
Leetcode-cn.com 2022-04-10
🟢 804.unique-morse-code-words
🏷️ Tags
#array #hash_table #string
Description
国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如:
为了方便,所有
给你一个字符串数组
例如,
对
Example
🟢 804.unique-morse-code-words
🏷️ Tags
#array #hash_table #string
Description
国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如:
'a' 对应 ".-" ,'b' 对应 "-..." ,'c' 对应 "-.-." ,以此类推。为了方便,所有
26 个英文字母的摩尔斯密码表如下:
[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
给你一个字符串数组
words ,每个单词可以写成每个字母对应摩尔斯密码的组合。例如,
"cab" 可以写成 "-.-..--..." ,(即 "-.-." + ".-" + "-..." 字符串的结合)。我们将这样一个连接过程称作 单词翻译 。对
words 中所有单词进行单词翻译,返回不同 单词翻译 的数量。Example
输入: words = ["gin", "zen", "gig", "msg"]
输出: 2
解释:
各单词翻译如下:
"gin" -> "--...-."
"zen" -> "--...-."
"gig" -> "--...--."
"msg" -> "--...--."
共有 2 种不同翻译, "--...-." 和 "--...--.".
Leetcode-cn.com 2022-04-14
🟢 1672.richest-customer-wealth
🏷️ Tags
#array #matrix
Description
给你一个
客户的 资产总量 就是他们在各家银行托管的资产数量之和。最富有客户就是 资产总量 最大的客户。
Example
🟢 1672.richest-customer-wealth
🏷️ Tags
#array #matrix
Description
给你一个
m x n 的整数网格 accounts ,其中 accounts[i][j] 是第 i 位客户在第 j 家银行托管的资产数量。返回最富有客户所拥有的 资产总量 。客户的 资产总量 就是他们在各家银行托管的资产数量之和。最富有客户就是 资产总量 最大的客户。
Example
输入:accounts = [[1,2,3],[3,2,1]]
输出:6
解释:
第 1 位客户的资产总量 = 1 + 2 + 3 = 6
第 2 位客户的资产总量 = 3 + 2 + 1 = 6
两位客户都是最富有的,资产总量都是 6 ,所以返回 6 。
Leetcode-cn.com 2022-04-15
🟡 385.mini-parser
🏷️ Tags
#stack #depth_first_search #string
Description
给定一个字符串 s 表示一个整数嵌套列表,实现一个解析它的语法分析器并返回解析的结果
列表中的每个元素只可能是整数或整数嵌套列表
Example
🟡 385.mini-parser
🏷️ Tags
#stack #depth_first_search #string
Description
给定一个字符串 s 表示一个整数嵌套列表,实现一个解析它的语法分析器并返回解析的结果
NestedInteger 。列表中的每个元素只可能是整数或整数嵌套列表
Example
输入:s = "324",
输出:324
解释:你应该返回一个 NestedInteger 对象,其中只包含整数值 324。
Leetcode-cn.com 2022-04-16
🔴 479.largest-palindrome-product
🏷️ Tags
#math
Description
给定一个整数 n ,返回 可表示为两个
Example
🔴 479.largest-palindrome-product
🏷️ Tags
#math
Description
给定一个整数 n ,返回 可表示为两个
n 位整数乘积的 最大回文整数 。因为答案可能非常大,所以返回它对 1337 取余 。Example
输入: n = 1
输出: 9
Leetcode-cn.com 2022-04-17
🟢 819.most-common-word
🏷️ Tags
#hash_table #string #counting
Description
给定一个段落 (paragraph) 和一个禁用单词列表 (banned)。返回出现次数最多,同时不在禁用列表中的单词。
题目保证至少有一个词不在禁用列表中,而且答案唯一。
禁用列表中的单词用小写字母表示,不含标点符号。段落中的单词不区分大小写。答案都是小写字母。
Example
🟢 819.most-common-word
🏷️ Tags
#hash_table #string #counting
Description
给定一个段落 (paragraph) 和一个禁用单词列表 (banned)。返回出现次数最多,同时不在禁用列表中的单词。
题目保证至少有一个词不在禁用列表中,而且答案唯一。
禁用列表中的单词用小写字母表示,不含标点符号。段落中的单词不区分大小写。答案都是小写字母。
Example
输入:
paragraph = "Bob hit a ball, the hit BALL flew far after it was hit."
banned = ["hit"]
输出: "ball"
解释:
"hit" 出现了3次,但它是一个禁用的单词。
"ball" 出现了2次 (同时没有其他单词出现2次),所以它是段落里出现次数最多的,且不在禁用列表中的单词。
注意,所有这些单词在段落里不区分大小写,标点符号需要忽略(即使是紧挨着单词也忽略, 比如 "ball,"),
"hit"不是最终的答案,虽然它出现次数更多,但它在禁用单词列表中。
Leetcode-cn.com 2022-04-18
🟡 386.lexicographical-numbers
🏷️ Tags
#depth_first_search #trie
Description
给你一个整数
你必须设计一个时间复杂度为
Example
🟡 386.lexicographical-numbers
🏷️ Tags
#depth_first_search #trie
Description
给你一个整数
n ,按字典序返回范围 [1, n] 内所有整数。你必须设计一个时间复杂度为
O(n) 且使用 O(1) 额外空间的算法。Example
输入:n = 13
输出:[1,10,11,12,13,2,3,4,5,6,7,8,9]
Leetcode-cn.com 2022-04-19
🟢 821.shortest-distance-to-a-character
🏷️ Tags
#array #two_pointers #string
Description
给你一个字符串
返回一个整数数组
两个下标
Example
🟢 821.shortest-distance-to-a-character
🏷️ Tags
#array #two_pointers #string
Description
给你一个字符串
s 和一个字符 c ,且 c 是 s 中出现过的字符。返回一个整数数组
answer ,其中 answer.length == s.length 且 answer[i] 是 s 中从下标 i 到离它 最近 的字符 c 的 距离 。两个下标
i 和 j 之间的 距离 为 abs(i - j) ,其中 abs 是绝对值函数。Example
输入:s = "loveleetcode", c = "e"
输出:[3,2,1,0,1,0,0,1,2,2,1,0]
解释:字符 'e' 出现在下标 3、5、6 和 11 处(下标从 0 开始计数)。
距下标 0 最近的 'e' 出现在下标 3 ,所以距离为 abs(0 - 3) = 3 。
距下标 1 最近的 'e' 出现在下标 3 ,所以距离为 abs(1 - 3) = 2 。
对于下标 4 ,出现在下标 3 和下标 5 处的 'e' 都离它最近,但距离是一样的 abs(4 - 3) == abs(4 - 5) = 1 。
距下标 8 最近的 'e' 出现在下标 6 ,所以距离为 abs(8 - 6) = 2 。
Leetcode-cn.com 2022-04-20
🟡 388.longest-absolute-file-path
🏷️ Tags
#stack #depth_first_search #string
Description
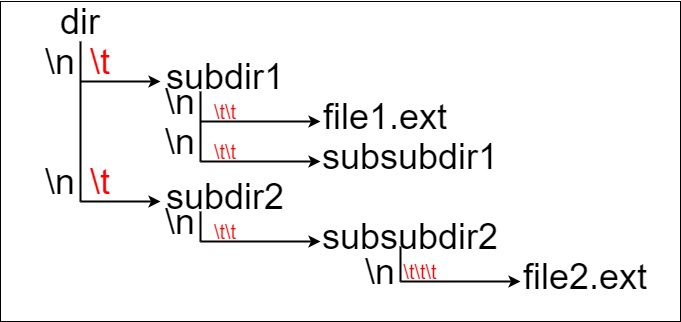
假设有一个同时存储文件和目录的文件系统。下图展示了文件系统的一个Example
🟡 388.longest-absolute-file-path
🏷️ Tags
#stack #depth_first_search #string
Description
假设有一个同时存储文件和目录的文件系统。下图展示了文件系统的一个Example
输入:input = "dir\n\tsubdir1\n\tsubdir2\n\t\tfile.ext"
输出:20
解释:只有一个文件,绝对路径为 "dir/subdir2/file.ext" ,路径长度 20
{kind=link}
Leetcode-cn.com 2022-04-21
🟢 824.goat-latin
🏷️ Tags
#string
Description
给你一个由若干单词组成的句子
请你将句子转换为 “山羊拉丁文(Goat Latin)”(一种类似于 猪拉丁文 - Pig Latin 的虚构语言)。山羊拉丁文的规则如下:
如果单词以元音开头(
例如,单词
如果单词以辅音字母开头(即,非元音字母),移除第一个字符并将它放到末尾,之后再添加
例如,单词
根据单词在句子中的索引,在单词最后添加与索引相同数量的字母
例如,在第一个单词后添加
返回将
Example
🟢 824.goat-latin
🏷️ Tags
#string
Description
给你一个由若干单词组成的句子
sentence ,单词间由空格分隔。每个单词仅由大写和小写英文字母组成。请你将句子转换为 “山羊拉丁文(Goat Latin)”(一种类似于 猪拉丁文 - Pig Latin 的虚构语言)。山羊拉丁文的规则如下:
如果单词以元音开头(
'a', 'e', 'i', 'o', 'u'),在单词后添加"ma"。例如,单词
"apple" 变为 "applema" 。如果单词以辅音字母开头(即,非元音字母),移除第一个字符并将它放到末尾,之后再添加
"ma"。例如,单词
"goat" 变为 "oatgma" 。根据单词在句子中的索引,在单词最后添加与索引相同数量的字母
'a',索引从 1 开始。例如,在第一个单词后添加
"a" ,在第二个单词后添加 "aa" ,以此类推。返回将
sentence 转换为山羊拉丁文后的句子。Example
输入:sentence = "I speak Goat Latin"
输出:"Imaa peaksmaaa oatGmaaaa atinLmaaaaa"
Leetcode-cn.com 2022-04-22
🟡 396.rotate-function
🏷️ Tags
#array #math #dynamic_programming
Description
给定一个长度为
假设
返回
生成的测试用例让答案符合 32 位 整数。
Example
🟡 396.rotate-function
🏷️ Tags
#array #math #dynamic_programming
Description
给定一个长度为
n 的整数数组 nums 。假设
arrk 是数组 nums 顺时针旋转 k 个位置后的数组,我们定义 nums 的 旋转函数 F 为:F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1]返回
F(0), F(1), ..., F(n-1)中的最大值 。生成的测试用例让答案符合 32 位 整数。
Example
输入: nums = [4,3,2,6]
输出: 26
解释:
F(0) = (0 * 4) + (1 * 3) + (2 * 2) + (3 * 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 * 6) + (1 * 4) + (2 * 3) + (3 * 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 * 2) + (1 * 6) + (2 * 4) + (3 * 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 * 3) + (1 * 2) + (2 * 6) + (3 * 4) = 0 + 2 + 12 + 12 = 26
所以 F(0), F(1), F(2), F(3) 中的最大值是 F(3) = 26 。
Leetcode-cn.com 2022-04-24
🟢 868.binary-gap
🏷️ Tags
#bit_manipulation #math
Description
给定一个正整数
如果只有
Example
🟢 868.binary-gap
🏷️ Tags
#bit_manipulation #math
Description
给定一个正整数
n,找到并返回 n 的二进制表示中两个 相邻 1 之间的 最长距离 。如果不存在两个相邻的 1,返回 0 。如果只有
0 将两个 1 分隔开(可能不存在 0 ),则认为这两个 1 彼此 相邻 。两个 1 之间的距离是它们的二进制表示中位置的绝对差。例如,"1001" 中的两个 1 的距离为 3 。Example
输入:n = 22
输出:2
解释:22 的二进制是 "10110" 。
在 22 的二进制表示中,有三个 1,组成两对相邻的 1 。
第一对相邻的 1 中,两个 1 之间的距离为 2 。
第二对相邻的 1 中,两个 1 之间的距离为 1 。
答案取两个距离之中最大的,也就是 2 。
Leetcode-cn.com 2022-04-27
🟡 417.pacific-atlantic-water-flow
🏷️ Tags
#depth_first_search #breadth_first_search #array #matrix
Description
有一个
这个岛被分割成一个由若干方形单元格组成的网格。给定一个
岛上雨水较多,如果相邻单元格的高度 小于或等于 当前单元格的高度,雨水可以直接向北、南、东、西流向相邻单元格。水可以从海洋附近的任何单元格流入海洋。
返回 网格坐标
Example
🟡 417.pacific-atlantic-water-flow
🏷️ Tags
#depth_first_search #breadth_first_search #array #matrix
Description
有一个
m × n 的矩形岛屿,与 太平洋 和 大西洋 相邻。 “太平洋” 处于大陆的左边界和上边界,而 “大西洋” 处于大陆的右边界和下边界。这个岛被分割成一个由若干方形单元格组成的网格。给定一个
m x n 的整数矩阵 heights , heights[r][c] 表示坐标 (r, c) 上单元格 高于海平面的高度 。岛上雨水较多,如果相邻单元格的高度 小于或等于 当前单元格的高度,雨水可以直接向北、南、东、西流向相邻单元格。水可以从海洋附近的任何单元格流入海洋。
返回 网格坐标
result 的 2D列表 ,其中 result[i] = [ri, ci] 表示雨水可以从单元格 (ri, ci) 流向 太平洋和大西洋 。Example
输入: heights = [[1,2,2,3,5],[3,2,3,4,4],[2,4,5,3,1],[6,7,1,4,5],[5,1,1,2,4]]
输出: [[0,4],[1,3],[1,4],[2,2],[3,0],[3,1],[4,0]]
Leetcode-cn.com 2022-04-28
🟢 905.sort-array-by-parity
🏷️ Tags
#array #two_pointers #sorting
Description
给你一个整数数组
返回满足此条件的 任一数组 作为答案。
Example
🟢 905.sort-array-by-parity
🏷️ Tags
#array #two_pointers #sorting
Description
给你一个整数数组
nums,将 nums 中的的所有偶数元素移动到数组的前面,后跟所有奇数元素。返回满足此条件的 任一数组 作为答案。
Example
输入:nums = [3,1,2,4]
输出:[2,4,3,1]
解释:[4,2,3,1]、[2,4,1,3] 和 [4,2,1,3] 也会被视作正确答案。
Leetcode-cn.com 2022-04-30
🟢 908.smallest-range-i
🏷️ Tags
#array #math
Description
给你一个整数数组
在一个操作中,您可以选择
在对
Example
🟢 908.smallest-range-i
🏷️ Tags
#array #math
Description
给你一个整数数组
nums,和一个整数 k 。在一个操作中,您可以选择
0 <= i < nums.length 的任何索引 i 。将 nums[i] 改为 nums[i] + x ,其中 x 是一个范围为 [-k, k] 的整数。对于每个索引 i ,最多 只能 应用 一次 此操作。nums 的 分数 是 nums 中最大和最小元素的差值。 在对
nums 中的每个索引最多应用一次上述操作后,返回 nums 的最低 分数 。Example
输入:nums = [1], k = 0
输出:0
解释:分数是 max(nums) - min(nums) = 1 - 1 = 0。
Leetcode-cn.com 2022-05-01
🟡 1305.all-elements-in-two-binary-search-trees
🏷️ Tags
#tree #depth_first_search #binary_search_tree #binary_tree #sorting
Description
给你
Example
🟡 1305.all-elements-in-two-binary-search-trees
🏷️ Tags
#tree #depth_first_search #binary_search_tree #binary_tree #sorting
Description
给你
root1 和 root2 这两棵二叉搜索树。请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.Example
输入:root1 = [2,1,4], root2 = [1,0,3]
输出:[0,1,1,2,3,4]
Leetcode-cn.com 2022-05-02
🔴 591.tag-validator
🏷️ Tags
#stack #string
undefinedExample
🔴 591.tag-validator
🏷️ Tags
#stack #string
undefinedExample
输入: "<DIV>This is the first line <![CDATA[<div>]]></DIV>"
输出: True
解释:
代码被包含在了闭合的标签内: <DIV> 和 </DIV> 。
TAG_NAME 是合法的,TAG_CONTENT 包含了一些字符和 cdata 。
即使 CDATA_CONTENT 含有不匹配的起始标签和不合法的 TAG_NAME,它应该被视为普通的文本,而不是标签。
所以 TAG_CONTENT 是合法的,因此代码是合法的。最终返回True。
输入: "<DIV>>> ![cdata[]] <![CDATA[<div>]>]]>]]>>]</DIV>"
输出: True
解释:
我们首先将代码分割为: start_tag|tag_content|end_tag 。
start_tag -> "<DIV>"
end_tag -> "</DIV>"
tag_content 也可被分割为: text1|cdata|text2 。
text1 -> ">> ![cdata[]] "
cdata -> "<![CDATA[<div>]>]]>" ,其中 CDATA_CONTENT 为 "<div>]>"
text2 -> "]]>>]"
start_tag 不是 "<DIV>>>" 的原因参照规则 6 。
cdata 不是 "<![CDATA[<div>]>]]>]]>" 的原因参照规则 7 。
Leetcode-cn.com 2022-05-03
🟢 937.reorder-data-in-log-files
🏷️ Tags
#array #string #sorting
Description
给你一个日志数组
有两种不同类型的日志:
字母日志:除标识符之外,所有字均由小写字母组成
数字日志:除标识符之外,所有字均由数字组成
请按下述规则将日志重新排序:
所有 字母日志 都排在 数字日志 之前。
字母日志 在内容不同时,忽略标识符后,按内容字母顺序排序;在内容相同时,按标识符排序。
数字日志 应该保留原来的相对顺序。
返回日志的最终顺序。
Example
🟢 937.reorder-data-in-log-files
🏷️ Tags
#array #string #sorting
Description
给你一个日志数组
logs。每条日志都是以空格分隔的字串,其第一个字为字母与数字混合的 标识符 。有两种不同类型的日志:
字母日志:除标识符之外,所有字均由小写字母组成
数字日志:除标识符之外,所有字均由数字组成
请按下述规则将日志重新排序:
所有 字母日志 都排在 数字日志 之前。
字母日志 在内容不同时,忽略标识符后,按内容字母顺序排序;在内容相同时,按标识符排序。
数字日志 应该保留原来的相对顺序。
返回日志的最终顺序。
Example
输入:logs = ["dig1 8 1 5 1","let1 art can","dig2 3 6","let2 own kit dig","let3 art zero"]
输出:["let1 art can","let3 art zero","let2 own kit dig","dig1 8 1 5 1","dig2 3 6"]
解释:
字母日志的内容都不同,所以顺序为 "art can", "art zero", "own kit dig" 。
数字日志保留原来的相对顺序 "dig1 8 1 5 1", "dig2 3 6" 。
Leetcode-cn.com 2022-05-05
🟡 713.subarray-product-less-than-k
🏷️ Tags
#array #sliding_window
Description
给你一个整数数组
Example
🟡 713.subarray-product-less-than-k
🏷️ Tags
#array #sliding_window
Description
给你一个整数数组
nums 和一个整数 k ,请你返回子数组内所有元素的乘积严格小于 k 的连续子数组的数目。Example
输入:nums = [10,5,2,6], k = 100
输出:8
解释:8 个乘积小于 100 的子数组分别为:[10]、[5]、[2],、[6]、[10,5]、[5,2]、[2,6]、[5,2,6]。
需要注意的是 [10,5,2] 并不是乘积小于 100 的子数组。
Leetcode-cn.com 2022-05-06
🟢 933.number-of-recent-calls
🏷️ Tags
#design #queue #data_stream
Description
写一个
请你实现
保证 每次对
Example
🟢 933.number-of-recent-calls
🏷️ Tags
#design #queue #data_stream
Description
写一个
RecentCounter 类来计算特定时间范围内最近的请求。请你实现
RecentCounter 类:RecentCounter() 初始化计数器,请求数为 0 。int ping(int t) 在时间 t 添加一个新请求,其中 t 表示以毫秒为单位的某个时间,并返回过去 3000 毫秒内发生的所有请求数(包括新请求)。确切地说,返回在 [t-3000, t] 内发生的请求数。保证 每次对
ping 的调用都使用比之前更大的 t 值。Example
输入:
["RecentCounter", "ping", "ping", "ping", "ping"]
[[], [1], [100], [3001], [3002]]
输出:
[null, 1, 2, 3, 3]
解释:
RecentCounter recentCounter = new RecentCounter();
recentCounter.ping(1); // requests = [1],范围是 [-2999,1],返回 1
recentCounter.ping(100); // requests = [1, 100],范围是 [-2900,100],返回 2
recentCounter.ping(3001); // requests = [1, 100, 3001],范围是 [1,3001],返回 3
recentCounter.ping(3002); // requests = [1, 100, 3001, 3002],范围是 [2,3002],返回 3
Leetcode-cn.com 2022-05-07
🟡 433.minimum-genetic-mutation
🏷️ Tags
#breadth_first_search #hash_table #string
Description
基因序列可以表示为一条由 8 个字符组成的字符串,其中每个字符都是
假设我们需要调查从基因序列
例如,
另有一个基因库
给你两个基因序列
注意:起始基因序列
Example
🟡 433.minimum-genetic-mutation
🏷️ Tags
#breadth_first_search #hash_table #string
Description
基因序列可以表示为一条由 8 个字符组成的字符串,其中每个字符都是
'A'、'C'、'G' 和 'T' 之一。假设我们需要调查从基因序列
start 变为 end 所发生的基因变化。一次基因变化就意味着这个基因序列中的一个字符发生了变化。例如,
"AACCGGTT" --> "AACCGGTA" 就是一次基因变化。另有一个基因库
bank 记录了所有有效的基因变化,只有基因库中的基因才是有效的基因序列。给你两个基因序列
start 和 end ,以及一个基因库 bank ,请你找出并返回能够使 start 变化为 end 所需的最少变化次数。如果无法完成此基因变化,返回 -1 。注意:起始基因序列
start 默认是有效的,但是它并不一定会出现在基因库中。Example
输入:start = "AACCGGTT", end = "AACCGGTA", bank = ["AACCGGTA"]
输出:1