
14 seconds of April #Nvidia 's CEO speech was generated in silico
Why this important: demand for usage of 3080 and newer GPU models might also get pumped by CGI artists and researchers working in VR / AR tech.
And this raises the bar for #speechsinthesis / #speechgeneration and definately for the rendering of photorealistic picture.
YouTube making of video: https://www.youtube.com/watch?v=1qhqZ9ECm70&t=1430s
Vice article on the subject: https://www.vice.com/en/article/88nbpa/nvidia-reveals-its-ceo-was-computer-generated-in-keynote-speech
Why this important: demand for usage of 3080 and newer GPU models might also get pumped by CGI artists and researchers working in VR / AR tech.
And this raises the bar for #speechsinthesis / #speechgeneration and definately for the rendering of photorealistic picture.
YouTube making of video: https://www.youtube.com/watch?v=1qhqZ9ECm70&t=1430s
Vice article on the subject: https://www.vice.com/en/article/88nbpa/nvidia-reveals-its-ceo-was-computer-generated-in-keynote-speech
YouTube
Connecting in the Metaverse: The Making of the GTC Keynote
See how a small team of artists were able to blur the line between real and rendered in NVIDIA’s #GTC21 keynote in this behind-the-scenes documentary. Read more: https://nvda.ws/3s97Tpy
@NVIDIAOmniverse is an open platform built for virtual collaboration…
@NVIDIAOmniverse is an open platform built for virtual collaboration…
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
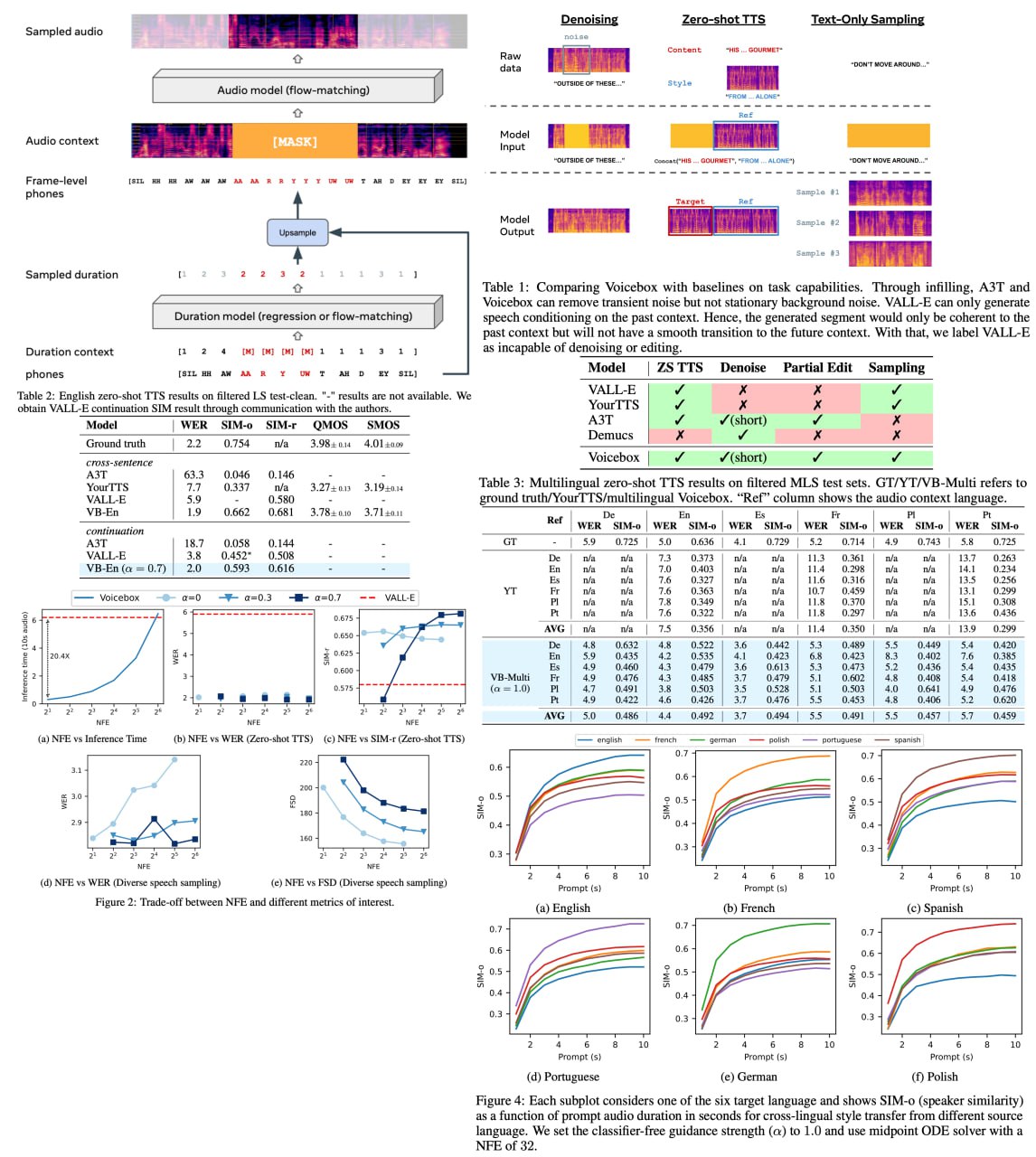
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
{kind=link}