Сколько памяти вы можете аллоцировать?
Пару месяцев назад мы обсуждали, что будет, если маллокнуть 100 Гб памяти. Идея эксперимента мне понравилась, поэтому решил сделать что-то похожее. На этот раз я попробую в цикле на каждой итерации выделять по одному гигабайту памяти.
На этом месте я предлагаю вам задуматься, на какой итерации остановится цикл? Ну то есть, сколько всего памяти с смогу выделить таким образом?
Для конкретики определимся, что у меня на машине 64-битная Ubuntu c 21111872 кбайт оперативной памяти или ~21 Гб. И выделяю я, просто вызывая маллок, ничего больше. Память я также не освобождаю (ждал бы завершения эксперимента уже в гробу😵).
Тут есть несколько вариантов:
1️⃣ Система нам выделить 21 Гб и скажет гуляй хлопец дальше без меня.
2️⃣ У операционной системы есть какой-то внутренний лимит, больше или меньше реального количества доступной памяти, который зависит от количества доступной RAM, и при достижении вот этого лимита ОС откажется выдавать больше памяти.
3️⃣ Мы каким-то образом сможем использовать тот факт, что процессы оперируют с виртуальной памятью, которая по размерам намного больше доступной, и сможем выделить больше памяти, чем есть на самом деле.
В целом, все варианты имеют место быть. Но давайте перейдем уже к результатам. Они на картинке под постом.
Система смогла выделить 131 террабайт памяти для нас. 131 ТЕРРАБАЙТ, КАРЛ. Вы в шоке? Я в шоке. Все в шоке.
Это примерно в 2^12 раза больше, чем доступно на машине. Кто офигел - ставим лайкосик.
What the fuck is going on и откуда такие цифры взялись, разберем в следующих постах.
Stay in touch. Stay cool.
#fun #memory #hardcore
Пару месяцев назад мы обсуждали, что будет, если маллокнуть 100 Гб памяти. Идея эксперимента мне понравилась, поэтому решил сделать что-то похожее. На этот раз я попробую в цикле на каждой итерации выделять по одному гигабайту памяти.
На этом месте я предлагаю вам задуматься, на какой итерации остановится цикл? Ну то есть, сколько всего памяти с смогу выделить таким образом?
Для конкретики определимся, что у меня на машине 64-битная Ubuntu c 21111872 кбайт оперативной памяти или ~21 Гб. И выделяю я, просто вызывая маллок, ничего больше. Память я также не освобождаю (ждал бы завершения эксперимента уже в гробу😵).
Тут есть несколько вариантов:
1️⃣ Система нам выделить 21 Гб и скажет гуляй хлопец дальше без меня.
2️⃣ У операционной системы есть какой-то внутренний лимит, больше или меньше реального количества доступной памяти, который зависит от количества доступной RAM, и при достижении вот этого лимита ОС откажется выдавать больше памяти.
3️⃣ Мы каким-то образом сможем использовать тот факт, что процессы оперируют с виртуальной памятью, которая по размерам намного больше доступной, и сможем выделить больше памяти, чем есть на самом деле.
В целом, все варианты имеют место быть. Но давайте перейдем уже к результатам. Они на картинке под постом.
Система смогла выделить 131 террабайт памяти для нас. 131 ТЕРРАБАЙТ, КАРЛ. Вы в шоке? Я в шоке. Все в шоке.
Это примерно в 2^12 раза больше, чем доступно на машине. Кто офигел - ставим лайкосик.
What the fuck is going on и откуда такие цифры взялись, разберем в следующих постах.
Stay in touch. Stay cool.
#fun #memory #hardcore
{kind=link}
Как система может выделить 131 Терабайт оперативы?
Здесь мы выясняли, сколько же памяти может нам выдать система. И ответ для многих оказался неожиданным. 131 тарабайт - в дохренальен раз больше, чем реальный объем RAM на тестовой машине. Понятное дело, что это фейковые терабайты, потому что их просто негде расположить. И если бы было хотя бы RAMx2, можно было бы еще поговорить про такие штуки, как файлы подкачки. Но здесь прям совсем ничего не сходится, поэтому погнали разбираться, что к чему. Повторю ремарку, что здесь я говорю про 64-битные системы.
Первая подсказка к ответу для вас - практически в точности такой же результат я получил на других своих машинах. Да и под тем постом @dtbeaver оставил скрин, что у него такие же цифры +- 2 Гб от того, что получил я. Значит этот предел - общий для, по крайней мере, большой группы линуксоидов с 64-битными системами. Это наводит на вопрос: а сколько вообще можно адресовать памяти? Может 131 Тб и есть это количество?
Вторая подсказка - выделилось на самом деле не 131(ох уж это эти десятичные приставки в двоичном мире...), а 128. До боли знакомое число...
Однажды на собесе меня спросили: сколько байт я могу адресовать в программе? И я ответил: 2^64 байт. Ну вот у нас есть указатель. Он занимает 8 байт или 64-бит памяти. Минимально адресуемый размер памяти - 1 байт. И получается, что 8 байт памяти могут хранить 2^64 уникальных чисел и, соответственно, именно столько байт и могут быть адресованы. У меня этот ответ приняли, типа я ответил правильно. Но я ошибался....
Для начала вспомним, как вообще данные программы маппятся на физическую память. Напрямую использовать физические адреса мы не можем, потому что тогда каждый процесс должен был знать о том, какие ячейки уже используются, чтобы не нарваться на конфликт. Поэтому придумали такую абстракцию - виртуальная память. Теперь каждый процесс думает, что он пуп вселенной и ему одному принадлежит вся память компьютера. Теперь процессу ничего не нужно знать, он просто кайфует и оперирует всем адресным пространством единолично. А грязной работой занимается ОС. А раз процессу "принадлежит" вся память компьютера, то в теории ему и доступны все те 2^64 байта для размещения своих данных.
Но на самом деле в современных системах для адресации используются только 48 бит адреса. Почему не все 64? 48-бит - это 256 Тб оперативной памяти. Нет таких промышленных систем, которые бы обладали таким объемом оперативной+swap памяти. Сейчас уже конечно стали появляться, поэтому появляются системы с 52/57 адресными битами, но сегодня не об этом. Представим, что их нет. Тогда введение возможности адресовать все 2^64 байта виртуальной памяти будет увеличивать сложность и нагрузку на преобразование виртуального адреса в физический. Зачем платить за то, чем не пользуешься? Да и 64-битная адресация потребовала бы больший размер страниц, больший размер таблиц страниц или большую глубину страничной структуры. Это все увеличивает стоимость кеш промаха в буфере ассоциативной трансляции (TLB). В общем, накладные расходы были бы больше. А никому этого не надо, пока у нас нет столько памяти.
Но вы спросите у меня: 128 терабайт - это 2^47, а ты нам говоришь, что 48 бит адресуются. Куда делся еще один бит, ааа?
Операционная система, как главный дерижер всех процессов в системе, может вмешиваться в их работу по самым разным причинам. Ну например, через системные вызовы. Поэтому в ОС нужно иметь возможность в адресном пространстве конкретного процесса адресовать свой код и свои данные. Поэтому операционка делает свою виртуальную память видимой в адресном пространстве каждого процесса. Это значит, что 2^48 байт делятся между адресным пространством пользователя (user space) и ядра (kernel space). История встречала разные отношения в этом разделении. Но сейчас более-менее все остановились на соотношении 1:1. То есть 256 терабайт делятся поровну между пользовательским процессом и системой. Положительную часть берет себе система, а отрицательную - процесс. Так и получаются те самые 128 Тб.
Продолжение в комментариях
#memory #OS #fun #hardcore
Здесь мы выясняли, сколько же памяти может нам выдать система. И ответ для многих оказался неожиданным. 131 тарабайт - в дохренальен раз больше, чем реальный объем RAM на тестовой машине. Понятное дело, что это фейковые терабайты, потому что их просто негде расположить. И если бы было хотя бы RAMx2, можно было бы еще поговорить про такие штуки, как файлы подкачки. Но здесь прям совсем ничего не сходится, поэтому погнали разбираться, что к чему. Повторю ремарку, что здесь я говорю про 64-битные системы.
Первая подсказка к ответу для вас - практически в точности такой же результат я получил на других своих машинах. Да и под тем постом @dtbeaver оставил скрин, что у него такие же цифры +- 2 Гб от того, что получил я. Значит этот предел - общий для, по крайней мере, большой группы линуксоидов с 64-битными системами. Это наводит на вопрос: а сколько вообще можно адресовать памяти? Может 131 Тб и есть это количество?
Вторая подсказка - выделилось на самом деле не 131(ох уж это эти десятичные приставки в двоичном мире...), а 128. До боли знакомое число...
Однажды на собесе меня спросили: сколько байт я могу адресовать в программе? И я ответил: 2^64 байт. Ну вот у нас есть указатель. Он занимает 8 байт или 64-бит памяти. Минимально адресуемый размер памяти - 1 байт. И получается, что 8 байт памяти могут хранить 2^64 уникальных чисел и, соответственно, именно столько байт и могут быть адресованы. У меня этот ответ приняли, типа я ответил правильно. Но я ошибался....
Для начала вспомним, как вообще данные программы маппятся на физическую память. Напрямую использовать физические адреса мы не можем, потому что тогда каждый процесс должен был знать о том, какие ячейки уже используются, чтобы не нарваться на конфликт. Поэтому придумали такую абстракцию - виртуальная память. Теперь каждый процесс думает, что он пуп вселенной и ему одному принадлежит вся память компьютера. Теперь процессу ничего не нужно знать, он просто кайфует и оперирует всем адресным пространством единолично. А грязной работой занимается ОС. А раз процессу "принадлежит" вся память компьютера, то в теории ему и доступны все те 2^64 байта для размещения своих данных.
Но на самом деле в современных системах для адресации используются только 48 бит адреса. Почему не все 64? 48-бит - это 256 Тб оперативной памяти. Нет таких промышленных систем, которые бы обладали таким объемом оперативной+swap памяти. Сейчас уже конечно стали появляться, поэтому появляются системы с 52/57 адресными битами, но сегодня не об этом. Представим, что их нет. Тогда введение возможности адресовать все 2^64 байта виртуальной памяти будет увеличивать сложность и нагрузку на преобразование виртуального адреса в физический. Зачем платить за то, чем не пользуешься? Да и 64-битная адресация потребовала бы больший размер страниц, больший размер таблиц страниц или большую глубину страничной структуры. Это все увеличивает стоимость кеш промаха в буфере ассоциативной трансляции (TLB). В общем, накладные расходы были бы больше. А никому этого не надо, пока у нас нет столько памяти.
Но вы спросите у меня: 128 терабайт - это 2^47, а ты нам говоришь, что 48 бит адресуются. Куда делся еще один бит, ааа?
Операционная система, как главный дерижер всех процессов в системе, может вмешиваться в их работу по самым разным причинам. Ну например, через системные вызовы. Поэтому в ОС нужно иметь возможность в адресном пространстве конкретного процесса адресовать свой код и свои данные. Поэтому операционка делает свою виртуальную память видимой в адресном пространстве каждого процесса. Это значит, что 2^48 байт делятся между адресным пространством пользователя (user space) и ядра (kernel space). История встречала разные отношения в этом разделении. Но сейчас более-менее все остановились на соотношении 1:1. То есть 256 терабайт делятся поровну между пользовательским процессом и системой. Положительную часть берет себе система, а отрицательную - процесс. Так и получаются те самые 128 Тб.
Продолжение в комментариях
#memory #OS #fun #hardcore
{kind=link}
STL vs stdlib
Откопаем один из популярнейших холиваров по С++, о котором вы даже могли и не слышать. Из-за того, что мы с вами не носители, то плохо понимаем ориджин терминов, которые сами используем. Ну типа всю нашу жизнь вокруг нас на туалетах написано WC и мы даже не понимаем, а что это значит на самом деле. Но продолжаем в новых заведениях помечать туалет именно этими буквами и просто принимаем это, как данность. Water closet. Так давно в Англии начали назывались маленькие приватные комнатки с подачей воды для смыва.
Так и мы с вами употребляем термин STL скорее в каком-то нашем интуитивном понимании, чем в реальном его значении. Ну вот например, в вакансиях плюсовиков в требованиях часто пишут, что необходимо знание буста и STL. Думаю, что и HR'ы и соискатели удивятся, что 99.9% плюсовиков никогда не пользовались STL....
Утверждение громкое и для кого-то может быть обидное, поэтому погнали разбираться, пока меня тухлыми помидорами не закидали.
С 1979 года, когда мастер-Бьёрн создал С с классами, пройдет почти 20 лет прежде, чем С++ будет стандартизирован в 1998 году. Процесс стандартизации шел долго и люди со временем вносили свои пропоузалы в будущий стандарт. В принципе и сейчас так делают. Так вот. Жил, был и работал в HP один русский эмигрант - Александр Степанов. У него давно были мысли по созданию обобщенной библиотеки, в которой данные и алгоритмы над ними находились бы отдельно друг от друга. Он пытался воплотить свои мысли в жизнь даже в других языках, типа Ada, потому что на тот момент С++ не обладал необходимой функциональностью. Но язык развивался, появились необходимые фичи и Александр начал думать над реализацией своих идей в С++. В конце 1993 года он рассказал о своих наработках бывшему коллеге - Эндрю Кёнингу, который на тот момент работал в ISO комитете С++. Эндрю восхитился замыслом Александра и организовал ему встречу с комитетом. Комитет тоже охал и ахал от гениальности идей и включил их в драфт страндарта С++. Но не полностью. Что-то пришлось удалить и что-то пришлось подкорректировать в сотрудничестве со Степановым. Именно так были созданы стандартные библиотеки алгоритмов, итераторов и контейнеров.
В 1995 году Александр перешел в компанию Silicon Graphics, доработал и релизнул окончательную версию своего видения STL. Ее даже вроде можно скачать тут. То есть это вообще отдельная библиотека, которую надо отдельно подключать к своему проекту. И с почти стопроцентной вероятностью, вы ей никогда не пользовались.
То есть STL никогда не была частью стандарта, хотя и сильно повлияло на него. В тексте стандарта нет ни одного упоминания STL! Но Степанов сам называл включения своей библиотеки в стандартную библиотеку как STL. И авторы многих книг по С++ называли эти включения STL. Даже Страуструп называет стандартные библиотеки алгоритмов, итераторов и контейнеров STL. Поэтому в умах закрепилась эта ассоциация и, в целом, сейчас легитимно называть так этот набор библиотек.
Но мозг людей склонен к обобщениям, поэтому под STL со временем многие начали понимать в принципе всю стандартную библотеку. Масла в огонь подливает еще, что STL можно расшифровать, как STandard Library. Да и другие части stdlib сугубо шаблонизированы. Типа тех же умных указателей или работы со случайными числами. Для многих STL стала уже симулякром в чистом виде, потому что люди забыли изначальное значение этого акронима.
Я не против использования термина STL в качестве референса к либам алгоритмов, итераторов и контейнеров. Даже для stdlib не против. Потому что не понимаю, как это может вредить программисту. Но считаю важным, чтобы люди понимали настоящий смысл слов, которые они употребляют. Используя в жизни ситулякры, мы отдаляемся от реальных вещей и переходим в мир выдуманный, нереальный. А настоящий мир будет продолжать влиять на нас по прежнему и это противоречие может вылиться в проблемы.
А к какому лагерю вы относитесь? Только stdlib и больше ничего или STL, но в правильном контексте? Напишите свои мысли в комментариях)
Stay in reality. Stay cool.
#fun #commercial #STL
Откопаем один из популярнейших холиваров по С++, о котором вы даже могли и не слышать. Из-за того, что мы с вами не носители, то плохо понимаем ориджин терминов, которые сами используем. Ну типа всю нашу жизнь вокруг нас на туалетах написано WC и мы даже не понимаем, а что это значит на самом деле. Но продолжаем в новых заведениях помечать туалет именно этими буквами и просто принимаем это, как данность. Water closet. Так давно в Англии начали назывались маленькие приватные комнатки с подачей воды для смыва.
Так и мы с вами употребляем термин STL скорее в каком-то нашем интуитивном понимании, чем в реальном его значении. Ну вот например, в вакансиях плюсовиков в требованиях часто пишут, что необходимо знание буста и STL. Думаю, что и HR'ы и соискатели удивятся, что 99.9% плюсовиков никогда не пользовались STL....
Утверждение громкое и для кого-то может быть обидное, поэтому погнали разбираться, пока меня тухлыми помидорами не закидали.
С 1979 года, когда мастер-Бьёрн создал С с классами, пройдет почти 20 лет прежде, чем С++ будет стандартизирован в 1998 году. Процесс стандартизации шел долго и люди со временем вносили свои пропоузалы в будущий стандарт. В принципе и сейчас так делают. Так вот. Жил, был и работал в HP один русский эмигрант - Александр Степанов. У него давно были мысли по созданию обобщенной библиотеки, в которой данные и алгоритмы над ними находились бы отдельно друг от друга. Он пытался воплотить свои мысли в жизнь даже в других языках, типа Ada, потому что на тот момент С++ не обладал необходимой функциональностью. Но язык развивался, появились необходимые фичи и Александр начал думать над реализацией своих идей в С++. В конце 1993 года он рассказал о своих наработках бывшему коллеге - Эндрю Кёнингу, который на тот момент работал в ISO комитете С++. Эндрю восхитился замыслом Александра и организовал ему встречу с комитетом. Комитет тоже охал и ахал от гениальности идей и включил их в драфт страндарта С++. Но не полностью. Что-то пришлось удалить и что-то пришлось подкорректировать в сотрудничестве со Степановым. Именно так были созданы стандартные библиотеки алгоритмов, итераторов и контейнеров.
В 1995 году Александр перешел в компанию Silicon Graphics, доработал и релизнул окончательную версию своего видения STL. Ее даже вроде можно скачать тут. То есть это вообще отдельная библиотека, которую надо отдельно подключать к своему проекту. И с почти стопроцентной вероятностью, вы ей никогда не пользовались.
То есть STL никогда не была частью стандарта, хотя и сильно повлияло на него. В тексте стандарта нет ни одного упоминания STL! Но Степанов сам называл включения своей библиотеки в стандартную библиотеку как STL. И авторы многих книг по С++ называли эти включения STL. Даже Страуструп называет стандартные библиотеки алгоритмов, итераторов и контейнеров STL. Поэтому в умах закрепилась эта ассоциация и, в целом, сейчас легитимно называть так этот набор библиотек.
Но мозг людей склонен к обобщениям, поэтому под STL со временем многие начали понимать в принципе всю стандартную библотеку. Масла в огонь подливает еще, что STL можно расшифровать, как STandard Library. Да и другие части stdlib сугубо шаблонизированы. Типа тех же умных указателей или работы со случайными числами. Для многих STL стала уже симулякром в чистом виде, потому что люди забыли изначальное значение этого акронима.
Я не против использования термина STL в качестве референса к либам алгоритмов, итераторов и контейнеров. Даже для stdlib не против. Потому что не понимаю, как это может вредить программисту. Но считаю важным, чтобы люди понимали настоящий смысл слов, которые они употребляют. Используя в жизни ситулякры, мы отдаляемся от реальных вещей и переходим в мир выдуманный, нереальный. А настоящий мир будет продолжать влиять на нас по прежнему и это противоречие может вылиться в проблемы.
А к какому лагерю вы относитесь? Только stdlib и больше ничего или STL, но в правильном контексте? Напишите свои мысли в комментариях)
Stay in reality. Stay cool.
#fun #commercial #STL
{kind=link}
Сравниваем циклы
Пришла в голову такая незамысловатая идея сравнить время работы разных видов циклов, в которых будут выполняться простая операция - инкремент элемента массива. Операция простая и сравнимая по затратам с затратами на само итерирование. Поэтому разница в затратах на итерирование должна сыграть весомую роль в различиях итоговых значений. Если конечно, такие различия будут.
Берем довольно солидный массивчик на 1кк элементов и в циклах будем просто инкрементировать его элементы. Если вам 1кк кажется небольшим числом и результаты будут неточными, вы правы. Результаты в любом случае будут неточные, потому что моя тачка не заточена под перформанс тестирование. Однако флуктуации можно убрать: надо запустить изменение времени много-много раз и затем усреднить результаты. При достаточном количестве запусков, результатам можно будет верить. Я выбрал его равным 100 000. Просто имперически. Не хотел ждать больше 10 мин выполнения кода)
Дальше дело техники. Шаблонная функция для измерения времени, по циклу на сбор статистики и вывод результатов.
Шо по цифрам. В целом, все довольно ожидаемо. С++-like циклы прикурили у старых-добрых Си-style циклов. За комфорт, лаконичность и объектно-ориентированность приходится платить самым дорогим, что у программиста есть - процессорными клоками. Однако не совсем ожидаемо, что разница будет ~50%. Эт довольно много, поэтому все мы на заметочку себе взяли.
Не зря в критичных узких местах все до сих пор используют сишечку. С++ хорош при описании сущностей, способе работы с ними и удобстве работы с ними. Но С - гарант качественного перформанса.
Ну и соболезнования для for_each. Им как бы и так никто не пользуется, еще и здесь унизили.
Тема сравнения производительности кажется мне интересной и в будущем думаю, что затестим еще много чего.
Measure your performance. Stay cool.
#performance #fun #goodoldc
Пришла в голову такая незамысловатая идея сравнить время работы разных видов циклов, в которых будут выполняться простая операция - инкремент элемента массива. Операция простая и сравнимая по затратам с затратами на само итерирование. Поэтому разница в затратах на итерирование должна сыграть весомую роль в различиях итоговых значений. Если конечно, такие различия будут.
Берем довольно солидный массивчик на 1кк элементов и в циклах будем просто инкрементировать его элементы. Если вам 1кк кажется небольшим числом и результаты будут неточными, вы правы. Результаты в любом случае будут неточные, потому что моя тачка не заточена под перформанс тестирование. Однако флуктуации можно убрать: надо запустить изменение времени много-много раз и затем усреднить результаты. При достаточном количестве запусков, результатам можно будет верить. Я выбрал его равным 100 000. Просто имперически. Не хотел ждать больше 10 мин выполнения кода)
Дальше дело техники. Шаблонная функция для измерения времени, по циклу на сбор статистики и вывод результатов.
Шо по цифрам. В целом, все довольно ожидаемо. С++-like циклы прикурили у старых-добрых Си-style циклов. За комфорт, лаконичность и объектно-ориентированность приходится платить самым дорогим, что у программиста есть - процессорными клоками. Однако не совсем ожидаемо, что разница будет ~50%. Эт довольно много, поэтому все мы на заметочку себе взяли.
Не зря в критичных узких местах все до сих пор используют сишечку. С++ хорош при описании сущностей, способе работы с ними и удобстве работы с ними. Но С - гарант качественного перформанса.
Ну и соболезнования для for_each. Им как бы и так никто не пользуется, еще и здесь унизили.
Тема сравнения производительности кажется мне интересной и в будущем думаю, что затестим еще много чего.
Measure your performance. Stay cool.
#performance #fun #goodoldc
{kind=link}
Самая программистская математическая задачка
Есть одна задачка, которая вскружила мне голову элегантностью своего решения. Сформулирована она как обычная задачка на логику, но по сути своей очень программистская. Для людей с очень «низкоуровневым мышлением». Поэтому и решил с вами ей поделиться. Кажется плюсовый канал - подходящее место для таких задачек. Может я преувеличиваю, но я художник, я так чувствую.
Собсна формулировка. Жил был король. Хорошо король правил своей страной, богатая она была. И король соответственно тоже жил в большой роскоши. Появился у этого короля завистник среди придворной интеллигенции и захотел он убить короля. Думал про разные способы убийства и вспомнил одну деталь. Король очень любит вино и в погребе дворца есть 1000 бутылок его самого любимого вина, которое он пьет каждый день. И решил завистник отравить вино. Послал вместо себя убийцу в погреб, чтобы он отравил бутылки. Однако убийцу быстро нашли и поймали до того, как он отравил все бутылки. По правде говоря, он успел только одну из них отравить.
И теперь перед королем стоит задача - определить отравленное вино, потому что убийца не сознается.
Чтобы не травить людей, король приказал принести ему 10 кроликов. По задумке кролики будут пить вина из каждой бутылки и рано и поздно, найдется отравленная. Каждый кролик может пить неограниченное количество вина. То что он будет вдрызг пьяный, не значит, что он мертвый 😁
Чтобы убить живое существо, яду нужно примерно 24 часа.
Имея 10 кроликов и 1000 бутылок, королю нужно за минимальное время определить, какая из бутылок отравленная, чтобы продолжить пить свое любимое вино.
Решением задачи будет стратегия, придерживаясь которой гарантированно определяется нужная бутылка за минимальное количество времени.
Кидайте свои варианты в комменты. Если знаете реальное решение, то прошу не писать его, чтобы другие могли хорошенько подумать.
Кажется, что тут даже можно что-то пообсуждать, поэтому оставлю вас без решения пока. Ответ напишу в комментах к завтрашнему посту. Не гуглите решение, чтобы не испортить себе впечатление. Так что подрубаем уведомления, скорее всего вы сильно удивитесь решению.
Solve problems. Stay cool.
#fun
Есть одна задачка, которая вскружила мне голову элегантностью своего решения. Сформулирована она как обычная задачка на логику, но по сути своей очень программистская. Для людей с очень «низкоуровневым мышлением». Поэтому и решил с вами ей поделиться. Кажется плюсовый канал - подходящее место для таких задачек. Может я преувеличиваю, но я художник, я так чувствую.
Собсна формулировка. Жил был король. Хорошо король правил своей страной, богатая она была. И король соответственно тоже жил в большой роскоши. Появился у этого короля завистник среди придворной интеллигенции и захотел он убить короля. Думал про разные способы убийства и вспомнил одну деталь. Король очень любит вино и в погребе дворца есть 1000 бутылок его самого любимого вина, которое он пьет каждый день. И решил завистник отравить вино. Послал вместо себя убийцу в погреб, чтобы он отравил бутылки. Однако убийцу быстро нашли и поймали до того, как он отравил все бутылки. По правде говоря, он успел только одну из них отравить.
И теперь перед королем стоит задача - определить отравленное вино, потому что убийца не сознается.
Чтобы не травить людей, король приказал принести ему 10 кроликов. По задумке кролики будут пить вина из каждой бутылки и рано и поздно, найдется отравленная. Каждый кролик может пить неограниченное количество вина. То что он будет вдрызг пьяный, не значит, что он мертвый 😁
Чтобы убить живое существо, яду нужно примерно 24 часа.
Имея 10 кроликов и 1000 бутылок, королю нужно за минимальное время определить, какая из бутылок отравленная, чтобы продолжить пить свое любимое вино.
Решением задачи будет стратегия, придерживаясь которой гарантированно определяется нужная бутылка за минимальное количество времени.
Кидайте свои варианты в комменты. Если знаете реальное решение, то прошу не писать его, чтобы другие могли хорошенько подумать.
Кажется, что тут даже можно что-то пообсуждать, поэтому оставлю вас без решения пока. Ответ напишу в комментах к завтрашнему посту. Не гуглите решение, чтобы не испортить себе впечатление. Так что подрубаем уведомления, скорее всего вы сильно удивитесь решению.
Solve problems. Stay cool.
#fun
{kind=link}
Cамая популярная задачка с собеседований
Это вообще отдельный жанр в собеседованиях - логические задачки. Есть те, кто любит задавать их каждому кандидату. Но большинство обходит не используют их при найме людей. Оно и понятно, на собесах люди в довольно стрессовом состоянии находятся. Им бы вспомнить, чем вектор от листа отличается, не говоря уже о том, чтобы сказать, как засунуть слона в холодильник.
На моем пути у меня 2 раза спрашивали логические задачки и оба раза спрашивали одну и ту же. Поэтому название поста в стиле ошибки выжившего. Но, думаю, что она реально такая популярная, поэтому будет полезно подготовиться к ней.
Формулировка.
Вы находитесь в кольцевом поезде. То есть как будто бы 2 конца одного поезда соединили и можно бесконечно теперь в нем гулять. Количество вагонов вам неизвестно. В каждом вагоне есть всего одна лампочка. Она имеет 2 состояния: вкл и выкл. По дефолту они в рандомном порядке включены во всех вагонах, то есть вы заранее не знаете, в каком порядке в вагонах зажжены лампочки. И у каждой лампочки есть выключатель, который исправно работает.
Вас телепортируют в какой-то из вагонов поезда. Ваша задача - найти длину поезда аля количество вагонов. Естественно, вы можете переходить из вагона в вагон.
Такая вот незамысловатая задачка. Рассуждая логически, можно довольно быстро прийти к ответу. Главное - правильно себе вопросы ставить.
Знающих прошу не спойлерить в комментах и не подсказывать. Обсуждения как всегда поощряются. Если вы допетрили до решения, то лучше его при себе оставить.
Решение сброшу завтра в комментах к отдельному посту, посвященному ответу.
Всем удачи!
Train your logic. Stay cool.
#fun
Это вообще отдельный жанр в собеседованиях - логические задачки. Есть те, кто любит задавать их каждому кандидату. Но большинство обходит не используют их при найме людей. Оно и понятно, на собесах люди в довольно стрессовом состоянии находятся. Им бы вспомнить, чем вектор от листа отличается, не говоря уже о том, чтобы сказать, как засунуть слона в холодильник.
На моем пути у меня 2 раза спрашивали логические задачки и оба раза спрашивали одну и ту же. Поэтому название поста в стиле ошибки выжившего. Но, думаю, что она реально такая популярная, поэтому будет полезно подготовиться к ней.
Формулировка.
Вы находитесь в кольцевом поезде. То есть как будто бы 2 конца одного поезда соединили и можно бесконечно теперь в нем гулять. Количество вагонов вам неизвестно. В каждом вагоне есть всего одна лампочка. Она имеет 2 состояния: вкл и выкл. По дефолту они в рандомном порядке включены во всех вагонах, то есть вы заранее не знаете, в каком порядке в вагонах зажжены лампочки. И у каждой лампочки есть выключатель, который исправно работает.
Вас телепортируют в какой-то из вагонов поезда. Ваша задача - найти длину поезда аля количество вагонов. Естественно, вы можете переходить из вагона в вагон.
Такая вот незамысловатая задачка. Рассуждая логически, можно довольно быстро прийти к ответу. Главное - правильно себе вопросы ставить.
Знающих прошу не спойлерить в комментах и не подсказывать. Обсуждения как всегда поощряются. Если вы допетрили до решения, то лучше его при себе оставить.
Решение сброшу завтра в комментах к отдельному посту, посвященному ответу.
Всем удачи!
Train your logic. Stay cool.
#fun
{kind=link}
Снова сравниваем решения задачи с поездами
Кто забыл или не в теме, вот эта задача. В прошлом мы уже сравнивали два решения: условный маятник и спидометр. Лучше освежить в памяти контекст, чтобы понятнее был предмет разговора. Однако наша подписчица @tigrisVD сделала несколько улучшений алгоритма спидометра. Вот ее сообщение с пояснениями и кодом.
Первое - базовое улучшение. Вместо того, чтобы возвращаться назад на каждом шаге(что очень расточительно), мы возвращаемся назад, только, если встретили единичку и поменяли ее на ноль. Только в этом случае мы могли поменять самую первую лампочку.
Это уже улучшение уполовинило количество шагов. И сравняло его с маятником.
Но она пошла дальше и придумала следующую оптимизацию: пусть мы встретили единичку, когда шли вправо. Тогда разрешим себе поменять ее на нолик и идти дальше на еще столько же шагов, сколько мы сделали до этой единички. Но если мы встретим еще одну единичку, то возвращаемся обратно и чекаем нулевую ячейку. Таким образом мы сэкономим себе проход до первой ячейки и обратно. А если мы за этот удвоенный период не нашли ее одну единичку, то мы просто обязаны обратно вернуться, чтобы проверить была ли первая новая единичка на нашем пути - тем самым началом.
Там есть некоторые проблемы с тем, что оптимизированные алгоритмы спидометра зависят от входных данных. И в худшем случае, когда в поезде включены все лампочки, последний оптимизированный алгоритм работает лишь в 2 раза лучше базового спидометра. В лучшем случае, когда все лампочки выключены - сложность алгоритмов линейно зависит от количества вагонов, а не квадратично, как у базового спидометра. Базовое улучшение - нужно пройти всего х2 от количества вагонов. А оптимизированный вариант- х4(я там одну ошибочку нашел в коде при подсчете пройденных вагонов, поэтому не в 3, а в 4). Но в рандомных случаях оптимизированный вариант примерно в 2 раза быстрее базового улучшенного и в 4 раза быстрее оригинального спидометра.
Позапускать ее код и посмотреть на цифры можно тут
Спасибо вам, @tigrisVD, за такие интересные решения!
Но ваши улучшения натолкнули и меня на размышления и улучшения, о которых я расскажу завтра.
Impove yourself. Stay cool.
#fun #optimization
Кто забыл или не в теме, вот эта задача. В прошлом мы уже сравнивали два решения: условный маятник и спидометр. Лучше освежить в памяти контекст, чтобы понятнее был предмет разговора. Однако наша подписчица @tigrisVD сделала несколько улучшений алгоритма спидометра. Вот ее сообщение с пояснениями и кодом.
Первое - базовое улучшение. Вместо того, чтобы возвращаться назад на каждом шаге(что очень расточительно), мы возвращаемся назад, только, если встретили единичку и поменяли ее на ноль. Только в этом случае мы могли поменять самую первую лампочку.
Это уже улучшение уполовинило количество шагов. И сравняло его с маятником.
Но она пошла дальше и придумала следующую оптимизацию: пусть мы встретили единичку, когда шли вправо. Тогда разрешим себе поменять ее на нолик и идти дальше на еще столько же шагов, сколько мы сделали до этой единички. Но если мы встретим еще одну единичку, то возвращаемся обратно и чекаем нулевую ячейку. Таким образом мы сэкономим себе проход до первой ячейки и обратно. А если мы за этот удвоенный период не нашли ее одну единичку, то мы просто обязаны обратно вернуться, чтобы проверить была ли первая новая единичка на нашем пути - тем самым началом.
Там есть некоторые проблемы с тем, что оптимизированные алгоритмы спидометра зависят от входных данных. И в худшем случае, когда в поезде включены все лампочки, последний оптимизированный алгоритм работает лишь в 2 раза лучше базового спидометра. В лучшем случае, когда все лампочки выключены - сложность алгоритмов линейно зависит от количества вагонов, а не квадратично, как у базового спидометра. Базовое улучшение - нужно пройти всего х2 от количества вагонов. А оптимизированный вариант- х4(я там одну ошибочку нашел в коде при подсчете пройденных вагонов, поэтому не в 3, а в 4). Но в рандомных случаях оптимизированный вариант примерно в 2 раза быстрее базового улучшенного и в 4 раза быстрее оригинального спидометра.
Позапускать ее код и посмотреть на цифры можно тут
Спасибо вам, @tigrisVD, за такие интересные решения!
Но ваши улучшения натолкнули и меня на размышления и улучшения, о которых я расскажу завтра.
Impove yourself. Stay cool.
#fun #optimization
Telegram
Грокаем C++
Cамая популярная задачка с собеседований
Это вообще отдельный жанр в собеседованиях - логические задачки. Есть те, кто любит задавать их каждому кандидату. Но большинство обходит не используют их при найме людей. Оно и понятно, на собесах люди в довольно…
Это вообще отдельный жанр в собеседованиях - логические задачки. Есть те, кто любит задавать их каждому кандидату. Но большинство обходит не используют их при найме людей. Оно и понятно, на собесах люди в довольно…
Линейное решение задачи с поездами
По поводу моих улучшений. Немного поразмыслив, первая моя мысль - что с маятником тоже можно сделать маленькое улучшение такое же, как и базовое улучшение спидометра. Мы не каждый раз поворачиваем и идем в обратную сторону, а только тогда, когда меняем состояние встретившейся лампочки.
Во всех особых случаях, когда все лампочки либо включены, либо выключены, такое улучшение работает за время х2 от количества вагонов. И в среднем работает в 2 раза быстрее, чем оригинальный маятник, и примерно наравне с оптимизированным спидометром(чуточку хуже).
Но! Кажется на основе оптимизированного спидометра я придумал линейный алгоритм, дающий стабильно O(4n) для совершенно рандомных случаев и во всех особых случаях, когда все лампочки либо включены, либо выключены. И где-то О(8n) в худшем случае для конкретно этого алгоритма.
В чем суть. Для оптимизированного спидометра мы разрешали себе идти дальше, когда на очередном проходе на пути от начального вагона мы в первый раз встретили зажженную лампочку, но только до тех пор, пока не встретим еще одну единичку или не закончатся наши разрешенные шаги. А что если пойти дальше, даже после второй зажженной лампочки? Что если каждый раз когда мы встречаем такую лампочку, то разрешаем себе идти еще в 2 раза дальше? Прям каждый раз. Встретили зажженную лампочку - погасили и может идти дальше на столько же вагонов, сколько мы прошли от начала до только что погашенной нами лампочки. По факту, мы идем вперед всегда, пока нам встречаются зажженные лампочки и мы не уходим слишком далеко от последней погашенной нами. Тогда существует всего 2 варианта - рано или поздно мы погасим начальную лампочку или последняя погашенная не была начальной, но мы так и не дошли до следующей зажженной до того, как истекли наши разрешенные вагоны.
В первом случае мы просто пройдем лишний круг и вернемся обратно. Таким образом пройдя 2 лишних круга.
Во втором случае мы идем обратно и проверяем, была ли последняя выключенная нами лампочка той самой начальной. Если не была, то снова начинаем идти вправо, пока не наткнемся на зажженную лампочку.
Таким образом, если зажженные лампочки достаточно часто встречаются, то мы идем в один проход до конца поезда, потом еще удвоенную его длину и обратно. Получается, что нам понадобится 4 длины поезда, чтобы посчитать количество вагонов.
Но есть у такого алгоритма худший случай. Тогда, когда зажженные лампочки стоят ровно на один вагон дальше, чем нам разрешено пройти. Пример: зажженная лампочка находится в 3-м вагоне. После того, как мы ее погасили, нам разрешается идти еще 2 вагона и искать там зажженные лампочки. То есть последний вагон, который мы можем посмотреть на этой итерации - 5-ый. А вот следующая зажженная лампочка будет в шестом. И мы могли бы всего на один вагончик вперед пройти и встретить ее, но согласно алгоритму мы должны вернуться к изначальному вагону. Если после шестого вагона лампочка будет в 12-м, то мы обязаны будем вернуться назад и снова пройти вперед до 12-ого. И так далее. Думаю, суть вы уловили.
Так вот на таких данных сложность повышается до примерно О(8n). Эту чиселку вывел совершенно экспериментально. Возможно знатоки математики и теории алгоритмов выведут более точную зависимость. Чему я очень буду рад)
Вроде бы звучит разумно и тесты все проходятся прекрасно. И сложность на первый взгляд линейная во всех случаях, что не может не радовать.
Прикреплю в комменты полный файл со всеми сравнениями. Но вот ссылка на годболт кому будет так удобнее.
Критика и замечания приветствуются.
Improve yourself. Stay cool.
#fun #optimization
По поводу моих улучшений. Немного поразмыслив, первая моя мысль - что с маятником тоже можно сделать маленькое улучшение такое же, как и базовое улучшение спидометра. Мы не каждый раз поворачиваем и идем в обратную сторону, а только тогда, когда меняем состояние встретившейся лампочки.
Во всех особых случаях, когда все лампочки либо включены, либо выключены, такое улучшение работает за время х2 от количества вагонов. И в среднем работает в 2 раза быстрее, чем оригинальный маятник, и примерно наравне с оптимизированным спидометром(чуточку хуже).
Но! Кажется на основе оптимизированного спидометра я придумал линейный алгоритм, дающий стабильно O(4n) для совершенно рандомных случаев и во всех особых случаях, когда все лампочки либо включены, либо выключены. И где-то О(8n) в худшем случае для конкретно этого алгоритма.
В чем суть. Для оптимизированного спидометра мы разрешали себе идти дальше, когда на очередном проходе на пути от начального вагона мы в первый раз встретили зажженную лампочку, но только до тех пор, пока не встретим еще одну единичку или не закончатся наши разрешенные шаги. А что если пойти дальше, даже после второй зажженной лампочки? Что если каждый раз когда мы встречаем такую лампочку, то разрешаем себе идти еще в 2 раза дальше? Прям каждый раз. Встретили зажженную лампочку - погасили и может идти дальше на столько же вагонов, сколько мы прошли от начала до только что погашенной нами лампочки. По факту, мы идем вперед всегда, пока нам встречаются зажженные лампочки и мы не уходим слишком далеко от последней погашенной нами. Тогда существует всего 2 варианта - рано или поздно мы погасим начальную лампочку или последняя погашенная не была начальной, но мы так и не дошли до следующей зажженной до того, как истекли наши разрешенные вагоны.
В первом случае мы просто пройдем лишний круг и вернемся обратно. Таким образом пройдя 2 лишних круга.
Во втором случае мы идем обратно и проверяем, была ли последняя выключенная нами лампочка той самой начальной. Если не была, то снова начинаем идти вправо, пока не наткнемся на зажженную лампочку.
Таким образом, если зажженные лампочки достаточно часто встречаются, то мы идем в один проход до конца поезда, потом еще удвоенную его длину и обратно. Получается, что нам понадобится 4 длины поезда, чтобы посчитать количество вагонов.
Но есть у такого алгоритма худший случай. Тогда, когда зажженные лампочки стоят ровно на один вагон дальше, чем нам разрешено пройти. Пример: зажженная лампочка находится в 3-м вагоне. После того, как мы ее погасили, нам разрешается идти еще 2 вагона и искать там зажженные лампочки. То есть последний вагон, который мы можем посмотреть на этой итерации - 5-ый. А вот следующая зажженная лампочка будет в шестом. И мы могли бы всего на один вагончик вперед пройти и встретить ее, но согласно алгоритму мы должны вернуться к изначальному вагону. Если после шестого вагона лампочка будет в 12-м, то мы обязаны будем вернуться назад и снова пройти вперед до 12-ого. И так далее. Думаю, суть вы уловили.
Так вот на таких данных сложность повышается до примерно О(8n). Эту чиселку вывел совершенно экспериментально. Возможно знатоки математики и теории алгоритмов выведут более точную зависимость. Чему я очень буду рад)
Вроде бы звучит разумно и тесты все проходятся прекрасно. И сложность на первый взгляд линейная во всех случаях, что не может не радовать.
Прикреплю в комменты полный файл со всеми сравнениями. Но вот ссылка на годболт кому будет так удобнее.
Критика и замечания приветствуются.
Improve yourself. Stay cool.
#fun #optimization
Способы узнать знак целого числа
Иногда появляется необходимость узнать, является ли данное число отрицательным или нет. За примером далеко ходить не будем. В одной из наших задачек про переворачивание десятичных цифр числа один из подходов к решению может быть таким: узнать, является ли число отрицательным, если да, то домножить его на -1 и оперировать им как положительным числом. После всех действий и проверок домножить число обратно на -1.
И вот мне стало интересно. Сколько способов есть, чтобы узнать является ли число отрицательным? Давайте же узнаем! Я вот что надумал:
💥 Как в прошлом посте сдвинуть число вправо на 31/63 бита и привести все к инту. Если получился 0 - число положительное. Если 1 - отрицательное.
💥 bool is_signed = number < 0. Один из самых очевидных и прямолинейных подходов. Просто проверяем число оператором меньше и все на этом. Скучно, попсово, но зато понятно и эффективно.
💥 Использовать битовую маску. bool is_signed = number & 0x80000000. Здесь мы оставляем только знаковый бит на его месте. Затем приводим число к булевому значению. Положительное число превратится в нолик, а значит в true, а отрицательное - в false. Размер маски естественно меняется в зависимости от типа знакового числа.
💥 std::signbit(number). Эта шаблонная функция вернет вам true, если number - отрицательное, и false в обратном случае. На мой взгляд, это больше по плюсовому и функция имеет человеческое название, поэтому читаться такой код будет намного проще, чем в предыдущих случаях.
На этом я застопорился. Никак больше не могу придумать других способов, которые бы не включали в себя предыдущие. Тут скорее мне интересно, какие вы варианты придумаете. Обязательно отпишитесь к комментах!
Generate a dozens of different solutions. Stay cool.
#fun #cppcore
Иногда появляется необходимость узнать, является ли данное число отрицательным или нет. За примером далеко ходить не будем. В одной из наших задачек про переворачивание десятичных цифр числа один из подходов к решению может быть таким: узнать, является ли число отрицательным, если да, то домножить его на -1 и оперировать им как положительным числом. После всех действий и проверок домножить число обратно на -1.
И вот мне стало интересно. Сколько способов есть, чтобы узнать является ли число отрицательным? Давайте же узнаем! Я вот что надумал:
💥 Как в прошлом посте сдвинуть число вправо на 31/63 бита и привести все к инту. Если получился 0 - число положительное. Если 1 - отрицательное.
💥 bool is_signed = number < 0. Один из самых очевидных и прямолинейных подходов. Просто проверяем число оператором меньше и все на этом. Скучно, попсово, но зато понятно и эффективно.
💥 Использовать битовую маску. bool is_signed = number & 0x80000000. Здесь мы оставляем только знаковый бит на его месте. Затем приводим число к булевому значению. Положительное число превратится в нолик, а значит в true, а отрицательное - в false. Размер маски естественно меняется в зависимости от типа знакового числа.
💥 std::signbit(number). Эта шаблонная функция вернет вам true, если number - отрицательное, и false в обратном случае. На мой взгляд, это больше по плюсовому и функция имеет человеческое название, поэтому читаться такой код будет намного проще, чем в предыдущих случаях.
На этом я застопорился. Никак больше не могу придумать других способов, которые бы не включали в себя предыдущие. Тут скорее мне интересно, какие вы варианты придумаете. Обязательно отпишитесь к комментах!
Generate a dozens of different solutions. Stay cool.
#fun #cppcore
{kind=link}
Как работает dynamic_cast? RTTI!
#опытным #fun
Продолжаем серию! В прошлой статье мы познакомились с таблицей виртуальных методов. Помимо этой таблицы, в этой же области памяти скрывается еще одна структура.
Как мы видели ранее, для полиморфных объектов существует специальный оператор dynamic_cast. Стандарт не регламентирует его реализацию, но чаще всего, для работы требуется дополнительная информация о типе полиморфного объекта RTTI (Run Time Type Information). Посмотреть эту структуру можно с помощью оператора
Содержимое RTTI зависит от компилятора, но как минимум там хранится
Операторы
Как же нам найти начало объекта RTTI? Не боги горшки обжигают, есть просто специальный указатель, который расположен прямо перед началом таблицы виртуальных методов. Он и ведёт к объекту RTTI:
Получив доступ к дополнительной информации остаётся выполнить приведение типа: upcast, downcast, sidecast/crosscast. Эта задача требует совершить поиск в ориентированном ациклическом графе (DAG, directed acyclic graph), что в рамках этой операции может быть трудоёмким, но необходимым для обработки общего случая. Теперь мы можем даже ответить, почему
Можем ли мы как-то ускорить работу? Мы можем просто запретить использовать
И такое ограничение будет автоматически подталкивать к пересмотру полученной архитектуры решения или разработке собственного механизма приведения типов.
На счет последнего надо много и долго думать. На стыке двух динамических библиотек, которые могут ничего не знать друг о друге, придется как-то проверять, что лежит в динамическом типе. Так же необходимо учитывать особенности множественного и виртуального наследования. От них можно и в принципе отказаться, но как запретить вышеупомянутые виды наследования в коде? Меня бы в первую очередь интересовала автономная и независимая жизнь проекта без пристального надзора хранителей знаний. Это задача, которая имеет много подводных камней или требует введения в проект ограничений, дополнительного контроля.
Если
#cppcore #howitworks
#опытным #fun
Продолжаем серию! В прошлой статье мы познакомились с таблицей виртуальных методов. Помимо этой таблицы, в этой же области памяти скрывается еще одна структура.
Как мы видели ранее, для полиморфных объектов существует специальный оператор dynamic_cast. Стандарт не регламентирует его реализацию, но чаще всего, для работы требуется дополнительная информация о типе полиморфного объекта RTTI (Run Time Type Information). Посмотреть эту структуру можно с помощью оператора
typeid:cppОбратите внимание,
const auto &RTTI = typeid(object);
typeid возвращает read-only ссылку на объект std::type_info, т.к. эту область памяти нельзя изменять — она была сгенерирована компилятором на этапе компиляции.Содержимое RTTI зависит от компилятора, но как минимум там хранится
hash полиморфного класса и его имя, которые доступны из std::type_info. Маловероятно, что вам на этом потребуется построить какую-то логику приложения, но эта штука могла бы быть вам полезна при отладке / подсчёте статистики и т.д. Операторы
dynamic_cast и typeid получают доступ к этой структуре так же через скрытый виртуальный указатель, который подшивается к объектам полиморфного класса. Как мы знаем, этот указатель смотрит на начало таблицы виртуальных методов, коих может быть бесчисленное множество и варьироваться от наследника к наследнику.Как же нам найти начало объекта RTTI? Не боги горшки обжигают, есть просто специальный указатель, который расположен прямо перед началом таблицы виртуальных методов. Он и ведёт к объекту RTTI:
┌-─| ptr to RTTI | vtable pointer
| |----------------| <- looks here
| | vtable methods |
| |----------------|
└─>| RTTI object |
Получив доступ к дополнительной информации остаётся выполнить приведение типа: upcast, downcast, sidecast/crosscast. Эта задача требует совершить поиск в ориентированном ациклическом графе (DAG, directed acyclic graph), что в рамках этой операции может быть трудоёмким, но необходимым для обработки общего случая. Теперь мы можем даже ответить, почему
dynamic_cast такой медленный.Можем ли мы как-то ускорить работу? Мы можем просто запретить использовать
dynamic_cast 😄 Это можно сделать, отключив RTTI с помощью флага компиляции:-fno-rtti
И такое ограничение будет автоматически подталкивать к пересмотру полученной архитектуры решения или разработке собственного механизма приведения типов.
На счет последнего надо много и долго думать. На стыке двух динамических библиотек, которые могут ничего не знать друг о друге, придется как-то проверять, что лежит в динамическом типе. Так же необходимо учитывать особенности множественного и виртуального наследования. От них можно и в принципе отказаться, но как запретить вышеупомянутые виды наследования в коде? Меня бы в первую очередь интересовала автономная и независимая жизнь проекта без пристального надзора хранителей знаний. Это задача, которая имеет много подводных камней или требует введения в проект ограничений, дополнительного контроля.
Если
dynamic_cast становится бутылочным горлышком, то в первую очередь стоит пересмотреть именно архитектуру решения, а оптимизации оставить на крайний случай.#cppcore #howitworks
XOR Swap
Есть такая интересная техника для свопинга содержимого двух переменных без надобности во временной третьей! Стандартный подход выглядит примерно так:
Все мы с программистких пеленок уже выучили это. И примерно так и реализована функция std::swap из стандартной библиотеки. Однако вот вам задали на собесе вопрос: "вот у вас есть 2 числа, но я хочу, чтобы вы обменяли их значения без временной переменной?". Какие мысли? Подумайте пару секунд.
Как всегда, на помощь приходит магия математики и битовых операций. Можно использовать 3 подряд операции xor над этими числами и мы получим нужный результат.
Доказывать сие утверждения я, конечно, не буду. Однако можете почитать в английской вики, там все подробно выводится из свойств Исключающего ИЛИ.
Тут есть один интересный момент, что в случае подачи на вход функции одной и той же переменной, то произойдет эффект зануления. Первый же xor занулит x, а значит и y. Поэтому в самом начале стоит условие на проверку одинакового адреса.
При подаче на вход просто одинаковых значений, все работает и без условия.
Ну и работает это дело только с целочисленными параметрами.
Но предостерегаю вас - не используйте эту технику в современных программах! Результаты этих трех ксоров напрямую зависят друг от друга по цепочке. А значит параллелизма на уровне инструкций можно не ждать.
Современные компиляторы вполне могут и соптимизировать третью переменную и вы ее вовсе не увидите в ассемблере. Да и еще и вариант с доп переменной тупо быстрее работает. Всего 2 store'а и 2 load'а, которые еще и распараллелить можно, против 3 затратных ксоров. Да и даже довольно тяжеловесная XCHG работает быстрее, чем 3 xor'а.
Зачем я это все рассказываю тогда, если эта техника уже никому не уперлась? Для ретроспективы событий. Дело в том, что раньше люди писали программы без компиляторов, напрямую на ассемблере. Плюс в то время компьютеры имели такое маленькое количество памяти, что биться приходилось буквально за каждый байт. А используя операции xor, мы экономим 33% памяти на эту операцию. Довольно неплохо. В стародавние времена как только не извращались люди, чтобы выжимать все из железа. Эх, были времена...
Понимание тонкостей операции xor и ее возможных приложений делают ее довольно мощным инструментом в низкоуровневых вычислениях. А в некоторых задачах вы и вовсе никогда даже не подумаете, что они могут наиболее эффективным образом решаться с помощью xor.
Learn technics from the past. Stay cool.
#cppcore #fun #algorithms
Есть такая интересная техника для свопинга содержимого двух переменных без надобности во временной третьей! Стандартный подход выглядит примерно так:
template <class T>
void swap(T& lhs, T& rhs) {
T tmp = std::move(lhs);
lhs = std::move(rhs);
rhs = std::move(tmp);
}
Все мы с программистких пеленок уже выучили это. И примерно так и реализована функция std::swap из стандартной библиотеки. Однако вот вам задали на собесе вопрос: "вот у вас есть 2 числа, но я хочу, чтобы вы обменяли их значения без временной переменной?". Какие мысли? Подумайте пару секунд.
Как всегда, на помощь приходит магия математики и битовых операций. Можно использовать 3 подряд операции xor над этими числами и мы получим нужный результат.
template <class T, typename std::enable_if_t<std::is_integral_v<T>> = 0>
void swap(T& x, T& y) {
if (&x == &y)
return;
x = x ^ y;
y = x ^ y;
x = x ^ y;
}
Доказывать сие утверждения я, конечно, не буду. Однако можете почитать в английской вики, там все подробно выводится из свойств Исключающего ИЛИ.
Тут есть один интересный момент, что в случае подачи на вход функции одной и той же переменной, то произойдет эффект зануления. Первый же xor занулит x, а значит и y. Поэтому в самом начале стоит условие на проверку одинакового адреса.
При подаче на вход просто одинаковых значений, все работает и без условия.
Ну и работает это дело только с целочисленными параметрами.
Но предостерегаю вас - не используйте эту технику в современных программах! Результаты этих трех ксоров напрямую зависят друг от друга по цепочке. А значит параллелизма на уровне инструкций можно не ждать.
Современные компиляторы вполне могут и соптимизировать третью переменную и вы ее вовсе не увидите в ассемблере. Да и еще и вариант с доп переменной тупо быстрее работает. Всего 2 store'а и 2 load'а, которые еще и распараллелить можно, против 3 затратных ксоров. Да и даже довольно тяжеловесная XCHG работает быстрее, чем 3 xor'а.
Зачем я это все рассказываю тогда, если эта техника уже никому не уперлась? Для ретроспективы событий. Дело в том, что раньше люди писали программы без компиляторов, напрямую на ассемблере. Плюс в то время компьютеры имели такое маленькое количество памяти, что биться приходилось буквально за каждый байт. А используя операции xor, мы экономим 33% памяти на эту операцию. Довольно неплохо. В стародавние времена как только не извращались люди, чтобы выжимать все из железа. Эх, были времена...
Понимание тонкостей операции xor и ее возможных приложений делают ее довольно мощным инструментом в низкоуровневых вычислениях. А в некоторых задачах вы и вовсе никогда даже не подумаете, что они могут наиболее эффективным образом решаться с помощью xor.
Learn technics from the past. Stay cool.
#cppcore #fun #algorithms
{kind=link}
Отпуск
Ребята, Грокаем С++ в отпуске! Посты будут выходить чуть реже, но все же будут и там запланированы несколько интересных тем.
Профессиональная карьера - это не только про непрерывную работу с 9 до 18, и вечер, занятый пилением пет-проектов. Имхо, но настоящий профессионал - человек, который знает, как грамотно отдыхать. И не имею ввиду просиживать штаны на работе.
Знаю кучу историй, когда люди не ходили в отпуск годами. Когда компания заставляла брать отпуск, а ребята брали его в выходные. Лишь бы ничего не пропустить. "А вдруг прод решит неожиданно заболеть?" Всегда надо быть на подхвате. "Да и какой отпуск вообще, С++ - это зизнь!!"
Что мы имеем в итоге? Человеку 30-40 лет, мир не видел, системные выгорания из-за переработок, перепады настроения, радикулит жопы из-за сидячей работы и дряблое тело из-за отсутствия активности. You name it.
Стратегия постоянного впахивания, конечно, имеет место быть и дает свои плоды. По-началу надо хреначить, чтобы выбиться из студенческой бедности и остальной серой массы, наконец устроиться на работу и начать приносить пользу.
Как только у вас есть приличное жилье и хорошая еда - давайте себе отдых. На самом деле все просто: загружены мозги? Не думай!
Сидеть в телефоне и смотреть видосики не катит. Мозг не отдыхает. Он продолжает анализировать большой объем информации. По итогу вы и не отдохнули, и ничего полезного не сделали.
На мой взгляд, есть 2 самых эффективных способа не думать: физическая работа и яркие впечатления.
80% всех наших клеток мозга - моторные нейроны, которые отвечают за движение и координацию. И только лишь небольшая часть отвечает за мыслительный процесс. Исследования четко показывают - занятие физическими нагрузками имеет долгосрочное позитивное влияние на когнитивные способности. Потому поход в зал - это ваши вложения не только в свое тело, но и в длительную и продуктивную карьеру.
Ну и яркие впечатления. Если вы посмотрите в ретроспективе на свою жизнь, то большинство ваших воспоминаний - какие-то яркие моменты из прошлого. Первое сальто с крыши гаража в снег, прыжок с парашютом, рождение ребенка - вот из чего состоит наша память. Эмоции так переливаются через край, что существуете только вы, этот момент и больше ничего. Ни тасок, ни дедлайнов, ни назойливых менеджеров. Такие события дают большой буст в жизненной энергии. Но не только. По итогу все рано или поздно понимают, что ради этих событий и стоит жить.
Отдыхайте, друзья. В будущем, скажете себе спасибо.
Be a professional. Stay cool.
#fun #commercial
Ребята, Грокаем С++ в отпуске! Посты будут выходить чуть реже, но все же будут и там запланированы несколько интересных тем.
Профессиональная карьера - это не только про непрерывную работу с 9 до 18, и вечер, занятый пилением пет-проектов. Имхо, но настоящий профессионал - человек, который знает, как грамотно отдыхать. И не имею ввиду просиживать штаны на работе.
Знаю кучу историй, когда люди не ходили в отпуск годами. Когда компания заставляла брать отпуск, а ребята брали его в выходные. Лишь бы ничего не пропустить. "А вдруг прод решит неожиданно заболеть?" Всегда надо быть на подхвате. "Да и какой отпуск вообще, С++ - это зизнь!!"
Что мы имеем в итоге? Человеку 30-40 лет, мир не видел, системные выгорания из-за переработок, перепады настроения, радикулит жопы из-за сидячей работы и дряблое тело из-за отсутствия активности. You name it.
Стратегия постоянного впахивания, конечно, имеет место быть и дает свои плоды. По-началу надо хреначить, чтобы выбиться из студенческой бедности и остальной серой массы, наконец устроиться на работу и начать приносить пользу.
Как только у вас есть приличное жилье и хорошая еда - давайте себе отдых. На самом деле все просто: загружены мозги? Не думай!
Сидеть в телефоне и смотреть видосики не катит. Мозг не отдыхает. Он продолжает анализировать большой объем информации. По итогу вы и не отдохнули, и ничего полезного не сделали.
На мой взгляд, есть 2 самых эффективных способа не думать: физическая работа и яркие впечатления.
80% всех наших клеток мозга - моторные нейроны, которые отвечают за движение и координацию. И только лишь небольшая часть отвечает за мыслительный процесс. Исследования четко показывают - занятие физическими нагрузками имеет долгосрочное позитивное влияние на когнитивные способности. Потому поход в зал - это ваши вложения не только в свое тело, но и в длительную и продуктивную карьеру.
Ну и яркие впечатления. Если вы посмотрите в ретроспективе на свою жизнь, то большинство ваших воспоминаний - какие-то яркие моменты из прошлого. Первое сальто с крыши гаража в снег, прыжок с парашютом, рождение ребенка - вот из чего состоит наша память. Эмоции так переливаются через край, что существуете только вы, этот момент и больше ничего. Ни тасок, ни дедлайнов, ни назойливых менеджеров. Такие события дают большой буст в жизненной энергии. Но не только. По итогу все рано или поздно понимают, что ради этих событий и стоит жить.
Отдыхайте, друзья. В будущем, скажете себе спасибо.
Be a professional. Stay cool.
#fun #commercial
{kind=link}
Отдых
Мы уже поговорили о том, что важно отдыхать. Но это было в контексте отпуска и такого, основательного релакса. Но знаете, какое самое крутое состояние? Когда тебе не нужен отпуск. Тебе базово очень нравится твоя жизнь и ты не доводишь себя до такой усталости, что уже вынужден уходить на долгий перерыв, чтобы не сгореть дотла.
Но как этого достигнуть?
Грамотное распределение рабочего времени и перерывов - один из способов.
У вас есть 8 часов рабочего времени. Дада, дорогие программисты. Ни 10 и ни 12. Хардворк энивеа вычеркиваем из списка своих жизненных девизов. Надо работать не тяжело, а с умом. Нам голову создатели придумали не только для того, чтобы в нее есть. Работать долго может только четко выстроенная система.
И в эти 8 часов нужно впихнуть весь обьем насущных задач. Цель - амбициозная и нетривиальная. Но умные дяди придумали некоторые схемы, которые помогут несколько систематизировать этот хаос.
Для начала нужно составлять план на день. Желательно письменно, но можно и в голове, если вы Джимми Нейтроны. Это помогает видеть конкретные цели, при достижении которых мозг выделит дофамин, давая вам приятные ощущения и мотивацию двигаться дальше. Вам же приятно закрывать тикеты в жире? С собственным микропланированием вы можете закрывать несколько задач за день! Сколько приятных эмоций от зачеркивания пунков в своем плане, мммм.
Далее - приоритизация задач. Схем существует куча, но приведу ту, которая мне больше всего нравится.
Разделяем весь спектр задач на простые, средние и тяжелые. Как только у вас появилось это разбиение, вы делаете не более 1 тяжелой задачи + не более 3-х средних задач + не более 5 легких задач в день. Схема 1+3+5.
Разделение задач по сложности - вполне соответствует реальности среднего рабочего дня. Нужно ответить на почту, создать задачи, провести собес, сходить на митинг и тд. Все это разные по затрате энергии действия и очевидно, что это нужно учитывать при планировании своего дня.
Вот мы получили шаблон, куда мы можем вставлять свои реальные задачи. Теперь осталось только понять, сколько по времени выполнять таски разной сложности, чтобы появился адекватный мэтчинг.
Обычно цифры такие: тяжелая задача - 3-4 часа, средняя - 30-40 мин, легкая - 10 мин.
Счетоводы уже все посчитали и напряглись: даже при максимальных цифрах пропадает 1 час. Куда он тратится?
На отдых
Какое бы у вас не было суперское внимание, оно понижается при непрерывной и вовлеченной работе.
Делайте себе перерывы.
Для тех, кто работает из офиса - это вполне органичная вещь. Пошел, кофеек с коллегой попил, мозги переключились, отдохнули и готовы разрывать эти ваши си-плюс-плюсы.
Но для удаленщиков перерывы не естественны. И парадокс в том, что именно им больше всего они и нужны! Отсутствие естественных отвлекающих факторов приводит к тому, что человек садится за стол в 9 и до вечера прожевывает пятой точкой дырку в этом стуле, зачастую без обеда. Кстати, ставь лайк, если пролеживаешь дырку в диване и зарабатываешь остеохондроз aka работаешь лежа(посмотрим сколько нас).
Завершил какой-то логический блок - отдохнул. Надолго застрял - отдохнул. Даже по гостам нужно делать перерывы. Да, может не так много суммарно. Но мы ж программисты. Мы тонкие и творческие личности🦋🌸. Нам можно.
Опять же. Этот пост - не руководство к действию, которое нужно выполнить в строгости. Мы, как и бизнес, должны быть agile и подстраивать свои концепции под ситуацию. Иногда надо и поработать побольше. Иногда, когда чувствуешь, что не вывозишь, отдохнуть побольше.
В общем, вроде простые рекомендации, но внедряя их вы ощущите всю мощь успешного успеха и расти будете не до синьора/лида/Илона Маска, а до самих просторов космоса.
Stay smarter. Stay cool.
#fun #commertial
Мы уже поговорили о том, что важно отдыхать. Но это было в контексте отпуска и такого, основательного релакса. Но знаете, какое самое крутое состояние? Когда тебе не нужен отпуск. Тебе базово очень нравится твоя жизнь и ты не доводишь себя до такой усталости, что уже вынужден уходить на долгий перерыв, чтобы не сгореть дотла.
Но как этого достигнуть?
Грамотное распределение рабочего времени и перерывов - один из способов.
У вас есть 8 часов рабочего времени. Дада, дорогие программисты. Ни 10 и ни 12. Хардворк энивеа вычеркиваем из списка своих жизненных девизов. Надо работать не тяжело, а с умом. Нам голову создатели придумали не только для того, чтобы в нее есть. Работать долго может только четко выстроенная система.
И в эти 8 часов нужно впихнуть весь обьем насущных задач. Цель - амбициозная и нетривиальная. Но умные дяди придумали некоторые схемы, которые помогут несколько систематизировать этот хаос.
Для начала нужно составлять план на день. Желательно письменно, но можно и в голове, если вы Джимми Нейтроны. Это помогает видеть конкретные цели, при достижении которых мозг выделит дофамин, давая вам приятные ощущения и мотивацию двигаться дальше. Вам же приятно закрывать тикеты в жире? С собственным микропланированием вы можете закрывать несколько задач за день! Сколько приятных эмоций от зачеркивания пунков в своем плане, мммм.
Далее - приоритизация задач. Схем существует куча, но приведу ту, которая мне больше всего нравится.
Разделяем весь спектр задач на простые, средние и тяжелые. Как только у вас появилось это разбиение, вы делаете не более 1 тяжелой задачи + не более 3-х средних задач + не более 5 легких задач в день. Схема 1+3+5.
Разделение задач по сложности - вполне соответствует реальности среднего рабочего дня. Нужно ответить на почту, создать задачи, провести собес, сходить на митинг и тд. Все это разные по затрате энергии действия и очевидно, что это нужно учитывать при планировании своего дня.
Вот мы получили шаблон, куда мы можем вставлять свои реальные задачи. Теперь осталось только понять, сколько по времени выполнять таски разной сложности, чтобы появился адекватный мэтчинг.
Обычно цифры такие: тяжелая задача - 3-4 часа, средняя - 30-40 мин, легкая - 10 мин.
Счетоводы уже все посчитали и напряглись: даже при максимальных цифрах пропадает 1 час. Куда он тратится?
На отдых
Какое бы у вас не было суперское внимание, оно понижается при непрерывной и вовлеченной работе.
Делайте себе перерывы.
Для тех, кто работает из офиса - это вполне органичная вещь. Пошел, кофеек с коллегой попил, мозги переключились, отдохнули и готовы разрывать эти ваши си-плюс-плюсы.
Но для удаленщиков перерывы не естественны. И парадокс в том, что именно им больше всего они и нужны! Отсутствие естественных отвлекающих факторов приводит к тому, что человек садится за стол в 9 и до вечера прожевывает пятой точкой дырку в этом стуле, зачастую без обеда. Кстати, ставь лайк, если пролеживаешь дырку в диване и зарабатываешь остеохондроз aka работаешь лежа(посмотрим сколько нас).
Завершил какой-то логический блок - отдохнул. Надолго застрял - отдохнул. Даже по гостам нужно делать перерывы. Да, может не так много суммарно. Но мы ж программисты. Мы тонкие и творческие личности🦋🌸. Нам можно.
Опять же. Этот пост - не руководство к действию, которое нужно выполнить в строгости. Мы, как и бизнес, должны быть agile и подстраивать свои концепции под ситуацию. Иногда надо и поработать побольше. Иногда, когда чувствуешь, что не вывозишь, отдохнуть побольше.
В общем, вроде простые рекомендации, но внедряя их вы ощущите всю мощь успешного успеха и расти будете не до синьора/лида/Илона Маска, а до самих просторов космоса.
Stay smarter. Stay cool.
#fun #commertial
{kind=link}
Ковариантные возвращаемые типы
Есть такое интересное понятие, о котором вы возможно ни разу не слышали. Пример из поста выше с методами clone и create можно было написать иначе:
Вы скажете: "Сигнатуры не совпадают! Код не скомпилируется!".
А я скажу: "Shape и Circle - ковариантные типы". С++ разрешает наследнику переопределять методы с возвращаемым типом, который является наследником типа метода из базового класса. Говорят, что это даже называется идиомой С++.
Какие юзкейсы у этой идиомы? По факту всего один. Представьте, что все методы возвращают один тип Shape. Вы создали объект Circle в куче и присвоили указатель на него к указателю на Circle. Тогда при клонировании объекта Circle вам вернется указатель на объект базового класса. И по хорошему его надо динамик кастить к Circle, чтобы работать с конкретным типом наследника. А это оверхэд:
Выглядит не очень. Посмотрим, как изменится код, если методы Circle будут возвращать указатель на Circle:
Выглядит намного лучше. Но вот вопрос: почему вы нигде не увидите в коде применения ковариантных типов?
Потому что этот подход не работает с умными указателями, которые де факто являются стандартом при возвращении объектов из фабрик. std::unique_ptr<Circle> не является наследником std::unique_ptr<Shape>, поэтому они и не ковариантные типы и сигнатуры методов будут несовместимы.
Возвращение сырых указателей - супер bad practice, один только этот факт заставляет отказаться от такого подхода.
Тем более полиморфные объекты и придумали для того, чтобы использовать их полиморфно. То есть через ссылку или указатель на базовый класс. Зачем оперировать полиморфным объектом с указателем на конкретный тип - не очень понятно.
Раньше, до изобретения умных указателей, идиома была легитимна. Теперь же она отправилась на свалку истории.
Только что вы прочитали очередную статью про совсем ненужную хрень. Ставьте 🗿, если ваше лицо сейчас на него похоже)
Stay poker-faced. Stay cool.
#fun #cppcore
Есть такое интересное понятие, о котором вы возможно ни разу не слышали. Пример из поста выше с методами clone и create можно было написать иначе:
class Shape {
public:
virtual ~Shape() { } // A virtual destructor
// ...
virtual Shape* clone() const = 0; // Uses the copy constructor
virtual Shape* create() const = 0; // Uses the default constructor
};
class Circle : public Shape {
public:
Circle* clone() const override;
Circle* create() const override;
// ...
};
Circle* Circle::clone() const { return new Circle(this); }
Circle* Circle::create() const { return new Circle(); }Вы скажете: "Сигнатуры не совпадают! Код не скомпилируется!".
А я скажу: "Shape и Circle - ковариантные типы". С++ разрешает наследнику переопределять методы с возвращаемым типом, который является наследником типа метода из базового класса. Говорят, что это даже называется идиомой С++.
Какие юзкейсы у этой идиомы? По факту всего один. Представьте, что все методы возвращают один тип Shape. Вы создали объект Circle в куче и присвоили указатель на него к указателю на Circle. Тогда при клонировании объекта Circle вам вернется указатель на объект базового класса. И по хорошему его надо динамик кастить к Circle, чтобы работать с конкретным типом наследника. А это оверхэд:
Circle *circle1 = new Circle();
Shape *shape = d1->clone();
Circle *circle2 = dynamic_cast<Circle *>(shape);
if(circle2) {
// Use circle2 here.
}
Выглядит не очень. Посмотрим, как изменится код, если методы Circle будут возвращать указатель на Circle:
Circle *circle1 = new Circle();
Circle *circle2 = d1->clone();
Выглядит намного лучше. Но вот вопрос: почему вы нигде не увидите в коде применения ковариантных типов?
Потому что этот подход не работает с умными указателями, которые де факто являются стандартом при возвращении объектов из фабрик. std::unique_ptr<Circle> не является наследником std::unique_ptr<Shape>, поэтому они и не ковариантные типы и сигнатуры методов будут несовместимы.
Возвращение сырых указателей - супер bad practice, один только этот факт заставляет отказаться от такого подхода.
Тем более полиморфные объекты и придумали для того, чтобы использовать их полиморфно. То есть через ссылку или указатель на базовый класс. Зачем оперировать полиморфным объектом с указателем на конкретный тип - не очень понятно.
Раньше, до изобретения умных указателей, идиома была легитимна. Теперь же она отправилась на свалку истории.
Только что вы прочитали очередную статью про совсем ненужную хрень. Ставьте 🗿, если ваше лицо сейчас на него похоже)
Stay poker-faced. Stay cool.
#fun #cppcore
{kind=link}
Найди летающих друзей
Сегодня будет не по С++ контент, но я не мог мимо этого пройти. Надеюсь вы сейчас никуда не спешите и у вас есть огнетушитель под рукой, будет жарко.
В общем, недавно в твиттере завирусился японский "'экспресс" тест на деменцию. Задача очень простая - найти на картинке бабочку, летучую мышь и утку. Все это надо сделать за 10 мин. Успели - молодцы. Не успели - скорее всего ваша разработческая карьера продлится не так долго, как вы этого ожидаете.
У меня не хватает усидчивости на такие штуки. Через 3 минуты безрезультатного поиска мне захотелось с криками "лайт вейт бэйбэээ" выкинуть что-нибудь тяжелое из окна и я понял, что пора залезать в комменты и ловить спойлеры. Буду верить, что раз я искал не 10 мин, это все не считается.
❤️ - нашел всех за 10 мин.
🤬 - где эта ср*ная бабочка?!
Keep calm. Stay cool.
#fun
Сегодня будет не по С++ контент, но я не мог мимо этого пройти. Надеюсь вы сейчас никуда не спешите и у вас есть огнетушитель под рукой, будет жарко.
В общем, недавно в твиттере завирусился японский "'экспресс" тест на деменцию. Задача очень простая - найти на картинке бабочку, летучую мышь и утку. Все это надо сделать за 10 мин. Успели - молодцы. Не успели - скорее всего ваша разработческая карьера продлится не так долго, как вы этого ожидаете.
У меня не хватает усидчивости на такие штуки. Через 3 минуты безрезультатного поиска мне захотелось с криками "лайт вейт бэйбэээ" выкинуть что-нибудь тяжелое из окна и я понял, что пора залезать в комменты и ловить спойлеры. Буду верить, что раз я искал не 10 мин, это все не считается.
❤️ - нашел всех за 10 мин.
🤬 - где эта ср*ная бабочка?!
Keep calm. Stay cool.
#fun
Теория заговора
Вот живет программист по С++ своей прекрасной и беззаботной жизнью. Все у него хорошо: код пишется, баги фиксятся, деньги мутятся. И имя у него такое прекрасное - Иннокентий.
Иногда он лазается по cppreference, чтобы освежить знания по каким-то фичам или узнать что-то новое. Представим себе, что он зашел просмотреть на доку std::atoi и видит там такой фрагмент:
Ничего необычного, просто определяется std::initializer_list<const char *> и записываются туда разные строки. Ну ладно, работает дальше.
А дальше ищет статейку по std::variant. И находит там вот какой отрывок:
Почему-то он обратил внимание на число 42. "Где-то я его уже видел.". И вспоминает, что недавно видел это же число в коде для std::atoi. Это, конечно, немного странно - подумал, он. Но решил, что это просто случайность.
Приходит наш герой домой с работы и, как каждый уважающий себя программист, вместо ужина садится писать свой пет-проект. А вы не знали, что программисты могут годами жить на диете "код+кофе"?
Пишет он какое-то многопоточное приложение. Чтобы адекватно писать такие штуки, нужны глубокие знания о модели памяти в С++ и как работает синхронизация данных в многопроцессорном мире. Поэтому кодер снова идет на cppreference и находит там статейку про std::memory_order. Читает, читает. И херак, вылупил глаза в экран. "Это уже очень странно". А увидел он следующий фрагмент:
Опять это 42! "Что за приколы такие? Это что, любимое число плюсовиков, что они его везде пихают?". На том и порешил. Не нервничать же по поводу чьего-то любимого числа. Может именно на этот день рождения Страуструпу подарили маленького щеночка....
В общем, затерпели и забыли.
Иннокентий только начинает писать свой проект и ему нужен хороший сборочный скрипт. Выбор языка пал на модномолодежный питухон, поэтому он полез в документацию изучать базовый синтаксис питона. И тут на тебе:
Whatafuck? Страуструп здесь уже никак не может быть замешан. Ситуация больше похожа на массонский заговор. Кенни не выдержал и пошел распутывать тайну века.
Оказалось, что это отсылка на книгу Дугласа Адамса "Автостопом по галактике". Там люди создали супермощный супекомпьютер только с одной целью - узнать ответ на "Главный вопрос жизни, Вселенной и всего такого". Этот вопрос настолько сложный и комплексный, что на нахождение ответа суперкомпьютер потратил целых 7.5 млн лет вычислений. И в окончании выдал: "42".
Роман вышел в период расцвета sci-fi, поэтому оставил глубокий отпечаток в массовой культуре. Оно появлялось в популярных сериалах типа "Остаться в живых". Даже один из радиотелескопов НАСА использует ровно 42 тарелки в честь отсылки к произведению.
Неудивительно, что гики по всему миру начали пихать это число во всех места в качестве пасхалки. Сейчас почти где-угодно встречая 42, вы можете быть на 99% уверены, что это именно отсылка на "Автостопом по галактике".
Так и была разгадана величайшая из тайн иллюминатов и Иннокентий довольный пошел спать. The end.
Make references to the great things. Stay cool.
#fun
Вот живет программист по С++ своей прекрасной и беззаботной жизнью. Все у него хорошо: код пишется, баги фиксятся, деньги мутятся. И имя у него такое прекрасное - Иннокентий.
Иногда он лазается по cppreference, чтобы освежить знания по каким-то фичам или узнать что-то новое. Представим себе, что он зашел просмотреть на доку std::atoi и видит там такой фрагмент:
const auto data =
{
"42",
"0x2A", // treated as "0" and junk "x2A", not as hexadecimal
"3.14159",
"31337 with words",
"words and 2",
"-012345",
"10000000000" // note: out of int32_t range
};
Ничего необычного, просто определяется std::initializer_list<const char *> и записываются туда разные строки. Ну ладно, работает дальше.
А дальше ищет статейку по std::variant. И находит там вот какой отрывок:
int main()
{
std::variant<int, float> v, w;
v = 42; // v contains int
int i = std::get<int>(v);
assert(42 == i); // succeeds
w = std::get<int>(v);
w = std::get<0>(v); // same effect as the previous line
w = v; // same effect as the previous line
...
}
Почему-то он обратил внимание на число 42. "Где-то я его уже видел.". И вспоминает, что недавно видел это же число в коде для std::atoi. Это, конечно, немного странно - подумал, он. Но решил, что это просто случайность.
Приходит наш герой домой с работы и, как каждый уважающий себя программист, вместо ужина садится писать свой пет-проект. А вы не знали, что программисты могут годами жить на диете "код+кофе"?
Пишет он какое-то многопоточное приложение. Чтобы адекватно писать такие штуки, нужны глубокие знания о модели памяти в С++ и как работает синхронизация данных в многопроцессорном мире. Поэтому кодер снова идет на cppreference и находит там статейку про std::memory_order. Читает, читает. И херак, вылупил глаза в экран. "Это уже очень странно". А увидел он следующий фрагмент:
std::vector<int> data;
std::atomic<int> flag = {0};
void thread_1()
{
data.push_back(42);
flag.store(1, std::memory_order_release);
}
Опять это 42! "Что за приколы такие? Это что, любимое число плюсовиков, что они его везде пихают?". На том и порешил. Не нервничать же по поводу чьего-то любимого числа. Может именно на этот день рождения Страуструпу подарили маленького щеночка....
В общем, затерпели и забыли.
Иннокентий только начинает писать свой проект и ему нужен хороший сборочный скрипт. Выбор языка пал на модномолодежный питухон, поэтому он полез в документацию изучать базовый синтаксис питона. И тут на тебе:
x = int(input("Please enter an integer: "))
Please enter an integer: 42
if x < 0:
x = 0
print('Negative changed to zero')
elif x == 0:
print('Zero')
elif x == 1:
print('Single')
else:
print('More')Whatafuck? Страуструп здесь уже никак не может быть замешан. Ситуация больше похожа на массонский заговор. Кенни не выдержал и пошел распутывать тайну века.
Оказалось, что это отсылка на книгу Дугласа Адамса "Автостопом по галактике". Там люди создали супермощный супекомпьютер только с одной целью - узнать ответ на "Главный вопрос жизни, Вселенной и всего такого". Этот вопрос настолько сложный и комплексный, что на нахождение ответа суперкомпьютер потратил целых 7.5 млн лет вычислений. И в окончании выдал: "42".
Роман вышел в период расцвета sci-fi, поэтому оставил глубокий отпечаток в массовой культуре. Оно появлялось в популярных сериалах типа "Остаться в живых". Даже один из радиотелескопов НАСА использует ровно 42 тарелки в честь отсылки к произведению.
Неудивительно, что гики по всему миру начали пихать это число во всех места в качестве пасхалки. Сейчас почти где-угодно встречая 42, вы можете быть на 99% уверены, что это именно отсылка на "Автостопом по галактике".
Так и была разгадана величайшая из тайн иллюминатов и Иннокентий довольный пошел спать. The end.
Make references to the great things. Stay cool.
#fun
{kind=link}
Квиз
Вчера в комментах наш подписчик Вячеслав скинул интересный примерчик, который здорово показывает вашу плюсовую интуицию. Поэтому захотелось разобрать его в рамках поста. Ну и для интереса предлагаю вам поучаствовать в #quiz и испытать свою интуицию. Код до боли краток, и до еще большей боли бессмысленен и ужасен. Но все же.
Какой будет результат попытки компиляции и запуска следующего кода?
Have a meaning in your life. Stay cool.
#fun
Вчера в комментах наш подписчик Вячеслав скинул интересный примерчик, который здорово показывает вашу плюсовую интуицию. Поэтому захотелось разобрать его в рамках поста. Ну и для интереса предлагаю вам поучаствовать в #quiz и испытать свою интуицию. Код до боли краток, и до еще большей боли бессмысленен и ужасен. Но все же.
Какой будет результат попытки компиляции и запуска следующего кода?
#include <iostream>
int main () {
std::cout << +-!!"" << std::endl;
return 0;
}
Have a meaning in your life. Stay cool.
#fun
Как узнать четное ли число
Вы сейчас подумали, типа "wtf, он шо нас за идиотов держит". Но погодите, щас все объясню.
Есть одно условие: нельзя использовать операции целочисленного деления и брать остаток от деления. Вот это уже задачка не для второклассников и обычный человек вряд ли с ней справится. Но программист может. Хотя и не любой, судя по моему небольшому опросу😆)
Сделайте паузу, скушайте твикс и подумайте. Знаю, что у нас крутое коммьюнити и все с легкостью решат эту задачу. Но если вдруг, вы не решили, то просто посидите на литкоде, там таких задачек навалом и вы довольно быстро выработаете интуицию к решению в принципе любых алгоритмических задач, включая такие.
В общем. Нужно просто проверить последний бит. Если он ноль - число четное, если нет - число нечетное. Все очень просто. Делается это с помощью битового & с единичкой.
Но во время написания этого поста мне пришла идея задать эту задачку ChatGPT, в тему недавнего поста про него. Правда я попросил сгенерировать 3 примера. Чисто из интереса. И результат меня сильно удивил. Все 3 примера были правильные, среди них было решение из абзаца выше, но было и еще 2, о которых я и не думал. После этого попросил нагенерить еще 2 примера. И они тоже были верные. Конечно, все из них использовали битовые операции, но как филигранно!
Очень интересно решение с битовым умножением на -2. Дело в том, что -2 в памяти компьютера представляется как 111...1110. Поэтому умножение любого числа на -2 будет давать то же самое число, только если последний бит был выставлен в 0.
Короче говоря решил с вами поделиться этим небольшим открытием. Просто еще один пример, что языковые модели реально могут в реально простые задачи. Ниже вы можете посмотреть все 5 способов решения. Некоторые правда пришлось все-таки подредактировать, но это мелочи.
Stay amazed. Stay cool.
#fun
Вы сейчас подумали, типа "wtf, он шо нас за идиотов держит". Но погодите, щас все объясню.
Есть одно условие: нельзя использовать операции целочисленного деления и брать остаток от деления. Вот это уже задачка не для второклассников и обычный человек вряд ли с ней справится. Но программист может. Хотя и не любой, судя по моему небольшому опросу😆)
Сделайте паузу, скушайте твикс и подумайте. Знаю, что у нас крутое коммьюнити и все с легкостью решат эту задачу. Но если вдруг, вы не решили, то просто посидите на литкоде, там таких задачек навалом и вы довольно быстро выработаете интуицию к решению в принципе любых алгоритмических задач, включая такие.
В общем. Нужно просто проверить последний бит. Если он ноль - число четное, если нет - число нечетное. Все очень просто. Делается это с помощью битового & с единичкой.
Но во время написания этого поста мне пришла идея задать эту задачку ChatGPT, в тему недавнего поста про него. Правда я попросил сгенерировать 3 примера. Чисто из интереса. И результат меня сильно удивил. Все 3 примера были правильные, среди них было решение из абзаца выше, но было и еще 2, о которых я и не думал. После этого попросил нагенерить еще 2 примера. И они тоже были верные. Конечно, все из них использовали битовые операции, но как филигранно!
Очень интересно решение с битовым умножением на -2. Дело в том, что -2 в памяти компьютера представляется как 111...1110. Поэтому умножение любого числа на -2 будет давать то же самое число, только если последний бит был выставлен в 0.
Короче говоря решил с вами поделиться этим небольшим открытием. Просто еще один пример, что языковые модели реально могут в реально простые задачи. Ниже вы можете посмотреть все 5 способов решения. Некоторые правда пришлось все-таки подредактировать, но это мелочи.
Stay amazed. Stay cool.
#fun
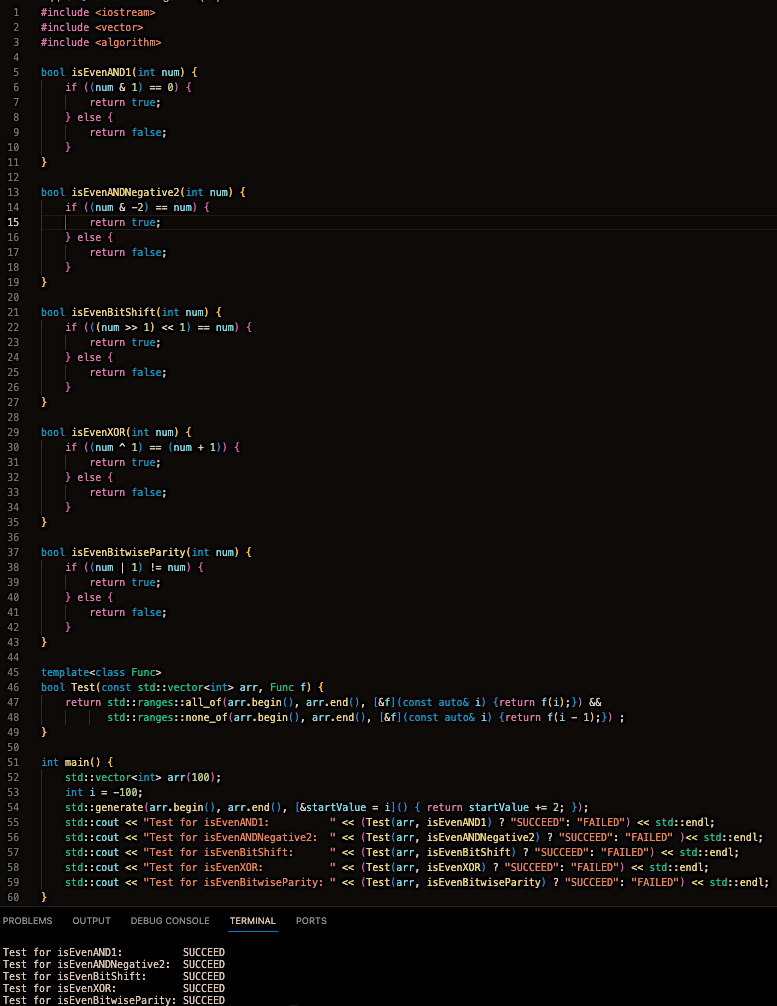{kind=link}
Достигаем недостижимое
В прошлом посте вот такой код:
Приводил к очень неожиданным сайд-эффектам. При его компиляции клангом выводился принт, хотя в функции main мы нигде не вызываем unreachable.
Темная магия это или проделки ГосДепа узнаем дальше.
Для начала, этот код содержит UB. Согласно стандарту программа должна производить какие-то обозримые эффекты. Или завершиться, или работать с вводом-выводом, или работать с volatile переменными, или выполнять синхронизирующие операции. Это требования forward progress. Если программа ничего из этого не делает - код содержит UB.
Так вот у нас пустой бесконечный цикл. То есть предполагается, что он будет работать бесконечно и ничего полезного не делать.
Тут очень важно понять одну вещь. Компилятор следует не вашей логике и ожиданиям, как должна работать программа. У него есть фактически инструкция(стандарт), которой он следует.
По стандарту программа, содержащая бесконечные циклы без side-эффектов, содержит UB и компилятор имеет право делать с этим циклом все, что ему захочется.
В данном случае он просто удаляет цикл. Но он не только удаляет цикл. Но еще и удаляет инструкцию возврата из main.
В нормальных программах функция main в ассемблере представляет из себя следующее:
ret - инструкция возврата из функции. И код функции main выполняется, пока не достигнет этой инструкции.
Так вот в нашем случае этой инструкции нет и код продолжает выполнение дальше. А дальше у нас очень удобненько расположилась функция с принтом, вывод которой мы и видим. Выглядит это так:
Почему удаляется return - не так уж очевидно и для самих разработчиков компилятора. У них есть тред обсуждения этого вопроса, который не привел к какому-то знаменателю. Так что не буду городить догадок.
Справедливости ради стоит сказать, что в 19-м шланге поменяли это поведение и теперь таких неожиданностей нет.
Stay predictable. Stay cool.
#fun #cppcore #compiler
В прошлом посте вот такой код:
int main() {
while(1);
return 0;
}
void unreachable() {
std::cout << "Hello, World!" << std::endl;
}Приводил к очень неожиданным сайд-эффектам. При его компиляции клангом выводился принт, хотя в функции main мы нигде не вызываем unreachable.
Темная магия это или проделки ГосДепа узнаем дальше.
Для начала, этот код содержит UB. Согласно стандарту программа должна производить какие-то обозримые эффекты. Или завершиться, или работать с вводом-выводом, или работать с volatile переменными, или выполнять синхронизирующие операции. Это требования forward progress. Если программа ничего из этого не делает - код содержит UB.
Так вот у нас пустой бесконечный цикл. То есть предполагается, что он будет работать бесконечно и ничего полезного не делать.
Тут очень важно понять одну вещь. Компилятор следует не вашей логике и ожиданиям, как должна работать программа. У него есть фактически инструкция(стандарт), которой он следует.
По стандарту программа, содержащая бесконечные циклы без side-эффектов, содержит UB и компилятор имеет право делать с этим циклом все, что ему захочется.
В данном случае он просто удаляет цикл. Но он не только удаляет цикл. Но еще и удаляет инструкцию возврата из main.
В нормальных программах функция main в ассемблере представляет из себя следующее:
main:
// Perform some code
ret
ret - инструкция возврата из функции. И код функции main выполняется, пока не достигнет этой инструкции.
Так вот в нашем случае этой инструкции нет и код продолжает выполнение дальше. А дальше у нас очень удобненько расположилась функция с принтом, вывод которой мы и видим. Выглядит это так:
main:
unreachable():
push rax
mov rdi, qword ptr [rip + std::cout@GOTPCREL]
lea rsi, [rip + .L.str]
call std::basic_ostream<char, std::char_traits<char>>...
Почему удаляется return - не так уж очевидно и для самих разработчиков компилятора. У них есть тред обсуждения этого вопроса, который не привел к какому-то знаменателю. Так что не буду городить догадок.
Справедливости ради стоит сказать, что в 19-м шланге поменяли это поведение и теперь таких неожиданностей нет.
Stay predictable. Stay cool.
#fun #cppcore #compiler
{kind=link}
Программа без main?
Все мы знаем, что функция main - входная точка в программу. С нее начинается исполнение программы, если не считать глобальные переменные.
Без функции main программа просто не запустится.
Или нет?
Может быть мы можем что-нибудь нахимичить, чтобы, например, написать Hello, World без main?
Оказывается, можем. Однако, естественно, это все непереносимо. Но она на то и магия, что у разных магов свои заклинания.
Скомпилируем вот такую программу под gcc с флагом -nostartfiles:
И на консоли появится наша горячо-любимая надпись:
Для любителей поиграться с кодом вот вам ссылочка на годболт.
А вот что за такая функция _start и какой все-таки код выполняется до main, мы поговорим в следующий раз.
Make impossible things. Stay cool.
#fun #cppcore
Все мы знаем, что функция main - входная точка в программу. С нее начинается исполнение программы, если не считать глобальные переменные.
Без функции main программа просто не запустится.
Или нет?
Может быть мы можем что-нибудь нахимичить, чтобы, например, написать Hello, World без main?
Оказывается, можем. Однако, естественно, это все непереносимо. Но она на то и магия, что у разных магов свои заклинания.
Скомпилируем вот такую программу под gcc с флагом -nostartfiles:
#include <iostream>
int my_fun();
void _start()
{
int x = my_fun();
exit(x);
}
int my_fun()
{
std::cout << "Hello, World!\n";
return 0;
}
И на консоли появится наша горячо-любимая надпись:
Hello, World!Для любителей поиграться с кодом вот вам ссылочка на годболт.
А вот что за такая функция _start и какой все-таки код выполняется до main, мы поговорим в следующий раз.
Make impossible things. Stay cool.
#fun #cppcore
{kind=link}