
VirTex: Learning Visual Representations from Textual Annotations
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
{kind=link}
Semi-Autoregressive Transformer for Image Captioning
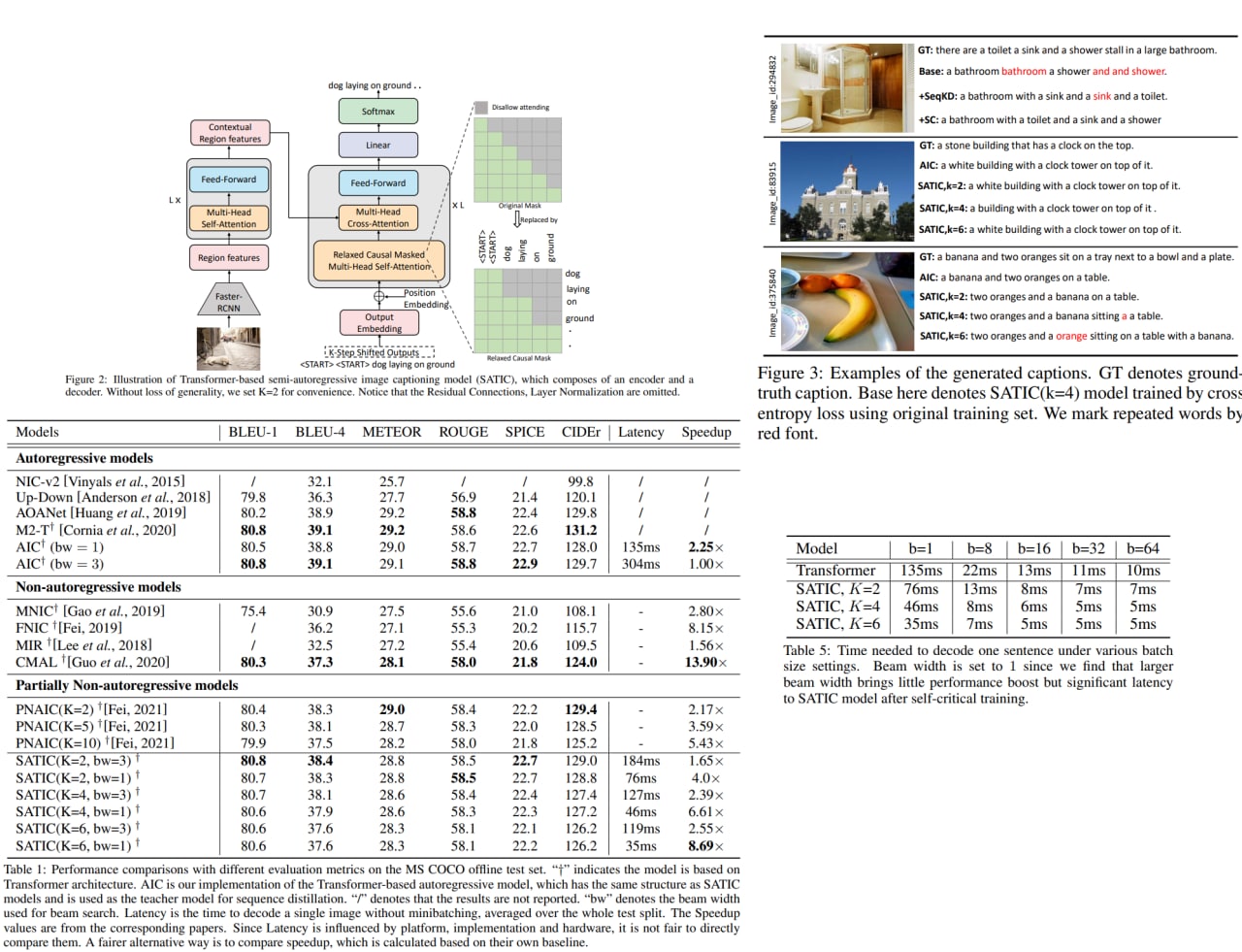
Current state-of-the-art image captioning models use autoregressive decoders - they generate one word after another, which leads to heavy latency during inference. Non-autoregressive models predict all the words in parallel; however, they suffer from quality degradation as they remove word dependence excessively.
The authors suggest a semi-autoregressive approach to image captioning to improve a trade-off between speed and quality: the model keeps the autoregressive property in global but generates words parallelly in local. Experiments on MSCOCO show that SATIC can achieve a better trade-off without bells and whistles.
Paper: https://arxiv.org/abs/2106.09436
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-satic
#imagecaptioning #deeplearning #transformer
Current state-of-the-art image captioning models use autoregressive decoders - they generate one word after another, which leads to heavy latency during inference. Non-autoregressive models predict all the words in parallel; however, they suffer from quality degradation as they remove word dependence excessively.
The authors suggest a semi-autoregressive approach to image captioning to improve a trade-off between speed and quality: the model keeps the autoregressive property in global but generates words parallelly in local. Experiments on MSCOCO show that SATIC can achieve a better trade-off without bells and whistles.
Paper: https://arxiv.org/abs/2106.09436
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-satic
#imagecaptioning #deeplearning #transformer
{kind=link}
Recognize Anything: A Strong Image Tagging Model
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
RAM's development comprises a strategic, four-step process. Initially, annotation-free image tags are obtained on a large scale via an automated text semantic parsing. This is followed by training a preliminary model for automatic annotation, fusing caption and tagging tasks under the supervision of original texts and parsed tags. Then, RAM utilizes a data engine to generate extra annotations and eliminate incorrect ones, refining the input. Finally, the model is meticulously retrained with the cleaned data and fine-tuned using a smaller, higher-quality dataset. Extensive evaluations of RAM have revealed stunning results: it outshines its counterparts like CLIP and BLIP in zero-shot performance, even surpassing fully supervised models, exhibiting a competitive edge akin to Google's tagging API!
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
Get ready for a breakthrough in the realm of AI: introducing the Recognize Anything Model (RAM), a powerful new model that is set to revolutionize image tagging. RAM, a titan in the world of large computer vision models, astoundingly exhibits the zero-shot ability to recognize any common category with an impressive level of accuracy. Shattering traditional approaches, RAM employs a unique paradigm for image tagging, utilizing large-scale image-text pairs for training instead of relying on tedious manual annotations.
RAM's development comprises a strategic, four-step process. Initially, annotation-free image tags are obtained on a large scale via an automated text semantic parsing. This is followed by training a preliminary model for automatic annotation, fusing caption and tagging tasks under the supervision of original texts and parsed tags. Then, RAM utilizes a data engine to generate extra annotations and eliminate incorrect ones, refining the input. Finally, the model is meticulously retrained with the cleaned data and fine-tuned using a smaller, higher-quality dataset. Extensive evaluations of RAM have revealed stunning results: it outshines its counterparts like CLIP and BLIP in zero-shot performance, even surpassing fully supervised models, exhibiting a competitive edge akin to Google's tagging API!
Paper link: https://arxiv.org/abs/2306.03514
Code link: https://github.com/xinyu1205/recognize-anything
Project link: https://recognize-anything.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ram
#deeplearning #cv #imagecaptioning
{kind=link}