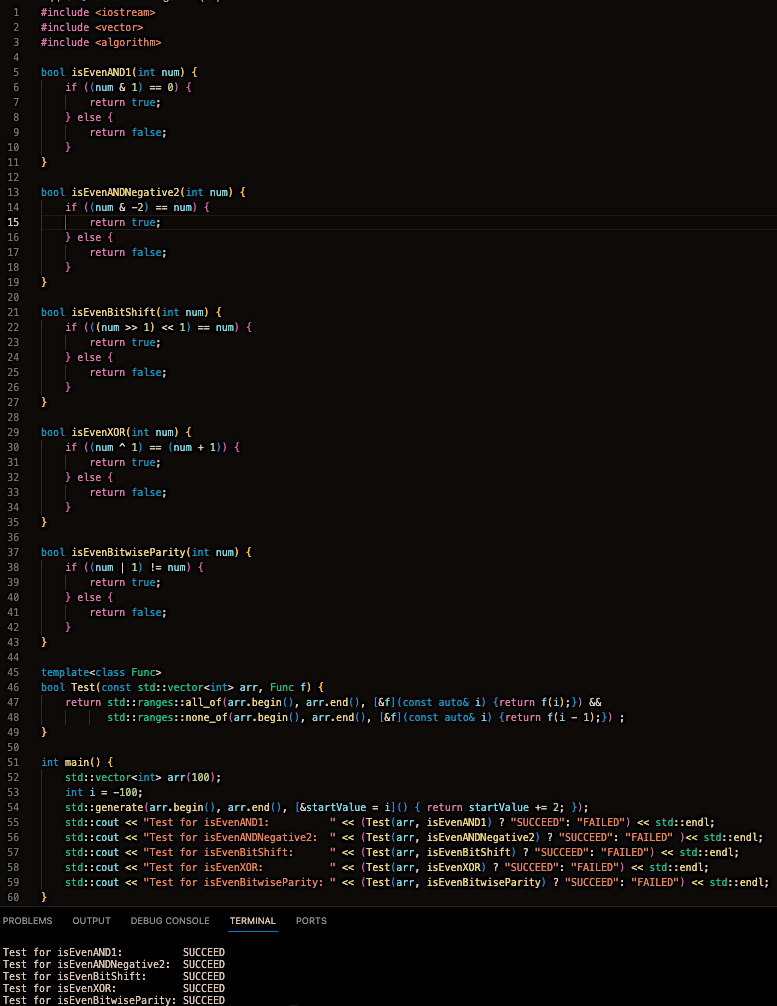
Как узнать четное ли число
Вы сейчас подумали, типа "wtf, он шо нас за идиотов держит". Но погодите, щас все объясню.
Есть одно условие: нельзя использовать операции целочисленного деления и брать остаток от деления. Вот это уже задачка не для второклассников и обычный человек вряд ли с ней справится. Но программист может. Хотя и не любой, судя по моему небольшому опросу😆)
Сделайте паузу, скушайте твикс и подумайте. Знаю, что у нас крутое коммьюнити и все с легкостью решат эту задачу. Но если вдруг, вы не решили, то просто посидите на литкоде, там таких задачек навалом и вы довольно быстро выработаете интуицию к решению в принципе любых алгоритмических задач, включая такие.
В общем. Нужно просто проверить последний бит. Если он ноль - число четное, если нет - число нечетное. Все очень просто. Делается это с помощью битового & с единичкой.
Но во время написания этого поста мне пришла идея задать эту задачку ChatGPT, в тему недавнего поста про него. Правда я попросил сгенерировать 3 примера. Чисто из интереса. И результат меня сильно удивил. Все 3 примера были правильные, среди них было решение из абзаца выше, но было и еще 2, о которых я и не думал. После этого попросил нагенерить еще 2 примера. И они тоже были верные. Конечно, все из них использовали битовые операции, но как филигранно!
Очень интересно решение с битовым умножением на -2. Дело в том, что -2 в памяти компьютера представляется как 111...1110. Поэтому умножение любого числа на -2 будет давать то же самое число, только если последний бит был выставлен в 0.
Короче говоря решил с вами поделиться этим небольшим открытием. Просто еще один пример, что языковые модели реально могут в реально простые задачи. Ниже вы можете посмотреть все 5 способов решения. Некоторые правда пришлось все-таки подредактировать, но это мелочи.
Stay amazed. Stay cool.
#fun
Вы сейчас подумали, типа "wtf, он шо нас за идиотов держит". Но погодите, щас все объясню.
Есть одно условие: нельзя использовать операции целочисленного деления и брать остаток от деления. Вот это уже задачка не для второклассников и обычный человек вряд ли с ней справится. Но программист может. Хотя и не любой, судя по моему небольшому опросу😆)
Сделайте паузу, скушайте твикс и подумайте. Знаю, что у нас крутое коммьюнити и все с легкостью решат эту задачу. Но если вдруг, вы не решили, то просто посидите на литкоде, там таких задачек навалом и вы довольно быстро выработаете интуицию к решению в принципе любых алгоритмических задач, включая такие.
В общем. Нужно просто проверить последний бит. Если он ноль - число четное, если нет - число нечетное. Все очень просто. Делается это с помощью битового & с единичкой.
Но во время написания этого поста мне пришла идея задать эту задачку ChatGPT, в тему недавнего поста про него. Правда я попросил сгенерировать 3 примера. Чисто из интереса. И результат меня сильно удивил. Все 3 примера были правильные, среди них было решение из абзаца выше, но было и еще 2, о которых я и не думал. После этого попросил нагенерить еще 2 примера. И они тоже были верные. Конечно, все из них использовали битовые операции, но как филигранно!
Очень интересно решение с битовым умножением на -2. Дело в том, что -2 в памяти компьютера представляется как 111...1110. Поэтому умножение любого числа на -2 будет давать то же самое число, только если последний бит был выставлен в 0.
Короче говоря решил с вами поделиться этим небольшим открытием. Просто еще один пример, что языковые модели реально могут в реально простые задачи. Ниже вы можете посмотреть все 5 способов решения. Некоторые правда пришлось все-таки подредактировать, но это мелочи.
Stay amazed. Stay cool.
#fun
{kind=link}
4❤🔥38👍23❤5👎3😱3🥱3
Неименованные параметры функций
С++ позволяет не указывать имена параметров функций, если они не используются в коде.
Это можно делать и в объявлении функции, и в ее определении.
Важный момент, что отсутствие имени параметра не говорит о том, что параметра нет и его не нужно передавать. Для вызова такой функции вы должны передать в нее аргумент соответствующего типа. Даже если он ничего не делает полезного.
Но вот вопрос возникает тогда. Если параметр ничего не делает, нахрена он тогда вообще нужен?
На самом деле много кейсов, где неименованный параметр может пригодится.
💥 Допустим, у вас есть функция, которая используется в очень многих местах кода, может даже через какие-нибудь указатели на функцию. И в один момент времени часть функционала стала ненужной и один или несколько параметров стали ненужны. Править все вызовы этой функции было бы болью, особенно если туда вовлечены function поинтеры. Вместо этого вы можете сделать эти параметры безымянными, чтобы явно в коде показать, что этот параметр не используется. Его и нельзя даже будет использовать.
💥 Заглушки. Зачастую для тестирования функциональности применяют сущности-болванки, которые внешне ведут себя, как нормальные ребята, но на самом деле они лодыри и ничего путного не делают. Это нужно для мокания соседних модулей, чтобы протестировать только функциональность выбранного набора модулей. Такие заглушки должны выглядеть подобающе, то есть полностью повторять апи замоканой сущности, но могут не делать никакой полезной работы. Поэтому можно в этом апи сделать безымянные параметры, чтобы еще раз подчеркнуть, что они не используются.
💥 Иногда существующие сущности в коде требуют коллбэки определенного вида. И вам в своем коллбэке возможно не нужно использовать весь набор параметров. Но для соблюдения апи вы должны их указать в сигнатуре своего обратного вызова. В этом случае можно сделать эти параметры безымянными.
💥 Иногда в иерархии полиморфных классов в конкретном наследнике вам не нужны все параметры виртуальной функции. Но для поддержания корректности переопределения виртуального интерфейса вы должны включить все параметры в сигнатуру метода. Опять же, неиспользуемые параметры можно пометить безымянными.
💥 Знаменитая перегрузка постфиксного оператора инкремента/декремента. Есть 2 вида этих операторов: префикстный и постфиксный. Проблема в том, что это все еще вызов функции operator++. Как различить реализации этих функций? Правильно, нужна перегрузка. Вот здесь и приходит на помощь безымянный параметр: в коде он не нужен, но влияет на выбор конкретной перегрузки. Выглядит это так:
В целом, эта фича нужна либо для соблюдения существующего апи, либо для того, чтобы при вызове функции гарантировано вызвалась правильная перегрузка.
Stay useful. Stay cool.
#cppcore #design
С++ позволяет не указывать имена параметров функций, если они не используются в коде.
void foo(int /no name here/);
void foo(int /no name here/)
{
std::cout << "foo" << std::endl;
}
foo(5);
Это можно делать и в объявлении функции, и в ее определении.
Важный момент, что отсутствие имени параметра не говорит о том, что параметра нет и его не нужно передавать. Для вызова такой функции вы должны передать в нее аргумент соответствующего типа. Даже если он ничего не делает полезного.
Но вот вопрос возникает тогда. Если параметр ничего не делает, нахрена он тогда вообще нужен?
На самом деле много кейсов, где неименованный параметр может пригодится.
💥 Допустим, у вас есть функция, которая используется в очень многих местах кода, может даже через какие-нибудь указатели на функцию. И в один момент времени часть функционала стала ненужной и один или несколько параметров стали ненужны. Править все вызовы этой функции было бы болью, особенно если туда вовлечены function поинтеры. Вместо этого вы можете сделать эти параметры безымянными, чтобы явно в коде показать, что этот параметр не используется. Его и нельзя даже будет использовать.
💥 Заглушки. Зачастую для тестирования функциональности применяют сущности-болванки, которые внешне ведут себя, как нормальные ребята, но на самом деле они лодыри и ничего путного не делают. Это нужно для мокания соседних модулей, чтобы протестировать только функциональность выбранного набора модулей. Такие заглушки должны выглядеть подобающе, то есть полностью повторять апи замоканой сущности, но могут не делать никакой полезной работы. Поэтому можно в этом апи сделать безымянные параметры, чтобы еще раз подчеркнуть, что они не используются.
💥 Иногда существующие сущности в коде требуют коллбэки определенного вида. И вам в своем коллбэке возможно не нужно использовать весь набор параметров. Но для соблюдения апи вы должны их указать в сигнатуре своего обратного вызова. В этом случае можно сделать эти параметры безымянными.
💥 Иногда в иерархии полиморфных классов в конкретном наследнике вам не нужны все параметры виртуальной функции. Но для поддержания корректности переопределения виртуального интерфейса вы должны включить все параметры в сигнатуру метода. Опять же, неиспользуемые параметры можно пометить безымянными.
💥 Знаменитая перегрузка постфиксного оператора инкремента/декремента. Есть 2 вида этих операторов: префикстный и постфиксный. Проблема в том, что это все еще вызов функции operator++. Как различить реализации этих функций? Правильно, нужна перегрузка. Вот здесь и приходит на помощь безымянный параметр: в коде он не нужен, но влияет на выбор конкретной перегрузки. Выглядит это так:
struct Digit
{
Digit(int digit=0) : m_digit{digit} {}
Digit& operator++(); // prefix has no parameter
Digit operator++(int); // postfix has an int parameter
private:
int m_digit{};
};
В целом, эта фича нужна либо для соблюдения существующего апи, либо для того, чтобы при вызове функции гарантировано вызвалась правильная перегрузка.
Stay useful. Stay cool.
#cppcore #design
{kind=link}
4❤🔥15🔥7❤6😁6👍5
Достигаем недостижимое
В прошлом посте вот такой код:
Приводил к очень неожиданным сайд-эффектам. При его компиляции клангом выводился принт, хотя в функции main мы нигде не вызываем unreachable.
Темная магия это или проделки ГосДепа узнаем дальше.
Для начала, этот код содержит UB. Согласно стандарту программа должна производить какие-то обозримые эффекты. Или завершиться, или работать с вводом-выводом, или работать с volatile переменными, или выполнять синхронизирующие операции. Это требования forward progress. Если программа ничего из этого не делает - код содержит UB.
Так вот у нас пустой бесконечный цикл. То есть предполагается, что он будет работать бесконечно и ничего полезного не делать.
Тут очень важно понять одну вещь. Компилятор следует не вашей логике и ожиданиям, как должна работать программа. У него есть фактически инструкция(стандарт), которой он следует.
По стандарту программа, содержащая бесконечные циклы без side-эффектов, содержит UB и компилятор имеет право делать с этим циклом все, что ему захочется.
В данном случае он просто удаляет цикл. Но он не только удаляет цикл. Но еще и удаляет инструкцию возврата из main.
В нормальных программах функция main в ассемблере представляет из себя следующее:
ret - инструкция возврата из функции. И код функции main выполняется, пока не достигнет этой инструкции.
Так вот в нашем случае этой инструкции нет и код продолжает выполнение дальше. А дальше у нас очень удобненько расположилась функция с принтом, вывод которой мы и видим. Выглядит это так:
Почему удаляется return - не так уж очевидно и для самих разработчиков компилятора. У них есть тред обсуждения этого вопроса, который не привел к какому-то знаменателю. Так что не буду городить догадок.
Справедливости ради стоит сказать, что в 19-м шланге поменяли это поведение и теперь таких неожиданностей нет.
Stay predictable. Stay cool.
#fun #cppcore #compiler
В прошлом посте вот такой код:
int main() {
while(1);
return 0;
}
void unreachable() {
std::cout << "Hello, World!" << std::endl;
}Приводил к очень неожиданным сайд-эффектам. При его компиляции клангом выводился принт, хотя в функции main мы нигде не вызываем unreachable.
Темная магия это или проделки ГосДепа узнаем дальше.
Для начала, этот код содержит UB. Согласно стандарту программа должна производить какие-то обозримые эффекты. Или завершиться, или работать с вводом-выводом, или работать с volatile переменными, или выполнять синхронизирующие операции. Это требования forward progress. Если программа ничего из этого не делает - код содержит UB.
Так вот у нас пустой бесконечный цикл. То есть предполагается, что он будет работать бесконечно и ничего полезного не делать.
Тут очень важно понять одну вещь. Компилятор следует не вашей логике и ожиданиям, как должна работать программа. У него есть фактически инструкция(стандарт), которой он следует.
По стандарту программа, содержащая бесконечные циклы без side-эффектов, содержит UB и компилятор имеет право делать с этим циклом все, что ему захочется.
В данном случае он просто удаляет цикл. Но он не только удаляет цикл. Но еще и удаляет инструкцию возврата из main.
В нормальных программах функция main в ассемблере представляет из себя следующее:
main:
// Perform some code
ret
ret - инструкция возврата из функции. И код функции main выполняется, пока не достигнет этой инструкции.
Так вот в нашем случае этой инструкции нет и код продолжает выполнение дальше. А дальше у нас очень удобненько расположилась функция с принтом, вывод которой мы и видим. Выглядит это так:
main:
unreachable():
push rax
mov rdi, qword ptr [rip + std::cout@GOTPCREL]
lea rsi, [rip + .L.str]
call std::basic_ostream<char, std::char_traits<char>>...
Почему удаляется return - не так уж очевидно и для самих разработчиков компилятора. У них есть тред обсуждения этого вопроса, который не привел к какому-то знаменателю. Так что не буду городить догадок.
Справедливости ради стоит сказать, что в 19-м шланге поменяли это поведение и теперь таких неожиданностей нет.
Stay predictable. Stay cool.
#fun #cppcore #compiler
{kind=link}
15🔥42👍10😁10❤4❤🔥2👎1
Достаем элемент из последовательного контейнера
Обработка ошибок, да и в принципе нежелательных путей развития ситуации, может порождать много споров, боли, баттхерта и, возможно, вызывать глобальное потепление. А ее отсутствие может порождать много багов. И вот один из интересных кейсов, на который все не обращают внимание и, при этом, все пользуются этой функциональностью.
Я говорю о попе элементов. Не вот этой ( | ), а вот этом
Эти методы достают из контейнера элементы из зада или из переда соответственно.
"Какие тут проблемы?" - спросите вы.
И я вам отвечу.
Что произойдет, если я вызову эти методы на пустом контейнере? Если вы задумались, то это нормально, обычно такого не происходит. Но вот я такой Маша-растеряша и забыл проверить на пустоту перед вызовом. Будет UB.
Даже не исключение, которое можно обработать. Просто УБ. И можно УБиться в поисках бага, которая появится в следствии пропуска одной проверки.
Понятно, что так или иначе придется городить огород вокруг подобных моментов, когда что-то может пойти не так. Проблема конкретно этого кейса, что из сигнатура метода настолько безобидная, что даже и мысли не возникает, что может что-то не так пойти. А внезапно может прилететь по башке лопатой.
Туда же идут и методы front() и back(). Они дают такое же UB, когда контейнер пуст.
Почему так сложилось? Вопрос сложный.
Но не в этом суть.
Суть в том, что не нужно делать похожий интерфейс у своих классов. Давайте пользователю сразу понять, что в функции может что-то пойти не так и эту ситуацию надо обработать.
Споры о дизайне - горячо любимый всеми процесс. Каждый может решать этот вопрос по-разному.
Даже что-то подобное, на мой взгляд, куда более безопасный дизайн:
А если его еще и аттрибутом nodiscard пометить, будет вообще щикарно(привет фанатам южного парка).
Может это и не лучшее решение для стандартной библиотеки. Вполне представляю, что это все бред и комитет лучше знает.
Но язык С++ никогда не славился своей безопасностью. И если вы можете своими силами обезопасить свой проект - нужно это делать. Даже таким несовершенным образом.
Stay safe. Stay cool.
#cppcore #STL
Обработка ошибок, да и в принципе нежелательных путей развития ситуации, может порождать много споров, боли, баттхерта и, возможно, вызывать глобальное потепление. А ее отсутствие может порождать много багов. И вот один из интересных кейсов, на который все не обращают внимание и, при этом, все пользуются этой функциональностью.
Я говорю о попе элементов. Не вот этой ( | ), а вот этом
void pop_back();
void pop_front();
Эти методы достают из контейнера элементы из зада или из переда соответственно.
"Какие тут проблемы?" - спросите вы.
И я вам отвечу.
Что произойдет, если я вызову эти методы на пустом контейнере? Если вы задумались, то это нормально, обычно такого не происходит. Но вот я такой Маша-растеряша и забыл проверить на пустоту перед вызовом. Будет UB.
Даже не исключение, которое можно обработать. Просто УБ. И можно УБиться в поисках бага, которая появится в следствии пропуска одной проверки.
Понятно, что так или иначе придется городить огород вокруг подобных моментов, когда что-то может пойти не так. Проблема конкретно этого кейса, что из сигнатура метода настолько безобидная, что даже и мысли не возникает, что может что-то не так пойти. А внезапно может прилететь по башке лопатой.
Туда же идут и методы front() и back(). Они дают такое же UB, когда контейнер пуст.
Почему так сложилось? Вопрос сложный.
Но не в этом суть.
Суть в том, что не нужно делать похожий интерфейс у своих классов. Давайте пользователю сразу понять, что в функции может что-то пойти не так и эту ситуацию надо обработать.
Споры о дизайне - горячо любимый всеми процесс. Каждый может решать этот вопрос по-разному.
Даже что-то подобное, на мой взгляд, куда более безопасный дизайн:
bool pop_back() {
if (data_.empty()) {
return false;
}
// remove element
return true;
}А если его еще и аттрибутом nodiscard пометить, будет вообще щикарно(привет фанатам южного парка).
Может это и не лучшее решение для стандартной библиотеки. Вполне представляю, что это все бред и комитет лучше знает.
Но язык С++ никогда не славился своей безопасностью. И если вы можете своими силами обезопасить свой проект - нужно это делать. Даже таким несовершенным образом.
Stay safe. Stay cool.
#cppcore #STL
{kind=link}
9❤🔥20👍7🔥7😁4❤1
Так больше нельзя жить
Все. Нет сил больше игнорировать эту тему.
Слишком часто люди в комментах просят подсказать им материалы для обучения новичкового уровня. И как будто бы все из раза в раз повторяется.
Хватит это терпеть!
Давайте наконец прекратим этот день сурка. Отпишите в комментах под этим постом свой список материалов, по которым вы рекомендуете обучаться новичкам. Книги, курсы, видяшки и тд. Дальше мы систематизируем этот список и выдадим оформленный дайджест. И всех можно будет отправлять на этот сборник.
Прошу активно участвовать в дискуссии. Мы все-таки новое поколение плюсовиков растим. Будущую гордость страны!
Мы вообще программисты или кто? Давайте автоматизируем процесс рекомендации.
Make life easier. Stay cool.
Все. Нет сил больше игнорировать эту тему.
Слишком часто люди в комментах просят подсказать им материалы для обучения новичкового уровня. И как будто бы все из раза в раз повторяется.
Хватит это терпеть!
Давайте наконец прекратим этот день сурка. Отпишите в комментах под этим постом свой список материалов, по которым вы рекомендуете обучаться новичкам. Книги, курсы, видяшки и тд. Дальше мы систематизируем этот список и выдадим оформленный дайджест. И всех можно будет отправлять на этот сборник.
Прошу активно участвовать в дискуссии. Мы все-таки новое поколение плюсовиков растим. Будущую гордость страны!
Мы вообще программисты или кто? Давайте автоматизируем процесс рекомендации.
Make life easier. Stay cool.
{kind=link}
10❤27👍12❤🔥9🔥6
Опасности автоматического вывода типов
#новичкам
C++17 дал нам замечательную фичу CTAD. Это автоматический вывод шаблонных параметров класса по инициализатору.
Теперь, если вы хотите создать например пару строки и числа, то вместо этого:
Можно писать так:
Удобно? Безусловно! Только вот один вопросик есть.
Что будет, если я попытаюсь достать размер строки?
А будет ошибка
Пара-то на самом деле не из строки и числа, а из указателя и числа. Но это и правильно. Компилятор не умеет читать мысли, а четко работает с тем, что ему предоставили. В данном случае "Hello there!" действительно преобразуется в тип const char*. Если вы хотите std::string, то нужно явно показать это компилятору:
При более сложном коде могут возникать такие простыни ошибок компиляции, что без бутылки и не разберешься, что там на самом деле происходит.
Поэтому при использовании CTAD нужно тщательно следить за типами аргументов. Классы с не explicit конструкторами могут наделать большую невкусную кучу беспокойства.
Кстати, знаю адептов строгой типизации, которые даже auto не признают. А как вы относитесь к автоматическому выводу типов? Жду ваши мысли в комментах)
Be careful. Stay cool.
#cppcore #cpp17
#новичкам
C++17 дал нам замечательную фичу CTAD. Это автоматический вывод шаблонных параметров класса по инициализатору.
Теперь, если вы хотите создать например пару строки и числа, то вместо этого:
std::pair<std::string, int> pair{"Hello there!", 1};Можно писать так:
std::pair pair{"Hello there!", 1};Удобно? Безусловно! Только вот один вопросик есть.
Что будет, если я попытаюсь достать размер строки?
size_t size = pair.first.size();
А будет ошибка
error: request for member 'size' in 'a.std::pair<const char*, int>::first',
which is of non-class type 'const char*'
Пара-то на самом деле не из строки и числа, а из указателя и числа. Но это и правильно. Компилятор не умеет читать мысли, а четко работает с тем, что ему предоставили. В данном случае "Hello there!" действительно преобразуется в тип const char*. Если вы хотите std::string, то нужно явно показать это компилятору:
std::pair pair{std::string("Hello there!"), 1};При более сложном коде могут возникать такие простыни ошибок компиляции, что без бутылки и не разберешься, что там на самом деле происходит.
Поэтому при использовании CTAD нужно тщательно следить за типами аргументов. Классы с не explicit конструкторами могут наделать большую невкусную кучу беспокойства.
Кстати, знаю адептов строгой типизации, которые даже auto не признают. А как вы относитесь к автоматическому выводу типов? Жду ваши мысли в комментах)
Be careful. Stay cool.
#cppcore #cpp17
31❤39👍11🔥6❤🔥4
Материалы для обучения
#новичкам
В этом посте вы очень хорошо постарались и накидали много ресурсов. Сейчас мы их немного систематизируем.
Начнем с самого популярного запроса. Книги. Пдфки будут в комментах.
База:
Бьерн Страуструп. "Программирование: принципы и практика использования C++".
Стивен Прата. «Язык программирования C++»
Стенли Липпман. "Язык программирования C++. Базовый курс"
Эндрю Кениг. "Эффективное программирование на С++"
Брайан Керниган. «Язык программирования С»
Немножко компьютер сайенса:
Бхаргава Адитья. "Грокаем алгоритмы".
Кирилл Бобров. "Грокаем конкурентность".
Книжки по продвинутому С++. Накладываются уже на адекватные знания языка и навыки написания кода.
Скотт Майерс. "Эффективный и современный С++"
Бартоломей Филипек. "С++17 в деталях".
Энтони Уильямс. «С++. Практика многопоточного программирования»
Пикус Ф. «Идиомы и паттерны проектирования С++».
Можно еще вот сюда заглянуть. Там еще больше полезных книжек.
Курсы:
Пояса от Яндекса. Платный.
"Добрый, добрый ОПП С++" на Stepik. Совсем недорогой.
1 и 2 части курса программирования на C++ от Computer Science Center на платформе Stepik. Из всех курсов, которые я изучал, это лучший в рунете имхо.
Программирование на языке C++ на Stepik. Бесплатный.
Программирование на языке C++ (продолжение) на Stepik. Бесплатный.
Введение в программирование (C++)курс Яндекса на Stepik. Бесплатный
Базовый курс С++ от Хэкслет. Бесплатный
Бесплатный курс от Яндекса
C++ Tutorial . Бесплатно
Яндекс Практикум «Разработчик С++». Платно.
Ютуб:
Константин Владимиров обо всем
Илья Мещерин С++
Роман Липовский. Конкурентность. Лекции и семинары
TheCherno. Нужен английский.
Simple Code
Интернет ресурсы:
https://ravesli.com/uroki-cpp. Нужен впн
https://www.learncpp.com
https://metanit.com/cpp/tutorial
https://leetcode.com - решение алгоритмических задачек. Примерный список задач, которые спрашивают в Яндексе, да и в других бигтехах: https://postypashki.ru/яндекс/
https://github.com/MattPD/cpplinks/blob/master/learning_teaching.md - сборная солянка обучающих ресурсов
Теперь отсебятина
У всех разная подходящая модель обучения. Не концентрируйтесь только на книгах или курсах. У всего есть свои плюсы. Надо попробовать все и найти подходящий ВАМ формат обучения. Но нужны какие-то начальные рекомендации. Я бы начал с одной из базовых книг и обязательно после каждой главы решал бы задачки(это самое главное, иначе не запомнится). "Чтобы научиться программированию, необходимо писать программы" - Брайан Керниган. Поэтому чуть освоившись с языком я бы пошел на какие-нибудь курсы из списка и просто начал бы писать код. Пройдите 3-4 из них и вы уже будете довольно хороши.
Дальше уже можете на эту базу наваливать и лекции, и специфику, и прочее.
Не обязательно делать именно так. Обучайтесь так, чтобы вам было интересно. Читайте те книги, которые вам по кайфу читать. Не любите читать книги? Пользуйтесь интернет ресурсами и ютуб уроками.
Но обязательно нужно писать свой пет-проект. Без навыков написания кода, который решает чью-то конкретную жизненную задачу - никуда. Вот там вы хлебнете сполна, протестируете полученные знания и будете остро нуждаться в новых. Как выбрать пет-проект - вопрос не для этого поста, поэтому оставляю его за кадром.
Заслуженно помещаем этот пост в закреп. Теперь можно отправлять всех на него.
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Upgrade yourself. Stay cool.
#digest
#новичкам
В этом посте вы очень хорошо постарались и накидали много ресурсов. Сейчас мы их немного систематизируем.
Начнем с самого популярного запроса. Книги. Пдфки будут в комментах.
База:
Бьерн Страуструп. "Программирование: принципы и практика использования C++".
Стивен Прата. «Язык программирования C++»
Стенли Липпман. "Язык программирования C++. Базовый курс"
Эндрю Кениг. "Эффективное программирование на С++"
Брайан Керниган. «Язык программирования С»
Немножко компьютер сайенса:
Бхаргава Адитья. "Грокаем алгоритмы".
Кирилл Бобров. "Грокаем конкурентность".
Книжки по продвинутому С++. Накладываются уже на адекватные знания языка и навыки написания кода.
Скотт Майерс. "Эффективный и современный С++"
Бартоломей Филипек. "С++17 в деталях".
Энтони Уильямс. «С++. Практика многопоточного программирования»
Пикус Ф. «Идиомы и паттерны проектирования С++».
Можно еще вот сюда заглянуть. Там еще больше полезных книжек.
Курсы:
Пояса от Яндекса. Платный.
"Добрый, добрый ОПП С++" на Stepik. Совсем недорогой.
1 и 2 части курса программирования на C++ от Computer Science Center на платформе Stepik. Из всех курсов, которые я изучал, это лучший в рунете имхо.
Программирование на языке C++ на Stepik. Бесплатный.
Программирование на языке C++ (продолжение) на Stepik. Бесплатный.
Введение в программирование (C++)курс Яндекса на Stepik. Бесплатный
Базовый курс С++ от Хэкслет. Бесплатный
Бесплатный курс от Яндекса
C++ Tutorial . Бесплатно
Яндекс Практикум «Разработчик С++». Платно.
Ютуб:
Константин Владимиров обо всем
Илья Мещерин С++
Роман Липовский. Конкурентность. Лекции и семинары
TheCherno. Нужен английский.
Simple Code
Интернет ресурсы:
https://ravesli.com/uroki-cpp. Нужен впн
https://www.learncpp.com
https://metanit.com/cpp/tutorial
https://leetcode.com - решение алгоритмических задачек. Примерный список задач, которые спрашивают в Яндексе, да и в других бигтехах: https://postypashki.ru/яндекс/
https://github.com/MattPD/cpplinks/blob/master/learning_teaching.md - сборная солянка обучающих ресурсов
Теперь отсебятина
У всех разная подходящая модель обучения. Не концентрируйтесь только на книгах или курсах. У всего есть свои плюсы. Надо попробовать все и найти подходящий ВАМ формат обучения. Но нужны какие-то начальные рекомендации. Я бы начал с одной из базовых книг и обязательно после каждой главы решал бы задачки(это самое главное, иначе не запомнится). "Чтобы научиться программированию, необходимо писать программы" - Брайан Керниган. Поэтому чуть освоившись с языком я бы пошел на какие-нибудь курсы из списка и просто начал бы писать код. Пройдите 3-4 из них и вы уже будете довольно хороши.
Дальше уже можете на эту базу наваливать и лекции, и специфику, и прочее.
Не обязательно делать именно так. Обучайтесь так, чтобы вам было интересно. Читайте те книги, которые вам по кайфу читать. Не любите читать книги? Пользуйтесь интернет ресурсами и ютуб уроками.
Но обязательно нужно писать свой пет-проект. Без навыков написания кода, который решает чью-то конкретную жизненную задачу - никуда. Вот там вы хлебнете сполна, протестируете полученные знания и будете остро нуждаться в новых. Как выбрать пет-проект - вопрос не для этого поста, поэтому оставляю его за кадром.
Заслуженно помещаем этот пост в закреп. Теперь можно отправлять всех на него.
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Upgrade yourself. Stay cool.
#digest
Ravesli
Уроки по С++ для начинающих / Ravesli
Здесь представлены более 240 бесплатных уроков, где с нуля рассматриваются основы и тонкости языка С++ и программирования в целом. Есть пошаговые создания игр на С++ с помощью библиотек MFC и SFML, и более 70 практических заданий для проверки ваших навыков…
31❤56🔥18👍13❤🔥9😢1
Квиз
#новичкам
Сегодня простенький #quiz на повтор материала. Настолько простенький, что может показаться очевидным. Но не дайте себя обмануть, хорошенько обдумайте и правильно ответьте. Ответ выложу вечером.
У меня к вам всего один вопрос. Что будет в результате попытки компиляции и запуска этого кода?
#новичкам
Сегодня простенький #quiz на повтор материала. Настолько простенький, что может показаться очевидным. Но не дайте себя обмануть, хорошенько обдумайте и правильно ответьте. Ответ выложу вечером.
У меня к вам всего один вопрос. Что будет в результате попытки компиляции и запуска этого кода?
#include <iostream>
int id;
int main()
{
std::cout << id;
}
❤18🔥6👍4
Результат попытки компиляции и запуска?
Anonymous Poll
16%
Ошибка компиляции
45%
Выведется 0
1%
Выведется 42
18%
Неопределенное поведение, остальное - домыслы
26%
Выведется рандомное число
👍11❤🔥3😱3
Ответ
Для начала - код полностью валидный и успешно соберется. Нехватка ретурна никак не мешает.
Дальше. Весь прикол тут в том, что id - глобальная переменная. Действительно, если бы она была локальной переменной main:
то было бы использование неинициализированной переменной, неопределенное поведение и на экран вывелся бы мусор.
Однако id - глобальная переменная. К ним применяются немного другие правила.
Дело в том, что все глобальные переменные инициализируются перед main. Вопрос только в том, как они это делают.
В данном случае, так как нет явного инициализатора, происходит так называемая zero-инициализация. И id будет равно 0.
Итого. На экране появится "0".
Stay defined. Stay cool.
#cppcore
Для начала - код полностью валидный и успешно соберется. Нехватка ретурна никак не мешает.
If control reaches the end of main without encountering a return statement, the effect is that of executing return 0
Дальше. Весь прикол тут в том, что id - глобальная переменная. Действительно, если бы она была локальной переменной main:
int main()
{
int id;
std::cout << id;
}
то было бы использование неинициализированной переменной, неопределенное поведение и на экран вывелся бы мусор.
Однако id - глобальная переменная. К ним применяются немного другие правила.
Дело в том, что все глобальные переменные инициализируются перед main. Вопрос только в том, как они это делают.
В данном случае, так как нет явного инициализатора, происходит так называемая zero-инициализация. И id будет равно 0.
Итого. На экране появится "0".
Stay defined. Stay cool.
#cppcore
👏72👍35🔥8❤6
Разница инициализаций
После вчерашнего поста у некоторых читателей мог возникнуть резонный вопрос. Почему глобальные переменные инициализируются автоматически, а локальные - нет? Не легче ли было установить какое-то одно правило для всех?
Единые правила - хорошая вещь. И как многие хорошие вещи, они чего-то стоят. А в С++ есть такой девиз: "мы не платим за то, что не используем". Мне не всегда нужно задавать значение переменной. Иногда меня это вообще не интересует. Я могу создать неинициализированную переменную и передать ее в функцию, где ей присвоится конкретное значение.
Чтобы ответить на вопрос из начала поста, давайте посмотрим, чем мы вообще платим за инициализацию в обоих случаях.
Рассмотрим локальные переменные.
В сущности, они являются просто набором байт на текущем фрейме стека. И программа интерпретирует эти байты, как наши локальные переменные.
Чтобы инициализировать локальную переменную, нужно положить нолик в каждый байтик, который ассоциирован с этой переменной. И так нужно делать каждый раз при каждом вызове функции. Итого стоимость инициализации: немножко кода на зануление памяти при каждом входе в скоуп переменной.
Теперь глобальные переменные
Они инициализируются всего один раз при старте программы. Соответственно, стоимость - немножко кода 1 раз при старте программы.
Причем обычно, когда мы говорим про какие-то затраты и перфоманс, мы говорим о времени, когда программа уже делает полезную работу. То есть инициализация глобальных переменных проходит в "бесплатное" с точки зрения производительности время.
Итого мы получаем, что предварительная установка значений глобальных переменных проходит для нас фактически бесплатно, а для локальных переменных мы тратимся на каждый вход в скоуп переменной.
Теперь представьте, что мы бы потребовали устанавливать валидное значение всегда. Это просто неэффективно. Да и не нужно.
Кстати, на самом деле zero-инициализация глобальных переменных может обходится нам действительно бесплатно. И никаких кавычек! Но об этом в следующем посте.
Be effective. Stay cool.
#cppcore #compiler
После вчерашнего поста у некоторых читателей мог возникнуть резонный вопрос. Почему глобальные переменные инициализируются автоматически, а локальные - нет? Не легче ли было установить какое-то одно правило для всех?
Единые правила - хорошая вещь. И как многие хорошие вещи, они чего-то стоят. А в С++ есть такой девиз: "мы не платим за то, что не используем". Мне не всегда нужно задавать значение переменной. Иногда меня это вообще не интересует. Я могу создать неинициализированную переменную и передать ее в функцию, где ей присвоится конкретное значение.
int i;
FillUpVariable(i);
Чтобы ответить на вопрос из начала поста, давайте посмотрим, чем мы вообще платим за инициализацию в обоих случаях.
Рассмотрим локальные переменные.
В сущности, они являются просто набором байт на текущем фрейме стека. И программа интерпретирует эти байты, как наши локальные переменные.
Чтобы инициализировать локальную переменную, нужно положить нолик в каждый байтик, который ассоциирован с этой переменной. И так нужно делать каждый раз при каждом вызове функции. Итого стоимость инициализации: немножко кода на зануление памяти при каждом входе в скоуп переменной.
Теперь глобальные переменные
Они инициализируются всего один раз при старте программы. Соответственно, стоимость - немножко кода 1 раз при старте программы.
Причем обычно, когда мы говорим про какие-то затраты и перфоманс, мы говорим о времени, когда программа уже делает полезную работу. То есть инициализация глобальных переменных проходит в "бесплатное" с точки зрения производительности время.
Итого мы получаем, что предварительная установка значений глобальных переменных проходит для нас фактически бесплатно, а для локальных переменных мы тратимся на каждый вход в скоуп переменной.
Теперь представьте, что мы бы потребовали устанавливать валидное значение всегда. Это просто неэффективно. Да и не нужно.
Кстати, на самом деле zero-инициализация глобальных переменных может обходится нам действительно бесплатно. И никаких кавычек! Но об этом в следующем посте.
Be effective. Stay cool.
#cppcore #compiler
{kind=link}
👍65🔥11❤5⚡1
Бесплатная zero-инициализация
Вчера я сказал, что иногда в самой программе может попросту отсутствовать код по занулению неинициализированных глобальных переменных. Сегодня разберем, за счет чего это может достигаться.
Во время старта программы ей необходимо выделить память под такие вещи, как стек, кучу, код самой программы и глобальные переменные. Память программе предоставляет операционная система. Ну и естественно, что в эту память раньше была записана какая-то информация. Вообще говоря, потенциально конфиденциальная. То есть раньше был какой-то процесс, который писал информацию в память, завершился, и теперь ее отдают другому процессу.
И что получается, наш новорожденный процесс может видеть какую-то конфиденциальную информацию? Это же большая уязвимость.
Может ли операционная система опираться на честность человека, написавшего код, или на компилятор, что кто-то из них останется приличным парнем и сам занулит всю выданную программе память? В большинстве случаев может. Но здесь очень важны исключения, которых быть не должно.
Поэтому ОС никому не доверяет и сама зануляет всю память, которую выдает новому процессу.
Компилятор/линкер при формировании бинарника собирает все неинициализированные переменные вместе в одну секцию с названием .bss.
Получается, при старте программы у ОС запрашивается память в том числе под секцию .bss, и эта память уже аллоцируется зануленной! И никакого кода не нужно, за нас все делает операционка.
Важное уточнение, что такое поведение наблюдается не у всех операционок. Да, все эти ваши винды, линуксы и прочие макоси зануляют память перед ее передачей другому процессу. Но для каких-нибудь микроконтроллеров это может быть неактуально и компилятор должен честно вставить код зануления для того, чтобы соблюсти требования стандарта.
В чате последние пару дней были бурные обсуждения того, что этого зануления может и не быть. Ну как бы, может и не быть. Только тогда компилятор будет противоречить стандарту. И пользоваться им можно на свой страх и риск.
Don't reveal secrets. Stay cool.
#OS #compiler #cppcore
Вчера я сказал, что иногда в самой программе может попросту отсутствовать код по занулению неинициализированных глобальных переменных. Сегодня разберем, за счет чего это может достигаться.
Во время старта программы ей необходимо выделить память под такие вещи, как стек, кучу, код самой программы и глобальные переменные. Память программе предоставляет операционная система. Ну и естественно, что в эту память раньше была записана какая-то информация. Вообще говоря, потенциально конфиденциальная. То есть раньше был какой-то процесс, который писал информацию в память, завершился, и теперь ее отдают другому процессу.
И что получается, наш новорожденный процесс может видеть какую-то конфиденциальную информацию? Это же большая уязвимость.
Может ли операционная система опираться на честность человека, написавшего код, или на компилятор, что кто-то из них останется приличным парнем и сам занулит всю выданную программе память? В большинстве случаев может. Но здесь очень важны исключения, которых быть не должно.
Поэтому ОС никому не доверяет и сама зануляет всю память, которую выдает новому процессу.
Компилятор/линкер при формировании бинарника собирает все неинициализированные переменные вместе в одну секцию с названием .bss.
Получается, при старте программы у ОС запрашивается память в том числе под секцию .bss, и эта память уже аллоцируется зануленной! И никакого кода не нужно, за нас все делает операционка.
Важное уточнение, что такое поведение наблюдается не у всех операционок. Да, все эти ваши винды, линуксы и прочие макоси зануляют память перед ее передачей другому процессу. Но для каких-нибудь микроконтроллеров это может быть неактуально и компилятор должен честно вставить код зануления для того, чтобы соблюсти требования стандарта.
В чате последние пару дней были бурные обсуждения того, что этого зануления может и не быть. Ну как бы, может и не быть. Только тогда компилятор будет противоречить стандарту. И пользоваться им можно на свой страх и риск.
Don't reveal secrets. Stay cool.
#OS #compiler #cppcore
{kind=link}
🔥45👍19❤12❤🔥2😁1
Почему тогда локальные переменные не зануляются?
Вчера мы разобрали, что когда операционка выдает процессу память, она ее зануляет. Тогда получается, что сегмент глобальных данных автоматически заполнен нулями.
Но возникает вопрос: раз ОС такая молодец и зануляет всю память, то почему локальные переменные и куча заполнены мусором? Какие-то двойные стандарты.
Все на самом деле немножко сложнее.
Есть такое понятие, как "zero-fill on demand". Заполнение нулями по требованию.
Когда процесс запрашивает память под свои сегменты, стек и кучу, ОС на самом деле не дает ему реальные страницы памяти. А дает "виртуальные". То есть ничего не аллоцирует по факту. Такие страницы заполнены нулями.
Процесс может свободно читать эти страницы и будет действительно видеть там нули. Однако это не будет физической памятью. Как только процесс захочет что-то записать в нее, только тогда операционка разрождается, реально аллоцирует физическую страницу и копирует в нее содержимое той виртуальной страницы. То есть заполняет физическую нулями.
И так она делает один раз на каждую физическую страницу.
Вот как появляются нули в реальной памяти. Теперь почему они не остаются навсегда.
Дело в том, что процесс переиспользует свою память. Программа в течение всей своей жизни использует один и тот же стек и кучу.
Мы выделили маллоком массив байт, попользовали его и освободили. И эта память не вернулась операционке. Процесс может ее переиспользовать. Да, изначально, при попытке записи в эти байты, ОС выдавала зануленные страницы. Но после того, как мы ими попользовались, там уже лежат наши данные. И с точки зрения куска программы, которая в следующий раз получит эту память, там уже лежит "мусор". Но это просто данные из предыдущей аллокации.
Также и локальные переменные. Мы выполнили одну функцию, вернулись обратно, и выполняя следующую функцию, мы будем переиспользовать память стека под локальные переменные.
Именно поэтому кстати, мы можем очень легко получить доступ к данным, которые лежали на стеке ранее:
Возможный вывод такого кода:
Обратите внимание, что, вызывая функцию с переменной uninitialize в первый раз, мы получили мусор. Однако после вызова func1, где переменная инициализирована, в памяти стека на месте, где лежала initialize будет лежать число 10. Так как сигнатуры и содержимое функций в целом идентичны, то uninitialize во второй раз будет располагаться на том же самом месте, где и была переменная initialize. Соответственно, она будет содержать то же значение.
А учитывая, что до пользовательского кода выполняется некий "скрытый код", то даже в "начале" программы вы будете видеть на стеке мусор.
Reuse resources. Stay cool.
#OS #compiler
Вчера мы разобрали, что когда операционка выдает процессу память, она ее зануляет. Тогда получается, что сегмент глобальных данных автоматически заполнен нулями.
Но возникает вопрос: раз ОС такая молодец и зануляет всю память, то почему локальные переменные и куча заполнены мусором? Какие-то двойные стандарты.
Все на самом деле немножко сложнее.
Есть такое понятие, как "zero-fill on demand". Заполнение нулями по требованию.
Когда процесс запрашивает память под свои сегменты, стек и кучу, ОС на самом деле не дает ему реальные страницы памяти. А дает "виртуальные". То есть ничего не аллоцирует по факту. Такие страницы заполнены нулями.
Процесс может свободно читать эти страницы и будет действительно видеть там нули. Однако это не будет физической памятью. Как только процесс захочет что-то записать в нее, только тогда операционка разрождается, реально аллоцирует физическую страницу и копирует в нее содержимое той виртуальной страницы. То есть заполняет физическую нулями.
И так она делает один раз на каждую физическую страницу.
Вот как появляются нули в реальной памяти. Теперь почему они не остаются навсегда.
Дело в том, что процесс переиспользует свою память. Программа в течение всей своей жизни использует один и тот же стек и кучу.
Мы выделили маллоком массив байт, попользовали его и освободили. И эта память не вернулась операционке. Процесс может ее переиспользовать. Да, изначально, при попытке записи в эти байты, ОС выдавала зануленные страницы. Но после того, как мы ими попользовались, там уже лежат наши данные. И с точки зрения куска программы, которая в следующий раз получит эту память, там уже лежит "мусор". Но это просто данные из предыдущей аллокации.
Также и локальные переменные. Мы выполнили одну функцию, вернулись обратно, и выполняя следующую функцию, мы будем переиспользовать память стека под локальные переменные.
Именно поэтому кстати, мы можем очень легко получить доступ к данным, которые лежали на стеке ранее:
void fun1() {
int initialize = 10;
std::cout << initialize << std::endl;
}
void fun2() {
int uninitialize;
std::cout << uninitialize << std::endl;
}
int main() {
fun2();
fun1();
fun2();
}Возможный вывод такого кода:
32760
10
10
Обратите внимание, что, вызывая функцию с переменной uninitialize в первый раз, мы получили мусор. Однако после вызова func1, где переменная инициализирована, в памяти стека на месте, где лежала initialize будет лежать число 10. Так как сигнатуры и содержимое функций в целом идентичны, то uninitialize во второй раз будет располагаться на том же самом месте, где и была переменная initialize. Соответственно, она будет содержать то же значение.
А учитывая, что до пользовательского кода выполняется некий "скрытый код", то даже в "начале" программы вы будете видеть на стеке мусор.
Reuse resources. Stay cool.
#OS #compiler
{kind=link}
👍54❤🔥28🔥15❤4⚡3👎1
Программа без main?
Все мы знаем, что функция main - входная точка в программу. С нее начинается исполнение программы, если не считать глобальные переменные.
Без функции main программа просто не запустится.
Или нет?
Может быть мы можем что-нибудь нахимичить, чтобы, например, написать Hello, World без main?
Оказывается, можем. Однако, естественно, это все непереносимо. Но она на то и магия, что у разных магов свои заклинания.
Скомпилируем вот такую программу под gcc с флагом -nostartfiles:
И на консоли появится наша горячо-любимая надпись:
Для любителей поиграться с кодом вот вам ссылочка на годболт.
А вот что за такая функция _start и какой все-таки код выполняется до main, мы поговорим в следующий раз.
Make impossible things. Stay cool.
#fun #cppcore
Все мы знаем, что функция main - входная точка в программу. С нее начинается исполнение программы, если не считать глобальные переменные.
Без функции main программа просто не запустится.
Или нет?
Может быть мы можем что-нибудь нахимичить, чтобы, например, написать Hello, World без main?
Оказывается, можем. Однако, естественно, это все непереносимо. Но она на то и магия, что у разных магов свои заклинания.
Скомпилируем вот такую программу под gcc с флагом -nostartfiles:
#include <iostream>
int my_fun();
void _start()
{
int x = my_fun();
exit(x);
}
int my_fun()
{
std::cout << "Hello, World!\n";
return 0;
}
И на консоли появится наша горячо-любимая надпись:
Hello, World!Для любителей поиграться с кодом вот вам ссылочка на годболт.
А вот что за такая функция _start и какой все-таки код выполняется до main, мы поговорим в следующий раз.
Make impossible things. Stay cool.
#fun #cppcore
{kind=link}
🔥50👍19😁8❤🔥5❤4👎1
std::cout
Кажется, что на начальном этапе становления про-с++-ером, вывод в использование конструкции:
воспринимается, как "штука, которая выводит текст на консоль".
Даже со временем картинка не до конца складывается и на вопрос "что такое std::cout?", многие плывут. Сегодня закроем этот вопрос.
В этой строчке мы вызываем такой оператор:
Получается, что std::cout - объект класса std::ostream. И ни какой-то там временный. Раз он принимается по левой ссылке, значит он уже где-то хранится в памяти.
Но мы же ничего не делаем для его создания? Откуда он взялся?
Мы говорили о том, что есть "невидимые" для нас вещи, которые происходят при старте программы. Так вот, это одна из таких вещей.
std::cout - глобальный объект типа std::ostream. За его создание отвечает класс std::ios_base::Init, инстанс которого явно или неявно определяется в библиотеке <iostream>.
Но это все слова. И новичкам будет достаточно этого. Но мы тут глубоко закапываемся, поэтому давайте закопаемся в код.
Полазаем по исходникам gcc. Ссылочки кликабельные для пытливых умов.
А в хэдэре iostream мы можем найти вот это:
Здесь определяются символы стандартных потоков и создается глобальная переменная класса ios_base::Init. Пойдемте тогда в конструктор:
Немножко разберем происходящее.
В условии проверяется ref_count, чтобы предотвратить повторную инициализацию. Так как не предполагается, что такие объекты, как cout будут удалены, они просто создаются через placement new с помощью инстансов stdio_sync_filebuf<char>. Это внутренний буфер для объектов потоков, который ассоциирован с "файлами" stdout, stdin, stderr. Буферы как раз и предназначены для получения/записи io данных.
Хорошо. Мы видим как и где создаются объекты. Но это же placement new. Для объектов уже должная быть подготовлена память для их размещения. Где же она?
В файлике globals_io.cc:
то есть, объекты - это пустые символьные массивы правильного размера и выравнивания.
Все это должно вам дать довольно полное представление, что такое стандартные потоки ввода-вывода.
#cppcore #compiler
Кажется, что на начальном этапе становления про-с++-ером, вывод в использование конструкции:
std::cout << "Print something in consol\n";
воспринимается, как "штука, которая выводит текст на консоль".
Даже со временем картинка не до конца складывается и на вопрос "что такое std::cout?", многие плывут. Сегодня закроем этот вопрос.
В этой строчке мы вызываем такой оператор:
std::ostream& operator<< (std::ostream& stream, const char * str)
Получается, что std::cout - объект класса std::ostream. И ни какой-то там временный. Раз он принимается по левой ссылке, значит он уже где-то хранится в памяти.
Но мы же ничего не делаем для его создания? Откуда он взялся?
Мы говорили о том, что есть "невидимые" для нас вещи, которые происходят при старте программы. Так вот, это одна из таких вещей.
std::cout - глобальный объект типа std::ostream. За его создание отвечает класс std::ios_base::Init, инстанс которого явно или неявно определяется в библиотеке <iostream>.
Но это все слова. И новичкам будет достаточно этого. Но мы тут глубоко закапываемся, поэтому давайте закопаемся в код.
Полазаем по исходникам gcc. Ссылочки кликабельные для пытливых умов.
А в хэдэре iostream мы можем найти вот это:
extern istream cin; ///< Linked to standard input
extern ostream cout; ///< Linked to standard output
extern ostream cerr; ///< Linked to standard error (unbuffered)
extern ostream clog; ///< Linked to standard error (buffered)
...
static ios_base::Init __ioinit;
Здесь определяются символы стандартных потоков и создается глобальная переменная класса ios_base::Init. Пойдемте тогда в конструктор:
ios_base::Init::Init()
{
if (__gnu_cxx::__exchange_and_add_dispatch(&_S_refcount, 1) == 0)
{
// Standard streams default to synced with "C" operations.
_S_synced_with_stdio = true;
new (&buf_cout_sync) stdio_sync_filebuf<char>(stdout);
new (&buf_cin_sync) stdio_sync_filebuf<char>(stdin);
new (&buf_cerr_sync) stdio_sync_filebuf<char>(stderr);
// The standard streams are constructed once only and never
// destroyed.
new (&cout) ostream(&buf_cout_sync);
new (&cin) istream(&buf_cin_sync);
new (&cerr) ostream(&buf_cerr_sync);
new (&clog) ostream(&buf_cerr_sync);
cin.tie(&cout);
cerr.setf(ios_base::unitbuf);
// _GLIBCXX_RESOLVE_LIB_DEFECTS
// 455. cerr::tie() and wcerr::tie() are overspecified.
cerr.tie(&cout);
...
__gnu_cxx::__atomic_add_dispatch(&_S_refcount, 1);
Немножко разберем происходящее.
В условии проверяется ref_count, чтобы предотвратить повторную инициализацию. Так как не предполагается, что такие объекты, как cout будут удалены, они просто создаются через placement new с помощью инстансов stdio_sync_filebuf<char>. Это внутренний буфер для объектов потоков, который ассоциирован с "файлами" stdout, stdin, stderr. Буферы как раз и предназначены для получения/записи io данных.
Хорошо. Мы видим как и где создаются объекты. Но это же placement new. Для объектов уже должная быть подготовлена память для их размещения. Где же она?
В файлике globals_io.cc:
// Standard stream objects.
// NB: Iff <iostream> is included, these definitions become wonky.
typedef char fake_istream[sizeof(istream)]
attribute ((aligned(alignof(istream))));
typedef char fake_ostream[sizeof(ostream)]
attribute ((aligned(alignof(ostream))));
fake_istream cin;
fake_ostream cout;
fake_ostream cerr;
fake_ostream clog;
то есть, объекты - это пустые символьные массивы правильного размера и выравнивания.
Все это должно вам дать довольно полное представление, что такое стандартные потоки ввода-вывода.
#cppcore #compiler
{kind=link}
👍61🔥17❤12🤯6
Линкуем массивы к объектам
Опытные читатели могли заметить кое-что странное в этом посте. И заметили кстати. Изначально cin, cout и тд определены, как простые массивы. А в iostream они уже становятся объектами потоков и линкуются как онные. То есть в одной единице трансляции
А в другой
Что за приколы такие? Почему массивы нормально линкуются на объекты кастомных классов?
В С++ кстати запрещены такие фокусы. Типы объявления и определения сущности должны совпадать.
Все потому что линкер особо не заботится о типах, выравнивании и даже особо о размерах объектов. То есть я буквально могу прилинковать объект одного кастомного класса к другому и мне никто никакого предупреждения не влепит. Такой код вполне нормально компилится и запускается:
На консоли появится "1 2". Но ни типы, ни размеры типов, ни выравнивания у объектов из объявления и определения не совпадают. Поэтому здесь явное UB.
Но в исходниках GCC так удачно сложилось, что массивы реально представляют собой идеальные сосуды для объектов io-потоков. На них даже сконструировали реальные объекты. Поэтому такие массивы можно интерпретировать как сами объекты.
Это, естественно, все непереносимо. Но поговорка "спички детям - не игрушка" подходит только для тех, кто плохо понимает, что делает. А разработчики компилятора явно не из этих ребят.
Take conscious risks. Stay cool.
#cppcore #compiler
Опытные читатели могли заметить кое-что странное в этом посте. И заметили кстати. Изначально cin, cout и тд определены, как простые массивы. А в iostream они уже становятся объектами потоков и линкуются как онные. То есть в одной единице трансляции
extern std::ostream cout;
extern std::istream cin;
...
А в другой
// Standard stream objects.
// NB: Iff <iostream> is included, these definitions become wonky.
typedef char fake_istream[sizeof(istream)]
attribute ((aligned(alignof(istream))));
typedef char fake_ostream[sizeof(ostream)]
attribute ((aligned(alignof(ostream))));
fake_istream cin;
fake_ostream cout;
fake_ostream cerr;
fake_ostream clog;
Что за приколы такие? Почему массивы нормально линкуются на объекты кастомных классов?
В С++ кстати запрещены такие фокусы. Типы объявления и определения сущности должны совпадать.
Все потому что линкер особо не заботится о типах, выравнивании и даже особо о размерах объектов. То есть я буквально могу прилинковать объект одного кастомного класса к другому и мне никто никакого предупреждения не влепит. Такой код вполне нормально компилится и запускается:
// header.hpp
#pragma once
struct TwoFields {
int a;
int b;
};
struct ThreeFields {
char a;
int b;
long long c;
};
// source.cpp
ThreeFields test = {1, 2, 3};
// main.cpp
#include <iostream>
#include "header.hpp"
extern TwoFields test;
int main() {
std::cout << test.a << " " << test.b << std::endl;
}
На консоли появится "1 2". Но ни типы, ни размеры типов, ни выравнивания у объектов из объявления и определения не совпадают. Поэтому здесь явное UB.
Но в исходниках GCC так удачно сложилось, что массивы реально представляют собой идеальные сосуды для объектов io-потоков. На них даже сконструировали реальные объекты. Поэтому такие массивы можно интерпретировать как сами объекты.
Это, естественно, все непереносимо. Но поговорка "спички детям - не игрушка" подходит только для тех, кто плохо понимает, что делает. А разработчики компилятора явно не из этих ребят.
Take conscious risks. Stay cool.
#cppcore #compiler
{kind=link}
🔥47🤯10❤🔥4👍4❤2
Квиз
Вчера в комментах наш подписчик @d7d1cd задал очень интересную задачку, которой мне захотелось с вами поделиться. Да, кто-то уже ее обсудил, но тем, кто не участвовал в дискуссии, тоже будет интересно проверить свои знания в #quiz.
Как всегда это бывает с плюсами, задачка не простая и сходу вгоняет в ступор. Но без паники! Вдох, выдохи мы опять играем в любимых, успокоили разум, подумали и ответили.
Подписчику спасибо за контент, а у меня для вас всего один вопрос. Как правильно вызвать конструктор у такого класса?
Challenge your knowledge. Stay cool.
Вчера в комментах наш подписчик @d7d1cd задал очень интересную задачку, которой мне захотелось с вами поделиться. Да, кто-то уже ее обсудил, но тем, кто не участвовал в дискуссии, тоже будет интересно проверить свои знания в #quiz.
Как всегда это бывает с плюсами, задачка не простая и сходу вгоняет в ступор. Но без паники! Вдох, выдох
Подписчику спасибо за контент, а у меня для вас всего один вопрос. Как правильно вызвать конструктор у такого класса?
struct Type {
template <typename>
Type() {}
};Challenge your knowledge. Stay cool.
😍16🔥6❤4👍4👀3👎1
Как правильно вызвать конструктор у такого класса?
Anonymous Poll
13%
Type obj;
10%
auto obj = Type{};
20%
Type<int> obj{};
11%
Type<> obj{};
9%
Я пытался, у меня не получилось. Значит, это невозможно!
16%
Type::Type<int> obj{};
7%
Type::Type<> obj{};
13%
auto obj = Type::Type<>{};
30%
Может я и не знаю ответа, зато мне мама говорит, что я красивый!
❤14👍6❤🔥2