
Translating music to predict a musician’s body movements
Long story short: animating personalized avatar with the help of neural networks.
https://research.fb.com/translating-music-to-predict-a-musicians-body-movements/
#lstm #cvpr2018 #facebook
Long story short: animating personalized avatar with the help of neural networks.
https://research.fb.com/translating-music-to-predict-a-musicians-body-movements/
#lstm #cvpr2018 #facebook
Facebook Research
Translating music to predict a musician’s body movements - Facebook Research
When pianists play a musical piece on a piano, their body reacts to the music. Their fingers strike piano keys…
This is a day to remembered. #OpenAI 's team of five neural networks, OpenAI Five, has started to defeat amateur human teams (including a semi-pro team) at Dota 2:
https://blog.openai.com/openai-five/
It is important, because Dota2 is a way more complicated game than Chess or Go, where #AI has already surpassed human players.
#rl #reinforcementlearning #dl #dota2 #lstm
https://blog.openai.com/openai-five/
It is important, because Dota2 is a way more complicated game than Chess or Go, where #AI has already surpassed human players.
#rl #reinforcementlearning #dl #dota2 #lstm
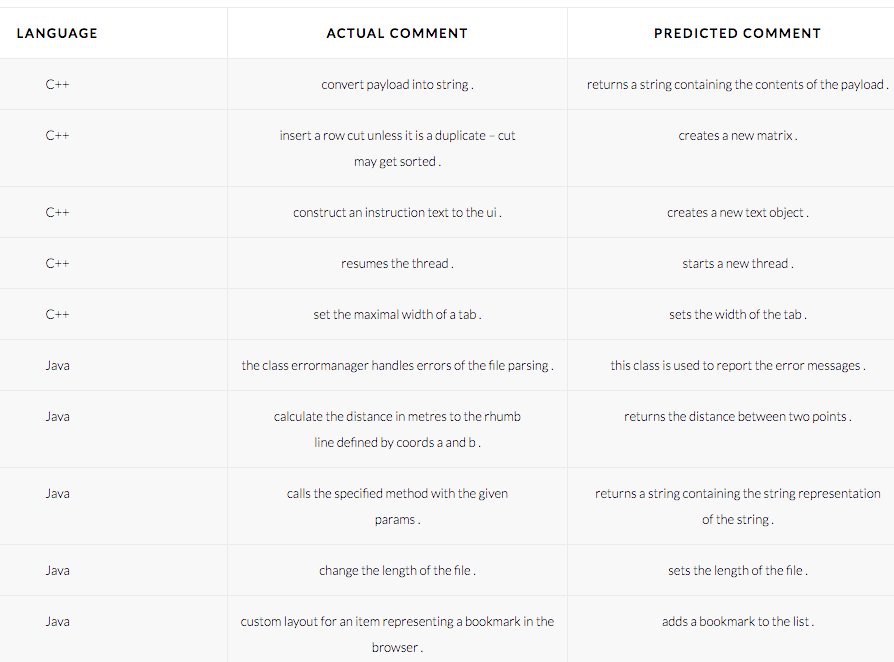
Automatically Generating Comments for Arbitrary Source Code
Automatically generating code comments directly from source code using an LSTM. Works with multiple languages. Can’t wait to JetBrains discovering it.
Link: https://www.twosixlabs.com/automatically-generating-comments-for-arbitrary-source-code/
#NLP #CS #coding #LSTM
Automatically generating code comments directly from source code using an LSTM. Works with multiple languages. Can’t wait to JetBrains discovering it.
Link: https://www.twosixlabs.com/automatically-generating-comments-for-arbitrary-source-code/
#NLP #CS #coding #LSTM
{kind=link}
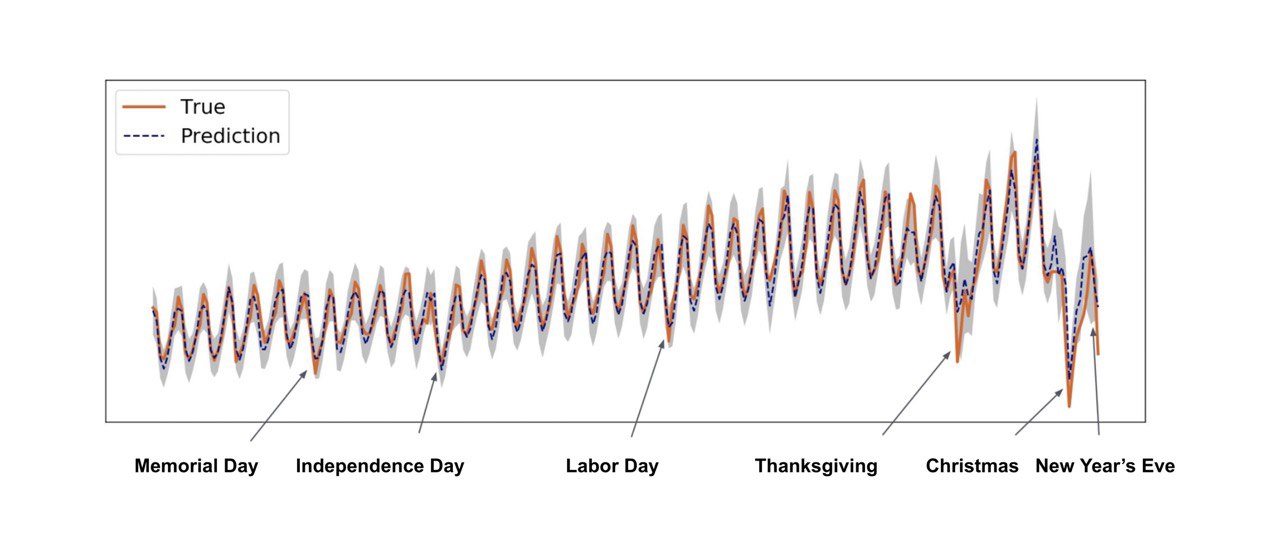
How Uber predicts prices
Engineering Uncertainty Estimation in Neural Networks for Time Series Prediction at Uber
Link: https://eng.uber.com/neural-networks-uncertainty-estimation/
#RNN #LSTM #Uber
Engineering Uncertainty Estimation in Neural Networks for Time Series Prediction at Uber
Link: https://eng.uber.com/neural-networks-uncertainty-estimation/
#RNN #LSTM #Uber
{kind=link}
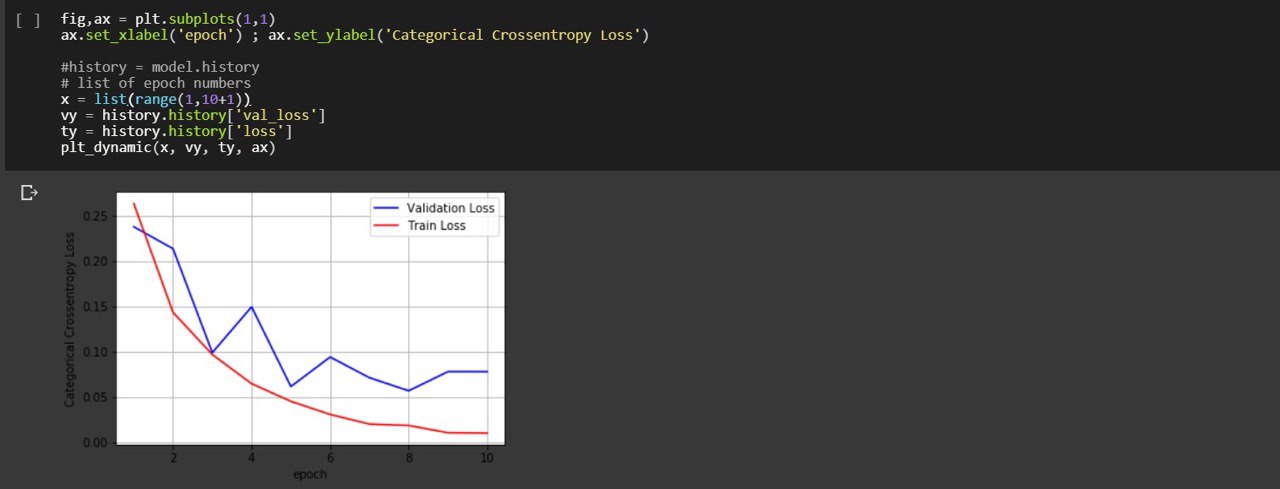
LSTM on Amazon Food Reviews using Google Collaboratory
Article describing how to build easy and small #LSTM network to predict review score based on its text, using #GoogleCollab. This is an #entrylevel post, useful if you have medium experience in #NLP.
Link: https://medium.com/@theodoxbolt/lstm-on-amazon-food-reviews-using-google-collaboratory-34b1c2eceb80
#novice
Article describing how to build easy and small #LSTM network to predict review score based on its text, using #GoogleCollab. This is an #entrylevel post, useful if you have medium experience in #NLP.
Link: https://medium.com/@theodoxbolt/lstm-on-amazon-food-reviews-using-google-collaboratory-34b1c2eceb80
#novice
{kind=link}
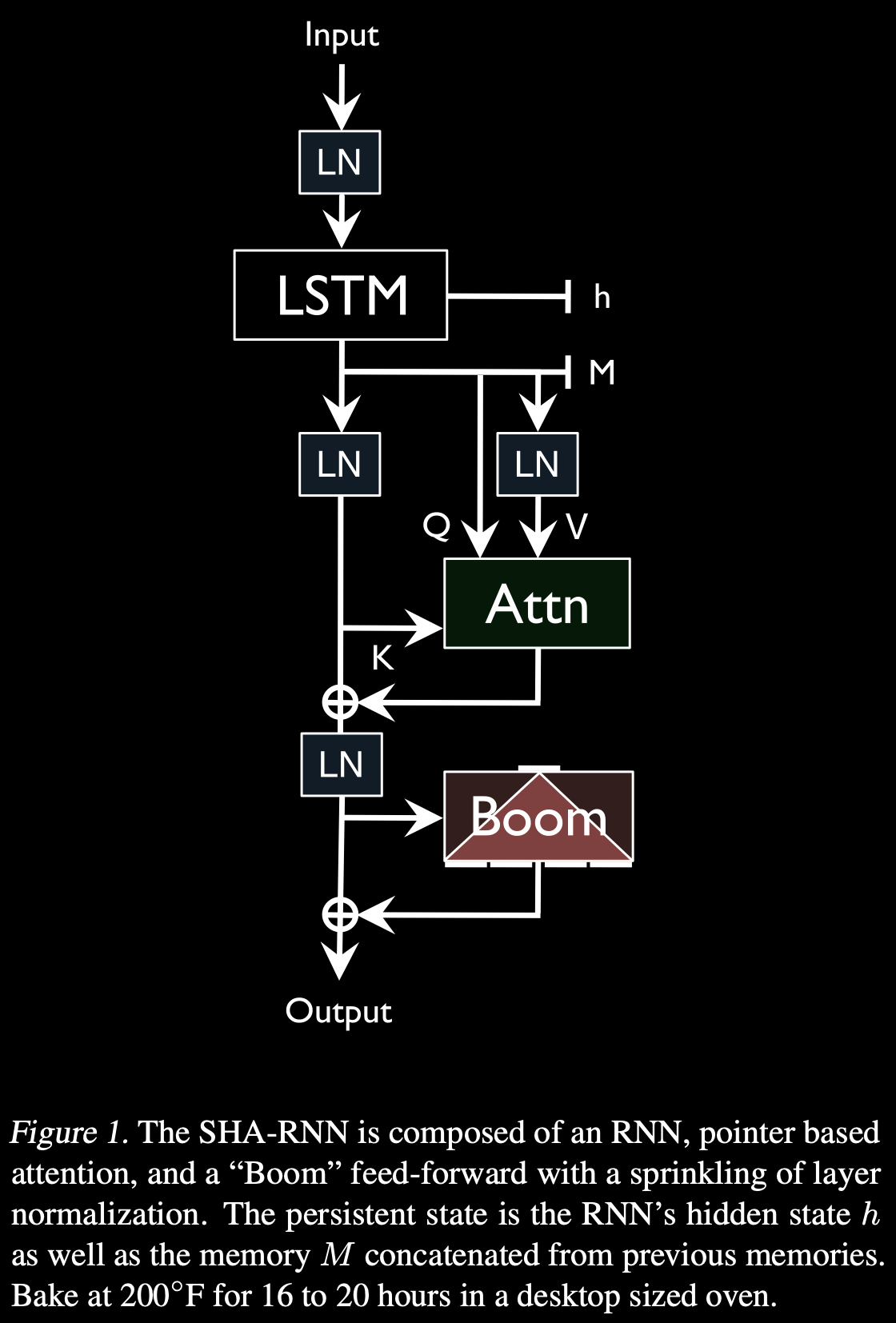
Single Headed Attention RNN
tl;dr: stop thinking with your (#attention) head :kekeke:
* obtain strong results on a byte level #languageModeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
* support long-range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
* avoid the fragile training process required by standard #Transformer models such as a long warmup
* back off toward a standard #LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
* provide a smaller model that features only standard components such as the LSTM, single-headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
paper: https://arxiv.org/abs/1911.11423
code: https://github.com/Smerity/sha-rnn
tweet: https://twitter.com/Smerity/status/1199529360954257408?s=20
tl;dr: stop thinking with your (#attention) head :kekeke:
* obtain strong results on a byte level #languageModeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
* support long-range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
* avoid the fragile training process required by standard #Transformer models such as a long warmup
* back off toward a standard #LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
* provide a smaller model that features only standard components such as the LSTM, single-headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
paper: https://arxiv.org/abs/1911.11423
code: https://github.com/Smerity/sha-rnn
tweet: https://twitter.com/Smerity/status/1199529360954257408?s=20
{kind=link}