
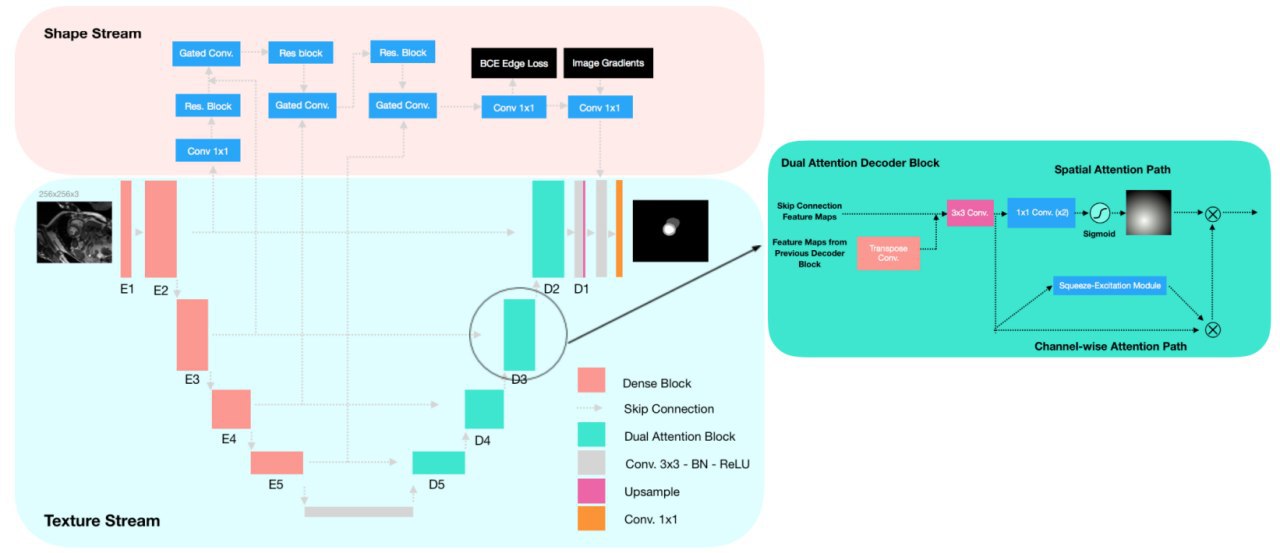
SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
{kind=link}
ObjectAug: Object-level Data Augmentation for Semantic Image Segmentation
The authors suggest ObjectAug perform object-level augmentation for semantic image segmentation.
This approach has the following steps:
- decouple the image into individual objects and the background using the semantic labels;
- augment each object separately;
- restore the black area brought by object augmentation using image inpainting;
- assemble the augmented objects and background;
Thanks to the fact that objects are separate, we can apply different augmentations to different categories and combine them with image-level augmentation methods.
Paper: https://arxiv.org/abs/2102.00221
#deeplearning #augmentation #imageinpainting #imagesegmentation
The authors suggest ObjectAug perform object-level augmentation for semantic image segmentation.
This approach has the following steps:
- decouple the image into individual objects and the background using the semantic labels;
- augment each object separately;
- restore the black area brought by object augmentation using image inpainting;
- assemble the augmented objects and background;
Thanks to the fact that objects are separate, we can apply different augmentations to different categories and combine them with image-level augmentation methods.
Paper: https://arxiv.org/abs/2102.00221
#deeplearning #augmentation #imageinpainting #imagesegmentation
{kind=link}
Cut and Learn for Unsupervised Object Detection and Instance Segmentation
CutLER (Cut-and-LEaRn) is a new approach for training unsupervised object detection and segmentation models without using any human labels. It uses a combination of a MaskCut approach to generate object masks and a robust loss function to learn a detector. The model is simple and compatible with different detection architectures and can detect multiple objects. It is a zero-shot detector, meaning it performs well without additional in-domain data and is robust against domain shifts across various types of images. CutLER can also be used as a pretrained model for supervised detection and improves performance on few-shot benchmarks. Results show improved performance over previous work, including being a zero-shot unsupervised detector and surpassing other low-shot detectors with finetuning.
Paper: https://arxiv.org/abs/2301.11320
Code link: https://github.com/facebookresearch/CutLER1
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cutler
#deeplearning #cv #objectdetection #imagesegmentation
CutLER (Cut-and-LEaRn) is a new approach for training unsupervised object detection and segmentation models without using any human labels. It uses a combination of a MaskCut approach to generate object masks and a robust loss function to learn a detector. The model is simple and compatible with different detection architectures and can detect multiple objects. It is a zero-shot detector, meaning it performs well without additional in-domain data and is robust against domain shifts across various types of images. CutLER can also be used as a pretrained model for supervised detection and improves performance on few-shot benchmarks. Results show improved performance over previous work, including being a zero-shot unsupervised detector and surpassing other low-shot detectors with finetuning.
Paper: https://arxiv.org/abs/2301.11320
Code link: https://github.com/facebookresearch/CutLER1
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cutler
#deeplearning #cv #objectdetection #imagesegmentation
{kind=link}
Segment Anything
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
{kind=link}
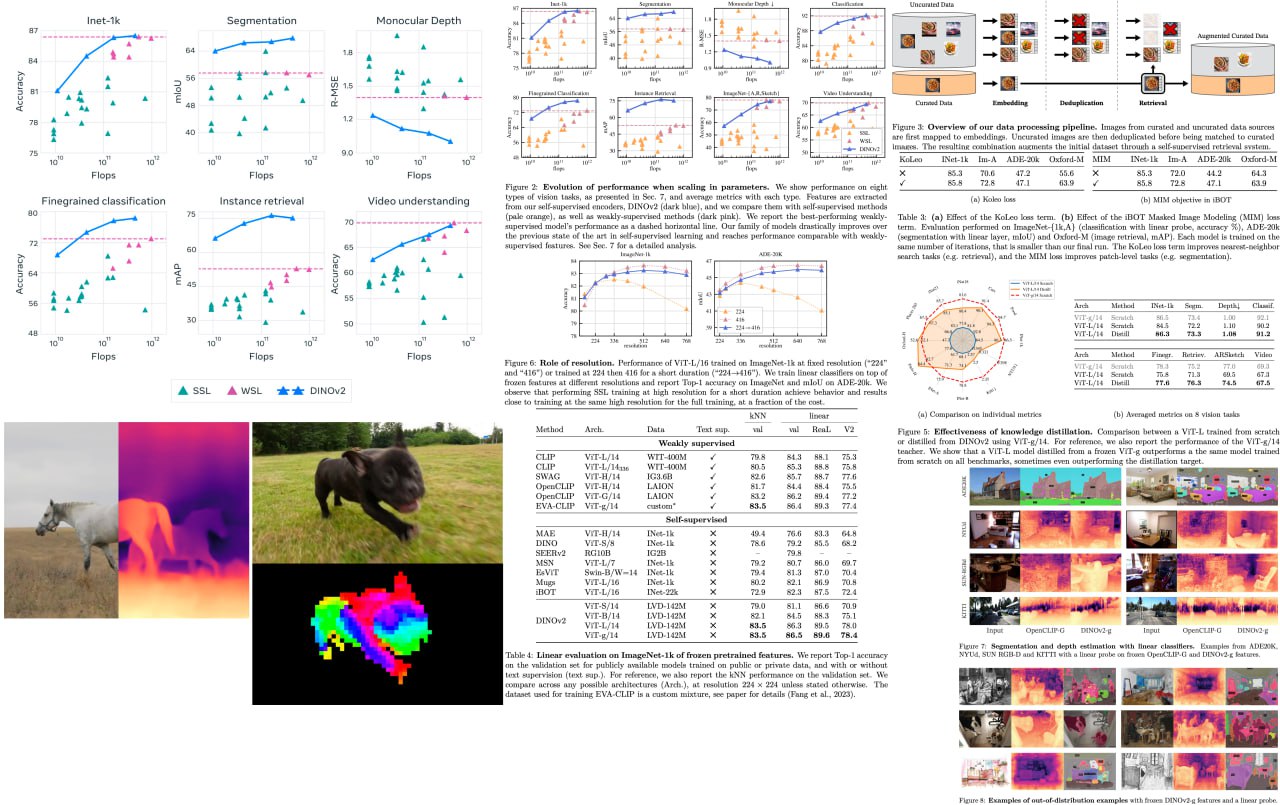
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}
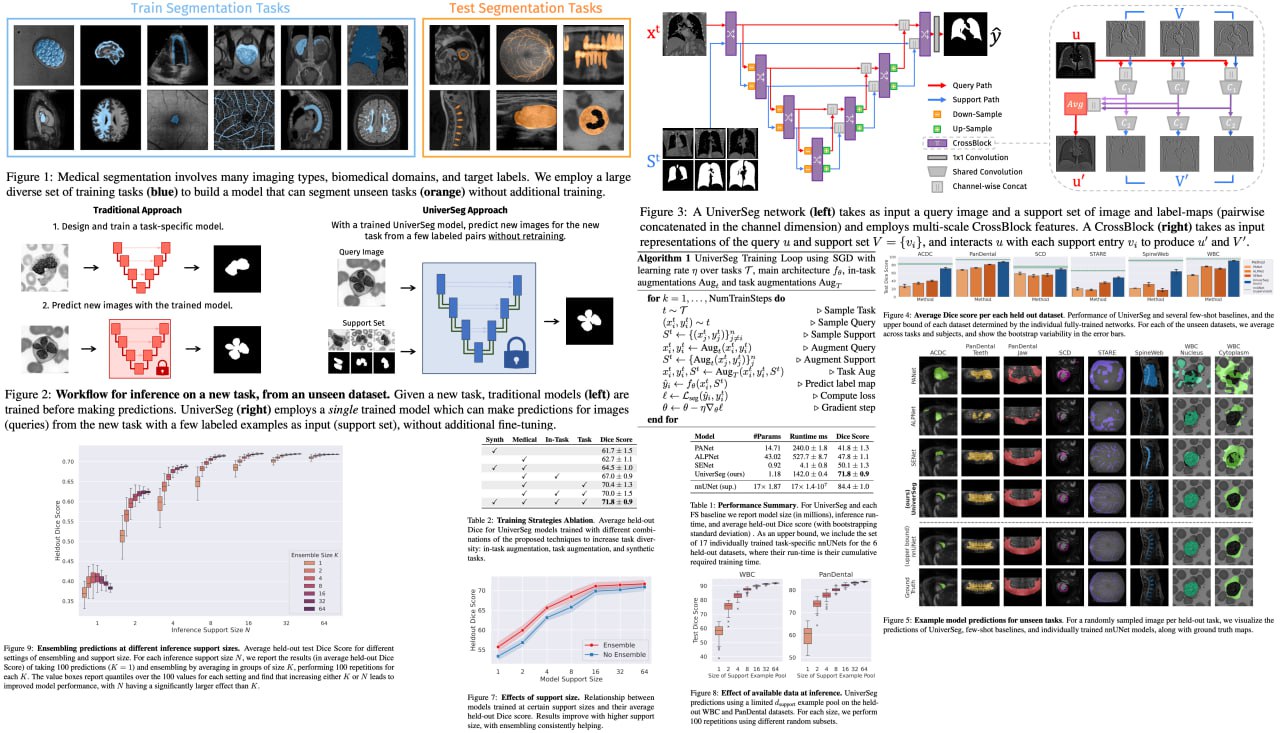
UniverSeg: Universal Medical Image Segmentation
Get ready for a major breakthrough in the field of medical image segmentation! Deep learning models, despite being the primary tool for medical image segmentation, have always struggled to generalize to new, unseen segmentation tasks involving different anatomies, image modalities, or labels. This has typically required researchers to spend significant time and resources on training or fine-tuning models for each new task, a process often out of reach for many clinical researchers. Enter UniverSeg, a trailblazing solution that simplifies this process by tackling unseen medical segmentation tasks without any need for additional training. Its revolutionary Cross-Block mechanism delivers accurate segmentation maps from a query image and a set of example image-label pairs, completely eliminating the need for retraining.
To make this leap, the team behind UniverSeg went the extra mile and assembled MegaMedical, an expansive collection of over 22,000 scans from 53 diverse open-access medical segmentation datasets. This wide variety of anatomies and imaging modalities provided a comprehensive training ground for UniverSeg, priming it to excel in a multitude of scenarios. The results are nothing short of phenomenal - UniverSeg substantially outperforms several related methods on unseen tasks, bringing a new era of efficiency and accessibility to medical imaging.
Paper link: https://arxiv.org/abs/2304.06131
Project link: https://universeg.csail.mit.edu/
Code link: https://github.com/JJGO/UniverSeg
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universeg-med
#deeplearning #cv #imagesegmentation
Get ready for a major breakthrough in the field of medical image segmentation! Deep learning models, despite being the primary tool for medical image segmentation, have always struggled to generalize to new, unseen segmentation tasks involving different anatomies, image modalities, or labels. This has typically required researchers to spend significant time and resources on training or fine-tuning models for each new task, a process often out of reach for many clinical researchers. Enter UniverSeg, a trailblazing solution that simplifies this process by tackling unseen medical segmentation tasks without any need for additional training. Its revolutionary Cross-Block mechanism delivers accurate segmentation maps from a query image and a set of example image-label pairs, completely eliminating the need for retraining.
To make this leap, the team behind UniverSeg went the extra mile and assembled MegaMedical, an expansive collection of over 22,000 scans from 53 diverse open-access medical segmentation datasets. This wide variety of anatomies and imaging modalities provided a comprehensive training ground for UniverSeg, priming it to excel in a multitude of scenarios. The results are nothing short of phenomenal - UniverSeg substantially outperforms several related methods on unseen tasks, bringing a new era of efficiency and accessibility to medical imaging.
Paper link: https://arxiv.org/abs/2304.06131
Project link: https://universeg.csail.mit.edu/
Code link: https://github.com/JJGO/UniverSeg
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universeg-med
#deeplearning #cv #imagesegmentation
{kind=link}
LISA: Reasoning Segmentation via Large Language Model
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
{kind=link}