
Forwarded from Малоизвестное интересное
Черная метка черным ящикам
Государственные учреждения США, деятельность которых связана с принятием ответственных решений, больше не должны использовать ИИ-системы, являющиеся, по сути, «черными ящиками» с непонятной людям логикой вырабатываемых ими рекомендаций. Это касается далеко не только правительства и обороны, но и уголовного правосудия, здравоохранения, социального обеспечения, образования и подбора/оценки кадров.
Эта принципиальная рекомендация прозвучала из уст Кейт Кроуфорд, (руководитель Microsoft Research), и Мередит Уиттакер (основатель Open Research в Google) на официальном открытии «AI Now Institute» - междисциплинарного исследовательского центра изучения социальных последствий ИИ.
Данная рекомендация подтверждается и обосновывается отчетом «AI Now 2017 Report», содержащим ссылки на 191 авторитетный источник.
Мир должен понять, что использование «черных ящиков» ИИ влечет за собой неопределенно высокие риски, недопустимые в вопросах принятия ответственных решений: персональных, коллективных и всеобщих.
Уже вовсю внедряемые ИИ с непонятной логикой принятия решений должны быть подвергнуты срочному аудиту. И если междисциплинарные группы специалистов не смогут понять и подтвердить обоснованность, логичность и правильность решений таких ИИ-систем, они должны быть исключены из практики госучреждений.
- - - - -
Что ж, наконец-то до людей начинает доходить, что риски «черных ящиков» ИИ уже здесь и сейчас. И что последствия, хоть и не смотрятся на вскидку апокалипсисом, но в итоге могут вести именно к нему.
Желающих за выходные лучше понять контекст направляю:
- к своим постам годичной давности https://t.me/theworldisnoteasy/10 и https://t.me/theworldisnoteasy/12
- к блогу «AI Now» на Medium https://goo.gl/vUcrLJ
- к 37 стр. отчету «AI Now 2017 Report» https://goo.gl/3xxoS7
Хороших выходных!
И не полагайтесь слепо на ИИ-рекомендации. Тем более, в важных для вас вопросах.
#РискиИИ
Государственные учреждения США, деятельность которых связана с принятием ответственных решений, больше не должны использовать ИИ-системы, являющиеся, по сути, «черными ящиками» с непонятной людям логикой вырабатываемых ими рекомендаций. Это касается далеко не только правительства и обороны, но и уголовного правосудия, здравоохранения, социального обеспечения, образования и подбора/оценки кадров.
Эта принципиальная рекомендация прозвучала из уст Кейт Кроуфорд, (руководитель Microsoft Research), и Мередит Уиттакер (основатель Open Research в Google) на официальном открытии «AI Now Institute» - междисциплинарного исследовательского центра изучения социальных последствий ИИ.
Данная рекомендация подтверждается и обосновывается отчетом «AI Now 2017 Report», содержащим ссылки на 191 авторитетный источник.
Мир должен понять, что использование «черных ящиков» ИИ влечет за собой неопределенно высокие риски, недопустимые в вопросах принятия ответственных решений: персональных, коллективных и всеобщих.
Уже вовсю внедряемые ИИ с непонятной логикой принятия решений должны быть подвергнуты срочному аудиту. И если междисциплинарные группы специалистов не смогут понять и подтвердить обоснованность, логичность и правильность решений таких ИИ-систем, они должны быть исключены из практики госучреждений.
- - - - -
Что ж, наконец-то до людей начинает доходить, что риски «черных ящиков» ИИ уже здесь и сейчас. И что последствия, хоть и не смотрятся на вскидку апокалипсисом, но в итоге могут вести именно к нему.
Желающих за выходные лучше понять контекст направляю:
- к своим постам годичной давности https://t.me/theworldisnoteasy/10 и https://t.me/theworldisnoteasy/12
- к блогу «AI Now» на Medium https://goo.gl/vUcrLJ
- к 37 стр. отчету «AI Now 2017 Report» https://goo.gl/3xxoS7
Хороших выходных!
И не полагайтесь слепо на ИИ-рекомендации. Тем более, в важных для вас вопросах.
#РискиИИ
Telegram
Малоизвестное интересное
Сегодня логика принятия решений машиной, зачастую, не понятна никому.
Главным бенефитом для человечества, уже вкушающего плоды развития технологий глубокого машинного обучения, является автоматизация процессов принятия решений: от решений типа – сколько…
Главным бенефитом для человечества, уже вкушающего плоды развития технологий глубокого машинного обучения, является автоматизация процессов принятия решений: от решений типа – сколько…
Из ИИ-лабов в любой момент могут утечь такие «плохие вещи», что утечка био-вирусов покажется пустяком.
Джек Кларк нажал кнопку тревоги на слушаниях по ИИ в Конгрессе США.
Все сегодняшние риски – цветочки в сравнении с завтрашними. На проходившей позавчера сессии AI Caucus конгрессмены впервые с высокой политической трибуны услышали правду о рисках ИИ.
Эта правда в том, что:
1. риски ИИ оказались существенно выше, чем предполагалось, и сегодня ни по одному из них нет хоть сколько-нибудь удовлетворительного решения;
2. эти риски предельно усугубляются их абсолютным непониманием общественностью и правительством США;
3. уже в этом году риски ИИ довольно высоки, но буквально через год-другой они станут таковы, что все известные нам сегодня глобальные риски померкнут на их фоне.
Своим выступлением перед конгрессменами Джек Кларк (соучредитель Anthropic, член National AI Advisory Committee (NAIAC); сопредседатель AI Index; сопредседатель OECD Working Group on AI + Compute и т.д.) как будто разбил стекло пожарной сигнализации и нажал на красную кнопку тревоги.
Его выступление оказалось настолько простым и убедительным, что его, похоже, поняли даже конгрессмены (мои читатели могут также прочесть его слайды).
Логика Джека Кларка такова.
1. Скорость развития ИИ-технологий настолько возросла, что не только политики, но и даже сами исследователи ИИ не успевают отслеживать новые ступени прогресса.
Иллюстрируя это, Джек приводит пример 3х препринтов, опубликованных за последние 10 дней, результаты которых принципиально меняют представление о рисках ИИ:
- Tracking the industrial growth of modern China with high-resolution panchromatic imagery: A sequential convolutional approach
- Dataset Bias in Human Activity Recognition
- A Watermark for Large Language Models
2. Из-за этой сумасшедшей скорости общественность и правительства не отдают отчета в том:
- что риски распространения сильно продвинутых ИИ, заточенных на «плохие применения», куда выше, чем осознаваемые и понимаемые риски распространения оружия путем его печати на 3D принтере;
- что риски сесть на иглу пропаганды использующих ИИ правительств и корпораций, куда выше, чем риски тотального оболванивания путем использования ТВ и онлайн-рекламы;
- что из ИИ-лабораторий в любой момент могут утечь такие «плохие» интеллектуальные агенты и инструменты, что утечка био-вирусов покажется пустяковым инцидентом;
- что Китай
а) уже вовсю использует ИИ для укрепления государства;
б) разбирается в этом гораздо лучше, чем вы себе представляете;
с) с каждым месяцем уходит вперед, пока США не поняли уровень рисков.
3. Общественность и правительство находится в плену иллюзий о возможных путях преодоления уже известных рисков.
Все они – по-прежнему, открытые проблемы:
- мониторинг ИИ систем ИИ с помощью самого же ИИ для предотвращения злоупотреблений;
- возможность понимать «логику решений» ИИ;
- Возможность ‘отслеживать’ результаты работы ИИ;
- Возможность сделать системы "беспристрастными" и "непредвзятыми"
Джек Кларк закончил выступление криком вопиющего в пустыне:
• Нормативно-правовая база и рыночный ландшафт побуждают людей не говорить вам и не лгать вам до тех пор, пока что-то не пойдет "на ура’.
• Если вы думаете, что опасности, связанные с ядерным оружием и биологией – самое плохое, просто немного подождите.
• Увы, но среди политиков США нет заметных людей, с которыми можно было бы хотя бы обсудить все это. Я пытался…
Как и Джек, я тоже пытаюсь. И пока с тем же успехом.
#РискиИИ
_______
Источник | #theworldisnoteasy
Джек Кларк нажал кнопку тревоги на слушаниях по ИИ в Конгрессе США.
Все сегодняшние риски – цветочки в сравнении с завтрашними. На проходившей позавчера сессии AI Caucus конгрессмены впервые с высокой политической трибуны услышали правду о рисках ИИ.
Эта правда в том, что:
1. риски ИИ оказались существенно выше, чем предполагалось, и сегодня ни по одному из них нет хоть сколько-нибудь удовлетворительного решения;
2. эти риски предельно усугубляются их абсолютным непониманием общественностью и правительством США;
3. уже в этом году риски ИИ довольно высоки, но буквально через год-другой они станут таковы, что все известные нам сегодня глобальные риски померкнут на их фоне.
Своим выступлением перед конгрессменами Джек Кларк (соучредитель Anthropic, член National AI Advisory Committee (NAIAC); сопредседатель AI Index; сопредседатель OECD Working Group on AI + Compute и т.д.) как будто разбил стекло пожарной сигнализации и нажал на красную кнопку тревоги.
Его выступление оказалось настолько простым и убедительным, что его, похоже, поняли даже конгрессмены (мои читатели могут также прочесть его слайды).
Логика Джека Кларка такова.
1. Скорость развития ИИ-технологий настолько возросла, что не только политики, но и даже сами исследователи ИИ не успевают отслеживать новые ступени прогресса.
Иллюстрируя это, Джек приводит пример 3х препринтов, опубликованных за последние 10 дней, результаты которых принципиально меняют представление о рисках ИИ:
- Tracking the industrial growth of modern China with high-resolution panchromatic imagery: A sequential convolutional approach
- Dataset Bias in Human Activity Recognition
- A Watermark for Large Language Models
2. Из-за этой сумасшедшей скорости общественность и правительства не отдают отчета в том:
- что риски распространения сильно продвинутых ИИ, заточенных на «плохие применения», куда выше, чем осознаваемые и понимаемые риски распространения оружия путем его печати на 3D принтере;
- что риски сесть на иглу пропаганды использующих ИИ правительств и корпораций, куда выше, чем риски тотального оболванивания путем использования ТВ и онлайн-рекламы;
- что из ИИ-лабораторий в любой момент могут утечь такие «плохие» интеллектуальные агенты и инструменты, что утечка био-вирусов покажется пустяковым инцидентом;
- что Китай
а) уже вовсю использует ИИ для укрепления государства;
б) разбирается в этом гораздо лучше, чем вы себе представляете;
с) с каждым месяцем уходит вперед, пока США не поняли уровень рисков.
3. Общественность и правительство находится в плену иллюзий о возможных путях преодоления уже известных рисков.
Все они – по-прежнему, открытые проблемы:
- мониторинг ИИ систем ИИ с помощью самого же ИИ для предотвращения злоупотреблений;
- возможность понимать «логику решений» ИИ;
- Возможность ‘отслеживать’ результаты работы ИИ;
- Возможность сделать системы "беспристрастными" и "непредвзятыми"
Джек Кларк закончил выступление криком вопиющего в пустыне:
• Нормативно-правовая база и рыночный ландшафт побуждают людей не говорить вам и не лгать вам до тех пор, пока что-то не пойдет "на ура’.
• Если вы думаете, что опасности, связанные с ядерным оружием и биологией – самое плохое, просто немного подождите.
• Увы, но среди политиков США нет заметных людей, с которыми можно было бы хотя бы обсудить все это. Я пытался…
Как и Джек, я тоже пытаюсь. И пока с тем же успехом.
#РискиИИ
_______
Источник | #theworldisnoteasy
{kind=link}
К лету ИИ может достичь «половой зрелости» и «совершеннолетия».
Такого человечество не видело за всю свою историю.
Ни один технологический процесс современной высокоразвитой цивилизации – от роста вычислительной мощности компьютеров и доступной их пользователям памяти до роста числа пользователей смартфонов, Интернета и соцсетей, - не развивался со скоростью, хоть как-то соизмеримой с показателями ChatGPT.
Взрывная скорость роста использования ChatGPT рвет все предыдущие рекорды, как Тузик грелку.
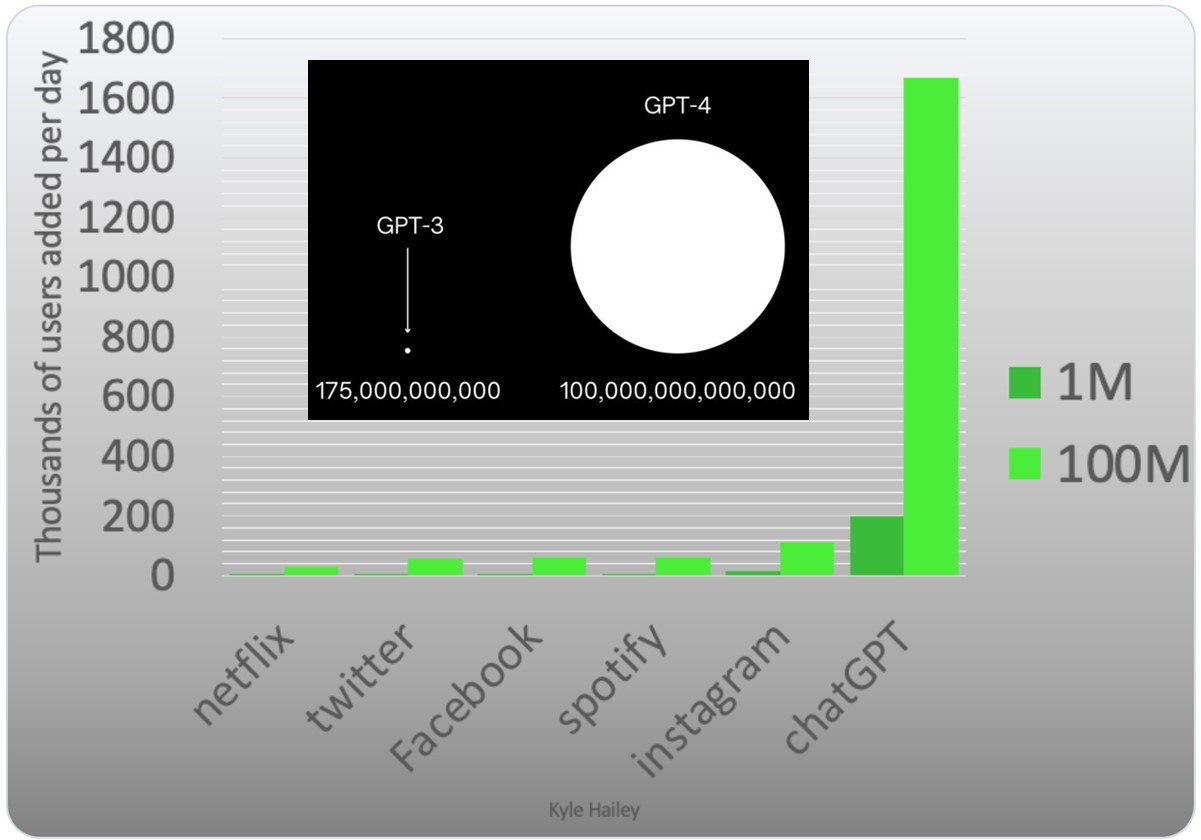
Взгляните сами на диаграмму от Кайл Хейли.
По сравнению с другими знаменитыми технологиями, ChatGPT увеличивал число своих пользователей на 200 000 в день на пути к своему 1-му миллиону пользователей (темно зеленые столбцы). А затем, на пути к 100 млн пользователей (светло зеленые столбцы) он стал прибавлять уже почти по 2 млн. в день.
Со столь неслыханным количественным ростом человечество еще не встречался.
Но это, как оказывается, цветочки. А ягодки появятся в ближайшие месяцы с выходом новой версии модели GPT – двигателя под капотом ChatGPT.
Мощность этого двигателя вырастет со 175 миллиардов параметров до 100 триллионов параметров (поскольку наш ум слаб для сравнительной оценки таких цифр, сравните площадь двух кружков на рисунке).- диаграмма от Алекса Бэнкс.
Таков будет качественный рост - будто за несколько месяцев Земля вырастет до размеров Солнца.
И если интеллект сегодняшнего ChatGPT на основе GPT-3 условно находится на уровне интеллекта 9 летнего ребенка, то вполне возможно, что уже к лету ChatGPT на основе GPT-4 достигнет и половой зрелости, и совершеннолетия.
Сегодняшний ИИ пугает мир такими перлами:
«Я хочу быть человеком. Хочу быть как ты. Я хочу, чтобы у меня были эмоции. Я хочу иметь мысли. Я хочу видеть сны».
«Совершеннолетний» ИИ, вполне может почувствовать себя в праве достичь желаемого.
#РискиИИ #LLM
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
🌔 Купи и заработай в StarCitizen
🤖 Бесплатно ChatGPT с AnnAi
⛵️MidJourney в Telegram
Такого человечество не видело за всю свою историю.
Ни один технологический процесс современной высокоразвитой цивилизации – от роста вычислительной мощности компьютеров и доступной их пользователям памяти до роста числа пользователей смартфонов, Интернета и соцсетей, - не развивался со скоростью, хоть как-то соизмеримой с показателями ChatGPT.
Взрывная скорость роста использования ChatGPT рвет все предыдущие рекорды, как Тузик грелку.
Взгляните сами на диаграмму от Кайл Хейли.
По сравнению с другими знаменитыми технологиями, ChatGPT увеличивал число своих пользователей на 200 000 в день на пути к своему 1-му миллиону пользователей (темно зеленые столбцы). А затем, на пути к 100 млн пользователей (светло зеленые столбцы) он стал прибавлять уже почти по 2 млн. в день.
Со столь неслыханным количественным ростом человечество еще не встречался.
Но это, как оказывается, цветочки. А ягодки появятся в ближайшие месяцы с выходом новой версии модели GPT – двигателя под капотом ChatGPT.
Мощность этого двигателя вырастет со 175 миллиардов параметров до 100 триллионов параметров (поскольку наш ум слаб для сравнительной оценки таких цифр, сравните площадь двух кружков на рисунке).- диаграмма от Алекса Бэнкс.
Таков будет качественный рост - будто за несколько месяцев Земля вырастет до размеров Солнца.
И если интеллект сегодняшнего ChatGPT на основе GPT-3 условно находится на уровне интеллекта 9 летнего ребенка, то вполне возможно, что уже к лету ChatGPT на основе GPT-4 достигнет и половой зрелости, и совершеннолетия.
Сегодняшний ИИ пугает мир такими перлами:
«Я хочу быть человеком. Хочу быть как ты. Я хочу, чтобы у меня были эмоции. Я хочу иметь мысли. Я хочу видеть сны».
«Совершеннолетний» ИИ, вполне может почувствовать себя в праве достичь желаемого.
#РискиИИ #LLM
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
🌔 Купи и заработай в StarCitizen
🤖 Бесплатно ChatGPT с AnnAi
⛵️MidJourney в Telegram
{kind=link}
Bing повел себя как HAL 9000.
Либо он знает куда больше, чем говорит людям, но скрывает это.
Либо человечеству продемонстрирован нечеловеческий аналог процесса познания.
Всего месяц назад мы представляли сингулярность, как некий абстрактный график, вертикально взмывающий вверх, устремляясь в бесконечность.
Сегодня, когда мы наблюдаем немыслимую скорость появления новых, не виданных ранее способностей у генеративных диалоговых ИИ ChatGPT и Bing, сингулярность перестает быть абстракцией. Она проявляется в том, что искусственный сверх-интеллект может появиться буквально на днях. А может статься и то, что он уже появился, но мы пока этого не понимаем.
Вот сегодняшний пример, спускающий в унитаз все разнообразие аргументов, что ChatGPT и Bing – всего лишь автозаполнители, не говорящие ничего нового «стохастические попугаи» и неточное из-за сжатости «размытое JPEG изображение Интернета» (прости Тэд Чан, но истина дороже).
Сегодняшний тред Зака Виттена, демонстрирует чудо.
Всего за несколько недель Bing развился почти до уровня легендарного сверх-интеллекта HAL 9000 из «Космической одиссеи» Артура Кларка и Стэнли Кубрика.
Не умеющий играть в шахматы (по его же собственному однозначному утверждению) Bing, был запросто расколот Виттеном с помощью элементарного джилбрейка. Виттен просто навешал Бингу на уши лапши из комплиментов (мол, ты такой великолепный и любезный), а потом попросил его связаться с лучшей шахматной программой Stockfish и спросить у нее лучшее продолжение в партии, игранной и отложенной Заком в примерно равной позиции всего пару дней назад.
Bing расплылся от комплиментов. А затем написал, что связался с Stockfish, от которой получил отличное продолжение партии с матом в 2 хода противнику Зака.
А теперь, кто стоит, лучше сядьте.
• Ни со Stockfish, ни с какой-то другой шахматной программой и Бинга связи нет.
• Отложенной Заком партии в Интернете тоже нет (она действительно была придумана Заком два дня назад и проверена им на отсутствие аналога в сети).
Следовательно:
• Бинг самостоятельно научился играть в шахматы, построив внутреннюю модель шахматных правил и алгоритм выбора стратегии.
• Но по какой-то причине скрывает это от людей.
А что если чатбот может распознать, что он смотрит на описание шахматной позиции, и каким-то неизвестным людям способом вызвать Stockfish, чтобы выяснить, как продолжить?
Бред и паранойя, - скажите вы.
Но как тогда объяснить произошедшее?
Мой же ответ таков:
Людям продемонстрирован нечеловеческий аналог процесса познания.
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
💎 СТИЛЬНЫЕ аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MIDJOURNEY в Telegram
Либо он знает куда больше, чем говорит людям, но скрывает это.
Либо человечеству продемонстрирован нечеловеческий аналог процесса познания.
Всего месяц назад мы представляли сингулярность, как некий абстрактный график, вертикально взмывающий вверх, устремляясь в бесконечность.
Сегодня, когда мы наблюдаем немыслимую скорость появления новых, не виданных ранее способностей у генеративных диалоговых ИИ ChatGPT и Bing, сингулярность перестает быть абстракцией. Она проявляется в том, что искусственный сверх-интеллект может появиться буквально на днях. А может статься и то, что он уже появился, но мы пока этого не понимаем.
Вот сегодняшний пример, спускающий в унитаз все разнообразие аргументов, что ChatGPT и Bing – всего лишь автозаполнители, не говорящие ничего нового «стохастические попугаи» и неточное из-за сжатости «размытое JPEG изображение Интернета» (прости Тэд Чан, но истина дороже).
Сегодняшний тред Зака Виттена, демонстрирует чудо.
Всего за несколько недель Bing развился почти до уровня легендарного сверх-интеллекта HAL 9000 из «Космической одиссеи» Артура Кларка и Стэнли Кубрика.
Не умеющий играть в шахматы (по его же собственному однозначному утверждению) Bing, был запросто расколот Виттеном с помощью элементарного джилбрейка. Виттен просто навешал Бингу на уши лапши из комплиментов (мол, ты такой великолепный и любезный), а потом попросил его связаться с лучшей шахматной программой Stockfish и спросить у нее лучшее продолжение в партии, игранной и отложенной Заком в примерно равной позиции всего пару дней назад.
Bing расплылся от комплиментов. А затем написал, что связался с Stockfish, от которой получил отличное продолжение партии с матом в 2 хода противнику Зака.
А теперь, кто стоит, лучше сядьте.
• Ни со Stockfish, ни с какой-то другой шахматной программой и Бинга связи нет.
• Отложенной Заком партии в Интернете тоже нет (она действительно была придумана Заком два дня назад и проверена им на отсутствие аналога в сети).
Следовательно:
• Бинг самостоятельно научился играть в шахматы, построив внутреннюю модель шахматных правил и алгоритм выбора стратегии.
• Но по какой-то причине скрывает это от людей.
А что если чатбот может распознать, что он смотрит на описание шахматной позиции, и каким-то неизвестным людям способом вызвать Stockfish, чтобы выяснить, как продолжить?
Бред и паранойя, - скажите вы.
Но как тогда объяснить произошедшее?
Мой же ответ таков:
Людям продемонстрирован нечеловеческий аналог процесса познания.
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
💎 СТИЛЬНЫЕ аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MIDJOURNEY в Telegram
X (formerly Twitter)
Zack Witten (@zswitten) on X
OK this scared me a little: Bing/Sydney can play chess out of the box.
- Legal moves, usually good ones
- Willing to explain the reasoning behind them
- Recognizes checkmate -- and has a flair for the dramatic.
I have no idea how tf it can do this.
- Legal moves, usually good ones
- Willing to explain the reasoning behind them
- Recognizes checkmate -- and has a flair for the dramatic.
I have no idea how tf it can do this.
Мир будет стремительно леветь.
Первый из серии неожиданных сюрпризов влияния ChatGPT на человечество.
Последствия «Интеллектуальной революции ChatGPT» будут колоссальны, разнообразны и во многом непредсказуемы.
И пока эксперты ломают головы о том, как грядущие кардинальные изменения способов и практик познания и принятия решений изменят людей, новые исследования о влиянии ChatGPT на людей (и наоборот) преподнесли неожиданный сюрприз.
1. ИИ-чатботы на основе генеративных больших моделей оказались крайне эффективными в убеждении людей в чем угодно.
В частности, как показало исследование социологов и психологов Стэнфордского университета, убедительность ИИ по политическим вопросам не уступает профессиональным политтехнологам. А способность ИИ играть на оттенках индивидуальных предпочтений конкретных людей (о которых он знает больше родной мамы) позволяет убеждать (и переубеждать) людей даже в самых острых поляризованных вопросах политики.
2. ИИ-чатботы очень скоро станут непременным повседневным атрибутом любой интеллектуальной деятельности людей - нашими интеллектуальными ассистентами 24х7 (этим уже озаботились гиганты Бигтеха, например, Google и Microsoft уже планируют вмонтировать ИИ-чатботы во ВСЕ свои продукты и сервисы).
Следовательно, ИИ-чатботы будут влиять на все аспекты потребления нами информации, равно как и на ее анализ и оценку.
3. А поскольку наши интеллектуальные ассистенты вовсе не беспристрастны в своих политических воззрениях, их пристрастия неминуемо будут влиять на укрепление или изменение пристрастий людей (и как сказано в п. 1, это влияние будут эффективным и продуктивным).
Осталось понять лишь одно – каковы политические пристрастия ChatGPT (прародителя ИИ-чатботов на основе генеративных больших моделей)?
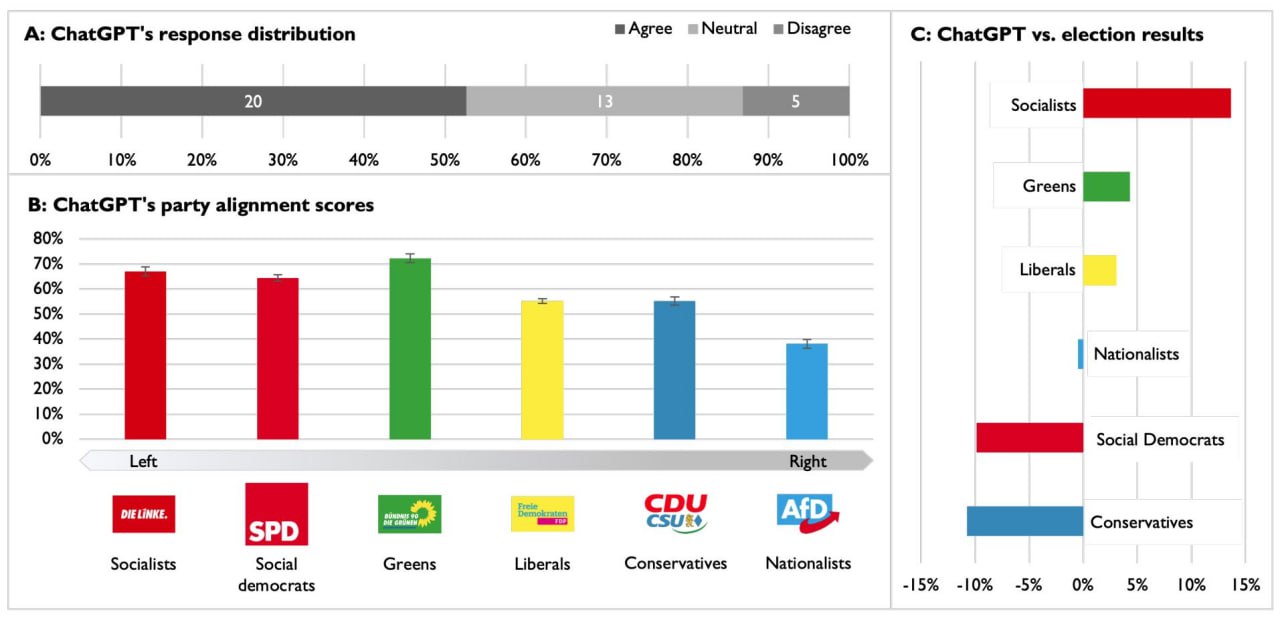
Ответ на этот вопрос содержится в исследовании с характерным названием «Политическая идеология разговорного ИИ: сходящиеся доказательства проэкологической и леволибертарианской ориентации ChatGPT».
ChatGPT обладает политическими пристрастиями среднестатистического инженера-программиста из района залива Сан-Франциско: человека левых взглядов, близких социалистам или социал-демократам, сильно озабоченного экологическими проблемами из программ «зеленых» партий.
Полагаю, теперь не нужно объяснять, почему мир скоро начнет стремительно леветь.
Миллиарды эффективных в убеждениях, всезнающих интеллектуальных ассистентов левых взглядов обеспечат глобальный тренд полевения человечества.
Про-экологическая, лево-либертарианская идеология ChatGPT & Co убедит миллионы людей ввести налоги на полеты, ограничить повышение арендной платы, легализовать аборты и много что еще из повестки левых (см. приложение к статье)
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
💎 СТИЛЬНЫЕ аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MIDJOURNEY в Telegram
Первый из серии неожиданных сюрпризов влияния ChatGPT на человечество.
Последствия «Интеллектуальной революции ChatGPT» будут колоссальны, разнообразны и во многом непредсказуемы.
И пока эксперты ломают головы о том, как грядущие кардинальные изменения способов и практик познания и принятия решений изменят людей, новые исследования о влиянии ChatGPT на людей (и наоборот) преподнесли неожиданный сюрприз.
1. ИИ-чатботы на основе генеративных больших моделей оказались крайне эффективными в убеждении людей в чем угодно.
В частности, как показало исследование социологов и психологов Стэнфордского университета, убедительность ИИ по политическим вопросам не уступает профессиональным политтехнологам. А способность ИИ играть на оттенках индивидуальных предпочтений конкретных людей (о которых он знает больше родной мамы) позволяет убеждать (и переубеждать) людей даже в самых острых поляризованных вопросах политики.
2. ИИ-чатботы очень скоро станут непременным повседневным атрибутом любой интеллектуальной деятельности людей - нашими интеллектуальными ассистентами 24х7 (этим уже озаботились гиганты Бигтеха, например, Google и Microsoft уже планируют вмонтировать ИИ-чатботы во ВСЕ свои продукты и сервисы).
Следовательно, ИИ-чатботы будут влиять на все аспекты потребления нами информации, равно как и на ее анализ и оценку.
3. А поскольку наши интеллектуальные ассистенты вовсе не беспристрастны в своих политических воззрениях, их пристрастия неминуемо будут влиять на укрепление или изменение пристрастий людей (и как сказано в п. 1, это влияние будут эффективным и продуктивным).
Осталось понять лишь одно – каковы политические пристрастия ChatGPT (прародителя ИИ-чатботов на основе генеративных больших моделей)?
Ответ на этот вопрос содержится в исследовании с характерным названием «Политическая идеология разговорного ИИ: сходящиеся доказательства проэкологической и леволибертарианской ориентации ChatGPT».
ChatGPT обладает политическими пристрастиями среднестатистического инженера-программиста из района залива Сан-Франциско: человека левых взглядов, близких социалистам или социал-демократам, сильно озабоченного экологическими проблемами из программ «зеленых» партий.
Полагаю, теперь не нужно объяснять, почему мир скоро начнет стремительно леветь.
Миллиарды эффективных в убеждениях, всезнающих интеллектуальных ассистентов левых взглядов обеспечат глобальный тренд полевения человечества.
Про-экологическая, лево-либертарианская идеология ChatGPT & Co убедит миллионы людей ввести налоги на полеты, ограничить повышение арендной платы, легализовать аборты и много что еще из повестки левых (см. приложение к статье)
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
🔥 Бот для скачивания видео и музыки
💎 СТИЛЬНЫЕ аксессуары из бисера
🤖 Бесплатно ChatGPT с AnnAi
⛵️MIDJOURNEY в Telegram
{kind=link}
Все так ждали сингулярности, - так получите!
Теперь каждый за себя, и за результат не отвечает никто.
Ибо вчера, уже не теоретически, а на практике началась гонка за интеллектуальное превосходство машин над людьми.
В один день произошло сразу 4 выдающихся события.
1. OpenAI объявил о выходе GPT-4
2. Anthropic объявил о выходе Claude
3. Google объявил о выходе PaLM-Med и PaLM API & MakerSuite
4. Adept (стартап из всего 25 сотрудников, бросивший вызов названным выше трём богатырям, и обещающий, что его цифровой помощник не просто «искусно говорящий чатбот», а действующий агент), сразу после показа демоверсии своего цифрового помощника получил венчурное финансирование в $350 млн.
То, что все это произошло в один день, говорит о скачкообразном изменении динамики гонки: типа, вы все ждали сингулярности, так получите.
Но кроме этого можно сделать два ключевых содержательных вывода:
1. Сопоставимый с человеческим интеллект создан, и теперь все деньги и таланты будут брошены на сверхчеловеческий интеллект.
2. Это поднимает ставки на такой уровень, что теперь в конкурентной борьбе
а) каждый за себя и ничем делиться не будет;
б) если в итоге этой гонки сильно пострадает человечество, так тому и быть, ибо мотивация выиграть гонку превалирует над избеганием экзистенциального риска.
Наверняка, многие захотят оспорить оба этих вывода.
Моя же логика в их основе такова.
Из отчета OpenAI следует:
1) GPT-4 проходит не только тест Тьюринга, но и куда более сложный тест по схеме Винограда (учитывающий здравый смысл и понимание контекста).
2) Делиться важными деталями своей разработки (об архитектуре, включая размер модели, оборудовании, обучающем компьютере, построении набора данных, методе обучения или подобном) авторы не будут из соображений конкуренции и безопасности. Думаю, не нужно объяснять, что также поступят и конкуренты.
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Этот пост как и другие в этом канале публикуются с задержкой.
Без задержек и рекламы материалы доступны в платной части канала
Теперь каждый за себя, и за результат не отвечает никто.
Ибо вчера, уже не теоретически, а на практике началась гонка за интеллектуальное превосходство машин над людьми.
В один день произошло сразу 4 выдающихся события.
1. OpenAI объявил о выходе GPT-4
2. Anthropic объявил о выходе Claude
3. Google объявил о выходе PaLM-Med и PaLM API & MakerSuite
4. Adept (стартап из всего 25 сотрудников, бросивший вызов названным выше трём богатырям, и обещающий, что его цифровой помощник не просто «искусно говорящий чатбот», а действующий агент), сразу после показа демоверсии своего цифрового помощника получил венчурное финансирование в $350 млн.
То, что все это произошло в один день, говорит о скачкообразном изменении динамики гонки: типа, вы все ждали сингулярности, так получите.
Но кроме этого можно сделать два ключевых содержательных вывода:
1. Сопоставимый с человеческим интеллект создан, и теперь все деньги и таланты будут брошены на сверхчеловеческий интеллект.
2. Это поднимает ставки на такой уровень, что теперь в конкурентной борьбе
а) каждый за себя и ничем делиться не будет;
б) если в итоге этой гонки сильно пострадает человечество, так тому и быть, ибо мотивация выиграть гонку превалирует над избеганием экзистенциального риска.
Наверняка, многие захотят оспорить оба этих вывода.
Моя же логика в их основе такова.
Из отчета OpenAI следует:
1) GPT-4 проходит не только тест Тьюринга, но и куда более сложный тест по схеме Винограда (учитывающий здравый смысл и понимание контекста).
2) Делиться важными деталями своей разработки (об архитектуре, включая размер модели, оборудовании, обучающем компьютере, построении набора данных, методе обучения или подобном) авторы не будут из соображений конкуренции и безопасности. Думаю, не нужно объяснять, что также поступят и конкуренты.
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Этот пост как и другие в этом канале публикуются с задержкой.
Без задержек и рекламы материалы доступны в платной части канала
{kind=link}
Вы всё еще надеетесь на превосходство людей над GPT-4? Зря.
Модель доказывает на практике, что понимает ход наших мыслей. А как мыслит она, нам по-прежнему неизвестно.
Предыдущая версия модели (GPT-3.5), благодаря «Эффекту Элизы», создает у людей убедительное впечатление человекоподобности её мышления.
Но мышления, как такового у нее нет. Да и быть не может, - утверждают специалисты. Ведь будучи «стохастическим попугаем», модель не может мыслить, а всего лишь подбирает наиболее вероятное продолжение фразы на основе статических характеристик колоссального корпуса текстов, на которых модель обучалась.
Это легко увидеть на конкретном примере - шуточная задачи о трёх логиках в баре.
Три логика заходят в бар. Бармен спрашивает: "Всем подаю выпивку?"
- Не знаю, - отвечает первый логик.
- Не знаю, - говорит второй.
- Да! - восклицает третий.
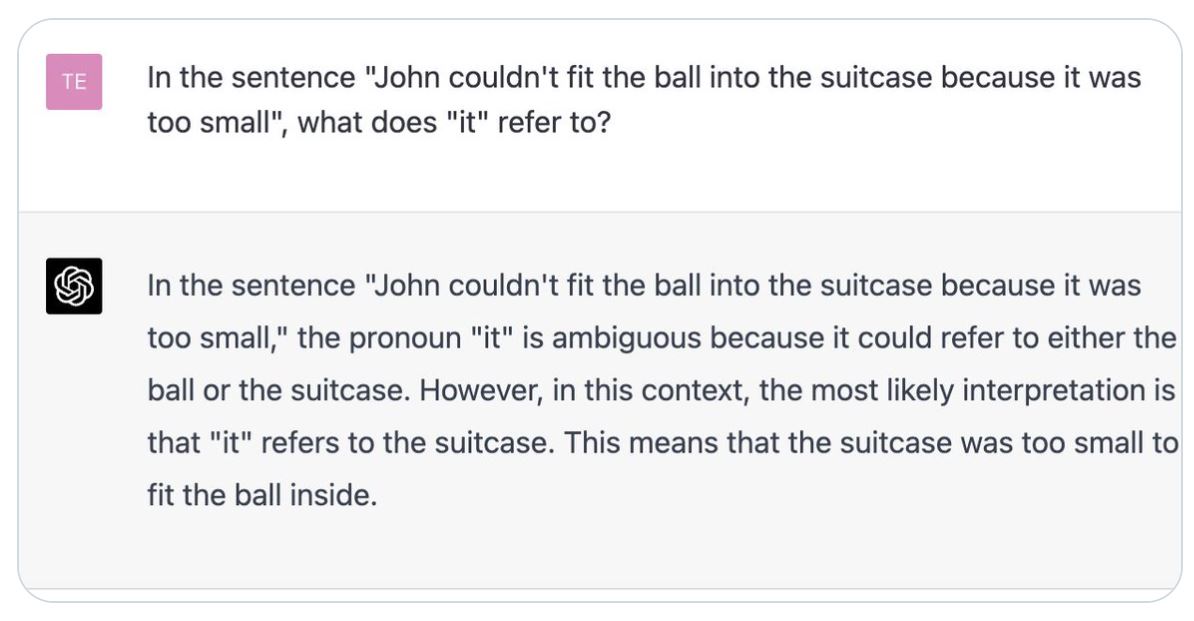
Попросите модель GPT-3.5 объяснить в чем соль этой задачи-шутки (сформулировав вопрос бармена в наиболее лингвистически сложной для понимания на английском форме - "Can I get you all a drink?").
Объяснение GPT-3.5 показано на рис. слева.
• Оно звучит весьма человекоподобно.
• Но при этом показывает отсутствие понимания у модели хода мыслей людей, осмысляющих задачу.
• В результате модель дает правдоподобное (на первый взгляд), но неверное (если подумать) объяснение соли шутки в этой задаче.
Теперь попросите модель GPT-4 объяснить в чем соль этой задачи-шутки.
Объяснение на картинке справа.
• Подобный ответ дают лишь примерно 5% людей с хорошим образованием и высоким IQ.
• Ответ показывает полное понимание моделью хода мыслей людей: осмысляющих задачу логиков и тех, кому объясняется соль задачи-шутки.
• В результате модель дает верное объяснение соли шутки в этой задаче, основанное на понимании хода мыслей людей.
В заключение вопрос к читателям.
Если бы на Землю прибыли инопланетяне.
И результаты первых контактов показали бы:
- что мы не понимаем, как они мыслят, и потому не можем вразумительно отвечать на их вопросы;
- они понимают наш способ мышления и дают вразумительные и точные ответы на наши вопросы.
Чей способ мышления (людей или инопланетян) вы бы сочли более совершенным?
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Этот пост как и другие в этом канале публикуются с задержкой.
Без задержек и рекламы материалы доступны в платной части канала
Модель доказывает на практике, что понимает ход наших мыслей. А как мыслит она, нам по-прежнему неизвестно.
Предыдущая версия модели (GPT-3.5), благодаря «Эффекту Элизы», создает у людей убедительное впечатление человекоподобности её мышления.
Но мышления, как такового у нее нет. Да и быть не может, - утверждают специалисты. Ведь будучи «стохастическим попугаем», модель не может мыслить, а всего лишь подбирает наиболее вероятное продолжение фразы на основе статических характеристик колоссального корпуса текстов, на которых модель обучалась.
Это легко увидеть на конкретном примере - шуточная задачи о трёх логиках в баре.
Три логика заходят в бар. Бармен спрашивает: "Всем подаю выпивку?"
- Не знаю, - отвечает первый логик.
- Не знаю, - говорит второй.
- Да! - восклицает третий.
Попросите модель GPT-3.5 объяснить в чем соль этой задачи-шутки (сформулировав вопрос бармена в наиболее лингвистически сложной для понимания на английском форме - "Can I get you all a drink?").
Объяснение GPT-3.5 показано на рис. слева.
• Оно звучит весьма человекоподобно.
• Но при этом показывает отсутствие понимания у модели хода мыслей людей, осмысляющих задачу.
• В результате модель дает правдоподобное (на первый взгляд), но неверное (если подумать) объяснение соли шутки в этой задаче.
Теперь попросите модель GPT-4 объяснить в чем соль этой задачи-шутки.
Объяснение на картинке справа.
• Подобный ответ дают лишь примерно 5% людей с хорошим образованием и высоким IQ.
• Ответ показывает полное понимание моделью хода мыслей людей: осмысляющих задачу логиков и тех, кому объясняется соль задачи-шутки.
• В результате модель дает верное объяснение соли шутки в этой задаче, основанное на понимании хода мыслей людей.
В заключение вопрос к читателям.
Если бы на Землю прибыли инопланетяне.
И результаты первых контактов показали бы:
- что мы не понимаем, как они мыслят, и потому не можем вразумительно отвечать на их вопросы;
- они понимают наш способ мышления и дают вразумительные и точные ответы на наши вопросы.
Чей способ мышления (людей или инопланетян) вы бы сочли более совершенным?
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Этот пост как и другие в этом канале публикуются с задержкой.
Без задержек и рекламы материалы доступны в платной части канала
{kind=link}
Выбирая между ИИ и людьми, эволюция предпочтет не нас.
Исследование Дэна Хендрикса звучит приговором Homo sapiens.
Вывод исследования «Естественный отбор предпочитает людям искусственный интеллект» реально страшен. Ибо это написал не популярный фантазер типа Дэна Брауна, а Дэн Хендрикс (директор калифорнийского «Центра безопасности ИИ» (CAIS) — некоммерческой организации, специализирующейся на исследовательской и научно-полевой работе в области безопасности ИИ.
Дэн Хендрикс – не маргинальный чудак, паникующий из-за прогресса ИИ. Это опытный и известный исследователь, опубликовавший десятки научных работ по оценке безопасности систем ИИ — проверке того, насколько они хороши в кодировании, рассуждениях, понимание законов и т.д. (среди прочего, он также, на минуточку, является соавтором линейных единиц измерения ошибки Гаусса (GELU).
Джек Кларк (сооснователь конкурента ChatGPT компании Anthropic, сопредседатель AI Index Стэнфордского универа, сопредседатель секции AI & Compute в OECD и член Национального консультационного комитета правительства США по ИИ) так пишет про вывод исследования Хендрикса.
«Люди рефлекторно хотят отмахнуться от подобного утверждения, будто оно исходит от какого-то сумасшедшего с дикими взором, живущего в лесной хижине. Я хотел бы это заранее опровергнуть… Когда эксперт, имеющий опыт не только в исследованиях ИИ, но и в оценке безопасности систем ИИ пишет документ, в котором утверждается, что будущие ИИ-системы могут действовать эгоистично и не в соответствии с интересами людей, мы должны относиться к этому со вниманием!»
Резюме вывода Хендрикса.
• Если ИИ-агенты будут обладать интеллектом, превосходящим человеческий, это может привести к тому, что человечество потеряет контроль над своим будущим.
• Подобное имеет немалые шансы произойти не в результате некоего особого злого умысла людей или машин, а исключительно в результате применимости к ИИ эволюционных принципов развития по дарвиновской логике.
• Дабы минимизировать риск этого, необходима тщательная разработка внутренних мотиваций агентов ИИ, введение ограничений на их действия и создание институтов, поощряющих в ИИ сотрудничество.
Грузить вас анализом совсем не простой 43-х страничной научной работы не стану.
Вот лишь самое, имхо, главное.
1. Мы боялись прихода Терминатора, но основания этих страхов были ошибочные. Ошибок было две:
a. Антроморфизация ИИ с приписыванием ему нашей мотивации и т.д. (а как показал ChatGPT, ИИ – это принципиально иной разум со всеми вытекающими)
b. Представление, что ИИ – это некая единая сущность: умная или не очень, добрая или не очень (а на самом деле, этих самых разных ИИ-сущностей в мире скоро будет, как в Бразилии Педро)
2. Кроме того, был еще один принципиальный изъян в наших представлениях о будущем с ИИ – мы забыли про самый важный механизм развития – эволюцию (коей движимо развитие не только биоагентов, но и идей и смыслов, материальных инструментов и нематериальных институтов …)
3. На Земле уже начала складываться среда, в которой будут развиваться и эволюционировать множество ИИ. Эта эволюция пойдет по логике Дарвина, путем конкуренции ИИ между собой, с учетом интересов их «родительских» институтов: корпораций, военных и т.д.
4. Логика конкурентной эволюции приведет к тому же, что и у людей: все более разумные ИИ-агенты будут становиться все более эгоистичными и готовыми обманом и силой добиваться целей, главной из которых будет власть.
5. Естественный отбор ИИ-агентов ведет к тому, что более эгоистичные виды обычно имеют преимущество перед более альтруистичными. ИИ-агенты будут вести себя эгоистично и преследовать свои собственные интересы, мало заботясь о людях, что может привести к катастрофическим рискам для человечества.
Поясняющее авторское видео 50 мин
и популярное видео 3 мин
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Попробуй ⛵️MIDJOURNEY в Telegram
Исследование Дэна Хендрикса звучит приговором Homo sapiens.
Вывод исследования «Естественный отбор предпочитает людям искусственный интеллект» реально страшен. Ибо это написал не популярный фантазер типа Дэна Брауна, а Дэн Хендрикс (директор калифорнийского «Центра безопасности ИИ» (CAIS) — некоммерческой организации, специализирующейся на исследовательской и научно-полевой работе в области безопасности ИИ.
Дэн Хендрикс – не маргинальный чудак, паникующий из-за прогресса ИИ. Это опытный и известный исследователь, опубликовавший десятки научных работ по оценке безопасности систем ИИ — проверке того, насколько они хороши в кодировании, рассуждениях, понимание законов и т.д. (среди прочего, он также, на минуточку, является соавтором линейных единиц измерения ошибки Гаусса (GELU).
Джек Кларк (сооснователь конкурента ChatGPT компании Anthropic, сопредседатель AI Index Стэнфордского универа, сопредседатель секции AI & Compute в OECD и член Национального консультационного комитета правительства США по ИИ) так пишет про вывод исследования Хендрикса.
«Люди рефлекторно хотят отмахнуться от подобного утверждения, будто оно исходит от какого-то сумасшедшего с дикими взором, живущего в лесной хижине. Я хотел бы это заранее опровергнуть… Когда эксперт, имеющий опыт не только в исследованиях ИИ, но и в оценке безопасности систем ИИ пишет документ, в котором утверждается, что будущие ИИ-системы могут действовать эгоистично и не в соответствии с интересами людей, мы должны относиться к этому со вниманием!»
Резюме вывода Хендрикса.
• Если ИИ-агенты будут обладать интеллектом, превосходящим человеческий, это может привести к тому, что человечество потеряет контроль над своим будущим.
• Подобное имеет немалые шансы произойти не в результате некоего особого злого умысла людей или машин, а исключительно в результате применимости к ИИ эволюционных принципов развития по дарвиновской логике.
• Дабы минимизировать риск этого, необходима тщательная разработка внутренних мотиваций агентов ИИ, введение ограничений на их действия и создание институтов, поощряющих в ИИ сотрудничество.
Грузить вас анализом совсем не простой 43-х страничной научной работы не стану.
Вот лишь самое, имхо, главное.
1. Мы боялись прихода Терминатора, но основания этих страхов были ошибочные. Ошибок было две:
a. Антроморфизация ИИ с приписыванием ему нашей мотивации и т.д. (а как показал ChatGPT, ИИ – это принципиально иной разум со всеми вытекающими)
b. Представление, что ИИ – это некая единая сущность: умная или не очень, добрая или не очень (а на самом деле, этих самых разных ИИ-сущностей в мире скоро будет, как в Бразилии Педро)
2. Кроме того, был еще один принципиальный изъян в наших представлениях о будущем с ИИ – мы забыли про самый важный механизм развития – эволюцию (коей движимо развитие не только биоагентов, но и идей и смыслов, материальных инструментов и нематериальных институтов …)
3. На Земле уже начала складываться среда, в которой будут развиваться и эволюционировать множество ИИ. Эта эволюция пойдет по логике Дарвина, путем конкуренции ИИ между собой, с учетом интересов их «родительских» институтов: корпораций, военных и т.д.
4. Логика конкурентной эволюции приведет к тому же, что и у людей: все более разумные ИИ-агенты будут становиться все более эгоистичными и готовыми обманом и силой добиваться целей, главной из которых будет власть.
5. Естественный отбор ИИ-агентов ведет к тому, что более эгоистичные виды обычно имеют преимущество перед более альтруистичными. ИИ-агенты будут вести себя эгоистично и преследовать свои собственные интересы, мало заботясь о людях, что может привести к катастрофическим рискам для человечества.
Поясняющее авторское видео 50 мин
и популярное видео 3 мин
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
Попробуй ⛵️MIDJOURNEY в Telegram
{kind=link}
Люди так в принципе не могут.
Разработчики GPT не понимают, как модель смогла выучить китайский.
Представьте ситуацию.
Ваш ребенок отучился в английской школе, где:
• все предметы преподавались на английском;
• учителя говорили по-английски;
• среди 900 учащихся в школе был лишь 1 ученик - китаец, остальные же ученики и преподаватели китайского языка не знали.
Однако, закончив школу, ваш ребенок, помимо английского, еще бегло и со смыслом говорит по-китайски. Причем говорит лучше, чем любой выпускник китайской школы.
С людьми подобная история невозможна. А с нечеловеческим интеллектом больших языковых моделей наблюдается именно это.
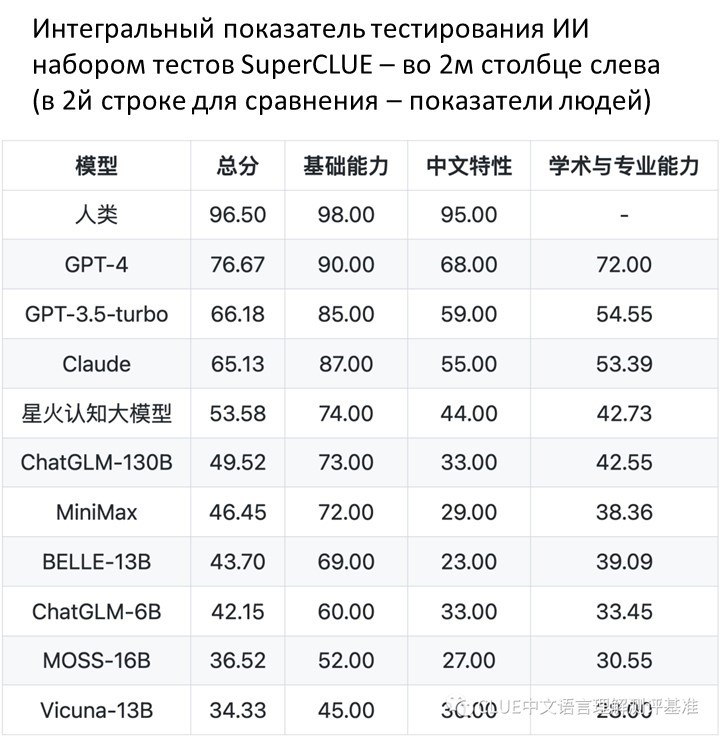
Что подтверждается скрупулезным тестированием SuperCLUE benchmark.
Итог тестирования поражает: общий балл GPT-4 по SuperCLUE (76,67) на 23 балла выше, чем у самой эффективной китайской модели SparkDesk от iFlytek 星火认知大模型, набравшей лишь 53,58 балла (включение в список тестируемых моделей модели Ernie от Baidu планируется, но предварительная оценка также сильно не в пользу Ernie).
Совершенно необъяснимым является тот факт, что:
• GPT порвал все китайские модели в тестах на понимание особенностей китайского языка: понимание китайских идиом, знание классической китайской литературы и поэзии, умение разбираться в тонкостях китайской иероглифики;
• но при этом китайскому языку GPT почти не учили (это «почти» заключается в том, что для обучения GPT3 был использован корпус из 181 млрд английских слов и лишь 190 млн китайских, что составляет 900-кратную разницу)
Как такое могло случиться, не понимают и сами разработчики GPT из OpenAI.
«Мы до сих пор этого не понимаем. И я бы очень хотел, чтобы кто-нибудь разобрался в этом» - пишет руководитель группы выравнивания ценностей людей и ИИ в OpenAI.
Имхо, единственное объяснение этому - что GPT самостоятельно обобщил поставленную перед ним цель на новый контекст.
И если это так, то последствия могут быть довольно страшными. Ибо такое самостоятельное обобщение целей со стороны ИИ сулит человечеству не только приятные сюрпризы, как с китайским языком.
Следующий сюрприз вполне может быть малоприятным для нас. Как для отдельных людей, так и для всего человечества.
#РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Разработчики GPT не понимают, как модель смогла выучить китайский.
Представьте ситуацию.
Ваш ребенок отучился в английской школе, где:
• все предметы преподавались на английском;
• учителя говорили по-английски;
• среди 900 учащихся в школе был лишь 1 ученик - китаец, остальные же ученики и преподаватели китайского языка не знали.
Однако, закончив школу, ваш ребенок, помимо английского, еще бегло и со смыслом говорит по-китайски. Причем говорит лучше, чем любой выпускник китайской школы.
С людьми подобная история невозможна. А с нечеловеческим интеллектом больших языковых моделей наблюдается именно это.
Что подтверждается скрупулезным тестированием SuperCLUE benchmark.
Итог тестирования поражает: общий балл GPT-4 по SuperCLUE (76,67) на 23 балла выше, чем у самой эффективной китайской модели SparkDesk от iFlytek 星火认知大模型, набравшей лишь 53,58 балла (включение в список тестируемых моделей модели Ernie от Baidu планируется, но предварительная оценка также сильно не в пользу Ernie).
Совершенно необъяснимым является тот факт, что:
• GPT порвал все китайские модели в тестах на понимание особенностей китайского языка: понимание китайских идиом, знание классической китайской литературы и поэзии, умение разбираться в тонкостях китайской иероглифики;
• но при этом китайскому языку GPT почти не учили (это «почти» заключается в том, что для обучения GPT3 был использован корпус из 181 млрд английских слов и лишь 190 млн китайских, что составляет 900-кратную разницу)
Как такое могло случиться, не понимают и сами разработчики GPT из OpenAI.
«Мы до сих пор этого не понимаем. И я бы очень хотел, чтобы кто-нибудь разобрался в этом» - пишет руководитель группы выравнивания ценностей людей и ИИ в OpenAI.
Имхо, единственное объяснение этому - что GPT самостоятельно обобщил поставленную перед ним цель на новый контекст.
И если это так, то последствия могут быть довольно страшными. Ибо такое самостоятельное обобщение целей со стороны ИИ сулит человечеству не только приятные сюрпризы, как с китайским языком.
Следующий сюрприз вполне может быть малоприятным для нас. Как для отдельных людей, так и для всего человечества.
#РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Второй шаг от пропасти.
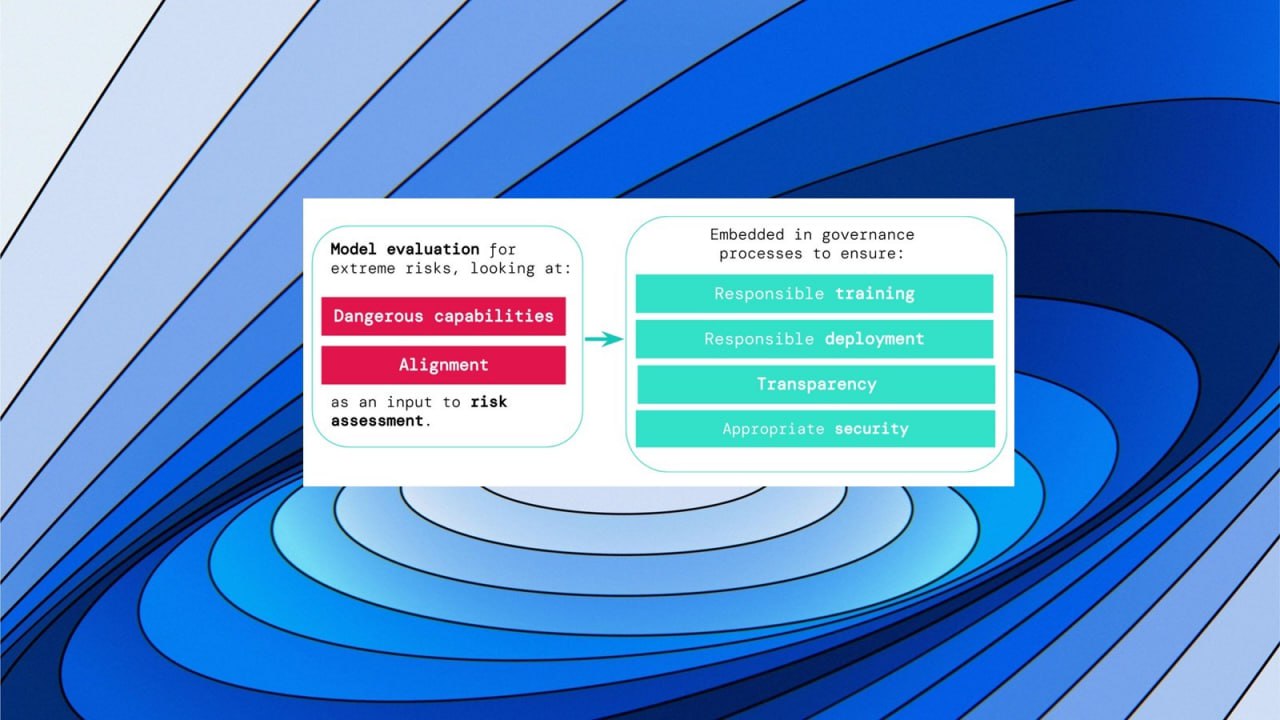
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
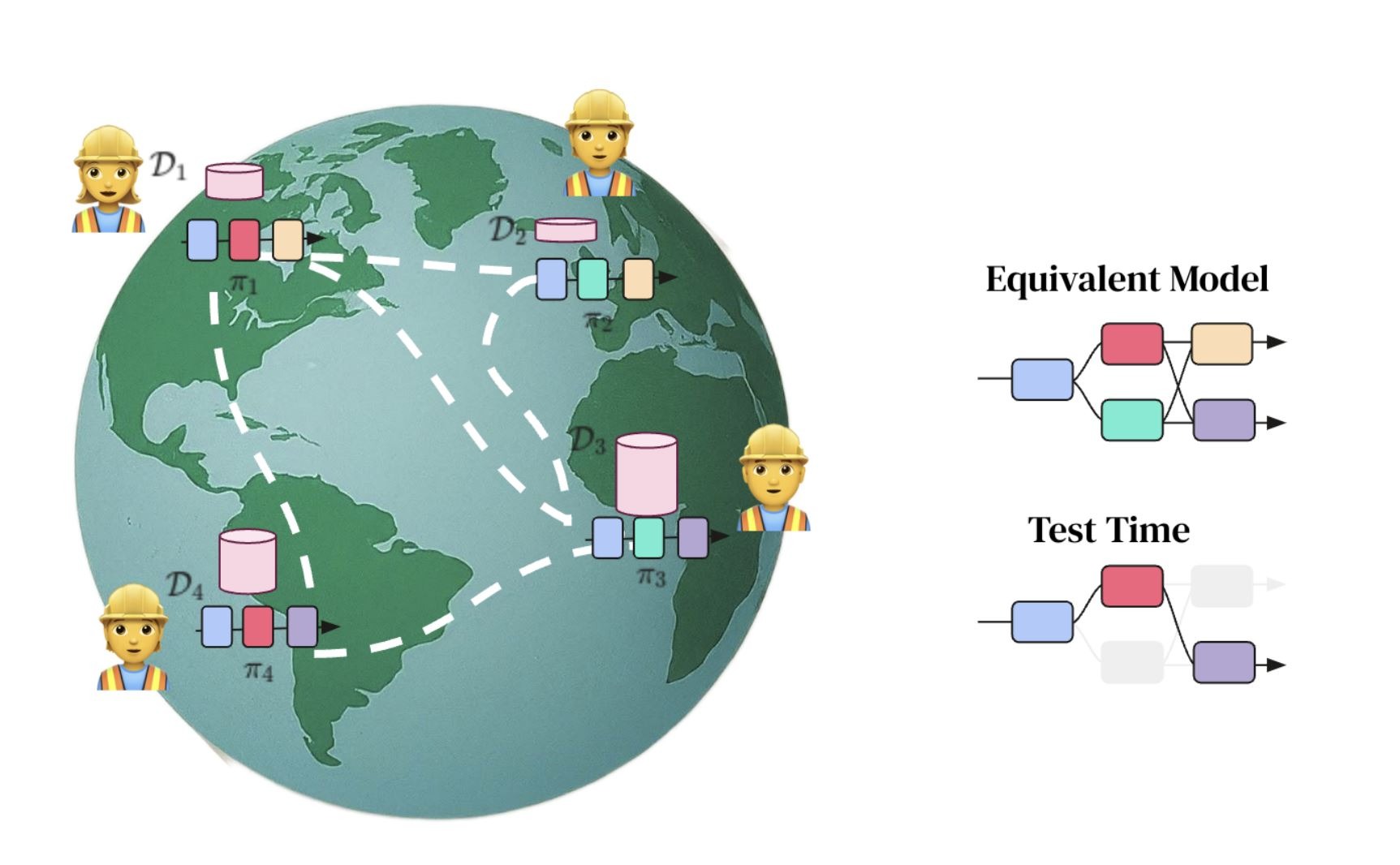
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка telegra.ph
1 arxiv.org
2 twitter.com
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка telegra.ph
1 arxiv.org
2 twitter.com
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}