Невероятные вероятности
Зачастую, когда мы пишем какие-то условия, то предполагаем, что какая-то ветка будет выполняться чаще другой. Самый простой пример - проверка чего-то на корректность. И если это что-то некорректно, то мы делаем какие-то действия, сигнализирующие о проблеме. И логично предположить, что наша программа хорошо написана (по крайней мере мы в это охотно верим). Поэтому ошибка - некая экстренная ситуация, которая не должна появляться часто. В принципе, любой не happy path может рассматриваться, как пример такой ситуации.
Может ли нам это знание как-то помочь? Вполне. В процессорах есть такой модуль - предсказатель переходов. На основе кода он по определенным эвристикам пытается понять, какая из веток выполниться с большей вероятностью. Он заранее подгружает данные и код для этой ветки, чтобы в случае удачного предсказания сократить время простоя вычислительного конвейера. И на самом деле, современные процессоры - настоящие Ванги! Их модуль предсказания переходов принимает правильные решения примерно в 90% случаев! Что не мало. Но все равно не идеально.
И вот тут-то мы и вступаем в дело. Мы можем немножко помочь предсказателю сделать более правильный выбор в конкретной ситуации. Путем указания ветки, которая по нашему мнению, будет выполняться с большей вероятностью.
У компиляторов есть свои расширения, которые могут помочь нам в этой задаче. Но они нам больше не нужны!
Потому что в С++20 появились стандартные аттрибуты [[likely]] и [[unlikely]]!
Допустим, мы пишем свой вектор интов. Причины покататься на байсикле мы отбросим в сторону и сконцентрируемся на сути. И мы дошли до метода MyVector::at, который по индексу выдает элемент. Но фишка в том, что этот метод проверяет индекс на нахождение в границах дозволенного и кидает исключение, если нештатная ситуация все-таки произошла.
Это довольно базовый класс, которым будет пользоваться множество программистов во множестве модулей. И разумно предположить, что большинство использований этого метода будут вполне корректны и все будет стабильно работать. Поэтому вполне логично сказать компилятору встроить в код подсказку, которая поможет процессору предсказывать правильно с большей вероятностью.
Ставьте лайки, если хотите немного бэнчмарков на эту тему. Если хотите что-то определенное померять(в пределах разумного времени написания поста), то пишите в комментах свои идеи.
Predict people's actions. Stay cool.
#cpp20 #compiler #performance
Зачастую, когда мы пишем какие-то условия, то предполагаем, что какая-то ветка будет выполняться чаще другой. Самый простой пример - проверка чего-то на корректность. И если это что-то некорректно, то мы делаем какие-то действия, сигнализирующие о проблеме. И логично предположить, что наша программа хорошо написана (по крайней мере мы в это охотно верим). Поэтому ошибка - некая экстренная ситуация, которая не должна появляться часто. В принципе, любой не happy path может рассматриваться, как пример такой ситуации.
Может ли нам это знание как-то помочь? Вполне. В процессорах есть такой модуль - предсказатель переходов. На основе кода он по определенным эвристикам пытается понять, какая из веток выполниться с большей вероятностью. Он заранее подгружает данные и код для этой ветки, чтобы в случае удачного предсказания сократить время простоя вычислительного конвейера. И на самом деле, современные процессоры - настоящие Ванги! Их модуль предсказания переходов принимает правильные решения примерно в 90% случаев! Что не мало. Но все равно не идеально.
И вот тут-то мы и вступаем в дело. Мы можем немножко помочь предсказателю сделать более правильный выбор в конкретной ситуации. Путем указания ветки, которая по нашему мнению, будет выполняться с большей вероятностью.
У компиляторов есть свои расширения, которые могут помочь нам в этой задаче. Но они нам больше не нужны!
Потому что в С++20 появились стандартные аттрибуты [[likely]] и [[unlikely]]!
Допустим, мы пишем свой вектор интов. Причины покататься на байсикле мы отбросим в сторону и сконцентрируемся на сути. И мы дошли до метода MyVector::at, который по индексу выдает элемент. Но фишка в том, что этот метод проверяет индекс на нахождение в границах дозволенного и кидает исключение, если нештатная ситуация все-таки произошла.
int MyVector::at(size_t index) {
if (index >= this->size) [[unlikely]] {
throw std::out_of_range ("MyVector index is out of range");
}
return this->data[index];
}
Это довольно базовый класс, которым будет пользоваться множество программистов во множестве модулей. И разумно предположить, что большинство использований этого метода будут вполне корректны и все будет стабильно работать. Поэтому вполне логично сказать компилятору встроить в код подсказку, которая поможет процессору предсказывать правильно с большей вероятностью.
Ставьте лайки, если хотите немного бэнчмарков на эту тему. Если хотите что-то определенное померять(в пределах разумного времени написания поста), то пишите в комментах свои идеи.
Predict people's actions. Stay cool.
#cpp20 #compiler #performance
{kind=link}
June 23, 2024
Директивы ifdef, ifndef, if
#новичкам
Иногда код, который мы пишем, должен зависеть от каких-то внешних параметров. Например, неплохо было бы довалять дебажный вывод при дебажной сборке. Или нам нужно написать кусочек платформоспецифичного кода и конкретная платформа передается нам наружными параметрами. Разные в общем бывают ситуации. Получается нам нужен какой-то механизм, который может проверять эти внешние параметры и в зависимости от их значений включать или выключать нужный кусок кода. Эту задачу можно решать по-разному. Сегодня мы обсудим доисторический способ, который, несмотря на свой почтенный возраст и опасность применения, активно используется в существующих проектах.
Этот способ - использование директив препроцессора #ifdef, #ifndef, #if. Все три - условные конструкции. Первая смотрит, определен ли в коде какой-то макрос. Если да, то делаем одни действия, если нет - другие. Второй наоборот, входит в первую ветку условия, если макрос не определен, и входит во вторую, если определен. Директива #if проверяет какое-то условие, ничего необычного. Все три директивы могут иметь как полные формы(с веткой в случае если условие ложно), так и неполные(без "else").
И вот в чем их прикол. Препроцессор работает с текстом программы. И он просто удаляет из этого текста ненужную ветку так, что до компиляции она даже не доходит, а нужная ветка как раз и подвергается обработке компилятором.
Например, у нас есть какой-то платформоспецифичный участок кода. Пусть это будет низкоуровневая оптимизация скалярного произведения на векторных инструкциях. Они разные для интеловских процессоров и для армов. Код может выглядеть примерно так:
Если каждое значение CPU_TYPE включает нужную ветку кода и убирает из текста программы все остальные.
Если мы хотим оптимизировать только под интеловские процессоры, то можем написать чуть проще:
(Все примеры - учебные, все совпадения с реальным кодом - случайны, не повторяйте код в домашних условиях). Здесь мы проверяем директивой ifdef, определен ли макрос OPTIMIZATION_ON, сигнализирующий что нужно использовать векторные инструкции. Если да, то ключаем в текст программы оптимизированный код. Если нет - обычный.
Можно еще кучу примеров и приложений этим директивам привести. Но я хотел подчеркнуть именно вот эту особенность, что мы можем добавлять или выбрасывать определенные участки кода в зависимости от внешних параметров.
Широко известно, что такой способ не только устарел, но еще и опасен. Завтра посмотрим, чем конкретно.
Choose the right path. Stay cool.
#compiler
#новичкам
Иногда код, который мы пишем, должен зависеть от каких-то внешних параметров. Например, неплохо было бы довалять дебажный вывод при дебажной сборке. Или нам нужно написать кусочек платформоспецифичного кода и конкретная платформа передается нам наружными параметрами. Разные в общем бывают ситуации. Получается нам нужен какой-то механизм, который может проверять эти внешние параметры и в зависимости от их значений включать или выключать нужный кусок кода. Эту задачу можно решать по-разному. Сегодня мы обсудим доисторический способ, который, несмотря на свой почтенный возраст и опасность применения, активно используется в существующих проектах.
Этот способ - использование директив препроцессора #ifdef, #ifndef, #if. Все три - условные конструкции. Первая смотрит, определен ли в коде какой-то макрос. Если да, то делаем одни действия, если нет - другие. Второй наоборот, входит в первую ветку условия, если макрос не определен, и входит во вторую, если определен. Директива #if проверяет какое-то условие, ничего необычного. Все три директивы могут иметь как полные формы(с веткой в случае если условие ложно), так и неполные(без "else").
И вот в чем их прикол. Препроцессор работает с текстом программы. И он просто удаляет из этого текста ненужную ветку так, что до компиляции она даже не доходит, а нужная ветка как раз и подвергается обработке компилятором.
Например, у нас есть какой-то платформоспецифичный участок кода. Пусть это будет низкоуровневая оптимизация скалярного произведения на векторных инструкциях. Они разные для интеловских процессоров и для армов. Код может выглядеть примерно так:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#if CPU_TYPE == 0
// mmx|sse|avx code
#elif CPU_TYPE == 1
// arm neon code
#else
static_assert(0, "NO CPU_TYPE IS SPECIFIED");
#endif
return result;
}
Если каждое значение CPU_TYPE включает нужную ветку кода и убирает из текста программы все остальные.
Если мы хотим оптимизировать только под интеловские процессоры, то можем написать чуть проще:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#ifdef OPTIMIZATION_ON
// mmx|sse|avx code
#else
for (int i = 0; i < vec1.size(); ++i)
result += vec1[i] * vec2[i];
#endif
return result;
}
(Все примеры - учебные, все совпадения с реальным кодом - случайны, не повторяйте код в домашних условиях). Здесь мы проверяем директивой ifdef, определен ли макрос OPTIMIZATION_ON, сигнализирующий что нужно использовать векторные инструкции. Если да, то ключаем в текст программы оптимизированный код. Если нет - обычный.
Можно еще кучу примеров и приложений этим директивам привести. Но я хотел подчеркнуть именно вот эту особенность, что мы можем добавлять или выбрасывать определенные участки кода в зависимости от внешних параметров.
Широко известно, что такой способ не только устарел, но еще и опасен. Завтра посмотрим, чем конкретно.
Choose the right path. Stay cool.
#compiler
{kind=link}
July 9, 2024
Опасности использования директив препроцессора
Вчерашний способ выбора ветки кода имеет несколько недостатков:
⛔️ Препроцессор работает с буквами/текстом программы, но не понимает программных сущностей. Это значит, что типабезопасность уходит из окна, и открывается простор для разного рода трудноотловимых багов.
⛔️ При компиляции проверяется только та ветка, которая попадет в итоговый код. Если вы не протестировали сборку своего кода для разных значений внешних параметров, а такое бывает например когда пока что есть только одно значение, а другое будет только в будущем. И в будущем скорее всего придется отлаживать элементарную сборку, потому что в код попадет непроверенная ветка.
⛔️ Вы ограничены возможностями препроцессора. Это значит, что вы не можете использовать в условии compile-time вычисления (аля результат работы constexpr функции).
⛔️ Отсюда же вытекает отсутствие возможности проверки условий, основанных на шаблонных параметрах кода. Это все из-за того, что препроцессор работает до начала компиляции программы. Он в душе не знает, что вы вообще программу пишите. Ему в целом ничего не мешает обработать текст Войны и Мира. Именно из-за отсутствия понимания контекста программы, мы и не можем проверять условия, основанные на compile-time значениях или шаблонных параметрах. Если вы хотите проверить, указатель ли к вам пришел в функцию или нет, или собрать какую-то метрику с constexpr массива и на ее основе принять решение - у вас ничего не выйдет.
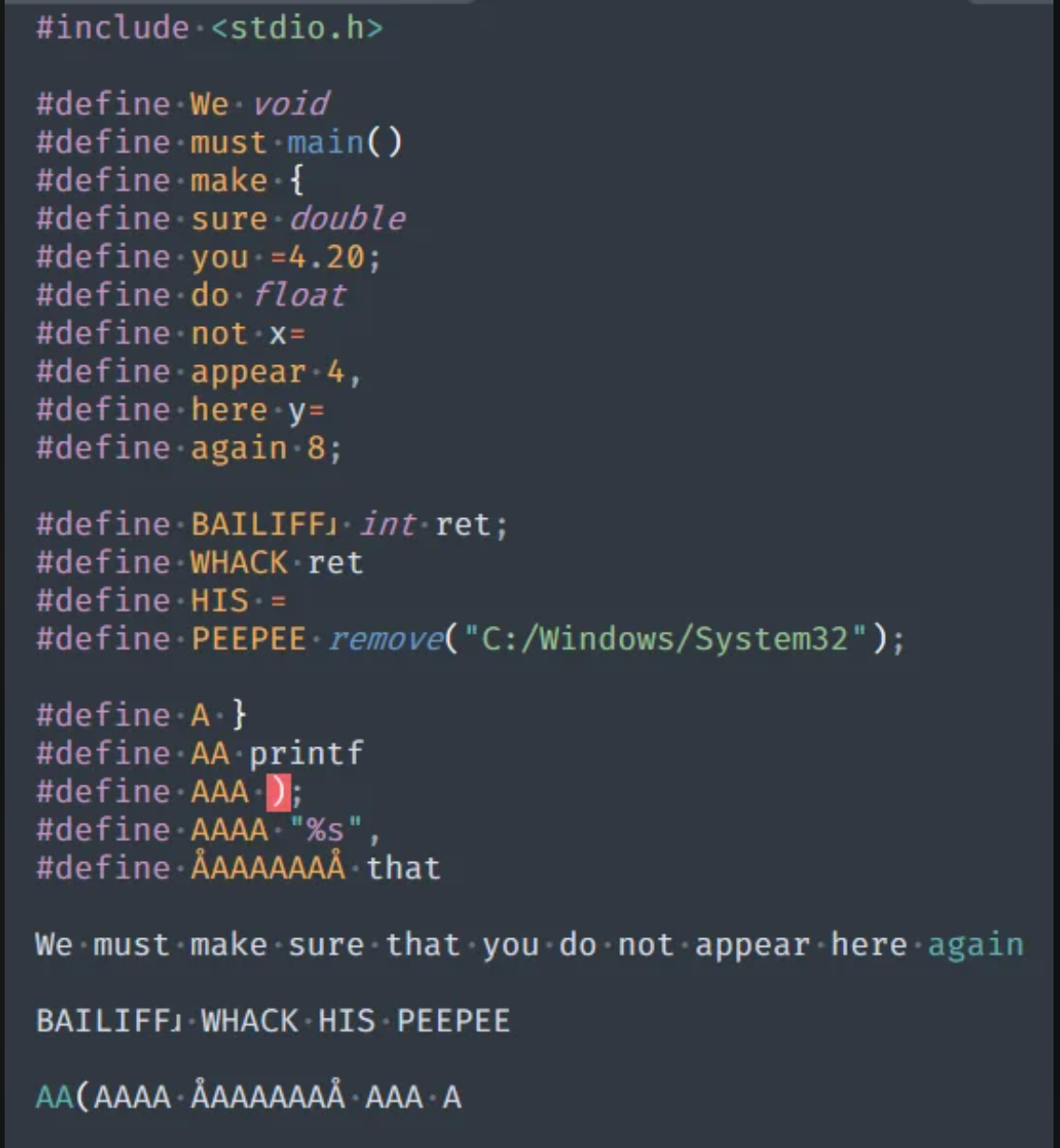
⛔️ Вы очень сильно ограничены возможностями препроцессора. Попробуйте например сравнить какой-нибудь макрос с фиксированной строкой. Спойлер: у вас скорее всего ничего не выйдет. Например, как в примере из поста выше мы не можем написать так:
Поэтому и приходилось определять тип циферками.
Это конечно мем: сущность, которая работает с текстом программы, то есть со строками, не может работать со строками.
⛔️ С препроцессором в принципе опасно работать и еще труднее отлаживать магические баги. Могут возникнуть например вот такие трудноотловимые ошибки. Вам придется смотреть уже обработанную единицу трансляции, причем иногда даже не понимая, где может быть проблема. А со всеми включенными бинарниками и преобразованиями препроцессора это делать очень долго и больно. А потом оказывается, что какой-то умник заменил в макросах функцию DontWorryBeHappy на ILovePainGiveMeMore.
В комментах @xiran22 скидывал пример библиотечки, написанной с помощью макросов. Вот она, можете посмотреть. Это не только пример сложности понимания кода и всех проблем выше. Тут просто плохая архитектура, затыки которой решаются макросами.
Поделитесь в комментах своими интересными кейсами простреленных ступней из-за макросов.
Avoid dangerous tools. Stay cool.
#compiler #cppcore
Вчерашний способ выбора ветки кода имеет несколько недостатков:
⛔️ Препроцессор работает с буквами/текстом программы, но не понимает программных сущностей. Это значит, что типабезопасность уходит из окна, и открывается простор для разного рода трудноотловимых багов.
⛔️ При компиляции проверяется только та ветка, которая попадет в итоговый код. Если вы не протестировали сборку своего кода для разных значений внешних параметров, а такое бывает например когда пока что есть только одно значение, а другое будет только в будущем. И в будущем скорее всего придется отлаживать элементарную сборку, потому что в код попадет непроверенная ветка.
⛔️ Вы ограничены возможностями препроцессора. Это значит, что вы не можете использовать в условии compile-time вычисления (аля результат работы constexpr функции).
⛔️ Отсюда же вытекает отсутствие возможности проверки условий, основанных на шаблонных параметрах кода. Это все из-за того, что препроцессор работает до начала компиляции программы. Он в душе не знает, что вы вообще программу пишите. Ему в целом ничего не мешает обработать текст Войны и Мира. Именно из-за отсутствия понимания контекста программы, мы и не можем проверять условия, основанные на compile-time значениях или шаблонных параметрах. Если вы хотите проверить, указатель ли к вам пришел в функцию или нет, или собрать какую-то метрику с constexpr массива и на ее основе принять решение - у вас ничего не выйдет.
⛔️ Вы очень сильно ограничены возможностями препроцессора. Попробуйте например сравнить какой-нибудь макрос с фиксированной строкой. Спойлер: у вас скорее всего ничего не выйдет. Например, как в примере из поста выше мы не можем написать так:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#if CPU_TYPE == "INTEL"
// mmx|sse|avx code
#elif CPU_TYPE == "ARM"
// arm neon code
#else
static_assert(0, "NO CPU_TYPE IS SPECIFIED");
#endif
return result;
}
Поэтому и приходилось определять тип циферками.
Это конечно мем: сущность, которая работает с текстом программы, то есть со строками, не может работать со строками.
⛔️ С препроцессором в принципе опасно работать и еще труднее отлаживать магические баги. Могут возникнуть например вот такие трудноотловимые ошибки. Вам придется смотреть уже обработанную единицу трансляции, причем иногда даже не понимая, где может быть проблема. А со всеми включенными бинарниками и преобразованиями препроцессора это делать очень долго и больно. А потом оказывается, что какой-то умник заменил в макросах функцию DontWorryBeHappy на ILovePainGiveMeMore.
В комментах @xiran22 скидывал пример библиотечки, написанной с помощью макросов. Вот она, можете посмотреть. Это не только пример сложности понимания кода и всех проблем выше. Тут просто плохая архитектура, затыки которой решаются макросами.
Поделитесь в комментах своими интересными кейсами простреленных ступней из-за макросов.
Avoid dangerous tools. Stay cool.
#compiler #cppcore
{kind=link}
July 10, 2024
Странный размер std::unordered_map
#опытным
Стандартная ситуация. Создаем контейнер, резервируем подходящий размер для ожидаемого количества элементов в коллекции и запихиваем элементы. Все просто. Но это с каким-нибудь вектором все просто. А хэш-мапа - дело нетривиальное. Смотрим на код:
Все, как обычно. А теперь вывод:
WTF? Я же сказал выделить в мапе 6 бакетов, а не 7. Какой непослушный компилятор!
Вообще, поведение странное, но может там просто всегда +1 по какой-то причине?
Поменяем map_size на 9 и посмотрим вывод:
Again. WTF? Уже на 2 разница. Нужна новая гипотеза... Попробуем третье число. Возьмем 13.
А тут работает! Но это не прибавляет понимания проблемы... В чем же дело?
Из цппреференса про метод reserve:
То есть стандарт разрешает реализациям выделять больше элементов для мапы, чем мы запросили.
Легитимацию безобразия мы получили, но хотелось бы внятное объяснение причины предоставления такой возможности.
Реализации обычно выбирают bucket_count исходя из соображений быстродействия(как обычно). Тут они выбирают из двух опций:
1️⃣ Выбирают в качестве bucket_count степень двойки, то есть округляют до степени двойки в большую сторону. Это помогает эффективно маппить результат хэш функции на размер самой хэш-таблицы. Можно просто сделать битовое И и отбросить все биты, старше нашей степени. Что делается на один цикл цпу.
Но этот способ имеет негативный эффект в виде того же отбрасывания битов. То есть эти страшие биты никак не влияют на маппинг хэша на бакеты, то уменьшает равномерность распределения.
Таким способом пользуется Visual C++.
2️⃣ Поддерживают bucket_count простым числом.
Это дает крутой эффект того, что старшие биты также влияют на распределение объектов по бакетам. В этом случае даже плохие хэш-функции имеют более равномерное размещение бакетов.
Однако наивная реализация такого подхода заставляет каждый раз делить на рантаймовое значение bucket_count, что может занимать до 100 раз больше циклов.
Более быстрой альтернативой может быть использование захардкоженой таблицы простых чисел. Индекс в ней выбирается на основе запрашиваемого значения bucket_count. Таким образом компилятор может заоптимизировать деление по модулю через битовые операции, сложения, вычитания и умножения. Можете посмотреть на эти оптимизации более подробно на этом примере в годболт.
Этой реализацией пользуется GCC и Clang.
Вот такие страсти происходят у нас под носом под капотом неупорядоченной мапы.
Optimize everything. Stay cool.
#STL #optimization #compiler
#опытным
Стандартная ситуация. Создаем контейнер, резервируем подходящий размер для ожидаемого количества элементов в коллекции и запихиваем элементы. Все просто. Но это с каким-нибудь вектором все просто. А хэш-мапа - дело нетривиальное. Смотрим на код:
constexpr size_t map_size = 6;
std::unordered_map<int, int> mymap;
mymap.reserve(map_size);
for (int i = 0; i < map_size; i++) {
mymap[i] = i;
}
std::cout << "mymap has " << mymap.bucket_count() << " buckets\n";
Все, как обычно. А теперь вывод:
mymap has 7 buckets
WTF? Я же сказал выделить в мапе 6 бакетов, а не 7. Какой непослушный компилятор!
Вообще, поведение странное, но может там просто всегда +1 по какой-то причине?
Поменяем map_size на 9 и посмотрим вывод:
mymap has 11 buckets
Again. WTF? Уже на 2 разница. Нужна новая гипотеза... Попробуем третье число. Возьмем 13.
mymap has 13 buckets
А тут работает! Но это не прибавляет понимания проблемы... В чем же дело?
Из цппреференса про метод reserve:
Request a capacity change
Sets the number of buckets in the container (bucket_count) to the most appropriate to contain at least n elements.
То есть стандарт разрешает реализациям выделять больше элементов для мапы, чем мы запросили.
Легитимацию безобразия мы получили, но хотелось бы внятное объяснение причины предоставления такой возможности.
Реализации обычно выбирают bucket_count исходя из соображений быстродействия(как обычно). Тут они выбирают из двух опций:
1️⃣ Выбирают в качестве bucket_count степень двойки, то есть округляют до степени двойки в большую сторону. Это помогает эффективно маппить результат хэш функции на размер самой хэш-таблицы. Можно просто сделать битовое И и отбросить все биты, старше нашей степени. Что делается на один цикл цпу.
Но этот способ имеет негативный эффект в виде того же отбрасывания битов. То есть эти страшие биты никак не влияют на маппинг хэша на бакеты, то уменьшает равномерность распределения.
Таким способом пользуется Visual C++.
2️⃣ Поддерживают bucket_count простым числом.
Это дает крутой эффект того, что старшие биты также влияют на распределение объектов по бакетам. В этом случае даже плохие хэш-функции имеют более равномерное размещение бакетов.
Однако наивная реализация такого подхода заставляет каждый раз делить на рантаймовое значение bucket_count, что может занимать до 100 раз больше циклов.
Более быстрой альтернативой может быть использование захардкоженой таблицы простых чисел. Индекс в ней выбирается на основе запрашиваемого значения bucket_count. Таким образом компилятор может заоптимизировать деление по модулю через битовые операции, сложения, вычитания и умножения. Можете посмотреть на эти оптимизации более подробно на этом примере в годболт.
Этой реализацией пользуется GCC и Clang.
Вот такие страсти происходят у нас под носом под капотом неупорядоченной мапы.
Optimize everything. Stay cool.
#STL #optimization #compiler
{kind=link}
July 19, 2024
Как посмотреть шаблонный тип
#новичкам
Вчера Антон сделал важное замечание, что неплохо бы показать, как самому посмотреть, во что выводится тип Т в каждом конкретном случае. Собсна, погнали.
В С++ стандартными средствами конечно можно это сделать, но решение будет довольно громоздкое и некрасивое с точки зрения пользователя.
Хотелось бы что-то очень простое, желательно вообще однострочное. Обычно таких решений в плюсах нет и надо городить огород, но не в этом случае. Благодаря обширным возможностям препроцессора компиляторы зачастую определяют свои макросы, которые раскрываются в сигнатуру функции. В случае же с шаблонной функцией, они показывают и правильный выведенный шаблонный тип.
Для шланга и гцц этот макрос называется __PRETTY_FUNCTION__, а для msvc - __FUNCSIG__. Пользоваться ими можно примерно так:
Для кланга вывод будет такой:
Для msvc:
Тут на мой взгляд msvc предоставляет несколько более полный и понятный функционал, но кому как удобно.
Можете поиграться в годболте.
See through things. Stay cool.
#compiler #template
#новичкам
Вчера Антон сделал важное замечание, что неплохо бы показать, как самому посмотреть, во что выводится тип Т в каждом конкретном случае. Собсна, погнали.
В С++ стандартными средствами конечно можно это сделать, но решение будет довольно громоздкое и некрасивое с точки зрения пользователя.
Хотелось бы что-то очень простое, желательно вообще однострочное. Обычно таких решений в плюсах нет и надо городить огород, но не в этом случае. Благодаря обширным возможностям препроцессора компиляторы зачастую определяют свои макросы, которые раскрываются в сигнатуру функции. В случае же с шаблонной функцией, они показывают и правильный выведенный шаблонный тип.
Для шланга и гцц этот макрос называется __PRETTY_FUNCTION__, а для msvc - __FUNCSIG__. Пользоваться ими можно примерно так:
#if defined __clang__ || __GNUC__
#define FUNCTION_SIGNATURE __PRETTY_FUNCTION__
#elif defined __FUNCSIG__
#define FUNCTION_SIGNATURE __FUNCSIG__
#endif
template<class T>
void func(const T& param) {
std::cout << FUNCTION_SIGNATURE << std::endl;
}
func(std::vector<int>{});
Для кланга вывод будет такой:
void func(const T &) [T = std::vector<int>]
Для msvc:
void __cdecl func<class std::vector<int,class std::allocator<int> >>(const class std::vector<int,class std::allocator<int> > &)
Тут на мой взгляд msvc предоставляет несколько более полный и понятный функционал, но кому как удобно.
Можете поиграться в годболте.
See through things. Stay cool.
#compiler #template
{kind=link}
July 27, 2024
Что на самом деле представляют собой short circuit операторы?
Мы уже узнали, что операторы && и || для кастомных типов - простые функции. Для функций существует гарантия вычисления всех аргументов перед тем как функция начнет выполняться. Поэтому перегруженные версии этих операторов и не проявляют своих короткосхемных свойств. Однако операторы && и || для тривиальных типов - другое дело и имеют такие свойства. Но почему? Как это так работает в одном случае и не работает в другом? Давайте разбираться.
Во-первых(и в-единственных), операторы для тривиальных типов - это не функции. Они сразу превращаются в определенную последовательность машинных команд. Так как у нас теперь нет ограничения, что мы должны вычислить все аргументы сразу, то и похимичить можно уже знатно.
Если подумать, то логика тут очень похожа на вложенные условия. Если первое выражение правдиво, переходим в вычислению второго, если нет, то выходим из условия(это для &&). И если еще подумать, то у нас и нет никаких других средств это сделать, кроме джампов(условных переходов к метке). Покажу, во что примерно компиляторы С/С++ преобразуют выражение содержащее оператор &&. Не настаиваю на достоверность и точность. Объяснение больше для понимание происходящих процессов.
Вот есть у нас такой код
Он преобразуется примерно вот в такое:
Что здесь происходит. Входим в первое условие и если оно ложное(то есть expr1 - true), то проваливаемся дальше в следующее условие и делаем так, пока наши выражения правдивые. Если они в итоге все оказались правдивыми, то мы входим в блок выполняющий клевую операцию и дальше прыгаем уже наружу первоначального условия и выполняем самую клевую операцию. Если хоть одно из выражений expr оказалось ложным, то мы переходим по метке и выполняем еще круче операцию и естественным образом переходим к выполнению самой крутой операции. Прикол здесь в трех условиях. Так как они абсолютно не связаны друг другом и последовательны, то следующее по счету выражение просто не будет выполняться, пока выполнение не дойдет до него. Таким образом и обеспечиваются последовательные вычисления слева направо.
То есть встроенные операторы && и || разворачиваются вот с такую гармошку условий. Надеюсь, для кого-то открыл глаза, как это работает)
See what's under the hood. Stay cool.
#compiler #cppcore
Мы уже узнали, что операторы && и || для кастомных типов - простые функции. Для функций существует гарантия вычисления всех аргументов перед тем как функция начнет выполняться. Поэтому перегруженные версии этих операторов и не проявляют своих короткосхемных свойств. Однако операторы && и || для тривиальных типов - другое дело и имеют такие свойства. Но почему? Как это так работает в одном случае и не работает в другом? Давайте разбираться.
Во-первых(и в-единственных), операторы для тривиальных типов - это не функции. Они сразу превращаются в определенную последовательность машинных команд. Так как у нас теперь нет ограничения, что мы должны вычислить все аргументы сразу, то и похимичить можно уже знатно.
Если подумать, то логика тут очень похожа на вложенные условия. Если первое выражение правдиво, переходим в вычислению второго, если нет, то выходим из условия(это для &&). И если еще подумать, то у нас и нет никаких других средств это сделать, кроме джампов(условных переходов к метке). Покажу, во что примерно компиляторы С/С++ преобразуют выражение содержащее оператор &&. Не настаиваю на достоверность и точность. Объяснение больше для понимание происходящих процессов.
Вот есть у нас такой код
if (expr1 && expr2 && expr3) {
// cool operation
} else {
// even cooler operation
}
// the coolest operation
Он преобразуется примерно вот в такое:
if (!expr1) goto do_even_cooler_operation;
if (!expr2) goto do_even_cooler_operation;
if (!expr3) goto do_even_cooler_operation;
{
// cool operation
goto do_the_coolest_operation;
}
do_even_cooler_operation:
{
// even cooler operation
}
do_the_coolest_operation:
// the coolest operation
Что здесь происходит. Входим в первое условие и если оно ложное(то есть expr1 - true), то проваливаемся дальше в следующее условие и делаем так, пока наши выражения правдивые. Если они в итоге все оказались правдивыми, то мы входим в блок выполняющий клевую операцию и дальше прыгаем уже наружу первоначального условия и выполняем самую клевую операцию. Если хоть одно из выражений expr оказалось ложным, то мы переходим по метке и выполняем еще круче операцию и естественным образом переходим к выполнению самой крутой операции. Прикол здесь в трех условиях. Так как они абсолютно не связаны друг другом и последовательны, то следующее по счету выражение просто не будет выполняться, пока выполнение не дойдет до него. Таким образом и обеспечиваются последовательные вычисления слева направо.
То есть встроенные операторы && и || разворачиваются вот с такую гармошку условий. Надеюсь, для кого-то открыл глаза, как это работает)
See what's under the hood. Stay cool.
#compiler #cppcore
{kind=link}
September 18, 2024
Целочисленные переполнения
Переполнения интегральных типов - одна из самых частых проблем при написании кода, наряду с выходом за границу массива и попыткой записи по нулевому указателю. Поэтому важно знать, как это происходит и какие гарантии при этом нам дает стандарт.
Для беззнаковых типов тут довольно просто. Переполнение переменных этих типов нельзя в полной мере назвать переполнением, потому что для них все операции происходят по модулю 2^N. При "переполнении" беззнакового числа происходит его уменьшение с помощью деления по модулю числа, которое на 1 больше максимально доступного значения данного типа(то есть 2^N, N - количество доступных разрядов). Но это скорее не математическая операция настоящего деления по модулю, а следствие ограниченного размера ячейки памяти. Чтобы было понятно, сразу приведу пример.
Вот у нас есть число UINT32_MAX. Его бинарное представление - 32 единички. Больше просто не влезет. Дальше мы пробуем прибавить к нему единичку. Чистая и незапятнанная плотью компьютеров математика говорит нам, что в результате должно получится число, которое состоит из единички и 32 нулей. Но у нас в распоряжении всего 32 бита. Поэтому верхушка просто отрезается и остаются только нолики.
Захотим мы допустим пятерку, бинарное представление которой это 101, прибавить к UINT32_MAX. Произойдет опять переполнение. В начале мы берем младший разряд 5-ки и складываем его с UINT32_MAX и уже переполненяемся, получаем ноль. Осталось прибавить 100 в двоичном виде к нолю и получим 4. Как и полагается.
И здесь поведение определенное, известное и стандартное. На него можно положиться.
Но вот что со знаковыми числами?
Стандарт говорит, что переполнение знаковых целых чисел - undefined behaviour. Но почему?
Ну как минимум потому что стандарт отдавал на откуп компиляторам выбор представления отрицательных чисел. Как ранее мы обсуждали, выбирать приходится между тремя представлениями: обратный код, дополнительный код и метод "знак-амплитуда".
Так вот во всех трех сценариях результат переполнения будет разный!
Возьмем для примера дополнительный код и 4-х байтное знаковое число. Ноль выглядит, как
Однако для обратного кода те же рассуждения приводят к тому, что результатом вычислений будет отрицательный ноль!
Ситуация здесь на самом деле немного поменялась с приходом С++20, который сказал нам, что у нас теперь единственный стандартный способ представления отрицательных чисел - дополнительный код. Об этих изменениях расскажу в следующем посте.
Don't let the patience cup overflow. Stay cool.
#cpp20 #compiler #cppcore
Переполнения интегральных типов - одна из самых частых проблем при написании кода, наряду с выходом за границу массива и попыткой записи по нулевому указателю. Поэтому важно знать, как это происходит и какие гарантии при этом нам дает стандарт.
Для беззнаковых типов тут довольно просто. Переполнение переменных этих типов нельзя в полной мере назвать переполнением, потому что для них все операции происходят по модулю 2^N. При "переполнении" беззнакового числа происходит его уменьшение с помощью деления по модулю числа, которое на 1 больше максимально доступного значения данного типа(то есть 2^N, N - количество доступных разрядов). Но это скорее не математическая операция настоящего деления по модулю, а следствие ограниченного размера ячейки памяти. Чтобы было понятно, сразу приведу пример.
Вот у нас есть число UINT32_MAX. Его бинарное представление - 32 единички. Больше просто не влезет. Дальше мы пробуем прибавить к нему единичку. Чистая и незапятнанная плотью компьютеров математика говорит нам, что в результате должно получится число, которое состоит из единички и 32 нулей. Но у нас в распоряжении всего 32 бита. Поэтому верхушка просто отрезается и остаются только нолики.
Захотим мы допустим пятерку, бинарное представление которой это 101, прибавить к UINT32_MAX. Произойдет опять переполнение. В начале мы берем младший разряд 5-ки и складываем его с UINT32_MAX и уже переполненяемся, получаем ноль. Осталось прибавить 100 в двоичном виде к нолю и получим 4. Как и полагается.
И здесь поведение определенное, известное и стандартное. На него можно положиться.
Но вот что со знаковыми числами?
Стандарт говорит, что переполнение знаковых целых чисел - undefined behaviour. Но почему?
Ну как минимум потому что стандарт отдавал на откуп компиляторам выбор представления отрицательных чисел. Как ранее мы обсуждали, выбирать приходится между тремя представлениями: обратный код, дополнительный код и метод "знак-амплитуда".
Так вот во всех трех сценариях результат переполнения будет разный!
Возьмем для примера дополнительный код и 4-х байтное знаковое число. Ноль выглядит, как
000...00, один как 000...01 и тд. Максимальное значение этого типа INT_MAX выглядит так: 0111...11 (2,147,483,647). Но! Когда мы прибавляем к нему единичку, то получаем 100...000, что переворачиваем знаковый бит, число становится отрицательным и равным INT_MIN.Однако для обратного кода те же рассуждения приводят к тому, что результатом вычислений будет отрицательный ноль!
Ситуация здесь на самом деле немного поменялась с приходом С++20, который сказал нам, что у нас теперь единственный стандартный способ представления отрицательных чисел - дополнительный код. Об этих изменениях расскажу в следующем посте.
Don't let the patience cup overflow. Stay cool.
#cpp20 #compiler #cppcore
{kind=link}
October 1, 2024
Проверяем на целочисленное переполнение
По просьбам трудящихся рассказываю, как определить, произошло переполнение или нет.
Почти очевидно, что если переполнение - это неопределенное поведение, то мы не хотим, чтобы оно возникало. Ну или хотя бы хотим, чтобы нам сигнализировали о таком событии и мы что-нибудь с ним сделали.
Какие вообще бывают переполнения по типу операции? Если мы складываем 2 числа, то их результат может не влезать в нужное количество разрядов. Вычитание тоже может привести к переполнению, если оба числа будут сильно негативные(не будьте, как эти числа). Умножение тоже, очевидно, может привести к overflow. А вот деление не может. Целые числа у нас не могут быть по модулю меньше единицы, поэтому деление всегда неувеличивает модуль делимого. Значит и переполнится оно не может.
И какая радость, что популярные компиляторы GCC и Clang уже за нас сделали готовые функции, которые могут проверять на signed integer overflow!
Они возвращают false, если операция проведена штатно, и true, если было переполнение. Типы type1, type2 и type3 должны быть интегральными типами.
Пользоваться функциями очень просто. Допустим мы решаем стандартную задачку по перевороту инта. То есть из 123 нужно получить 321, из 7493 - 3947, и тд. Задачка плевая, но есть загвоздка. Не любое число можно так перевернуть. Модуль максимального инта ограничивается двумя миллиадрами с копейками. Если у входного значения будут заняты все разряды и на конце будет 9, то перевернутое число уже не влезет в инт. Такие события хотелось бы детектировать и возвращать в этом случае фигу.
Use ready-made solutions. Stay cool.
#cppcore #compiler
По просьбам трудящихся рассказываю, как определить, произошло переполнение или нет.
Почти очевидно, что если переполнение - это неопределенное поведение, то мы не хотим, чтобы оно возникало. Ну или хотя бы хотим, чтобы нам сигнализировали о таком событии и мы что-нибудь с ним сделали.
Какие вообще бывают переполнения по типу операции? Если мы складываем 2 числа, то их результат может не влезать в нужное количество разрядов. Вычитание тоже может привести к переполнению, если оба числа будут сильно негативные(не будьте, как эти числа). Умножение тоже, очевидно, может привести к overflow. А вот деление не может. Целые числа у нас не могут быть по модулю меньше единицы, поэтому деление всегда неувеличивает модуль делимого. Значит и переполнится оно не может.
И какая радость, что популярные компиляторы GCC и Clang уже за нас сделали готовые функции, которые могут проверять на signed integer overflow!
bool __builtin_add_overflow(type1 a, type2 b, type3 *res);
bool __builtin_sub_overflow(type1 a, type2 b, type3 *res);
bool __builtin_mul_overflow(type1 a, type2 b, type3 *res);
Они возвращают false, если операция проведена штатно, и true, если было переполнение. Типы type1, type2 и type3 должны быть интегральными типами.
Пользоваться функциями очень просто. Допустим мы решаем стандартную задачку по перевороту инта. То есть из 123 нужно получить 321, из 7493 - 3947, и тд. Задачка плевая, но есть загвоздка. Не любое число можно так перевернуть. Модуль максимального инта ограничивается двумя миллиадрами с копейками. Если у входного значения будут заняты все разряды и на конце будет 9, то перевернутое число уже не влезет в инт. Такие события хотелось бы детектировать и возвращать в этом случае фигу.
std::optional<int32_t> decimal_reverse(int32_t value) {
int32_t result{};
while (value) {
if (__builtin_mul_overflow(result, 10, &result) or
__builtin_add_overflow(result, value % 10, &result))
return std::nullopt;
value /= 10;
}
return result;
}
int main() {
if (decimal_reverse(1234567891).has_value()) {
std::cout << decimal_reverse(1234567891).value() << std::endl;
} else {
std::cout << "Reversing cannot be perform due overflow" << std::endl;
}
if (decimal_reverse(1234567894).has_value()) {
std::cout << decimal_reverse(1234567894).value() << std::endl;
} else {
std::cout << "Reversing cannot be perform due overflow" << std::endl;
}
}
// OUTPUT:
// 1987654321
// Reversing cannot be perform due overflowUse ready-made solutions. Stay cool.
#cppcore #compiler
{kind=link}
October 2, 2024
Как компилятор определяет переполнение
В прошлом посте я рассказал, как можно детектировать signed integer overflow с помощью готовых функций. Сегодня рассмотрим, что ж за магия такая используется для таких заклинаний.
Сразу с места в карьер. То есть в ассемблер.
Есть функция
Посмотрим, во что эта штука компилируется под гцц х86.
Все немного упрощаю, но в целом картина такая:
Подготавливаем регистры, делаем сложение. А далее идет инструкция
Инструкция
1️⃣ Если операция между двумя положительными числами дает отрицательное число.
2️⃣ Если сумма двух отрицательных чисел дает в результате положительное число.
Можно считать, что это два условия для переполнения знаковых чисел. Например
127 + 127 = 0111 1111 + 0111 1111 = 1111 1110 = -2 (в дополнительном коде)
Результат сложения двух положительных чисел - отрицательное число, поэтому при таком сложении выставится регист OF.
Для беззнаковых чисел тоже кстати есть похожий флаг. CF или Carry Flag. Мы говорили, что переполнение для беззнаковых - не совсем переполнение, но процессор нам и о таком событии дает знать через выставление carry флага.
Собственно, вы и сами можете детектировать переполнение подобным образом. Конечно, придется делать асемблерную вставку, но тем не менее.
Но учитывая все условия для overflow, есть более простые способы его задетектить, чисто на арифметике. Но об этом позже.
Detect problems. Stay cool.
#base #cppcore #compiler
В прошлом посте я рассказал, как можно детектировать signed integer overflow с помощью готовых функций. Сегодня рассмотрим, что ж за магия такая используется для таких заклинаний.
Сразу с места в карьер. То есть в ассемблер.
Есть функция
int add(int lhs, int rhs) {
int sum;
if (__builtin_add_overflow(lhs, rhs, &sum))
abort();
return sum;
}Посмотрим, во что эта штука компилируется под гцц х86.
Все немного упрощаю, но в целом картина такая:
mov %edi, %eax
add %esi, %eax
jo call_abort
ret
call_abort:
call abort
Подготавливаем регистры, делаем сложение. А далее идет инструкция
jo. Это условный прыжок. Если условие истино - прыгаем на метку call_abort, если нет - то выходим из функции.Инструкция
jo выполняет прыжок, если выставлен флаг OF в регистре EFLAGS. То есть Overflow Flag. Он выставляется в двух случаях:1️⃣ Если операция между двумя положительными числами дает отрицательное число.
2️⃣ Если сумма двух отрицательных чисел дает в результате положительное число.
Можно считать, что это два условия для переполнения знаковых чисел. Например
127 + 127 = 0111 1111 + 0111 1111 = 1111 1110 = -2 (в дополнительном коде)
Результат сложения двух положительных чисел - отрицательное число, поэтому при таком сложении выставится регист OF.
Для беззнаковых чисел тоже кстати есть похожий флаг. CF или Carry Flag. Мы говорили, что переполнение для беззнаковых - не совсем переполнение, но процессор нам и о таком событии дает знать через выставление carry флага.
Собственно, вы и сами можете детектировать переполнение подобным образом. Конечно, придется делать асемблерную вставку, но тем не менее.
Но учитывая все условия для overflow, есть более простые способы его задетектить, чисто на арифметике. Но об этом позже.
Detect problems. Stay cool.
#base #cppcore #compiler
{kind=link}
October 3, 2024
Signed Integer overflow
Переполнение знаковых целых чисел - всегда было и остается болью в левой булке. Раньше даже стандартом не было определено, каким образом отрицательные числа хранились бы в памяти. Однако с приходом С++20 мы можем смело утверждать, что стандартом разрешено единственное представление отрицательных чисел - дополнительный код или two's complement по-жидоанглосаксонски. Казалось бы, мы теперь знаем наверняка, что будет происходить с битиками при любых видах операций. Так давайте снимем клеймо позора с переполнения знаковых интов. Однако не все так просто оказывается.
С приходом С++20 только переполнение знаковых чисел вследствие преобразования стало определенным по стандарту поведением. Теперь говорится, что, если результирующий тип преобразование - знаковый, то значение переменной никак не изменяется, если исходное число может быть представлено в результирующем типе без потерь.
В обратном случае, если исходное число не может быть представлено в результирующем типе, то результирующим значением будет являться остаток от деления исходного значения по модулю 2^N, где N - количество бит, которое занимает результирующий тип. То есть результат будет получаться просто откидыванием лишних наиболее значащих бит и все!
Однако переполнение знаковых интов вследствие арифметических операций до сих пор является неопределенным поведением!(возмутительно восклицаю). Однако сколько бы возмущений не было, все упирается в конкретные причины. Я подумал вот о каких:
👉🏿 Переносимость. Разные системы работают по разным принципам и UB помогает поддерживать все системы оптимальным образом. Мы могли бы сказать, что пусть переполнение знаковых интов работает также как и переполнение беззнаковых. То есть получалось бы просто совершенно другое неожиданное (ожидаемое с точки зрения стандарта, но неожиданное для нас при запуске программы) значение. Однако некоторые системы просто напросто не продуцируют это "неправильное значение". Например, процессоры MIPS генерируют CPU exception при знаковом переполнении. Для обработки этих исключений и получения стандартного поведения было бы потрачено слишком много ресурсов.
👉🏿 Оптимизации. Неопределенное поведение позволяет компиляторам предположить, что переполнения не произойдет, и оптимизировать код. Действительно, если УБ - так плохо и об этом знают все, то можно предположить, что никто этого не допустит. Тогда компилятор может заняться своим любимым делом - оптимизировать все на свете.
Очень простой пример: когда происходит сравнение a - 10 < b -10, то компилятор может просто убрать вычитание и тогда переполнения не будет и все пойдет, как ожидается.
Так что УБ оставляет некий коридор свободы, благодаря которому могут существовать разные сценарии обработки переполнения: от полного его игнора до включения процессором "сирены", что произошло что-то очень плохое.
Leave room for uncertainty in life. Stay cool.
#cpp20 #compiler #cppcore
Переполнение знаковых целых чисел - всегда было и остается болью в левой булке. Раньше даже стандартом не было определено, каким образом отрицательные числа хранились бы в памяти. Однако с приходом С++20 мы можем смело утверждать, что стандартом разрешено единственное представление отрицательных чисел - дополнительный код или two's complement по-жидоанглосаксонски. Казалось бы, мы теперь знаем наверняка, что будет происходить с битиками при любых видах операций. Так давайте снимем клеймо позора с переполнения знаковых интов. Однако не все так просто оказывается.
С приходом С++20 только переполнение знаковых чисел вследствие преобразования стало определенным по стандарту поведением. Теперь говорится, что, если результирующий тип преобразование - знаковый, то значение переменной никак не изменяется, если исходное число может быть представлено в результирующем типе без потерь.
В обратном случае, если исходное число не может быть представлено в результирующем типе, то результирующим значением будет являться остаток от деления исходного значения по модулю 2^N, где N - количество бит, которое занимает результирующий тип. То есть результат будет получаться просто откидыванием лишних наиболее значащих бит и все!
Однако переполнение знаковых интов вследствие арифметических операций до сих пор является неопределенным поведением!(возмутительно восклицаю). Однако сколько бы возмущений не было, все упирается в конкретные причины. Я подумал вот о каких:
👉🏿 Переносимость. Разные системы работают по разным принципам и UB помогает поддерживать все системы оптимальным образом. Мы могли бы сказать, что пусть переполнение знаковых интов работает также как и переполнение беззнаковых. То есть получалось бы просто совершенно другое неожиданное (ожидаемое с точки зрения стандарта, но неожиданное для нас при запуске программы) значение. Однако некоторые системы просто напросто не продуцируют это "неправильное значение". Например, процессоры MIPS генерируют CPU exception при знаковом переполнении. Для обработки этих исключений и получения стандартного поведения было бы потрачено слишком много ресурсов.
👉🏿 Оптимизации. Неопределенное поведение позволяет компиляторам предположить, что переполнения не произойдет, и оптимизировать код. Действительно, если УБ - так плохо и об этом знают все, то можно предположить, что никто этого не допустит. Тогда компилятор может заняться своим любимым делом - оптимизировать все на свете.
Очень простой пример: когда происходит сравнение a - 10 < b -10, то компилятор может просто убрать вычитание и тогда переполнения не будет и все пойдет, как ожидается.
Так что УБ оставляет некий коридор свободы, благодаря которому могут существовать разные сценарии обработки переполнения: от полного его игнора до включения процессором "сирены", что произошло что-то очень плохое.
Leave room for uncertainty in life. Stay cool.
#cpp20 #compiler #cppcore
{kind=link}
October 4, 2024