
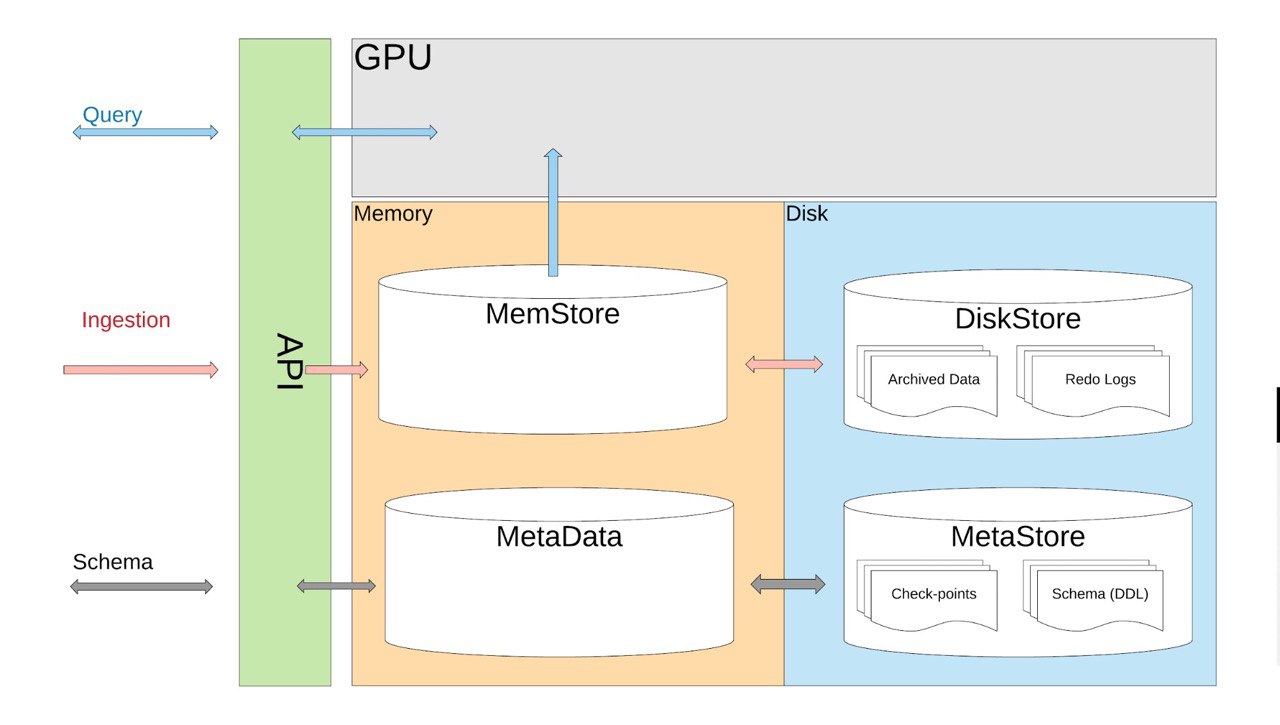
Introducing AresDB: Uber’s GPU-Powered Open Source, Real-time Analytics Engine
Link: https://eng.uber.com/aresdb/
#Uber #analytics #opensource
Link: https://eng.uber.com/aresdb/
#Uber #analytics #opensource
{kind=link}
Manifold: A Model-Agnostic Visual Debugging Tool for Machine Learning at Uber
Seesm like there is no week without any news from #Uber engineering team. This time Uber built Manifold, a model-agnostic visualization tool for #ML performance diagnosis and model debugging, to facilitate a more informed and actionable model iteration process.
Link: https://ubere.ng/2Hac0O8
#Pipeline #administration
Seesm like there is no week without any news from #Uber engineering team. This time Uber built Manifold, a model-agnostic visualization tool for #ML performance diagnosis and model debugging, to facilitate a more informed and actionable model iteration process.
Link: https://ubere.ng/2Hac0O8
#Pipeline #administration
Why Financial Planning is Exciting… At Least for a Data Scientist
Great introduction into the finance world and what data scientist can lack diving into the topic.
Link: https://eng.uber.com/financial-planning-for-data-scientist/
#Financial #statistics #Uber
Great introduction into the finance world and what data scientist can lack diving into the topic.
Link: https://eng.uber.com/financial-planning-for-data-scientist/
#Financial #statistics #Uber
{kind=link}
{kind=link}
Analyzing Experiment Outcomes: Beyond Average Treatment Effects
Good #statistics article on why tail distribution and #experimentdesign matters. Quantile treatment effects (QTEs) helps to capture the inherent heterogeneity in treatment effects when riders and drivers interact within the #Uber marketplace.
Link: https://eng.uber.com/analyzing-experiment-outcomes/
Good #statistics article on why tail distribution and #experimentdesign matters. Quantile treatment effects (QTEs) helps to capture the inherent heterogeneity in treatment effects when riders and drivers interact within the #Uber marketplace.
Link: https://eng.uber.com/analyzing-experiment-outcomes/
Food Discovery with Uber Eats: Recommending for the Marketplace
Another great article from #Uber engeneering team on how they built recommendation engine for #UberEats and what balance they had to maintain.
Link: https://eng.uber.com/uber-eats-recommending-marketplace/
Another great article from #Uber engeneering team on how they built recommendation engine for #UberEats and what balance they had to maintain.
Link: https://eng.uber.com/uber-eats-recommending-marketplace/
{kind=link}
Big article on how #uber ML system Michelangelo works
Michelangelo enables internal teams to seamlessly build, deploy, and operate machine learning solutions at Uber’s scale. It is designed to cover the end-to-end ML workflow: manage data, train, evaluate, and deploy models, make predictions, and monitor predictions. The system also supports traditional ML models, time series forecasting, and deep learning.
Link: https://eng.uber.com/michelangelo/
#ML #MLSystem #MLatwork #practical
Michelangelo enables internal teams to seamlessly build, deploy, and operate machine learning solutions at Uber’s scale. It is designed to cover the end-to-end ML workflow: manage data, train, evaluate, and deploy models, make predictions, and monitor predictions. The system also supports traditional ML models, time series forecasting, and deep learning.
Link: https://eng.uber.com/michelangelo/
#ML #MLSystem #MLatwork #practical
How is Uber predicting demand, surge and where will be high demand area.
One more post from brilliant #Uber engineering team, sharing their approach and general experience about forecasting.
Link: https://eng.uber.com/forecasting-introduction/
#ts #timeseries #arima #demandprediction #ml
One more post from brilliant #Uber engineering team, sharing their approach and general experience about forecasting.
Link: https://eng.uber.com/forecasting-introduction/
#ts #timeseries #arima #demandprediction #ml
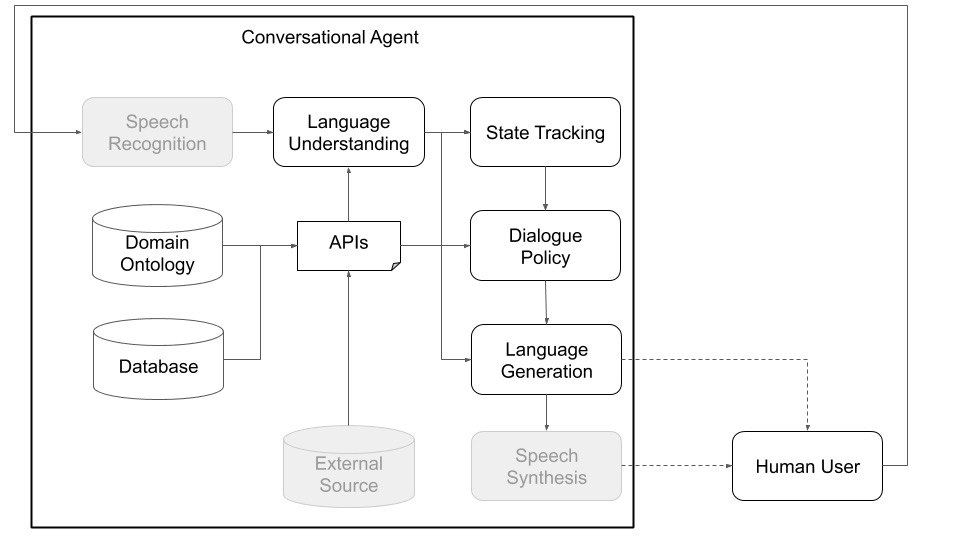
Plato Research Dialogue System: A Flexible Conversational AI Platform
The Plato Research Dialogue System is a platform #Uber developed to enable experts and non-experts alike to quickly build, train, and deploy conversational AI agents.
Link: https://eng.uber.com/plato-research-dialogue-system/
#ConversationalAI #converstaion #NLP #NLU
The Plato Research Dialogue System is a platform #Uber developed to enable experts and non-experts alike to quickly build, train, and deploy conversational AI agents.
Link: https://eng.uber.com/plato-research-dialogue-system/
#ConversationalAI #converstaion #NLP #NLU
{kind=link}
How Trip Inferences and Machine Learning Optimize Delivery Times on Uber Eats
Article on how business task can be decomposed to ML problem
Link: https://eng.uber.com/uber-eats-trip-optimization/
#Uber #ml #taskdesign #analytics
Article on how business task can be decomposed to ML problem
Link: https://eng.uber.com/uber-eats-trip-optimization/
#Uber #ml #taskdesign #analytics
Uber Blog
How Trip Inferences and Machine Learning Optimize Delivery Times on Uber Eats | Uber Blog
Using GPS and sensor data from Android phones, Uber engineers develop a state model for trips taken by Uber Eats delivery-partners, helping to optimize trip timing for delivery-partners and eaters alike.
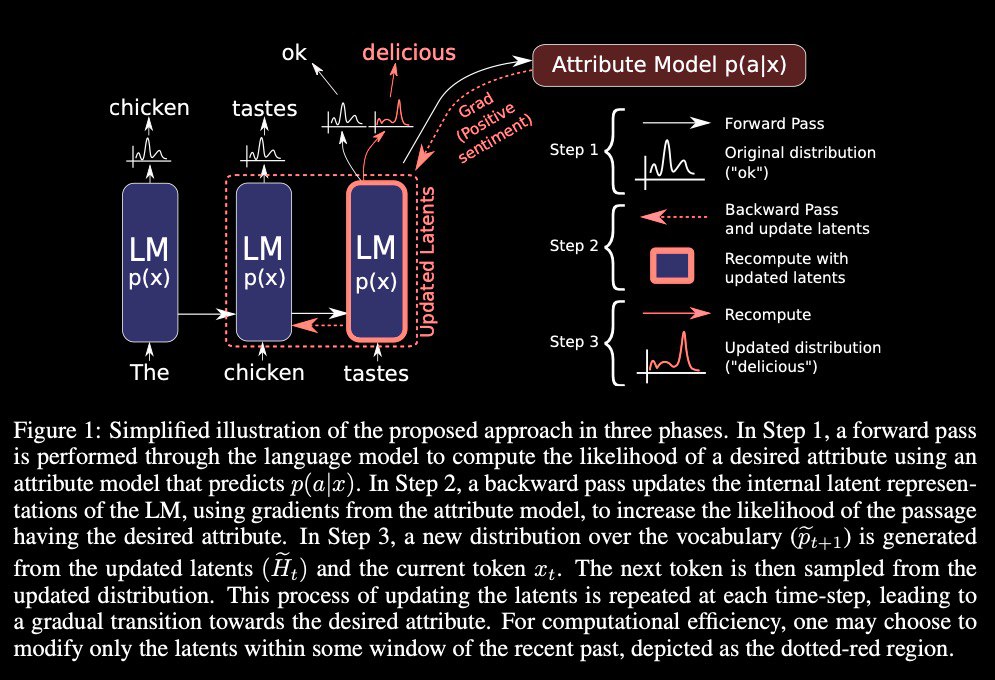
Uber AI Plug and Play Language Model (PPLM)
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
{kind=link}
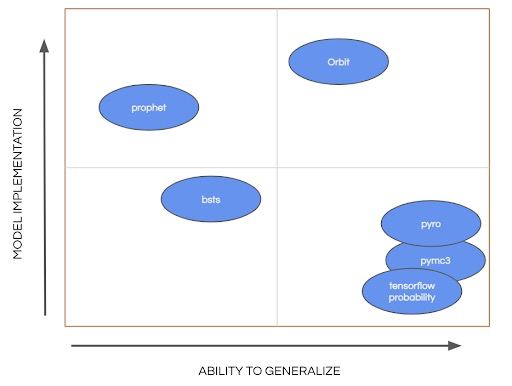
Orbit — An Open Source Package for Time Series Inference and Forecasting
Object-ORiented BayesIan Time Series is a new project for #timeseries forecasting by #Uber team. Has #scikit-learn compatible interface and claimed to have results comparable to #prophet .
Post: https://eng.uber.com/orbit/
Docs: https://uber.github.io/orbit/about.html
GitHub: https://github.com/uber/orbit/
Object-ORiented BayesIan Time Series is a new project for #timeseries forecasting by #Uber team. Has #scikit-learn compatible interface and claimed to have results comparable to #prophet .
Post: https://eng.uber.com/orbit/
Docs: https://uber.github.io/orbit/about.html
GitHub: https://github.com/uber/orbit/
{kind=link}