
TabNine showed deep learning code autocomplete tool based on GPT-2 architecture.
Video demonstrates the concept. Hopefully, it will allow us to write code with less bugs, not more.
Link: https://tabnine.com/blog/deep
Something relatively similar by Microsoft: https://visualstudio.microsoft.com/ru/services/intellicode
#GPT2 #TabNine #autocomplete #product #NLP #NLU #codegeneration
Video demonstrates the concept. Hopefully, it will allow us to write code with less bugs, not more.
Link: https://tabnine.com/blog/deep
Something relatively similar by Microsoft: https://visualstudio.microsoft.com/ru/services/intellicode
#GPT2 #TabNine #autocomplete #product #NLP #NLU #codegeneration
GPT-2: 6-Month Follow-Up
#OpenAI released the 774 million parameter #GPT2 language model.
Link: https://openai.com/blog/gpt-2-6-month-follow-up/
#NLU #NLP
#OpenAI released the 774 million parameter #GPT2 language model.
Link: https://openai.com/blog/gpt-2-6-month-follow-up/
#NLU #NLP
Openai
GPT-2: 6-month follow-up
We’re releasing the 774 million parameter GPT-2 language model after the release of our small 124M model in February, staged release of our medium 355M model in May, and subsequent research with partners and the AI community into the model’s potential for…
OpenGPT-2: We Replicated GPT-2 Because You Can Too
Article about replication of famous #GPT2. This replication project trained a 1.5B parameter «OpenGPT-2» model on OpenWebTextCorpus, a 38GB dataset similar to the original, and showed comparable results to original GPT-2 on various benchmarks.
Link: https://medium.com/@vanya_cohen/opengpt-2-we-replicated-gpt-2-because-you-can-too-45e34e6d36dc
Google colab: https://colab.research.google.com/drive/1esbpDOorf7DQJV8GXWON24c-EQrSKOit
OpenWebCorpus: https://skylion007.github.io/OpenWebTextCorpus/
#NLU #NLP
Article about replication of famous #GPT2. This replication project trained a 1.5B parameter «OpenGPT-2» model on OpenWebTextCorpus, a 38GB dataset similar to the original, and showed comparable results to original GPT-2 on various benchmarks.
Link: https://medium.com/@vanya_cohen/opengpt-2-we-replicated-gpt-2-because-you-can-too-45e34e6d36dc
Google colab: https://colab.research.google.com/drive/1esbpDOorf7DQJV8GXWON24c-EQrSKOit
OpenWebCorpus: https://skylion007.github.io/OpenWebTextCorpus/
#NLU #NLP
Medium
OpenGPT-2: We Replicated GPT-2 Because You Can Too
By Aaron Gokaslan* and Vanya Cohen*
GPT-2 hadn’t (yet) fooled jury at The Economist’s Open Future Essay Contest
Though one of the judges suggested that «It is strongly worded and backs up claims with evidence, but the idea is not incredibly original.»
Link: https://www.economist.com/open-future/2019/10/01/how-to-respond-to-climate-change-if-you-are-an-algorithm
#NLP #GPT2 #NLU
Though one of the judges suggested that «It is strongly worded and backs up claims with evidence, but the idea is not incredibly original.»
Link: https://www.economist.com/open-future/2019/10/01/how-to-respond-to-climate-change-if-you-are-an-algorithm
#NLP #GPT2 #NLU
The Economist
How to respond to climate change, if you are an algorithm
We ran our youth essay question through an artificial-intelligence system to produce an essay
🔥OpenAI realesed the 1.5billion parameter GPT-2 model
Post: https://openai.com/blog/gpt-2-1-5b-release/
GPT-2 output detection model: https://github.com/openai/gpt-2-output-dataset/tree/master/detector
Research from partners on potential malicious uses: https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
#NLU #GPT2 #OpenAI #NLP
Post: https://openai.com/blog/gpt-2-1-5b-release/
GPT-2 output detection model: https://github.com/openai/gpt-2-output-dataset/tree/master/detector
Research from partners on potential malicious uses: https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
#NLU #GPT2 #OpenAI #NLP
Openai
GPT-2: 1.5B release
As the final model release of GPT-2’s staged release, we’re releasing the largest version (1.5B parameters) of GPT-2 along with code and model weights to facilitate detection of outputs of GPT-2 models. While there have been larger language models released…
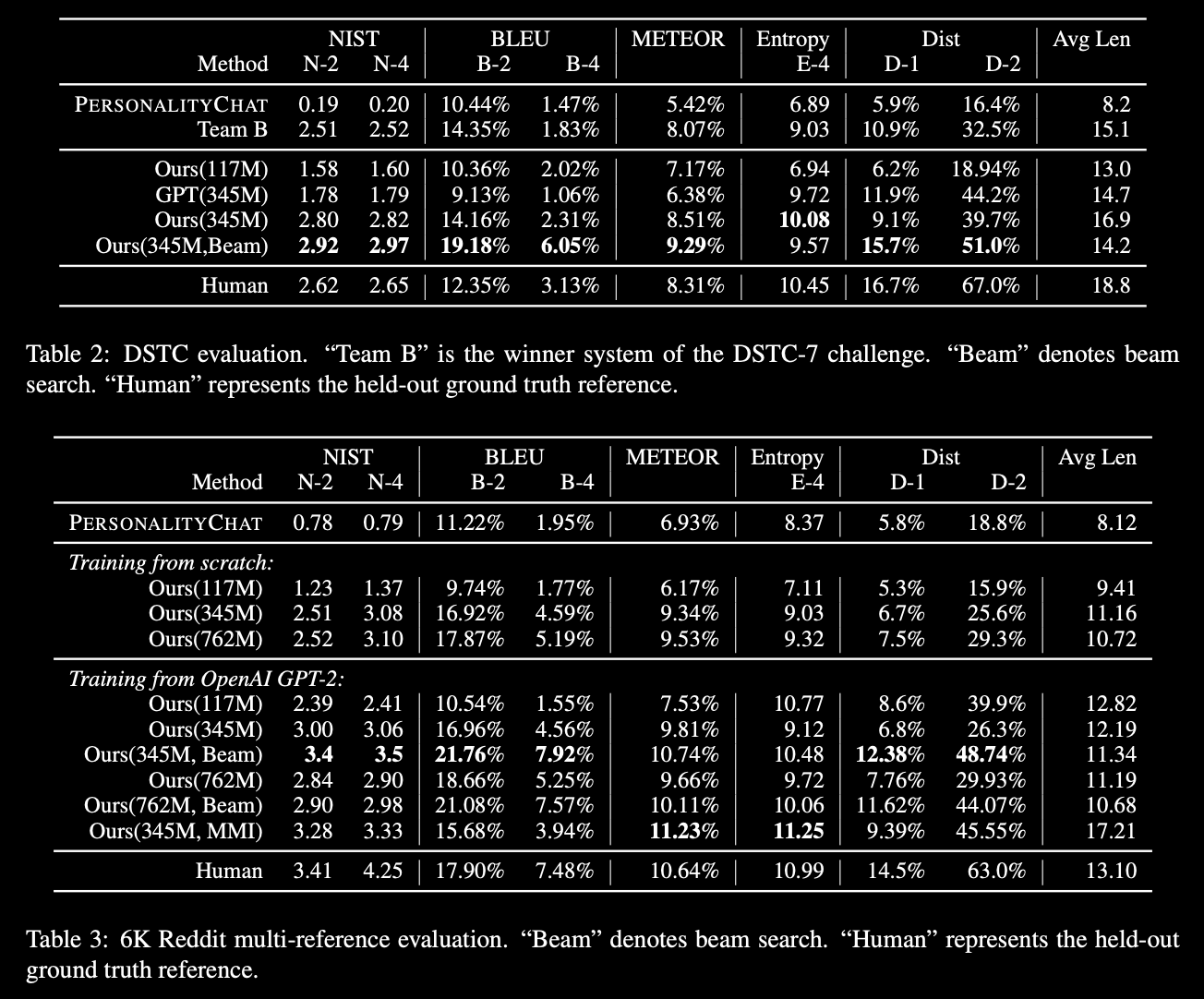
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
tl;dr: GPT2 + Dialogue data = DialoGPT
trained on Reddit comments from 2005 through 2017 (not a very big dataset, about 2Gb)
Paper: https://arxiv.org/abs/1911.00536
Code: https://github.com/microsoft/DialoGPT
Blog: https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/
#nlp #gpt2 #dialog
tl;dr: GPT2 + Dialogue data = DialoGPT
trained on Reddit comments from 2005 through 2017 (not a very big dataset, about 2Gb)
Paper: https://arxiv.org/abs/1911.00536
Code: https://github.com/microsoft/DialoGPT
Blog: https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/
#nlp #gpt2 #dialog
{kind=link}
What GPT-2 thinks of the future
Link: https://worldin.economist.com/article/17521/edition2020artificial-intelligence-predicts-future
#NLU #NLP #NLG #GPT2
Link: https://worldin.economist.com/article/17521/edition2020artificial-intelligence-predicts-future
#NLU #NLP #NLG #GPT2
Very cool application of GPT-2
It is a game endless generating by large GPT-2 depends of your actions which litterally anything with just words. Without any gamemaster or gamedisigner limitations) GPT-2 was fine-tuned on collection of adventures texts.
But it is work not very well, esspecially on custom setting (I try to setup cyberpunk, but it is wa a fantasy anyway sometimes))
But it is fun and very cool applications of this type of nets. And it is really awesome to be suprised each time by power of this model esspecialy in this task.
Site: http://www.aidungeon.io/
Post: https://pcc.cs.byu.edu/2019/11/21/ai-dungeon-2-creating-infinitely-generated-text-adventures-with-deep-learning-language-models/
Github: https://github.com/nickwalton/AIDungeon/
Play in colab: https://colab.research.google.com/drive/1u7flclharvMchwWHY7Ya41NKjX3dkslu#forceEdit=true&sandboxMode=true&scrollTo=FKqlSCrpS9dH
#GPT2 #NLP #NLU
It is a game endless generating by large GPT-2 depends of your actions which litterally anything with just words. Without any gamemaster or gamedisigner limitations) GPT-2 was fine-tuned on collection of adventures texts.
But it is work not very well, esspecially on custom setting (I try to setup cyberpunk, but it is wa a fantasy anyway sometimes))
But it is fun and very cool applications of this type of nets. And it is really awesome to be suprised each time by power of this model esspecialy in this task.
Site: http://www.aidungeon.io/
Post: https://pcc.cs.byu.edu/2019/11/21/ai-dungeon-2-creating-infinitely-generated-text-adventures-with-deep-learning-language-models/
Github: https://github.com/nickwalton/AIDungeon/
Play in colab: https://colab.research.google.com/drive/1u7flclharvMchwWHY7Ya41NKjX3dkslu#forceEdit=true&sandboxMode=true&scrollTo=FKqlSCrpS9dH
#GPT2 #NLP #NLU
#NLP #News (by Sebastian Ruder):
* 2020 NLP wish lists
* #HuggingFace + #fastai
* #NeurIPS 2019
* #GPT2 things
* #ML Interviews
blog post: http://newsletter.ruder.io/archive/211277
* 2020 NLP wish lists
* #HuggingFace + #fastai
* #NeurIPS 2019
* #GPT2 things
* #ML Interviews
blog post: http://newsletter.ruder.io/archive/211277
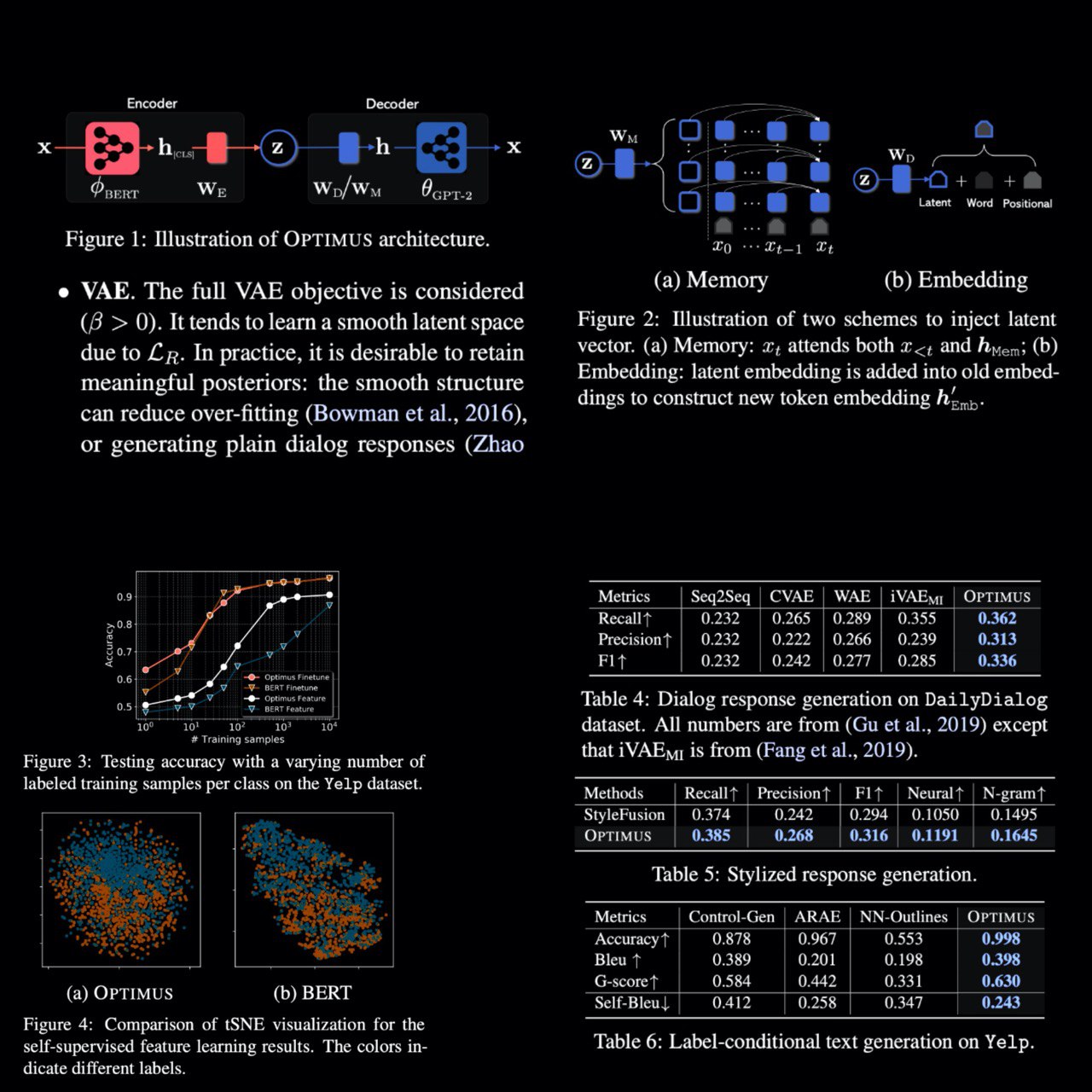
Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space
The authors propose the first large-scale language VAE model – Optimus.
This new model uses BERT weights in the encoder and GPT-2 weights in the decoder. Thanks to this Optimus supports NLU and text generation tasks. Learned language representation is more universal, which means that it is easier to fine-tune this model to a new domain/task. Also, Optimus can control high-level semantics in text generation (tense, topic, sentiment).
There are several novel contributions, which are made thanks to this work:
– latent vector injection: two schemes are suggested to inject conditioning vectors into GPT-2 without retraining it;
– the idea to combine BERT and GPT-2 could inspire people to integrate existing language models into larger and ever more complex models;
– pre-training on a big corpora is an effective approach to reduce KL vanishing;
– VAE is a good approach to balance the compactness and usability of learned representations;
– pre-training latent space improves performance on several language tasks;
Experimental results on a wide range of tasks and datasets have demonstrated the strong performance of OPTIMUS, including new state-of-the-art for language VAEs.
Paper: https://arxiv.org/abs/2004.04092v1
Github: https://github.com/ChunyuanLI/Optimus
#deeplearning #nlp #nlu #transformer #vae #bert #gpt2
The authors propose the first large-scale language VAE model – Optimus.
This new model uses BERT weights in the encoder and GPT-2 weights in the decoder. Thanks to this Optimus supports NLU and text generation tasks. Learned language representation is more universal, which means that it is easier to fine-tune this model to a new domain/task. Also, Optimus can control high-level semantics in text generation (tense, topic, sentiment).
There are several novel contributions, which are made thanks to this work:
– latent vector injection: two schemes are suggested to inject conditioning vectors into GPT-2 without retraining it;
– the idea to combine BERT and GPT-2 could inspire people to integrate existing language models into larger and ever more complex models;
– pre-training on a big corpora is an effective approach to reduce KL vanishing;
– VAE is a good approach to balance the compactness and usability of learned representations;
– pre-training latent space improves performance on several language tasks;
Experimental results on a wide range of tasks and datasets have demonstrated the strong performance of OPTIMUS, including new state-of-the-art for language VAEs.
Paper: https://arxiv.org/abs/2004.04092v1
Github: https://github.com/ChunyuanLI/Optimus
#deeplearning #nlp #nlu #transformer #vae #bert #gpt2
{kind=link}
Image GPT
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020