Универсальная инициализация и непростые пути инициализации векторов
Живете вы себе такой спокойно, хотите по фану создать массив на 10 элементов. И пишите:
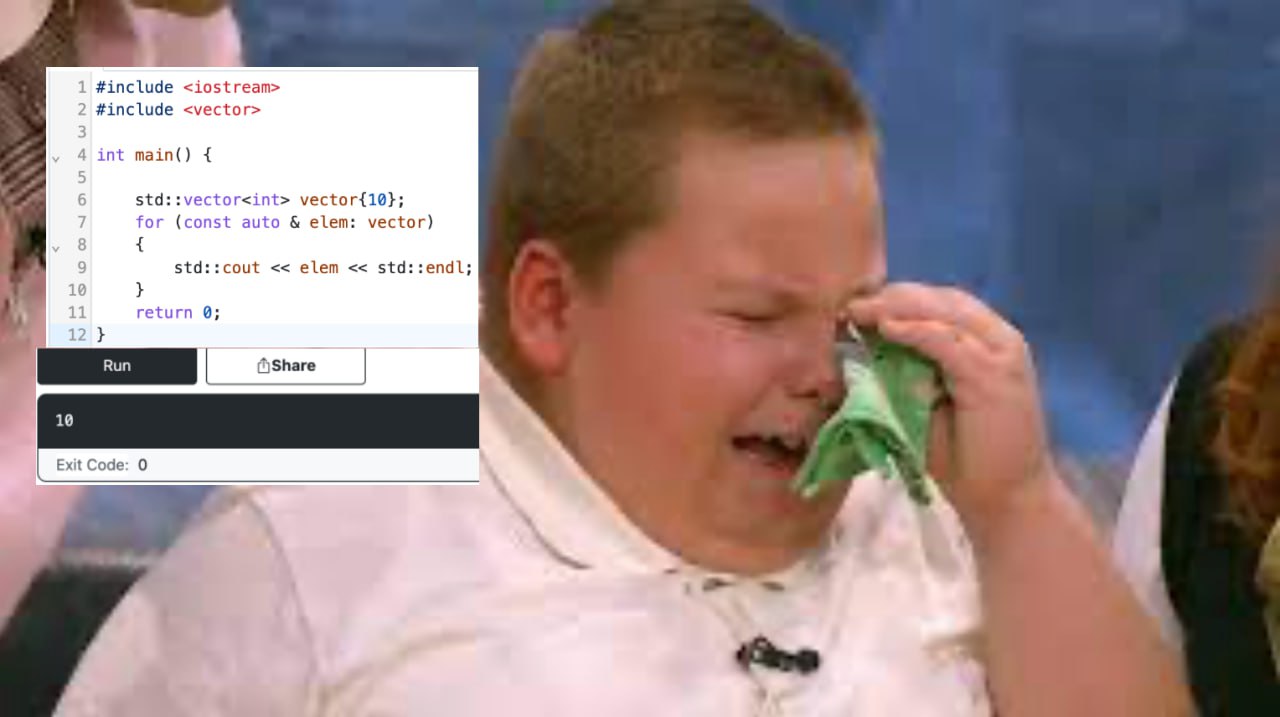
std::vector<int> vector{10};
Запустив свой код, вы нихера не понимаете, че происходит. Поведение совершенно не такое, какое ожидалось при запуске. Проверяете все части программы, все в порядке. И доходите до того, что у вас в векторе не 10 элементов, а всего 1. WTF?! Щас разберемся.
Универсальная инициализация, представленная в C++11, позволяет нам инициализировать объекты, используя один набор фигурных скобок {}. Это безопасный и удобный способ инициализации различных типов. Не буду перечислять причин удобства, можете поверить на слово. Однако, когда дело доходит до инициализации векторов, возникает несколько препятствий.
На самом деле, не только векторов. А всех классов с конструкторами от std::initializer_list. Дело в том, что эта перегрузка затемняет все другие конструкторы класса. То есть, если вы определили такой конструктор и вы используете универсальную инициализацию, то компилятор всегда будет предполагать, что вы хотите вызвать именно конструктор от std::initializer_list. Даже если другие перегрузки будут иметь намного больший смысл. В основном эта проблема касается именно числовых типов. Но после С++17, когда мы можем опускать шаблонный параметр вектора, проблема заиграла новыми красками.
Что же с этим делать?
Универсального способа, конечно, нет. В разных командах существуют разные гайдлайны, как решать проблему. Приведу несколько общих правил, которые помогут не попадаться в ловушку:
Если вы намеренно используете список инициализации в качестве параметра конструктора, то можно явно его создавать, используя explicit конструктор. Типа того:
std::vector<int> myVector{std::initializer_list<int>{1, 2, 3}};. Это никогда не создаст семантическую путаницу.
Для инициализации объектов классов с помощью обычных аргументов используйте круглые скобки. Это предотвратит интерпретацию компилятором параметров как списка инициализации и поспособствует вызову нужных конструкторов.
Проектируйте свои классы, чтобы этой путаницы не происходило. Мы не можем повлиять на код стандартной библиотеки. Но можем в своих проектах придерживаться порядка и однозначности.
Stay well-designed. Stay cool.
#cpp11 #design #STL
Живете вы себе такой спокойно, хотите по фану создать массив на 10 элементов. И пишите:
std::vector<int> vector{10};
Запустив свой код, вы нихера не понимаете, че происходит. Поведение совершенно не такое, какое ожидалось при запуске. Проверяете все части программы, все в порядке. И доходите до того, что у вас в векторе не 10 элементов, а всего 1. WTF?! Щас разберемся.
Универсальная инициализация, представленная в C++11, позволяет нам инициализировать объекты, используя один набор фигурных скобок {}. Это безопасный и удобный способ инициализации различных типов. Не буду перечислять причин удобства, можете поверить на слово. Однако, когда дело доходит до инициализации векторов, возникает несколько препятствий.
На самом деле, не только векторов. А всех классов с конструкторами от std::initializer_list. Дело в том, что эта перегрузка затемняет все другие конструкторы класса. То есть, если вы определили такой конструктор и вы используете универсальную инициализацию, то компилятор всегда будет предполагать, что вы хотите вызвать именно конструктор от std::initializer_list. Даже если другие перегрузки будут иметь намного больший смысл. В основном эта проблема касается именно числовых типов. Но после С++17, когда мы можем опускать шаблонный параметр вектора, проблема заиграла новыми красками.
Что же с этим делать?
Универсального способа, конечно, нет. В разных командах существуют разные гайдлайны, как решать проблему. Приведу несколько общих правил, которые помогут не попадаться в ловушку:
Если вы намеренно используете список инициализации в качестве параметра конструктора, то можно явно его создавать, используя explicit конструктор. Типа того:
std::vector<int> myVector{std::initializer_list<int>{1, 2, 3}};. Это никогда не создаст семантическую путаницу.
Для инициализации объектов классов с помощью обычных аргументов используйте круглые скобки. Это предотвратит интерпретацию компилятором параметров как списка инициализации и поспособствует вызову нужных конструкторов.
Проектируйте свои классы, чтобы этой путаницы не происходило. Мы не можем повлиять на код стандартной библиотеки. Но можем в своих проектах придерживаться порядка и однозначности.
Stay well-designed. Stay cool.
#cpp11 #design #STL
{kind=link}
Как использовать RAII с сишным API
Все мы с вами используем сишный API. Базы данных, работа с сетью, криптография. Перечислять области можно долго. И все мы с вами немного недолюбливаем такой способ взаимодействия с сущностями. Оно и понятно. Не зря умные дяди придумывали объектно-ориентированное программирование и не зря мы, не такие умные дяди, стараемся этой методологии следовать. А тут нужны какие-то сырые указатели, байтовые буфферы и прочие вульгарности. Это не только неудобно, но может приводить к трудноотловимым ошибкам, недостаточной гарантии безопасности. Старшие ребята, естественно, знают, как правильно использовать плюсовые объекты в таких случаях, а вот молодняк может не знать этого или не осознавать подходов, которые они использовали. Поэтому поделюсь своей интерпретацией адекватного подхода, который поможет грамотно использовать RAII с сишным апи.
На помощь нам неожиданно приходят std::array и std::vector. Это простые RAII обертки над статическими и динамическими массивами, которые предлагают следующие фичи:
1️⃣ Автоматическое управление памятью. std::array в конструкторе аллоцирует память на стеке, std::vector - на куче. Их деструктор вызывается при выходе из скоупа.
2️⃣ Детерминированная инициализация. Инициализация этих контейнеров происходи в конструкторе, что предотвращает обращение к неинициализированной памяти.
3️⃣ Безопасный и удобный доступ к элементам с помощью методов .at(), .back(), .front() и итераторов.
4️⃣ Легкий доступ к буферу через метод .data().
Как их использовать для взаимодействия с С API? Гениально и просто.
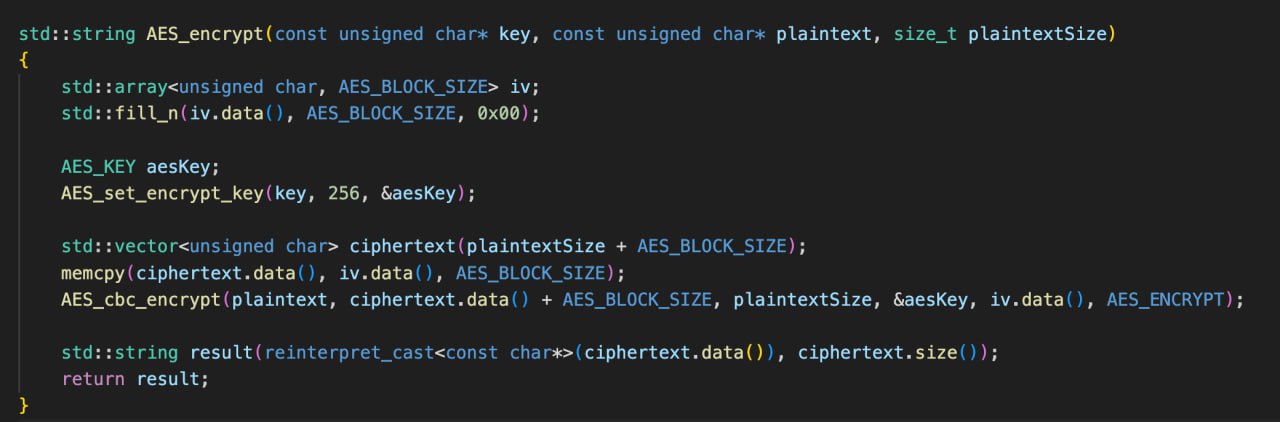
👉🏿 Объявить нужный массив. Если размер структуры известен на момент компиляции - std::array, если нет - std::vector. Инициализировать его в конструкторе нужными значениями: дефолтовыми - в конструкторе, кастомными - через memcpy(array_ptr, struct_ptr, struct_size).
👉🏿 Передать в Сишный апи. Например так:
AES_cbc_encrypt(plaintext_array.data, ciphertext_array.size(), plaintext_array.size() ...);
👉🏿 Наслаждаться жизнью, ибо больше вам не нужно ни о чем беспокоиться.
Если уж вы передаете в С API более сложные структуры, чем массивы, то вам могут понадобиться методы сериализации и десериализации.
Используя возможности RAII массивов вы можете упростить и оптимизировать свой код, гарантировать правильное управление памятью и безопасную передачу данных в С API.
Делитесь своим опытом взаимодействия с API C и используйте modern C++ для более надежного и эффективного кода.
Stay cool.
#goodoldc #design #cppcore #STL
Все мы с вами используем сишный API. Базы данных, работа с сетью, криптография. Перечислять области можно долго. И все мы с вами немного недолюбливаем такой способ взаимодействия с сущностями. Оно и понятно. Не зря умные дяди придумывали объектно-ориентированное программирование и не зря мы, не такие умные дяди, стараемся этой методологии следовать. А тут нужны какие-то сырые указатели, байтовые буфферы и прочие вульгарности. Это не только неудобно, но может приводить к трудноотловимым ошибкам, недостаточной гарантии безопасности. Старшие ребята, естественно, знают, как правильно использовать плюсовые объекты в таких случаях, а вот молодняк может не знать этого или не осознавать подходов, которые они использовали. Поэтому поделюсь своей интерпретацией адекватного подхода, который поможет грамотно использовать RAII с сишным апи.
На помощь нам неожиданно приходят std::array и std::vector. Это простые RAII обертки над статическими и динамическими массивами, которые предлагают следующие фичи:
1️⃣ Автоматическое управление памятью. std::array в конструкторе аллоцирует память на стеке, std::vector - на куче. Их деструктор вызывается при выходе из скоупа.
2️⃣ Детерминированная инициализация. Инициализация этих контейнеров происходи в конструкторе, что предотвращает обращение к неинициализированной памяти.
3️⃣ Безопасный и удобный доступ к элементам с помощью методов .at(), .back(), .front() и итераторов.
4️⃣ Легкий доступ к буферу через метод .data().
Как их использовать для взаимодействия с С API? Гениально и просто.
👉🏿 Объявить нужный массив. Если размер структуры известен на момент компиляции - std::array, если нет - std::vector. Инициализировать его в конструкторе нужными значениями: дефолтовыми - в конструкторе, кастомными - через memcpy(array_ptr, struct_ptr, struct_size).
👉🏿 Передать в Сишный апи. Например так:
AES_cbc_encrypt(plaintext_array.data, ciphertext_array.size(), plaintext_array.size() ...);
👉🏿 Наслаждаться жизнью, ибо больше вам не нужно ни о чем беспокоиться.
Если уж вы передаете в С API более сложные структуры, чем массивы, то вам могут понадобиться методы сериализации и десериализации.
Используя возможности RAII массивов вы можете упростить и оптимизировать свой код, гарантировать правильное управление памятью и безопасную передачу данных в С API.
Делитесь своим опытом взаимодействия с API C и используйте modern C++ для более надежного и эффективного кода.
Stay cool.
#goodoldc #design #cppcore #STL
{kind=link}
Перенос элементов между ассоциативными контейнерами
Пост для тех, кто много работает с древовидными структурами данных. Таких среди нас, думаю, немного. Но мне кажется фишка интересная. Слышали когда-нибудь об одной изящной функции, представленной в C++17, которая значительно облегчила нам жизнь при работе с ассоциативными контейнерами? Я говорю о методе extract, который как бы вырезает ноду из внутренней структуры контейнера и помещает его наружу, в специальный хэндлер node_type, не дергая конструкторы класса.
Что было до С++17
В эпоху до C++17 перемещение или перенос узлов между ассоциативными контейнерами было обременительной задачей. Представьте, что у вас есть узел в одном std::map или std::set, и вы хотите переместить его в другой контейнер. Вам приходилось вручную выполнять операцию копирования/перемещения объекта во временный объект, удаления этой ноды из одной мапы и вставки в другую копированием/перемещением . Это было не очень красиво эстетически, нельзя было трансферрить объекты, у которых не было конструкторов копирования и перемещения. Ну и конечно были совершенно лишние вызовы конструкторов.
Splicing в C++17
С появлением C++17 нам была предоставлена возможность для так называемого «сращивания». Вот как это работает:
👉🏿std::map::extract() и std::set::extract()
Эти новые функции-члены позволяют вам извлекать узел из std::map или std::set и возвращать его как «извлеченный» узел типа node_type. Эта операция эффективно отвязывает узел от исходного контейнера и внутри этого узла объект остаётся нетронутым. Никаких вызовов конструкторов объекта!
👉🏿std::map::insert() и std::set::insert()
Имея извлеченный узел на руках, вы теперь можете легко вставить его в другой std::map или std::set, используя метод insert(). Перенесенный узел будет легко интегрирован в новый контейнер без необходимости вовлечения конструкторов.
И все! Такой приём можно провернуть с любыми видами упорядоченных и неупорядоченных ассоциативных контейнеров. И да, это все ещё может вызывать перебалансировку дерева. Куда же без этого.
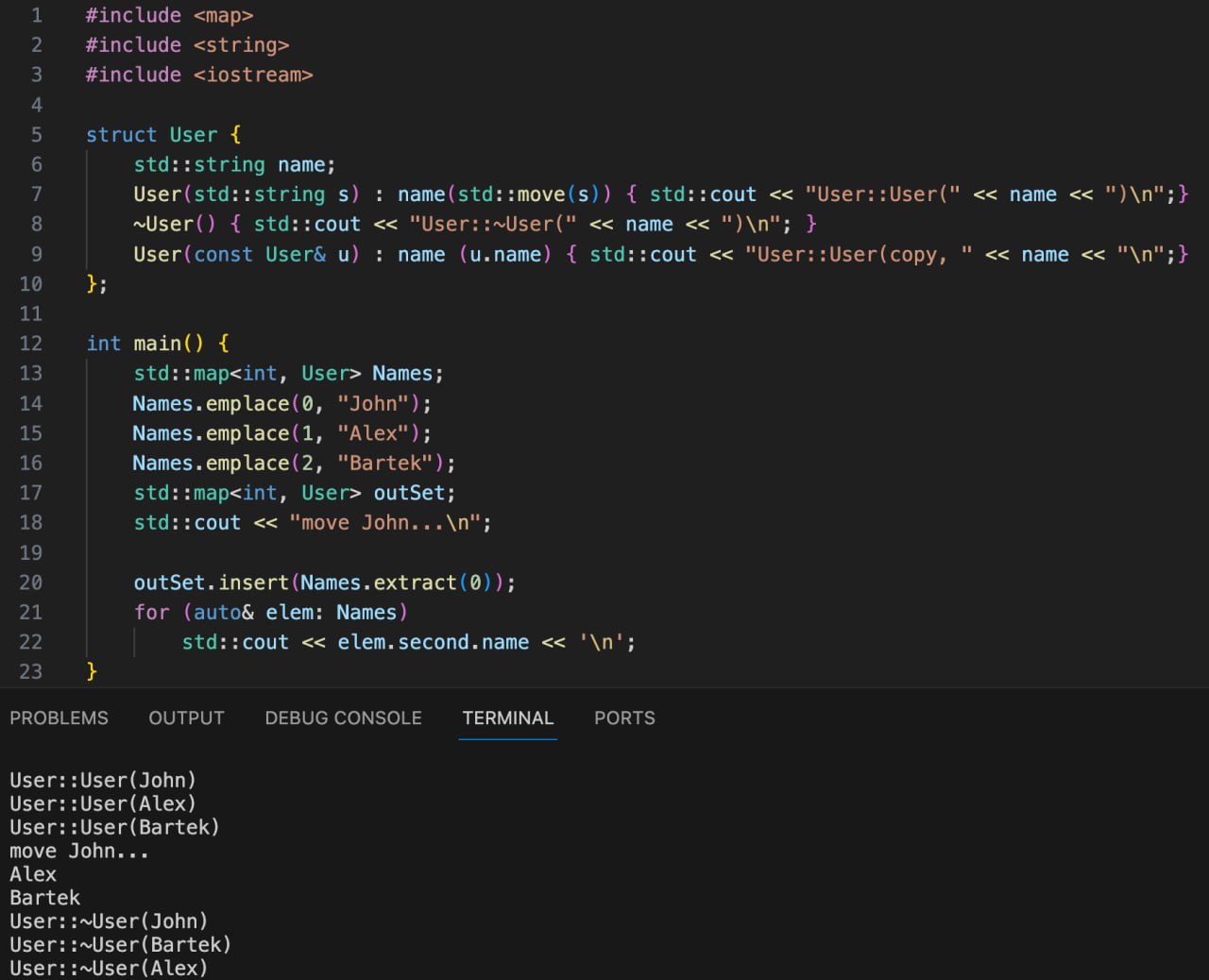
На картинке можете увидеть, как теперь за одну строчку перенести элемент из одной мапы в другую и при этом конструкторы и деструкторы вызываются только по одному разу. Я считаю это сильно.
Короче говоря, C++17 в целом значительно облегчил нам жизнь. Эта фича не геймченджер, но очень приятное нововведение, которое позитивно сказалось на качестве кода и его производительности.
Stay updated. Stay cool.
#cpp17 #datastructures #STL
Пост для тех, кто много работает с древовидными структурами данных. Таких среди нас, думаю, немного. Но мне кажется фишка интересная. Слышали когда-нибудь об одной изящной функции, представленной в C++17, которая значительно облегчила нам жизнь при работе с ассоциативными контейнерами? Я говорю о методе extract, который как бы вырезает ноду из внутренней структуры контейнера и помещает его наружу, в специальный хэндлер node_type, не дергая конструкторы класса.
Что было до С++17
В эпоху до C++17 перемещение или перенос узлов между ассоциативными контейнерами было обременительной задачей. Представьте, что у вас есть узел в одном std::map или std::set, и вы хотите переместить его в другой контейнер. Вам приходилось вручную выполнять операцию копирования/перемещения объекта во временный объект, удаления этой ноды из одной мапы и вставки в другую копированием/перемещением . Это было не очень красиво эстетически, нельзя было трансферрить объекты, у которых не было конструкторов копирования и перемещения. Ну и конечно были совершенно лишние вызовы конструкторов.
Splicing в C++17
С появлением C++17 нам была предоставлена возможность для так называемого «сращивания». Вот как это работает:
👉🏿std::map::extract() и std::set::extract()
Эти новые функции-члены позволяют вам извлекать узел из std::map или std::set и возвращать его как «извлеченный» узел типа node_type. Эта операция эффективно отвязывает узел от исходного контейнера и внутри этого узла объект остаётся нетронутым. Никаких вызовов конструкторов объекта!
👉🏿std::map::insert() и std::set::insert()
Имея извлеченный узел на руках, вы теперь можете легко вставить его в другой std::map или std::set, используя метод insert(). Перенесенный узел будет легко интегрирован в новый контейнер без необходимости вовлечения конструкторов.
И все! Такой приём можно провернуть с любыми видами упорядоченных и неупорядоченных ассоциативных контейнеров. И да, это все ещё может вызывать перебалансировку дерева. Куда же без этого.
На картинке можете увидеть, как теперь за одну строчку перенести элемент из одной мапы в другую и при этом конструкторы и деструкторы вызываются только по одному разу. Я считаю это сильно.
Короче говоря, C++17 в целом значительно облегчил нам жизнь. Эта фича не геймченджер, но очень приятное нововведение, которое позитивно сказалось на качестве кода и его производительности.
Stay updated. Stay cool.
#cpp17 #datastructures #STL
{kind=link}
Remove-erase идиома
Удаление элементов из вектора - вещь не совсем тривиальная. Безусловно, в STL есть интерфейс для этого, бери да вызывай. Проблема в том, что удаление вызывает копирование всех элементов вектора, которые находятся правее от удаляемого элемента. То есть, в среднем, сложность удаления одного элемента контейнера будет линейной. А сложность очистки всего контейнера - квадратичная. Это все очень печальные результаты. И хоть для последовательности упорядоченных элементов нет стандартного алгоритма удаления из середины, для вектора, в котором порядок неважен, такой алгоритм есть.
Нам нужно лишь свопнуть удаляемый элемент с последним элементом в векторе и очистить последнюю с конца ячейку. Таким образом, удаление будет занимать всего 2 действия, а значит сложность этой операции - константная. Звучит намного лучше.
А что, если нужно отфильтровать массив по какому-то критерию? Ну удалить все ячейки, которые обладают какими-то характеристиками. Например, из массива удалить все числа, кратные 5. Надо тогда в цикле проделать действия из предыдущего абзаца и все будет пучком.
Однако, есть ощущение, что это задача слишком общая и хотелось бы иметь для нее какое-то более элегантное решение, чем каждый раз писать цикл. Можно конечно объявить функцию, но все-таки хочется чего-то стандартного.
И такое есть. В плюсах это называется remove-erase idiom. Идиома удаления-очистки. Какой у меня прекрасный английский)
Решение хоть и стандартное, но не прям очень элегантное. Ну а что вы хотели? Это плюсы все-таки.
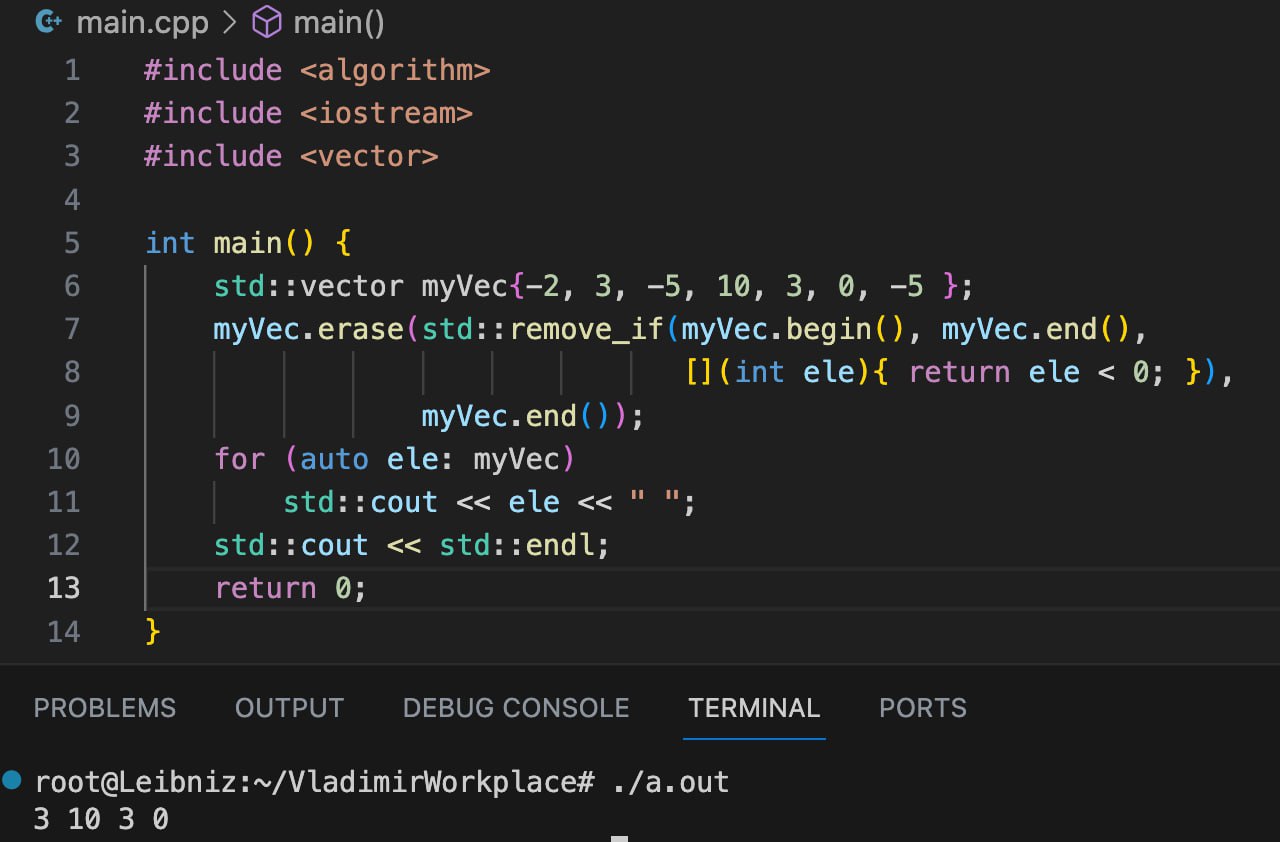
Судя по названию, надо просто скомбинировать стандартный алгоритм std::remove (или std::remove_if) и метод вектора std::vector::erase.
На картинке снизу можете увидеть, как конкретно эта комбинация решает задачу удаления элементов.
Stay cool.
#algorithms #STL #datastructures
Удаление элементов из вектора - вещь не совсем тривиальная. Безусловно, в STL есть интерфейс для этого, бери да вызывай. Проблема в том, что удаление вызывает копирование всех элементов вектора, которые находятся правее от удаляемого элемента. То есть, в среднем, сложность удаления одного элемента контейнера будет линейной. А сложность очистки всего контейнера - квадратичная. Это все очень печальные результаты. И хоть для последовательности упорядоченных элементов нет стандартного алгоритма удаления из середины, для вектора, в котором порядок неважен, такой алгоритм есть.
Нам нужно лишь свопнуть удаляемый элемент с последним элементом в векторе и очистить последнюю с конца ячейку. Таким образом, удаление будет занимать всего 2 действия, а значит сложность этой операции - константная. Звучит намного лучше.
А что, если нужно отфильтровать массив по какому-то критерию? Ну удалить все ячейки, которые обладают какими-то характеристиками. Например, из массива удалить все числа, кратные 5. Надо тогда в цикле проделать действия из предыдущего абзаца и все будет пучком.
Однако, есть ощущение, что это задача слишком общая и хотелось бы иметь для нее какое-то более элегантное решение, чем каждый раз писать цикл. Можно конечно объявить функцию, но все-таки хочется чего-то стандартного.
И такое есть. В плюсах это называется remove-erase idiom. Идиома удаления-очистки. Какой у меня прекрасный английский)
Решение хоть и стандартное, но не прям очень элегантное. Ну а что вы хотели? Это плюсы все-таки.
Судя по названию, надо просто скомбинировать стандартный алгоритм std::remove (или std::remove_if) и метод вектора std::vector::erase.
На картинке снизу можете увидеть, как конкретно эта комбинация решает задачу удаления элементов.
Stay cool.
#algorithms #STL #datastructures
{kind=link}
std::span
Все мы любим С++ за способность работать как на высоком уровне, так и на низком уровне абстракции. Ну ладно, за это не любим. За это ценим. Довольно много проблем зашито в самом языке из-за этой особенности, однако плюсы перевешивают(какой каламбур получился неожиданный). Одна из таких проблем - поддержка высокоуровневых контейнеров и низкоуровневых сишных массивов. Проектируя обобщенный код, нам нужно учитывать, что пользователь хотел бы оперировать и контейнерами, и массивами, при работе с этим кодом. Однако это не всегда удается сделать красиво, да и комон, какие сишные массивы? 2к23 наконец. Хочется писать в терминах С++, объектно-ориентированной модели и все такое. Однако с недавних пор у нас появился инструмент, который может нам помочь.
Я говорю в std::span.
template<class T, std::size_t Extent = std::dynamic_extent>
class span;
Этот шаблонный класс, который введен в С++20. Он описывает объекты, являющиеся ссылкой на непрерывную последовательность объектов. В чем фишка этой фичи?
1️⃣ Первое. Она позволяет единообразно работать с динамическими контейнерами и со статическими массивами. Для статических последовательностей в конструктор передается указатель на первый элемент и количество элементов в массиве. Тогда типичная реализация будет содержать только указатель на первый элемент последовательности, и количество элементов будет содержаться в самом типе. А если передать в конструктор контейнер, то объект будет содержать 2 поля - указатель и размер последовательности.
2️⃣ Второе. Это по сути вьюха на существующий контейнер или массив, которая позволяет работать с ними целиком и даже с подпоследовательностями без передачи владения и главное без копирования. Мы можем проектировать свои апи так, чтобы пользователь был уверен, что ничего плохого не случится с его массивом в функции. Это повышает безопасность кода. А отсутствие копирования открывает нам двери к адекватным легковесным слайсам в с++. Метод subspan предоставляет интерфейс слайсинга. Теперь для задания отрезка массива необходимы просто 2 числа. Как во всех нормальных языках.
Фича на самом деле рабочая. Даже в кор гайдлайнах код написан с использованием std::span. Там не советуют его использовать. А просто используют его в листингах. Как бы предполагая, что все про это знают и это стандартный способ написания кода. А это уже о многом говорит.
Stay updated. Stay cool.
#cpp20 #STL
Все мы любим С++ за способность работать как на высоком уровне, так и на низком уровне абстракции. Ну ладно, за это не любим. За это ценим. Довольно много проблем зашито в самом языке из-за этой особенности, однако плюсы перевешивают(какой каламбур получился неожиданный). Одна из таких проблем - поддержка высокоуровневых контейнеров и низкоуровневых сишных массивов. Проектируя обобщенный код, нам нужно учитывать, что пользователь хотел бы оперировать и контейнерами, и массивами, при работе с этим кодом. Однако это не всегда удается сделать красиво, да и комон, какие сишные массивы? 2к23 наконец. Хочется писать в терминах С++, объектно-ориентированной модели и все такое. Однако с недавних пор у нас появился инструмент, который может нам помочь.
Я говорю в std::span.
template<class T, std::size_t Extent = std::dynamic_extent>
class span;
Этот шаблонный класс, который введен в С++20. Он описывает объекты, являющиеся ссылкой на непрерывную последовательность объектов. В чем фишка этой фичи?
1️⃣ Первое. Она позволяет единообразно работать с динамическими контейнерами и со статическими массивами. Для статических последовательностей в конструктор передается указатель на первый элемент и количество элементов в массиве. Тогда типичная реализация будет содержать только указатель на первый элемент последовательности, и количество элементов будет содержаться в самом типе. А если передать в конструктор контейнер, то объект будет содержать 2 поля - указатель и размер последовательности.
2️⃣ Второе. Это по сути вьюха на существующий контейнер или массив, которая позволяет работать с ними целиком и даже с подпоследовательностями без передачи владения и главное без копирования. Мы можем проектировать свои апи так, чтобы пользователь был уверен, что ничего плохого не случится с его массивом в функции. Это повышает безопасность кода. А отсутствие копирования открывает нам двери к адекватным легковесным слайсам в с++. Метод subspan предоставляет интерфейс слайсинга. Теперь для задания отрезка массива необходимы просто 2 числа. Как во всех нормальных языках.
Фича на самом деле рабочая. Даже в кор гайдлайнах код написан с использованием std::span. Там не советуют его использовать. А просто используют его в листингах. Как бы предполагая, что все про это знают и это стандартный способ написания кода. А это уже о многом говорит.
Stay updated. Stay cool.
#cpp20 #STL
{kind=link}
std::make_unique
В комментах под этим постом, @Zolderix предложил рассказать про плюсы-минусы использования std::make_unique и std::make_shared. Темы клевые, да и умные указатели, судя по всему, вам заходят. Но будем делать все по порядку и поэтому сегодня говорим про std::make_unique.
Нет ни одной ситуации, где я бы предпочел создать объект через new вместо того, чтобы воспользоваться какой-нибудь RAII оберткой, будь то smart pointer или, например, std::array. Бывает апи говно и по-другому просто нельзя. Но чтобы намеренно делать это - неа. Но и даже при работе с умными указателями, их можно создать с помощью сырого поинтера, возвращенного new. Нужно ли так делать или лучше воспользоваться специальными функциями?
Мне кажется, что в целом идея умных указателей - снять с разработчиков ответственность за работу с памятью(потому что они ее не вывозят) и семантически разграничить разные по предназначению виды указателей. И, как мне кажется, функции std:make_... делают большой вклад именно в полной снятии ответственности. Я большой фанат отказа от явного вызова new и delete. Со вторым умные указатели и сами хорошо справляются, а вот с первым сильно помогают их функции-фабрики. Программист в идеале должен один раз сказать: "создать объект", объект создастся и программист просто забудет о том, что за этим объектом надо следить. Уверен, что большую часть компонентов систем можно и нужно строить без упоминания операторов new и delete вообще. И если с delete все и так ясно, то ограничение использования new может привести к улучшению безопасности и читаемости кода.
Это было особенно актуально до С++17, когда гарантии для порядка вычисления выражений были довольно слабые. Использование new, даже в комбинации с умным указателем, в качестве аргумента функции могло привести к утечкам памяти. Об этом более подробно я рассказывал в этом посте. А введение std::make_unique в С++14 полностью решило это проблему! Эта функция дает базовую гарантию безопасности исключений и, даже в случае их появлений, никакие ресурсы не утекут. Уверен, что какие-то проекты до сих не апнулись до 17 версии по разным причинам, поэтому для них это будет особенно актуально. Но гарантии исключений std::make_unique остаются прежними для всех существующих версий плюсов. Поэтому, кажется, что сердцу будет все равно спокойнее при ее использовании. У меня каждый раз повышается алертность, когда я вижу new. А какой цикл жизни у объекта? А что с исключениями? Оно того не стоит.
Также std::make_unique улучшает читаемость кода. И на этом есть 2 причины.
Первая - она лучше выражает намерение. На канале мы много об этом говорим. Эта функция доносит в понятной человеку языковой форме, что сейчас идет создание объекта. Я считаю использование фабрик - хорошей идеей именно поэтому. Хотя ничего и не меняется, и в конструктор и фабрику мы передаем одни и те же аргументы. Но вот это человеческое сообщение "make" "create" воспринимается в несколько раз лучше, чем просто имя класса.
Вторая - вы избегаете повторения кода. Чтобы создать unique_ptr через new нужно написать что-то такое:
std::unique_ptr<VeryLongAndClearNameLikeItShouldBeType> ptr{ new VeryLongAndClearNameLikeItShouldBeType(...) };
И сравните во с этим:
auto ptr = std::make_unique<VeryLongAndClearNameLikeItShouldBeType>(...);
В полтора раза короче и намного приятнее на вид.
Еще std::make_unique разделят типы Т и Т[]. Здесь вы обязаны явно специфицировать шаблон с подходящим типом, иначе вы просто создадите не массив, а объект. Функция сделает так, чтобы при выходе из скоупа обязательно вызовется подходящий оператор delete или delete[]. А вот если работать с непосредственно с конструктором std::unique_ptr, то вот такая строчка
std::unique_ptr<int> ptr(new int[5]);
хоть и компилируется, но приводит к UB.
Надеюсь, я убедил вас, что это действительно крутая фича. Пост уже получился довольно длинный, а я еще хотел впихнуть сюда недостатки. Но видимо придется разбить на 2 части. Поэтому
Stay in touch. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
В комментах под этим постом, @Zolderix предложил рассказать про плюсы-минусы использования std::make_unique и std::make_shared. Темы клевые, да и умные указатели, судя по всему, вам заходят. Но будем делать все по порядку и поэтому сегодня говорим про std::make_unique.
Нет ни одной ситуации, где я бы предпочел создать объект через new вместо того, чтобы воспользоваться какой-нибудь RAII оберткой, будь то smart pointer или, например, std::array. Бывает апи говно и по-другому просто нельзя. Но чтобы намеренно делать это - неа. Но и даже при работе с умными указателями, их можно создать с помощью сырого поинтера, возвращенного new. Нужно ли так делать или лучше воспользоваться специальными функциями?
Мне кажется, что в целом идея умных указателей - снять с разработчиков ответственность за работу с памятью(потому что они ее не вывозят) и семантически разграничить разные по предназначению виды указателей. И, как мне кажется, функции std:make_... делают большой вклад именно в полной снятии ответственности. Я большой фанат отказа от явного вызова new и delete. Со вторым умные указатели и сами хорошо справляются, а вот с первым сильно помогают их функции-фабрики. Программист в идеале должен один раз сказать: "создать объект", объект создастся и программист просто забудет о том, что за этим объектом надо следить. Уверен, что большую часть компонентов систем можно и нужно строить без упоминания операторов new и delete вообще. И если с delete все и так ясно, то ограничение использования new может привести к улучшению безопасности и читаемости кода.
Это было особенно актуально до С++17, когда гарантии для порядка вычисления выражений были довольно слабые. Использование new, даже в комбинации с умным указателем, в качестве аргумента функции могло привести к утечкам памяти. Об этом более подробно я рассказывал в этом посте. А введение std::make_unique в С++14 полностью решило это проблему! Эта функция дает базовую гарантию безопасности исключений и, даже в случае их появлений, никакие ресурсы не утекут. Уверен, что какие-то проекты до сих не апнулись до 17 версии по разным причинам, поэтому для них это будет особенно актуально. Но гарантии исключений std::make_unique остаются прежними для всех существующих версий плюсов. Поэтому, кажется, что сердцу будет все равно спокойнее при ее использовании. У меня каждый раз повышается алертность, когда я вижу new. А какой цикл жизни у объекта? А что с исключениями? Оно того не стоит.
Также std::make_unique улучшает читаемость кода. И на этом есть 2 причины.
Первая - она лучше выражает намерение. На канале мы много об этом говорим. Эта функция доносит в понятной человеку языковой форме, что сейчас идет создание объекта. Я считаю использование фабрик - хорошей идеей именно поэтому. Хотя ничего и не меняется, и в конструктор и фабрику мы передаем одни и те же аргументы. Но вот это человеческое сообщение "make" "create" воспринимается в несколько раз лучше, чем просто имя класса.
Вторая - вы избегаете повторения кода. Чтобы создать unique_ptr через new нужно написать что-то такое:
std::unique_ptr<VeryLongAndClearNameLikeItShouldBeType> ptr{ new VeryLongAndClearNameLikeItShouldBeType(...) };
И сравните во с этим:
auto ptr = std::make_unique<VeryLongAndClearNameLikeItShouldBeType>(...);
В полтора раза короче и намного приятнее на вид.
Еще std::make_unique разделят типы Т и Т[]. Здесь вы обязаны явно специфицировать шаблон с подходящим типом, иначе вы просто создадите не массив, а объект. Функция сделает так, чтобы при выходе из скоупа обязательно вызовется подходящий оператор delete или delete[]. А вот если работать с непосредственно с конструктором std::unique_ptr, то вот такая строчка
std::unique_ptr<int> ptr(new int[5]);
хоть и компилируется, но приводит к UB.
Надеюсь, я убедил вас, что это действительно крутая фича. Пост уже получился довольно длинный, а я еще хотел впихнуть сюда недостатки. Но видимо придется разбить на 2 части. Поэтому
Stay in touch. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
std::make_unique. Part 2
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
std::make_shared
Недавно тут и тут мы поговорили про плюсы и минусы использования std::make_unique. Настала очередь его братишки std::make_shared.
Базового все pros and cons с предыдущих постов справедливы и для сегодняшнего разбора. Поэтому не будем на этом долго останавливаться.
Но шаренный указатель немного сложнее внутри устроен, чем уникальный. От этого идут и уникальные преимущества и недостатки. А связаны они вот с чем. Посмотрите на эту строчку:
std::shared_ptr<T>(new T(...));
Сколько раз память аллоцируется в результате выполнения этой строчки?
Многие скажут 1. А люди, знающие внутреннее устройство шареного уккзателя, скажут 2. И будут правы.
Первая аллокация, очевидно, происходит в new. А вот где вторая?
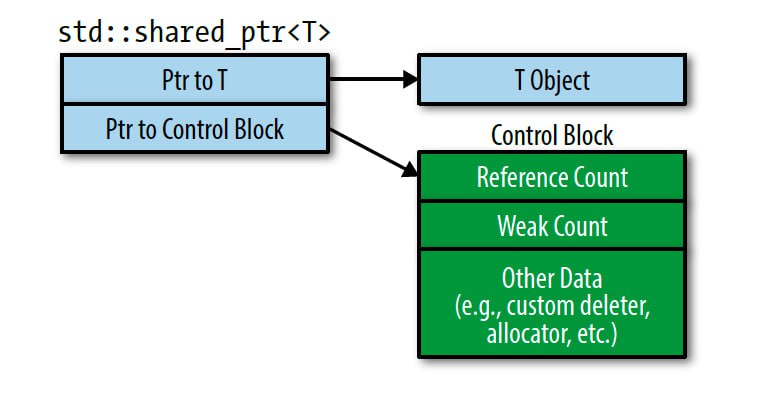
На выделении памяти для, так называемого, control block'а. Это внутренняя структура, которая хранит счетчики ссылок и еще пару приколюх. Она нужна для того, чтобы вести учет существующих объектов указателя, указывающих на данный объект. Естественно, эта структура должна быть общей для всех таких объектов. Поэтому в каждом объекте указателя хранится сырой указатель на этот самый контрол блок. То есть базово в классе std::shared_ptr 2 поля: указатель на объект и указатель на контрол блок. Ну и приняв указатель на объект, конструктор указателя дополнитель выделяет память для этого блока.
Чем в этом контексте отличается поведение std::make_shared?
Она вызывает всего одну аллокацию. Как? выделяет просто один блок памяти, который может содержать сразу и создаваемый объект, и control block, и кладет эти данные вместе. Это уменьшает статический размер программы, потому что код содержит всего 1 вызов аллокатора. И увеличивает скорость выполнения кода, потому что аллокация - довольно дорогостоящий вызов.
Перформанс - это уже серьезный аргумент отдать свое предпочтение в пользу make функции.
Однако эта фича ведет к одной проблеме. Для кого-то она совсем не проблемная, но об этом надо знать.
Дело в том, что может создаться такая ситуация, когда ни одного shared_pointer уже не существует, а память, выделенная для объекта и блока, все еще не отдана системе. Как такое может быть? Слабые ссылки.
Контрол блок помимо счетчика сильных ссылок(собственно сами shared_ptr'ы) хранит еще и счетчик слабых ссылок - для weak_ptr'ов. А деструктор control block'а и деаллокация памяти происходят только после того, как оба счетчика зануляться. Поэтому, если у вас есть хоть один висящий std::weak_ptr, то у вашего объекта хоть и будет вызван деструктор, но память так и не будет возвращена системе.
При создании больших объектов и при обильном использовании слабых ссылок это действительно может создавать проблему.
А если у вас не этот случай - смело используйте std::make_shared()
Stay efficient. Stay cool.
#cpp17 #cpp17 #STL #optimization #memory
Недавно тут и тут мы поговорили про плюсы и минусы использования std::make_unique. Настала очередь его братишки std::make_shared.
Базового все pros and cons с предыдущих постов справедливы и для сегодняшнего разбора. Поэтому не будем на этом долго останавливаться.
Но шаренный указатель немного сложнее внутри устроен, чем уникальный. От этого идут и уникальные преимущества и недостатки. А связаны они вот с чем. Посмотрите на эту строчку:
std::shared_ptr<T>(new T(...));
Сколько раз память аллоцируется в результате выполнения этой строчки?
Многие скажут 1. А люди, знающие внутреннее устройство шареного уккзателя, скажут 2. И будут правы.
Первая аллокация, очевидно, происходит в new. А вот где вторая?
На выделении памяти для, так называемого, control block'а. Это внутренняя структура, которая хранит счетчики ссылок и еще пару приколюх. Она нужна для того, чтобы вести учет существующих объектов указателя, указывающих на данный объект. Естественно, эта структура должна быть общей для всех таких объектов. Поэтому в каждом объекте указателя хранится сырой указатель на этот самый контрол блок. То есть базово в классе std::shared_ptr 2 поля: указатель на объект и указатель на контрол блок. Ну и приняв указатель на объект, конструктор указателя дополнитель выделяет память для этого блока.
Чем в этом контексте отличается поведение std::make_shared?
Она вызывает всего одну аллокацию. Как? выделяет просто один блок памяти, который может содержать сразу и создаваемый объект, и control block, и кладет эти данные вместе. Это уменьшает статический размер программы, потому что код содержит всего 1 вызов аллокатора. И увеличивает скорость выполнения кода, потому что аллокация - довольно дорогостоящий вызов.
Перформанс - это уже серьезный аргумент отдать свое предпочтение в пользу make функции.
Однако эта фича ведет к одной проблеме. Для кого-то она совсем не проблемная, но об этом надо знать.
Дело в том, что может создаться такая ситуация, когда ни одного shared_pointer уже не существует, а память, выделенная для объекта и блока, все еще не отдана системе. Как такое может быть? Слабые ссылки.
Контрол блок помимо счетчика сильных ссылок(собственно сами shared_ptr'ы) хранит еще и счетчик слабых ссылок - для weak_ptr'ов. А деструктор control block'а и деаллокация памяти происходят только после того, как оба счетчика зануляться. Поэтому, если у вас есть хоть один висящий std::weak_ptr, то у вашего объекта хоть и будет вызван деструктор, но память так и не будет возвращена системе.
При создании больших объектов и при обильном использовании слабых ссылок это действительно может создавать проблему.
А если у вас не этот случай - смело используйте std::make_shared()
Stay efficient. Stay cool.
#cpp17 #cpp17 #STL #optimization #memory
{kind=link}
STL vs stdlib
Откопаем один из популярнейших холиваров по С++, о котором вы даже могли и не слышать. Из-за того, что мы с вами не носители, то плохо понимаем ориджин терминов, которые сами используем. Ну типа всю нашу жизнь вокруг нас на туалетах написано WC и мы даже не понимаем, а что это значит на самом деле. Но продолжаем в новых заведениях помечать туалет именно этими буквами и просто принимаем это, как данность. Water closet. Так давно в Англии начали назывались маленькие приватные комнатки с подачей воды для смыва.
Так и мы с вами употребляем термин STL скорее в каком-то нашем интуитивном понимании, чем в реальном его значении. Ну вот например, в вакансиях плюсовиков в требованиях часто пишут, что необходимо знание буста и STL. Думаю, что и HR'ы и соискатели удивятся, что 99.9% плюсовиков никогда не пользовались STL....
Утверждение громкое и для кого-то может быть обидное, поэтому погнали разбираться, пока меня тухлыми помидорами не закидали.
С 1979 года, когда мастер-Бьёрн создал С с классами, пройдет почти 20 лет прежде, чем С++ будет стандартизирован в 1998 году. Процесс стандартизации шел долго и люди со временем вносили свои пропоузалы в будущий стандарт. В принципе и сейчас так делают. Так вот. Жил, был и работал в HP один русский эмигрант - Александр Степанов. У него давно были мысли по созданию обобщенной библиотеки, в которой данные и алгоритмы над ними находились бы отдельно друг от друга. Он пытался воплотить свои мысли в жизнь даже в других языках, типа Ada, потому что на тот момент С++ не обладал необходимой функциональностью. Но язык развивался, появились необходимые фичи и Александр начал думать над реализацией своих идей в С++. В конце 1993 года он рассказал о своих наработках бывшему коллеге - Эндрю Кёнингу, который на тот момент работал в ISO комитете С++. Эндрю восхитился замыслом Александра и организовал ему встречу с комитетом. Комитет тоже охал и ахал от гениальности идей и включил их в драфт страндарта С++. Но не полностью. Что-то пришлось удалить и что-то пришлось подкорректировать в сотрудничестве со Степановым. Именно так были созданы стандартные библиотеки алгоритмов, итераторов и контейнеров.
В 1995 году Александр перешел в компанию Silicon Graphics, доработал и релизнул окончательную версию своего видения STL. Ее даже вроде можно скачать тут. То есть это вообще отдельная библиотека, которую надо отдельно подключать к своему проекту. И с почти стопроцентной вероятностью, вы ей никогда не пользовались.
То есть STL никогда не была частью стандарта, хотя и сильно повлияло на него. В тексте стандарта нет ни одного упоминания STL! Но Степанов сам называл включения своей библиотеки в стандартную библиотеку как STL. И авторы многих книг по С++ называли эти включения STL. Даже Страуструп называет стандартные библиотеки алгоритмов, итераторов и контейнеров STL. Поэтому в умах закрепилась эта ассоциация и, в целом, сейчас легитимно называть так этот набор библиотек.
Но мозг людей склонен к обобщениям, поэтому под STL со временем многие начали понимать в принципе всю стандартную библотеку. Масла в огонь подливает еще, что STL можно расшифровать, как STandard Library. Да и другие части stdlib сугубо шаблонизированы. Типа тех же умных указателей или работы со случайными числами. Для многих STL стала уже симулякром в чистом виде, потому что люди забыли изначальное значение этого акронима.
Я не против использования термина STL в качестве референса к либам алгоритмов, итераторов и контейнеров. Даже для stdlib не против. Потому что не понимаю, как это может вредить программисту. Но считаю важным, чтобы люди понимали настоящий смысл слов, которые они употребляют. Используя в жизни ситулякры, мы отдаляемся от реальных вещей и переходим в мир выдуманный, нереальный. А настоящий мир будет продолжать влиять на нас по прежнему и это противоречие может вылиться в проблемы.
А к какому лагерю вы относитесь? Только stdlib и больше ничего или STL, но в правильном контексте? Напишите свои мысли в комментариях)
Stay in reality. Stay cool.
#fun #commercial #STL
Откопаем один из популярнейших холиваров по С++, о котором вы даже могли и не слышать. Из-за того, что мы с вами не носители, то плохо понимаем ориджин терминов, которые сами используем. Ну типа всю нашу жизнь вокруг нас на туалетах написано WC и мы даже не понимаем, а что это значит на самом деле. Но продолжаем в новых заведениях помечать туалет именно этими буквами и просто принимаем это, как данность. Water closet. Так давно в Англии начали назывались маленькие приватные комнатки с подачей воды для смыва.
Так и мы с вами употребляем термин STL скорее в каком-то нашем интуитивном понимании, чем в реальном его значении. Ну вот например, в вакансиях плюсовиков в требованиях часто пишут, что необходимо знание буста и STL. Думаю, что и HR'ы и соискатели удивятся, что 99.9% плюсовиков никогда не пользовались STL....
Утверждение громкое и для кого-то может быть обидное, поэтому погнали разбираться, пока меня тухлыми помидорами не закидали.
С 1979 года, когда мастер-Бьёрн создал С с классами, пройдет почти 20 лет прежде, чем С++ будет стандартизирован в 1998 году. Процесс стандартизации шел долго и люди со временем вносили свои пропоузалы в будущий стандарт. В принципе и сейчас так делают. Так вот. Жил, был и работал в HP один русский эмигрант - Александр Степанов. У него давно были мысли по созданию обобщенной библиотеки, в которой данные и алгоритмы над ними находились бы отдельно друг от друга. Он пытался воплотить свои мысли в жизнь даже в других языках, типа Ada, потому что на тот момент С++ не обладал необходимой функциональностью. Но язык развивался, появились необходимые фичи и Александр начал думать над реализацией своих идей в С++. В конце 1993 года он рассказал о своих наработках бывшему коллеге - Эндрю Кёнингу, который на тот момент работал в ISO комитете С++. Эндрю восхитился замыслом Александра и организовал ему встречу с комитетом. Комитет тоже охал и ахал от гениальности идей и включил их в драфт страндарта С++. Но не полностью. Что-то пришлось удалить и что-то пришлось подкорректировать в сотрудничестве со Степановым. Именно так были созданы стандартные библиотеки алгоритмов, итераторов и контейнеров.
В 1995 году Александр перешел в компанию Silicon Graphics, доработал и релизнул окончательную версию своего видения STL. Ее даже вроде можно скачать тут. То есть это вообще отдельная библиотека, которую надо отдельно подключать к своему проекту. И с почти стопроцентной вероятностью, вы ей никогда не пользовались.
То есть STL никогда не была частью стандарта, хотя и сильно повлияло на него. В тексте стандарта нет ни одного упоминания STL! Но Степанов сам называл включения своей библиотеки в стандартную библиотеку как STL. И авторы многих книг по С++ называли эти включения STL. Даже Страуструп называет стандартные библиотеки алгоритмов, итераторов и контейнеров STL. Поэтому в умах закрепилась эта ассоциация и, в целом, сейчас легитимно называть так этот набор библиотек.
Но мозг людей склонен к обобщениям, поэтому под STL со временем многие начали понимать в принципе всю стандартную библотеку. Масла в огонь подливает еще, что STL можно расшифровать, как STandard Library. Да и другие части stdlib сугубо шаблонизированы. Типа тех же умных указателей или работы со случайными числами. Для многих STL стала уже симулякром в чистом виде, потому что люди забыли изначальное значение этого акронима.
Я не против использования термина STL в качестве референса к либам алгоритмов, итераторов и контейнеров. Даже для stdlib не против. Потому что не понимаю, как это может вредить программисту. Но считаю важным, чтобы люди понимали настоящий смысл слов, которые они употребляют. Используя в жизни ситулякры, мы отдаляемся от реальных вещей и переходим в мир выдуманный, нереальный. А настоящий мир будет продолжать влиять на нас по прежнему и это противоречие может вылиться в проблемы.
А к какому лагерю вы относитесь? Только stdlib и больше ничего или STL, но в правильном контексте? Напишите свои мысли в комментариях)
Stay in reality. Stay cool.
#fun #commercial #STL
{kind=link}
Зачем для Remove-Erase идиомы нужны 2 алгоритма?
Удалить из вектора элементы по значению или подходящие под какой-то шаблон не получится напрямую через API вектора. Ну точнее получится, просто вы не хотите, чтобы получалось именно так)
Дело в том, что метод erase у вектора действительно удаляет элемент или рэндж элементов. Но как он это делает?
Вектор - массив смежных ячеек памяти, в которых находятся объекты. То есть один элемент заканчивается и начинается новый. Представим, что мы хотим удалить объект где-нибудь в середине массива. Если мы просто вызовем деструктор этого объекта(отдельную ячейку памяти вернуть системе мы не можем), то тогда у нас нарушится этот инвариант вектора, что все элементы идут друг за другом. И это чисто идейная проблема. А на практике это место в памяти еще и можно было бы также итерпретировать, как живой объект, и работать с ним. Потому что в векторе нет механизма запоминания данных об удаленных ячейках. А если удалять рэндж, то будет целая область пустующая.
Решается эта проблема метода erase сдвигом влево всех элементов, которые остались справа после удаленных. То есть либо копированием, либо перемещением объектов. Тогда все дырки заполнены, инвариантов не нарушено. Но это линейная сложность удаления. То есть на удаление каждого одиноко стоящего элемента нужно тратить линейное время. И для фильтрации всего массива понадобится уже квадратичное время, что не может не огорчать.
Хорошо. Лезем в cpp-reference и находим там алгоритмы std::remove и std:remove_if. Они принимают рендж начало-конец, ищут там конкретное значение или проверяют предикат на верность и удаляют найденные элементы. Вот что там написано про сложность:
Given
1,2) exactly
3,4) exactly
Сложность удаления найденных элементов - линейная. Ну отлично. Х*як и в рабочий код. Тесты валятся, код работает не так как ожидалось. После применения алгоритма на самом деле ничего не удалилось. Элементов столько же, только они в каком-то странном порядке. Почему?
Это я объясняю в видосе из вчерашнего поста. Довольно сложно описать работу std::remove на пальцах в тексте, поэтому и видео появилось. Но для тех, кто не смотрел кратко зарезюмирую. С помощью двух указателей нужные элементы остаются в массиве и перемещаются на свои новые места и делается это так, что в конце массива скапливаются ненужные ячейки. А возвращается из алгоритма итератор на новый конец последовательности, то есть на начало вот этого скопления. Получается std::remove ничего не удаляет, он только переупорядочивает элементы.
И это хорошо, потому что теперь мы можем действительно удалить эти элементы. Причем все разом. Делается это через уже знакомый нам метод вектора erase. Если erase очищает рэндж и этот рендж заканчивается последним элементом, то никаких копирований не происходит. Вызываются деструкторы объектов и изменяется поле, хранящее размер массива. Поэтому получается такая каша:
myVec.erase(std::remove(myVec.begin(), myVec.end(), value), myVec.end());
Собственно, когда эти 2 алгоритма применяются в одной строчке, можно наглядно увидеть причину названия идиомы.
Теперь сложность удаления будет линейной, а это уже не может не радовать.
Да, это выглядит не очень солидно, но имеем, что имеем. Хотя в 20-х плюсах эта ситуация изменилась, как-нибудь расскажу про это.
Stay based. Stay cool.
#cppcore #STL #algorithms #datastructures
Удалить из вектора элементы по значению или подходящие под какой-то шаблон не получится напрямую через API вектора. Ну точнее получится, просто вы не хотите, чтобы получалось именно так)
Дело в том, что метод erase у вектора действительно удаляет элемент или рэндж элементов. Но как он это делает?
Вектор - массив смежных ячеек памяти, в которых находятся объекты. То есть один элемент заканчивается и начинается новый. Представим, что мы хотим удалить объект где-нибудь в середине массива. Если мы просто вызовем деструктор этого объекта(отдельную ячейку памяти вернуть системе мы не можем), то тогда у нас нарушится этот инвариант вектора, что все элементы идут друг за другом. И это чисто идейная проблема. А на практике это место в памяти еще и можно было бы также итерпретировать, как живой объект, и работать с ним. Потому что в векторе нет механизма запоминания данных об удаленных ячейках. А если удалять рэндж, то будет целая область пустующая.
Решается эта проблема метода erase сдвигом влево всех элементов, которые остались справа после удаленных. То есть либо копированием, либо перемещением объектов. Тогда все дырки заполнены, инвариантов не нарушено. Но это линейная сложность удаления. То есть на удаление каждого одиноко стоящего элемента нужно тратить линейное время. И для фильтрации всего массива понадобится уже квадратичное время, что не может не огорчать.
Хорошо. Лезем в cpp-reference и находим там алгоритмы std::remove и std:remove_if. Они принимают рендж начало-конец, ищут там конкретное значение или проверяют предикат на верность и удаляют найденные элементы. Вот что там написано про сложность:
Given
N as std::distance(first, last)1,2) exactly
N comparisons with value using operator==.3,4) exactly
N applications of the predicate p.Сложность удаления найденных элементов - линейная. Ну отлично. Х*як и в рабочий код. Тесты валятся, код работает не так как ожидалось. После применения алгоритма на самом деле ничего не удалилось. Элементов столько же, только они в каком-то странном порядке. Почему?
Это я объясняю в видосе из вчерашнего поста. Довольно сложно описать работу std::remove на пальцах в тексте, поэтому и видео появилось. Но для тех, кто не смотрел кратко зарезюмирую. С помощью двух указателей нужные элементы остаются в массиве и перемещаются на свои новые места и делается это так, что в конце массива скапливаются ненужные ячейки. А возвращается из алгоритма итератор на новый конец последовательности, то есть на начало вот этого скопления. Получается std::remove ничего не удаляет, он только переупорядочивает элементы.
И это хорошо, потому что теперь мы можем действительно удалить эти элементы. Причем все разом. Делается это через уже знакомый нам метод вектора erase. Если erase очищает рэндж и этот рендж заканчивается последним элементом, то никаких копирований не происходит. Вызываются деструкторы объектов и изменяется поле, хранящее размер массива. Поэтому получается такая каша:
myVec.erase(std::remove(myVec.begin(), myVec.end(), value), myVec.end());
Собственно, когда эти 2 алгоритма применяются в одной строчке, можно наглядно увидеть причину названия идиомы.
Теперь сложность удаления будет линейной, а это уже не может не радовать.
Да, это выглядит не очень солидно, но имеем, что имеем. Хотя в 20-х плюсах эта ситуация изменилась, как-нибудь расскажу про это.
Stay based. Stay cool.
#cppcore #STL #algorithms #datastructures
{kind=link}