
Baidu’s neural network based system learned to "clone" a voice with less than a minute of audio data from the speaker.
Explaining website: http://research.baidu.com/neural-voice-cloning-samples/
Paper: https://arxiv.org/pdf/1802.06006.pdf
#DeepLearning #Voice #Speech
Explaining website: http://research.baidu.com/neural-voice-cloning-samples/
Paper: https://arxiv.org/pdf/1802.06006.pdf
#DeepLearning #Voice #Speech
Neural Voice Cloning with a Few Samples
Paper behind Baidu's Neural Voice Cloning with Few samples: http://research.baidu.com/neural-voice-cloning-samples/
Arxiv: https://arxiv.org/abs/1802.06006
#arxiv #baidu #neuralnetworks #voice #sound #dl
Paper behind Baidu's Neural Voice Cloning with Few samples: http://research.baidu.com/neural-voice-cloning-samples/
Arxiv: https://arxiv.org/abs/1802.06006
#arxiv #baidu #neuralnetworks #voice #sound #dl
Reproducing high-quality singing voice
with state-of-the-art AI technology.
Some advance in singing voice synthesis. This opens path toward more interesting collaborations and sythetic celebrities projects.
P.S. Hatsune Miku's will still remain popular for their particular qualities, but now there is more room for competitors.
Link: https://www.techno-speech.com/news-20181214a-en
#SOTA #Voice #Synthesis
with state-of-the-art AI technology.
Some advance in singing voice synthesis. This opens path toward more interesting collaborations and sythetic celebrities projects.
P.S. Hatsune Miku's will still remain popular for their particular qualities, but now there is more room for competitors.
Link: https://www.techno-speech.com/news-20181214a-en
#SOTA #Voice #Synthesis
{kind=link}
Separate voice from music
Spleeter is the Deezer source separation library with pretrained models written in Python and uses Tensorflow. It makes it easy to train source separation model (assuming you have a dataset of isolated sources), and provides already trained state of the art model for performing various flavor of separation:
* vocals (singing voice) / accompaniment separation (2 stems)
* vocals / drums / bass / other separation (4 stems)
* vocals / drums / bass / piano / other separation (5 stems)
Spleeter is also very fast as it can perform separation of audio files to 4 stems 100x faster than real-time when run on a GPU
blog: https://deezer.io/releasing-spleeter-deezer-r-d-source-separation-engine-2b88985e797e
paper: http://archives.ismir.net/ismir2019/latebreaking/000036.pdf
github: https://github.com/deezer/spleeter
#voice #music #tf
Spleeter is the Deezer source separation library with pretrained models written in Python and uses Tensorflow. It makes it easy to train source separation model (assuming you have a dataset of isolated sources), and provides already trained state of the art model for performing various flavor of separation:
* vocals (singing voice) / accompaniment separation (2 stems)
* vocals / drums / bass / other separation (4 stems)
* vocals / drums / bass / piano / other separation (5 stems)
Spleeter is also very fast as it can perform separation of audio files to 4 stems 100x faster than real-time when run on a GPU
blog: https://deezer.io/releasing-spleeter-deezer-r-d-source-separation-engine-2b88985e797e
paper: http://archives.ismir.net/ismir2019/latebreaking/000036.pdf
github: https://github.com/deezer/spleeter
#voice #music #tf
{kind=link}
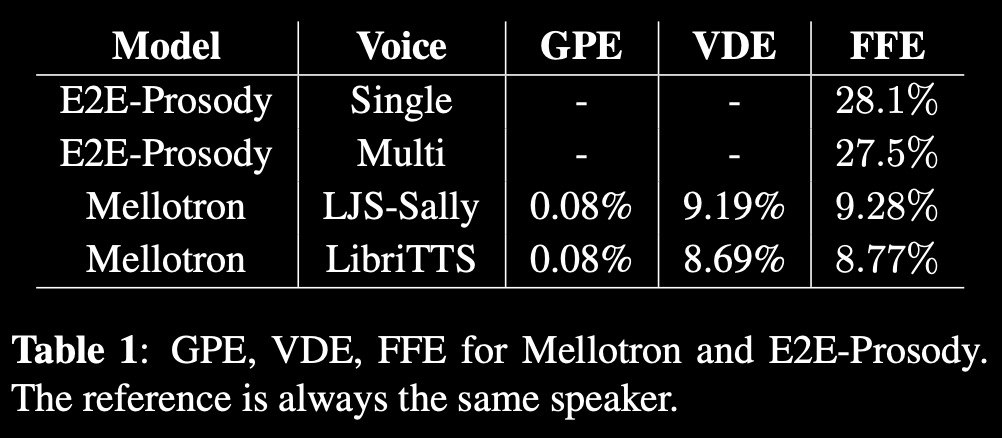
mellotron by #NVIDIA
It's a multispeaker #voice synthesis model based on #Tacotron 2 GST that can make a voice emote and sing without emotive or singing training data.
By explicitly conditioning on rhythm and continuous pitch contours from an audio signal or music score, Mellotron is able to generate #speech in a variety of styles ranging from reading speech to expressive speech, from slow drawls to rap and from monotonous voice to singing voice.
Unlike other methods, Mellotron trains using only read speech data without alignments between text and audio.
Site: https://nv-adlr.github.io/Mellotron
Paper: https://arxiv.org/abs/1910.11997
Git: https://github.com/NVIDIA/mellotron
It's a multispeaker #voice synthesis model based on #Tacotron 2 GST that can make a voice emote and sing without emotive or singing training data.
By explicitly conditioning on rhythm and continuous pitch contours from an audio signal or music score, Mellotron is able to generate #speech in a variety of styles ranging from reading speech to expressive speech, from slow drawls to rap and from monotonous voice to singing voice.
Unlike other methods, Mellotron trains using only read speech data without alignments between text and audio.
Site: https://nv-adlr.github.io/Mellotron
Paper: https://arxiv.org/abs/1910.11997
Git: https://github.com/NVIDIA/mellotron
{kind=link}
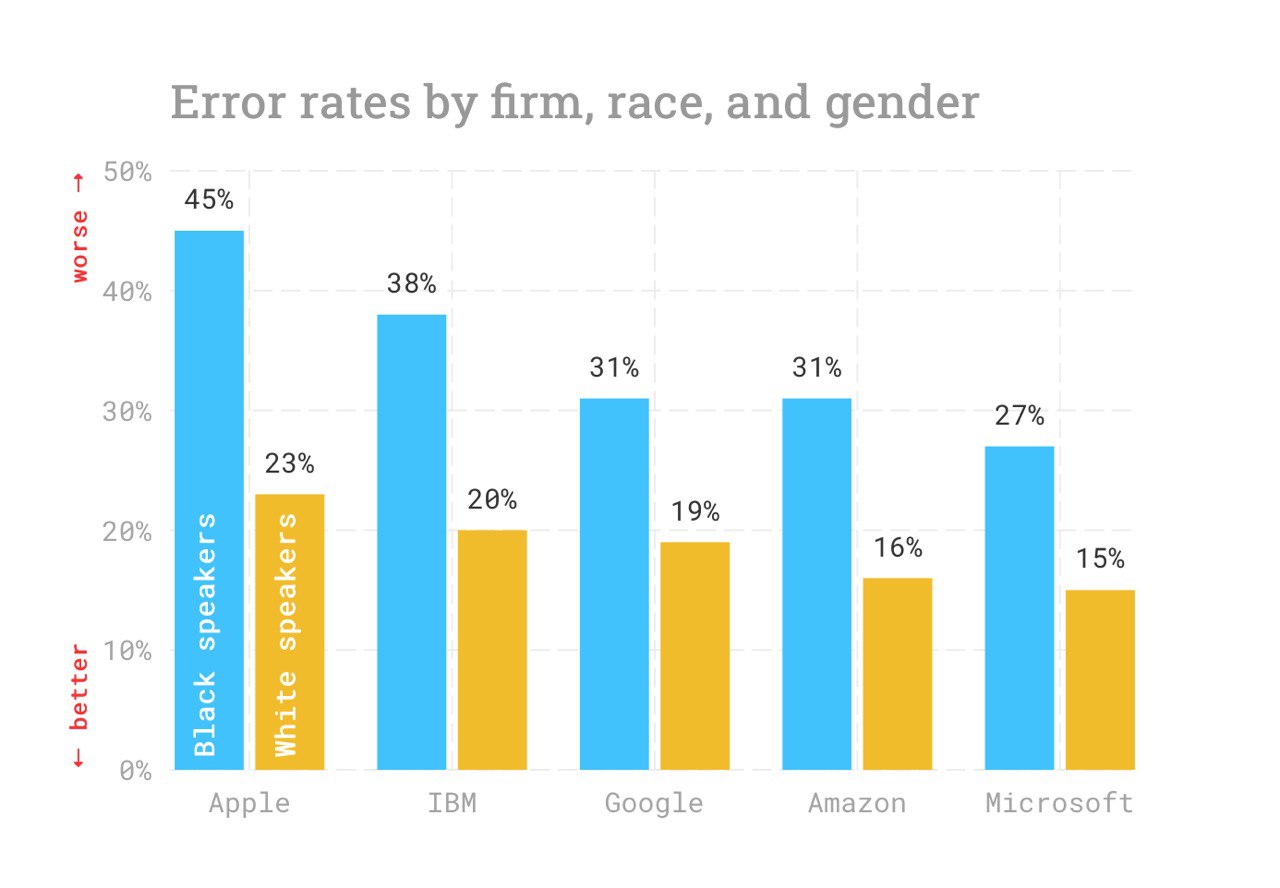
Racial Disparities in Automated Speech Recognition
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
{kind=link}
Forwarded from Machinelearning
Qwen2-Audio - аудио-языковых модель, которая способна принимать аудио и текст на вход и генерировать текст на выходе.
Предусмотрено два режима взаимодействия:
Обе опубликованные модели поддерживают 8 языков и диалектов: китайский, английский, кантонский, французский, итальянский, испанский, немецкий и японский:
Инференс на transformers в cli возможен в нескольких режимах:
# Ensure you have latest Hugging face transformers
pip install git+https://github.com/huggingface/transformers
# to build a web UI demoinstall the following packages
pip install -r requirements_web_demo.txt
# run Gradio web UI
python demo/web_demo_audio.py
@ai_machinelearning_big_data
#AI #LLM #ML #Qwen2
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM