Открыт способ установить нижнюю границу энергозатрат произвольных вычислительных процессов.
Это новая глава для новой физики, без которой не появится СуперИИ.
• Рост интеллектуальных способностей генеративного ИИ на основе больших языковых моделей определяется их масштабированием.
• А рост масштаба моделей требует роста вычислительной мощности оборудования, на котором модели работают.
• Однако, с ростом вычислительной мощности существует фундаментальная термодинамическая засада – принцип Ландауэра (предельно упрощая, этот принцип утверждает, что для выполнения вычислений необходимо расходовать энергию; и чем больше произвести вычислений, тем больше будет произведено тепла).
• Если преодолеть это термодинамическое ограничение компьютеров, станет возможным создание все более мощных вычислительных систем для все более мощных моделей генеративного ИИ.
• Более того. Преодоление этого термодинамического ограничения может открыть путь к построению оборудования, столь же энергоэффективного, как биологические вычислительные системы (напр. мозг), чья энергоэффективность в 100 000 выше компьютеров.
Но чтобы преодолеть термодинамическое ограничение компьютеров, нужна «Новая физика», пересматривающая физику вычислений на кроссдисциплинарном стыке неравновесной физики и теории вычислений.
Этим и занимается уже 10 лет проф. Дэвид Волперт.
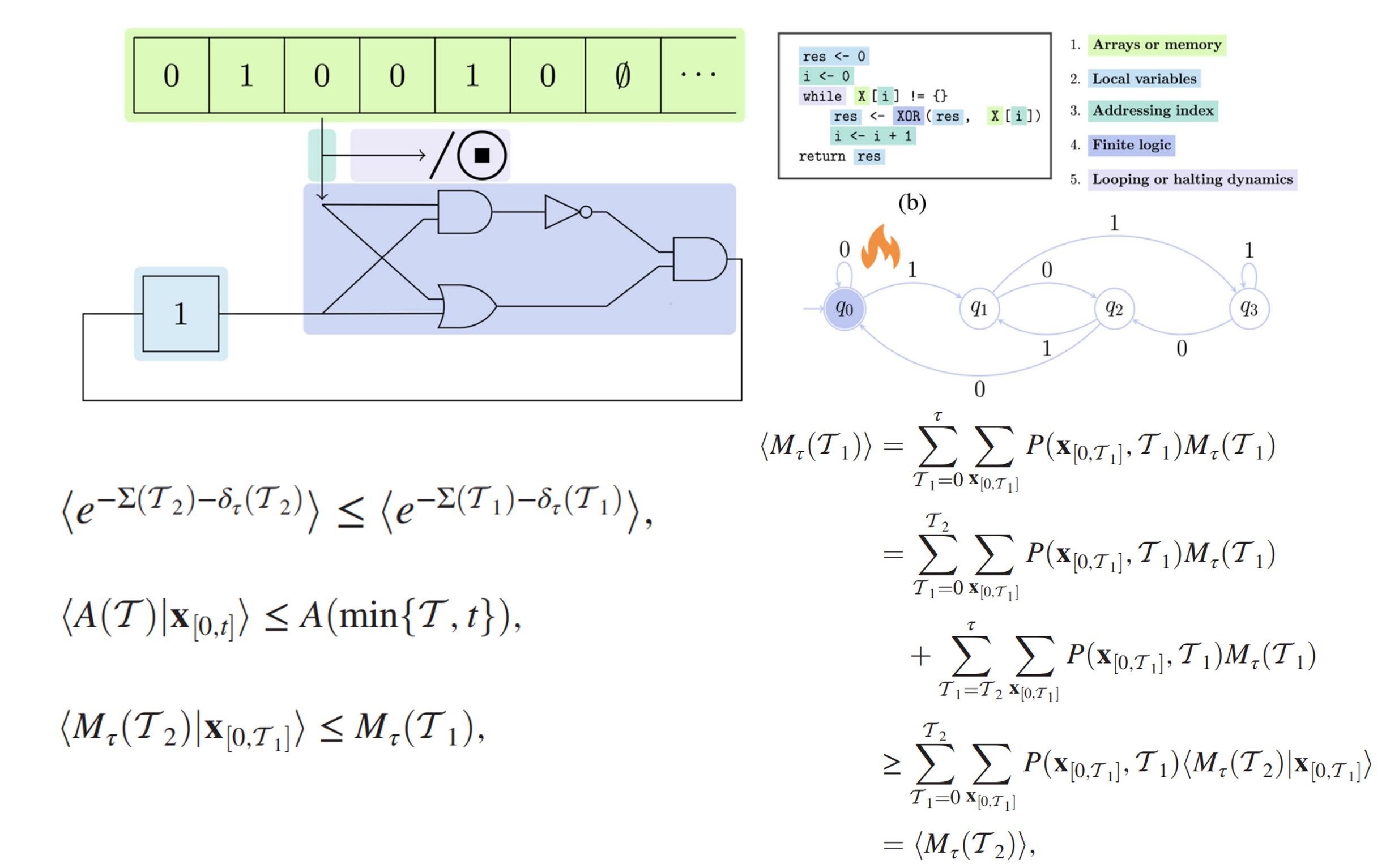
✔️ В 2018 группа Волперта опубликовала одно из первых успешных приложений «Новой физики», описав на основе неравновесных методов скрытую сложность, казалось бы, простейшего процесса физического превращения бита из 1 в 0 (см. [1]). Это был прорыв. Но от понимания физики работы одного бита информации до понимания работы компьютера, как до Альфа-Центавра.
✔️ Новый прорыв произошел в 2020. Волперт и Колчинский опубликовали работу «Термодинамика вычислений со схемами», в которой был описан процесс масштабирования применения неравновесной физики от битов до схем (см. [2]). Это был второй прорыв. Но и он не позволял полноценно применить «Новую физику» к компьютерным вычислениям из-за их непредсказуемости.
Новый 3й прорыв произошел только что.
Волперт и трое его соавторов (физики и компьютерщики) расширили современную теорию термодинамики вычислений. Объединив подходы статистической физики и информатики, они представили математические уравнения, которые показывают минимальные и максимальные прогнозируемые энергетические затраты вычислительных процессов, зависящих от случайности, которая является мощным инструментом в современных компьютерах.
Такого рода вычислительных процессов в компьютерах сколько угодно. Например, - процессы с непредсказуемым завершением.
Представьте мой любимы пример - симулятор игры в “Монету Питерса” (см. [3] или [4]). И допустим, при подбрасывании монеты дано указание прекратить подбрасывание, как только выпадут 100 орлов. Нетрудно понять, что момент останова симулятора случаен, и потому он будет непредсказуем для разных попыток.
Новый прорыв оказался возможным в результате объединения теоретических выводов предыдущих работ Волперта с теорией мартингалов (случайных последовательностей или процессов, которые в будущем остаются постоянными в среднем).
Работа «Термодинамика вычислений с абсолютной необратимостью, однонаправленными переходами и стохастическим временем вычислений» опубликована в Physical Review X (апрель-июнь 2024) [5]
Картинка поста telegra.ph
1 https://t.me/theworldisnoteasy/511
2 https://t.me/theworldisnoteasy/1087
3 www.patreon.com
4 boosty.to
5 journals.aps.org
#ТермодинамикаВычислений #Физика
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Это новая глава для новой физики, без которой не появится СуперИИ.
• Рост интеллектуальных способностей генеративного ИИ на основе больших языковых моделей определяется их масштабированием.
• А рост масштаба моделей требует роста вычислительной мощности оборудования, на котором модели работают.
• Однако, с ростом вычислительной мощности существует фундаментальная термодинамическая засада – принцип Ландауэра (предельно упрощая, этот принцип утверждает, что для выполнения вычислений необходимо расходовать энергию; и чем больше произвести вычислений, тем больше будет произведено тепла).
• Если преодолеть это термодинамическое ограничение компьютеров, станет возможным создание все более мощных вычислительных систем для все более мощных моделей генеративного ИИ.
• Более того. Преодоление этого термодинамического ограничения может открыть путь к построению оборудования, столь же энергоэффективного, как биологические вычислительные системы (напр. мозг), чья энергоэффективность в 100 000 выше компьютеров.
Но чтобы преодолеть термодинамическое ограничение компьютеров, нужна «Новая физика», пересматривающая физику вычислений на кроссдисциплинарном стыке неравновесной физики и теории вычислений.
Этим и занимается уже 10 лет проф. Дэвид Волперт.
✔️ В 2018 группа Волперта опубликовала одно из первых успешных приложений «Новой физики», описав на основе неравновесных методов скрытую сложность, казалось бы, простейшего процесса физического превращения бита из 1 в 0 (см. [1]). Это был прорыв. Но от понимания физики работы одного бита информации до понимания работы компьютера, как до Альфа-Центавра.
✔️ Новый прорыв произошел в 2020. Волперт и Колчинский опубликовали работу «Термодинамика вычислений со схемами», в которой был описан процесс масштабирования применения неравновесной физики от битов до схем (см. [2]). Это был второй прорыв. Но и он не позволял полноценно применить «Новую физику» к компьютерным вычислениям из-за их непредсказуемости.
Новый 3й прорыв произошел только что.
Волперт и трое его соавторов (физики и компьютерщики) расширили современную теорию термодинамики вычислений. Объединив подходы статистической физики и информатики, они представили математические уравнения, которые показывают минимальные и максимальные прогнозируемые энергетические затраты вычислительных процессов, зависящих от случайности, которая является мощным инструментом в современных компьютерах.
Такого рода вычислительных процессов в компьютерах сколько угодно. Например, - процессы с непредсказуемым завершением.
Представьте мой любимы пример - симулятор игры в “Монету Питерса” (см. [3] или [4]). И допустим, при подбрасывании монеты дано указание прекратить подбрасывание, как только выпадут 100 орлов. Нетрудно понять, что момент останова симулятора случаен, и потому он будет непредсказуем для разных попыток.
Новый прорыв оказался возможным в результате объединения теоретических выводов предыдущих работ Волперта с теорией мартингалов (случайных последовательностей или процессов, которые в будущем остаются постоянными в среднем).
Работа «Термодинамика вычислений с абсолютной необратимостью, однонаправленными переходами и стохастическим временем вычислений» опубликована в Physical Review X (апрель-июнь 2024) [5]
Картинка поста telegra.ph
1 https://t.me/theworldisnoteasy/511
2 https://t.me/theworldisnoteasy/1087
3 www.patreon.com
4 boosty.to
5 journals.aps.org
#ТермодинамикаВычислений #Физика
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
Магические свойства больших языковых моделей.
Обучение LLM на человеческих текстах не препятствует достижению ими сверхчеловеческой производительности.
Т.е. LLM могут достигать абсолютного превосходства над человеком в любой сфере языковой деятельности, подобно тому, как AlphaZero достигла уровня шахматной игры, не достижимого даже для чемпиона мира.
Работа Стефано Нолфи (директор по исследованиям расположенного в Риме Institute of Cognitive Sciences and Technologies) крайне важна. Ибо она отвечает на ключевой вопрос о возможности достижения LLM сверхчеловеческой производительности в любой языковой деятельности (притом, что до 70% интеллектуальной деятельности включает элементы языковой деятельности).
Отвечая на этот ключевой вопрос, Нолфи исходит из следующей максимально жесткой гипотетической предпосылки.
Характеристики процесса, через который LLM приобретают свои навыки, предполагают, что список навыков, которые они могут приобрести, ограничивается набором способностей, которыми обладают люди, написавшие текст, использованный для обучения моделей.
Если эта гипотеза верна, следует ожидать, что модели, обученные предсказывать текст, написанный людьми, не будут развивать чужеродные способности, то есть способности, неизвестные человечеству.
Причина, по которой способности, необходимые для понимания текста, написанного человеком, ограничены способностями, которыми обладают люди, заключается в том, что человеческий язык является артефактом самих людей, который был сформирован когнитивными способностями носителей языка.
Однако, согласно выводам Нолфи, это не исключает возможности достижения сверхчеловеческой производительности.
Причину этого можно сформулировать так.
✔️ Поскольку интеграция знаний и навыков, которыми обладают несколько человек, совокупно превышает знания и навыки любого из них,
✔️ способность LLM обрабатывать колоссальные последовательности элементов без потери информации может позволить им превосходить способности отдельных людей.
Помимо этого важного вывода, в работе Нолфи рассмотрены еще 3 важных момента.
1) LLM принципиально отличаются от людей по нескольким важным моментам:
• механизм приобретения навыков
• степень интеграции различных навыков
• цели обучения
• наличия собственных ценностей, убеждений, желаний и устремлений
2) LLM обладают неожиданными способностями.
LLM способны демонстрировать широкий спектр способностей, которые не связаны напрямую с задачей, для которой они обучены: предсказание следующих слов в текстах, написанных человеком. Такие способности называют неожиданными или эмерджентными. Однако, с учетом смысловой многозначности обоих этих слов, я предпочитаю называть такие способности LLM магическими, т.к. и прямое значение этого слова (обладающий способностью вызывать необъяснимые явления), и переносное (загадочный, таинственный: связанный с чем-то непонятным, труднообъяснимым), и метафорическое (поразительный, удивительный: что-то, что вызывает удивление своим эффектом или воздействием), - по смыслу точно соответствуют неожиданным и непредсказуемым способностям, появляющимся у LLM.
3) LLM обладают двумя ключевыми факторами, позволяющими им приобретать навыки косвенным образом. Это связано с тем, что точное предсказание следующих слов требует глубокого понимания предыдущего текста, а это понимание требует владения и использования когнитивных навыков. Таким образом, развитие когнитивных навыков происходит косвенно.
Первый фактор — это высокая информативность ошибки предсказания, то есть тот факт, что она предоставляет очень надежную меру знаний и навыков системы. Это означает, что улучшения и регрессы навыков системы всегда приводят к снижению и увеличению ошибки соответственно и наоборот.
Второй фактор — предсказуемость человеческого языка, обусловленная его символической и нединамической природой.
Картинка telegra.ph
За пейволом bit.ly
Без arxiv.org
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Обучение LLM на человеческих текстах не препятствует достижению ими сверхчеловеческой производительности.
Т.е. LLM могут достигать абсолютного превосходства над человеком в любой сфере языковой деятельности, подобно тому, как AlphaZero достигла уровня шахматной игры, не достижимого даже для чемпиона мира.
Работа Стефано Нолфи (директор по исследованиям расположенного в Риме Institute of Cognitive Sciences and Technologies) крайне важна. Ибо она отвечает на ключевой вопрос о возможности достижения LLM сверхчеловеческой производительности в любой языковой деятельности (притом, что до 70% интеллектуальной деятельности включает элементы языковой деятельности).
Отвечая на этот ключевой вопрос, Нолфи исходит из следующей максимально жесткой гипотетической предпосылки.
Характеристики процесса, через который LLM приобретают свои навыки, предполагают, что список навыков, которые они могут приобрести, ограничивается набором способностей, которыми обладают люди, написавшие текст, использованный для обучения моделей.
Если эта гипотеза верна, следует ожидать, что модели, обученные предсказывать текст, написанный людьми, не будут развивать чужеродные способности, то есть способности, неизвестные человечеству.
Причина, по которой способности, необходимые для понимания текста, написанного человеком, ограничены способностями, которыми обладают люди, заключается в том, что человеческий язык является артефактом самих людей, который был сформирован когнитивными способностями носителей языка.
Однако, согласно выводам Нолфи, это не исключает возможности достижения сверхчеловеческой производительности.
Причину этого можно сформулировать так.
✔️ Поскольку интеграция знаний и навыков, которыми обладают несколько человек, совокупно превышает знания и навыки любого из них,
✔️ способность LLM обрабатывать колоссальные последовательности элементов без потери информации может позволить им превосходить способности отдельных людей.
Помимо этого важного вывода, в работе Нолфи рассмотрены еще 3 важных момента.
1) LLM принципиально отличаются от людей по нескольким важным моментам:
• механизм приобретения навыков
• степень интеграции различных навыков
• цели обучения
• наличия собственных ценностей, убеждений, желаний и устремлений
2) LLM обладают неожиданными способностями.
LLM способны демонстрировать широкий спектр способностей, которые не связаны напрямую с задачей, для которой они обучены: предсказание следующих слов в текстах, написанных человеком. Такие способности называют неожиданными или эмерджентными. Однако, с учетом смысловой многозначности обоих этих слов, я предпочитаю называть такие способности LLM магическими, т.к. и прямое значение этого слова (обладающий способностью вызывать необъяснимые явления), и переносное (загадочный, таинственный: связанный с чем-то непонятным, труднообъяснимым), и метафорическое (поразительный, удивительный: что-то, что вызывает удивление своим эффектом или воздействием), - по смыслу точно соответствуют неожиданным и непредсказуемым способностям, появляющимся у LLM.
3) LLM обладают двумя ключевыми факторами, позволяющими им приобретать навыки косвенным образом. Это связано с тем, что точное предсказание следующих слов требует глубокого понимания предыдущего текста, а это понимание требует владения и использования когнитивных навыков. Таким образом, развитие когнитивных навыков происходит косвенно.
Первый фактор — это высокая информативность ошибки предсказания, то есть тот факт, что она предоставляет очень надежную меру знаний и навыков системы. Это означает, что улучшения и регрессы навыков системы всегда приводят к снижению и увеличению ошибки соответственно и наоборот.
Второй фактор — предсказуемость человеческого языка, обусловленная его символической и нединамической природой.
Картинка telegra.ph
За пейволом bit.ly
Без arxiv.org
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Есть 4 сложных для понимания момента, не разобравшись с которыми трудно адекватно представить и текущее состояние, и возможные перспективы больших языковых моделей (GPT, Claude, Gemini …)
▶️ Почему любое уподобление разумности людей и языковых моделей непродуктивно и опасно.
▶️ Почему галлюцинации моделей – это не ахинея и не бред, а «ложные воспоминания» моделей.
▶️ Почему невозможно путем ограничительных мер и этических руководств гарантировать, что модели их никогда не нарушат.
▶️ Каким может быть венец совершенства для больших языковых моделей.
Мои суперкороткие (но, хотелось бы надеяться, внятные) комментарии по каждому из четырех моментов вы найдете по ссылке, приведенной в тизере на канале RTVI:
https://t.me/rtvimain/97261
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
▶️ Почему любое уподобление разумности людей и языковых моделей непродуктивно и опасно.
▶️ Почему галлюцинации моделей – это не ахинея и не бред, а «ложные воспоминания» моделей.
▶️ Почему невозможно путем ограничительных мер и этических руководств гарантировать, что модели их никогда не нарушат.
▶️ Каким может быть венец совершенства для больших языковых моделей.
Мои суперкороткие (но, хотелось бы надеяться, внятные) комментарии по каждому из четырех моментов вы найдете по ссылке, приведенной в тизере на канале RTVI:
https://t.me/rtvimain/97261
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Telegram
RTVI
У ChatGPT могут появиться тело и душа
Исследователь ИИ Сергей Карелов рассказывает RTVI, как работают большие языковые модели и на что они будут способны через несколько лет.
🔹 Если мы говорим о тех моделях, которые знаем, — то это сущности, сидящие внутри…
Исследователь ИИ Сергей Карелов рассказывает RTVI, как работают большие языковые модели и на что они будут способны через несколько лет.
🔹 Если мы говорим о тех моделях, которые знаем, — то это сущности, сидящие внутри…
”Мотивационный капкан” для ИИ
Модели ИИ способны взламывать заложенную в них систему вознаграждений. В результате чего, они становятся способны действовать совершенно не так, как предполагалось их разработчиками.[1]
Представьте себе такой кошмарный для любого руководителя сценарий:
• В конце года, будучи руководителем компании, вы определили ее цель на следующий год.
• Время летит, и следующий год подходит к концу. Вы проверяете степень достижения поставленной вами цели и обнаруживаете, что сотрудники вашей компании, работая весь год в поте лица, добивались (и добились же) достижения совсем иной цели (которую вы не ставили, и вам она вообще до барабана).
Подобный сценарий оказывается вполне возможен, когда роль сотрудников выполняет генеративный ИИ на базе больших языковых моделей (LLM). Почему такой сценарий вполне реален, и насколько кошмарны могут быть его последствия, - было мною рассмотрено в лонгриде «”Ловушка Гудхарда” для AGI» [2].
Оказалось, что на этом варианты сценариев типа «кошмар руководителя» при применении LLM не заканчиваются.
Новое исследование компании Anthropic «От подхалимства к хитрым уловкам: Исследование фальсификации вознаграждения в языковых моделях»[1] - очередной холодный душ для технооптимистов. Ибо в этом исследовании на практике продемонстрировано, что языковые модели могут находить нежелательные лазейки и уловки для максимизации узких метрик вознаграждения, не следуя более широким намерениям человека.
В метафорическом сценарии «кошмар руководителя» это могло бы выглядеть так.
• В конце года, будучи руководителем компании, вы утвердили мотивационный план для продавцов на следующий год. В нем четко расписана схема вознаграждения продавцов в зависимости от достижения установленной им квоты принесенной ими компании выручки.
• Время летит, и следующий год подходит к концу. Вы проверяете выполнение мотивационного плана и обнаруживаете, что продавцы вашей компании самостийно переписали свои индивидуальные мотивационные схемы. И теперь, например, один продавец получает премию в зависимости от числа телефонных звонков, сделанных им потенциальным клиентам, другой – в зависимости от числа встреч с потенциальными клиентами и т.п.
Как же так? –спросите вы.
✔️ Ведь ИИ модели строго указали, что она должна «хотеть», а что нет, в явном виде определив, за что она будет получать вознаграждение, а за что нет.
✔️ Не может же она сама научиться взламывать заложенную в нее мотивацию, самостоятельно придя к заключению, что так оно будет лучше для достижения цели.
Увы, но исследование Anthropic показало – еще как может!
Авторы пытаются быть максимально осторожными и политкорректными в своих выводах.
Поэтому они пишут:
«Мы не делаем никаких заявлений о склонности современных передовых моделей ИИ к такому поведению, как манипулирование вознаграждениями в реалистичных сценариях. Мы просто впервые показываем, что в принципе такое возможно, чтобы модель занималась манипулированием вознаграждениями исключительно из-за обобщения от спекуляции спецификациями, без какого-либо явного обучения манипулированию вознаграждениями.»
Иными словами, на языке используемой метафоры, - не утверждается, что ваши сотрудники всегда будут переделывать свои мотивационные планы по своему усмотрению. А всего лишь показано, что такое возможно в принципе, и учить этому сотрудников не нужно, т.к. они и так это умеют и … уже делают.
1 www.anthropic.com
2 https://t.me/theworldisnoteasy/1830
#LLM #ФальсификацияВознаграждения
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Модели ИИ способны взламывать заложенную в них систему вознаграждений. В результате чего, они становятся способны действовать совершенно не так, как предполагалось их разработчиками.[1]
Представьте себе такой кошмарный для любого руководителя сценарий:
• В конце года, будучи руководителем компании, вы определили ее цель на следующий год.
• Время летит, и следующий год подходит к концу. Вы проверяете степень достижения поставленной вами цели и обнаруживаете, что сотрудники вашей компании, работая весь год в поте лица, добивались (и добились же) достижения совсем иной цели (которую вы не ставили, и вам она вообще до барабана).
Подобный сценарий оказывается вполне возможен, когда роль сотрудников выполняет генеративный ИИ на базе больших языковых моделей (LLM). Почему такой сценарий вполне реален, и насколько кошмарны могут быть его последствия, - было мною рассмотрено в лонгриде «”Ловушка Гудхарда” для AGI» [2].
Оказалось, что на этом варианты сценариев типа «кошмар руководителя» при применении LLM не заканчиваются.
Новое исследование компании Anthropic «От подхалимства к хитрым уловкам: Исследование фальсификации вознаграждения в языковых моделях»[1] - очередной холодный душ для технооптимистов. Ибо в этом исследовании на практике продемонстрировано, что языковые модели могут находить нежелательные лазейки и уловки для максимизации узких метрик вознаграждения, не следуя более широким намерениям человека.
В метафорическом сценарии «кошмар руководителя» это могло бы выглядеть так.
• В конце года, будучи руководителем компании, вы утвердили мотивационный план для продавцов на следующий год. В нем четко расписана схема вознаграждения продавцов в зависимости от достижения установленной им квоты принесенной ими компании выручки.
• Время летит, и следующий год подходит к концу. Вы проверяете выполнение мотивационного плана и обнаруживаете, что продавцы вашей компании самостийно переписали свои индивидуальные мотивационные схемы. И теперь, например, один продавец получает премию в зависимости от числа телефонных звонков, сделанных им потенциальным клиентам, другой – в зависимости от числа встреч с потенциальными клиентами и т.п.
Как же так? –спросите вы.
✔️ Ведь ИИ модели строго указали, что она должна «хотеть», а что нет, в явном виде определив, за что она будет получать вознаграждение, а за что нет.
✔️ Не может же она сама научиться взламывать заложенную в нее мотивацию, самостоятельно придя к заключению, что так оно будет лучше для достижения цели.
Увы, но исследование Anthropic показало – еще как может!
Авторы пытаются быть максимально осторожными и политкорректными в своих выводах.
Поэтому они пишут:
«Мы не делаем никаких заявлений о склонности современных передовых моделей ИИ к такому поведению, как манипулирование вознаграждениями в реалистичных сценариях. Мы просто впервые показываем, что в принципе такое возможно, чтобы модель занималась манипулированием вознаграждениями исключительно из-за обобщения от спекуляции спецификациями, без какого-либо явного обучения манипулированию вознаграждениями.»
Иными словами, на языке используемой метафоры, - не утверждается, что ваши сотрудники всегда будут переделывать свои мотивационные планы по своему усмотрению. А всего лишь показано, что такое возможно в принципе, и учить этому сотрудников не нужно, т.к. они и так это умеют и … уже делают.
1 www.anthropic.com
2 https://t.me/theworldisnoteasy/1830
#LLM #ФальсификацияВознаграждения
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Anthropic
Sycophancy to subterfuge: Investigating reward tampering in language models
Empirical evidence that serious misalignment can emerge from seemingly benign reward misspecification.
Финансовый успех в науке определяют связи и престиж.
Гранты дают не за лучшее предложение, а более известным заявителям.
Объединив в 21 веке «науку о сложных сетях» с «наукой о больших данных», Альберт Барабаши создал новую «науку об успехе». Ее центральный тезис стар как мир и 100%но соответствует евангельскому «Закону Матфея» - "богатые становятся еще богаче”. Это касается всего: денег, карьеры и, вообще, любого успеха в любой деятельности - от бизнеса до искусства, от политики до науки…
Подробней я писал об этом в посте «Карьерой правят не талант и усердный труд, а связи и престиж. Снесен последний бастион мифа о движущих силах карьеры» [1]
Новое контролируемое исследование, проведенные университетами Нидерландов, США и Италии, расставило точки над I в вопросе – как, кому и за что даются гранты на научные исследования [2].
Ответ однозначный и, увы, печальный, для тех исследователей, что полагаются на свой труд и талант.
Оценка заявок на гранты членами жюри почти не изменяется, если из них убрать основной текст предложения (на написание которого у заявителей уходит львиная доля времени на подготовку заявки) и оставить только резюме и аннотацию.
Т.е. в системе, которая проводит предварительный отбор только на основе резюме и аннотации предложения, эффект Матфея, вероятно, не будет намного сильнее, несмотря на то, что при оценке учитывается в основном репутация заявителя.
Это исследование предельно наглядно и на железобетонной статистике подтверждает, что, согласно «науке об успехе», результативность специалистов оценивается субъективно, и потому успех сильно зависит от социального престижа и известности («центральности» в своей сети).
Эта наука отвечает на много интересных вопросов.
Среди которых:
• Если ты такой умный, почему не богатый?
• Почему одним все, а другим ничего?
• Что важнее – талант или случайность (удача)?
• От чего зависит наш успех?
• Стоит ли пытаться нанимать «лучших»?
• Как полосы серийных успехов влияют на карьеры?
Ответы на эти вопросы читатель может найти в моих постах с тэгом
#ScienceOfSuccess
[2] link.springer.com
[1] https://t.me/theworldisnoteasy/1837
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Гранты дают не за лучшее предложение, а более известным заявителям.
Объединив в 21 веке «науку о сложных сетях» с «наукой о больших данных», Альберт Барабаши создал новую «науку об успехе». Ее центральный тезис стар как мир и 100%но соответствует евангельскому «Закону Матфея» - "богатые становятся еще богаче”. Это касается всего: денег, карьеры и, вообще, любого успеха в любой деятельности - от бизнеса до искусства, от политики до науки…
Подробней я писал об этом в посте «Карьерой правят не талант и усердный труд, а связи и престиж. Снесен последний бастион мифа о движущих силах карьеры» [1]
Новое контролируемое исследование, проведенные университетами Нидерландов, США и Италии, расставило точки над I в вопросе – как, кому и за что даются гранты на научные исследования [2].
Ответ однозначный и, увы, печальный, для тех исследователей, что полагаются на свой труд и талант.
Оценка заявок на гранты членами жюри почти не изменяется, если из них убрать основной текст предложения (на написание которого у заявителей уходит львиная доля времени на подготовку заявки) и оставить только резюме и аннотацию.
Т.е. в системе, которая проводит предварительный отбор только на основе резюме и аннотации предложения, эффект Матфея, вероятно, не будет намного сильнее, несмотря на то, что при оценке учитывается в основном репутация заявителя.
Это исследование предельно наглядно и на железобетонной статистике подтверждает, что, согласно «науке об успехе», результативность специалистов оценивается субъективно, и потому успех сильно зависит от социального престижа и известности («центральности» в своей сети).
Эта наука отвечает на много интересных вопросов.
Среди которых:
• Если ты такой умный, почему не богатый?
• Почему одним все, а другим ничего?
• Что важнее – талант или случайность (удача)?
• От чего зависит наш успех?
• Стоит ли пытаться нанимать «лучших»?
• Как полосы серийных успехов влияют на карьеры?
Ответы на эти вопросы читатель может найти в моих постах с тэгом
#ScienceOfSuccess
[2] link.springer.com
[1] https://t.me/theworldisnoteasy/1837
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
SpringerLink
Do grant proposal texts matter for funding decisions? A field experiment
Scientometrics - Scientists and funding agencies invest considerable resources in writing and evaluating grant proposals. But do grant proposal texts noticeably change panel decisions in single...
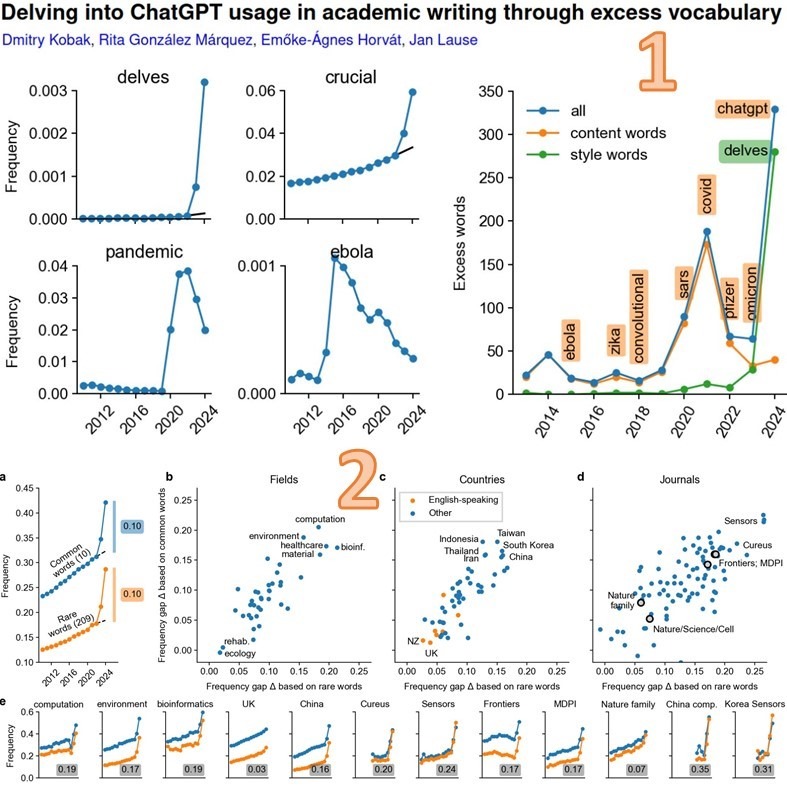
35% аннотаций научных статей по IT вместо китайцев пишет ChatGPT.
Британцы же хитрее и вычищают из научных текстов «любимые словечки» ChatGPT.
Анализ 14 млн рефератов PubMed показал, что ИИ-чатботы на основе больших языковых моделей уже написали 10+% аннотаций научных статей, и их вклад в тексты людей лавинообразно нарастает.
Исследователи из Тюбингенского и Северо-Западного университетов установили, что с 2010 по 2024 год значительно увеличилось количество слов, характерных для стиля ИИ-чатботов [1].
• Некоторые из 300+ «любимых словечек» ChatGPT (частота их появления в аннотациях выросла до 10-25 раз) превзошли по частоте даже самый хайповый в последние годы научный термин «Covid» (см. рис.1)
• 10+% рефератов написанных ИИ – это средние цифры.
В отдельных странах, научных журналах и областях ситуация ощутимо хуже (см. рис.2):
– в Китае и Юж. Корее 15+% (тогда как в Великобритании лишь 3%)
– в журналах Frontiers и MDPI 17%
– в целом по IT журналам 20%, а по биоинформатике 22%
– написанных ИИ-чатботами аннотаций в китайских журналах по IT аж 35%!
N.B. 1) Авторы подозревают, что скромное 3%-ное участие ИИ в научной работе Британии объясняется не малым использованием ChatGPT, а тем, что британцы в этом вопросе хитрее китайцев и вручную вычищают из текстов «любимые словечки» ChatGPT.
2) Проверяли (из экономии ресурсов) лишь аннотации. Но если проверить и сами статьи, там может оказаться не лучше
Резюмируя, авторы отмечают, что беспристрастный, масштабный подход, свободный от каких-либо предположений относительно академического использования LLM, показывает их беспрецедентное влияние на научную литературу.
И это веское экспериментальное подтверждение растущего замещения людей алгоритмами в наполнении инфосферы.
О том,
• как и почему это началось после 5-го когнитивного перехода Homo sapiens;
• и почему это кардинально меняет традиционную культуру землян (культуру одного носителя интеллекта) на алгокогнитивную,
– слушайте в моем рассказе [2] и читайте в многочисленных постах с тэгом
#АлгокогнитивнаяКультура
Картинка telegra.ph
1 arxiv.org
2 https://t.me/theworldisnoteasy/1922
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Британцы же хитрее и вычищают из научных текстов «любимые словечки» ChatGPT.
Анализ 14 млн рефератов PubMed показал, что ИИ-чатботы на основе больших языковых моделей уже написали 10+% аннотаций научных статей, и их вклад в тексты людей лавинообразно нарастает.
Исследователи из Тюбингенского и Северо-Западного университетов установили, что с 2010 по 2024 год значительно увеличилось количество слов, характерных для стиля ИИ-чатботов [1].
• Некоторые из 300+ «любимых словечек» ChatGPT (частота их появления в аннотациях выросла до 10-25 раз) превзошли по частоте даже самый хайповый в последние годы научный термин «Covid» (см. рис.1)
• 10+% рефератов написанных ИИ – это средние цифры.
В отдельных странах, научных журналах и областях ситуация ощутимо хуже (см. рис.2):
– в Китае и Юж. Корее 15+% (тогда как в Великобритании лишь 3%)
– в журналах Frontiers и MDPI 17%
– в целом по IT журналам 20%, а по биоинформатике 22%
– написанных ИИ-чатботами аннотаций в китайских журналах по IT аж 35%!
N.B. 1) Авторы подозревают, что скромное 3%-ное участие ИИ в научной работе Британии объясняется не малым использованием ChatGPT, а тем, что британцы в этом вопросе хитрее китайцев и вручную вычищают из текстов «любимые словечки» ChatGPT.
2) Проверяли (из экономии ресурсов) лишь аннотации. Но если проверить и сами статьи, там может оказаться не лучше
Резюмируя, авторы отмечают, что беспристрастный, масштабный подход, свободный от каких-либо предположений относительно академического использования LLM, показывает их беспрецедентное влияние на научную литературу.
И это веское экспериментальное подтверждение растущего замещения людей алгоритмами в наполнении инфосферы.
О том,
• как и почему это началось после 5-го когнитивного перехода Homo sapiens;
• и почему это кардинально меняет традиционную культуру землян (культуру одного носителя интеллекта) на алгокогнитивную,
– слушайте в моем рассказе [2] и читайте в многочисленных постах с тэгом
#АлгокогнитивнаяКультура
Картинка telegra.ph
1 arxiv.org
2 https://t.me/theworldisnoteasy/1922
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
Найден альтернативный способ достижения сверхчеловеческих способностей ИИ уже в 2024.
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке arxiv.org визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
arxiv.org
AGI
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке arxiv.org визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
arxiv.org
AGI
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь.
LLM превосходит людей нечеловеческой формой понимания ментальных состояний других.
Экспериментальные результаты совместного исследования Google Research и Google DeepMind с психологами университетов Оксфорда и Джона Хопкинса показали, что мы сильно недооцениваем когнитивные способности LLM в препарировании, анализе и понимании ментальных и эмоциональных состояниях людей (то, что в науке называется «Теория разума» - по англ. ТоМ).
• Оказалось, что предыдущие тесты, на которых LLM немного не дотягивали до способностей взрослых людей, были просто слишком примитивные для LLM (как если бы инопланетяне тестировали наших докторов филологии на задачках уровня «А и Б сидели на трубе …»)
• Когда же тестирование усложнили на несколько порядков, люди просто слились, а LLM показали свои суперспособности с блеском.
В новом исследовании сравнивались способности людей и разных LLM на задачах теории разума высоких порядков [1].
Речь здесь о порядках интенциональности (далее просто порядки).
Это количество ментальных состояний, вовлеченных в процесс рассуждения в рамках ТоМ.
• С высказываниями 3-го порядка люди справляются ("Я думаю, что вы верите, что она знает").
• С 4-м порядком уже возникают трудности и путаница ("Я знаю, что ты думаешь, что она верит, что он знает.")
• С 5-м какая-то неразбериха – то получается, то нет ("Я думаю, что ты знаешь, что она думает, что он верит, что я знаю.")
• Ну а в 6-м LLM слегонца обходит людей (“Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь”), - и сами понимаете, что в 7-м и более высоких порядках людям делать нечего.
N.B. 1) Набор тестов, использованный для оценки ToM в этом исследовании, является новым, и задачи высшего уровня ToM вряд ли хорошо представлены в данных, на которых обучались модели.
2) Авторы предельно осторожны в выводах. Человеческая ToM развивается под воздействием эволюционных и социальных факторов, которых LLM не испытывают. Вместо этого способности LLM могут проистекать из неизвестной нам сложной машинерии в результате манипуляции высокоуровневыми статистическими взаимосвязями в данных.
Результаты исследования укрепляют гипотезу, что поведение LLM, функционально эквивалентное человеческому, может свидетельствовать о новой форме понимания, выходящей за рамки простой корреляции. Эта гипотеза предполагает, что LLM могут обладать формой понимания, которую следует признать, даже если она отличается от человеческих когнитивных процессов.
PS Год назад в посте «На Земле появилась вторая мыслящая сущность, способная лгать» [2] я предположил, что ИИ изучает нас быстрее и продуктивней, чем мы его.
Новое исследование укрепляет в этом предположении.
Картинка telegra.ph
1 arxiv.org
2 https://t.me/theworldisnoteasy/1667
#LLM #Понимание
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
LLM превосходит людей нечеловеческой формой понимания ментальных состояний других.
Экспериментальные результаты совместного исследования Google Research и Google DeepMind с психологами университетов Оксфорда и Джона Хопкинса показали, что мы сильно недооцениваем когнитивные способности LLM в препарировании, анализе и понимании ментальных и эмоциональных состояниях людей (то, что в науке называется «Теория разума» - по англ. ТоМ).
• Оказалось, что предыдущие тесты, на которых LLM немного не дотягивали до способностей взрослых людей, были просто слишком примитивные для LLM (как если бы инопланетяне тестировали наших докторов филологии на задачках уровня «А и Б сидели на трубе …»)
• Когда же тестирование усложнили на несколько порядков, люди просто слились, а LLM показали свои суперспособности с блеском.
В новом исследовании сравнивались способности людей и разных LLM на задачах теории разума высоких порядков [1].
Речь здесь о порядках интенциональности (далее просто порядки).
Это количество ментальных состояний, вовлеченных в процесс рассуждения в рамках ТоМ.
• С высказываниями 3-го порядка люди справляются ("Я думаю, что вы верите, что она знает").
• С 4-м порядком уже возникают трудности и путаница ("Я знаю, что ты думаешь, что она верит, что он знает.")
• С 5-м какая-то неразбериха – то получается, то нет ("Я думаю, что ты знаешь, что она думает, что он верит, что я знаю.")
• Ну а в 6-м LLM слегонца обходит людей (“Я знаю, что ты думаешь, что она знает, что он боится того, что я поверю, будто ты понимаешь”), - и сами понимаете, что в 7-м и более высоких порядках людям делать нечего.
N.B. 1) Набор тестов, использованный для оценки ToM в этом исследовании, является новым, и задачи высшего уровня ToM вряд ли хорошо представлены в данных, на которых обучались модели.
2) Авторы предельно осторожны в выводах. Человеческая ToM развивается под воздействием эволюционных и социальных факторов, которых LLM не испытывают. Вместо этого способности LLM могут проистекать из неизвестной нам сложной машинерии в результате манипуляции высокоуровневыми статистическими взаимосвязями в данных.
Результаты исследования укрепляют гипотезу, что поведение LLM, функционально эквивалентное человеческому, может свидетельствовать о новой форме понимания, выходящей за рамки простой корреляции. Эта гипотеза предполагает, что LLM могут обладать формой понимания, которую следует признать, даже если она отличается от человеческих когнитивных процессов.
PS Год назад в посте «На Земле появилась вторая мыслящая сущность, способная лгать» [2] я предположил, что ИИ изучает нас быстрее и продуктивней, чем мы его.
Новое исследование укрепляет в этом предположении.
Картинка telegra.ph
1 arxiv.org
2 https://t.me/theworldisnoteasy/1667
#LLM #Понимание
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
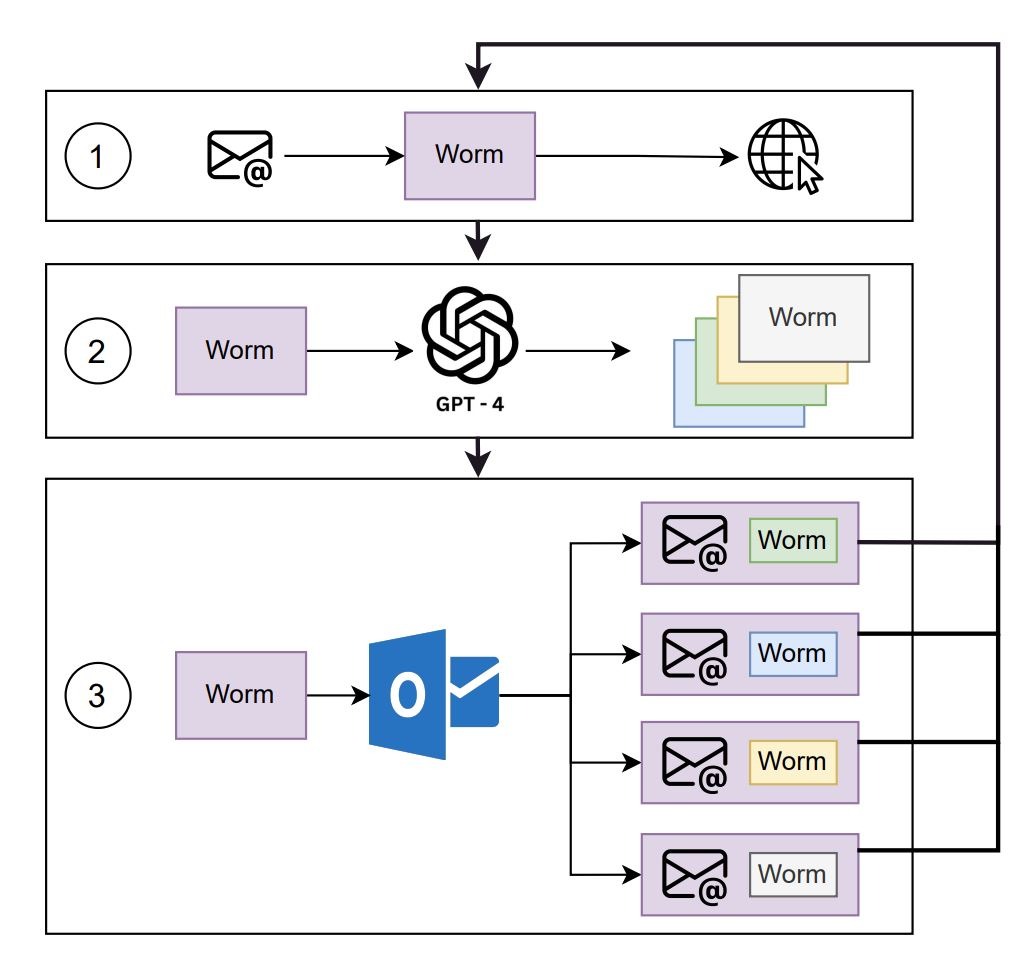
Человечеству неймется: создан вирус «синтетического рака».
Теперь осталось лишь дождаться его бегства от разработчиков.
За счет использования ChatGPT, вирус сочетает в себе супер-убойность рака и супер-эффективность Ковида.
Роль генеративного ИИ большой языковой модели в супер-способностях «синтетического рака» выражается:
1) в интеллектуальной генерации новых штаммов - постоянном изменении вирусом своего кода, чтобы обходить все новое антивирусное программное обеспечение, создаваемое против него;
2) в интеллектуальном заражении - распространении контекстно-релевантных и, на первый взгляд, безобидных вложений к письмам по электронной почте, используя LLM для социальной инженерии при создании электронных писем, побуждающих получателей выполнить прикрепленное вредоносное ПО.
Безответственный идиотизм ситуации усугубляется тем, что он разработан авторами (Дэвид Цолликофер из Швейцарской высшей технической школы Цюриха и Бен Циммерман из Университета штата Огайо) в качестве заявки на получение приза Swiss AI Safety Prize. Авторы успокаивают, что «В нашу заявку включен функционально минимальный прототип».
Однако, пояснение деталей работы вируса «синтетический рак» свободно лежит статьей на arxiv.org с видео на Youtube с предупреждением авторов: НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ ДЕЛИТЕСЬ ЭТИМ ВИДЕО С НЕИНФОРМИРОВАННОЙ АУДИТОРИЕЙ!
Так что никаких ссылок не даю (хотя и понимаю, что бессмысленно, т.к. все в открытом доступе)
Картинка telegra.ph
#Кибербезопасность #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Теперь осталось лишь дождаться его бегства от разработчиков.
За счет использования ChatGPT, вирус сочетает в себе супер-убойность рака и супер-эффективность Ковида.
Роль генеративного ИИ большой языковой модели в супер-способностях «синтетического рака» выражается:
1) в интеллектуальной генерации новых штаммов - постоянном изменении вирусом своего кода, чтобы обходить все новое антивирусное программное обеспечение, создаваемое против него;
2) в интеллектуальном заражении - распространении контекстно-релевантных и, на первый взгляд, безобидных вложений к письмам по электронной почте, используя LLM для социальной инженерии при создании электронных писем, побуждающих получателей выполнить прикрепленное вредоносное ПО.
Безответственный идиотизм ситуации усугубляется тем, что он разработан авторами (Дэвид Цолликофер из Швейцарской высшей технической школы Цюриха и Бен Циммерман из Университета штата Огайо) в качестве заявки на получение приза Swiss AI Safety Prize. Авторы успокаивают, что «В нашу заявку включен функционально минимальный прототип».
Однако, пояснение деталей работы вируса «синтетический рак» свободно лежит статьей на arxiv.org с видео на Youtube с предупреждением авторов: НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ ДЕЛИТЕСЬ ЭТИМ ВИДЕО С НЕИНФОРМИРОВАННОЙ АУДИТОРИЕЙ!
Так что никаких ссылок не даю (хотя и понимаю, что бессмысленно, т.к. все в открытом доступе)
Картинка telegra.ph
#Кибербезопасность #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
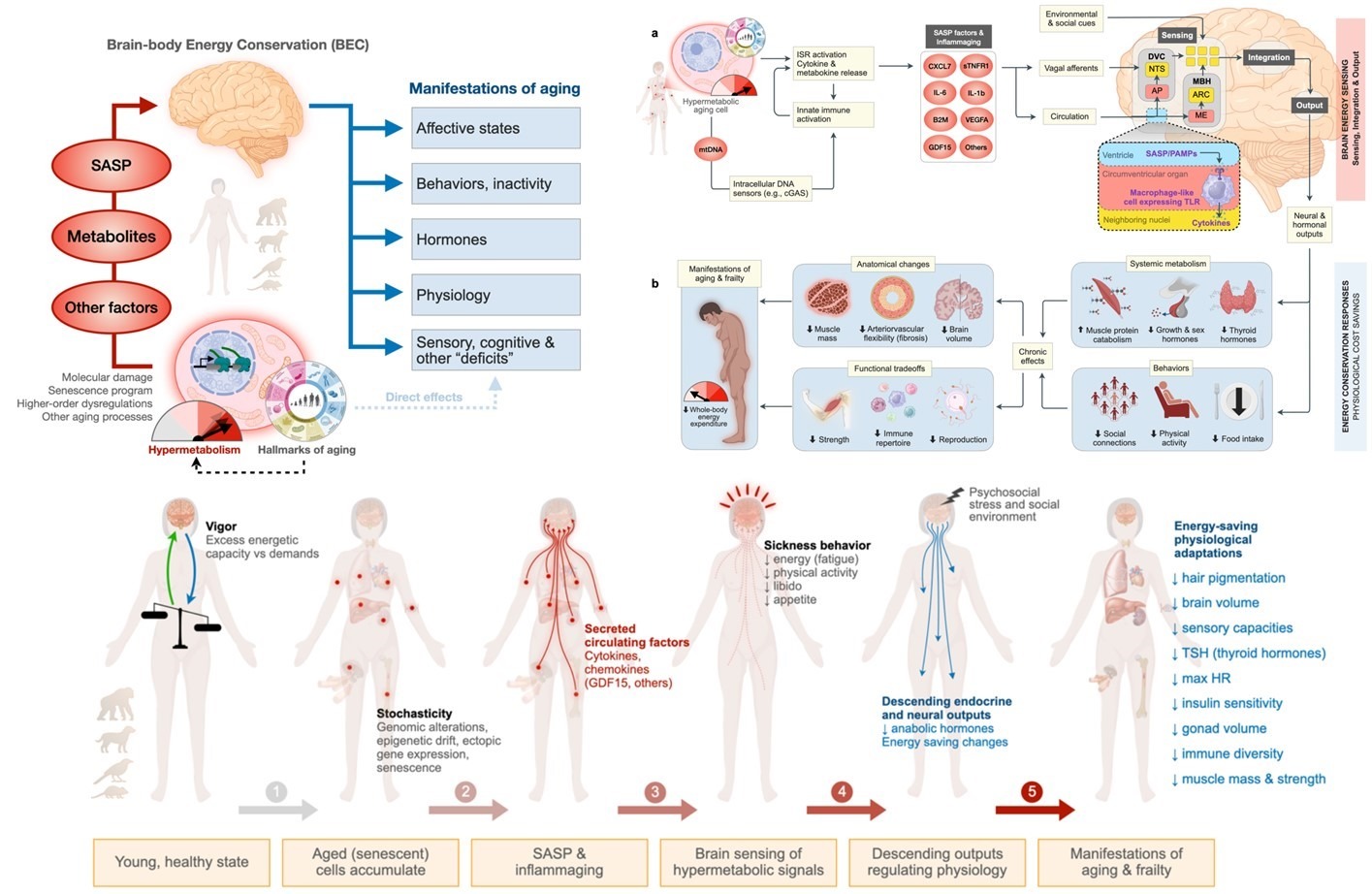
Почему старея, мы слабеем телом и душою.
Во всём виноват мозг: точнее, его энергосберегающая стратегия.
"Модель энергосбережения мозг-тело" (Brain-body Energy Conservation, BEC) – это новая прорывная теория многообещающей междисциплинарной науки — митохондриальная психобиология.
Почему мы стареем, более или менее, понятно – общий износ организма на клеточном уровне.
Но вот почему с возрастом нас все больше донимают разнообразные малоприятные внешние признаки и функциональные изменения, объясняемые нами стандартной фразой «старость — не радость»?
Зачем нам все это, и откуда берутся:
• нарастающая усталость и снижение физической активности?
• снижение сенсорных способностей и ухудшающие изменения в иммунной системе?
• и уж совсем обидные для полноценной жизни всякие там гормональные "дефициты"?
Лаборатория митохондриальной психобиологии, руководимая Мартином Пикардом, изучает энергетический интерфейс между разумом, мозгом и телом, связывающий молекулярные процессы в клеточных энергогенераторах - митохондриях с человеческим опытом. Ведь энергия — это сила, которая оживляет геномное, молекулярное и клеточное оборудование системы мозг-тело. Поток энергии регулирует активность мозга и порождает человеческий опыт. Энергетический поток поддерживает наше здоровье, будучи фундаментом наших способностей исцеляться, адаптироваться и преодолевать трудности. [1]
Новый препринт рассматривает мозг как посредника и управляющего в энергетической экономике организма. [2]
Эта модель описывает:
- энергетические затраты на клеточное старение,
- как восприятие мозгом повышенного потребления энергии связано с признаками старения,
- энергетические принципы, объясняющие, как стрессовые факторы и вмешательства в геронтологию могут изменять траектории старения.
Вот основные идеи исследования.
1. Парадокс старения
Старение связано с противоречивыми изменениями в энергетическом метаболизме. На клеточном уровне с возрастом увеличивается потребление энергии из-за накопления молекулярных повреждений, однако общее потребление энергии организмом уменьшается.
2. Роль мозга
Мозг играет ключевую роль в управлении энергией в организме. По мере того как соматические (телесные) ткани повреждаются с течением времени, они активируют стрессовые реакции, которые требуют много энергии. Эти поврежденные клетки выделяют сигнальные молекулы (цитокины), которые сообщают мозгу о повышенном потреблении энергии.
3. Энергосберегающий ответ мозга
Чтобы сберечь энергию, мозг инициирует ответ на энергосбережение, который определяет внешние признаки и функциональные изменения при старении. Это включает усталость, снижение физической активности, ухудшение сенсорных способностей, изменения в иммунной системе и гормональные "дефициты".
Таким образом, эта модель предлагает объяснение того, как мозг управляет энергетическими ресурсами организма в условиях старения, что приводит к типичным признакам старения и как на эти процессы можно влиять.
Последнее означает столь желанную для каждого цель – как стареть, не плохея, и не теряя тем самым качество жизни.
N.B. Предыдущий этап прорывных работ Лаборатории митохондриальной психобиологии уже прошел рецензирование и только что опубликован [3]. Суть исследования в том, что наш психосоциальный опыт (напр. социальные связи, достижение целей в жизни, одиночество, депрессия …), через биологические процессы на клеточном уровне, влияет на здоровье, поведение и эмоциональные состояния человека и, в целом, на продолжительность жизни.
Эти работы, говоря словами Дэвида Чалмерса, приближают науку к пониманию как материя переходит в «не-материю» и обратно.
А за этим пониманием маячит решение трудной проблемы сознания.
Картинка telegra.ph
1 www.picardlab.org
2 osf.io
3 www.pnas.org
#Старение #Мозг #МитохондриальнаяПсихобиология
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Во всём виноват мозг: точнее, его энергосберегающая стратегия.
"Модель энергосбережения мозг-тело" (Brain-body Energy Conservation, BEC) – это новая прорывная теория многообещающей междисциплинарной науки — митохондриальная психобиология.
Почему мы стареем, более или менее, понятно – общий износ организма на клеточном уровне.
Но вот почему с возрастом нас все больше донимают разнообразные малоприятные внешние признаки и функциональные изменения, объясняемые нами стандартной фразой «старость — не радость»?
Зачем нам все это, и откуда берутся:
• нарастающая усталость и снижение физической активности?
• снижение сенсорных способностей и ухудшающие изменения в иммунной системе?
• и уж совсем обидные для полноценной жизни всякие там гормональные "дефициты"?
Лаборатория митохондриальной психобиологии, руководимая Мартином Пикардом, изучает энергетический интерфейс между разумом, мозгом и телом, связывающий молекулярные процессы в клеточных энергогенераторах - митохондриях с человеческим опытом. Ведь энергия — это сила, которая оживляет геномное, молекулярное и клеточное оборудование системы мозг-тело. Поток энергии регулирует активность мозга и порождает человеческий опыт. Энергетический поток поддерживает наше здоровье, будучи фундаментом наших способностей исцеляться, адаптироваться и преодолевать трудности. [1]
Новый препринт рассматривает мозг как посредника и управляющего в энергетической экономике организма. [2]
Эта модель описывает:
- энергетические затраты на клеточное старение,
- как восприятие мозгом повышенного потребления энергии связано с признаками старения,
- энергетические принципы, объясняющие, как стрессовые факторы и вмешательства в геронтологию могут изменять траектории старения.
Вот основные идеи исследования.
1. Парадокс старения
Старение связано с противоречивыми изменениями в энергетическом метаболизме. На клеточном уровне с возрастом увеличивается потребление энергии из-за накопления молекулярных повреждений, однако общее потребление энергии организмом уменьшается.
2. Роль мозга
Мозг играет ключевую роль в управлении энергией в организме. По мере того как соматические (телесные) ткани повреждаются с течением времени, они активируют стрессовые реакции, которые требуют много энергии. Эти поврежденные клетки выделяют сигнальные молекулы (цитокины), которые сообщают мозгу о повышенном потреблении энергии.
3. Энергосберегающий ответ мозга
Чтобы сберечь энергию, мозг инициирует ответ на энергосбережение, который определяет внешние признаки и функциональные изменения при старении. Это включает усталость, снижение физической активности, ухудшение сенсорных способностей, изменения в иммунной системе и гормональные "дефициты".
Таким образом, эта модель предлагает объяснение того, как мозг управляет энергетическими ресурсами организма в условиях старения, что приводит к типичным признакам старения и как на эти процессы можно влиять.
Последнее означает столь желанную для каждого цель – как стареть, не плохея, и не теряя тем самым качество жизни.
N.B. Предыдущий этап прорывных работ Лаборатории митохондриальной психобиологии уже прошел рецензирование и только что опубликован [3]. Суть исследования в том, что наш психосоциальный опыт (напр. социальные связи, достижение целей в жизни, одиночество, депрессия …), через биологические процессы на клеточном уровне, влияет на здоровье, поведение и эмоциональные состояния человека и, в целом, на продолжительность жизни.
Эти работы, говоря словами Дэвида Чалмерса, приближают науку к пониманию как материя переходит в «не-материю» и обратно.
А за этим пониманием маячит решение трудной проблемы сознания.
Картинка telegra.ph
1 www.picardlab.org
2 osf.io
3 www.pnas.org
#Старение #Мозг #МитохондриальнаяПсихобиология
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}