracks/ml-in-marketing-df2021
Modern Digital Advertising Platforms Leverage Machine Learning and AI to help Advertisers to achieve their goals. Being managed by humans, Advertising…
ML in Marketing track https://ods.ai/tracks/ml-in-marketing-df2021
Modern Digital Advertising Platforms Leverage Machine Learning and AI to help Advertisers to achieve their goals. Being managed by humans, Advertising…
Forwarded from Silero News (Alexander)
New Language Classifier For 116 Languages
- 116 languages (83% accuracy), 77 language groups (87% accuracy)
- Mutually intelligible languages are united into language groups (i.e. Serbian + Croatian + Bosnian)
- Trained on approx 20k hours of data (10k of which are for 5 most popular languages)
- 1.7M params
Shortcomings
- Predictably, related and mutually intelligible languages are hard to tell apart
- The confusion matrix mostly makes sense, except for low resource languages and English
- English has the lowest accuracy
- Dataset needs some further curation (i.e. remove hardly spoken or artificial languages)
- Make a model larger
Link
- https://github.com/snakers4/silero-vad
- 116 languages (83% accuracy), 77 language groups (87% accuracy)
- Mutually intelligible languages are united into language groups (i.e. Serbian + Croatian + Bosnian)
- Trained on approx 20k hours of data (10k of which are for 5 most popular languages)
- 1.7M params
Shortcomings
- Predictably, related and mutually intelligible languages are hard to tell apart
- The confusion matrix mostly makes sense, except for low resource languages and English
- English has the lowest accuracy
- Dataset needs some further curation (i.e. remove hardly spoken or artificial languages)
- Make a model larger
Link
- https://github.com/snakers4/silero-vad
GitHub
GitHub - snakers4/silero-vad: Silero VAD: pre-trained enterprise-grade Voice Activity Detector
Silero VAD: pre-trained enterprise-grade Voice Activity Detector - snakers4/silero-vad
Automated Machine Learning Library
Simple but powerful Automated Machine Learning library for tabular data. It uses efficient in-memory SAP HANA algorithms to automate routine Data Science tasks. Beats built-in solution in HANA, database from SAP. Written by 2 students as diploma project.
Features:
• Easy to use Python interface
• Automates most Machine Learning steps
• Complete documentation
• Intuitive web client
• Supports Regression and Binary Classification tasks
Roadmap:
• Text classification
• Multi class classification
• Forecasting
• Automate all ML steps
• Beat other libraries in accuracy
• More hyperparameter tuning methods
GitHub: https://github.com/dan0nchik/SAP-HANA-AutoML
Web app: https://share.streamlit.io/dan0nchik/sap-hana-automl/main/web.py
Docs: https://sap-hana-automl.readthedocs.io/en/latest/index.html#
Authors: @dan0nchik, @m_whiskas
#automl
Simple but powerful Automated Machine Learning library for tabular data. It uses efficient in-memory SAP HANA algorithms to automate routine Data Science tasks. Beats built-in solution in HANA, database from SAP. Written by 2 students as diploma project.
Features:
• Easy to use Python interface
• Automates most Machine Learning steps
• Complete documentation
• Intuitive web client
• Supports Regression and Binary Classification tasks
Roadmap:
• Text classification
• Multi class classification
• Forecasting
• Automate all ML steps
• Beat other libraries in accuracy
• More hyperparameter tuning methods
GitHub: https://github.com/dan0nchik/SAP-HANA-AutoML
Web app: https://share.streamlit.io/dan0nchik/sap-hana-automl/main/web.py
Docs: https://sap-hana-automl.readthedocs.io/en/latest/index.html#
Authors: @dan0nchik, @m_whiskas
#automl
GitHub
GitHub - dan0nchik/SAP-HANA-AutoML: Python Automated Machine Learning library for tabular data.
Python Automated Machine Learning library for tabular data. - dan0nchik/SAP-HANA-AutoML
Long-Short Transformer: Efficient Transformers for Language and Vision
This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. The authors propose Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. It aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms. Transformer-LS can be applied to both autoregressive and bidirectional models without additional complexity.
This method outperforms the state-of-the-art models on multiple tasks in language and vision domains. For instance, Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than previous methods, while being faster and is able to handle 3× as long sequences. On ImageNet, it can obtain 84.1% Top-1 accuracy, while being more scalable on high-resolution images.
Paper: https://arxiv.org/abs/2107.02192
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-transformerls
#deeplearning #cv #nlp #transformer #attention
This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. The authors propose Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. It aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms. Transformer-LS can be applied to both autoregressive and bidirectional models without additional complexity.
This method outperforms the state-of-the-art models on multiple tasks in language and vision domains. For instance, Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than previous methods, while being faster and is able to handle 3× as long sequences. On ImageNet, it can obtain 84.1% Top-1 accuracy, while being more scalable on high-resolution images.
Paper: https://arxiv.org/abs/2107.02192
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-transformerls
#deeplearning #cv #nlp #transformer #attention
{kind=link}
We are happy to announce the start of our first ODS Summer of Code #1
This is our first official Summer School, designed after the famous Google GSoC. ODS Summer School activities are hosted on the same basis of Data Fest - if you are already registered to the Data Fest 2021 feel free to join ODS SoC projects.
ODS Summer School is 100% online and lasts until September 3rd with a finale on ODS Course Fest. We will have an equator stream on August 6th.
At ODS Summer of Code start we have 14 Summer projects grouped into 3 tracks:
• Open Source: if you ever wanted to develop an open source AutoML or maybe finally get used to Catalyst, scikit-uplift, DeepPavlov or DVC
• Open Science: for those of you who want to have more ML
• ML4SG: to make the world a better place
We also have our hardware-centric partners for Summer School - a combo of Intel and SberCloud. For those of you who would like to know more about project development - visit their joint track CloudCity and register on aicloud to try out awesome tech for free.
We managed to get a prize pool of 1,000,000+₽. All the prize information is available on the SoC prize page.
There will be an onboarding in ODS Spatial Chat this Saturday, July 17th at 1 PM. Feel free to join!
ODS Summer of Code #1: https://ods.ai/tracks/summer-of-code-2021
Register: https://ods.ai/events/datafest2021
SoC prize page: https://ods.ai/tracks/summer-of-code-2021/blocks/ae0e78c2-ae3e-468d-bc80-9346bab55465
ODS Spatial Chat: https://live.ods.ai/
This is our first official Summer School, designed after the famous Google GSoC. ODS Summer School activities are hosted on the same basis of Data Fest - if you are already registered to the Data Fest 2021 feel free to join ODS SoC projects.
ODS Summer School is 100% online and lasts until September 3rd with a finale on ODS Course Fest. We will have an equator stream on August 6th.
At ODS Summer of Code start we have 14 Summer projects grouped into 3 tracks:
• Open Source: if you ever wanted to develop an open source AutoML or maybe finally get used to Catalyst, scikit-uplift, DeepPavlov or DVC
• Open Science: for those of you who want to have more ML
• ML4SG: to make the world a better place
We also have our hardware-centric partners for Summer School - a combo of Intel and SberCloud. For those of you who would like to know more about project development - visit their joint track CloudCity and register on aicloud to try out awesome tech for free.
We managed to get a prize pool of 1,000,000+₽. All the prize information is available on the SoC prize page.
There will be an onboarding in ODS Spatial Chat this Saturday, July 17th at 1 PM. Feel free to join!
ODS Summer of Code #1: https://ods.ai/tracks/summer-of-code-2021
Register: https://ods.ai/events/datafest2021
SoC prize page: https://ods.ai/tracks/summer-of-code-2021/blocks/ae0e78c2-ae3e-468d-bc80-9346bab55465
ODS Spatial Chat: https://live.ods.ai/
{kind=link}
JupyterLite is a JupyterLab distribution that runs entirely in the web browser, backed by in-browser language kernels.
Scientific, Data science and visualisation packages are supported.
Basically it means you can use Jupyter just by opening a new browser tab. Starting to learn Data Science has never been easier.
Read the intro[1] for full feature list, or try it online[2].
#jupyterlab #jupyterlite
[1] https://blog.jupyter.org/jupyterlite-jupyter-%EF%B8%8F-webassembly-%EF%B8%8F-python-f6e2e41ab3fa
[2] https://jupyterlite.github.io/demo
Scientific, Data science and visualisation packages are supported.
Basically it means you can use Jupyter just by opening a new browser tab. Starting to learn Data Science has never been easier.
Read the intro[1] for full feature list, or try it online[2].
#jupyterlab #jupyterlite
[1] https://blog.jupyter.org/jupyterlite-jupyter-%EF%B8%8F-webassembly-%EF%B8%8F-python-f6e2e41ab3fa
[2] https://jupyterlite.github.io/demo
Medium
JupyterLite: Jupyter ❤️ WebAssembly ❤️ Python
JupyterLite is a JupyterLab distribution that runs entirely in the web browser, backed by in-browser language kernels powered by…
Blender Bot 2.0: An open source chatbot that builds long-term memory and searches the internet
Bot is capable of supporting a dialog and remembering the context of the sequential questions.
Blogpost: https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet
Github: https://github.com/facebookresearch/ParlAI
Paper 1: https://parl.ai/projects/sea
Paper 2: https://parl.ai/projects/msc
#chatbot #NLU #facebookai
Bot is capable of supporting a dialog and remembering the context of the sequential questions.
Blogpost: https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet
Github: https://github.com/facebookresearch/ParlAI
Paper 1: https://parl.ai/projects/sea
Paper 2: https://parl.ai/projects/msc
#chatbot #NLU #facebookai
Forwarded from Gradient Dude
OpenAI disbands its robotics research team. This is exactly the same team that, for example, taught a robotic arm to solve a Rubik's cube using Reinforcement Learning. This decision was made because the company considers more promising research in areas where physical equipment is not required (except for servers, of course), and there is already a lot of data available. And also for economic reasons, since Software as a Services is a business with a much higher margin. Yes, the joke is that the non-profit organization OpenAI is considered more and more about profit. This is understandable because it takes a lot of money to create general artificial intelligence (AGI) that can learn all the tasks that a person can do and even more.
It's no secret that research in the field of robotics is also a very costly activity that requires a lot of investment. Therefore, there are not so many companies involved in this. Among the large and successful, only Boston Dynamics comes to mind, which has already changed several owners. Did you know that in 2013 Google acquired Boston Dynamics, then Google also scaled down its robotics research program, and in 2017 sold Boston Dynamic to the Japanese firm SoftBank. The adventures of Boston Dynamics did not end there, and in December 2020 SoftBank resold 80% of the shares (a controlling stake) to the automaker Hyundai. This looks somehow fishy as if every company understands after a few years that it is still difficult to make a profit from Boston Dynamics and sells it to another patsy.
In any case, it is very interesting to observe which focus areas are chosen by the titans of AI research. But I'm a bit sad that robots are still lagging behind.
It's no secret that research in the field of robotics is also a very costly activity that requires a lot of investment. Therefore, there are not so many companies involved in this. Among the large and successful, only Boston Dynamics comes to mind, which has already changed several owners. Did you know that in 2013 Google acquired Boston Dynamics, then Google also scaled down its robotics research program, and in 2017 sold Boston Dynamic to the Japanese firm SoftBank. The adventures of Boston Dynamics did not end there, and in December 2020 SoftBank resold 80% of the shares (a controlling stake) to the automaker Hyundai. This looks somehow fishy as if every company understands after a few years that it is still difficult to make a profit from Boston Dynamics and sells it to another patsy.
In any case, it is very interesting to observe which focus areas are chosen by the titans of AI research. But I'm a bit sad that robots are still lagging behind.
VentureBeat
OpenAI disbands its robotics research team
OpenAI has disbanded its robotics team in what might be a reflection of economic and commercial realities.
🔪DiSECt: A Differentiable Simulation Engine for Autonomous Robotic Cutting
A differentiable simulator for robotic cutting at #RSS2021. It achieves highly accurate predictions of the knife forces, optimizes cutting actions & more!
Project site: https://diff-cutting-sim.github.io
ArXiV: https://arxiv.org/abs/2105.12244
A differentiable simulator for robotic cutting at #RSS2021. It achieves highly accurate predictions of the knife forces, optimizes cutting actions & more!
Project site: https://diff-cutting-sim.github.io
ArXiV: https://arxiv.org/abs/2105.12244
Politicians phone distraction tracking as an art project
Enthusiast used livestream of flemish goverment sessions to track those politicians who distracted on the phones during their worktime.
Project website: https://driesdepoorter.be/theflemishscrollers/
Twitter: https://twitter.com/FlemishScroller
#keras #neuroart #politics #ml4sg
Enthusiast used livestream of flemish goverment sessions to track those politicians who distracted on the phones during their worktime.
Project website: https://driesdepoorter.be/theflemishscrollers/
Twitter: https://twitter.com/FlemishScroller
#keras #neuroart #politics #ml4sg
{kind=link}
Mava: a scalable, research framework for multi-agent reinforcement learning
The framework integrates with popular MARL environments such as PettingZoo, SMAC, RoboCup, OpenSpiel, Flatland , as well as a few custom environments.
Mava includes distributed implementations of multi-agent versions of ddpg, d4pg, dqn, ppo, as well as DIAL, VDN and QMIX.
ArXiV: https://arxiv.org/pdf/2107.01460.pdf
GitHub: https://github.com/instadeepai/Mava
#MARL #RL #dl
The framework integrates with popular MARL environments such as PettingZoo, SMAC, RoboCup, OpenSpiel, Flatland , as well as a few custom environments.
Mava includes distributed implementations of multi-agent versions of ddpg, d4pg, dqn, ppo, as well as DIAL, VDN and QMIX.
ArXiV: https://arxiv.org/pdf/2107.01460.pdf
GitHub: https://github.com/instadeepai/Mava
#MARL #RL #dl
GitHub
GitHub - instadeepai/Mava: 🦁 A research-friendly codebase for fast experimentation of multi-agent reinforcement learning in JAX
🦁 A research-friendly codebase for fast experimentation of multi-agent reinforcement learning in JAX - instadeepai/Mava
Forwarded from Towards NLP🇺🇦
Natural Language Processing News
by Sebastian Ruder:
- Github Copilot: interesting upcoming technology that can leave you without job;
- The Perceiver: new architecture motivated by Transformer that can deal with very high-dimensional inputs;
- NL augementer: collaborative work that aims to collect all accepted transformations to NL; you still can participate and be a co-author of the paper!
and more here.
by Sebastian Ruder:
- Github Copilot: interesting upcoming technology that can leave you without job;
- The Perceiver: new architecture motivated by Transformer that can deal with very high-dimensional inputs;
- NL augementer: collaborative work that aims to collect all accepted transformations to NL; you still can participate and be a co-author of the paper!
and more here.
GitHub
GitHub Copilot · Your AI pair programmer
GitHub Copilot works alongside you directly in your editor, suggesting whole lines or entire functions for you.
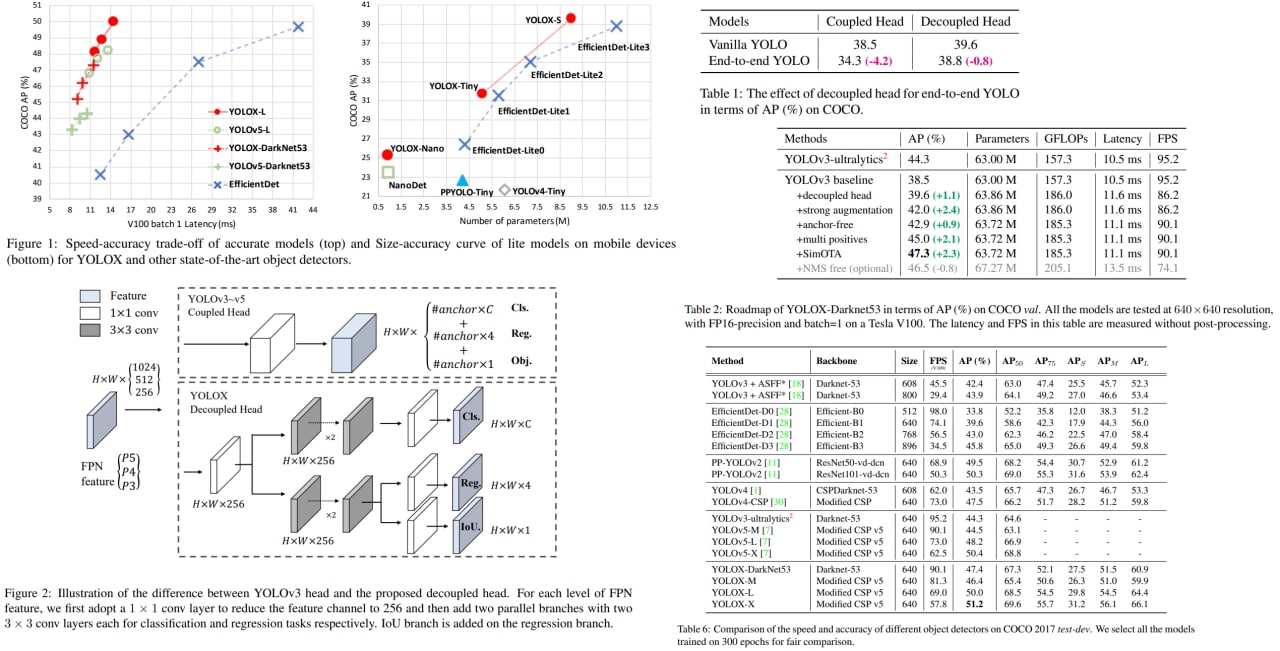
YOLOX: Exceeding YOLO Series in 2021
This paper presents a new high-performance variation of YOLO - YOLOX. Now it has an anchor-free detector, a decoupled head, and uses the leading label assignment strategy SimOTA.
Thanks to these changes, it reaches state-of-the-art results across a large scale range of models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
For YOLOv3, one of the most widely used detectors in industry, they boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP.
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
Paper: https://arxiv.org/abs/2107.08430
Code: https://github.com/Megvii-BaseDetection/YOLOX
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-yolox
#deeplearning #cv #objectdetection #endtoend #anchorfree
This paper presents a new high-performance variation of YOLO - YOLOX. Now it has an anchor-free detector, a decoupled head, and uses the leading label assignment strategy SimOTA.
Thanks to these changes, it reaches state-of-the-art results across a large scale range of models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
For YOLOv3, one of the most widely used detectors in industry, they boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP.
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
Paper: https://arxiv.org/abs/2107.08430
Code: https://github.com/Megvii-BaseDetection/YOLOX
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-yolox
#deeplearning #cv #objectdetection #endtoend #anchorfree
{kind=link}
Forwarded from Gradient Dude
Researchers from NVIDIA (in particular Tero Karras) have once again "solved" image generation.
This time, the scientists were able to remove aliasing in the generator. In a nutshell, then the reason for the artifacts was careless signal processing in the CNN resulting in incorrect discretization. The signal could not be accurately reconstructed, which led to unnatural "jerks" noticeable in the video. The authors have modified the generator to prevent these negative sampling effects.
The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales.
The code is not available yet, but I'm sure NVIDIA will release it soon.
Read more about Alias-Free GAN here.
This time, the scientists were able to remove aliasing in the generator. In a nutshell, then the reason for the artifacts was careless signal processing in the CNN resulting in incorrect discretization. The signal could not be accurately reconstructed, which led to unnatural "jerks" noticeable in the video. The authors have modified the generator to prevent these negative sampling effects.
The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales.
The code is not available yet, but I'm sure NVIDIA will release it soon.
Read more about Alias-Free GAN here.
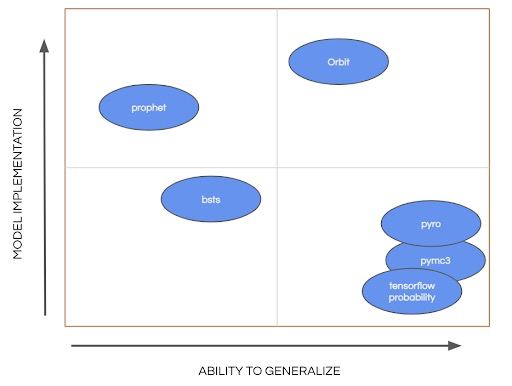
Orbit — An Open Source Package for Time Series Inference and Forecasting
Object-ORiented BayesIan Time Series is a new project for #timeseries forecasting by #Uber team. Has #scikit-learn compatible interface and claimed to have results comparable to #prophet .
Post: https://eng.uber.com/orbit/
Docs: https://uber.github.io/orbit/about.html
GitHub: https://github.com/uber/orbit/
Object-ORiented BayesIan Time Series is a new project for #timeseries forecasting by #Uber team. Has #scikit-learn compatible interface and claimed to have results comparable to #prophet .
Post: https://eng.uber.com/orbit/
Docs: https://uber.github.io/orbit/about.html
GitHub: https://github.com/uber/orbit/
{kind=link}
Forwarded from Silero News (Alexander)
New TTS Models for Minority Languages of the CIS / Russia
In collaboration with the community, we created totally unique models for the languages of the peoples of Russia / the CIS:
- Bashkir (aigul_v2)
- Kalmyk (erdni_v2)
- Tatar (dilyara_v2)
- Uzbek (dilnavoz_v2)
We also tried to create the Ukrainian voice, but the data we had (sourced from audiobooks) was not very good (all other voices were created from recordings).
Some models sound almost perfect, some a bit worse. Typically this boils down to how speakers can provide steady consistent recordings.
We used anywhere from 1 hour to 6 hours of recordings to create each voice.
These models obviously do not include automated stress and have the same major caveats as other v2 models (i.e. best used with batch size 1 on 2-4 CPU threads).
Link
- https://github.com/snakers4/silero-models#text-to-speech
In collaboration with the community, we created totally unique models for the languages of the peoples of Russia / the CIS:
- Bashkir (aigul_v2)
- Kalmyk (erdni_v2)
- Tatar (dilyara_v2)
- Uzbek (dilnavoz_v2)
We also tried to create the Ukrainian voice, but the data we had (sourced from audiobooks) was not very good (all other voices were created from recordings).
Some models sound almost perfect, some a bit worse. Typically this boils down to how speakers can provide steady consistent recordings.
We used anywhere from 1 hour to 6 hours of recordings to create each voice.
These models obviously do not include automated stress and have the same major caveats as other v2 models (i.e. best used with batch size 1 on 2-4 CPU threads).
Link
- https://github.com/snakers4/silero-models#text-to-speech
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Baidu announced opening 10k sq m park with 200 operating autonomous vehicles in China.
Source: https://twitter.com/Baidu_Inc/status/1420776376861405185
#Baidu #selfdriving
Source: https://twitter.com/Baidu_Inc/status/1420776376861405185
#Baidu #selfdriving
Tonight at 9 p.m. Moscow Time, Russia’s Krasnaya Polyana resort will host the AI & Chess meetup, bringing together data scientists and professional chess players
Location: Galaxy Mall in Krasnaya Polyana, Sochi + livestream
Program:
9-9:05 p.m.
Introductory speech.
9:05-9:25 p.m. (Rus)
Mark Glukhovsky, Executive Director of the Russian Chess Federation: “Chess and Computer Technology: What AI Is and How It Is Changing the Chess World.”
9:25-9:40 p.m. (Rus)
Conversation with Sergei Shipov, a Russian professional chess player, grandmaster, chess coach and commentator: “The Role of the Computer in Professional Chess Player Training.”
9:40-9:55 p.m. (Rus)
Aleksandr Shimanov, a Russian professional chess player, grandmaster and commentator, reviews the most incredible game from the AlphaZero vs. Stockfish match, which pitted the most powerful chess engines against each other.
9:55-10:25 p.m. (Eng)
Ulrich Paquet and Nenad Tomašev, DeepMind researchers and authors of papers on AlphaZero in collaboration with Vladimir Kramnik: “Inner Workings of Chess Algorithms Based on AI and Neural Networks: AlphaZero and Beyond.”
10:25-10:45 p.m. (Eng)
Discussion:
— Effects of technology, AI engines and applications on a chess player’s training, style and mindset.
— Challenges that arise in the use of chess engines.
— Impact of chess on life and vice versa, and how the situation has evolved with the advances in chess technology.
— Future prospects of the chess-AI symbiosis in education, entertainment and self-development.
Discussion participants:
Ulrich Paquet and Nenad Tomašev, researchers, DeepMind;
Sergey Rykovanov (professor) and Yuri Shkandybin (systems architect), Skoltech’s supercomputing group;
Aleksandr Shimanov, Russian chess player, grandmaster.
Links:
Sign up: http://surl.li/abbvc
Livestream: https://youtu.be/BDWELYal47c
Location: Galaxy Mall in Krasnaya Polyana, Sochi + livestream
Program:
9-9:05 p.m.
Introductory speech.
9:05-9:25 p.m. (Rus)
Mark Glukhovsky, Executive Director of the Russian Chess Federation: “Chess and Computer Technology: What AI Is and How It Is Changing the Chess World.”
9:25-9:40 p.m. (Rus)
Conversation with Sergei Shipov, a Russian professional chess player, grandmaster, chess coach and commentator: “The Role of the Computer in Professional Chess Player Training.”
9:40-9:55 p.m. (Rus)
Aleksandr Shimanov, a Russian professional chess player, grandmaster and commentator, reviews the most incredible game from the AlphaZero vs. Stockfish match, which pitted the most powerful chess engines against each other.
9:55-10:25 p.m. (Eng)
Ulrich Paquet and Nenad Tomašev, DeepMind researchers and authors of papers on AlphaZero in collaboration with Vladimir Kramnik: “Inner Workings of Chess Algorithms Based on AI and Neural Networks: AlphaZero and Beyond.”
10:25-10:45 p.m. (Eng)
Discussion:
— Effects of technology, AI engines and applications on a chess player’s training, style and mindset.
— Challenges that arise in the use of chess engines.
— Impact of chess on life and vice versa, and how the situation has evolved with the advances in chess technology.
— Future prospects of the chess-AI symbiosis in education, entertainment and self-development.
Discussion participants:
Ulrich Paquet and Nenad Tomašev, researchers, DeepMind;
Sergey Rykovanov (professor) and Yuri Shkandybin (systems architect), Skoltech’s supercomputing group;
Aleksandr Shimanov, Russian chess player, grandmaster.
Links:
Sign up: http://surl.li/abbvc
Livestream: https://youtu.be/BDWELYal47c
{kind=link}