
Взаимоцитирования США и Китая в области искусственного интеллекта
В последние годы ландшафт исследований в области машинного обучения изменился ввиду значительного роста числа китайских исследований в области искусственного интеллекта. В настоящее время Китай занимает стабильное второе место по количеству публикаций на NeurIPS (о которой мы упоминали в предыдущем посте) после США. В 2021 году материалы с аффилиациями китайских институтов составили 17,5% от всех публикаций в рамках NeurIPS. При этом несмотря на положение Китая как одного из лидеров развития ИИ сотрудничество между китайскими и американскими институтами происходит реже, чем, например, между американскими и западноевропейскими институтами.
Используя данные о цитировании конференционных материалов NeurIPS, авторы проанализировали взаимовлияние работ американских и китайских институтов. В то время как американские доклады составляют 60% общего набора данных, на них приходится только 34% ссылок от китайских коллег. Показатели цитирования китайских авторов от исследователей из США еще более драматичны: в то время как китайские материалы составляют 34% от всего набора данных, на них приходится только 9% цитирований от американских коллег. Кроме того, исследователи каждого из рассмотренных регионов намного чаще предпочитают внутрирегиональное цитирование межстрановому: разница между двумя показателями составляет 21% для Китая, 41% для США и 14% для Европы.
Таким образом, несмотря на то, что американские и китайские исследователи публикуются в одних и тех же сборниках и выступают на одних и тех же конференциях, они представляют собой во многом два параллельных сообщества, каждое из которых публикует работы, имеющие ограниченное влияние на соседей. В какой-то степени этот разрыв может объясняться интересом к разным темам и различными приоритетами исследований. Однако для компьютерных наук и областей, связанных с искусственным интеллектом, развитие коммуникации между странами, вносящими значимый вклад в данные области, может значительно ускорить достижение новых прорывных результатов.
#обзор #цитирования #китай #сша #искусственныйинтеллект
В последние годы ландшафт исследований в области машинного обучения изменился ввиду значительного роста числа китайских исследований в области искусственного интеллекта. В настоящее время Китай занимает стабильное второе место по количеству публикаций на NeurIPS (о которой мы упоминали в предыдущем посте) после США. В 2021 году материалы с аффилиациями китайских институтов составили 17,5% от всех публикаций в рамках NeurIPS. При этом несмотря на положение Китая как одного из лидеров развития ИИ сотрудничество между китайскими и американскими институтами происходит реже, чем, например, между американскими и западноевропейскими институтами.
Используя данные о цитировании конференционных материалов NeurIPS, авторы проанализировали взаимовлияние работ американских и китайских институтов. В то время как американские доклады составляют 60% общего набора данных, на них приходится только 34% ссылок от китайских коллег. Показатели цитирования китайских авторов от исследователей из США еще более драматичны: в то время как китайские материалы составляют 34% от всего набора данных, на них приходится только 9% цитирований от американских коллег. Кроме того, исследователи каждого из рассмотренных регионов намного чаще предпочитают внутрирегиональное цитирование межстрановому: разница между двумя показателями составляет 21% для Китая, 41% для США и 14% для Европы.
Таким образом, несмотря на то, что американские и китайские исследователи публикуются в одних и тех же сборниках и выступают на одних и тех же конференциях, они представляют собой во многом два параллельных сообщества, каждое из которых публикует работы, имеющие ограниченное влияние на соседей. В какой-то степени этот разрыв может объясняться интересом к разным темам и различными приоритетами исследований. Однако для компьютерных наук и областей, связанных с искусственным интеллектом, развитие коммуникации между странами, вносящими значимый вклад в данные области, может значительно ускорить достижение новых прорывных результатов.
#обзор #цитирования #китай #сша #искусственныйинтеллект
Может ли ChatGPT усилить эффект Матфея: на примере наук об окружающей среде
Коллеги провели исследование о том, какие статьи и журналы в области экологии чаще всего цитирует ChatGPT.
Авторы исследования попросили GPT:
• определить десять наиболее значимых субдисциплин в области науки об окружающей среде;
• подготовить научную обзорную статью по каждой субдисциплине, включив в нее 25 ссылок.
Далее авторы проанализировали эти ссылки (количество ссылок, дата публикации и журнал).
В ходе работы выяснили, что GPT, как правило:
• ссылается на высокоцитируемые публикации в области науки об окружающей среде с медианным числом цитирований 1184,5;
• отдает предпочтение более старым публикациям, средний год публикации — 2010;
• преимущественно ссылается на авторитетные журналы в этой области, причем самым цитируемым журналом в GPT является Nature;
• полагается исключительно на данные о количестве цитирований из Google Scholar, а не использует информацию о цитировании из других научных баз данных, таких как Web of Science или Scopus.
#обзор #цитирование #искусственныйинтеллект
Коллеги провели исследование о том, какие статьи и журналы в области экологии чаще всего цитирует ChatGPT.
Авторы исследования попросили GPT:
• определить десять наиболее значимых субдисциплин в области науки об окружающей среде;
• подготовить научную обзорную статью по каждой субдисциплине, включив в нее 25 ссылок.
Далее авторы проанализировали эти ссылки (количество ссылок, дата публикации и журнал).
В ходе работы выяснили, что GPT, как правило:
• ссылается на высокоцитируемые публикации в области науки об окружающей среде с медианным числом цитирований 1184,5;
• отдает предпочтение более старым публикациям, средний год публикации — 2010;
• преимущественно ссылается на авторитетные журналы в этой области, причем самым цитируемым журналом в GPT является Nature;
• полагается исключительно на данные о количестве цитирований из Google Scholar, а не использует информацию о цитировании из других научных баз данных, таких как Web of Science или Scopus.
#обзор #цитирование #искусственныйинтеллект
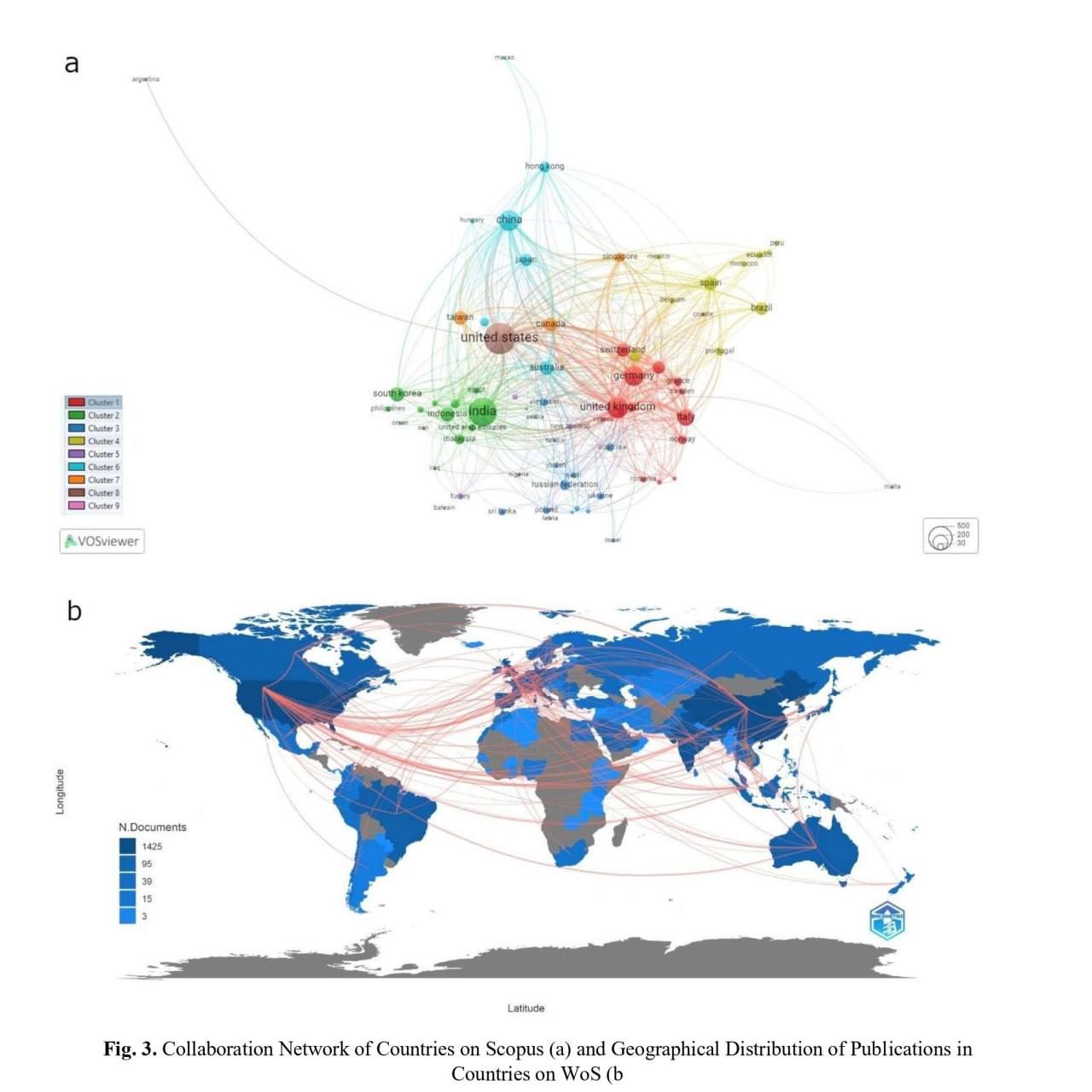
Что пишут о ChatGPT в Scopus и Web of Science
Из-за популярности чат-ботов и ChatGPT растет количество исследований, посвященных им. Одно из них представляет собой анализ литературы по чат-ботам и комплексный обзор научных документов по ChatGPT и фокусируется только на публикациях, индексируемых в Scopus и Web of Science.
Авторы выбрали Scopus и Web of Science, поскольку обе эти базы включают наиболее важные журналы по информатике, статистике, инженерии и математике. На первом этапе был проведен библиометрический анализ всей опубликованной литературы, включая статьи, главы книг, доклады конференций и обзоры по чатботам из баз данных Scopus (5839) и WoS (2531) за период с 1998 по 2023 год. Углубленный анализ, сосредоточенный на источниках, странах, влиянии авторов и ключевых словах, показал, что ChatGPT является мейнстримом в рамках анализа чат-ботов. На втором этапе был проведен библиометрический анализ публикаций ChatGPT, и 45 опубликованных исследований были тщательно проанализированы на предмет использованных методов, новизны и выводов. Ключевые области интересов, выявленные в ходе исследования, можно разделить на три группы: искусственный интеллект и связанные с ним технологии, разработка и оценка разговорных агентов, а также цифровые технологии и психическое здоровье.
Основные выводы:
1️⃣ Исследования чат-ботов вызывают интерес у исследователей по всему миру, в них принимают участие ученые из более чем половины стран мира. Исследования ChatGPT уже проводились в 46 странах.
2️⃣ США занимают первое место по количеству публикаций, связанных как с чат-ботами, так и с ChatGPT. Далее идут Германия и Великобритания. Они входят в первую группу стран, выпускающих публикации по чат-ботам в Scopus, и занимают второе и третье места по количеству публикаций по ChatGPT, соответственно.
3️⃣ Психическое здоровье становится все более популярной областью исследований при анализе чат-ботов, разрабатываемых в области охраны здоровья. Исследователи отмечают, чат-боты расширяют возможности реализации когнитивно-поведенческой терапии.
4️⃣ В исследованиях, связанных с ChatGPT, популярная область — здравоохранение. Исследователи изучают потенциал ChatGPT для предоставления персонализированных рекомендаций по лечению, облегчения удаленного мониторинга пациентов и помощи медицинским работникам в принятии решений.
В заключении авторы отмечают, что ChatGPT выступает ключевым направлением в исследованиях чат-ботов, при этом текущая литература в основном сосредоточена на его возможностях и ограничениях в таких областях, как исследовательская этика, медицина и социальные науки.
#обзор #искусственныйинтеллект #chatgpt #wos #scopus
Из-за популярности чат-ботов и ChatGPT растет количество исследований, посвященных им. Одно из них представляет собой анализ литературы по чат-ботам и комплексный обзор научных документов по ChatGPT и фокусируется только на публикациях, индексируемых в Scopus и Web of Science.
Авторы выбрали Scopus и Web of Science, поскольку обе эти базы включают наиболее важные журналы по информатике, статистике, инженерии и математике. На первом этапе был проведен библиометрический анализ всей опубликованной литературы, включая статьи, главы книг, доклады конференций и обзоры по чатботам из баз данных Scopus (5839) и WoS (2531) за период с 1998 по 2023 год. Углубленный анализ, сосредоточенный на источниках, странах, влиянии авторов и ключевых словах, показал, что ChatGPT является мейнстримом в рамках анализа чат-ботов. На втором этапе был проведен библиометрический анализ публикаций ChatGPT, и 45 опубликованных исследований были тщательно проанализированы на предмет использованных методов, новизны и выводов. Ключевые области интересов, выявленные в ходе исследования, можно разделить на три группы: искусственный интеллект и связанные с ним технологии, разработка и оценка разговорных агентов, а также цифровые технологии и психическое здоровье.
Основные выводы:
1️⃣ Исследования чат-ботов вызывают интерес у исследователей по всему миру, в них принимают участие ученые из более чем половины стран мира. Исследования ChatGPT уже проводились в 46 странах.
2️⃣ США занимают первое место по количеству публикаций, связанных как с чат-ботами, так и с ChatGPT. Далее идут Германия и Великобритания. Они входят в первую группу стран, выпускающих публикации по чат-ботам в Scopus, и занимают второе и третье места по количеству публикаций по ChatGPT, соответственно.
3️⃣ Психическое здоровье становится все более популярной областью исследований при анализе чат-ботов, разрабатываемых в области охраны здоровья. Исследователи отмечают, чат-боты расширяют возможности реализации когнитивно-поведенческой терапии.
4️⃣ В исследованиях, связанных с ChatGPT, популярная область — здравоохранение. Исследователи изучают потенциал ChatGPT для предоставления персонализированных рекомендаций по лечению, облегчения удаленного мониторинга пациентов и помощи медицинским работникам в принятии решений.
В заключении авторы отмечают, что ChatGPT выступает ключевым направлением в исследованиях чат-ботов, при этом текущая литература в основном сосредоточена на его возможностях и ограничениях в таких областях, как исследовательская этика, медицина и социальные науки.
#обзор #искусственныйинтеллект #chatgpt #wos #scopus
{kind=link}
«Призрак бродит по… журналам»: о последствиях использования GPT-моделей в качестве академического инструмента
ChatGPT от OpenAI, запущенный в конце ноября 2022, в последнее время находит всё больше применений в академической среде, о чем мы уже писали ранее. Он способен автоматизировать повторяющиеся задачи: например, генерировать код (правда не всегда актуальный для текущих версий пакетов), обобщать данные из нескольких научных статей, неплохо справляться с переводом текстов и даже перефразировать целые абзацы для большего соответствия академическому стилю. Однако у всего этого есть обратная сторона: во-первых, чат-боты, стремясь понравиться, зачастую выдают ложные факты за действительные, а во-вторых — могут недобросовестно использоваться самими авторами.
В недавней заметке в Scientometrics описывается одно из обнаруженных ограничений ChatGPT — склонность генерировать «призрачные» научные ссылки. Когда у чат-бота запрашивают библиографические ссылки по конкретной теме, он предоставляет правдоподобные результаты — это могут быть реальные названия статей, а в качестве источника публикации указываются названия ведущих журналов. Однако на практике выясняется, что таких статей никогда не существовало. Такие ссылки, сгенерированные при участии недобросовестных авторов, могут в конечном итоге попадать в научные публикации, особенно в тех издательствах, где процессы рецензирования слабы или вообще отсутствуют. Реальные же ссылки от GPT-моделей, вероятнее всего, усиливают эффект Матфея, о котором мы упоминали в одном из наших предыдущих постов.
Выявление таких «призрачных» ссылок — настоящий вызов для научного сообщества. Безусловно, полностью сгенерированная библиография вызовет вопросы у любого профессионала в области, однако отдельные аргументы, написанные при помощи GPT-моделей и ссылающиеся на несуществующие работы, могут с некоторой вероятностью тиражироваться в других исследованиях.
Мы же решили проверить описанный эффект сразу на трех моделях — ChatGPT, YandexGPT2 и GigaChat. Результаты вы можете видеть на скриншотах. Как и ожидалось, наиболее правдоподобные цитаты выдает ChatGPT. YandexGPT2 оказывается не менее изобретателен в создании новых публикаций: забывает о страницах, но упоминает реальных людей в качестве соавторов. А вот от GigaChat удается получить только библиографические сведения о журнале, без имен авторов и названия статей (вероятно, в данном случае использовались другие источники данных для обучения моделей).
#обзор #цитирование #искусственныйинтеллект #GPT
ChatGPT от OpenAI, запущенный в конце ноября 2022, в последнее время находит всё больше применений в академической среде, о чем мы уже писали ранее. Он способен автоматизировать повторяющиеся задачи: например, генерировать код (правда не всегда актуальный для текущих версий пакетов), обобщать данные из нескольких научных статей, неплохо справляться с переводом текстов и даже перефразировать целые абзацы для большего соответствия академическому стилю. Однако у всего этого есть обратная сторона: во-первых, чат-боты, стремясь понравиться, зачастую выдают ложные факты за действительные, а во-вторых — могут недобросовестно использоваться самими авторами.
В недавней заметке в Scientometrics описывается одно из обнаруженных ограничений ChatGPT — склонность генерировать «призрачные» научные ссылки. Когда у чат-бота запрашивают библиографические ссылки по конкретной теме, он предоставляет правдоподобные результаты — это могут быть реальные названия статей, а в качестве источника публикации указываются названия ведущих журналов. Однако на практике выясняется, что таких статей никогда не существовало. Такие ссылки, сгенерированные при участии недобросовестных авторов, могут в конечном итоге попадать в научные публикации, особенно в тех издательствах, где процессы рецензирования слабы или вообще отсутствуют. Реальные же ссылки от GPT-моделей, вероятнее всего, усиливают эффект Матфея, о котором мы упоминали в одном из наших предыдущих постов.
Выявление таких «призрачных» ссылок — настоящий вызов для научного сообщества. Безусловно, полностью сгенерированная библиография вызовет вопросы у любого профессионала в области, однако отдельные аргументы, написанные при помощи GPT-моделей и ссылающиеся на несуществующие работы, могут с некоторой вероятностью тиражироваться в других исследованиях.
Мы же решили проверить описанный эффект сразу на трех моделях — ChatGPT, YandexGPT2 и GigaChat. Результаты вы можете видеть на скриншотах. Как и ожидалось, наиболее правдоподобные цитаты выдает ChatGPT. YandexGPT2 оказывается не менее изобретателен в создании новых публикаций: забывает о страницах, но упоминает реальных людей в качестве соавторов. А вот от GigaChat удается получить только библиографические сведения о журнале, без имен авторов и названия статей (вероятно, в данном случае использовались другие источники данных для обучения моделей).
#обзор #цитирование #искусственныйинтеллект #GPT
Telegram
Выше квартилей
Что пишут о ChatGPT в Scopus и Web of Science
Из-за популярности чат-ботов и ChatGPT растет количество исследований, посвященных им. Одно из них представляет собой анализ литературы по чат-ботам и комплексный обзор научных документов по ChatGPT и фокусируется…
Из-за популярности чат-ботов и ChatGPT растет количество исследований, посвященных им. Одно из них представляет собой анализ литературы по чат-ботам и комплексный обзор научных документов по ChatGPT и фокусируется…
Чат-боты: цитировать или не цитировать?
Растущий интерес к использованию искусственного интеллекта (ИИ) в написании научных работ и ряд скандалов, связанных с его недобросовестным применением в академической сфере, провоцируют острую дискуссию. Летисия Антунес Ногейра (Leticia Antunes Nogueira), руководитель проекта по искусственному интеллекту, и Ян Уве Рейн (Jan Ove Rein), библиотекарь-исследователь, оба — сотрудники NTNU опубликовали заметку (ч. 1, ч. 2), в которой сосредоточились на критике концепции цитирования языковых моделей в научных публикациях.
В заметке авторы сузили фокус до двух моделей (ChatGPT от OpenAI или Claude от Anthropic), так как предполагают, что пользователи, которые работают с инструментами, применяющими возможности GenAI в сочетании с другими системами (например, Perplexity и Scopus AI), будут ссылаться на оригинальные источники.
В политике ведущих мировых издательств и академических организаций существует общее мнение насчет того, что чат-боты не отвечают минимальным требованиям к авторству, однако вопрос о том, можно ли (и следует ли) цитировать чат-боты в качестве источников, остается открытым.
Сторонники цитирования сообщений чат-ботов отмечают, что цитирование необходимо как минимум по двум причинам:
· признание чужого вклада и влияния идей;
· раскрытие источников информации.
Эти два, казалось бы, простых аспекта связаны с некоторыми противоречиями.
Противники цитирования (и иногда использования) чат-ботов подчеркивают, что результаты, полученные с использованием ИИ, преимущественно невозможно отследить, воспроизвести или проверить. В дополнение к этим ощутимым аргументам, исследователи акцентируют внимание на нескольких этических аспектах:
🔹Ответственность авторов
Языковая модель не может нести ответственность за утверждения, включенные в публикацию от её «лица». Одно дело цитировать организацию (например, доклад ООН), и совсем другое — чат-бота. Организации состоят из людей и поэтому несут ответственность за предоставляемую информацию, чат-бот или его разработчики нести такую ответственность не могут.
🔹Загрязнение информационной среды
Упоминание чат-ботов в источниках ведет к загрязнению информационных экосистем. Если для обучения больших языковых моделей использовать данные, сгенерированные ИИ (т. е. тексты из Интернета, академические тексты и т. д.), это приведет к ухудшению качества моделей.
🔹ИИ — не истина в последней инстанции
Чат-боты не создавались как инструменты для информационных целей. Неопределенность в отношении качества их ответов обусловлена назначением и структурой чат-ботов, а не степенью технологической зрелости. Большие языковые модели (LLM) основаны на моделях использования языка, а не на информации, и вероятностны по своему принципу работы, а это означает, что некорректный результат в таком случае — особенность, а не ошибка.
APA рекомендует цитировать текст, полученный от чат-бота, как результат работы алгоритма: а именно, ссылаться на автора алгоритма в списке источников. Дело в том, что результаты «переписки» с ChatGPT невозможно воспроизвести. Сейчас в APA такие данные часто цитируются как личная переписка, но это не совсем корректно, потому что сгенерированный текст не исходит от чьей-либо личности. В то же время ICMJE и Elsevier занимают однозначную позицию и рекомендуют авторам не ссылаться на чат-боты.
Появление чат-ботов бросает вызов устоявшимся представлениям об источниках, информации и знании, которые совсем недавно считались само собой разумеющимися. Тем не менее, в эпоху искусственного интеллекта обеспечение целостности информационной экосистемы требует все больших усилий. По мнению авторов, поскольку связность и смыслы в любом случае находятся «в глазах смотрящего», наборы слов, полученные в результате вероятностных вычислений, нельзя назвать ни источниками, ни информацией, ни знаниями. Текст, генерируемый чат-ботами — скорее, воплощение отсутствия информации.
#ChatGPT #ИИ #искусственныйинтеллект #цитирование
Растущий интерес к использованию искусственного интеллекта (ИИ) в написании научных работ и ряд скандалов, связанных с его недобросовестным применением в академической сфере, провоцируют острую дискуссию. Летисия Антунес Ногейра (Leticia Antunes Nogueira), руководитель проекта по искусственному интеллекту, и Ян Уве Рейн (Jan Ove Rein), библиотекарь-исследователь, оба — сотрудники NTNU опубликовали заметку (ч. 1, ч. 2), в которой сосредоточились на критике концепции цитирования языковых моделей в научных публикациях.
В заметке авторы сузили фокус до двух моделей (ChatGPT от OpenAI или Claude от Anthropic), так как предполагают, что пользователи, которые работают с инструментами, применяющими возможности GenAI в сочетании с другими системами (например, Perplexity и Scopus AI), будут ссылаться на оригинальные источники.
В политике ведущих мировых издательств и академических организаций существует общее мнение насчет того, что чат-боты не отвечают минимальным требованиям к авторству, однако вопрос о том, можно ли (и следует ли) цитировать чат-боты в качестве источников, остается открытым.
Сторонники цитирования сообщений чат-ботов отмечают, что цитирование необходимо как минимум по двум причинам:
· признание чужого вклада и влияния идей;
· раскрытие источников информации.
Эти два, казалось бы, простых аспекта связаны с некоторыми противоречиями.
Противники цитирования (и иногда использования) чат-ботов подчеркивают, что результаты, полученные с использованием ИИ, преимущественно невозможно отследить, воспроизвести или проверить. В дополнение к этим ощутимым аргументам, исследователи акцентируют внимание на нескольких этических аспектах:
🔹Ответственность авторов
Языковая модель не может нести ответственность за утверждения, включенные в публикацию от её «лица». Одно дело цитировать организацию (например, доклад ООН), и совсем другое — чат-бота. Организации состоят из людей и поэтому несут ответственность за предоставляемую информацию, чат-бот или его разработчики нести такую ответственность не могут.
🔹Загрязнение информационной среды
Упоминание чат-ботов в источниках ведет к загрязнению информационных экосистем. Если для обучения больших языковых моделей использовать данные, сгенерированные ИИ (т. е. тексты из Интернета, академические тексты и т. д.), это приведет к ухудшению качества моделей.
🔹ИИ — не истина в последней инстанции
Чат-боты не создавались как инструменты для информационных целей. Неопределенность в отношении качества их ответов обусловлена назначением и структурой чат-ботов, а не степенью технологической зрелости. Большие языковые модели (LLM) основаны на моделях использования языка, а не на информации, и вероятностны по своему принципу работы, а это означает, что некорректный результат в таком случае — особенность, а не ошибка.
APA рекомендует цитировать текст, полученный от чат-бота, как результат работы алгоритма: а именно, ссылаться на автора алгоритма в списке источников. Дело в том, что результаты «переписки» с ChatGPT невозможно воспроизвести. Сейчас в APA такие данные часто цитируются как личная переписка, но это не совсем корректно, потому что сгенерированный текст не исходит от чьей-либо личности. В то же время ICMJE и Elsevier занимают однозначную позицию и рекомендуют авторам не ссылаться на чат-боты.
Появление чат-ботов бросает вызов устоявшимся представлениям об источниках, информации и знании, которые совсем недавно считались само собой разумеющимися. Тем не менее, в эпоху искусственного интеллекта обеспечение целостности информационной экосистемы требует все больших усилий. По мнению авторов, поскольку связность и смыслы в любом случае находятся «в глазах смотрящего», наборы слов, полученные в результате вероятностных вычислений, нельзя назвать ни источниками, ни информацией, ни знаниями. Текст, генерируемый чат-ботами — скорее, воплощение отсутствия информации.
#ChatGPT #ИИ #искусственныйинтеллект #цитирование
Использование ИИ в технологическом трансфере
Месяц назад в Nature вышла заметка основателя “Научного центра науки и инноваций Северо-Западного университета” Дашунь Вана (Dashun Wang), посвященная использованию алгоритмов ИИ для выявления ученых, нуждающихся в поддержке их научных результатов для практического приложения.
Во время пилотного проекта исследовательской группы Вана обнаружилось, что одна исследовательница в области биологии не знала о влиянии своих научных работ на рынок, но в результате знакомства с подразделением технологического трансфера она узнала, что частные компании широко цитируют ее исследования в своих патентах, и подала заявку на регистрацию своего изобретения. Этот пример сподвигнул Вана задаться вытекающими из этого кейса вопросами: можно ли выявить исследователей с невостребованным инновационным потенциалом и каким образом?
В течение нескольких лет исследовательский коллектив Вана работал с различными университетами США, пытаясь найти оптимальные способы максимизировать результаты научной деятельности.
В ходе исследования обнаружились некоторые потворяющиеся паттерны, например:
- женщины реже патентуют свои работы, чем мужчины (причем разница — от двух до десяти раз в зависимости от области), при одинаковом (судя по цитируемости) уровне работы;
- преподаватели с постоянным контрактом подают заявки чаще, чем те, кто трудоустроен по временному контракту.
Кроме того, выяснилось, что существует довольно много ученых, которые не стремятся к трансферу технологий, не взаимодействуют с соответствующим департаментом (а такие есть почти во всех университетах), не подают заявки на патенты.
Ван и его коллеги полагают, что публикующиеся ежегодно наборы данных о миллионах статей, препринтов и грантовых заявок можно анализировать при помощи ИИ, чтобы выявить пробелы и узкие места, которые мешают технологическим прорывам.
Одним из главных хайлайтов статьи является утверждение Вана о дихотомии между фундаментальными и прикладными исследованиями и условиями современности: сложно спрогнозировать какие исследования найдут непосредственное технологическое применение.
Вывод Вана состоит в том, что исследования были бы намного влиятельней, если бы университеты использовали инструменты ИИ с целью поиска научных результатов своих сотрудников, к которым применим технологический трансфер.
#обзор #искусственныйинтеллект #патенты
Месяц назад в Nature вышла заметка основателя “Научного центра науки и инноваций Северо-Западного университета” Дашунь Вана (Dashun Wang), посвященная использованию алгоритмов ИИ для выявления ученых, нуждающихся в поддержке их научных результатов для практического приложения.
Во время пилотного проекта исследовательской группы Вана обнаружилось, что одна исследовательница в области биологии не знала о влиянии своих научных работ на рынок, но в результате знакомства с подразделением технологического трансфера она узнала, что частные компании широко цитируют ее исследования в своих патентах, и подала заявку на регистрацию своего изобретения. Этот пример сподвигнул Вана задаться вытекающими из этого кейса вопросами: можно ли выявить исследователей с невостребованным инновационным потенциалом и каким образом?
В течение нескольких лет исследовательский коллектив Вана работал с различными университетами США, пытаясь найти оптимальные способы максимизировать результаты научной деятельности.
В ходе исследования обнаружились некоторые потворяющиеся паттерны, например:
- женщины реже патентуют свои работы, чем мужчины (причем разница — от двух до десяти раз в зависимости от области), при одинаковом (судя по цитируемости) уровне работы;
- преподаватели с постоянным контрактом подают заявки чаще, чем те, кто трудоустроен по временному контракту.
Кроме того, выяснилось, что существует довольно много ученых, которые не стремятся к трансферу технологий, не взаимодействуют с соответствующим департаментом (а такие есть почти во всех университетах), не подают заявки на патенты.
Ван и его коллеги полагают, что публикующиеся ежегодно наборы данных о миллионах статей, препринтов и грантовых заявок можно анализировать при помощи ИИ, чтобы выявить пробелы и узкие места, которые мешают технологическим прорывам.
Одним из главных хайлайтов статьи является утверждение Вана о дихотомии между фундаментальными и прикладными исследованиями и условиями современности: сложно спрогнозировать какие исследования найдут непосредственное технологическое применение.
Вывод Вана состоит в том, что исследования были бы намного влиятельней, если бы университеты использовали инструменты ИИ с целью поиска научных результатов своих сотрудников, к которым применим технологический трансфер.
#обзор #искусственныйинтеллект #патенты
Оценка влияния внедрения ИИ в науку
Быстрое развитие искусственного интеллекта (ИИ) затрагивает практически все сферы. Неудивительно, что применение ИИ всё чаще встречается в науке, о чем свидетельствует неумолимо растущее (особенно с 2015 года) количество упоминаний терминов этой сферы в заголовках и аннотациях статей. На днях в Nature Human Behaviour вышла статья, авторы которой подвергли количественной оценке использование и потенциальные преимущества ИИ в научных исследованиях.
Исследователи из Северо-Западного университета (Northwestern University) сопоставили данные более 74 миллионов публикаций с 1960 по 2019 год из Microsoft Academic Graph, охватывающих 19 дисциплин и 292 области, с данными о чуть более 7 миллионах патентов, выданных в период с 1976 по 2019 год Ведомством по патентным и товарным знакам США (USPTO), что позволило проанализировать практическое применение ИИ в научных исследованиях. Также авторы проанализировали встречаемость терминов ИИ в заголовках и аннотациях статей.
Основные результаты работы сводятся к следующему:
• упоминание ИИ в статьях повышает их цитируемость как внутри своей области, так и за ее пределами;
• почти каждая дисциплина включает в себя некоторые области, которые видят потенциал в применении ИИ (см. рис.);
• междисциплинарное сотрудничество способствует стремительному развитию использования ИИ в науке;
• есть разрыв между применением ИИ и обучением ИИ (спрос превышает предложение);
• ИИ может усугубить существующее неравенство в науке (например, демографическое и гендерное).
Искусственный интеллект как открывает новые исследовательские пути, так и является источником неразрешимых проблем, например, этических. Цифровизация и внедрение инструментов ИИ в науку вынуждают трансформировать и переосмыслять традиционные академические форматы, ресурсы и практики.
Кстати, завтра, 23 октября в 16:00, Центр научной интеграции НИУ ВШЭ проведет вебинар с элементами тренинга «Ученый в эпоху перемен: ключевые навыки для построения академической карьеры», на котором среди прочего будет затронута тема влияния глобальных изменений последних 5 лет на деятельность ученого, а также будет поднят вопрос развития необходимых навыков для построения академической карьеры в нестабильное время.
Формат вебинара предполагает взаимодействие. В рамках тренинга будет возможность познакомиться с исследователями из научных и образовательных организаций, а также поделиться своим опытом развития в академической среде. Регистрация доступа по ссылке.
#Искусственныйинтеллект #Центрнаучнойинтеграции
#ИИ #MAG
Быстрое развитие искусственного интеллекта (ИИ) затрагивает практически все сферы. Неудивительно, что применение ИИ всё чаще встречается в науке, о чем свидетельствует неумолимо растущее (особенно с 2015 года) количество упоминаний терминов этой сферы в заголовках и аннотациях статей. На днях в Nature Human Behaviour вышла статья, авторы которой подвергли количественной оценке использование и потенциальные преимущества ИИ в научных исследованиях.
Исследователи из Северо-Западного университета (Northwestern University) сопоставили данные более 74 миллионов публикаций с 1960 по 2019 год из Microsoft Academic Graph, охватывающих 19 дисциплин и 292 области, с данными о чуть более 7 миллионах патентов, выданных в период с 1976 по 2019 год Ведомством по патентным и товарным знакам США (USPTO), что позволило проанализировать практическое применение ИИ в научных исследованиях. Также авторы проанализировали встречаемость терминов ИИ в заголовках и аннотациях статей.
Основные результаты работы сводятся к следующему:
• упоминание ИИ в статьях повышает их цитируемость как внутри своей области, так и за ее пределами;
• почти каждая дисциплина включает в себя некоторые области, которые видят потенциал в применении ИИ (см. рис.);
• междисциплинарное сотрудничество способствует стремительному развитию использования ИИ в науке;
• есть разрыв между применением ИИ и обучением ИИ (спрос превышает предложение);
• ИИ может усугубить существующее неравенство в науке (например, демографическое и гендерное).
Искусственный интеллект как открывает новые исследовательские пути, так и является источником неразрешимых проблем, например, этических. Цифровизация и внедрение инструментов ИИ в науку вынуждают трансформировать и переосмыслять традиционные академические форматы, ресурсы и практики.
Кстати, завтра, 23 октября в 16:00, Центр научной интеграции НИУ ВШЭ проведет вебинар с элементами тренинга «Ученый в эпоху перемен: ключевые навыки для построения академической карьеры», на котором среди прочего будет затронута тема влияния глобальных изменений последних 5 лет на деятельность ученого, а также будет поднят вопрос развития необходимых навыков для построения академической карьеры в нестабильное время.
Формат вебинара предполагает взаимодействие. В рамках тренинга будет возможность познакомиться с исследователями из научных и образовательных организаций, а также поделиться своим опытом развития в академической среде. Регистрация доступа по ссылке.
#Искусственныйинтеллект #Центрнаучнойинтеграции
#ИИ #MAG
{kind=link}