
Tracking Anything in High Quality
Visual object tracking, a cornerstone of computer vision, is being revolutionized by the ever-increasing power of perception algorithms, facilitating the unification of single/multi-object and box/mask-based tracking. In this thrilling technological panorama, the Segment Anything Model stands out, drawing significant attention from researchers around the globe.
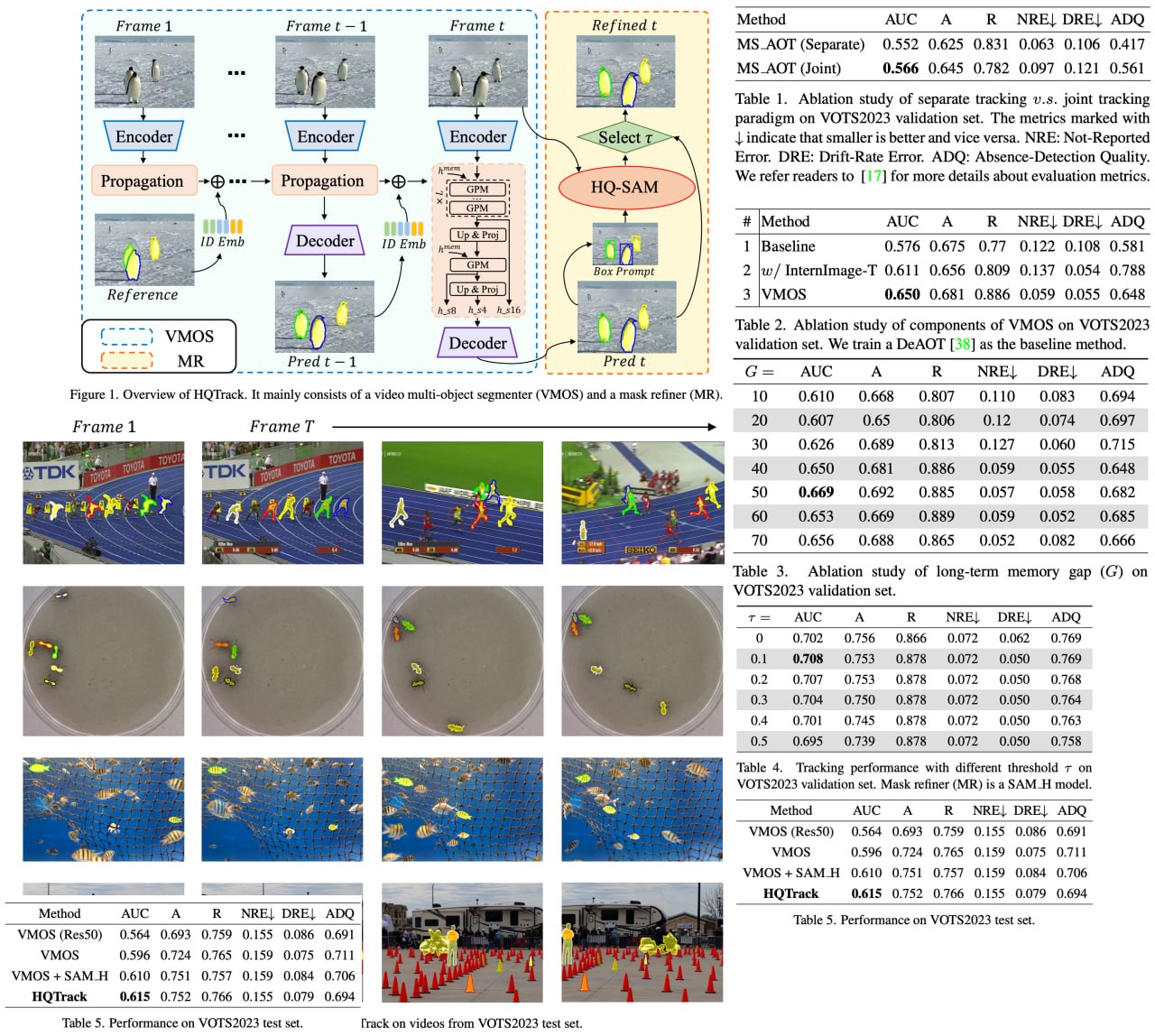
HQTrack is ingeniously constructed with a video multi-object segmenter and a mask refiner. VMOS, given an object in the initial frame, works its magic by propagating object masks to the current frame. However, its initial results may not be perfect due to limited training data, but that's where the MR comes in, refining these results and significantly enhancing the tracking mask quality. HQTrack claimed an impressive second place in the prestigious Visual Object Tracking and Segmentation challenge, all without resorting to any tricks such as test-time data augmentations and model ensembles.
Code link: https://github.com/jiawen-zhu/HQTrack
Paper link: https://arxiv.org/abs/2307.13974
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-hqtrack
#deeplearning #objectdetection #objecttracking
Visual object tracking, a cornerstone of computer vision, is being revolutionized by the ever-increasing power of perception algorithms, facilitating the unification of single/multi-object and box/mask-based tracking. In this thrilling technological panorama, the Segment Anything Model stands out, drawing significant attention from researchers around the globe.
HQTrack is ingeniously constructed with a video multi-object segmenter and a mask refiner. VMOS, given an object in the initial frame, works its magic by propagating object masks to the current frame. However, its initial results may not be perfect due to limited training data, but that's where the MR comes in, refining these results and significantly enhancing the tracking mask quality. HQTrack claimed an impressive second place in the prestigious Visual Object Tracking and Segmentation challenge, all without resorting to any tricks such as test-time data augmentations and model ensembles.
Code link: https://github.com/jiawen-zhu/HQTrack
Paper link: https://arxiv.org/abs/2307.13974
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-hqtrack
#deeplearning #objectdetection #objecttracking
{kind=link}
CoTracker: It is Better to Track Together
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
{kind=link}