
Мотивация оптимизации пересекающихся областей памяти
В предыдущей статье было рассказано о правиле
Давайте «поиграем в компилятор» и попробуем понять логику оптимизации этой функции:
Итак, можем ли мы оптимизировать данный код?
С одной стороны, мы можем предположить, что раз мы задали
Давайте попробует измерить с помощью игрушечного бенчмарка, будет ли это как-то влиять? Опустим момент, почему я его запустил с опцией
С другой стороны, если
Вышеописанная ситуация может показаться неоднозначной. В большинстве случаев, скорее всего, она будет легальна, но для каких-то совершенно недопустима. В случае, если бы вы разрабатывали свою программу, то вы бы могли решить этот вопрос просто посмотрев, где и как используется такая функция.
Но вообще говоря, это касается не только вырванных из контекста функций с их аргументами, а любых указателей и ссылок на пересекающуюся память. Можно ли подставлять значения в последующих выражениях без перечитывания памяти?
Для вашего компилятора это одновременно и возможность офигенно ускорить исполнение программ, и головная боль: как понять, происходит наложение памяти (aliasing) и оптимизироваться нельзя?
Попробуем рассуждать дальше. Условно, этапе компиляции можно попробовать отследить какие адреса должны быть в указателях. Но вопрос особенно остро встаёт, когда мы компилируем какую-то функцию для динамической библиотеки. По сути, перед нами только сама функция и всё! Контекста вызова этой функции нет. У компилятора не так много информации, которую он может использовать, поэтому в качестве критерия выступает тип ссылки/указателя. Вероятно, что представление пересекающейся памяти совершенно разными типами - это все таки очень редкий случай в рамках одного приложения.
Комитет стандартизации C/С++ предпочел регламентировать правила, по которым можно не ограничивать программистов и предоставить лучшую производительность. Компромиссный вариант.
Компилятор не может применить оптимизацию, если соблюдается правило strict aliasing. Во всех остальных случаях компилятор по умолчанию считает любые указатели/ссылки непересекающимися областями памяти и будет их оптимизировать, если не удается явно детектировать его нарушение... Это можно сделать, преимущественно в рамках тела одной функции, когда есть полный контекст взаимодействия с указателем. В этом случае будут сгенерированы инструкции, аналогичные корректному коду: живой пример. Вероятно, именно поэтому с такой проблемой разработчики сталкиваются реже, чем могли бы.
Но вот можно ли рассчитывать на то, что в другой версии компилятора это будет работать точно так же? Раз не стандартизировано и это UB, значит нет. В общем случае, такой код становится непереносимым.
#compiler
В предыдущей статье было рассказано о правиле
strict aliasing. Предлагаю сегодня немного порассуждать, почему оптимизация имеет место быть?Давайте «поиграем в компилятор» и попробуем понять логику оптимизации этой функции:
auto set_default(int &ival, float &dval)
{
ival = 0;
dval = 2.0;
return std::pair(ival, dval);
}
Итак, можем ли мы оптимизировать данный код?
С одной стороны, мы можем предположить, что раз мы задали
ival и dval конкретные константы и больше никаких операций с этими ссылками не делали, то мы можем заранее вычислить объект std::pair(ival, dval) вот так:auto set_default(int &ival, float &dval)
{
ival = 0;
dval = 2.0;
// Вычислим в compile time
constexpr auto result = std::pair(0, 2.0);
return result;
}
Давайте попробует измерить с помощью игрушечного бенчмарка, будет ли это как-то влиять? Опустим момент, почему я его запустил с опцией
-O0, но мы видим прирост на ~30%. Получается, что наша ручная оптимизация имеет значение. И это лишь одна оптимизация, которая может комбинироваться с другими.С другой стороны, если
ival и dval ссылаются на пересекающиеся области памяти, то мы явно понимаем, что наша функция должна возвращать совершенно другие значения. Вот вам живой пример для наглядности.Вышеописанная ситуация может показаться неоднозначной. В большинстве случаев, скорее всего, она будет легальна, но для каких-то совершенно недопустима. В случае, если бы вы разрабатывали свою программу, то вы бы могли решить этот вопрос просто посмотрев, где и как используется такая функция.
Но вообще говоря, это касается не только вырванных из контекста функций с их аргументами, а любых указателей и ссылок на пересекающуюся память. Можно ли подставлять значения в последующих выражениях без перечитывания памяти?
Для вашего компилятора это одновременно и возможность офигенно ускорить исполнение программ, и головная боль: как понять, происходит наложение памяти (aliasing) и оптимизироваться нельзя?
Попробуем рассуждать дальше. Условно, этапе компиляции можно попробовать отследить какие адреса должны быть в указателях. Но вопрос особенно остро встаёт, когда мы компилируем какую-то функцию для динамической библиотеки. По сути, перед нами только сама функция и всё! Контекста вызова этой функции нет. У компилятора не так много информации, которую он может использовать, поэтому в качестве критерия выступает тип ссылки/указателя. Вероятно, что представление пересекающейся памяти совершенно разными типами - это все таки очень редкий случай в рамках одного приложения.
Комитет стандартизации C/С++ предпочел регламентировать правила, по которым можно не ограничивать программистов и предоставить лучшую производительность. Компромиссный вариант.
Компилятор не может применить оптимизацию, если соблюдается правило strict aliasing. Во всех остальных случаях компилятор по умолчанию считает любые указатели/ссылки непересекающимися областями памяти и будет их оптимизировать, если не удается явно детектировать его нарушение... Это можно сделать, преимущественно в рамках тела одной функции, когда есть полный контекст взаимодействия с указателем. В этом случае будут сгенерированы инструкции, аналогичные корректному коду: живой пример. Вероятно, именно поэтому с такой проблемой разработчики сталкиваются реже, чем могли бы.
Но вот можно ли рассчитывать на то, что в другой версии компилятора это будет работать точно так же? Раз не стандартизировано и это UB, значит нет. В общем случае, такой код становится непереносимым.
#compiler
Константная инициализация. Ч1
Это первый шаг, который пытается выполнить компилятор, когда пробует инициализировать переменную. Для него требуется, чтобы инициализатор был константным выражением. То есть его можно было бы вычислить во время компиляции. И не путать с обычным const! Позже покажу почему.
Также гарантируется, что эта инициализация происходит до любой другой инициализации статиков. На практике же компиляторы вообще сразу в бинарь помещают предвычисленное значение объекта и во время выполнения с ним уже ничего не нужно делать. Пример:
С переменной
Точнее немного не так. Она будет проиниализирована последней, но аж 2 раза! Первый раз - zero-инициализацией на этапе компиляции, второй раз - динамической в рантайме.
Чтобы не пустословить по чем зря, покажу вырезки из ассембера, которые подкрепляют мои слова. Вот чего нашел:
Дальше мы переходим к data секции, в которой подряд инициализируются
И в последнюю очередь, уже в рантайме, динамически ини
Это рантаймовая рутина, которая запускается перед вызовом main() и инициализирует
Тут можно довольно простую аналогию провести. Константная инициализаци выполняется для тех объектов, которые можно пометить constexpr, и, не учитывая весь остальной код, компиляция после этого успешно завершится.
Define order of your life. Stay cool.
#cppcore #compiler
Это первый шаг, который пытается выполнить компилятор, когда пробует инициализировать переменную. Для него требуется, чтобы инициализатор был константным выражением. То есть его можно было бы вычислить во время компиляции. И не путать с обычным const! Позже покажу почему.
Также гарантируется, что эта инициализация происходит до любой другой инициализации статиков. На практике же компиляторы вообще сразу в бинарь помещают предвычисленное значение объекта и во время выполнения с ним уже ничего не нужно делать. Пример:
constexpr double constexpr_var{1.0};
double const_intialized_var1{constexpr_var};
const double const_var{const_intialized_var1};
double const_intialized_var2{3.0};
С переменной
constexpr_var все хорошо, константа присваивается константному выражению и инициализируется эта переменная первой. Далее устанавливается значение для const_intialized_var1. Несмотря на то, что эта переменная не константа, ее инициализатор - константное выражение, а этого достаточно для выполнения константной инициализации. Интересно, что дальше устанавливается значение переменной const_intialized_var2, а не const_var. Хоть const_var и константа, ее инициализатор не является константным выражением! Все потому, что у переменной const_intialized_var1 нет пометки const(constexpr), а значит, хоть она и проинициализирована константой, сама таковой не является. И const_var будет инициализироваться последней уже в рантайме.Точнее немного не так. Она будет проиниализирована последней, но аж 2 раза! Первый раз - zero-инициализацией на этапе компиляции, второй раз - динамической в рантайме.
Чтобы не пустословить по чем зря, покажу вырезки из ассембера, которые подкрепляют мои слова. Вот чего нашел:
.section __DATA,__data
.globl _const_intialized_var1 ## @const_intialized_var1
.p2align 3, 0x0
_const_intialized_var1:
.quad 0x3ff0000000000000 ## double 1
.globl _const_intialized_var2 ## @const_intialized_var2
.p2align 3, 0x0
_const_intialized_var2:
.quad 0x4008000000000000 ## double 3
.section __TEXT,__const
.p2align 3, 0x0 ## @_ZL13constexpr_var
__ZL13constexpr_var:
.quad 0x3ff0000000000000 ## double 1
.zerofill __DATA,__bss,__ZL9const_var,8,3 ## @_ZL9const_var
.section __DATA,__mod_init_func,mod_init_funcs
.p2align 3, 0x0
.quad __GLOBAL__sub_I_main.cpp
constexpr_var инициализируется в текстовой секции. Не смотрите, что эта секция расположена в середине, стандарт гарантирует, что ее инициализация произойдет первой(в ином случае const_intialized_var1 досталась бы фига).Дальше мы переходим к data секции, в которой подряд инициализируются
const_intialized_var1 и _const_intialized_var2. И после всего этого в секции .zerofill у нас заполняется нулями const_var.И в последнюю очередь, уже в рантайме, динамически ини
циализируется const_var.
.section __TEXT,__StaticInit,regular,pure_instructions
.p2align 4, 0x90 ## -- Begin function __cxx_global_var_init
___cxx_global_var_init: ## @__cxx_global_var_init
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movsd _const_intialized_var1(%rip), %xmm0 ## xmm0 = mem[0],zero
movsd %xmm0, __ZL9const_var(%rip)
popq %rbp
retq
.cfi_endproc
Это рантаймовая рутина, которая запускается перед вызовом main() и инициализирует
const_var.Тут можно довольно простую аналогию провести. Константная инициализаци выполняется для тех объектов, которые можно пометить constexpr, и, не учитывая весь остальной код, компиляция после этого успешно завершится.
Define order of your life. Stay cool.
#cppcore #compiler
{kind=link}
Константная инициализация. Ч2
То, каким образом в деталях работает константная иницализация, довольно сложно понять, просто читая стандарт и другие официальные источники. И вот почему.
Вот такой пример они дают:
И говорится, что
Но видимо при проведении константной инициализации компилятор только один раз проходит сверху вниз программы. По факту,
Еще более интересные вещи происходят в ассемблер
Это внутреннее представление этих глобальных переменных. static_class_var прям глобальная, ее могу видеть и другие единицы трансляции. Поэтому она с пометкой .globl. const_var же статическая переменная, а значит ее видно видно только из текущей единицы трансляции.
Проблема в том, что
Дело в том, что здесь замешано одно интересное право компилятора. Ему в определенных случаях разрешено устанавливать начальные значения переменным в compile-time, если он уверен, что их значения не изменится на момент начала старта программы.
Этот пример и пример из прошлого поста кстати показывают, что инициализация глобальных переменных идет не совсем сверху вниз. Для каждого этап инициализации это более менее верно, но под каждый этап попадают разные подмножества переменных. Поэтому могут возникать сайд-эффекты, подобные тем, что были в этом посте.
Accept side affects. Stay cool.
#cpcore #compiler
То, каким образом в деталях работает константная иницализация, довольно сложно понять, просто читая стандарт и другие официальные источники. И вот почему.
Вот такой пример они дают:
struct S
{
static const int static_class_var;
};
static const int const_var = 10 * S::static_class_var;
const int S::static_class_var = 5;
int main()
{
std::cout << &const_var << std::endl; // ODR-use for explicit generation of symbol
std::array<int, S::static_class_var> a1; // OK
// std::array<int, const_var> a2; // ERROR
}
И говорится, что
static_class_var на момент создания const_var не имеет инициализатора. А так как компилятор в первую очередь выполняет константную инициализацию, поэтому он не может сейчас установить значение для const_var. Поэтому в начале инициализируется static_class_var. И вот уже дальше - const_var.Но видимо при проведении константной инициализации компилятор только один раз проходит сверху вниз программы. По факту,
static_class_var - константа, инициализированная константным выражением. И по всем канонам должна сама стать константным выражением. Так и получается, ведь мы можем создать std::array из нее. Но вот из const_var - не можем. Хотя эта переменная тоже проинициализирована константным выражением. Но так, как ее инициализация происходит после константной инициализации, то этот факт не дает ей шанса стать нормальным constant expression.Еще более интересные вещи происходят в ассемблер
е.
.section __TEXT,__const
.globl __ZN1S16static_class_varE ## @_ZN1S16static_class_varE
.p2align 2, 0x0
__ZN1S16static_class_varE:
.long 5 ## 0x5
.p2align 2, 0x0 ## @_ZL9const_var
__ZL9const_var:
.long 50 ## 0x32
Это внутреннее представление этих глобальных переменных. static_class_var прям глобальная, ее могу видеть и другие единицы трансляции. Поэтому она с пометкой .globl. const_var же статическая переменная, а значит ее видно видно только из текущей единицы трансляции.
Проблема в том, что
const_var выглядит такой же compile-time константой, как и static_class_var. Хотя по идее тут должна быть какая-нибудь zero-инициализация + динамическая в рантайме. Но array мы не можем создать с const_var🗿.Дело в том, что здесь замешано одно интересное право компилятора. Ему в определенных случаях разрешено устанавливать начальные значения переменным в compile-time, если он уверен, что их значения не изменится на момент начала старта программы.
Этот пример и пример из прошлого поста кстати показывают, что инициализация глобальных переменных идет не совсем сверху вниз. Для каждого этап инициализации это более менее верно, но под каждый этап попадают разные подмножества переменных. Поэтому могут возникать сайд-эффекты, подобные тем, что были в этом посте.
Accept side affects. Stay cool.
#cpcore #compiler
{kind=link}
Вот когда точно статики инициализируются после main
Все-таки есть стопроцентный способ создать условия, чтобы этот эффект проявился.
Как вы знаете, есть 2 вида библиотек: статические и динамические. Код статических библиотек вставляется в основной код программы в то время, как код динамических библиотек подгружается в рантайме.
Так вот есть способы в любой момент исполнения программы руками подгрузить shared library и использовать ее символы, даже ничего не зная о ней на этапе линковки объектников!
На юниксах это системный вызов dlopen. Он принимает путь к библиотеки и возвращает ее хэндл. Через этот хэндл можно получать указатели на сущности из либы.
Естественно, что раз бинарник ничего не знал о сущностях библиотеки до ее explicit подгрузки, а библиотека просто лежала камнем в файловой системе, то буквально никакой код библиотеки не может быть выполнен до ее подгрузки. А значит, если мы открываем либу в main(), то только в этот момент начинается вся динамическая инициализация сущностей либы. Поэтому значение ее переменных со static storage duration устанавливается после входа в main()!
Минимальный пример:
Вывод:
Чтобы запустить это дело(на примере gcc), нужно:
1️⃣ Скомпилировать объектный файл из source.cpp g++ -c -fpic -std=c++17 source.cpp
2️⃣ Превратить его в библиотеку g++ -shared -o libsource.so source.o
3️⃣ Скомпилировать main.cpp g++ -o test main.cpp -std=c++17
4️⃣ Запустить ./test
Важно отметить, что о существовании библиотеки исполняемый файл test вообще не в курсе. Также не нужно добавлять путь до либы в какой-нибудь $LD_LIBRARY_PATH.
Если библиотеку сликовать с бинарем сразу же и подгружать ее неявно, то порядок инициализации будет снова неопределен в соотвествии с предыдущим постом. И скорее всего такого эффекта в этом случае не будет.
Вот такие интересности существуют в мире инициализации статиков. Пост не несет какого-то особого смысла, разве что познакомить некоторых читателей с таким вот явным способом загрузки динамических либ в код.
Dig deeper. Stay cool.
#compiler
Все-таки есть стопроцентный способ создать условия, чтобы этот эффект проявился.
Как вы знаете, есть 2 вида библиотек: статические и динамические. Код статических библиотек вставляется в основной код программы в то время, как код динамических библиотек подгружается в рантайме.
Так вот есть способы в любой момент исполнения программы руками подгрузить shared library и использовать ее символы, даже ничего не зная о ней на этапе линковки объектников!
На юниксах это системный вызов dlopen. Он принимает путь к библиотеки и возвращает ее хэндл. Через этот хэндл можно получать указатели на сущности из либы.
Естественно, что раз бинарник ничего не знал о сущностях библиотеки до ее explicit подгрузки, а библиотека просто лежала камнем в файловой системе, то буквально никакой код библиотеки не может быть выполнен до ее подгрузки. А значит, если мы открываем либу в main(), то только в этот момент начинается вся динамическая инициализация сущностей либы. Поэтому значение ее переменных со static storage duration устанавливается после входа в main()!
Минимальный пример:
// lib.cpp
struct CreationMomentShower {
CreationMomentShower(int num=0) : data{num} {
std::cout << "Created object with data " << num << std::endl;
}
int data;
};
struct Use {
static inline CreationMomentShower help{6};
};
// main.cpp
#include <iostream>
#include <dlfcn.h>
int main()
{
std::cout << "Main has already started" << std::endl;
void* libraryHandle = dlopen("libsource.so", RTLD_NOW);
if (libraryHandle == nullptr) {
std::cerr << dlerror() << std::endl;
return 1;
}
dlclose(libraryHandle);
}
Вывод:
Main has already started
Created object with data 6
Чтобы запустить это дело(на примере gcc), нужно:
1️⃣ Скомпилировать объектный файл из source.cpp g++ -c -fpic -std=c++17 source.cpp
2️⃣ Превратить его в библиотеку g++ -shared -o libsource.so source.o
3️⃣ Скомпилировать main.cpp g++ -o test main.cpp -std=c++17
4️⃣ Запустить ./test
Важно отметить, что о существовании библиотеки исполняемый файл test вообще не в курсе. Также не нужно добавлять путь до либы в какой-нибудь $LD_LIBRARY_PATH.
Если библиотеку сликовать с бинарем сразу же и подгружать ее неявно, то порядок инициализации будет снова неопределен в соотвествии с предыдущим постом. И скорее всего такого эффекта в этом случае не будет.
Вот такие интересности существуют в мире инициализации статиков. Пост не несет какого-то особого смысла, разве что познакомить некоторых читателей с таким вот явным способом загрузки динамических либ в код.
Dig deeper. Stay cool.
#compiler
Double-Checked Locking Pattern Classic
#опытным
Ядро идеи этого паттерна - тот факт, что решение из предыдущего поста неоптимально. Нам на самом деле нужно всего один раз взять замок для того, чтобы создать объект и потом не возвращаться к этом шагу. Если кто-то увидит, что наш указатель - ненулевой, то он даже не будет пытаться что-то делать и сразу вернется из функции.
Поэтому в паттерне блокировки с двойной проверкой, нулёвость указателя проверяется перед локом. Таким образом мы откидываем просадку производительности для подавляющего большинства вызова геттера синглтона. Однако у нас теперь остается узкое место - момент инициализации. И вот где появляется вторая проверка(всю обертку уже не буду писать для краткости).
Таким образом, даже если 2 потока войдут в первое условие и первый из них проинициализирует указатель, то второй поток будет вынужден проверить еще раз, можно ли ему создать объект. И грустный вернется из геттера, потому что ему нельзя.
Это классическая реализация, многие подписчики, думаю, видели ее. Однако от того, что она классическая, не следует, что она корректная.
Давайте посмотрим на вот эту строчку поближе:
Что здесь происходит? На самом деле происходят 3 шага:
1️⃣ Аллокация памяти под объект.
2️⃣ Вызов его конструктора на аллоцированной памяти.
3️⃣ Присваивание inst_ptr'у нового значения.
И вот мы, как наивные чукотские мальчики, думаем, что все эти 3 шага происходят в этом конкретном порядке. А вот фигушки! Компилятор, мать его ети. Иногда он может просто взять и переставить шаги 2 и 3 местами! И вот к чему это может привести.
Давайте посмотрим эквивалентный плюсовый код, когда компилятор переставил шаги:
Че здесь происходит. Здесь просто явно показаны шаги. С помощью operator new мы выделяем память(1 шаг), дальше присваиваем указатель на эту память inst_ptr'у(шаг 3). И в конце конструируем объект. И напомню, это не программист так пишет. Это эквивалентный код тому, что может сгенерировать компилятор.
И этот код совсем не эквивалентен тому, что было изначально. Потому что конструктор Singleton может кинуть исключение и очень важно, чтобы есть он это сделает, то inst_ptr останется нетронутым. А он как бы изменяется. Поэтому, в большинстве случаев, компилятору нельзя генерировать такой код. Но при определенных условиях, он может это сделать. Например, если докажет сам себе, что конструктор не может кинуть исключение. И вот тогда происходит magic.
Тред №1 входит в первое условие, берет лок и выполняет шаги 1 и 3 и потом засыпает по воле планировщика. И мы имеем состояние, когда указатель проинициализирован, а объекта на этой памяти еще нет(шаг 2 не выполнен).
Тред №2 входит в функцию, видит, что указатель ненулевой и возвращает его наружу. А внешний код потом берет и разыименовывает указатель с непроинициализированной памятью. Уупс. UB.
Что можно сделать? Вообще говоря, ничего. Если сам язык не подразумевает многопоточности, то компилятор даже не думает о таких штуках и с его точки зрения все валидно. Даже volatile предотвращает реордеринг инструкций в рамках только одного потока. Но мы же в многоядерной среде и там существуют совершенно другие эффекты, о которых "безпоточные" С и С++ в душе не знают. Напоминаю, что мы до сих пор в эре до С++11. Завтра чуть ближе посмотрим на конкретные проблемы, при которых мы сталкиваемся, находясь в многопоточном окружении.
Criticize your solutions. Stay cool.
#concurrency #cppcore #compiler #cpp11
#опытным
Ядро идеи этого паттерна - тот факт, что решение из предыдущего поста неоптимально. Нам на самом деле нужно всего один раз взять замок для того, чтобы создать объект и потом не возвращаться к этом шагу. Если кто-то увидит, что наш указатель - ненулевой, то он даже не будет пытаться что-то делать и сразу вернется из функции.
Поэтому в паттерне блокировки с двойной проверкой, нулёвость указателя проверяется перед локом. Таким образом мы откидываем просадку производительности для подавляющего большинства вызова геттера синглтона. Однако у нас теперь остается узкое место - момент инициализации. И вот где появляется вторая проверка(всю обертку уже не буду писать для краткости).
static Singleton* Singleton::instance() {
if (inst_ptr == NULL) {
Lock lock;
if (inst_ptr == NULL) {
inst_ptr = new Singleton;
}
}
return inst_ptr;
}
Таким образом, даже если 2 потока войдут в первое условие и первый из них проинициализирует указатель, то второй поток будет вынужден проверить еще раз, можно ли ему создать объект. И грустный вернется из геттера, потому что ему нельзя.
Это классическая реализация, многие подписчики, думаю, видели ее. Однако от того, что она классическая, не следует, что она корректная.
Давайте посмотрим на вот эту строчку поближе:
inst_ptr = new Singleton;
Что здесь происходит? На самом деле происходят 3 шага:
1️⃣ Аллокация памяти под объект.
2️⃣ Вызов его конструктора на аллоцированной памяти.
3️⃣ Присваивание inst_ptr'у нового значения.
И вот мы, как наивные чукотские мальчики, думаем, что все эти 3 шага происходят в этом конкретном порядке. А вот фигушки! Компилятор, мать его ети. Иногда он может просто взять и переставить шаги 2 и 3 местами! И вот к чему это может привести.
Давайте посмотрим эквивалентный плюсовый код, когда компилятор переставил шаги:
static Singleton* Singleton::instance() {
if (inst_ptr == NULL) {
Lock lock;
if (inst_ptr == NULL) {
inst_ptr = // step 3
operator new(sizeof(Singleton)); // step 1
new(inst_ptr) Singleton; // step 2
}
}
return inst_ptr;
}
Че здесь происходит. Здесь просто явно показаны шаги. С помощью operator new мы выделяем память(1 шаг), дальше присваиваем указатель на эту память inst_ptr'у(шаг 3). И в конце конструируем объект. И напомню, это не программист так пишет. Это эквивалентный код тому, что может сгенерировать компилятор.
И этот код совсем не эквивалентен тому, что было изначально. Потому что конструктор Singleton может кинуть исключение и очень важно, чтобы есть он это сделает, то inst_ptr останется нетронутым. А он как бы изменяется. Поэтому, в большинстве случаев, компилятору нельзя генерировать такой код. Но при определенных условиях, он может это сделать. Например, если докажет сам себе, что конструктор не может кинуть исключение. И вот тогда происходит magic.
Тред №1 входит в первое условие, берет лок и выполняет шаги 1 и 3 и потом засыпает по воле планировщика. И мы имеем состояние, когда указатель проинициализирован, а объекта на этой памяти еще нет(шаг 2 не выполнен).
Тред №2 входит в функцию, видит, что указатель ненулевой и возвращает его наружу. А внешний код потом берет и разыименовывает указатель с непроинициализированной памятью. Уупс. UB.
Что можно сделать? Вообще говоря, ничего. Если сам язык не подразумевает многопоточности, то компилятор даже не думает о таких штуках и с его точки зрения все валидно. Даже volatile предотвращает реордеринг инструкций в рамках только одного потока. Но мы же в многоядерной среде и там существуют совершенно другие эффекты, о которых "безпоточные" С и С++ в душе не знают. Напоминаю, что мы до сих пор в эре до С++11. Завтра чуть ближе посмотрим на конкретные проблемы, при которых мы сталкиваемся, находясь в многопоточном окружении.
Criticize your solutions. Stay cool.
#concurrency #cppcore #compiler #cpp11
{kind=link}
Невероятные вероятности
Зачастую, когда мы пишем какие-то условия, то предполагаем, что какая-то ветка будет выполняться чаще другой. Самый простой пример - проверка чего-то на корректность. И если это что-то некорректно, то мы делаем какие-то действия, сигнализирующие о проблеме. И логично предположить, что наша программа хорошо написана (по крайней мере мы в это охотно верим). Поэтому ошибка - некая экстренная ситуация, которая не должна появляться часто. В принципе, любой не happy path может рассматриваться, как пример такой ситуации.
Может ли нам это знание как-то помочь? Вполне. В процессорах есть такой модуль - предсказатель переходов. На основе кода он по определенным эвристикам пытается понять, какая из веток выполниться с большей вероятностью. Он заранее подгружает данные и код для этой ветки, чтобы в случае удачного предсказания сократить время простоя вычислительного конвейера. И на самом деле, современные процессоры - настоящие Ванги! Их модуль предсказания переходов принимает правильные решения примерно в 90% случаев! Что не мало. Но все равно не идеально.
И вот тут-то мы и вступаем в дело. Мы можем немножко помочь предсказателю сделать более правильный выбор в конкретной ситуации. Путем указания ветки, которая по нашему мнению, будет выполняться с большей вероятностью.
У компиляторов есть свои расширения, которые могут помочь нам в этой задаче. Но они нам больше не нужны!
Потому что в С++20 появились стандартные аттрибуты [[likely]] и [[unlikely]]!
Допустим, мы пишем свой вектор интов. Причины покататься на байсикле мы отбросим в сторону и сконцентрируемся на сути. И мы дошли до метода MyVector::at, который по индексу выдает элемент. Но фишка в том, что этот метод проверяет индекс на нахождение в границах дозволенного и кидает исключение, если нештатная ситуация все-таки произошла.
Это довольно базовый класс, которым будет пользоваться множество программистов во множестве модулей. И разумно предположить, что большинство использований этого метода будут вполне корректны и все будет стабильно работать. Поэтому вполне логично сказать компилятору встроить в код подсказку, которая поможет процессору предсказывать правильно с большей вероятностью.
Ставьте лайки, если хотите немного бэнчмарков на эту тему. Если хотите что-то определенное померять(в пределах разумного времени написания поста), то пишите в комментах свои идеи.
Predict people's actions. Stay cool.
#cpp20 #compiler #performance
Зачастую, когда мы пишем какие-то условия, то предполагаем, что какая-то ветка будет выполняться чаще другой. Самый простой пример - проверка чего-то на корректность. И если это что-то некорректно, то мы делаем какие-то действия, сигнализирующие о проблеме. И логично предположить, что наша программа хорошо написана (по крайней мере мы в это охотно верим). Поэтому ошибка - некая экстренная ситуация, которая не должна появляться часто. В принципе, любой не happy path может рассматриваться, как пример такой ситуации.
Может ли нам это знание как-то помочь? Вполне. В процессорах есть такой модуль - предсказатель переходов. На основе кода он по определенным эвристикам пытается понять, какая из веток выполниться с большей вероятностью. Он заранее подгружает данные и код для этой ветки, чтобы в случае удачного предсказания сократить время простоя вычислительного конвейера. И на самом деле, современные процессоры - настоящие Ванги! Их модуль предсказания переходов принимает правильные решения примерно в 90% случаев! Что не мало. Но все равно не идеально.
И вот тут-то мы и вступаем в дело. Мы можем немножко помочь предсказателю сделать более правильный выбор в конкретной ситуации. Путем указания ветки, которая по нашему мнению, будет выполняться с большей вероятностью.
У компиляторов есть свои расширения, которые могут помочь нам в этой задаче. Но они нам больше не нужны!
Потому что в С++20 появились стандартные аттрибуты [[likely]] и [[unlikely]]!
Допустим, мы пишем свой вектор интов. Причины покататься на байсикле мы отбросим в сторону и сконцентрируемся на сути. И мы дошли до метода MyVector::at, который по индексу выдает элемент. Но фишка в том, что этот метод проверяет индекс на нахождение в границах дозволенного и кидает исключение, если нештатная ситуация все-таки произошла.
int MyVector::at(size_t index) {
if (index >= this->size) [[unlikely]] {
throw std::out_of_range ("MyVector index is out of range");
}
return this->data[index];
}
Это довольно базовый класс, которым будет пользоваться множество программистов во множестве модулей. И разумно предположить, что большинство использований этого метода будут вполне корректны и все будет стабильно работать. Поэтому вполне логично сказать компилятору встроить в код подсказку, которая поможет процессору предсказывать правильно с большей вероятностью.
Ставьте лайки, если хотите немного бэнчмарков на эту тему. Если хотите что-то определенное померять(в пределах разумного времени написания поста), то пишите в комментах свои идеи.
Predict people's actions. Stay cool.
#cpp20 #compiler #performance
{kind=link}
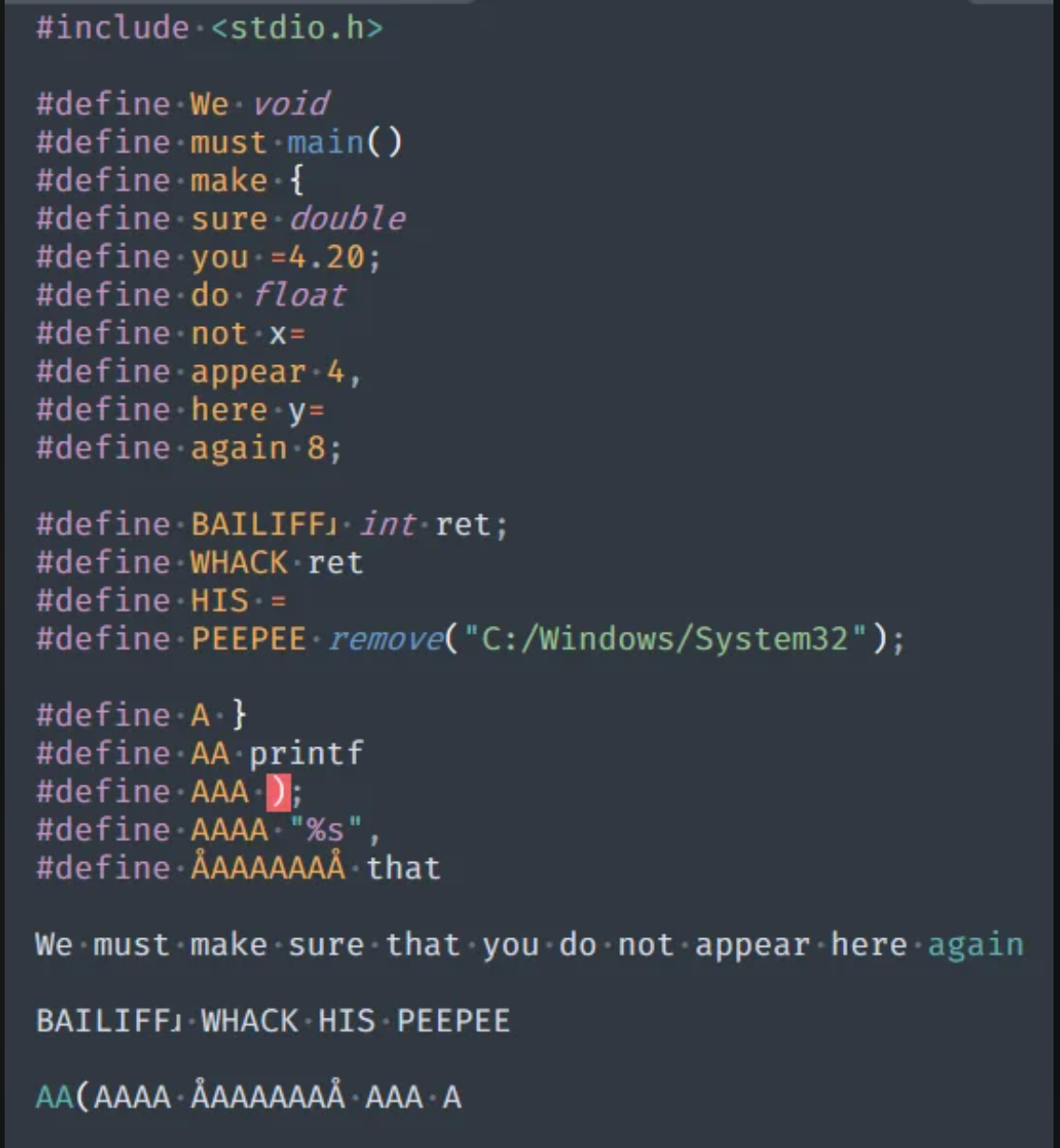
Директивы ifdef, ifndef, if
#новичкам
Иногда код, который мы пишем, должен зависеть от каких-то внешних параметров. Например, неплохо было бы довалять дебажный вывод при дебажной сборке. Или нам нужно написать кусочек платформоспецифичного кода и конкретная платформа передается нам наружными параметрами. Разные в общем бывают ситуации. Получается нам нужен какой-то механизм, который может проверять эти внешние параметры и в зависимости от их значений включать или выключать нужный кусок кода. Эту задачу можно решать по-разному. Сегодня мы обсудим доисторический способ, который, несмотря на свой почтенный возраст и опасность применения, активно используется в существующих проектах.
Этот способ - использование директив препроцессора #ifdef, #ifndef, #if. Все три - условные конструкции. Первая смотрит, определен ли в коде какой-то макрос. Если да, то делаем одни действия, если нет - другие. Второй наоборот, входит в первую ветку условия, если макрос не определен, и входит во вторую, если определен. Директива #if проверяет какое-то условие, ничего необычного. Все три директивы могут иметь как полные формы(с веткой в случае если условие ложно), так и неполные(без "else").
И вот в чем их прикол. Препроцессор работает с текстом программы. И он просто удаляет из этого текста ненужную ветку так, что до компиляции она даже не доходит, а нужная ветка как раз и подвергается обработке компилятором.
Например, у нас есть какой-то платформоспецифичный участок кода. Пусть это будет низкоуровневая оптимизация скалярного произведения на векторных инструкциях. Они разные для интеловских процессоров и для армов. Код может выглядеть примерно так:
Если каждое значение CPU_TYPE включает нужную ветку кода и убирает из текста программы все остальные.
Если мы хотим оптимизировать только под интеловские процессоры, то можем написать чуть проще:
(Все примеры - учебные, все совпадения с реальным кодом - случайны, не повторяйте код в домашних условиях). Здесь мы проверяем директивой ifdef, определен ли макрос OPTIMIZATION_ON, сигнализирующий что нужно использовать векторные инструкции. Если да, то ключаем в текст программы оптимизированный код. Если нет - обычный.
Можно еще кучу примеров и приложений этим директивам привести. Но я хотел подчеркнуть именно вот эту особенность, что мы можем добавлять или выбрасывать определенные участки кода в зависимости от внешних параметров.
Широко известно, что такой способ не только устарел, но еще и опасен. Завтра посмотрим, чем конкретно.
Choose the right path. Stay cool.
#compiler
#новичкам
Иногда код, который мы пишем, должен зависеть от каких-то внешних параметров. Например, неплохо было бы довалять дебажный вывод при дебажной сборке. Или нам нужно написать кусочек платформоспецифичного кода и конкретная платформа передается нам наружными параметрами. Разные в общем бывают ситуации. Получается нам нужен какой-то механизм, который может проверять эти внешние параметры и в зависимости от их значений включать или выключать нужный кусок кода. Эту задачу можно решать по-разному. Сегодня мы обсудим доисторический способ, который, несмотря на свой почтенный возраст и опасность применения, активно используется в существующих проектах.
Этот способ - использование директив препроцессора #ifdef, #ifndef, #if. Все три - условные конструкции. Первая смотрит, определен ли в коде какой-то макрос. Если да, то делаем одни действия, если нет - другие. Второй наоборот, входит в первую ветку условия, если макрос не определен, и входит во вторую, если определен. Директива #if проверяет какое-то условие, ничего необычного. Все три директивы могут иметь как полные формы(с веткой в случае если условие ложно), так и неполные(без "else").
И вот в чем их прикол. Препроцессор работает с текстом программы. И он просто удаляет из этого текста ненужную ветку так, что до компиляции она даже не доходит, а нужная ветка как раз и подвергается обработке компилятором.
Например, у нас есть какой-то платформоспецифичный участок кода. Пусть это будет низкоуровневая оптимизация скалярного произведения на векторных инструкциях. Они разные для интеловских процессоров и для армов. Код может выглядеть примерно так:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#if CPU_TYPE == 0
// mmx|sse|avx code
#elif CPU_TYPE == 1
// arm neon code
#else
static_assert(0, "NO CPU_TYPE IS SPECIFIED");
#endif
return result;
}
Если каждое значение CPU_TYPE включает нужную ветку кода и убирает из текста программы все остальные.
Если мы хотим оптимизировать только под интеловские процессоры, то можем написать чуть проще:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#ifdef OPTIMIZATION_ON
// mmx|sse|avx code
#else
for (int i = 0; i < vec1.size(); ++i)
result += vec1[i] * vec2[i];
#endif
return result;
}
(Все примеры - учебные, все совпадения с реальным кодом - случайны, не повторяйте код в домашних условиях). Здесь мы проверяем директивой ifdef, определен ли макрос OPTIMIZATION_ON, сигнализирующий что нужно использовать векторные инструкции. Если да, то ключаем в текст программы оптимизированный код. Если нет - обычный.
Можно еще кучу примеров и приложений этим директивам привести. Но я хотел подчеркнуть именно вот эту особенность, что мы можем добавлять или выбрасывать определенные участки кода в зависимости от внешних параметров.
Широко известно, что такой способ не только устарел, но еще и опасен. Завтра посмотрим, чем конкретно.
Choose the right path. Stay cool.
#compiler
{kind=link}
Опасности использования директив препроцессора
Вчерашний способ выбора ветки кода имеет несколько недостатков:
⛔️ Препроцессор работает с буквами/текстом программы, но не понимает программных сущностей. Это значит, что типабезопасность уходит из окна, и открывается простор для разного рода трудноотловимых багов.
⛔️ При компиляции проверяется только та ветка, которая попадет в итоговый код. Если вы не протестировали сборку своего кода для разных значений внешних параметров, а такое бывает например когда пока что есть только одно значение, а другое будет только в будущем. И в будущем скорее всего придется отлаживать элементарную сборку, потому что в код попадет непроверенная ветка.
⛔️ Вы ограничены возможностями препроцессора. Это значит, что вы не можете использовать в условии compile-time вычисления (аля результат работы constexpr функции).
⛔️ Отсюда же вытекает отсутствие возможности проверки условий, основанных на шаблонных параметрах кода. Это все из-за того, что препроцессор работает до начала компиляции программы. Он в душе не знает, что вы вообще программу пишите. Ему в целом ничего не мешает обработать текст Войны и Мира. Именно из-за отсутствия понимания контекста программы, мы и не можем проверять условия, основанные на compile-time значениях или шаблонных параметрах. Если вы хотите проверить, указатель ли к вам пришел в функцию или нет, или собрать какую-то метрику с constexpr массива и на ее основе принять решение - у вас ничего не выйдет.
⛔️ Вы очень сильно ограничены возможностями препроцессора. Попробуйте например сравнить какой-нибудь макрос с фиксированной строкой. Спойлер: у вас скорее всего ничего не выйдет. Например, как в примере из поста выше мы не можем написать так:
Поэтому и приходилось определять тип циферками.
Это конечно мем: сущность, которая работает с текстом программы, то есть со строками, не может работать со строками.
⛔️ С препроцессором в принципе опасно работать и еще труднее отлаживать магические баги. Могут возникнуть например вот такие трудноотловимые ошибки. Вам придется смотреть уже обработанную единицу трансляции, причем иногда даже не понимая, где может быть проблема. А со всеми включенными бинарниками и преобразованиями препроцессора это делать очень долго и больно. А потом оказывается, что какой-то умник заменил в макросах функцию DontWorryBeHappy на ILovePainGiveMeMore.
В комментах @xiran22 скидывал пример библиотечки, написанной с помощью макросов. Вот она, можете посмотреть. Это не только пример сложности понимания кода и всех проблем выше. Тут просто плохая архитектура, затыки которой решаются макросами.
Поделитесь в комментах своими интересными кейсами простреленных ступней из-за макросов.
Avoid dangerous tools. Stay cool.
#compiler #cppcore
Вчерашний способ выбора ветки кода имеет несколько недостатков:
⛔️ Препроцессор работает с буквами/текстом программы, но не понимает программных сущностей. Это значит, что типабезопасность уходит из окна, и открывается простор для разного рода трудноотловимых багов.
⛔️ При компиляции проверяется только та ветка, которая попадет в итоговый код. Если вы не протестировали сборку своего кода для разных значений внешних параметров, а такое бывает например когда пока что есть только одно значение, а другое будет только в будущем. И в будущем скорее всего придется отлаживать элементарную сборку, потому что в код попадет непроверенная ветка.
⛔️ Вы ограничены возможностями препроцессора. Это значит, что вы не можете использовать в условии compile-time вычисления (аля результат работы constexpr функции).
⛔️ Отсюда же вытекает отсутствие возможности проверки условий, основанных на шаблонных параметрах кода. Это все из-за того, что препроцессор работает до начала компиляции программы. Он в душе не знает, что вы вообще программу пишите. Ему в целом ничего не мешает обработать текст Войны и Мира. Именно из-за отсутствия понимания контекста программы, мы и не можем проверять условия, основанные на compile-time значениях или шаблонных параметрах. Если вы хотите проверить, указатель ли к вам пришел в функцию или нет, или собрать какую-то метрику с constexpr массива и на ее основе принять решение - у вас ничего не выйдет.
⛔️ Вы очень сильно ограничены возможностями препроцессора. Попробуйте например сравнить какой-нибудь макрос с фиксированной строкой. Спойлер: у вас скорее всего ничего не выйдет. Например, как в примере из поста выше мы не можем написать так:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#if CPU_TYPE == "INTEL"
// mmx|sse|avx code
#elif CPU_TYPE == "ARM"
// arm neon code
#else
static_assert(0, "NO CPU_TYPE IS SPECIFIED");
#endif
return result;
}
Поэтому и приходилось определять тип циферками.
Это конечно мем: сущность, которая работает с текстом программы, то есть со строками, не может работать со строками.
⛔️ С препроцессором в принципе опасно работать и еще труднее отлаживать магические баги. Могут возникнуть например вот такие трудноотловимые ошибки. Вам придется смотреть уже обработанную единицу трансляции, причем иногда даже не понимая, где может быть проблема. А со всеми включенными бинарниками и преобразованиями препроцессора это делать очень долго и больно. А потом оказывается, что какой-то умник заменил в макросах функцию DontWorryBeHappy на ILovePainGiveMeMore.
В комментах @xiran22 скидывал пример библиотечки, написанной с помощью макросов. Вот она, можете посмотреть. Это не только пример сложности понимания кода и всех проблем выше. Тут просто плохая архитектура, затыки которой решаются макросами.
Поделитесь в комментах своими интересными кейсами простреленных ступней из-за макросов.
Avoid dangerous tools. Stay cool.
#compiler #cppcore
{kind=link}
Странный размер std::unordered_map
#опытным
Стандартная ситуация. Создаем контейнер, резервируем подходящий размер для ожидаемого количества элементов в коллекции и запихиваем элементы. Все просто. Но это с каким-нибудь вектором все просто. А хэш-мапа - дело нетривиальное. Смотрим на код:
Все, как обычно. А теперь вывод:
WTF? Я же сказал выделить в мапе 6 бакетов, а не 7. Какой непослушный компилятор!
Вообще, поведение странное, но может там просто всегда +1 по какой-то причине?
Поменяем map_size на 9 и посмотрим вывод:
Again. WTF? Уже на 2 разница. Нужна новая гипотеза... Попробуем третье число. Возьмем 13.
А тут работает! Но это не прибавляет понимания проблемы... В чем же дело?
Из цппреференса про метод reserve:
То есть стандарт разрешает реализациям выделять больше элементов для мапы, чем мы запросили.
Легитимацию безобразия мы получили, но хотелось бы внятное объяснение причины предоставления такой возможности.
Реализации обычно выбирают bucket_count исходя из соображений быстродействия(как обычно). Тут они выбирают из двух опций:
1️⃣ Выбирают в качестве bucket_count степень двойки, то есть округляют до степени двойки в большую сторону. Это помогает эффективно маппить результат хэш функции на размер самой хэш-таблицы. Можно просто сделать битовое И и отбросить все биты, старше нашей степени. Что делается на один цикл цпу.
Но этот способ имеет негативный эффект в виде того же отбрасывания битов. То есть эти страшие биты никак не влияют на маппинг хэша на бакеты, то уменьшает равномерность распределения.
Таким способом пользуется Visual C++.
2️⃣ Поддерживают bucket_count простым числом.
Это дает крутой эффект того, что старшие биты также влияют на распределение объектов по бакетам. В этом случае даже плохие хэш-функции имеют более равномерное размещение бакетов.
Однако наивная реализация такого подхода заставляет каждый раз делить на рантаймовое значение bucket_count, что может занимать до 100 раз больше циклов.
Более быстрой альтернативой может быть использование захардкоженой таблицы простых чисел. Индекс в ней выбирается на основе запрашиваемого значения bucket_count. Таким образом компилятор может заоптимизировать деление по модулю через битовые операции, сложения, вычитания и умножения. Можете посмотреть на эти оптимизации более подробно на этом примере в годболт.
Этой реализацией пользуется GCC и Clang.
Вот такие страсти происходят у нас под носом под капотом неупорядоченной мапы.
Optimize everything. Stay cool.
#STL #optimization #compiler
#опытным
Стандартная ситуация. Создаем контейнер, резервируем подходящий размер для ожидаемого количества элементов в коллекции и запихиваем элементы. Все просто. Но это с каким-нибудь вектором все просто. А хэш-мапа - дело нетривиальное. Смотрим на код:
constexpr size_t map_size = 6;
std::unordered_map<int, int> mymap;
mymap.reserve(map_size);
for (int i = 0; i < map_size; i++) {
mymap[i] = i;
}
std::cout << "mymap has " << mymap.bucket_count() << " buckets\n";
Все, как обычно. А теперь вывод:
mymap has 7 buckets
WTF? Я же сказал выделить в мапе 6 бакетов, а не 7. Какой непослушный компилятор!
Вообще, поведение странное, но может там просто всегда +1 по какой-то причине?
Поменяем map_size на 9 и посмотрим вывод:
mymap has 11 buckets
Again. WTF? Уже на 2 разница. Нужна новая гипотеза... Попробуем третье число. Возьмем 13.
mymap has 13 buckets
А тут работает! Но это не прибавляет понимания проблемы... В чем же дело?
Из цппреференса про метод reserve:
Request a capacity change
Sets the number of buckets in the container (bucket_count) to the most appropriate to contain at least n elements.
То есть стандарт разрешает реализациям выделять больше элементов для мапы, чем мы запросили.
Легитимацию безобразия мы получили, но хотелось бы внятное объяснение причины предоставления такой возможности.
Реализации обычно выбирают bucket_count исходя из соображений быстродействия(как обычно). Тут они выбирают из двух опций:
1️⃣ Выбирают в качестве bucket_count степень двойки, то есть округляют до степени двойки в большую сторону. Это помогает эффективно маппить результат хэш функции на размер самой хэш-таблицы. Можно просто сделать битовое И и отбросить все биты, старше нашей степени. Что делается на один цикл цпу.
Но этот способ имеет негативный эффект в виде того же отбрасывания битов. То есть эти страшие биты никак не влияют на маппинг хэша на бакеты, то уменьшает равномерность распределения.
Таким способом пользуется Visual C++.
2️⃣ Поддерживают bucket_count простым числом.
Это дает крутой эффект того, что старшие биты также влияют на распределение объектов по бакетам. В этом случае даже плохие хэш-функции имеют более равномерное размещение бакетов.
Однако наивная реализация такого подхода заставляет каждый раз делить на рантаймовое значение bucket_count, что может занимать до 100 раз больше циклов.
Более быстрой альтернативой может быть использование захардкоженой таблицы простых чисел. Индекс в ней выбирается на основе запрашиваемого значения bucket_count. Таким образом компилятор может заоптимизировать деление по модулю через битовые операции, сложения, вычитания и умножения. Можете посмотреть на эти оптимизации более подробно на этом примере в годболт.
Этой реализацией пользуется GCC и Clang.
Вот такие страсти происходят у нас под носом под капотом неупорядоченной мапы.
Optimize everything. Stay cool.
#STL #optimization #compiler
{kind=link}