Еще один способ сделать new небросающим
#опытным
Дело в том, что new - не совсем ответственнен за поведение при недостатке памяти. По плюсовой традиции тут можно кастомизировать почти все. Встречайте: std::new_handler.
Это такой typedef'чик:
И алиас для функций, которые отвечают за обработку ситуации нехватки памяти. И вызываются они аллоцирующими функциями operator new и operator new[].
Чтобы установить такой хэдлер используется функция std::set_new_handler:
Она делает new_p новой глобальной функцией нового обработчика и возвращает ранее установленный обработчик.
Предполагаемое назначение хэндлера - одна из трех вещей:
1️⃣ Сделать больше памяти доступной. (За гранью фантастики)
2️⃣ Залогировать проблему и завершить программу (например, вызовом std::terminate) +. Если вам плевать на graceful shutdown, то ок.
3️⃣ Кинуть исключение типа std::bad_alloc или его отпрысков с какой-нибудь кастомной надписью и/или залогировать проблему.
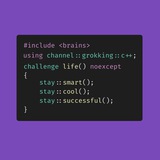
Раз std::new_handler - алиас на указатель функции, то что будет, если мы передадим nullptr в качестве хэндлера?
На самом деле это и делается по умолчанию. При старте программы nullptr выставляется в качестве хэндлера. При невозможности выделить память operator new вызывает std::get_new_handler. Если указатель на функцию нулевой, то в этом случае new ведет себя дефолтно - просто кидает исключение std::bad_alloc. В ином случае вызывает хэндлер.
С обработчиками есть один нюанс.
Если обработчик успешно заканчивает работу(то есть из него не вызван terminate или не брошено исключение), то operator new повторяет ранее неудачную попытку выделения и снова вызывает обработчик, если выделение снова не удается. Чтобы закончить цикл, new-handler может вызвать std::set_new_handler(nullptr): если после неудачной попытки new обнаружит, что std::get_new_handler возвращает нулевое значение указателя и выбросит std::bad_alloc.
Примерно так это работает:
Пользуйтесь фичей, чтобы оставлять на проде девопсерам сообщение: "А че так мало памяти в конфиге пода прописано, мм?"
Спасибо @Nikseas_314 за идею для поста)
Customize your tools. Stay cool.
#memory #cppcore
#опытным
Дело в том, что new - не совсем ответственнен за поведение при недостатке памяти. По плюсовой традиции тут можно кастомизировать почти все. Встречайте: std::new_handler.
Это такой typedef'чик:
typedef void (*new_handler)();
И алиас для функций, которые отвечают за обработку ситуации нехватки памяти. И вызываются они аллоцирующими функциями operator new и operator new[].
Чтобы установить такой хэдлер используется функция std::set_new_handler:
std::new_handler set_new_handler(std::new_handler new_p) noexcept;
Она делает new_p новой глобальной функцией нового обработчика и возвращает ранее установленный обработчик.
Предполагаемое назначение хэндлера - одна из трех вещей:
1️⃣ Сделать больше памяти доступной. (За гранью фантастики)
2️⃣ Залогировать проблему и завершить программу (например, вызовом std::terminate) +. Если вам плевать на graceful shutdown, то ок.
3️⃣ Кинуть исключение типа std::bad_alloc или его отпрысков с какой-нибудь кастомной надписью и/или залогировать проблему.
Раз std::new_handler - алиас на указатель функции, то что будет, если мы передадим nullptr в качестве хэндлера?
На самом деле это и делается по умолчанию. При старте программы nullptr выставляется в качестве хэндлера. При невозможности выделить память operator new вызывает std::get_new_handler. Если указатель на функцию нулевой, то в этом случае new ведет себя дефолтно - просто кидает исключение std::bad_alloc. В ином случае вызывает хэндлер.
С обработчиками есть один нюанс.
Если обработчик успешно заканчивает работу(то есть из него не вызван terminate или не брошено исключение), то operator new повторяет ранее неудачную попытку выделения и снова вызывает обработчик, если выделение снова не удается. Чтобы закончить цикл, new-handler может вызвать std::set_new_handler(nullptr): если после неудачной попытки new обнаружит, что std::get_new_handler возвращает нулевое значение указателя и выбросит std::bad_alloc.
Примерно так это работает:
void handler()
{
std::cout << "Memory allocation failed, terminating\n";
std::set_new_handler(nullptr);
}
int main()
{
std::set_new_handler(handler);
try
{
while (true)
{
new int [1000'000'000ul] ();
}
}
catch (const std::bad_alloc& e)
{
std::cout << e.what() << '\n';
}
}
Пользуйтесь фичей, чтобы оставлять на проде девопсерам сообщение: "А че так мало памяти в конфиге пода прописано, мм?"
Спасибо @Nikseas_314 за идею для поста)
Customize your tools. Stay cool.
#memory #cppcore
Почему мы везде не используем nothrow new?
#опытным
В прошлый раз мы обсудили, что существует форма оператора new, которая не возбуждает исключений, а вместо этого при ошибке возвращает нулевой указатель. Однако я почему-то уверен, что большинство из вас впервые увидели эту форму. Почему же ее практически нигде не используют?
1️⃣ В современных плюсах вообще не часто можно увидеть прямой вызов new. Контейнеры и функции helper'ы std::make_* инкапсулируют в себе аллокации. Внутри них вызывается обычный бросающий new. Только в очень специфических кейсах явный вызов new оправдан. Поэтому пул примеров в принципе очень небольшой.
2️⃣ Представьте, что у вас закончилась память и nothrow new вернул вас nullptr. Можете ли вы локально обработать ошибку недостатка памяти? 99.9%, что нет. Поэтому вы будете вести эту ошибку по всему стеку вызовов до того места, где ее возможно обработать. То есть весь проект должен быть построен с учетом возможности возврата ошибки и постоянной проверкой этих ошибок.
3️⃣ И все же есть те люди, которых устраивает такая форма проекта с возвратом ошибки из функции и постоянной ее проверкой. Но если немного подумать, то выяснится, что очень часто ошибку недостатка памяти вы примерно никак не сможете обработать, кроме как напишите об этом в лог и завершите приложение. То есть, шо словите вы std::bad_alloc, шо просто напишите об этом в лог - разница не большая.
Раз разница небольшая, мы можем обработать ошибку только на определенном слое приложения, а исключения предоставляют возможность централизованной их обработки, то давайте только там и поставим эту обработку. В одном единственном месте. Скорее всего это будет где-то в функции main или в главной функции потока.
Сейчас может начаться холивар "исключения vs объекты ошибок". Но вряд ли можно отрицать, что работать с bad_alloc исключением банально проще, чем обрабатывать nullptr. Именно поэтому вы скорее всего вообще не увидите nothrow new.
Handle problems easily. Stay cool.
#cppcore
#опытным
В прошлый раз мы обсудили, что существует форма оператора new, которая не возбуждает исключений, а вместо этого при ошибке возвращает нулевой указатель. Однако я почему-то уверен, что большинство из вас впервые увидели эту форму. Почему же ее практически нигде не используют?
1️⃣ В современных плюсах вообще не часто можно увидеть прямой вызов new. Контейнеры и функции helper'ы std::make_* инкапсулируют в себе аллокации. Внутри них вызывается обычный бросающий new. Только в очень специфических кейсах явный вызов new оправдан. Поэтому пул примеров в принципе очень небольшой.
2️⃣ Представьте, что у вас закончилась память и nothrow new вернул вас nullptr. Можете ли вы локально обработать ошибку недостатка памяти? 99.9%, что нет. Поэтому вы будете вести эту ошибку по всему стеку вызовов до того места, где ее возможно обработать. То есть весь проект должен быть построен с учетом возможности возврата ошибки и постоянной проверкой этих ошибок.
3️⃣ И все же есть те люди, которых устраивает такая форма проекта с возвратом ошибки из функции и постоянной ее проверкой. Но если немного подумать, то выяснится, что очень часто ошибку недостатка памяти вы примерно никак не сможете обработать, кроме как напишите об этом в лог и завершите приложение. То есть, шо словите вы std::bad_alloc, шо просто напишите об этом в лог - разница не большая.
Раз разница небольшая, мы можем обработать ошибку только на определенном слое приложения, а исключения предоставляют возможность централизованной их обработки, то давайте только там и поставим эту обработку. В одном единственном месте. Скорее всего это будет где-то в функции main или в главной функции потока.
Сейчас может начаться холивар "исключения vs объекты ошибок". Но вряд ли можно отрицать, что работать с bad_alloc исключением банально проще, чем обрабатывать nullptr. Именно поэтому вы скорее всего вообще не увидите nothrow new.
Handle problems easily. Stay cool.
#cppcore
{kind=link}
Ограничения в конструировании POD типов
#опытным
Довольно часто приходится работать с plain old data типами. Они не имеют никаких специальных методов и конструкторов, это просто структуры с полями. Например:
Создают объекты таких типов с помощью синтаксиса универсальной инициализации через фигурные скобки {}:
При этом через круглые скобки создать объект такого класса нельзя.
С повсеместным использованием универсальной инициализации с точки зрения код стайла создание таких объектов даже не выбивается из общего кода.
Но все-таки у этого есть проблемы.
Часто такие структурки хочется хранить в каком-нибудь векторе. Для добавления в вектор можно использовать push_back и emplace_back. Использование emplace_back выгоднее по перформансу, поэтому нужно обычно использовать именно этот метод.
Но с POD типами он работает хреново.
Вот так вы написать не можете. emplace_back под капотом использует создание объекта с помощью new именно через круглые скобки. А как мы помним, так инициализировать POD типы нельзя.
Поэтому приходится в этих случаях явно конструировать объект и вызывать мув-конструктор:
что убивает преимущества emplace_back перед push_back. Либо можно использовать непросредственно push_back.
Та же проблемы и в использовании функций std::make_*. Под капотом они тоже используют new с круглыми скобками и просто невозможно нормально использовать эти функции. Приходится явно вызывать new с фигурными скобками, что усугубляет проблему:
Конечно кейс с emplace_back намного чаще встречается в практике. POD типам не нужны фабличные методы и, обычно, контроль времени жизни.
В общем, не жизнь, а страдания.
Однако есть свет в конце тоннеля! Но об этом в следующий раз.
See the light. Stay cool.
#cppcore
#опытным
Довольно часто приходится работать с plain old data типами. Они не имеют никаких специальных методов и конструкторов, это просто структуры с полями. Например:
struct Point {
int x;
int y;
int z;
}Создают объекты таких типов с помощью синтаксиса универсальной инициализации через фигурные скобки {}:
Point p{1, 2, 3};
Point p(1, 2, 3); // WrongПри этом через круглые скобки создать объект такого класса нельзя.
С повсеместным использованием универсальной инициализации с точки зрения код стайла создание таких объектов даже не выбивается из общего кода.
Но все-таки у этого есть проблемы.
Часто такие структурки хочется хранить в каком-нибудь векторе. Для добавления в вектор можно использовать push_back и emplace_back. Использование emplace_back выгоднее по перформансу, поэтому нужно обычно использовать именно этот метод.
Но с POD типами он работает хреново.
std::vector<Point> vec;
vec.emplace_back(1, 2, 3); // Error!
Вот так вы написать не можете. emplace_back под капотом использует создание объекта с помощью new именно через круглые скобки. А как мы помним, так инициализировать POD типы нельзя.
Поэтому приходится в этих случаях явно конструировать объект и вызывать мув-конструктор:
vec.emplace_back(Point{1, 2, 3});что убивает преимущества emplace_back перед push_back. Либо можно использовать непросредственно push_back.
Та же проблемы и в использовании функций std::make_*. Под капотом они тоже используют new с круглыми скобками и просто невозможно нормально использовать эти функции. Приходится явно вызывать new с фигурными скобками, что усугубляет проблему:
std::unique_ptr<Point>(new Point{1, 2, 3}); Конечно кейс с emplace_back намного чаще встречается в практике. POD типам не нужны фабличные методы и, обычно, контроль времени жизни.
В общем, не жизнь, а страдания.
Однако есть свет в конце тоннеля! Но об этом в следующий раз.
See the light. Stay cool.
#cppcore
{kind=link}
Фиксим проблему с конструированием POD типов
#опытным
В прошлом посте говорили о том, что тяжело POD типам работать с функциями, которые внутри себя вызывают new. Клятые скобки!
Это очевидные недоработки стандарта. Которые взяли и пофиксили в С++20!
Теперь объекты POD типов можно создавать как через фигурные скобки, так и через круглые. Хотя небольшая разница есть. Но это уже супердетали:
Теперь можно использовать все преимущества метода emplace_back и писать такой код:
Вроде мелочь, а раньше это выбивало из колеи. Правило almost always use emplace_back здесь не работало.
Давайте добавлю еще чуть больше контекста(и своей боли) про emplace_back vs push_back.
Что было до с++20.
push_back спокойно переваривал следующий код:
Он принимает аргументом уже сконструированный объект нужного типа. И компилятору достаточно знаний о типе вектора и фирурных скобок, чтобы понять, как конструируется объект.
Как видите здесь нет явного указания типа. И это работало до 20-х плюсов и было причиной делать исключения для правила с emplace_back'ом. Сравните:
Больше букав! А если название структуры длинное? Вот вот.
Тут либо нужно было отходить от правила везде использования emplace_back, либо постоянно вписывать конструктор в аргументы вызова emplace_back, либо определять совершенно тривиальные и от этого не несущие полезной логики конструкторы.
Благо теперь наши пальцы сильнее защищены от стачивания, что не может не радовать!
Кстати, с С++20 и сам термин POD стал помечаться устаревшим, теперь его заменили более тонкие типы TrivialType, ScalarType, и StandardLayoutType. Ну и функции std::make_* тоже работают как надо с простыми структурами.
Enjoy small things. Stay cool.
#cppcore #cpp20
#опытным
В прошлом посте говорили о том, что тяжело POD типам работать с функциями, которые внутри себя вызывают new. Клятые скобки!
Это очевидные недоработки стандарта. Которые взяли и пофиксили в С++20!
Теперь объекты POD типов можно создавать как через фигурные скобки, так и через круглые. Хотя небольшая разница есть. Но это уже супердетали:
struct A {
int a;
int&& r;
};
int f();
int n = 10;
A a1{1, f()}; // OK, lifetime is extended
A a2(1, f()); // well-formed, but dangling reference
A a3{1.0, 1}; // error: narrowing conversion
A a4(1.0, 1); // well-formed, but dangling reference
A a5(1.0, std::move(n)); // OKТеперь можно использовать все преимущества метода emplace_back и писать такой код:
std::vector<Point> vec;
vec.emplace_back(1, 2, 3);
Вроде мелочь, а раньше это выбивало из колеи. Правило almost always use emplace_back здесь не работало.
Давайте добавлю еще чуть больше контекста(и своей боли) про emplace_back vs push_back.
Что было до с++20.
push_back спокойно переваривал следующий код:
std::vector<Point> vec;
vec.push_back({1, 2, 3});
Он принимает аргументом уже сконструированный объект нужного типа. И компилятору достаточно знаний о типе вектора и фирурных скобок, чтобы понять, как конструируется объект.
Как видите здесь нет явного указания типа. И это работало до 20-х плюсов и было причиной делать исключения для правила с emplace_back'ом. Сравните:
std::vector<Point> vec;
vec.push_back({1, 2, 3});
vec.emplace_back(Point{1, 2, 3});
Больше букав! А если название структуры длинное? Вот вот.
Тут либо нужно было отходить от правила везде использования emplace_back, либо постоянно вписывать конструктор в аргументы вызова emplace_back, либо определять совершенно тривиальные и от этого не несущие полезной логики конструкторы.
Благо теперь наши пальцы сильнее защищены от стачивания, что не может не радовать!
Кстати, с С++20 и сам термин POD стал помечаться устаревшим, теперь его заменили более тонкие типы TrivialType, ScalarType, и StandardLayoutType. Ну и функции std::make_* тоже работают как надо с простыми структурами.
Enjoy small things. Stay cool.
#cppcore #cpp20
{kind=link}
Когда мы вынуждены явно использовать new
#опытным
Сырые указатели - фуфуфу, бееее. Это не вкусно, мы такое не едим. new expression возвращает сырой указатель на объект. Соотвественно, мы должны максимально избегать явного использования new. У нас все-таки умные указатели и функции std::make_* довольно давно завезли.
Однако все-таки есть кейсы, когда мы просто вынуждены использовать new явно:
👉🏿 std::make_unique не может в кастомные делитеры. Если хотите создать уникальный указатель со своим удалителем - придется использовать new.
👉🏿 Приватный конструктор у класса. Странно вообще пытаться создать объект такого класса, но не торопитесь. Приватный конструктор может быть нужен, чтобы оставить только один легальный способ создания объекта - фабричную функцию Create. Она возвращает уникальный указатель на объект и обычно является статическим членом класса. Функция Create имеет доступ к приватным методам, поэтому может вызвать конструктор. Но вот std::make_unique ничего не знает о приватных методах класса и не сможет создать объект. Придется использовать new.
👉🏿 Жизнь без 20-го стандарта. До 20-го стандарта вы не могли создать объект POD класса без указания фигурных скобок. Но именно так и делает std::make_unique.
То есть вот так нельзя делать в С++17:
Но можно в С++20. Так что тем, кто необновился, придется использовать new.
В целом, все. Если что забыл - накидайте в комменты.
Но помимо этого, администрация этого канала не рекомендует в домашних и рабочих условиях явно вызывать new. Это может привести к потери конечности(отстрелу ноги).
Stay safe. Stay cool.
#cppcore #memory #cpp20 #cpp17
#опытным
Сырые указатели - фуфуфу, бееее. Это не вкусно, мы такое не едим. new expression возвращает сырой указатель на объект. Соотвественно, мы должны максимально избегать явного использования new. У нас все-таки умные указатели и функции std::make_* довольно давно завезли.
Однако все-таки есть кейсы, когда мы просто вынуждены использовать new явно:
👉🏿 std::make_unique не может в кастомные делитеры. Если хотите создать уникальный указатель со своим удалителем - придется использовать new.
auto ptr = std::unique_ptr<int, void()(int*)>(new int(42), [](int* p) {
delete p;
std::cout << "Custom deleter called!\n";
});👉🏿 Приватный конструктор у класса. Странно вообще пытаться создать объект такого класса, но не торопитесь. Приватный конструктор может быть нужен, чтобы оставить только один легальный способ создания объекта - фабричную функцию Create. Она возвращает уникальный указатель на объект и обычно является статическим членом класса. Функция Create имеет доступ к приватным методам, поэтому может вызвать конструктор. Но вот std::make_unique ничего не знает о приватных методах класса и не сможет создать объект. Придется использовать new.
struct Class {
static std::unique_ptr<Class> Create() {
// return std::make_unique<Class>(); // It will fail.
return std::unique_ptr<Class>(new Class);
}
private:
Class() {}
};👉🏿 Жизнь без 20-го стандарта. До 20-го стандарта вы не могли создать объект POD класса без указания фигурных скобок. Но именно так и делает std::make_unique.
То есть вот так нельзя делать в С++17:
struct MyStruct {
int a, b, c;
};
auto ptr = std::make_unique<MyStruct>(1, 2, 3); // Will fail C++17
auto ptr = std::unique_ptr<MyStruct>(new MyStruct{1, 2, 3}); // NormНо можно в С++20. Так что тем, кто необновился, придется использовать new.
В целом, все. Если что забыл - накидайте в комменты.
Но помимо этого, администрация этого канала не рекомендует в домашних и рабочих условиях явно вызывать new. Это может привести к потери конечности(отстрелу ноги).
Stay safe. Stay cool.
#cppcore #memory #cpp20 #cpp17
{kind=link}
Проблемы С-style массивов
#опытным
В наследство от языка С С++ достались статические массивы. Так называемые С-style массивы. Это проверенные средства языка, успешно решающие свои задачи. Но у них есть серьезные недостатки, которые в основном связаны с низкоуровневостью этого инструмента.
Давайте кратко повторим, что такое C-style массив.
Это непрерывная последовательность элементов одного типа и память под них выделяется на стеке(или реже в статический области, если массив глобальный) и автоматически освобождается при выходе из функции.
Определяется сишный массив вот так:
Размер памяти, занимаемый массивом равняется количеству его элементов помноженному на размер типа данных:
Соответственно, для получения количества элементов массива, нужно поделить sizeof от массива на размер типа данных, которые он хранит.
В чем же его недостатки?
❗️ Массивы нельзя сравнивать напрямую, а только поэлементно. Напрямую сравниваются указатели на первый элемент.
❗️ Мимикрирование под массивы разрешает странную семантику с условиями и арифметическими операциями.
❗️В С разрешены [массивы переменной длины](https://t.me/grokaemcpp/56) на уровне стандарта. И синтаксис у них ровно такой же, как и у статических массивов, только при его создании размер указывается не константой, а переменной. В С++ это не стандартная фича, а расширения компилятора. То есть нельзя писать кроссплатформенный код с использованием массивов переменной длины. Но за счет идентичного синтаксиса очень легко спутать один вид массива с другим и похерить переменосимость.
❗️ От синтаксиса сочетания функций и массивов хочется вырвать себе глаза, закрыть компьютер и уйти жить в лес:
❗️Массив не инкапсулирует в себе свой размер. Его нужно всегда вычислять, как мы говорили в начале.
❗️Из-за сложности синтаксиса, вы скорее всего захотите обрабатывать массивы с помощью функций с похожей сигнатурой:
Это потенциально может привести к доступу за границы выделенной области, так как функция foo ничего не знает про то, какой реальный размер имеет область памяти, на которую указывает
В общем, сишные массивы - это не объекты и не обладают преимуществами ООП и универсальной семантики для объектов в С++.
Поэтому стандартная библиотека предоставляет нам инструмент, который решает все проблемы C-style массивов. Это контейнер std::array. О нем мы поговорим в следующий раз.
Upgrade your tools. Stay cool.
#cppcore #goodoldc
#опытным
В наследство от языка С С++ достались статические массивы. Так называемые С-style массивы. Это проверенные средства языка, успешно решающие свои задачи. Но у них есть серьезные недостатки, которые в основном связаны с низкоуровневостью этого инструмента.
Давайте кратко повторим, что такое C-style массив.
Это непрерывная последовательность элементов одного типа и память под них выделяется на стеке(или реже в статический области, если массив глобальный) и автоматически освобождается при выходе из функции.
Определяется сишный массив вот так:
// создаем массив на 5 элементов,
// которые базово инициализируются мусором
int arr1[5];
// создаем массив на 5 элементов,
// которые инициализируются нулями
int arr1[5]{};
// создаем массив и предоставляем набор элементов, с помощью
// которых компилятор вычисляет длину массива и инициализирует элементы
int arr2[] = {1, 2, 3, 4, 5};
Размер памяти, занимаемый массивом равняется количеству его элементов помноженному на размер типа данных:
constexpr size_t array_size = 5;
int arr[array_size];
sizeof(arr) == array_size * sizeof(int); // true
Соответственно, для получения количества элементов массива, нужно поделить sizeof от массива на размер типа данных, которые он хранит.
auto array_size = sizeof(arr) / sizeof(Type);
В чем же его недостатки?
❗️ Массивы нельзя сравнивать напрямую, а только поэлементно. Напрямую сравниваются указатели на первый элемент.
int arr1[] = {0, 1, 2, 3};
int arr2[] = {0, 1, 2, 3};
// ложь так как сраниваются указатели,
// а они разные для разных объектов
arr1 == arr2; ❗️ Мимикрирование под массивы разрешает странную семантику с условиями и арифметическими операциями.
// создаем пустую строку в виде массива
char arr[] = "";
// условие будет всегда true, хотя мы создали пустую строку
if (arr);
// разрешается, но зачем? что значит прибавить к массиву число?
arr + 1;
❗️В С разрешены [массивы переменной длины](https://t.me/grokaemcpp/56) на уровне стандарта. И синтаксис у них ровно такой же, как и у статических массивов, только при его создании размер указывается не константой, а переменной. В С++ это не стандартная фича, а расширения компилятора. То есть нельзя писать кроссплатформенный код с использованием массивов переменной длины. Но за счет идентичного синтаксиса очень легко спутать один вид массива с другим и похерить переменосимость.
❗️ От синтаксиса сочетания функций и массивов хочется вырвать себе глаза, закрыть компьютер и уйти жить в лес:
int foo(int arr[4]);
// На самом деле такая сигнатура полностью эквивалентна int foo(int * arr),
// что позволяет принимать в функцию массив любой длины и указатели.
// В С++ нет синтаксиса приема массива по значению.
void foo(int (&arr)[4]); // зато есть синтаксис приема массива по ссылке
// Нормального синтаксиса для возврата массива из функции также не завезли.
// Вот воркэраунды.
int get_array()[10];
auto get_array() -> int[10];
❗️Массив не инкапсулирует в себе свой размер. Его нужно всегда вычислять, как мы говорили в начале.
❗️Из-за сложности синтаксиса, вы скорее всего захотите обрабатывать массивы с помощью функций с похожей сигнатурой:
void foo(int * p, size_t size);
Это потенциально может привести к доступу за границы выделенной области, так как функция foo ничего не знает про то, какой реальный размер имеет область памяти, на которую указывает
p. Она должна доверять программисту и переданному значению size. А программисту верить - себя не уважать.В общем, сишные массивы - это не объекты и не обладают преимуществами ООП и универсальной семантики для объектов в С++.
Поэтому стандартная библиотека предоставляет нам инструмент, который решает все проблемы C-style массивов. Это контейнер std::array. О нем мы поговорим в следующий раз.
Upgrade your tools. Stay cool.
#cppcore #goodoldc
{kind=link}
ref-qualified методы
#опытным
В С++ можно довольно интересными способами перегружать методы класса. Один из самых малоизвестных и малоиспользуемых - помечать методы квалификатором ссылочности.
Чтобы было понятнее. Примерно все знают, что бывают константные и неконстантные методы.
Константные объекты могут вызывать только константные методы. Поэтому мы можем перегрузить метод класса, чтобы он мог работать с константными объектами.
В примере видно что у константного объекта вызывается константная перегрузка.
По аналогии с cv-квалификаторами методов начиная с С++11 существуют ref-квалификаторы. Мы можем перегрузить метод так, чтобы он мог раздельно обрабатывать левые и правые ссылки.
Обратим внимание на сигнатуру методов. Метки ссылочных квалификаторов ожидаемо принимают форму одного и двух амперсандов, по аналогии с типами данных левых и правых сслылок соотвественно. Располагаются они после скобок с аргументами метода.
Работают они примерно также, как вы и ожидаете. lvalue-ref перегрузка вызывается на именованном объекте, rvalue-ref перегрузка - на временном.
Зачем это придумано?
Здесь на самом деле большие параллели с cv-квалификацией методов. Допустим, у вас класс - это какая-то коллекция. И вы хотите давать пользователям доступ к элементам этой коллекции через оператор[]. Для неконстантных объектов удобно возвращать ссылку. А вот для константных возвращение ссылки - потенциальное нарушение неизменяемости объекта. Поэтому в таких случаях константный оператор может возвращать элемент по значению или по константной ссылке.
Также и с ссылочностью. В каких-то случаях оптимально или просто необходимо использовать для правых ссылок иную логику метода.
Подробнее об этом чуде-юде будем разбираться в следующих постах.
Stay flexible. Stay cool.
#cpp11 #design
#опытным
В С++ можно довольно интересными способами перегружать методы класса. Один из самых малоизвестных и малоиспользуемых - помечать методы квалификатором ссылочности.
Чтобы было понятнее. Примерно все знают, что бывают константные и неконстантные методы.
struct SomeClass {
void foo() {std::cout << "Non-const member function" << std::endl;}
void foo() const {std::cout << "Const member function" << std::endl;}
};
SomeClass nonconst_obj;
const SomeClass const_obj;
nonconst_obj.foo();
const_obj.foo();
// OUTPUT
// Non-const member function
// Const member functionКонстантные объекты могут вызывать только константные методы. Поэтому мы можем перегрузить метод класса, чтобы он мог работать с константными объектами.
В примере видно что у константного объекта вызывается константная перегрузка.
По аналогии с cv-квалификаторами методов начиная с С++11 существуют ref-квалификаторы. Мы можем перегрузить метод так, чтобы он мог раздельно обрабатывать левые и правые ссылки.
struct SomeClass {
void foo() & {std::cout << "Call on lvalue reference" << std::endl;}
void foo() && {std::cout << "Call on rvalue reference" << std::endl;}
};
SomeClass lvalue;
lvalue.foo();
SomeClass{}.foo();
// OUTPUT
// Call on lvalue reference
// Call on rvalue referenceОбратим внимание на сигнатуру методов. Метки ссылочных квалификаторов ожидаемо принимают форму одного и двух амперсандов, по аналогии с типами данных левых и правых сслылок соотвественно. Располагаются они после скобок с аргументами метода.
Работают они примерно также, как вы и ожидаете. lvalue-ref перегрузка вызывается на именованном объекте, rvalue-ref перегрузка - на временном.
Зачем это придумано?
Здесь на самом деле большие параллели с cv-квалификацией методов. Допустим, у вас класс - это какая-то коллекция. И вы хотите давать пользователям доступ к элементам этой коллекции через оператор[]. Для неконстантных объектов удобно возвращать ссылку. А вот для константных возвращение ссылки - потенциальное нарушение неизменяемости объекта. Поэтому в таких случаях константный оператор может возвращать элемент по значению или по константной ссылке.
Также и с ссылочностью. В каких-то случаях оптимально или просто необходимо использовать для правых ссылок иную логику метода.
Подробнее об этом чуде-юде будем разбираться в следующих постах.
Stay flexible. Stay cool.
#cpp11 #design
Кейсы применения ref-qualified методов
#опытным
В нескольких предыдущих постах мы говорили про ref-qualified методы и как компилятор выбирает правильную перегрузку. Эта фича многим незнакома и сходу не очень понятно, где ее можно использовать. Давайте сегодня чуть подробнее поговорим о том, где они могут быть реально полезны, чтобы вы вдохновились и использовали такую перегрузку методов чаще.
✅ Разработка библиотек. Довольно очевидно, что разработчикам всяких библиотек нужно учитывать примерно все сценарии использования их классов. Пользователи(безумные) могут скастить объект к константной правой ссылке и методы класса должны работать корректно. Тут очень важно, чтобы тип возвращаемого значения методов соответствовал типу объекта. Пример:
Если объект временный, то возвращаем правую ссылку на мувнутый ресурс. Если объект lvalue, то возвращаем обычную ссылку.
✅ Форсить ограничения на методы. Если у вас методы возвращают левые ссылки(константные и неконстантные), то неплохо бы их пометитьразбитым корытом висячей ссылкой. Спасибо @d7d1cd за кейс)
Также прикрепляю ссылочку на быстрый ответ из блога стандарта С++ посвященный этому кейсу.
✅ Оптимизации. Иногда для определенных ссылочных типов мы можем оптимизировать какой-то метод. Например, в С++23 ввели rvalue reference перегрузку для метода substr класса std::basic_string. Мы знаем, что метод substr формирует новую строку, копируя туда рэндж из оригинальной строки. С++23 теперь сделал так, чтобы при вызове метода substr у правых ссылок объект подстроки тырил данные у оригинальной строки и фактически формировался из ее внутреннего буфера. Более подробно можно почитать в пропоузале.
Также, если вы возвращаете из метода легковесный объект, то в перегрузке для rvalue ссылок вы можете возвращать объект по значению. Так вы избавляетесь от избыточной ссылочной семантики и индирекции и , возможно, улучшаете перформанс. Ведь маленькие типы быстрее передавать и возвращать именно по значению:
В общем, в каждом конкретном случае оптимизировать можно по-разному.
Так что ref-qualified методы - это прекрасный инструмент тонкой настройки в руках профессионалов.
Be useful. Stay cool.
#cppcore #optimization #cpp23
#опытным
В нескольких предыдущих постах мы говорили про ref-qualified методы и как компилятор выбирает правильную перегрузку. Эта фича многим незнакома и сходу не очень понятно, где ее можно использовать. Давайте сегодня чуть подробнее поговорим о том, где они могут быть реально полезны, чтобы вы вдохновились и использовали такую перегрузку методов чаще.
✅ Разработка библиотек. Довольно очевидно, что разработчикам всяких библиотек нужно учитывать примерно все сценарии использования их классов. Пользователи(безумные) могут скастить объект к константной правой ссылке и методы класса должны работать корректно. Тут очень важно, чтобы тип возвращаемого значения методов соответствовал типу объекта. Пример:
template <typename T>
class optional {
constexpr T& value() & {
if (has_value()) {
return this->m_value;
}
throw bad_optional_access();
}
constexpr T const& value() const& {
if (has_value()) {
return this->m_value;
}
throw bad_optional_access();
}
constexpr T&& value() && {
if (has_value()) {
return std::move(this->m_value);
}
throw bad_optional_access();
}
constexpr T const&& value() const&& {
if (has_value()) {
return std::move(this->m_value);
}
throw bad_optional_access();
}
// ...
};
Если объект временный, то возвращаем правую ссылку на мувнутый ресурс. Если объект lvalue, то возвращаем обычную ссылку.
✅ Форсить ограничения на методы. Если у вас методы возвращают левые ссылки(константные и неконстантные), то неплохо бы их пометить
&, чтобы эти методы могли вызываться только у именованных объектов. Ведь если получить ссылку на внутренний ресурс временного объекта, то временный объект уничтожится, а вы останетесь с struct Vector {
int & operator[](size_t index) & { // notice & after arguments
return vec[index];
}
std::vector<int> vec;
};
Vector v;
v.vec = {1, 2, 3, 4};
v[1]; // ok
Vector{{1, 2, 3, 4}}[1]; // compile errorТакже прикрепляю ссылочку на быстрый ответ из блога стандарта С++ посвященный этому кейсу.
✅ Оптимизации. Иногда для определенных ссылочных типов мы можем оптимизировать какой-то метод. Например, в С++23 ввели rvalue reference перегрузку для метода substr класса std::basic_string. Мы знаем, что метод substr формирует новую строку, копируя туда рэндж из оригинальной строки. С++23 теперь сделал так, чтобы при вызове метода substr у правых ссылок объект подстроки тырил данные у оригинальной строки и фактически формировался из ее внутреннего буфера. Более подробно можно почитать в пропоузале.
Также, если вы возвращаете из метода легковесный объект, то в перегрузке для rvalue ссылок вы можете возвращать объект по значению. Так вы избавляетесь от избыточной ссылочной семантики и индирекции и , возможно, улучшаете перформанс. Ведь маленькие типы быстрее передавать и возвращать именно по значению:
struct Vector {
int operator[](size_t index) && { // notice & after arguments
return vec[index];
}
std::vector<int> vec;
};В общем, в каждом конкретном случае оптимизировать можно по-разному.
Так что ref-qualified методы - это прекрасный инструмент тонкой настройки в руках профессионалов.
Be useful. Stay cool.
#cppcore #optimization #cpp23
{kind=link}
auto аргументы функций
#опытным
Проследим историю с возможностью объявлять аргументы функций, как auto.
До С++14 у нас были только шаблонные параметры в функциях и лямбда выражения, без возможности передавать в них значения разных типов
Начиная с С++14, мы можем объявлять параметры лямбда выражения auto и передавать туда значения разных типов:
Это круто повысило вариативность лямбд, предоставив им некоторые плюшки шаблонов.
У обычных функции, тем не менее, так и остались обычные шаблонные параметры.
Но! Начиная с С++20, параметры обычных функций можно также объявлять auto:
Если для лямбд это было необходимым решением из-за того, что их не хотели делать шаблонными(хотя в С++20 их уже можно делать такими), то auto параметры обычных функций призваны немного упростить шаблонную логику там, где не нужно использовать непосредственно тип шаблонного параметра. Так сказать, шаблоны на чилле и расслабоне.
Осталось только добавить, что параметры auto работают по принципу выведения типов для шаблонов, а не по принципу выведения типов auto переменных.
История небольшая, но становится понятно, что С++ все больше уходит в неявную типизацию. С одной стороны это хорошо, проще писать код и не задумываться над типами. С другой стороны, чтобы этим пользоваться на высоком уровне, нужно знать всякие маленькие нюансики, которых становится все больше и больше.
Кому нравится, тот обрадуется и будет пользоваться. Кому не нравится, может писать в стиле С++03 и все будет у него прекрасно.
Hide unused details. Stay cool.
#cpp11 #cpp14 #cpp20 #template
#опытным
Проследим историю с возможностью объявлять аргументы функций, как auto.
До С++14 у нас были только шаблонные параметры в функциях и лямбда выражения, без возможности передавать в них значения разных типов
Начиная с С++14, мы можем объявлять параметры лямбда выражения auto и передавать туда значения разных типов:
auto print = [](auto& x){std::cout << x << std::endl;};
print(42);
print(3.14);Это круто повысило вариативность лямбд, предоставив им некоторые плюшки шаблонов.
У обычных функции, тем не менее, так и остались обычные шаблонные параметры.
Но! Начиная с С++20, параметры обычных функций можно также объявлять auto:
void sum(auto a, auto b)
{
auto result = a + b;
std::cout << a << " + " << b << " = " << result << std::endl;
}
sum(1, 3);
sum(3.14, 42);
sum(std::string("123"), std::string("456));
// OUTPUT:
// 1 + 3 = 4
// 3.14 + 42 = 45.14
// 123 + 456 = 123456
Если для лямбд это было необходимым решением из-за того, что их не хотели делать шаблонными(хотя в С++20 их уже можно делать такими), то auto параметры обычных функций призваны немного упростить шаблонную логику там, где не нужно использовать непосредственно тип шаблонного параметра. Так сказать, шаблоны на чилле и расслабоне.
Осталось только добавить, что параметры auto работают по принципу выведения типов для шаблонов, а не по принципу выведения типов auto переменных.
История небольшая, но становится понятно, что С++ все больше уходит в неявную типизацию. С одной стороны это хорошо, проще писать код и не задумываться над типами. С другой стороны, чтобы этим пользоваться на высоком уровне, нужно знать всякие маленькие нюансики, которых становится все больше и больше.
Кому нравится, тот обрадуется и будет пользоваться. Кому не нравится, может писать в стиле С++03 и все будет у него прекрасно.
Hide unused details. Stay cool.
#cpp11 #cpp14 #cpp20 #template
{kind=link}
Проблемы ref-qualified методов
#опытным
Мы разобрали, что перегрузки методов по ссылочным типам объектов могут быть полезными в разных контекстах. Они могут использовать как в совокупности для достижения универсальности в обработке объектов, или точечно для тонкой настройки-подкрутки функциональности
Но один из примеров в том посте выбивается из общей массы. Еще раз посмотрим на него:
Это примерно то, как метод value класса std::variant был введен в стандарт С++17.
Мягко говоря, есть ощущение, что код дублируется. А если не считать мува, то вообще квадруплицируется.
Это вот стандартная штука, когда функции отличаются немного и их нельзя объединить в одну.
В таких случаях обычно помогают шаблоны. А учитывая, что у нас для левых ссылок нет мува, а для правых - есть, очень сильно напрашиваются универсальные ссылки и шаблонный std::forward.
Но тут шаблон вообще никак не вписывается. Методы же не принимают даже никаких аргументов. Какой шаблонный параметр сюда вообще вписывается?
Ну вообще говоря, методы принимают неявный аргумент this....
To be continued.
Intrigue people. Stay cool.
#cppcore
#опытным
Мы разобрали, что перегрузки методов по ссылочным типам объектов могут быть полезными в разных контекстах. Они могут использовать как в совокупности для достижения универсальности в обработке объектов, или точечно для тонкой настройки-подкрутки функциональности
Но один из примеров в том посте выбивается из общей массы. Еще раз посмотрим на него:
template <typename T>
class optional {
// version of value for non-const lvalues
constexpr T& value() & {
if (has_value()) {
return this->m_value;
}
throw bad_optional_access();
}
// version of value for const lvalues
constexpr T const& value() const& {
if (has_value()) {
return this->m_value;
}
throw bad_optional_access();
}
// version of value for non-const rvalues... are you bored yet?
constexpr T&& value() && {
if (has_value()) {
return std::move(this->m_value);
}
throw bad_optional_access();
}
// you sure are by this point
constexpr T const&& value() const&& {
if (has_value()) {
return std::move(this->m_value);
}
throw bad_optional_access();
}
// ...
};
Это примерно то, как метод value класса std::variant был введен в стандарт С++17.
Мягко говоря, есть ощущение, что код дублируется. А если не считать мува, то вообще квадруплицируется.
Это вот стандартная штука, когда функции отличаются немного и их нельзя объединить в одну.
В таких случаях обычно помогают шаблоны. А учитывая, что у нас для левых ссылок нет мува, а для правых - есть, очень сильно напрашиваются универсальные ссылки и шаблонный std::forward.
Но тут шаблон вообще никак не вписывается. Методы же не принимают даже никаких аргументов. Какой шаблонный параметр сюда вообще вписывается?
Ну вообще говоря, методы принимают неявный аргумент this....
To be continued.
Intrigue people. Stay cool.
#cppcore
{kind=link}