
ResNeSt: Split-Attention Networks
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
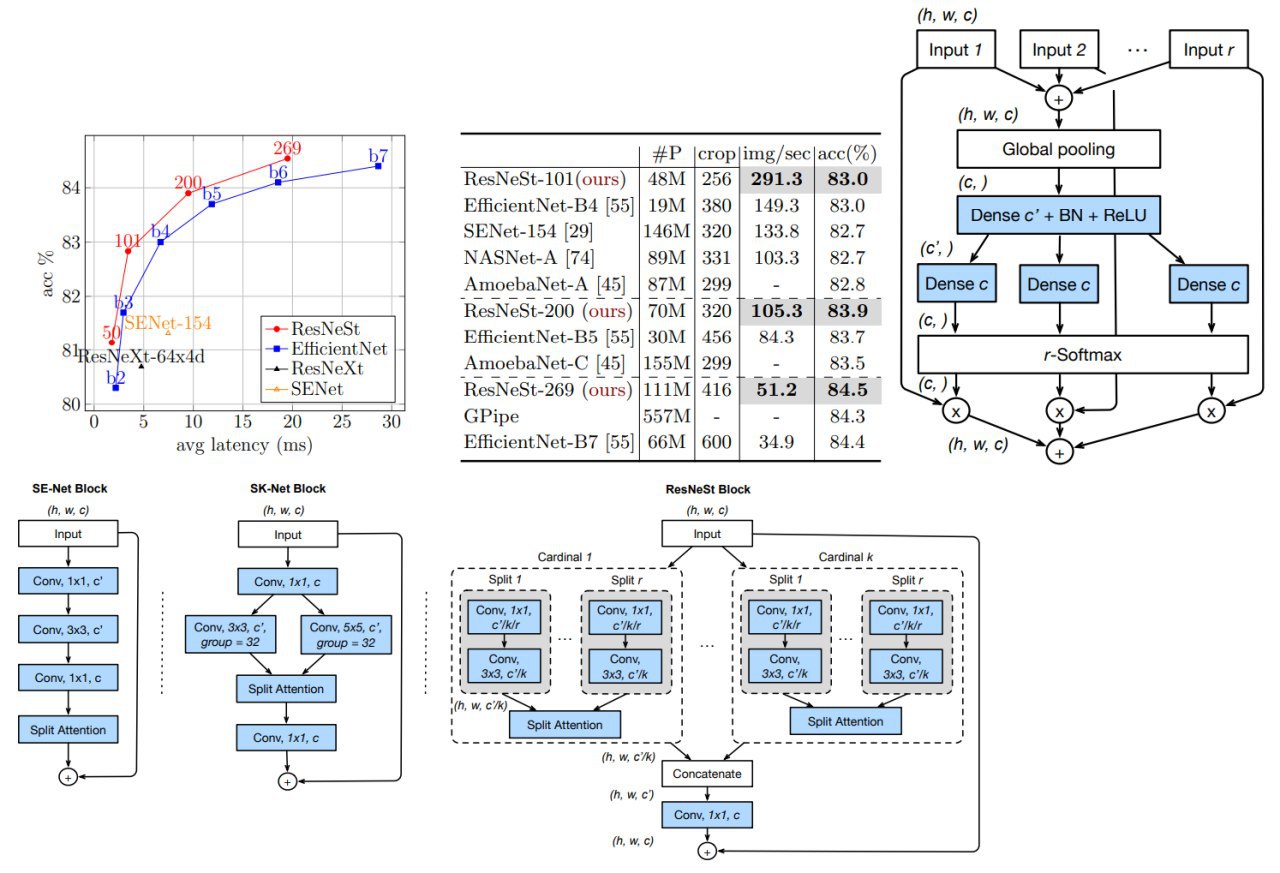
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
S stands for “split”). This architecture requires no more computation than existing ResNet-variants, and is easy to be adopted as a backbone for other vision tasks- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
{kind=link}