
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
tl;dr: GPT2 + Dialogue data = DialoGPT
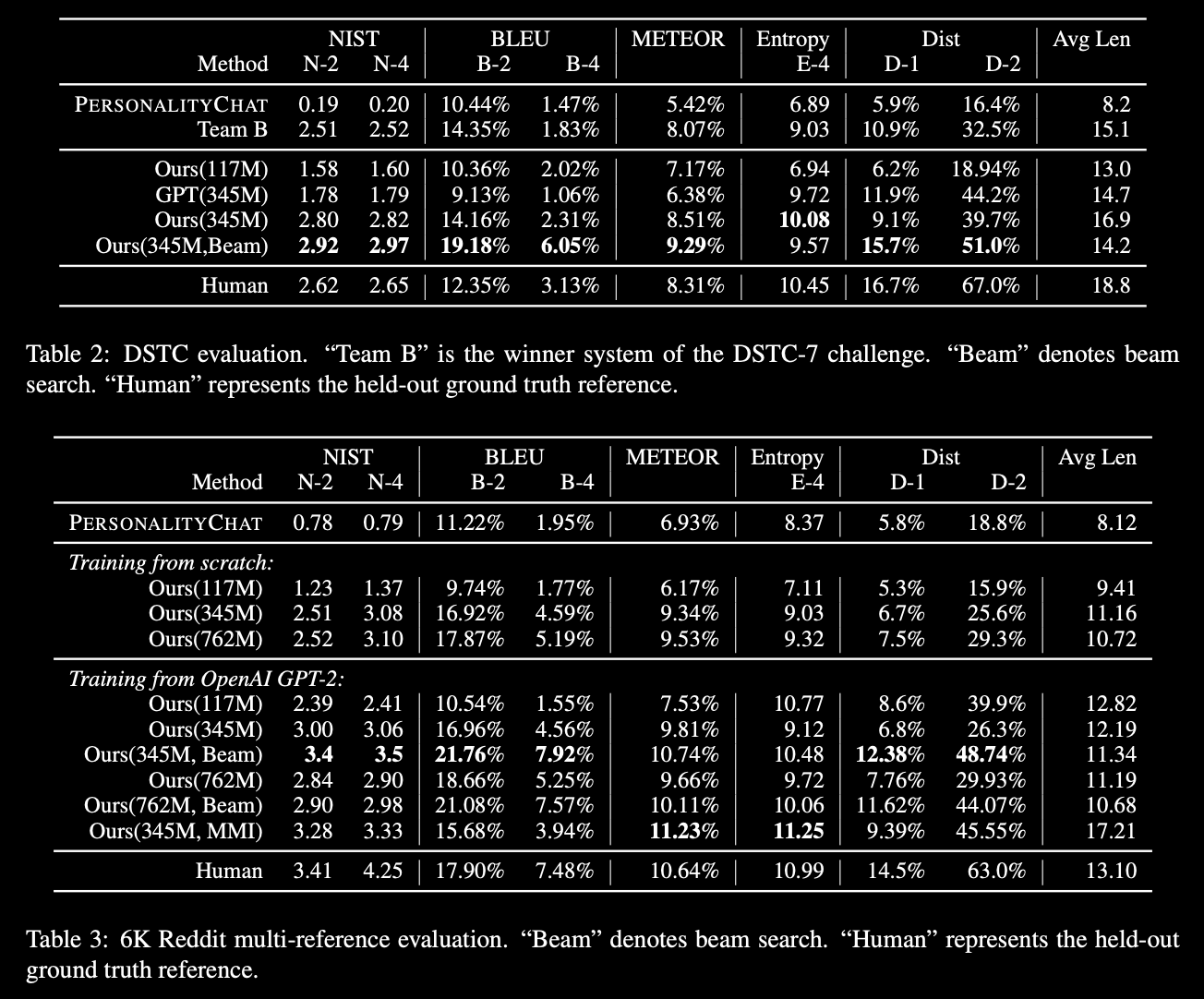
trained on Reddit comments from 2005 through 2017 (not a very big dataset, about 2Gb)
Paper: https://arxiv.org/abs/1911.00536
Code: https://github.com/microsoft/DialoGPT
Blog: https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/
#nlp #gpt2 #dialog
tl;dr: GPT2 + Dialogue data = DialoGPT
trained on Reddit comments from 2005 through 2017 (not a very big dataset, about 2Gb)
Paper: https://arxiv.org/abs/1911.00536
Code: https://github.com/microsoft/DialoGPT
Blog: https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/
#nlp #gpt2 #dialog
{kind=link}
MMM: Multi-stage Multi-task Learning for Multi-choice Reading Comprehension
This method involves two sequential stages:
* coarse-tuning stage using out-of-domain datasets
* multitask learning stage using a larger in-domain dataset to help model generalize better with limited data.
Also, they propose a novel multi-step attention network (MAN) as the top-level classifier for the above task.
MMM demonstrate significantly advances the SOTA on four representative
Dialogue Multiple-Choice QA datasets
paper: https://arxiv.org/abs/1910.00458
#nlp #dialog #qa
This method involves two sequential stages:
* coarse-tuning stage using out-of-domain datasets
* multitask learning stage using a larger in-domain dataset to help model generalize better with limited data.
Also, they propose a novel multi-step attention network (MAN) as the top-level classifier for the above task.
MMM demonstrate significantly advances the SOTA on four representative
Dialogue Multiple-Choice QA datasets
paper: https://arxiv.org/abs/1910.00458
#nlp #dialog #qa
{kind=link}