
Единица трансляции
В недавнем прошлом на канале было много линковочной тематики. Соответственно это требует частого упоминания термина "единица трансляции" aka translation unit aka юнит. На канале много не нюхавшего прода народа, поэтому пришла в голову идея закрыть этот гештальт.
Вот вы изучаете плюсы. Долго и упорно. И сделали свой первый нетривиальный проект. И бежите радостный показывать его маме со словами: "Мама! Смотри, какую я программу написал.". И показываете ей, как ваши условные крестики-нолики работают. Это вы запустили исполняемый файл, который является результатом превращения вашего кода на с++ в машинный код. Но каким образом все многообразие файлов собирается в одну сущность? Как они между собой взаимодействуют для этого?
В рамках культуры разработки на С++ есть 2 принципиальных вида файлов: headers(заголовочные файлы)(.h|.hpp) и sources(файлы реализации)(.cxx|.cpp). Первые обычно предназначены для помещения в них сущностей, которые будут широко(или потенциально широко) использоваться в проекте. Вторые уже конкретно реализуют поведение этих сущностей. Ответ на вопросы: "Зачем такое разделение в принципе есть?" и "Зачем мы пишем множество файлов реализации?"- заслуживают отдельных постов. Просто примем за данность всем известный факт существования двух видов файлов.
Но на вход компилятора попадает только один тип файлов - sources(не будем касаться precompiled headers и сильно усложнять разговор). На самом деле компилятора может сожрать любой подходящий файл, просто так принято, что это .cpp файлы.
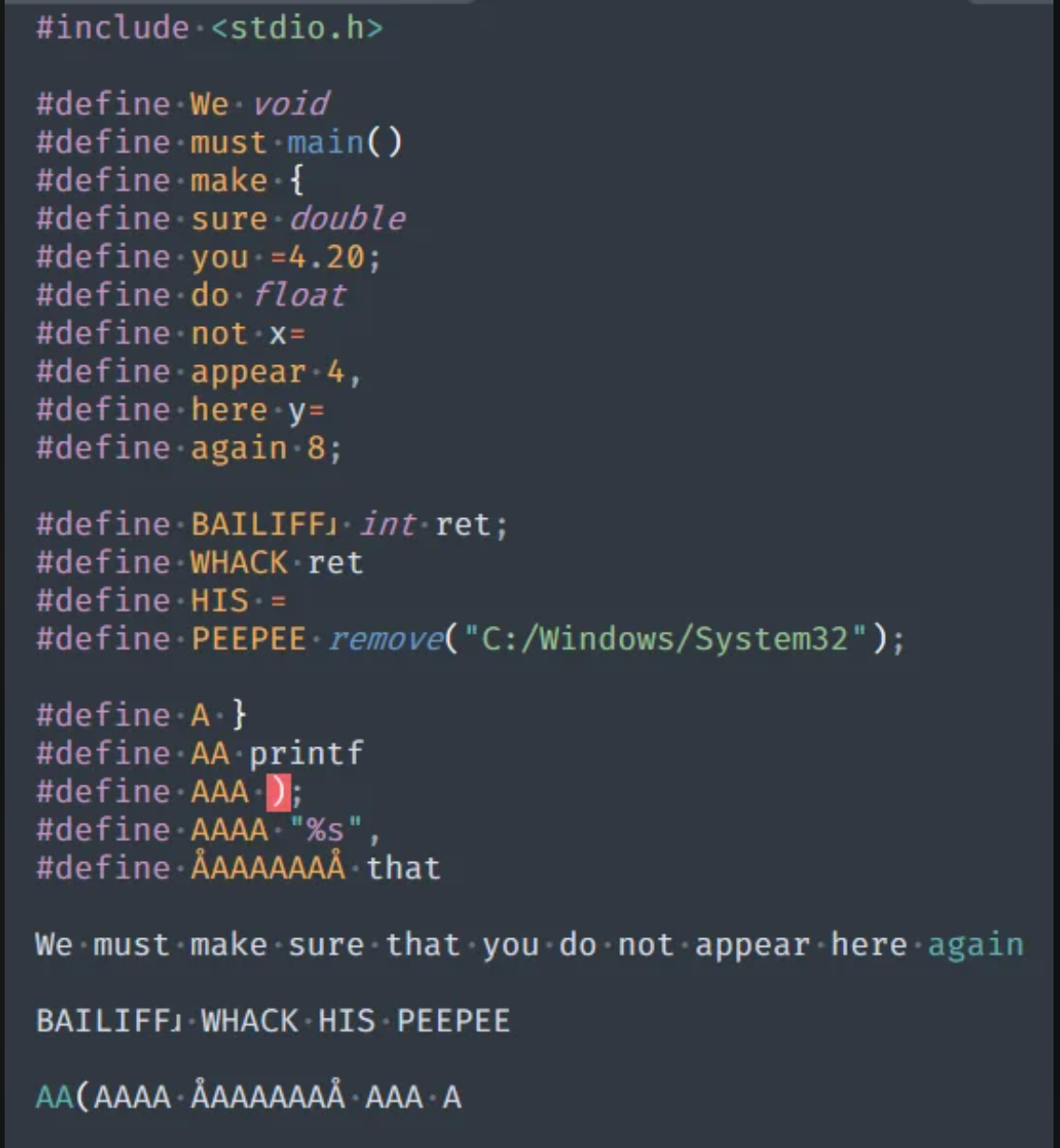
Стандартный source файл состоит из кучи заинклюженых заголовочников, возможно еще несколько видов директив препроцессора, типа #ifdef или #define и прочего, ну и, собственно, нашего кода. Когда такой файл пожирает компилятор, на самом деле первым в работу вступает препроцессор. Это такой предварительный обработчик файлов с кодом. В С и С++ есть несколько директив препроцессора, которые предназначены именно для этого обработчика. Он оперирует в основном текстом программы и фактически делает текстовые манипуляции. Например, директива #include"something.hpp" заменяется на полный текст файла something.hpp. Директива #define MAXARRAYSIZE 10 обозначает, что во всем файле строку MAXARRAYSIZE нужно заменить на 10. Причем 10 это будет прям строка в файле, это надо учитывать. Никакой проверки типов на этом этапе нет.
И вот файл, который получается после обработки исходника препроцессором называется единицей трансляции. То есть это базовый элемент компиляции С++ программы. Компилятор обрабатывает все единицы трансляции, превращая их в объектные файлы. И уже линкер собирает все эти объектные файлы в одну программу.
То есть и вправду не очень корректно говорить, что компилируются цппшники. Это делают все-таки единицы трансляции. Но я не оч понимаю людей, которые хейтят других за это, потому что просто культурой принято файлы реализации называть .cpp. А то, что там есть препроцессор - это и так понятно. Это понимает почти любой, кто писал #include <iostream>, а то есть почти все. Я уж преувеличиваю, но вы поняли мою мысль.
Divide et impera. Stay cool.
#compiler #cppcore
В недавнем прошлом на канале было много линковочной тематики. Соответственно это требует частого упоминания термина "единица трансляции" aka translation unit aka юнит. На канале много не нюхавшего прода народа, поэтому пришла в голову идея закрыть этот гештальт.
Вот вы изучаете плюсы. Долго и упорно. И сделали свой первый нетривиальный проект. И бежите радостный показывать его маме со словами: "Мама! Смотри, какую я программу написал.". И показываете ей, как ваши условные крестики-нолики работают. Это вы запустили исполняемый файл, который является результатом превращения вашего кода на с++ в машинный код. Но каким образом все многообразие файлов собирается в одну сущность? Как они между собой взаимодействуют для этого?
В рамках культуры разработки на С++ есть 2 принципиальных вида файлов: headers(заголовочные файлы)(.h|.hpp) и sources(файлы реализации)(.cxx|.cpp). Первые обычно предназначены для помещения в них сущностей, которые будут широко(или потенциально широко) использоваться в проекте. Вторые уже конкретно реализуют поведение этих сущностей. Ответ на вопросы: "Зачем такое разделение в принципе есть?" и "Зачем мы пишем множество файлов реализации?"- заслуживают отдельных постов. Просто примем за данность всем известный факт существования двух видов файлов.
Но на вход компилятора попадает только один тип файлов - sources(не будем касаться precompiled headers и сильно усложнять разговор). На самом деле компилятора может сожрать любой подходящий файл, просто так принято, что это .cpp файлы.
Стандартный source файл состоит из кучи заинклюженых заголовочников, возможно еще несколько видов директив препроцессора, типа #ifdef или #define и прочего, ну и, собственно, нашего кода. Когда такой файл пожирает компилятор, на самом деле первым в работу вступает препроцессор. Это такой предварительный обработчик файлов с кодом. В С и С++ есть несколько директив препроцессора, которые предназначены именно для этого обработчика. Он оперирует в основном текстом программы и фактически делает текстовые манипуляции. Например, директива #include"something.hpp" заменяется на полный текст файла something.hpp. Директива #define MAXARRAYSIZE 10 обозначает, что во всем файле строку MAXARRAYSIZE нужно заменить на 10. Причем 10 это будет прям строка в файле, это надо учитывать. Никакой проверки типов на этом этапе нет.
И вот файл, который получается после обработки исходника препроцессором называется единицей трансляции. То есть это базовый элемент компиляции С++ программы. Компилятор обрабатывает все единицы трансляции, превращая их в объектные файлы. И уже линкер собирает все эти объектные файлы в одну программу.
То есть и вправду не очень корректно говорить, что компилируются цппшники. Это делают все-таки единицы трансляции. Но я не оч понимаю людей, которые хейтят других за это, потому что просто культурой принято файлы реализации называть .cpp. А то, что там есть препроцессор - это и так понятно. Это понимает почти любой, кто писал #include <iostream>, а то есть почти все. Я уж преувеличиваю, но вы поняли мою мысль.
Divide et impera. Stay cool.
#compiler #cppcore
{kind=link}
static_cast
В предыдущих статьях мы несколько раз упоминали оператор
Исходя из своих наблюдений, наиболее востребованным оператором приведения является
Оператор
Конечно, некоторые смысловые ошибки нельзя поймать, ведь с точки зрения типа, все хорошо. Например, приведение значения к
Правила приведения для фундаментальных (встроенных) типов в C++ определены заранее, а вот для пользовательских классов можно определить свои собственные преобразования с помощью оператора приведения к типу:
Эта ручка будет дергаться при явном и неявном приведении типов в живом примере 1:
Если такое предупреждение появляется, то вероятно, что что-то вы все таки упускаете в своем коде. Но иногда такие ситуации встречаются, когда полезная нагрузка от вашего действия есть, а предупреждение не к месту. Например, в следствие какой-нибудь препроцессорной директивы. Напоминаем, что в C++17 так же есть атрибут
Так же
Разберем эту тему подробнее, когда дойдем до динамического полиморфизма
В предыдущих статьях мы несколько раз упоминали оператор
static_cast, поэтому мы решили затронуть еще и тему приведения типов. По мере развития серии, рассмотрим каждый из них, а завершим разбором C-style cast.Исходя из своих наблюдений, наиболее востребованным оператором приведения является
static_cast, т.к. в основном большинство приходится на преобразование между совместимыми друг с другом типами:int32_t value_i32 = 42;
int64_t value_i64 = static_cast<int64_t>(value_i32);
float value_f32 = 42.314;
int16_t value_i16 = static_cast<int16_t>(value_f32);
Оператор
static_cast так же проверяет корректность выполняемого приведения. Например, запрещает приведение указателя к значению:// error: invalid 'static_cast' from type 'int*' to type 'int'
static_cast<int>(&value);
Конечно, некоторые смысловые ошибки нельзя поймать, ведь с точки зрения типа, все хорошо. Например, приведение значения к
enum class может привести к непредвиденным сценариям 🤭:enum class action_e : int { RUN = 0, FIGHT = 1 };
// Should I run or fight?
action_e action = static_cast<action_e>(2);
Лучше бы их все таки дополнять еще debug-only assert или вообще условным ветвлением.Правила приведения для фундаментальных (встроенных) типов в C++ определены заранее, а вот для пользовательских классов можно определить свои собственные преобразования с помощью оператора приведения к типу:
operator Type():class specific_error_t
{
...
// Оператор приведение к типу `bool`
operator bool() const
{
return m_code < 0;
}
...
};
Эта ручка будет дергаться при явном и неявном приведении типов в живом примере 1:
specific_error_t internal_code = -1;Один из неочевидных способов применения этого оператора является приведение к типу
// Приведение `internal_code` к типу `bool`
bool has_internal_code = static_cast<bool>(internal_code);
void. Казалось бы, зачем? Но это помогает подавить предупреждение компилятора о неиспользуемой переменной / не присвоенном значении:void foo()
{
int result = read_and_do_something();
#ifdef DEBUG
// Debug build check only
assert(result == 0);
#endif
static_cast<void>(result);
}
Если такое предупреждение появляется, то вероятно, что что-то вы все таки упускаете в своем коде. Но иногда такие ситуации встречаются, когда полезная нагрузка от вашего действия есть, а предупреждение не к месту. Например, в следствие какой-нибудь препроцессорной директивы. Напоминаем, что в C++17 так же есть атрибут
[[maybe_unused]], который решает эту проблему.Так же
static_cast позволяет выполнить приведение к типу родительского класса (upcasting) и к типу наследников (downcasting) в рамках одной иерархии классов:Child *pointer = new Child();Важным моментом является тот факт, что
// Upcasting
Base *base_ptr = static_cast<Base*>(pointer);
// Downcasting
Child *child_ptr = static_cast<Child*>(base_ptr);
static_cast не может обеспечить проверку корректности совершенного преобразования к наследнику (downcasting)! Если наследник выбран неправильно и вы допустили ошибку преобразования к другому типу, то вам все равно дадут скомпилироваться: живой пример 2. У компилятора действительно не хватает информации, чтобы это проверить на этапе компиляции. Разберем эту тему подробнее, когда дойдем до динамического полиморфизма
{kind=link}
Директивы ifdef, ifndef, if
#новичкам
Иногда код, который мы пишем, должен зависеть от каких-то внешних параметров. Например, неплохо было бы довалять дебажный вывод при дебажной сборке. Или нам нужно написать кусочек платформоспецифичного кода и конкретная платформа передается нам наружными параметрами. Разные в общем бывают ситуации. Получается нам нужен какой-то механизм, который может проверять эти внешние параметры и в зависимости от их значений включать или выключать нужный кусок кода. Эту задачу можно решать по-разному. Сегодня мы обсудим доисторический способ, который, несмотря на свой почтенный возраст и опасность применения, активно используется в существующих проектах.
Этот способ - использование директив препроцессора #ifdef, #ifndef, #if. Все три - условные конструкции. Первая смотрит, определен ли в коде какой-то макрос. Если да, то делаем одни действия, если нет - другие. Второй наоборот, входит в первую ветку условия, если макрос не определен, и входит во вторую, если определен. Директива #if проверяет какое-то условие, ничего необычного. Все три директивы могут иметь как полные формы(с веткой в случае если условие ложно), так и неполные(без "else").
И вот в чем их прикол. Препроцессор работает с текстом программы. И он просто удаляет из этого текста ненужную ветку так, что до компиляции она даже не доходит, а нужная ветка как раз и подвергается обработке компилятором.
Например, у нас есть какой-то платформоспецифичный участок кода. Пусть это будет низкоуровневая оптимизация скалярного произведения на векторных инструкциях. Они разные для интеловских процессоров и для армов. Код может выглядеть примерно так:
Если каждое значение CPU_TYPE включает нужную ветку кода и убирает из текста программы все остальные.
Если мы хотим оптимизировать только под интеловские процессоры, то можем написать чуть проще:
(Все примеры - учебные, все совпадения с реальным кодом - случайны, не повторяйте код в домашних условиях). Здесь мы проверяем директивой ifdef, определен ли макрос OPTIMIZATION_ON, сигнализирующий что нужно использовать векторные инструкции. Если да, то ключаем в текст программы оптимизированный код. Если нет - обычный.
Можно еще кучу примеров и приложений этим директивам привести. Но я хотел подчеркнуть именно вот эту особенность, что мы можем добавлять или выбрасывать определенные участки кода в зависимости от внешних параметров.
Широко известно, что такой способ не только устарел, но еще и опасен. Завтра посмотрим, чем конкретно.
Choose the right path. Stay cool.
#compiler
#новичкам
Иногда код, который мы пишем, должен зависеть от каких-то внешних параметров. Например, неплохо было бы довалять дебажный вывод при дебажной сборке. Или нам нужно написать кусочек платформоспецифичного кода и конкретная платформа передается нам наружными параметрами. Разные в общем бывают ситуации. Получается нам нужен какой-то механизм, который может проверять эти внешние параметры и в зависимости от их значений включать или выключать нужный кусок кода. Эту задачу можно решать по-разному. Сегодня мы обсудим доисторический способ, который, несмотря на свой почтенный возраст и опасность применения, активно используется в существующих проектах.
Этот способ - использование директив препроцессора #ifdef, #ifndef, #if. Все три - условные конструкции. Первая смотрит, определен ли в коде какой-то макрос. Если да, то делаем одни действия, если нет - другие. Второй наоборот, входит в первую ветку условия, если макрос не определен, и входит во вторую, если определен. Директива #if проверяет какое-то условие, ничего необычного. Все три директивы могут иметь как полные формы(с веткой в случае если условие ложно), так и неполные(без "else").
И вот в чем их прикол. Препроцессор работает с текстом программы. И он просто удаляет из этого текста ненужную ветку так, что до компиляции она даже не доходит, а нужная ветка как раз и подвергается обработке компилятором.
Например, у нас есть какой-то платформоспецифичный участок кода. Пусть это будет низкоуровневая оптимизация скалярного произведения на векторных инструкциях. Они разные для интеловских процессоров и для армов. Код может выглядеть примерно так:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#if CPU_TYPE == 0
// mmx|sse|avx code
#elif CPU_TYPE == 1
// arm neon code
#else
static_assert(0, "NO CPU_TYPE IS SPECIFIED");
#endif
return result;
}
Если каждое значение CPU_TYPE включает нужную ветку кода и убирает из текста программы все остальные.
Если мы хотим оптимизировать только под интеловские процессоры, то можем написать чуть проще:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#ifdef OPTIMIZATION_ON
// mmx|sse|avx code
#else
for (int i = 0; i < vec1.size(); ++i)
result += vec1[i] * vec2[i];
#endif
return result;
}
(Все примеры - учебные, все совпадения с реальным кодом - случайны, не повторяйте код в домашних условиях). Здесь мы проверяем директивой ifdef, определен ли макрос OPTIMIZATION_ON, сигнализирующий что нужно использовать векторные инструкции. Если да, то ключаем в текст программы оптимизированный код. Если нет - обычный.
Можно еще кучу примеров и приложений этим директивам привести. Но я хотел подчеркнуть именно вот эту особенность, что мы можем добавлять или выбрасывать определенные участки кода в зависимости от внешних параметров.
Широко известно, что такой способ не только устарел, но еще и опасен. Завтра посмотрим, чем конкретно.
Choose the right path. Stay cool.
#compiler
{kind=link}