
std::span
Все мы любим С++ за способность работать как на высоком уровне, так и на низком уровне абстракции. Ну ладно, за это не любим. За это ценим. Довольно много проблем зашито в самом языке из-за этой особенности, однако плюсы перевешивают(какой каламбур получился неожиданный). Одна из таких проблем - поддержка высокоуровневых контейнеров и низкоуровневых сишных массивов. Проектируя обобщенный код, нам нужно учитывать, что пользователь хотел бы оперировать и контейнерами, и массивами, при работе с этим кодом. Однако это не всегда удается сделать красиво, да и комон, какие сишные массивы? 2к23 наконец. Хочется писать в терминах С++, объектно-ориентированной модели и все такое. Однако с недавних пор у нас появился инструмент, который может нам помочь.
Я говорю в std::span.
template<class T, std::size_t Extent = std::dynamic_extent>
class span;
Этот шаблонный класс, который введен в С++20. Он описывает объекты, являющиеся ссылкой на непрерывную последовательность объектов. В чем фишка этой фичи?
1️⃣ Первое. Она позволяет единообразно работать с динамическими контейнерами и со статическими массивами. Для статических последовательностей в конструктор передается указатель на первый элемент и количество элементов в массиве. Тогда типичная реализация будет содержать только указатель на первый элемент последовательности, и количество элементов будет содержаться в самом типе. А если передать в конструктор контейнер, то объект будет содержать 2 поля - указатель и размер последовательности.
2️⃣ Второе. Это по сути вьюха на существующий контейнер или массив, которая позволяет работать с ними целиком и даже с подпоследовательностями без передачи владения и главное без копирования. Мы можем проектировать свои апи так, чтобы пользователь был уверен, что ничего плохого не случится с его массивом в функции. Это повышает безопасность кода. А отсутствие копирования открывает нам двери к адекватным легковесным слайсам в с++. Метод subspan предоставляет интерфейс слайсинга. Теперь для задания отрезка массива необходимы просто 2 числа. Как во всех нормальных языках.
Фича на самом деле рабочая. Даже в кор гайдлайнах код написан с использованием std::span. Там не советуют его использовать. А просто используют его в листингах. Как бы предполагая, что все про это знают и это стандартный способ написания кода. А это уже о многом говорит.
Stay updated. Stay cool.
#cpp20 #STL
Все мы любим С++ за способность работать как на высоком уровне, так и на низком уровне абстракции. Ну ладно, за это не любим. За это ценим. Довольно много проблем зашито в самом языке из-за этой особенности, однако плюсы перевешивают(какой каламбур получился неожиданный). Одна из таких проблем - поддержка высокоуровневых контейнеров и низкоуровневых сишных массивов. Проектируя обобщенный код, нам нужно учитывать, что пользователь хотел бы оперировать и контейнерами, и массивами, при работе с этим кодом. Однако это не всегда удается сделать красиво, да и комон, какие сишные массивы? 2к23 наконец. Хочется писать в терминах С++, объектно-ориентированной модели и все такое. Однако с недавних пор у нас появился инструмент, который может нам помочь.
Я говорю в std::span.
template<class T, std::size_t Extent = std::dynamic_extent>
class span;
Этот шаблонный класс, который введен в С++20. Он описывает объекты, являющиеся ссылкой на непрерывную последовательность объектов. В чем фишка этой фичи?
1️⃣ Первое. Она позволяет единообразно работать с динамическими контейнерами и со статическими массивами. Для статических последовательностей в конструктор передается указатель на первый элемент и количество элементов в массиве. Тогда типичная реализация будет содержать только указатель на первый элемент последовательности, и количество элементов будет содержаться в самом типе. А если передать в конструктор контейнер, то объект будет содержать 2 поля - указатель и размер последовательности.
2️⃣ Второе. Это по сути вьюха на существующий контейнер или массив, которая позволяет работать с ними целиком и даже с подпоследовательностями без передачи владения и главное без копирования. Мы можем проектировать свои апи так, чтобы пользователь был уверен, что ничего плохого не случится с его массивом в функции. Это повышает безопасность кода. А отсутствие копирования открывает нам двери к адекватным легковесным слайсам в с++. Метод subspan предоставляет интерфейс слайсинга. Теперь для задания отрезка массива необходимы просто 2 числа. Как во всех нормальных языках.
Фича на самом деле рабочая. Даже в кор гайдлайнах код написан с использованием std::span. Там не советуют его использовать. А просто используют его в листингах. Как бы предполагая, что все про это знают и это стандартный способ написания кода. А это уже о многом говорит.
Stay updated. Stay cool.
#cpp20 #STL
{kind=link}
std::make_unique
В комментах под этим постом, @Zolderix предложил рассказать про плюсы-минусы использования std::make_unique и std::make_shared. Темы клевые, да и умные указатели, судя по всему, вам заходят. Но будем делать все по порядку и поэтому сегодня говорим про std::make_unique.
Нет ни одной ситуации, где я бы предпочел создать объект через new вместо того, чтобы воспользоваться какой-нибудь RAII оберткой, будь то smart pointer или, например, std::array. Бывает апи говно и по-другому просто нельзя. Но чтобы намеренно делать это - неа. Но и даже при работе с умными указателями, их можно создать с помощью сырого поинтера, возвращенного new. Нужно ли так делать или лучше воспользоваться специальными функциями?
Мне кажется, что в целом идея умных указателей - снять с разработчиков ответственность за работу с памятью(потому что они ее не вывозят) и семантически разграничить разные по предназначению виды указателей. И, как мне кажется, функции std:make_... делают большой вклад именно в полной снятии ответственности. Я большой фанат отказа от явного вызова new и delete. Со вторым умные указатели и сами хорошо справляются, а вот с первым сильно помогают их функции-фабрики. Программист в идеале должен один раз сказать: "создать объект", объект создастся и программист просто забудет о том, что за этим объектом надо следить. Уверен, что большую часть компонентов систем можно и нужно строить без упоминания операторов new и delete вообще. И если с delete все и так ясно, то ограничение использования new может привести к улучшению безопасности и читаемости кода.
Это было особенно актуально до С++17, когда гарантии для порядка вычисления выражений были довольно слабые. Использование new, даже в комбинации с умным указателем, в качестве аргумента функции могло привести к утечкам памяти. Об этом более подробно я рассказывал в этом посте. А введение std::make_unique в С++14 полностью решило это проблему! Эта функция дает базовую гарантию безопасности исключений и, даже в случае их появлений, никакие ресурсы не утекут. Уверен, что какие-то проекты до сих не апнулись до 17 версии по разным причинам, поэтому для них это будет особенно актуально. Но гарантии исключений std::make_unique остаются прежними для всех существующих версий плюсов. Поэтому, кажется, что сердцу будет все равно спокойнее при ее использовании. У меня каждый раз повышается алертность, когда я вижу new. А какой цикл жизни у объекта? А что с исключениями? Оно того не стоит.
Также std::make_unique улучшает читаемость кода. И на этом есть 2 причины.
Первая - она лучше выражает намерение. На канале мы много об этом говорим. Эта функция доносит в понятной человеку языковой форме, что сейчас идет создание объекта. Я считаю использование фабрик - хорошей идеей именно поэтому. Хотя ничего и не меняется, и в конструктор и фабрику мы передаем одни и те же аргументы. Но вот это человеческое сообщение "make" "create" воспринимается в несколько раз лучше, чем просто имя класса.
Вторая - вы избегаете повторения кода. Чтобы создать unique_ptr через new нужно написать что-то такое:
std::unique_ptr<VeryLongAndClearNameLikeItShouldBeType> ptr{ new VeryLongAndClearNameLikeItShouldBeType(...) };
И сравните во с этим:
auto ptr = std::make_unique<VeryLongAndClearNameLikeItShouldBeType>(...);
В полтора раза короче и намного приятнее на вид.
Еще std::make_unique разделят типы Т и Т[]. Здесь вы обязаны явно специфицировать шаблон с подходящим типом, иначе вы просто создадите не массив, а объект. Функция сделает так, чтобы при выходе из скоупа обязательно вызовется подходящий оператор delete или delete[]. А вот если работать с непосредственно с конструктором std::unique_ptr, то вот такая строчка
std::unique_ptr<int> ptr(new int[5]);
хоть и компилируется, но приводит к UB.
Надеюсь, я убедил вас, что это действительно крутая фича. Пост уже получился довольно длинный, а я еще хотел впихнуть сюда недостатки. Но видимо придется разбить на 2 части. Поэтому
Stay in touch. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
В комментах под этим постом, @Zolderix предложил рассказать про плюсы-минусы использования std::make_unique и std::make_shared. Темы клевые, да и умные указатели, судя по всему, вам заходят. Но будем делать все по порядку и поэтому сегодня говорим про std::make_unique.
Нет ни одной ситуации, где я бы предпочел создать объект через new вместо того, чтобы воспользоваться какой-нибудь RAII оберткой, будь то smart pointer или, например, std::array. Бывает апи говно и по-другому просто нельзя. Но чтобы намеренно делать это - неа. Но и даже при работе с умными указателями, их можно создать с помощью сырого поинтера, возвращенного new. Нужно ли так делать или лучше воспользоваться специальными функциями?
Мне кажется, что в целом идея умных указателей - снять с разработчиков ответственность за работу с памятью(потому что они ее не вывозят) и семантически разграничить разные по предназначению виды указателей. И, как мне кажется, функции std:make_... делают большой вклад именно в полной снятии ответственности. Я большой фанат отказа от явного вызова new и delete. Со вторым умные указатели и сами хорошо справляются, а вот с первым сильно помогают их функции-фабрики. Программист в идеале должен один раз сказать: "создать объект", объект создастся и программист просто забудет о том, что за этим объектом надо следить. Уверен, что большую часть компонентов систем можно и нужно строить без упоминания операторов new и delete вообще. И если с delete все и так ясно, то ограничение использования new может привести к улучшению безопасности и читаемости кода.
Это было особенно актуально до С++17, когда гарантии для порядка вычисления выражений были довольно слабые. Использование new, даже в комбинации с умным указателем, в качестве аргумента функции могло привести к утечкам памяти. Об этом более подробно я рассказывал в этом посте. А введение std::make_unique в С++14 полностью решило это проблему! Эта функция дает базовую гарантию безопасности исключений и, даже в случае их появлений, никакие ресурсы не утекут. Уверен, что какие-то проекты до сих не апнулись до 17 версии по разным причинам, поэтому для них это будет особенно актуально. Но гарантии исключений std::make_unique остаются прежними для всех существующих версий плюсов. Поэтому, кажется, что сердцу будет все равно спокойнее при ее использовании. У меня каждый раз повышается алертность, когда я вижу new. А какой цикл жизни у объекта? А что с исключениями? Оно того не стоит.
Также std::make_unique улучшает читаемость кода. И на этом есть 2 причины.
Первая - она лучше выражает намерение. На канале мы много об этом говорим. Эта функция доносит в понятной человеку языковой форме, что сейчас идет создание объекта. Я считаю использование фабрик - хорошей идеей именно поэтому. Хотя ничего и не меняется, и в конструктор и фабрику мы передаем одни и те же аргументы. Но вот это человеческое сообщение "make" "create" воспринимается в несколько раз лучше, чем просто имя класса.
Вторая - вы избегаете повторения кода. Чтобы создать unique_ptr через new нужно написать что-то такое:
std::unique_ptr<VeryLongAndClearNameLikeItShouldBeType> ptr{ new VeryLongAndClearNameLikeItShouldBeType(...) };
И сравните во с этим:
auto ptr = std::make_unique<VeryLongAndClearNameLikeItShouldBeType>(...);
В полтора раза короче и намного приятнее на вид.
Еще std::make_unique разделят типы Т и Т[]. Здесь вы обязаны явно специфицировать шаблон с подходящим типом, иначе вы просто создадите не массив, а объект. Функция сделает так, чтобы при выходе из скоупа обязательно вызовется подходящий оператор delete или delete[]. А вот если работать с непосредственно с конструктором std::unique_ptr, то вот такая строчка
std::unique_ptr<int> ptr(new int[5]);
хоть и компилируется, но приводит к UB.
Надеюсь, я убедил вас, что это действительно крутая фича. Пост уже получился довольно длинный, а я еще хотел впихнуть сюда недостатки. Но видимо придется разбить на 2 части. Поэтому
Stay in touch. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
std::make_unique. Part 2
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
std::make_shared
Недавно тут и тут мы поговорили про плюсы и минусы использования std::make_unique. Настала очередь его братишки std::make_shared.
Базового все pros and cons с предыдущих постов справедливы и для сегодняшнего разбора. Поэтому не будем на этом долго останавливаться.
Но шаренный указатель немного сложнее внутри устроен, чем уникальный. От этого идут и уникальные преимущества и недостатки. А связаны они вот с чем. Посмотрите на эту строчку:
std::shared_ptr<T>(new T(...));
Сколько раз память аллоцируется в результате выполнения этой строчки?
Многие скажут 1. А люди, знающие внутреннее устройство шареного уккзателя, скажут 2. И будут правы.
Первая аллокация, очевидно, происходит в new. А вот где вторая?
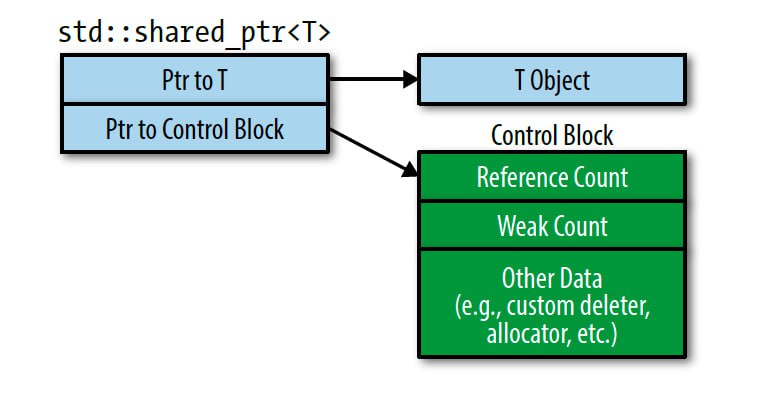
На выделении памяти для, так называемого, control block'а. Это внутренняя структура, которая хранит счетчики ссылок и еще пару приколюх. Она нужна для того, чтобы вести учет существующих объектов указателя, указывающих на данный объект. Естественно, эта структура должна быть общей для всех таких объектов. Поэтому в каждом объекте указателя хранится сырой указатель на этот самый контрол блок. То есть базово в классе std::shared_ptr 2 поля: указатель на объект и указатель на контрол блок. Ну и приняв указатель на объект, конструктор указателя дополнитель выделяет память для этого блока.
Чем в этом контексте отличается поведение std::make_shared?
Она вызывает всего одну аллокацию. Как? выделяет просто один блок памяти, который может содержать сразу и создаваемый объект, и control block, и кладет эти данные вместе. Это уменьшает статический размер программы, потому что код содержит всего 1 вызов аллокатора. И увеличивает скорость выполнения кода, потому что аллокация - довольно дорогостоящий вызов.
Перформанс - это уже серьезный аргумент отдать свое предпочтение в пользу make функции.
Однако эта фича ведет к одной проблеме. Для кого-то она совсем не проблемная, но об этом надо знать.
Дело в том, что может создаться такая ситуация, когда ни одного shared_pointer уже не существует, а память, выделенная для объекта и блока, все еще не отдана системе. Как такое может быть? Слабые ссылки.
Контрол блок помимо счетчика сильных ссылок(собственно сами shared_ptr'ы) хранит еще и счетчик слабых ссылок - для weak_ptr'ов. А деструктор control block'а и деаллокация памяти происходят только после того, как оба счетчика зануляться. Поэтому, если у вас есть хоть один висящий std::weak_ptr, то у вашего объекта хоть и будет вызван деструктор, но память так и не будет возвращена системе.
При создании больших объектов и при обильном использовании слабых ссылок это действительно может создавать проблему.
А если у вас не этот случай - смело используйте std::make_shared()
Stay efficient. Stay cool.
#cpp17 #cpp17 #STL #optimization #memory
Недавно тут и тут мы поговорили про плюсы и минусы использования std::make_unique. Настала очередь его братишки std::make_shared.
Базового все pros and cons с предыдущих постов справедливы и для сегодняшнего разбора. Поэтому не будем на этом долго останавливаться.
Но шаренный указатель немного сложнее внутри устроен, чем уникальный. От этого идут и уникальные преимущества и недостатки. А связаны они вот с чем. Посмотрите на эту строчку:
std::shared_ptr<T>(new T(...));
Сколько раз память аллоцируется в результате выполнения этой строчки?
Многие скажут 1. А люди, знающие внутреннее устройство шареного уккзателя, скажут 2. И будут правы.
Первая аллокация, очевидно, происходит в new. А вот где вторая?
На выделении памяти для, так называемого, control block'а. Это внутренняя структура, которая хранит счетчики ссылок и еще пару приколюх. Она нужна для того, чтобы вести учет существующих объектов указателя, указывающих на данный объект. Естественно, эта структура должна быть общей для всех таких объектов. Поэтому в каждом объекте указателя хранится сырой указатель на этот самый контрол блок. То есть базово в классе std::shared_ptr 2 поля: указатель на объект и указатель на контрол блок. Ну и приняв указатель на объект, конструктор указателя дополнитель выделяет память для этого блока.
Чем в этом контексте отличается поведение std::make_shared?
Она вызывает всего одну аллокацию. Как? выделяет просто один блок памяти, который может содержать сразу и создаваемый объект, и control block, и кладет эти данные вместе. Это уменьшает статический размер программы, потому что код содержит всего 1 вызов аллокатора. И увеличивает скорость выполнения кода, потому что аллокация - довольно дорогостоящий вызов.
Перформанс - это уже серьезный аргумент отдать свое предпочтение в пользу make функции.
Однако эта фича ведет к одной проблеме. Для кого-то она совсем не проблемная, но об этом надо знать.
Дело в том, что может создаться такая ситуация, когда ни одного shared_pointer уже не существует, а память, выделенная для объекта и блока, все еще не отдана системе. Как такое может быть? Слабые ссылки.
Контрол блок помимо счетчика сильных ссылок(собственно сами shared_ptr'ы) хранит еще и счетчик слабых ссылок - для weak_ptr'ов. А деструктор control block'а и деаллокация памяти происходят только после того, как оба счетчика зануляться. Поэтому, если у вас есть хоть один висящий std::weak_ptr, то у вашего объекта хоть и будет вызван деструктор, но память так и не будет возвращена системе.
При создании больших объектов и при обильном использовании слабых ссылок это действительно может создавать проблему.
А если у вас не этот случай - смело используйте std::make_shared()
Stay efficient. Stay cool.
#cpp17 #cpp17 #STL #optimization #memory
{kind=link}
STL vs stdlib
Откопаем один из популярнейших холиваров по С++, о котором вы даже могли и не слышать. Из-за того, что мы с вами не носители, то плохо понимаем ориджин терминов, которые сами используем. Ну типа всю нашу жизнь вокруг нас на туалетах написано WC и мы даже не понимаем, а что это значит на самом деле. Но продолжаем в новых заведениях помечать туалет именно этими буквами и просто принимаем это, как данность. Water closet. Так давно в Англии начали назывались маленькие приватные комнатки с подачей воды для смыва.
Так и мы с вами употребляем термин STL скорее в каком-то нашем интуитивном понимании, чем в реальном его значении. Ну вот например, в вакансиях плюсовиков в требованиях часто пишут, что необходимо знание буста и STL. Думаю, что и HR'ы и соискатели удивятся, что 99.9% плюсовиков никогда не пользовались STL....
Утверждение громкое и для кого-то может быть обидное, поэтому погнали разбираться, пока меня тухлыми помидорами не закидали.
С 1979 года, когда мастер-Бьёрн создал С с классами, пройдет почти 20 лет прежде, чем С++ будет стандартизирован в 1998 году. Процесс стандартизации шел долго и люди со временем вносили свои пропоузалы в будущий стандарт. В принципе и сейчас так делают. Так вот. Жил, был и работал в HP один русский эмигрант - Александр Степанов. У него давно были мысли по созданию обобщенной библиотеки, в которой данные и алгоритмы над ними находились бы отдельно друг от друга. Он пытался воплотить свои мысли в жизнь даже в других языках, типа Ada, потому что на тот момент С++ не обладал необходимой функциональностью. Но язык развивался, появились необходимые фичи и Александр начал думать над реализацией своих идей в С++. В конце 1993 года он рассказал о своих наработках бывшему коллеге - Эндрю Кёнингу, который на тот момент работал в ISO комитете С++. Эндрю восхитился замыслом Александра и организовал ему встречу с комитетом. Комитет тоже охал и ахал от гениальности идей и включил их в драфт страндарта С++. Но не полностью. Что-то пришлось удалить и что-то пришлось подкорректировать в сотрудничестве со Степановым. Именно так были созданы стандартные библиотеки алгоритмов, итераторов и контейнеров.
В 1995 году Александр перешел в компанию Silicon Graphics, доработал и релизнул окончательную версию своего видения STL. Ее даже вроде можно скачать тут. То есть это вообще отдельная библиотека, которую надо отдельно подключать к своему проекту. И с почти стопроцентной вероятностью, вы ей никогда не пользовались.
То есть STL никогда не была частью стандарта, хотя и сильно повлияло на него. В тексте стандарта нет ни одного упоминания STL! Но Степанов сам называл включения своей библиотеки в стандартную библиотеку как STL. И авторы многих книг по С++ называли эти включения STL. Даже Страуструп называет стандартные библиотеки алгоритмов, итераторов и контейнеров STL. Поэтому в умах закрепилась эта ассоциация и, в целом, сейчас легитимно называть так этот набор библиотек.
Но мозг людей склонен к обобщениям, поэтому под STL со временем многие начали понимать в принципе всю стандартную библотеку. Масла в огонь подливает еще, что STL можно расшифровать, как STandard Library. Да и другие части stdlib сугубо шаблонизированы. Типа тех же умных указателей или работы со случайными числами. Для многих STL стала уже симулякром в чистом виде, потому что люди забыли изначальное значение этого акронима.
Я не против использования термина STL в качестве референса к либам алгоритмов, итераторов и контейнеров. Даже для stdlib не против. Потому что не понимаю, как это может вредить программисту. Но считаю важным, чтобы люди понимали настоящий смысл слов, которые они употребляют. Используя в жизни ситулякры, мы отдаляемся от реальных вещей и переходим в мир выдуманный, нереальный. А настоящий мир будет продолжать влиять на нас по прежнему и это противоречие может вылиться в проблемы.
А к какому лагерю вы относитесь? Только stdlib и больше ничего или STL, но в правильном контексте? Напишите свои мысли в комментариях)
Stay in reality. Stay cool.
#fun #commercial #STL
Откопаем один из популярнейших холиваров по С++, о котором вы даже могли и не слышать. Из-за того, что мы с вами не носители, то плохо понимаем ориджин терминов, которые сами используем. Ну типа всю нашу жизнь вокруг нас на туалетах написано WC и мы даже не понимаем, а что это значит на самом деле. Но продолжаем в новых заведениях помечать туалет именно этими буквами и просто принимаем это, как данность. Water closet. Так давно в Англии начали назывались маленькие приватные комнатки с подачей воды для смыва.
Так и мы с вами употребляем термин STL скорее в каком-то нашем интуитивном понимании, чем в реальном его значении. Ну вот например, в вакансиях плюсовиков в требованиях часто пишут, что необходимо знание буста и STL. Думаю, что и HR'ы и соискатели удивятся, что 99.9% плюсовиков никогда не пользовались STL....
Утверждение громкое и для кого-то может быть обидное, поэтому погнали разбираться, пока меня тухлыми помидорами не закидали.
С 1979 года, когда мастер-Бьёрн создал С с классами, пройдет почти 20 лет прежде, чем С++ будет стандартизирован в 1998 году. Процесс стандартизации шел долго и люди со временем вносили свои пропоузалы в будущий стандарт. В принципе и сейчас так делают. Так вот. Жил, был и работал в HP один русский эмигрант - Александр Степанов. У него давно были мысли по созданию обобщенной библиотеки, в которой данные и алгоритмы над ними находились бы отдельно друг от друга. Он пытался воплотить свои мысли в жизнь даже в других языках, типа Ada, потому что на тот момент С++ не обладал необходимой функциональностью. Но язык развивался, появились необходимые фичи и Александр начал думать над реализацией своих идей в С++. В конце 1993 года он рассказал о своих наработках бывшему коллеге - Эндрю Кёнингу, который на тот момент работал в ISO комитете С++. Эндрю восхитился замыслом Александра и организовал ему встречу с комитетом. Комитет тоже охал и ахал от гениальности идей и включил их в драфт страндарта С++. Но не полностью. Что-то пришлось удалить и что-то пришлось подкорректировать в сотрудничестве со Степановым. Именно так были созданы стандартные библиотеки алгоритмов, итераторов и контейнеров.
В 1995 году Александр перешел в компанию Silicon Graphics, доработал и релизнул окончательную версию своего видения STL. Ее даже вроде можно скачать тут. То есть это вообще отдельная библиотека, которую надо отдельно подключать к своему проекту. И с почти стопроцентной вероятностью, вы ей никогда не пользовались.
То есть STL никогда не была частью стандарта, хотя и сильно повлияло на него. В тексте стандарта нет ни одного упоминания STL! Но Степанов сам называл включения своей библиотеки в стандартную библиотеку как STL. И авторы многих книг по С++ называли эти включения STL. Даже Страуструп называет стандартные библиотеки алгоритмов, итераторов и контейнеров STL. Поэтому в умах закрепилась эта ассоциация и, в целом, сейчас легитимно называть так этот набор библиотек.
Но мозг людей склонен к обобщениям, поэтому под STL со временем многие начали понимать в принципе всю стандартную библотеку. Масла в огонь подливает еще, что STL можно расшифровать, как STandard Library. Да и другие части stdlib сугубо шаблонизированы. Типа тех же умных указателей или работы со случайными числами. Для многих STL стала уже симулякром в чистом виде, потому что люди забыли изначальное значение этого акронима.
Я не против использования термина STL в качестве референса к либам алгоритмов, итераторов и контейнеров. Даже для stdlib не против. Потому что не понимаю, как это может вредить программисту. Но считаю важным, чтобы люди понимали настоящий смысл слов, которые они употребляют. Используя в жизни ситулякры, мы отдаляемся от реальных вещей и переходим в мир выдуманный, нереальный. А настоящий мир будет продолжать влиять на нас по прежнему и это противоречие может вылиться в проблемы.
А к какому лагерю вы относитесь? Только stdlib и больше ничего или STL, но в правильном контексте? Напишите свои мысли в комментариях)
Stay in reality. Stay cool.
#fun #commercial #STL
{kind=link}
Зачем для Remove-Erase идиомы нужны 2 алгоритма?
Удалить из вектора элементы по значению или подходящие под какой-то шаблон не получится напрямую через API вектора. Ну точнее получится, просто вы не хотите, чтобы получалось именно так)
Дело в том, что метод erase у вектора действительно удаляет элемент или рэндж элементов. Но как он это делает?
Вектор - массив смежных ячеек памяти, в которых находятся объекты. То есть один элемент заканчивается и начинается новый. Представим, что мы хотим удалить объект где-нибудь в середине массива. Если мы просто вызовем деструктор этого объекта(отдельную ячейку памяти вернуть системе мы не можем), то тогда у нас нарушится этот инвариант вектора, что все элементы идут друг за другом. И это чисто идейная проблема. А на практике это место в памяти еще и можно было бы также итерпретировать, как живой объект, и работать с ним. Потому что в векторе нет механизма запоминания данных об удаленных ячейках. А если удалять рэндж, то будет целая область пустующая.
Решается эта проблема метода erase сдвигом влево всех элементов, которые остались справа после удаленных. То есть либо копированием, либо перемещением объектов. Тогда все дырки заполнены, инвариантов не нарушено. Но это линейная сложность удаления. То есть на удаление каждого одиноко стоящего элемента нужно тратить линейное время. И для фильтрации всего массива понадобится уже квадратичное время, что не может не огорчать.
Хорошо. Лезем в cpp-reference и находим там алгоритмы std::remove и std:remove_if. Они принимают рендж начало-конец, ищут там конкретное значение или проверяют предикат на верность и удаляют найденные элементы. Вот что там написано про сложность:
Given
1,2) exactly
3,4) exactly
Сложность удаления найденных элементов - линейная. Ну отлично. Х*як и в рабочий код. Тесты валятся, код работает не так как ожидалось. После применения алгоритма на самом деле ничего не удалилось. Элементов столько же, только они в каком-то странном порядке. Почему?
Это я объясняю в видосе из вчерашнего поста. Довольно сложно описать работу std::remove на пальцах в тексте, поэтому и видео появилось. Но для тех, кто не смотрел кратко зарезюмирую. С помощью двух указателей нужные элементы остаются в массиве и перемещаются на свои новые места и делается это так, что в конце массива скапливаются ненужные ячейки. А возвращается из алгоритма итератор на новый конец последовательности, то есть на начало вот этого скопления. Получается std::remove ничего не удаляет, он только переупорядочивает элементы.
И это хорошо, потому что теперь мы можем действительно удалить эти элементы. Причем все разом. Делается это через уже знакомый нам метод вектора erase. Если erase очищает рэндж и этот рендж заканчивается последним элементом, то никаких копирований не происходит. Вызываются деструкторы объектов и изменяется поле, хранящее размер массива. Поэтому получается такая каша:
myVec.erase(std::remove(myVec.begin(), myVec.end(), value), myVec.end());
Собственно, когда эти 2 алгоритма применяются в одной строчке, можно наглядно увидеть причину названия идиомы.
Теперь сложность удаления будет линейной, а это уже не может не радовать.
Да, это выглядит не очень солидно, но имеем, что имеем. Хотя в 20-х плюсах эта ситуация изменилась, как-нибудь расскажу про это.
Stay based. Stay cool.
#cppcore #STL #algorithms #datastructures
Удалить из вектора элементы по значению или подходящие под какой-то шаблон не получится напрямую через API вектора. Ну точнее получится, просто вы не хотите, чтобы получалось именно так)
Дело в том, что метод erase у вектора действительно удаляет элемент или рэндж элементов. Но как он это делает?
Вектор - массив смежных ячеек памяти, в которых находятся объекты. То есть один элемент заканчивается и начинается новый. Представим, что мы хотим удалить объект где-нибудь в середине массива. Если мы просто вызовем деструктор этого объекта(отдельную ячейку памяти вернуть системе мы не можем), то тогда у нас нарушится этот инвариант вектора, что все элементы идут друг за другом. И это чисто идейная проблема. А на практике это место в памяти еще и можно было бы также итерпретировать, как живой объект, и работать с ним. Потому что в векторе нет механизма запоминания данных об удаленных ячейках. А если удалять рэндж, то будет целая область пустующая.
Решается эта проблема метода erase сдвигом влево всех элементов, которые остались справа после удаленных. То есть либо копированием, либо перемещением объектов. Тогда все дырки заполнены, инвариантов не нарушено. Но это линейная сложность удаления. То есть на удаление каждого одиноко стоящего элемента нужно тратить линейное время. И для фильтрации всего массива понадобится уже квадратичное время, что не может не огорчать.
Хорошо. Лезем в cpp-reference и находим там алгоритмы std::remove и std:remove_if. Они принимают рендж начало-конец, ищут там конкретное значение или проверяют предикат на верность и удаляют найденные элементы. Вот что там написано про сложность:
Given
N as std::distance(first, last)1,2) exactly
N comparisons with value using operator==.3,4) exactly
N applications of the predicate p.Сложность удаления найденных элементов - линейная. Ну отлично. Х*як и в рабочий код. Тесты валятся, код работает не так как ожидалось. После применения алгоритма на самом деле ничего не удалилось. Элементов столько же, только они в каком-то странном порядке. Почему?
Это я объясняю в видосе из вчерашнего поста. Довольно сложно описать работу std::remove на пальцах в тексте, поэтому и видео появилось. Но для тех, кто не смотрел кратко зарезюмирую. С помощью двух указателей нужные элементы остаются в массиве и перемещаются на свои новые места и делается это так, что в конце массива скапливаются ненужные ячейки. А возвращается из алгоритма итератор на новый конец последовательности, то есть на начало вот этого скопления. Получается std::remove ничего не удаляет, он только переупорядочивает элементы.
И это хорошо, потому что теперь мы можем действительно удалить эти элементы. Причем все разом. Делается это через уже знакомый нам метод вектора erase. Если erase очищает рэндж и этот рендж заканчивается последним элементом, то никаких копирований не происходит. Вызываются деструкторы объектов и изменяется поле, хранящее размер массива. Поэтому получается такая каша:
myVec.erase(std::remove(myVec.begin(), myVec.end(), value), myVec.end());
Собственно, когда эти 2 алгоритма применяются в одной строчке, можно наглядно увидеть причину названия идиомы.
Теперь сложность удаления будет линейной, а это уже не может не радовать.
Да, это выглядит не очень солидно, но имеем, что имеем. Хотя в 20-х плюсах эта ситуация изменилась, как-нибудь расскажу про это.
Stay based. Stay cool.
#cppcore #STL #algorithms #datastructures
{kind=link}
Идиома Remove-Erase устарела?
Снова вспомним про эту идиому. В прошлых частях тык и тык(кто не видел эту серию постов, то после первого нужно еще вот этот посмотреть) говорили о том, зачем что это такое, какую проблему решает, и как работает. А в этой части я расскажу, что это все не нужно)
Точнее будет не нужно, после того, как ваши проекты полностью перейдут на С++20.
Дело в том, что этот релиз подарил нам 2 прекрасные шаблонные функции: std::erase и std::erase_if. Чем они занимаются в контексте идиомы? А занимаются они ровно тем же, только намного красивее. Если раньше нам приходилось использовать 2 алгоритма, чтобы удалить нужные элементы из вектора, то здесь нужна всего одна функция.
std::vector<int> myVec = {1, 2, 3, 4, 5};
std::erase(myVec, 2);
И все. Больше ничего не нужно городить. И даже убрали этот некрасивый интерфейс с итераторами (по сути интерфейс крутой и функциональный, но слишком много букав писать надо). Да, для ренджей придется использовать идиому по старинке, но случаи, когда это реально необходимо, очень редки.
Вся прелесть этих функции в том, что они шаблонные. То есть могут принимать на вход любые контейнеры стандартной библиотеки. Примечательно, что для большинства контейнеров эти функции частично специализированы под этот конкретный контейнер. Писать обобщенный код теперь стало еще проще.
Stay updated. Stay cool.
#cpp20 #STL #algorithms
Снова вспомним про эту идиому. В прошлых частях тык и тык(кто не видел эту серию постов, то после первого нужно еще вот этот посмотреть) говорили о том, зачем что это такое, какую проблему решает, и как работает. А в этой части я расскажу, что это все не нужно)
Точнее будет не нужно, после того, как ваши проекты полностью перейдут на С++20.
Дело в том, что этот релиз подарил нам 2 прекрасные шаблонные функции: std::erase и std::erase_if. Чем они занимаются в контексте идиомы? А занимаются они ровно тем же, только намного красивее. Если раньше нам приходилось использовать 2 алгоритма, чтобы удалить нужные элементы из вектора, то здесь нужна всего одна функция.
std::vector<int> myVec = {1, 2, 3, 4, 5};
std::erase(myVec, 2);
И все. Больше ничего не нужно городить. И даже убрали этот некрасивый интерфейс с итераторами (по сути интерфейс крутой и функциональный, но слишком много букав писать надо). Да, для ренджей придется использовать идиому по старинке, но случаи, когда это реально необходимо, очень редки.
Вся прелесть этих функции в том, что они шаблонные. То есть могут принимать на вход любые контейнеры стандартной библиотеки. Примечательно, что для большинства контейнеров эти функции частично специализированы под этот конкретный контейнер. Писать обобщенный код теперь стало еще проще.
Stay updated. Stay cool.
#cpp20 #STL #algorithms
{kind=link}
Vector vs List
Знание алгоритмов и структур данных - критично для нашей профессии. Ведь в принципе все, что мы делаем - это берем какие-то явления реального мира, создаем их представления в программе и управляем ими. От нашего понимания эффективного представления данных в памяти компьютера и управления ими зависит количество ресурсов, которое требуется на предоставление какой-то услуги, а значит и доход заказчика. Чем лучше мы знаем эти вещи, тем дешевле предоставлять услугу и тем больше мы ценны как специалисты. И наши доходы растут. Но computer science намного обширнее, чем абстрактные вещи типа теории алгоритмов или архитектуры ПО. Это еще и знание и понимание работы конкретного железа, на котором наш софт выполняется. Что важнее - непонятно. Но только в синергии можно получить топовые результаты.
Согласно теории, проход по массиву и двунаправленному списку происходит за одинаковое алгоритмическое время. O(n). То есть время прохода линейно зависит от количества элементов в структуре. И без применения знаний о принципах работы железа, можно подумать, что они взаимозаменяемы. Просто в одном случае элементы лежат рядом, а в другом - связаны ссылками. А на практике получается, что не совсем линейно и совсем не взаимозаменяемы. Расскажу подробнее о последнем.
Дело в существовании кэша у процессора. Когда мы запрашиваем доступ к одной ячейке памяти, процессор верно предполагает, что нам скорее всего будут нужны и соседние ячейки тоже. Поэтому он копирует целый интервал в памяти, называемый кэш-строкой, в свой промежуточный буфер. А доступ к этому буферу происходит намного быстрее, чем к оперативной памяти. И процессору не нужно ходить за этими рядом лежащими данными в ОЗУ, он их просто берет из кэша.
Элементы же списка хранятся в разных участках памяти и связаны между собой ссылками. В общем виде нет никакой гарантии, что они будут лежать рядом. Если конечно вы не используете кастомный аллокатор. Поэтому за каждым элементом листа процессору приходится ходит в ОЗУ.
Вот и получается, что обработка элементов списка будет происходит медленнее, чем элементов массива.
Написал простенькую программку, которая проверит разницу во времени прохода.
Получилось, что для 100кк чисел в массиве и в листе, время отличается от 1.5 до 2 раз на разных машинах. Нихрена себе такая разница. И это без оптимизаций!
С ними разница вообще 6-8 раз. Это кстати еще один повод для того, чтобы понимать, как именно мы работаем на уровне железа и какие структуры данных хорошо ложатся на разные оптимизации.
Конечно, в реальных приложениях обработка - обычно более дорогая операция, чем просто инкремент и в процентном соотношении затраты на доступ к элементам будут другие. Но для того и пишутся такие тесты, чтобы максимально подсветить проблему.
Stay based. Stay cool.
#STL #algorithms #cppcore
Знание алгоритмов и структур данных - критично для нашей профессии. Ведь в принципе все, что мы делаем - это берем какие-то явления реального мира, создаем их представления в программе и управляем ими. От нашего понимания эффективного представления данных в памяти компьютера и управления ими зависит количество ресурсов, которое требуется на предоставление какой-то услуги, а значит и доход заказчика. Чем лучше мы знаем эти вещи, тем дешевле предоставлять услугу и тем больше мы ценны как специалисты. И наши доходы растут. Но computer science намного обширнее, чем абстрактные вещи типа теории алгоритмов или архитектуры ПО. Это еще и знание и понимание работы конкретного железа, на котором наш софт выполняется. Что важнее - непонятно. Но только в синергии можно получить топовые результаты.
Согласно теории, проход по массиву и двунаправленному списку происходит за одинаковое алгоритмическое время. O(n). То есть время прохода линейно зависит от количества элементов в структуре. И без применения знаний о принципах работы железа, можно подумать, что они взаимозаменяемы. Просто в одном случае элементы лежат рядом, а в другом - связаны ссылками. А на практике получается, что не совсем линейно и совсем не взаимозаменяемы. Расскажу подробнее о последнем.
Дело в существовании кэша у процессора. Когда мы запрашиваем доступ к одной ячейке памяти, процессор верно предполагает, что нам скорее всего будут нужны и соседние ячейки тоже. Поэтому он копирует целый интервал в памяти, называемый кэш-строкой, в свой промежуточный буфер. А доступ к этому буферу происходит намного быстрее, чем к оперативной памяти. И процессору не нужно ходить за этими рядом лежащими данными в ОЗУ, он их просто берет из кэша.
Элементы же списка хранятся в разных участках памяти и связаны между собой ссылками. В общем виде нет никакой гарантии, что они будут лежать рядом. Если конечно вы не используете кастомный аллокатор. Поэтому за каждым элементом листа процессору приходится ходит в ОЗУ.
Вот и получается, что обработка элементов списка будет происходит медленнее, чем элементов массива.
Написал простенькую программку, которая проверит разницу во времени прохода.
Получилось, что для 100кк чисел в массиве и в листе, время отличается от 1.5 до 2 раз на разных машинах. Нихрена себе такая разница. И это без оптимизаций!
С ними разница вообще 6-8 раз. Это кстати еще один повод для того, чтобы понимать, как именно мы работаем на уровне железа и какие структуры данных хорошо ложатся на разные оптимизации.
Конечно, в реальных приложениях обработка - обычно более дорогая операция, чем просто инкремент и в процентном соотношении затраты на доступ к элементам будут другие. Но для того и пишутся такие тесты, чтобы максимально подсветить проблему.
Stay based. Stay cool.
#STL #algorithms #cppcore
{kind=link}
Пример выстрела в лицо с помощью std::auto_ptr
Здесь мы рассмотрели проблемы std::auto_ptr. Проблемы понятные, но сегодня на практике разберем, как все может пойти не плану.
Прикол в том, что разработчики реализаций стандартной библиотеки понимали, люди так или иначе хотели пользоваться контейнерами, которые в себе содержали auto_ptr. Желание очевидное и поэтому разработчики делали такие реализации, которые сглаживают углы и косяки авто указателя. И в целом, хоть это и нестандарт, но с ними можно было работать.
Отчасти поэтому привести хороший пример того, как может выстрелить в ногу использование auto_ptr в контейнерах - задача не самая тривиальная. Но я вот попробую показать все эти интересности(см картинку).
Реализуем простенький класс с правилом нуля. Создадим вектор из авто указателей на объекты этого класса. Проинициализируем его.
И попробуем отсортировать. После вывода отсортированных элементов понимаем, что все сработало как надо и чиселки выстроились по порядку.
Однако теперь попробуем отсортировать с копирующей лямбдой. И вот тут-то мы и сегфолтнемся. При сортировке указатели будут копироваться в лямбду, то есть будут передавать туда владение ресурсом, а в контейнере будет оставаться фига. Поэтому при попытке снова получить доступ к полю ресурса мы наткнемся на нулевой указатель и упадем.
Да, сложно представить, что кто-то в проде напишет вторую лямбду(копирующую), но чем черт не шутит. Да и это лишь пример. Реальные ситуации могут быть сложные и неочевидные, поэтому будет легко попасться в ловушку. Это все-таки благосклонность компилятора, а не стандартная штука, на которую можно положиться в любых обстоятельствах.
Всем мув-семантики и непадающих программ.
Prevent your downfalls. Stay cool.
#compiler #STL #NONSTANDARD
Здесь мы рассмотрели проблемы std::auto_ptr. Проблемы понятные, но сегодня на практике разберем, как все может пойти не плану.
Прикол в том, что разработчики реализаций стандартной библиотеки понимали, люди так или иначе хотели пользоваться контейнерами, которые в себе содержали auto_ptr. Желание очевидное и поэтому разработчики делали такие реализации, которые сглаживают углы и косяки авто указателя. И в целом, хоть это и нестандарт, но с ними можно было работать.
Отчасти поэтому привести хороший пример того, как может выстрелить в ногу использование auto_ptr в контейнерах - задача не самая тривиальная. Но я вот попробую показать все эти интересности(см картинку).
Реализуем простенький класс с правилом нуля. Создадим вектор из авто указателей на объекты этого класса. Проинициализируем его.
И попробуем отсортировать. После вывода отсортированных элементов понимаем, что все сработало как надо и чиселки выстроились по порядку.
Однако теперь попробуем отсортировать с копирующей лямбдой. И вот тут-то мы и сегфолтнемся. При сортировке указатели будут копироваться в лямбду, то есть будут передавать туда владение ресурсом, а в контейнере будет оставаться фига. Поэтому при попытке снова получить доступ к полю ресурса мы наткнемся на нулевой указатель и упадем.
Да, сложно представить, что кто-то в проде напишет вторую лямбду(копирующую), но чем черт не шутит. Да и это лишь пример. Реальные ситуации могут быть сложные и неочевидные, поэтому будет легко попасться в ловушку. Это все-таки благосклонность компилятора, а не стандартная штука, на которую можно положиться в любых обстоятельствах.
Всем мув-семантики и непадающих программ.
Prevent your downfalls. Stay cool.
#compiler #STL #NONSTANDARD
{kind=link}
Реальная ценность ссылок
Да и помните, как вводятся ссылки в учебных целях? Помню читал, что они нужны, чтобы внутри функции изменять переменную и эти изменения отразились в вызывающем блоке кода. И это удобнее указателя, потому что не нужно его разыменовывать. Все. С таким подходом естественно, что никто нихрена не понимает предназначения ссылок. Может только я так криво читал книжки. Это очень на меня похоже. Но раз я такой есть, значит есть и другие, похожие на меня. Поэтому этот пост для всех тех, кто читаешь книжки затылком, или просто новичков, которые не писали много кода.
Как бы функционал-то правильный, никто не спорит. С помощью ссылки в функции действительно можно проводить манипуляции с тем же самым объектом, что мы в нее передали и эти изменения отражаются на этом оригинальном объекте. На этом все основано. Но из этого поначалу довольно сложно сформулировать реальные кейсы использования ссылок. Собсна, погнали их разбирать.
У них есть 5 функции(ну или это я столько придумал)
1️⃣ Предотвращение лишнего копирования объекта при передаче в функцию. Ссылка - обертка над указателем, поэтому она занимает всего 4|8 байт и позволяет получить доступ к памяти, где находится объект. Опять же, наверняка в книжках объясняется, что ссылка - это обертка, но, как мне кажется, черезчур большой акцент делается на возможности изменения объекта, на который ссылается псевдоним. В очень многих ситуациях, когда в функции один из параметров - ссылка, она используется как read-only сущность. Тогда она помечена как const. Поэтому она лишь задает значение другим сущностям. А раз так, то нам в целом и нужен этот функционал изменения оригинального объекта и можно подумать, что в этом случае нужно по значению принимать аргумент. А вот нет. Тогда у нас будет дополнительное копирование. Нам такого не нужно. Мы общество без лишних копирований! Поэтому можно воспользоваться свойством, что ссылка - обертка над указателем. А значит мы можем с ее помощью без копирований задать значение другим объектам.
2️⃣ Output параметры. Уже ближе к способности изменения оригинального объекта. Иногда не хватает одного возвращаемого значения в функции, поэтому прибегают к использованию output параметров, чтобы функция передала нужную информацию через них. Есть конечно туплы или можно запилить отдельный класс, который в себе будет инкапсулировать нужные параметры, и возвращать его. Но туплы не очень информативные, так как у их элементов нет своих имен, а постоянно плодить сущности - не всегда удобно. Поэтому на помощь могут прийти output параметры. В этом случае они передаются по неконстантной ссылке. Просто в функцию передаются "пустые" объекты, то есть только что дефолтно созданные. И в этой функции на них нанизывается нужная информация. Которую мы потом может достать с помощью такой ссылочной семантики.
3️⃣ Изменение оригинального объекта. Эт вот та история, с которой я начал. Но! По моему опыту, это не самый популярный кейс использования ссылок. Попробую объяснить. Для кастомных классов очень часто приходится использовать std::shared_ptr, если время его жизни больше времени жизни скоупа. Тогда этот указатель везде передается по константной ссылке, хотя и объект, на который он указывает, можно изменять. Если нужно изменить какой-то объект, который создан на стеке, это нужно скорее делать через его собственные методы, а не сторонние функции. Так объект становится актором и проще воспринимать действия, которые происходят с ним происходят. Это вот та самая инкапсуляция.
4️⃣ Предоставление доступа к содержимому класса, без раскрытия приватных членов. Таким свойством обладает неконстантный operator[] для контейнеров STL. Вектору опасно предоставлять доступ к буфферу данных, где хранятся все объекты. Но более менее безопасно давать доступ к отдельным элементам для возможности их модификации. Это очень похожая на прошлый пример механика. Только в качестве текущего стейта выступает объект со своим содержимым, а модифицирующей функцией - текущая функция, в которой применяем operator[].
ПРОДОЛЖЕНИЕ В КОММЕНТАХ
#cppcore #goodpractice #design #STL
Да и помните, как вводятся ссылки в учебных целях? Помню читал, что они нужны, чтобы внутри функции изменять переменную и эти изменения отразились в вызывающем блоке кода. И это удобнее указателя, потому что не нужно его разыменовывать. Все. С таким подходом естественно, что никто нихрена не понимает предназначения ссылок. Может только я так криво читал книжки. Это очень на меня похоже. Но раз я такой есть, значит есть и другие, похожие на меня. Поэтому этот пост для всех тех, кто читаешь книжки затылком, или просто новичков, которые не писали много кода.
Как бы функционал-то правильный, никто не спорит. С помощью ссылки в функции действительно можно проводить манипуляции с тем же самым объектом, что мы в нее передали и эти изменения отражаются на этом оригинальном объекте. На этом все основано. Но из этого поначалу довольно сложно сформулировать реальные кейсы использования ссылок. Собсна, погнали их разбирать.
У них есть 5 функции(ну или это я столько придумал)
1️⃣ Предотвращение лишнего копирования объекта при передаче в функцию. Ссылка - обертка над указателем, поэтому она занимает всего 4|8 байт и позволяет получить доступ к памяти, где находится объект. Опять же, наверняка в книжках объясняется, что ссылка - это обертка, но, как мне кажется, черезчур большой акцент делается на возможности изменения объекта, на который ссылается псевдоним. В очень многих ситуациях, когда в функции один из параметров - ссылка, она используется как read-only сущность. Тогда она помечена как const. Поэтому она лишь задает значение другим сущностям. А раз так, то нам в целом и нужен этот функционал изменения оригинального объекта и можно подумать, что в этом случае нужно по значению принимать аргумент. А вот нет. Тогда у нас будет дополнительное копирование. Нам такого не нужно. Мы общество без лишних копирований! Поэтому можно воспользоваться свойством, что ссылка - обертка над указателем. А значит мы можем с ее помощью без копирований задать значение другим объектам.
2️⃣ Output параметры. Уже ближе к способности изменения оригинального объекта. Иногда не хватает одного возвращаемого значения в функции, поэтому прибегают к использованию output параметров, чтобы функция передала нужную информацию через них. Есть конечно туплы или можно запилить отдельный класс, который в себе будет инкапсулировать нужные параметры, и возвращать его. Но туплы не очень информативные, так как у их элементов нет своих имен, а постоянно плодить сущности - не всегда удобно. Поэтому на помощь могут прийти output параметры. В этом случае они передаются по неконстантной ссылке. Просто в функцию передаются "пустые" объекты, то есть только что дефолтно созданные. И в этой функции на них нанизывается нужная информация. Которую мы потом может достать с помощью такой ссылочной семантики.
3️⃣ Изменение оригинального объекта. Эт вот та история, с которой я начал. Но! По моему опыту, это не самый популярный кейс использования ссылок. Попробую объяснить. Для кастомных классов очень часто приходится использовать std::shared_ptr, если время его жизни больше времени жизни скоупа. Тогда этот указатель везде передается по константной ссылке, хотя и объект, на который он указывает, можно изменять. Если нужно изменить какой-то объект, который создан на стеке, это нужно скорее делать через его собственные методы, а не сторонние функции. Так объект становится актором и проще воспринимать действия, которые происходят с ним происходят. Это вот та самая инкапсуляция.
4️⃣ Предоставление доступа к содержимому класса, без раскрытия приватных членов. Таким свойством обладает неконстантный operator[] для контейнеров STL. Вектору опасно предоставлять доступ к буфферу данных, где хранятся все объекты. Но более менее безопасно давать доступ к отдельным элементам для возможности их модификации. Это очень похожая на прошлый пример механика. Только в качестве текущего стейта выступает объект со своим содержимым, а модифицирующей функцией - текущая функция, в которой применяем operator[].
ПРОДОЛЖЕНИЕ В КОММЕНТАХ
#cppcore #goodpractice #design #STL
Еще один способ решения Static Initialization Order Fiasco
#опытным
Предыдущий пост навел меня на еще один метод решения SIOF. Это в догонку к этому посту с решениями.
Суть в чем. Как верно указал наш подписчик xiran в этом комментарии - управлять временем жизни глобальных динамически созданных объектов намного проще, чем временем жизни статиков. Поэтому можно объявить не статические переменные, а статические указатели. Указатель можно инициализировать nullptr и оставить его в таком состоянии хоть на месяц. И вы можете его инициализировать в любой подходящий для вас момент времени.
Это позволит вам в одном месте инициализировать связанные объекты сразу и в том порядке, в котором это не вызовет неприятных эффектов. Вы полностью контролируете ситуацию.
Примерно так это все выглядит. Если раньше, при обычной инициализации статиков в разных единицах трансляции, у нас порядок зависел от разумения линкера, то сейчас как ни компилируй, как ни линкуй, как ни меняй версию компилятора - все будет работать. Расширяйте этот пример как угодно, тема рабочая.
Правда тут есть одна загвоздочка, как вы могли заметить. У нас статиками являются обычные указатели и при разрушении всех статиков освободится лишь те 8 байт, которые были отведены этому указателю и никакого delete вызвано не будет. Как бы ситуация не очень, но нам и не всегда нужны эффекты от удаления статических объектов.
И эту загвоздочку прекрасно решают умные указатели. Сергей в своем комменте заванговал их использование. Покажу на примере unique_ptr. При деинициализации статиков вызовется деструктор unique_ptr, который за собой потянет деструктор объекта. Тут тоже могут быть проблемы с индирекцией данных и более медленным доступом к ним, но это настолько редкий кейс с плохим дизайном, что не хочется это даже обсуждать.
Вот так это выглядит в "идеале". Можете дальше пользоваться своими глобальными переменными(осуждаем), но хотя бы безопасно.
Stay safe. Stay cool.
#cpprore #cpp11 #STL #pattern
#опытным
Предыдущий пост навел меня на еще один метод решения SIOF. Это в догонку к этому посту с решениями.
Суть в чем. Как верно указал наш подписчик xiran в этом комментарии - управлять временем жизни глобальных динамически созданных объектов намного проще, чем временем жизни статиков. Поэтому можно объявить не статические переменные, а статические указатели. Указатель можно инициализировать nullptr и оставить его в таком состоянии хоть на месяц. И вы можете его инициализировать в любой подходящий для вас момент времени.
Это позволит вам в одном месте инициализировать связанные объекты сразу и в том порядке, в котором это не вызовет неприятных эффектов. Вы полностью контролируете ситуацию.
// header.hpp
struct Class {
Class(int num) : field{num} {}
int field;
};
// source.cpp
Class * static_ptr2 = nullptr;
//main.cpp
int * static_ptr1;
extern Class * static_ptr2;
void Init() {
static_ptr1 = new int{6};
static_ptr2 = new Class{*static_ptr1};
}
int main() {
Init();
std::cout << static_ptr2->field << std::endl;
}
Примерно так это все выглядит. Если раньше, при обычной инициализации статиков в разных единицах трансляции, у нас порядок зависел от разумения линкера, то сейчас как ни компилируй, как ни линкуй, как ни меняй версию компилятора - все будет работать. Расширяйте этот пример как угодно, тема рабочая.
Правда тут есть одна загвоздочка, как вы могли заметить. У нас статиками являются обычные указатели и при разрушении всех статиков освободится лишь те 8 байт, которые были отведены этому указателю и никакого delete вызвано не будет. Как бы ситуация не очень, но нам и не всегда нужны эффекты от удаления статических объектов.
И эту загвоздочку прекрасно решают умные указатели. Сергей в своем комменте заванговал их использование. Покажу на примере unique_ptr. При деинициализации статиков вызовется деструктор unique_ptr, который за собой потянет деструктор объекта. Тут тоже могут быть проблемы с индирекцией данных и более медленным доступом к ним, но это настолько редкий кейс с плохим дизайном, что не хочется это даже обсуждать.
// header.hpp
struct Class {
Class(int num) : field{num} {}
int field;
};
// source.cpp
std::unique_ptr<Class> static_ptr2 = nullptr;
//main.cpp
std::unique_ptr<int> static_ptr1 = nullptr;
extern std::unique_ptr<Class> static_ptr2;
void Init() {
static_ptr1 = std::make_unique<int>(6);
static_ptr2 = std::make_unique<Class>(*static_ptr1);
}
int main() {
Init();
std::cout << static_ptr2->field << std::endl;
}
Вот так это выглядит в "идеале". Можете дальше пользоваться своими глобальными переменными(осуждаем), но хотя бы безопасно.
Stay safe. Stay cool.
#cpprore #cpp11 #STL #pattern
{kind=link}
Вектор ссылок
#опытным
Не знаю, задумывались ли вы когда-нибудь создать вектор ссылок. Наверное задумывались, но не прям, чтобы пытались воплотить в жизнь. Не очень понятны кейсы применения этих сущностей. Однако они довольно хорошо подсвечивают одну интересную и базовую особенность вектора.
Дело в том, что вы не можете создать вектор ссылок. Не можете и все. Попробуйте написать что-то такое и запустить сборку:
Вылезет какая-то совершенно монструозная кракозябра, по которой мы хрен пойми, что должны понять. Это немного камней в огород бесполезных сообщений об ошибках в плюсах, но продолжим.
В сущности это происходит по одной причине. Шаблонный тип
До C++11 и появления мув-семантики элементы вектора должны были удовлетворять требованиям CopyAssignable и CopyConstructible. То есть из этих объектов должны получаться валидные копии, притом что исходный объект оказывается нетронутым. Это условие, кстати, не выполняется для запрещенного в РФ иноагента std::auto_ptr. Так вот ссылочный тип - не CopyAssignable. При попытке присвоить ссылке что-то копирования не происходит, а происходит просто перенаправление ссылки на другой объект.
После С++11 требования немного смягчились и теперь единственный критерий, которому тип элементов вектора должен удовлетворять - Erasable. Но ссылки также не попадают под этот критерий(для них не определен деструктор). Поэтому сидим без вектора ссылок. Или нет?
Можно хакнуть этот ваш сиплюсплюс и создать вектор из std::reference_wrapper. Это такая тривиальная обертка над ссылками, чтобы ими можно было оперировать, как обычными объектами. В смысле наличия у них всех специальных методов классов.
Но будьте осторожны(!), потому что есть одна большая проблема со ссылками. Вот мы создали и заполнили контейнер ссылками на какие-то объекты. И потом вышли из скоупа, где были объявлены объекты, на которые ссылки указывают. Вектор есть, ссылки есть, а объектов нет. Это чистой воды undefined behavior. Ссылки будут указывать на уже удаленные объекты. Пример:
Вывод будет такой:
Подумайте пару секунд, почему так. Переменная i меняется и мы добавляем ссылки на эту переменную в вектор. По итогу все элементы вектора указывают на одну и ту же переменную. Поэтому и элементы все одинаковы.
Но раз ссылка - это обертка над указателем, то элементы вектора по факту хранят адрес того места, где была переменная i. Поэтому все изменения ячейки памяти этой переменной будут отражаться на ссылках, даже если переменная уже удалена. Вот мы и сделали грязь: сохранили адрес ячейки и изменили его после выхода из скоупа цикла и удаления переменной i. Так обычно и происходит на стеке: переменная кладется на стек, с ней работают, она удаляется при выходе из скоупа и потом другие объект занимают место удаленной переменной в памяти. Мы здесь сымитировали такой процесс.
Так как вектор после выхода из скоупа цикла хранит висячие ссылки, то поведение в такой ситуации неопределено и наш грязный мув четко это показывает. После присваивания нового значения по указателю
Будьте аккуратны со ссылками. В этом случае проще использовать какой-нибудь умный указатель. Все будет чинно и цивильно. И никакого UB.
Be careful. Stay cool.
#cpp11 #cppcore #STL
#опытным
Не знаю, задумывались ли вы когда-нибудь создать вектор ссылок. Наверное задумывались, но не прям, чтобы пытались воплотить в жизнь. Не очень понятны кейсы применения этих сущностей. Однако они довольно хорошо подсвечивают одну интересную и базовую особенность вектора.
Дело в том, что вы не можете создать вектор ссылок. Не можете и все. Попробуйте написать что-то такое и запустить сборку:
std::vector<int&> vec;
Вылезет какая-то совершенно монструозная кракозябра, по которой мы хрен пойми, что должны понять. Это немного камней в огород бесполезных сообщений об ошибках в плюсах, но продолжим.
В сущности это происходит по одной причине. Шаблонный тип
vec не удовлетворяет требованиям к типам элементов вектора.До C++11 и появления мув-семантики элементы вектора должны были удовлетворять требованиям CopyAssignable и CopyConstructible. То есть из этих объектов должны получаться валидные копии, притом что исходный объект оказывается нетронутым. Это условие, кстати, не выполняется для запрещенного в РФ иноагента std::auto_ptr. Так вот ссылочный тип - не CopyAssignable. При попытке присвоить ссылке что-то копирования не происходит, а происходит просто перенаправление ссылки на другой объект.
После С++11 требования немного смягчились и теперь единственный критерий, которому тип элементов вектора должен удовлетворять - Erasable. Но ссылки также не попадают под этот критерий(для них не определен деструктор). Поэтому сидим без вектора ссылок. Или нет?
Можно хакнуть этот ваш сиплюсплюс и создать вектор из std::reference_wrapper. Это такая тривиальная обертка над ссылками, чтобы ими можно было оперировать, как обычными объектами. В смысле наличия у них всех специальных методов классов.
Но будьте осторожны(!), потому что есть одна большая проблема со ссылками. Вот мы создали и заполнили контейнер ссылками на какие-то объекты. И потом вышли из скоупа, где были объявлены объекты, на которые ссылки указывают. Вектор есть, ссылки есть, а объектов нет. Это чистой воды undefined behavior. Ссылки будут указывать на уже удаленные объекты. Пример:
std::vector<std::reference_wrapper<int>> vec;
int * p = nullptr;
{
int i;
for (i = 0, p = &i; i < 5; i++) {
vec.emplace_back(i);
}
}
*p = 10;
for (int i = 0; i < 5; i++) {
std::cout << vec[i] << std::endl;
}
Вывод будет такой:
10
10
10
10
10
Подумайте пару секунд, почему так. Переменная i меняется и мы добавляем ссылки на эту переменную в вектор. По итогу все элементы вектора указывают на одну и ту же переменную. Поэтому и элементы все одинаковы.
Но раз ссылка - это обертка над указателем, то элементы вектора по факту хранят адрес того места, где была переменная i. Поэтому все изменения ячейки памяти этой переменной будут отражаться на ссылках, даже если переменная уже удалена. Вот мы и сделали грязь: сохранили адрес ячейки и изменили его после выхода из скоупа цикла и удаления переменной i. Так обычно и происходит на стеке: переменная кладется на стек, с ней работают, она удаляется при выходе из скоупа и потом другие объект занимают место удаленной переменной в памяти. Мы здесь сымитировали такой процесс.
Так как вектор после выхода из скоупа цикла хранит висячие ссылки, то поведение в такой ситуации неопределено и наш грязный мув четко это показывает. После присваивания нового значения по указателю
p все ссылки будут иметь то же самое значение. Хотя изначально такая ситуация вообще не предполагалась.Будьте аккуратны со ссылками. В этом случае проще использовать какой-нибудь умный указатель. Все будет чинно и цивильно. И никакого UB.
Be careful. Stay cool.
#cpp11 #cppcore #STL
{kind=link}
Странный размер std::unordered_map
#опытным
Стандартная ситуация. Создаем контейнер, резервируем подходящий размер для ожидаемого количества элементов в коллекции и запихиваем элементы. Все просто. Но это с каким-нибудь вектором все просто. А хэш-мапа - дело нетривиальное. Смотрим на код:
Все, как обычно. А теперь вывод:
WTF? Я же сказал выделить в мапе 6 бакетов, а не 7. Какой непослушный компилятор!
Вообще, поведение странное, но может там просто всегда +1 по какой-то причине?
Поменяем map_size на 9 и посмотрим вывод:
Again. WTF? Уже на 2 разница. Нужна новая гипотеза... Попробуем третье число. Возьмем 13.
А тут работает! Но это не прибавляет понимания проблемы... В чем же дело?
Из цппреференса про метод reserve:
То есть стандарт разрешает реализациям выделять больше элементов для мапы, чем мы запросили.
Легитимацию безобразия мы получили, но хотелось бы внятное объяснение причины предоставления такой возможности.
Реализации обычно выбирают bucket_count исходя из соображений быстродействия(как обычно). Тут они выбирают из двух опций:
1️⃣ Выбирают в качестве bucket_count степень двойки, то есть округляют до степени двойки в большую сторону. Это помогает эффективно маппить результат хэш функции на размер самой хэш-таблицы. Можно просто сделать битовое И и отбросить все биты, старше нашей степени. Что делается на один цикл цпу.
Но этот способ имеет негативный эффект в виде того же отбрасывания битов. То есть эти страшие биты никак не влияют на маппинг хэша на бакеты, то уменьшает равномерность распределения.
Таким способом пользуется Visual C++.
2️⃣ Поддерживают bucket_count простым числом.
Это дает крутой эффект того, что старшие биты также влияют на распределение объектов по бакетам. В этом случае даже плохие хэш-функции имеют более равномерное размещение бакетов.
Однако наивная реализация такого подхода заставляет каждый раз делить на рантаймовое значение bucket_count, что может занимать до 100 раз больше циклов.
Более быстрой альтернативой может быть использование захардкоженой таблицы простых чисел. Индекс в ней выбирается на основе запрашиваемого значения bucket_count. Таким образом компилятор может заоптимизировать деление по модулю через битовые операции, сложения, вычитания и умножения. Можете посмотреть на эти оптимизации более подробно на этом примере в годболт.
Этой реализацией пользуется GCC и Clang.
Вот такие страсти происходят у нас под носом под капотом неупорядоченной мапы.
Optimize everything. Stay cool.
#STL #optimization #compiler
#опытным
Стандартная ситуация. Создаем контейнер, резервируем подходящий размер для ожидаемого количества элементов в коллекции и запихиваем элементы. Все просто. Но это с каким-нибудь вектором все просто. А хэш-мапа - дело нетривиальное. Смотрим на код:
constexpr size_t map_size = 6;
std::unordered_map<int, int> mymap;
mymap.reserve(map_size);
for (int i = 0; i < map_size; i++) {
mymap[i] = i;
}
std::cout << "mymap has " << mymap.bucket_count() << " buckets\n";
Все, как обычно. А теперь вывод:
mymap has 7 buckets
WTF? Я же сказал выделить в мапе 6 бакетов, а не 7. Какой непослушный компилятор!
Вообще, поведение странное, но может там просто всегда +1 по какой-то причине?
Поменяем map_size на 9 и посмотрим вывод:
mymap has 11 buckets
Again. WTF? Уже на 2 разница. Нужна новая гипотеза... Попробуем третье число. Возьмем 13.
mymap has 13 buckets
А тут работает! Но это не прибавляет понимания проблемы... В чем же дело?
Из цппреференса про метод reserve:
Request a capacity change
Sets the number of buckets in the container (bucket_count) to the most appropriate to contain at least n elements.
То есть стандарт разрешает реализациям выделять больше элементов для мапы, чем мы запросили.
Легитимацию безобразия мы получили, но хотелось бы внятное объяснение причины предоставления такой возможности.
Реализации обычно выбирают bucket_count исходя из соображений быстродействия(как обычно). Тут они выбирают из двух опций:
1️⃣ Выбирают в качестве bucket_count степень двойки, то есть округляют до степени двойки в большую сторону. Это помогает эффективно маппить результат хэш функции на размер самой хэш-таблицы. Можно просто сделать битовое И и отбросить все биты, старше нашей степени. Что делается на один цикл цпу.
Но этот способ имеет негативный эффект в виде того же отбрасывания битов. То есть эти страшие биты никак не влияют на маппинг хэша на бакеты, то уменьшает равномерность распределения.
Таким способом пользуется Visual C++.
2️⃣ Поддерживают bucket_count простым числом.
Это дает крутой эффект того, что старшие биты также влияют на распределение объектов по бакетам. В этом случае даже плохие хэш-функции имеют более равномерное размещение бакетов.
Однако наивная реализация такого подхода заставляет каждый раз делить на рантаймовое значение bucket_count, что может занимать до 100 раз больше циклов.
Более быстрой альтернативой может быть использование захардкоженой таблицы простых чисел. Индекс в ней выбирается на основе запрашиваемого значения bucket_count. Таким образом компилятор может заоптимизировать деление по модулю через битовые операции, сложения, вычитания и умножения. Можете посмотреть на эти оптимизации более подробно на этом примере в годболт.
Этой реализацией пользуется GCC и Clang.
Вот такие страсти происходят у нас под носом под капотом неупорядоченной мапы.
Optimize everything. Stay cool.
#STL #optimization #compiler
{kind=link}
Результаты ревью
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
template<typename T, template<class,class...> class C, class... Args>
std::ostream& operator <<(std::ostream& os, C<T,Args...> objs)
{
os << PRETTY_FUNCTION << '\n';
for (auto obj : objs)
os << obj << ' ';
return os;
}
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
std::copy(vec.begin(), vec.end(),
std::experimental::make_ostream_joiner(std::cout, ", "));
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
{kind=link}
Опасности std::unordered_map
#опытным
Когда писал прошлый пост, я хотел сразу вставить в пример range-based-for, чтобы показать одну приколюху. Но решил, что это заслуживает отдельного поста.
В копилку полезности auto.
Вдруг вы решили не пользоваться этой фичей и пишите вот так:
Вроде бы все хорошо и выглядит, как надо. И ожидать мы в консоли будем такой вывод:
При заполнении вектора кастомеры копируются из временных объектов, вызывается копирующий конструктор с принтом, и далее вывод цикла.
Однако на самом деле вывод будет такой:
Мы этого совсем не ожидали. Откуда еще 2 копии?!!
Дело в том, что в нашей неупорядоченной мапе хранятся не std::pair<std::string, std::vector<Customer>>, а std::pair<const std::string, std::vector<Customer>>. Это в принципе особенность std::unordered_map: ключ мапы - неизменяемый объект, поэтому обобщенно мапа хранит std::pair<const Key, Value>.
И у компилятора не получается забиндить пару с константным ключом к паре с неконстантным. Но делать-то что-то надо. Поэтому он просто делает копию пары, лежащей в мапе, и переменная цикла item ссылается на этот временный объект. Дальше временный объект уничтожается после завершения своей итерации цикла и уходит в историю, как тот, кого не ждали, кто просто так пожрал ресурсы, ничего полезного не сделал и ушел. Осуждаю таких наглецов.
Ну и естественно, эта проблема просто решается использованием ключевого слова auto.
Теперь у нас есть ожидаемый вывод.
Make your life easier. Stay cool.
#cpp11 #STL
#опытным
Когда писал прошлый пост, я хотел сразу вставить в пример range-based-for, чтобы показать одну приколюху. Но решил, что это заслуживает отдельного поста.
В копилку полезности auto.
Вдруг вы решили не пользоваться этой фичей и пишите вот так:
struct Customer{
Customer(int num) : data{num} {}
Customer(const Customer& other) {
data = other.data;
std::cout << "Copy ctor" << std::endl;
}
private:
int data;
};
std::unordered_map<std::string, std::vector<Customer>> data;
data["qwe"] = {Customer{1}, Customer{2}};
for (const std::pair<std::string, std::vector<Customer>>& item : data) {
std::cout << "Idle print" << std::endl;
}Вроде бы все хорошо и выглядит, как надо. И ожидать мы в консоли будем такой вывод:
Copy ctor
Copy ctor
Idle print
При заполнении вектора кастомеры копируются из временных объектов, вызывается копирующий конструктор с принтом, и далее вывод цикла.
Однако на самом деле вывод будет такой:
Copy ctor
Copy ctor
Copy ctor
Copy ctor
Idle print
Мы этого совсем не ожидали. Откуда еще 2 копии?!!
Дело в том, что в нашей неупорядоченной мапе хранятся не std::pair<std::string, std::vector<Customer>>, а std::pair<const std::string, std::vector<Customer>>. Это в принципе особенность std::unordered_map: ключ мапы - неизменяемый объект, поэтому обобщенно мапа хранит std::pair<const Key, Value>.
И у компилятора не получается забиндить пару с константным ключом к паре с неконстантным. Но делать-то что-то надо. Поэтому он просто делает копию пары, лежащей в мапе, и переменная цикла item ссылается на этот временный объект. Дальше временный объект уничтожается после завершения своей итерации цикла и уходит в историю, как тот, кого не ждали, кто просто так пожрал ресурсы, ничего полезного не сделал и ушел. Осуждаю таких наглецов.
Ну и естественно, эта проблема просто решается использованием ключевого слова auto.
struct Customer{
Customer(int num) : data{num} {}
Customer(const Customer& other) {
data = other.data;
std::cout << "Copy ctor" << std::endl;
}
private:
int data;
};
std::unordered_map<std::string, std::vector<Customer>> data;
data["qwe"] = {Customer{1}, Customer{2}};
for (const auto& item : data) {
std::cout << "Idle print" << std::endl;
}
Теперь у нас есть ожидаемый вывод.
Make your life easier. Stay cool.
#cpp11 #STL
{kind=link}
Примеры использования const T&&
#опытным
В прошлый раз мы поговорили о том, что можно использовать константную правую ссылку для того, чтобы запретить принимать любые rvalue reference в функцию.
Для чего это может быть нужно?
Допустим, мы храним в поле класса в каком-то виде ссылку на объект. И нам бы очень не хотелось принимать в конструкторе rvalue reference, потому что возможно сразу же после выхода из конструктора для объектов вызовется деструктор и хана этим объектам. И встречаем UB из-за хранения битой ссылки.
Есть такой стандартный класс std::reference_wrapper и его функции помощники std::ref() и std::cref(). Поскольку std::reference_wrapper предполагает хранение ссылки только для lvalue, то стандарт удалил перегрузки std::ref() и std::cref(), которые принимают const T&&.
По той же самой причине такая перегрузка удалена у функции std::as_const, которая формирует левую ссылку на константный тип из аргумента.
Также константные правые ссылки используются в более сложных штуках, типа std::optional, когда нужно вернуть из него значение.
С этой же целью оно используется, например, и в std::get.
В таких случаях использование const T&& оправдано передачей информации и о ссылочности типа, и о его константности. Это важно в обобщенном программировании, потому что никто не знает с каким типом будет работать шаблонная сущность. Вы вполне можете получить константный временный объект std::optional(да и любого другого объекта), это синтаксически корректно. И чтобы геттер его внутреннего значение отражал свойства обертки, приходится перегружать эти геттеры для любых возможных параметров. Так вот например методы std::optional упомянутые выше вызовутся только для временных константных объектов. И эти свойства отображаются в возвращаемом значении.
Также не стоит забывать, что константность объекта не накладывает ультимативных ограничений на использование объекта. Есть мутабельные и статические поля, которые можно изменять, и плевать они хотели на вашу константность. А также указатели. Мы не можем менять сам указатель, но можем изменить объект, на который он указывает. Это немного расширяет спектр возможностей использования константных правых ссылок, но не прям существенно. В голову пришел очевидный пример - pimpl idiom. Согласно этой идиоме класс хранит указатель на реализацию, в которой может лежать все, что угодно. Все операции, которые как-то изменяют состояние объекта, влияют на данные внутри указателя. Поэтому снаружи кажется, что объект и не изменился. Да и старый объект можно будет использовать. Непонятно только, зачем менять привычные традиции использования правых ссылок, но все же.
Stay useful even if nobody understands you. Stay cool.
#template #cpp11 #STL
#опытным
В прошлый раз мы поговорили о том, что можно использовать константную правую ссылку для того, чтобы запретить принимать любые rvalue reference в функцию.
Для чего это может быть нужно?
Допустим, мы храним в поле класса в каком-то виде ссылку на объект. И нам бы очень не хотелось принимать в конструкторе rvalue reference, потому что возможно сразу же после выхода из конструктора для объектов вызовется деструктор и хана этим объектам. И встречаем UB из-за хранения битой ссылки.
Есть такой стандартный класс std::reference_wrapper и его функции помощники std::ref() и std::cref(). Поскольку std::reference_wrapper предполагает хранение ссылки только для lvalue, то стандарт удалил перегрузки std::ref() и std::cref(), которые принимают const T&&.
template <class T> void ref(const T&&) = delete;
template <class T> void cref(const T&&) = delete;
По той же самой причине такая перегрузка удалена у функции std::as_const, которая формирует левую ссылку на константный тип из аргумента.
template< class T >
constexpr std::add_const_t<T>& as_const( T& t ) noexcept;
Также константные правые ссылки используются в более сложных штуках, типа std::optional, когда нужно вернуть из него значение.
constexpr const T&& operator*() const&&;
constexpr const T&& value() const &&;
С этой же целью оно используется, например, и в std::get.
template< std::size_t I, class... Types >
constexpr const std::variant_alternative_t<I, std::variant<Types...>>&&
get( const std::variant<Types...>&& v );
template< class T, class... Types >
constexpr const T&& get( const std::variant<Types...>&& v );
В таких случаях использование const T&& оправдано передачей информации и о ссылочности типа, и о его константности. Это важно в обобщенном программировании, потому что никто не знает с каким типом будет работать шаблонная сущность. Вы вполне можете получить константный временный объект std::optional(да и любого другого объекта), это синтаксически корректно. И чтобы геттер его внутреннего значение отражал свойства обертки, приходится перегружать эти геттеры для любых возможных параметров. Так вот например методы std::optional упомянутые выше вызовутся только для временных константных объектов. И эти свойства отображаются в возвращаемом значении.
Также не стоит забывать, что константность объекта не накладывает ультимативных ограничений на использование объекта. Есть мутабельные и статические поля, которые можно изменять, и плевать они хотели на вашу константность. А также указатели. Мы не можем менять сам указатель, но можем изменить объект, на который он указывает. Это немного расширяет спектр возможностей использования константных правых ссылок, но не прям существенно. В голову пришел очевидный пример - pimpl idiom. Согласно этой идиоме класс хранит указатель на реализацию, в которой может лежать все, что угодно. Все операции, которые как-то изменяют состояние объекта, влияют на данные внутри указателя. Поэтому снаружи кажется, что объект и не изменился. Да и старый объект можно будет использовать. Непонятно только, зачем менять привычные традиции использования правых ссылок, но все же.
// MyClass.hpp
class MyClass {
public:
MyClass();
MyClass(int g_meat);
MyClass(const MyClass &&other); // const rvalue reference!
~MyClass();
int GetMeat() const;
private:
class Pimpl;
Pimpl *impl {};
};
// MyClass.cpp
class MyClass::Pimpl {
public:
int meat {42};
};
MyClass::MyClass() : impl {new Pimpl} { }
MyClass::MyClass(int g_meat) : MyClass() {
impl->meat = g_meat;
}
MyClass::MyClass(const MyClass &&other) : MyClass()
{
impl->meat = other.impl->meat;
other.impl->meat = 0;
}
MyClass::~MyClass() { delete impl; }
int MyClass::GetMeat() const {
return impl->meat;
}
// main.cpp
int main() {
const MyClass a {100500};
MyClass b (std::move(a)); // moving from const!
std::cout << a.GetMeat() << "\n"; // returns 0, b/c a is moved-from
std::cout << b.GetMeat() << "\n"; // returns 100500
}
Stay useful even if nobody understands you. Stay cool.
#template #cpp11 #STL
{kind=link}