
Overview of 10 Stanford's Data Science courses
A survivor’s guide to Artificial Intelligence courses at Stanford
Link: https://huyenchip.com/2018/03/30/guide-to-Artificial-Intelligence-Stanford.html
#Staford #MOOC #course #free #rating #learning
A survivor’s guide to Artificial Intelligence courses at Stanford
Link: https://huyenchip.com/2018/03/30/guide-to-Artificial-Intelligence-Stanford.html
#Staford #MOOC #course #free #rating #learning
Chip Huyen
A survivor’s guide to Artificial Intelligence courses at Stanford (Updated Feb 2020)
Twitter thread
Becoming an Independent Researcher and getting published in ICLR with spotlight
* It is possible to get published as an independent researcher, but it is really HARD.
* Now you need a top tier publication (ACL/EMNLP/CVPR/ICCV/ICLR/NeurIPS or ICML paper) to get accepted into PhD program.
* Mind acceptance rate of 20% and keep on grinding.
Link: https://medium.com/@andreas_madsen/becoming-an-independent-researcher-and-getting-published-in-iclr-with-spotlight-c93ef0b39b8b
#Academia #PhD #conference #learning
* It is possible to get published as an independent researcher, but it is really HARD.
* Now you need a top tier publication (ACL/EMNLP/CVPR/ICCV/ICLR/NeurIPS or ICML paper) to get accepted into PhD program.
* Mind acceptance rate of 20% and keep on grinding.
Link: https://medium.com/@andreas_madsen/becoming-an-independent-researcher-and-getting-published-in-iclr-with-spotlight-c93ef0b39b8b
#Academia #PhD #conference #learning
Medium
Becoming an Independent Researcher and getting published in ICLR with spotlight
Why I became an Independent Researcher, why you should avoid it, and advice for those who make the difficult choice anyway.
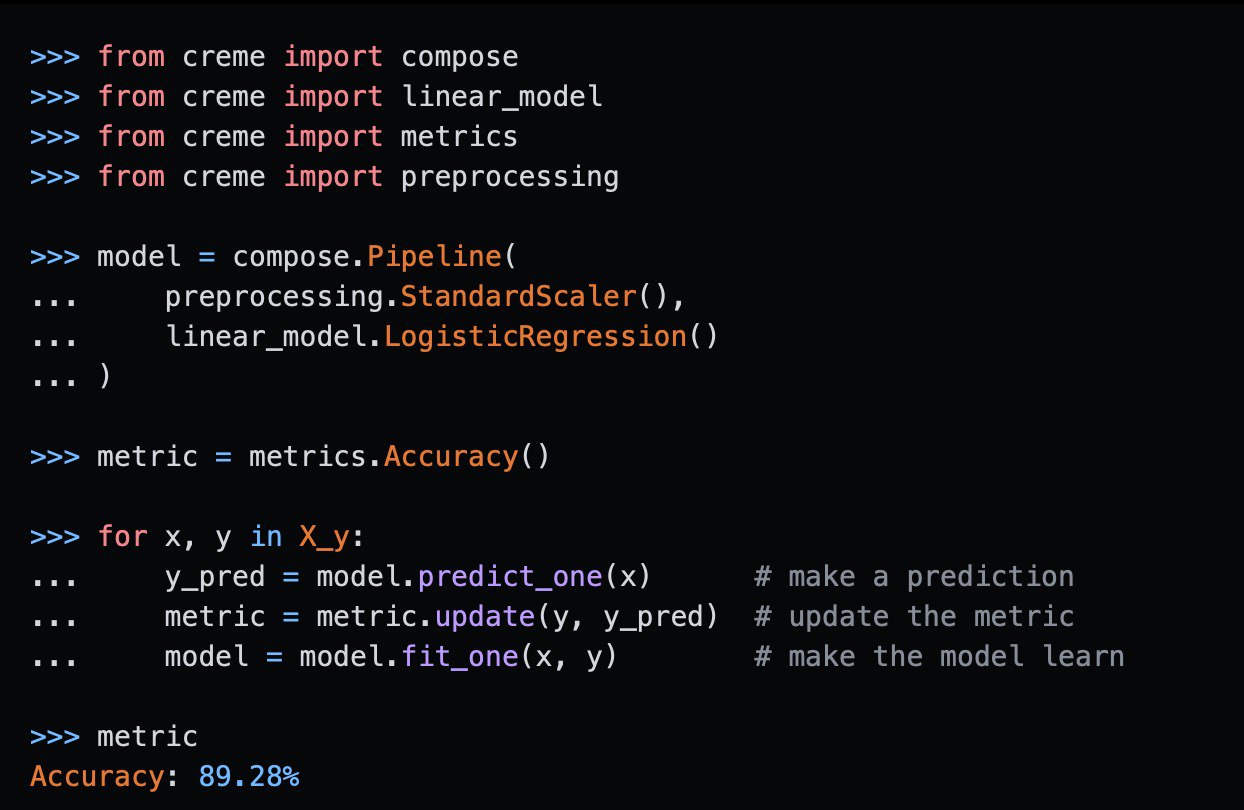
CREME – python library for online ML
All the tools in the library can be updated with a single observation at a time, and can therefore be used to learn from streaming data.
The model learns from one observation at a time, and can therefore be updated on the fly. This allows to learn from massive datasets that don't fit in main memory. Online machine learning also integrates nicely in cases where new data is constantly arriving. It shines in many use cases, such as time series forecasting, spam filtering, recommender systems, CTR prediction, and IoT applications. If you're bored with retraining models and want to instead build dynamic models, then online machine learning might be what you're looking for.
Here are some benefits of using creme (and online machine learning in general):
• incremental – models can update themselves in real-time
• adaptive – models can adapt to concept drift
• production-ready – working with data streams makes it simple to replicate production scenarios during model development
• efficient – models don't have to be retrained and require little compute power, which lowers their carbon footprint
api reference: https://creme-ml.github.io/content/api.html
github: https://github.com/creme-ml/creme
#ml #online #learning
All the tools in the library can be updated with a single observation at a time, and can therefore be used to learn from streaming data.
The model learns from one observation at a time, and can therefore be updated on the fly. This allows to learn from massive datasets that don't fit in main memory. Online machine learning also integrates nicely in cases where new data is constantly arriving. It shines in many use cases, such as time series forecasting, spam filtering, recommender systems, CTR prediction, and IoT applications. If you're bored with retraining models and want to instead build dynamic models, then online machine learning might be what you're looking for.
Here are some benefits of using creme (and online machine learning in general):
• incremental – models can update themselves in real-time
• adaptive – models can adapt to concept drift
• production-ready – working with data streams makes it simple to replicate production scenarios during model development
• efficient – models don't have to be retrained and require little compute power, which lowers their carbon footprint
api reference: https://creme-ml.github.io/content/api.html
github: https://github.com/creme-ml/creme
#ml #online #learning
{kind=link}
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
This paper introduces a new method that significantly improves the sample efficiency of RL algorithms when learning from raw pixel data.
CURL architecture consists of three models: Query Encoder, Key Encoder, and RL agent. Query Encoder outputs embedding which used in RL agent as state representation. Contrastive loss computed from outputs of Query Encoder and Key Encoder. An important thing is that Query Encoder learns to minimize both RL and contrastive losses which allow all models to be trained jointly.
The method was tested on Atari and DeepMind Control tasks with limited interaction steps. It showed SOTA results for most of these tasks.
Paper: https://arxiv.org/abs/2004.04136.pdf
Code: https://github.com/MishaLaskin/curl
#rl #agent #reinforcement #learning
This paper introduces a new method that significantly improves the sample efficiency of RL algorithms when learning from raw pixel data.
CURL architecture consists of three models: Query Encoder, Key Encoder, and RL agent. Query Encoder outputs embedding which used in RL agent as state representation. Contrastive loss computed from outputs of Query Encoder and Key Encoder. An important thing is that Query Encoder learns to minimize both RL and contrastive losses which allow all models to be trained jointly.
The method was tested on Atari and DeepMind Control tasks with limited interaction steps. It showed SOTA results for most of these tasks.
Paper: https://arxiv.org/abs/2004.04136.pdf
Code: https://github.com/MishaLaskin/curl
#rl #agent #reinforcement #learning
{kind=link}
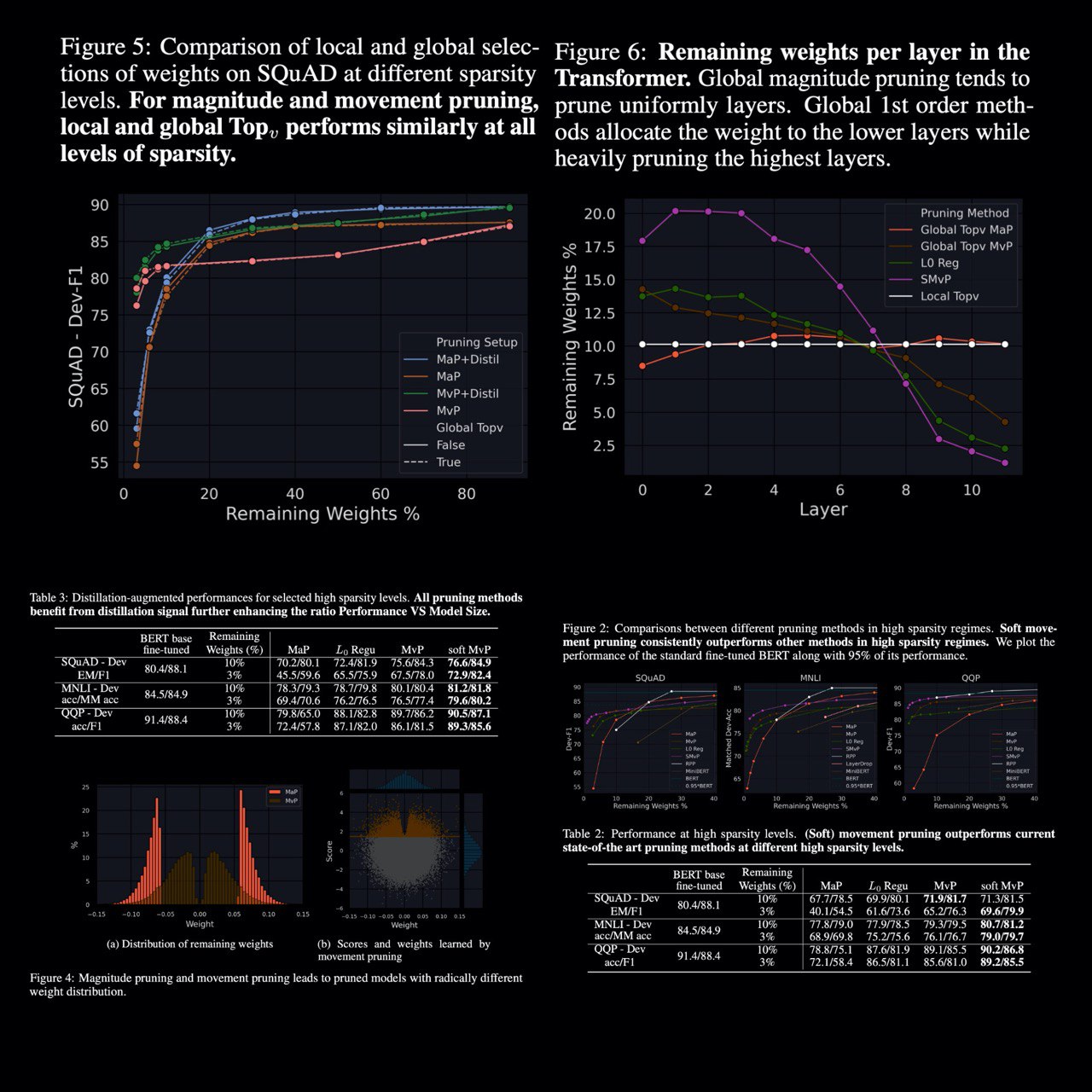
Movement Pruning: Adaptive Sparsity by Fine-Tuning
Victor Sanh, Thomas Wolf, Alexander M. Rush
Hugging Face, Cornell University
The authors consider the case of pruning of pretrained models for task-specific fine-tuning and compare zeroth- and first-order pruning methods. They show that a simple method for weight pruning based on straight-through gradients is effective for this task and that it adapts using a first-order importance score.
They apply this movement pruning to a transformer-based architecture and empirically show that their method consistently yields strong improvements over existing methods in high-sparsity regimes. The analysis demonstrates how this approach adapts to the fine-tuning regime in a way that magnitude pruning cannot.
In future work, it would also be interesting to leverage group-sparsity inducing penalties to remove entire columns or filters. In this setup, they would associate a score to a group of weights (a column or a row for instance). In the transformer architecture, it would give a systematic way to perform feature selection and remove entire columns of the embedding matrix.
paper: https://arxiv.org/abs/2005.07683
#nlp #pruning #sparsity #transfer #learning
Victor Sanh, Thomas Wolf, Alexander M. Rush
Hugging Face, Cornell University
The authors consider the case of pruning of pretrained models for task-specific fine-tuning and compare zeroth- and first-order pruning methods. They show that a simple method for weight pruning based on straight-through gradients is effective for this task and that it adapts using a first-order importance score.
They apply this movement pruning to a transformer-based architecture and empirically show that their method consistently yields strong improvements over existing methods in high-sparsity regimes. The analysis demonstrates how this approach adapts to the fine-tuning regime in a way that magnitude pruning cannot.
In future work, it would also be interesting to leverage group-sparsity inducing penalties to remove entire columns or filters. In this setup, they would associate a score to a group of weights (a column or a row for instance). In the transformer architecture, it would give a systematic way to perform feature selection and remove entire columns of the embedding matrix.
paper: https://arxiv.org/abs/2005.07683
#nlp #pruning #sparsity #transfer #learning
{kind=link}
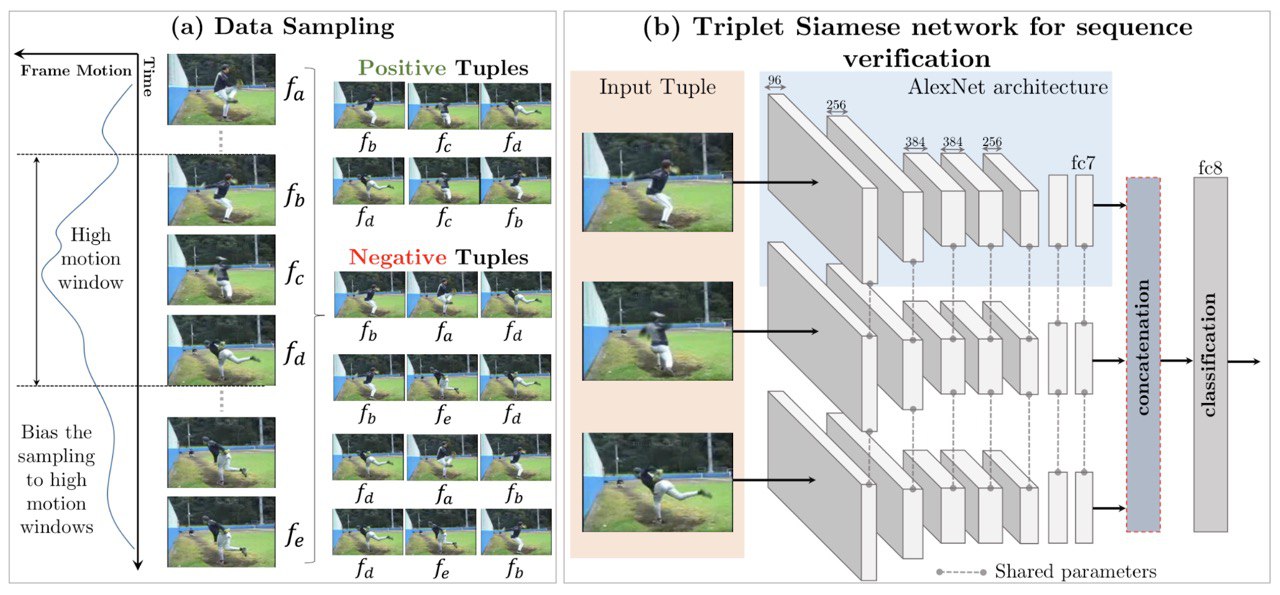
self-supervised learning
the recent time more & more talk about self-supervised learning; maybe because each year increase data, how to know
the authors (lilian weng @ openai) cover the main ideas in this area on
• images (distortion, patches, colorization, generative modeling, contrastive predictive coding, momentum contrast)
• videos (tracking, frame sequence, video colorization)
• control problems (multi-view metric learning, autonomous goal generation)
btw, this article is being updated
article: https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
#selfsupervised #learning #pretext #unlabel
the recent time more & more talk about self-supervised learning; maybe because each year increase data, how to know
the authors (lilian weng @ openai) cover the main ideas in this area on
• images (distortion, patches, colorization, generative modeling, contrastive predictive coding, momentum contrast)
• videos (tracking, frame sequence, video colorization)
• control problems (multi-view metric learning, autonomous goal generation)
btw, this article is being updated
article: https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
#selfsupervised #learning #pretext #unlabel
{kind=link}