
Dark side of publishing. Недобросовестные исследовательские практики, научная этика и опасности на исследовательском пути.
Использованы иллюстрации Robert Neubecker, David Parkins.
Использованы иллюстрации Robert Neubecker, David Parkins.
Обновление квартилей JCR
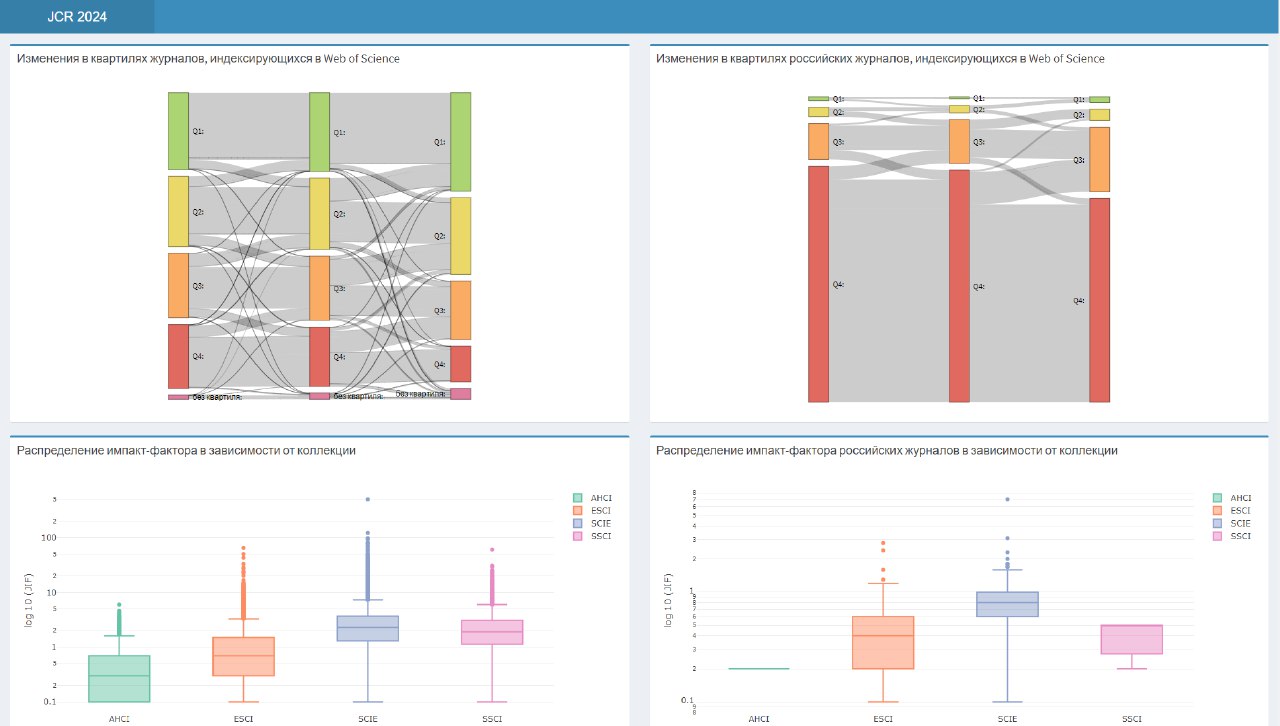
20 июня, как уже заметили некоторые наши коллеги, обновился список Journal Citation Reports (JCR) от Clarivate, в котором приводится распределение по квартилям для всех журналов, индексирующихся в Web of Science. А мы традиционно проанализировали «миграцию» журналов «классических» коллекций (SCIE и SSCI) между квартилями, добавив к sankey-диаграмме квартили за 2023 год (на диаграмме 2021, 2022 и 2023 годы приведены слева направо). Кроме того, мы дополнили приложение квартилями для российских журналов. Внизу же демонстрируются различия в распределении самого импакт-фактора для разных коллекций (AHCI, ESCI, SCIE и SSCI). Для журналов из коллекций Arts and Humanities Citation Index (AHCI) и Emerging Sources Citation Index (ESCI), как вы, наверное, помните, импакт-факторы опубликованы впервые в прошлом году, это — второй выпуск.
20 июня, как уже заметили некоторые наши коллеги, обновился список Journal Citation Reports (JCR) от Clarivate, в котором приводится распределение по квартилям для всех журналов, индексирующихся в Web of Science. А мы традиционно проанализировали «миграцию» журналов «классических» коллекций (SCIE и SSCI) между квартилями, добавив к sankey-диаграмме квартили за 2023 год (на диаграмме 2021, 2022 и 2023 годы приведены слева направо). Кроме того, мы дополнили приложение квартилями для российских журналов. Внизу же демонстрируются различия в распределении самого импакт-фактора для разных коллекций (AHCI, ESCI, SCIE и SSCI). Для журналов из коллекций Arts and Humanities Citation Index (AHCI) и Emerging Sources Citation Index (ESCI), как вы, наверное, помните, импакт-факторы опубликованы впервые в прошлом году, это — второй выпуск.
{kind=link}
Мы продолжаем нашу рубрику, посвященную истории развития наукометрии. Сегодня мы обратимся к истории одной из самых известных журнальных метрик — Journal Impact Factor (JIF). Посмотреть пост вы можете по ссылке.
#историянаукометрии
#историянаукометрии
Telegraph
Импакт-фактор
Ю. Гарфилд. «Агония и экстаз — история и значение импакт-фактора журнала» Импакт фактор или Journal Impact Factor (JIF) — это метрика, которая отображает среднее число цитирований статей, опубликованных в данном журнале за определённый период времени. Предтечей…
Дайджест: июнь 2024
Первый летний месяц в мире науки традиционно тихий. Тем не менее, за июнь произошел ряд интересных событий, и мы представляем свежий дайджест.
Научные публикации
- Подошла к концу история с амилоидной гипотезой возникновения болезни Альцгеймера (мы писали о ней ранее). Карен Эш, соавтор-корреспондент и коллега Сильвена Лесне, согласилась с необходимостью ретракции статьи 2006 года, и 24 июня статья была отозвана.
- На конференции FAccT’2024 была представлена работа А. Лизенфельда и М. Дингеманса, в которой анализируется, насколько генеративные ИИ с открытым исходным кодом действительно открыты (на самом деле не очень).
Редакторская политика
- На конференции Clarivate Ignite 2024, проходившей в Сан-Диего, США, представили IP Collaboration Hub. Новое решение позволит управлять всем процессом подачи и рассмотрения заявок на патенты и товарные знаки за рубежом с помощью единого механизма учета заявок.
- Кроме того, Web of Science запустили систему Research Horizon Navigator — новый модуль с поддержкой ИИ в InCites Benchmarking & Analytics. Он призван помогать быстро находить новые темы, возникающие в научном сообществе в области интересов конкретного исследователя или института.
- Система Problematic Paper Screener (PPS), используемая для обнаружения признаков плагиата в научных публикациях, теперь может распознавать так называемые «искаженные аббревиатуры» — довольно явный признак того, что статья была написана при помощи ИИ.
Базы данных
- В Scientometrics вышла статья о разработке и применении нового библиометрического пакета для R — biblioverlap. Сам пакет доступен в репозитории CRAN. Предлагаем читателям пробовать и делиться своими впечатлениями (мы тоже скоро планируем).
- Появился список Altmetrics 500. Туда входят статьи, которые привлекли наибольшее внимание в Интернете в 2023 году: в новостях, цитатах, Википедии и X/Twitter.
Университетские рейтинги
- 30 мая вышел новый выпуск международного рейтинга университетов RUR. Всего в этом году в рейтинге 131 российский вуз, но в первую сотню попал только МГУ.
- 19 июня на XII ежегодном форуме ведущих вузов «Будущее высшей школы» был представлен рейтинг лучших российских вузов RAEX-100. В топ-3 — МГУ, Бауманка и МФТИ.
- 25 июня был опубликован свежий рейтинг USNews, в котором рассматривается 2250 вузов из более чем 100 стран. Из России в рейтинге 42 вуза, на первом месте по стране — Южно-Уральский государственный университет.
Наука в мире
- Планируемые изменения в системе Research Excellence Framework (Великобритания) вызывают у научных администаторов опасения: если учитывать в REF результаты работы сотрудников, работающих всего на 0,2 ставки (FTE), то университеты могут начать фиктивно нанимать сильных ученых для повышения своих показателей.
Наука в России
- ТюмГУ вслед за САФУ и МГПУ утвердил право студентов использовать генеративный ИИ при написании ВКР.
- Федеральная антимонопольная служба оштрафовала Яндекс за распостранение рекламы сервиса по написанию рефератов, курсовых и дипломных работ.
- Опубликован список победителей в конкурсе на “президентскую мегастипендию для аспирантов” в размере 75 тыс. рублей. Мы поздравляем победителей!
- Указом Президента РФ от 18.06.24 были утверждены обновленные а) приоритетные направления научно-тенхологического развития и б) перечень важнейших наукоемких технологий.
И бонусная новость: фармацевтическая компания «Ланцет» подала иск с требованием прекратить правовую охрану товарного знака The Lancet (и не только). Дело зарегистрировано под номером №СИП-589/2024, к участию привлекли и Роспатент. Пока что суд вынес определение об оставлении искового заявления без движения, но мы будем с интересом наблюдать за развитием событий.
#дайджест #новости #редакторскаяполитика #базыданных #наукавроссии #искуственныйинтеллект #рейтинги
Первый летний месяц в мире науки традиционно тихий. Тем не менее, за июнь произошел ряд интересных событий, и мы представляем свежий дайджест.
Научные публикации
- Подошла к концу история с амилоидной гипотезой возникновения болезни Альцгеймера (мы писали о ней ранее). Карен Эш, соавтор-корреспондент и коллега Сильвена Лесне, согласилась с необходимостью ретракции статьи 2006 года, и 24 июня статья была отозвана.
- На конференции FAccT’2024 была представлена работа А. Лизенфельда и М. Дингеманса, в которой анализируется, насколько генеративные ИИ с открытым исходным кодом действительно открыты (на самом деле не очень).
Редакторская политика
- На конференции Clarivate Ignite 2024, проходившей в Сан-Диего, США, представили IP Collaboration Hub. Новое решение позволит управлять всем процессом подачи и рассмотрения заявок на патенты и товарные знаки за рубежом с помощью единого механизма учета заявок.
- Кроме того, Web of Science запустили систему Research Horizon Navigator — новый модуль с поддержкой ИИ в InCites Benchmarking & Analytics. Он призван помогать быстро находить новые темы, возникающие в научном сообществе в области интересов конкретного исследователя или института.
- Система Problematic Paper Screener (PPS), используемая для обнаружения признаков плагиата в научных публикациях, теперь может распознавать так называемые «искаженные аббревиатуры» — довольно явный признак того, что статья была написана при помощи ИИ.
Базы данных
- В Scientometrics вышла статья о разработке и применении нового библиометрического пакета для R — biblioverlap. Сам пакет доступен в репозитории CRAN. Предлагаем читателям пробовать и делиться своими впечатлениями (мы тоже скоро планируем).
- Появился список Altmetrics 500. Туда входят статьи, которые привлекли наибольшее внимание в Интернете в 2023 году: в новостях, цитатах, Википедии и X/Twitter.
Университетские рейтинги
- 30 мая вышел новый выпуск международного рейтинга университетов RUR. Всего в этом году в рейтинге 131 российский вуз, но в первую сотню попал только МГУ.
- 19 июня на XII ежегодном форуме ведущих вузов «Будущее высшей школы» был представлен рейтинг лучших российских вузов RAEX-100. В топ-3 — МГУ, Бауманка и МФТИ.
- 25 июня был опубликован свежий рейтинг USNews, в котором рассматривается 2250 вузов из более чем 100 стран. Из России в рейтинге 42 вуза, на первом месте по стране — Южно-Уральский государственный университет.
Наука в мире
- Планируемые изменения в системе Research Excellence Framework (Великобритания) вызывают у научных администаторов опасения: если учитывать в REF результаты работы сотрудников, работающих всего на 0,2 ставки (FTE), то университеты могут начать фиктивно нанимать сильных ученых для повышения своих показателей.
Наука в России
- ТюмГУ вслед за САФУ и МГПУ утвердил право студентов использовать генеративный ИИ при написании ВКР.
- Федеральная антимонопольная служба оштрафовала Яндекс за распостранение рекламы сервиса по написанию рефератов, курсовых и дипломных работ.
- Опубликован список победителей в конкурсе на “президентскую мегастипендию для аспирантов” в размере 75 тыс. рублей. Мы поздравляем победителей!
- Указом Президента РФ от 18.06.24 были утверждены обновленные а) приоритетные направления научно-тенхологического развития и б) перечень важнейших наукоемких технологий.
И бонусная новость: фармацевтическая компания «Ланцет» подала иск с требованием прекратить правовую охрану товарного знака The Lancet (и не только). Дело зарегистрировано под номером №СИП-589/2024, к участию привлекли и Роспатент. Пока что суд вынес определение об оставлении искового заявления без движения, но мы будем с интересом наблюдать за развитием событий.
#дайджест #новости #редакторскаяполитика #базыданных #наукавроссии #искуственныйинтеллект #рейтинги
{kind=link}
Чат-боты: цитировать или не цитировать?
Растущий интерес к использованию искусственного интеллекта (ИИ) в написании научных работ и ряд скандалов, связанных с его недобросовестным применением в академической сфере, провоцируют острую дискуссию. Летисия Антунес Ногейра (Leticia Antunes Nogueira), руководитель проекта по искусственному интеллекту, и Ян Уве Рейн (Jan Ove Rein), библиотекарь-исследователь, оба — сотрудники NTNU опубликовали заметку (ч. 1, ч. 2), в которой сосредоточились на критике концепции цитирования языковых моделей в научных публикациях.
В заметке авторы сузили фокус до двух моделей (ChatGPT от OpenAI или Claude от Anthropic), так как предполагают, что пользователи, которые работают с инструментами, применяющими возможности GenAI в сочетании с другими системами (например, Perplexity и Scopus AI), будут ссылаться на оригинальные источники.
В политике ведущих мировых издательств и академических организаций существует общее мнение насчет того, что чат-боты не отвечают минимальным требованиям к авторству, однако вопрос о том, можно ли (и следует ли) цитировать чат-боты в качестве источников, остается открытым.
Сторонники цитирования сообщений чат-ботов отмечают, что цитирование необходимо как минимум по двум причинам:
· признание чужого вклада и влияния идей;
· раскрытие источников информации.
Эти два, казалось бы, простых аспекта связаны с некоторыми противоречиями.
Противники цитирования (и иногда использования) чат-ботов подчеркивают, что результаты, полученные с использованием ИИ, преимущественно невозможно отследить, воспроизвести или проверить. В дополнение к этим ощутимым аргументам, исследователи акцентируют внимание на нескольких этических аспектах:
🔹Ответственность авторов
Языковая модель не может нести ответственность за утверждения, включенные в публикацию от её «лица». Одно дело цитировать организацию (например, доклад ООН), и совсем другое — чат-бота. Организации состоят из людей и поэтому несут ответственность за предоставляемую информацию, чат-бот или его разработчики нести такую ответственность не могут.
🔹Загрязнение информационной среды
Упоминание чат-ботов в источниках ведет к загрязнению информационных экосистем. Если для обучения больших языковых моделей использовать данные, сгенерированные ИИ (т. е. тексты из Интернета, академические тексты и т. д.), это приведет к ухудшению качества моделей.
🔹ИИ — не истина в последней инстанции
Чат-боты не создавались как инструменты для информационных целей. Неопределенность в отношении качества их ответов обусловлена назначением и структурой чат-ботов, а не степенью технологической зрелости. Большие языковые модели (LLM) основаны на моделях использования языка, а не на информации, и вероятностны по своему принципу работы, а это означает, что некорректный результат в таком случае — особенность, а не ошибка.
APA рекомендует цитировать текст, полученный от чат-бота, как результат работы алгоритма: а именно, ссылаться на автора алгоритма в списке источников. Дело в том, что результаты «переписки» с ChatGPT невозможно воспроизвести. Сейчас в APA такие данные часто цитируются как личная переписка, но это не совсем корректно, потому что сгенерированный текст не исходит от чьей-либо личности. В то же время ICMJE и Elsevier занимают однозначную позицию и рекомендуют авторам не ссылаться на чат-боты.
Появление чат-ботов бросает вызов устоявшимся представлениям об источниках, информации и знании, которые совсем недавно считались само собой разумеющимися. Тем не менее, в эпоху искусственного интеллекта обеспечение целостности информационной экосистемы требует все больших усилий. По мнению авторов, поскольку связность и смыслы в любом случае находятся «в глазах смотрящего», наборы слов, полученные в результате вероятностных вычислений, нельзя назвать ни источниками, ни информацией, ни знаниями. Текст, генерируемый чат-ботами — скорее, воплощение отсутствия информации.
#ChatGPT #ИИ #искусственныйинтеллект #цитирование
Растущий интерес к использованию искусственного интеллекта (ИИ) в написании научных работ и ряд скандалов, связанных с его недобросовестным применением в академической сфере, провоцируют острую дискуссию. Летисия Антунес Ногейра (Leticia Antunes Nogueira), руководитель проекта по искусственному интеллекту, и Ян Уве Рейн (Jan Ove Rein), библиотекарь-исследователь, оба — сотрудники NTNU опубликовали заметку (ч. 1, ч. 2), в которой сосредоточились на критике концепции цитирования языковых моделей в научных публикациях.
В заметке авторы сузили фокус до двух моделей (ChatGPT от OpenAI или Claude от Anthropic), так как предполагают, что пользователи, которые работают с инструментами, применяющими возможности GenAI в сочетании с другими системами (например, Perplexity и Scopus AI), будут ссылаться на оригинальные источники.
В политике ведущих мировых издательств и академических организаций существует общее мнение насчет того, что чат-боты не отвечают минимальным требованиям к авторству, однако вопрос о том, можно ли (и следует ли) цитировать чат-боты в качестве источников, остается открытым.
Сторонники цитирования сообщений чат-ботов отмечают, что цитирование необходимо как минимум по двум причинам:
· признание чужого вклада и влияния идей;
· раскрытие источников информации.
Эти два, казалось бы, простых аспекта связаны с некоторыми противоречиями.
Противники цитирования (и иногда использования) чат-ботов подчеркивают, что результаты, полученные с использованием ИИ, преимущественно невозможно отследить, воспроизвести или проверить. В дополнение к этим ощутимым аргументам, исследователи акцентируют внимание на нескольких этических аспектах:
🔹Ответственность авторов
Языковая модель не может нести ответственность за утверждения, включенные в публикацию от её «лица». Одно дело цитировать организацию (например, доклад ООН), и совсем другое — чат-бота. Организации состоят из людей и поэтому несут ответственность за предоставляемую информацию, чат-бот или его разработчики нести такую ответственность не могут.
🔹Загрязнение информационной среды
Упоминание чат-ботов в источниках ведет к загрязнению информационных экосистем. Если для обучения больших языковых моделей использовать данные, сгенерированные ИИ (т. е. тексты из Интернета, академические тексты и т. д.), это приведет к ухудшению качества моделей.
🔹ИИ — не истина в последней инстанции
Чат-боты не создавались как инструменты для информационных целей. Неопределенность в отношении качества их ответов обусловлена назначением и структурой чат-ботов, а не степенью технологической зрелости. Большие языковые модели (LLM) основаны на моделях использования языка, а не на информации, и вероятностны по своему принципу работы, а это означает, что некорректный результат в таком случае — особенность, а не ошибка.
APA рекомендует цитировать текст, полученный от чат-бота, как результат работы алгоритма: а именно, ссылаться на автора алгоритма в списке источников. Дело в том, что результаты «переписки» с ChatGPT невозможно воспроизвести. Сейчас в APA такие данные часто цитируются как личная переписка, но это не совсем корректно, потому что сгенерированный текст не исходит от чьей-либо личности. В то же время ICMJE и Elsevier занимают однозначную позицию и рекомендуют авторам не ссылаться на чат-боты.
Появление чат-ботов бросает вызов устоявшимся представлениям об источниках, информации и знании, которые совсем недавно считались само собой разумеющимися. Тем не менее, в эпоху искусственного интеллекта обеспечение целостности информационной экосистемы требует все больших усилий. По мнению авторов, поскольку связность и смыслы в любом случае находятся «в глазах смотрящего», наборы слов, полученные в результате вероятностных вычислений, нельзя назвать ни источниками, ни информацией, ни знаниями. Текст, генерируемый чат-ботами — скорее, воплощение отсутствия информации.
#ChatGPT #ИИ #искусственныйинтеллект #цитирование
Коротко и ясно: зависит ли цитируемость статьи от длины заголовка?
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
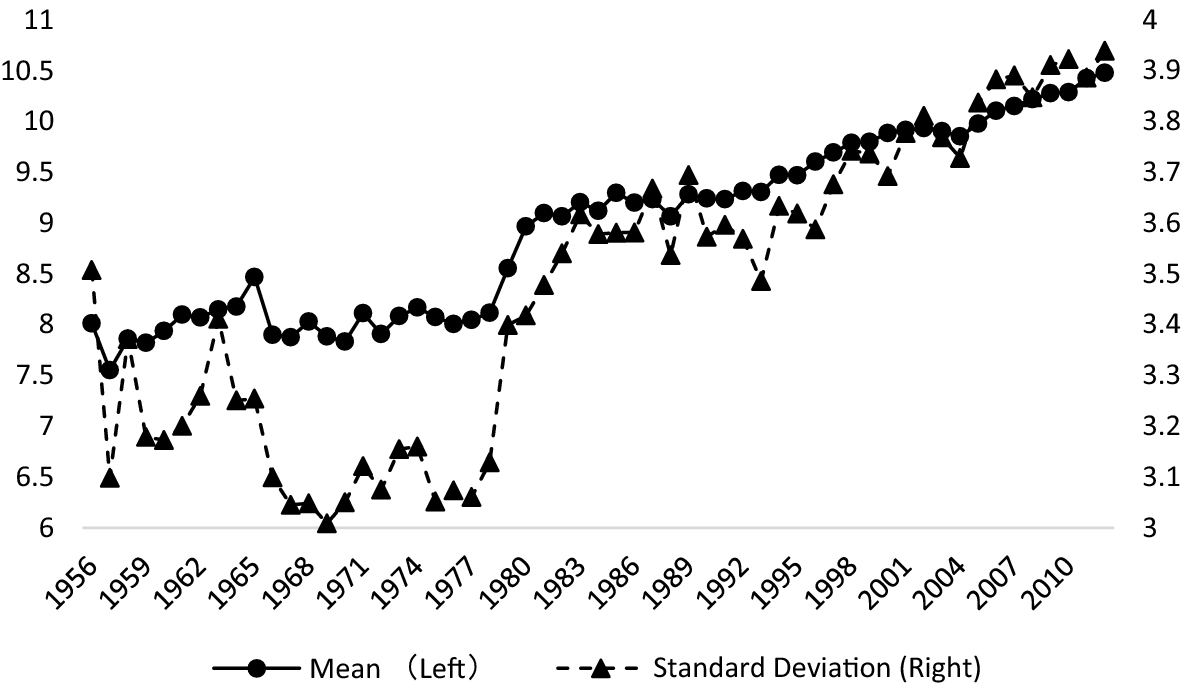
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
{kind=link}
«Стоковые» члены редколлегии в хищнических журналах
Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).
В июльском выпуске Learned Publishing вышла статья, посвященная описанию «стоковых» персонажей (stock characters) хищнических редколлегий, под которыми автор подразумевает ученых, которые одновременно входят в редколлегии 20 и более недобросовестных журналов.
В период с 2017 по 2023 год Майк Даунс (Mike Downes) тщательно изучал тысячи редакционных коллегий журналов, издатели которых входят в Список Билла (Beall's List). Им были обнаружены 96 исследователей, каждый из которых состоит в редколлегиях от 20 до 503 журналов (по состоянию на 2023 год).
В выборку вошли только хищнические журналы, редакционная политика которых допускает три этических нарушения:
🔹 фабрикация дат рецензирования статей;
🔹 кража личных данных;
🔹 заполнение архивов фальшивыми статьями.
По мнению автора, «стоковые» персонажи встречались настолько часто, что можно уверенно воспринимать их присутствие или отсутствие в качестве полноценного критерия, отличающего честного издателя от недобросовестного.
Такие персонажи, как правило, обращают на себя внимание за счет следующих «красных флагов»:
🔹 невозможность обнаружить профиль ученого на сайте вуза, в котором он якобы работает;
🔹 членство в редколлегиях журналов по двум и более несвязанным темам;
🔹 такой ученый практически никогда не встречается в редколлегии влиятельного журнала.
Конечно, информация о членах редколлегии может быть украдена полностью или частично, т.е. в некоторых случаях ученые не знают, что выступают в такой роли, но иногда исследователи добровольно вступают в такие редколлегии (в таких случаях они там же публикуют свои работы). Очевидно, что членство в совете редколлегии хищнического журнала, которое указано в разделе «Достижения» или в каком-либо схожем разделе биографии исследователя, нельзя назвать кражей личных данных.
Опасность заключается в том, что если имя ученого упоминается в хищнических редколлегиях сначала один, два, а потом несколько раз, и исследователь не замечает этого (или не хочет замечать), такое лицо легко становится типичной жертвой кражи личных данных.
Майк Даунс отмечает, что после его переписки с рядом «стоковых» персонажей, нескольким авторам, внесенным в редколлегии без их согласия, удалось немного исправить ситуацию. Например, один исследователь, который когда-то входил в 361 редколлегии, на данный момент состоит в 118. Однако существуют и мертвые «стоковые» персонажи, которые не могут за себя постоять (так, например, один профессор уже четвертый год после смерти продолжает занимать должность главного редактора журнала).
«Стоковые» персонажи включают в редакционные коллегии, чтобы создать впечатление, что журнал соответствует академическим стандартам. Согласно опросу автора, «стоковых» персонажей и многих других ученых, появлявшихся в редакционных коллегиях хищнических издательств, часто объединяет смутное воспоминание о том, что они согласились стать членом редакционной коллегии много лет назад и с тех пор больше ничего об этом не слышали. Внимательность в таких вопросах может помочь вовремя заметить кражу личных данных исследователя и принять соответствующие меры.
#predatoryjournals #хищническиежурналы #редколлегия #обзор
Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).
В июльском выпуске Learned Publishing вышла статья, посвященная описанию «стоковых» персонажей (stock characters) хищнических редколлегий, под которыми автор подразумевает ученых, которые одновременно входят в редколлегии 20 и более недобросовестных журналов.
В период с 2017 по 2023 год Майк Даунс (Mike Downes) тщательно изучал тысячи редакционных коллегий журналов, издатели которых входят в Список Билла (Beall's List). Им были обнаружены 96 исследователей, каждый из которых состоит в редколлегиях от 20 до 503 журналов (по состоянию на 2023 год).
В выборку вошли только хищнические журналы, редакционная политика которых допускает три этических нарушения:
🔹 фабрикация дат рецензирования статей;
🔹 кража личных данных;
🔹 заполнение архивов фальшивыми статьями.
По мнению автора, «стоковые» персонажи встречались настолько часто, что можно уверенно воспринимать их присутствие или отсутствие в качестве полноценного критерия, отличающего честного издателя от недобросовестного.
Такие персонажи, как правило, обращают на себя внимание за счет следующих «красных флагов»:
🔹 невозможность обнаружить профиль ученого на сайте вуза, в котором он якобы работает;
🔹 членство в редколлегиях журналов по двум и более несвязанным темам;
🔹 такой ученый практически никогда не встречается в редколлегии влиятельного журнала.
Конечно, информация о членах редколлегии может быть украдена полностью или частично, т.е. в некоторых случаях ученые не знают, что выступают в такой роли, но иногда исследователи добровольно вступают в такие редколлегии (в таких случаях они там же публикуют свои работы). Очевидно, что членство в совете редколлегии хищнического журнала, которое указано в разделе «Достижения» или в каком-либо схожем разделе биографии исследователя, нельзя назвать кражей личных данных.
Опасность заключается в том, что если имя ученого упоминается в хищнических редколлегиях сначала один, два, а потом несколько раз, и исследователь не замечает этого (или не хочет замечать), такое лицо легко становится типичной жертвой кражи личных данных.
Майк Даунс отмечает, что после его переписки с рядом «стоковых» персонажей, нескольким авторам, внесенным в редколлегии без их согласия, удалось немного исправить ситуацию. Например, один исследователь, который когда-то входил в 361 редколлегии, на данный момент состоит в 118. Однако существуют и мертвые «стоковые» персонажи, которые не могут за себя постоять (так, например, один профессор уже четвертый год после смерти продолжает занимать должность главного редактора журнала).
«Стоковые» персонажи включают в редакционные коллегии, чтобы создать впечатление, что журнал соответствует академическим стандартам. Согласно опросу автора, «стоковых» персонажей и многих других ученых, появлявшихся в редакционных коллегиях хищнических издательств, часто объединяет смутное воспоминание о том, что они согласились стать членом редакционной коллегии много лет назад и с тех пор больше ничего об этом не слышали. Внимательность в таких вопросах может помочь вовремя заметить кражу личных данных исследователя и принять соответствующие меры.
#predatoryjournals #хищническиежурналы #редколлегия #обзор
Выше квартилей pinned ««Стоковые» члены редколлегии в хищнических журналах Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).…»
Что с сайтами журналов в Elibrary?
В нашем канале мы уже неоднократно упоминали о феномене «похищенных» (hijacked) журналов (некоторые мошеннические издательства создают копии сайтов научных журналов, которые тяжело отличить от официальных страниц). В комментариях к апрельскому посту наш коллега отметил неактуальность некоторых доменов университетов из 1-Мониторинга, что навело нас на мысль: сколько неактуальных сайтов журналов сейчас присутствует в российском сегменте?
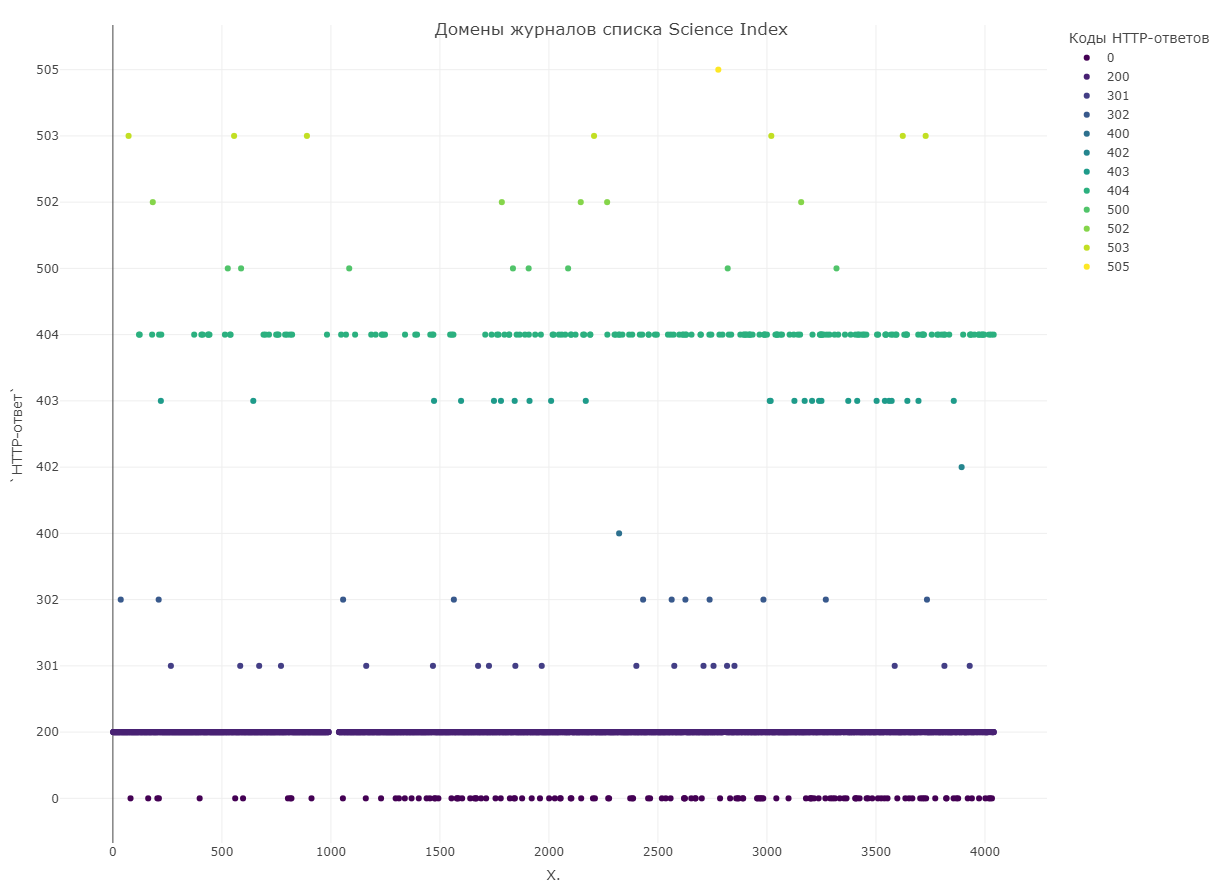
Для исследования мы выбрали рейтинг Science Index 2022, размещенный на Elibrary. В него входят 4044 журнала, в том числе 3058 журналов из списка ВАК. В Elibrary домашняя страница указана у 3786 (93,6%) из них. Для проверки ответов сервера мы использовали сервис https://coolakov.ru/tools/ping/, позволяющий отследить редиректы и получить итоговый адрес страницы (или 404, если страница не найдена).
Полученные данные мы разместили на диаграмме. По оси X указывается место журнала в рейтинге, а на оси Y — код ответа сервера. Распределение по ответам серверов следующее:
3397 журналов — код 2ХХ (успешная обработка запроса)
30 журналов — коды 3ХХ (редирект и после этого успешная обработка запроса)
209 журналов — коды 4ХХ (ошибка на стороне клиента — нет доступа или ошибочный адрес сайта)
21 журнал — коды 5ХХ (ошибка на стороне сервера — например, сайт временно недоступен)
129 журналов — код 0 (такой код сервис возвращал, если сайта просто не существует).
Итак, для 359 журналов (почти 9%) журналов из Science Index указаны некорректные адреса веб-страниц (при этом редиректов на подозрительные ресурсы мы не обнаружили). 209 журналов, сайты которых возвращают коды 4XX, как правило, поменяли адрес или архитектуру сайта — нужно только обновить данные. А вот 129 журналов с несуществующими сайтами вызывают больше беспокойства.
#аналитика #Elibrary #сайты
В нашем канале мы уже неоднократно упоминали о феномене «похищенных» (hijacked) журналов (некоторые мошеннические издательства создают копии сайтов научных журналов, которые тяжело отличить от официальных страниц). В комментариях к апрельскому посту наш коллега отметил неактуальность некоторых доменов университетов из 1-Мониторинга, что навело нас на мысль: сколько неактуальных сайтов журналов сейчас присутствует в российском сегменте?
Для исследования мы выбрали рейтинг Science Index 2022, размещенный на Elibrary. В него входят 4044 журнала, в том числе 3058 журналов из списка ВАК. В Elibrary домашняя страница указана у 3786 (93,6%) из них. Для проверки ответов сервера мы использовали сервис https://coolakov.ru/tools/ping/, позволяющий отследить редиректы и получить итоговый адрес страницы (или 404, если страница не найдена).
Полученные данные мы разместили на диаграмме. По оси X указывается место журнала в рейтинге, а на оси Y — код ответа сервера. Распределение по ответам серверов следующее:
3397 журналов — код 2ХХ (успешная обработка запроса)
30 журналов — коды 3ХХ (редирект и после этого успешная обработка запроса)
209 журналов — коды 4ХХ (ошибка на стороне клиента — нет доступа или ошибочный адрес сайта)
21 журнал — коды 5ХХ (ошибка на стороне сервера — например, сайт временно недоступен)
129 журналов — код 0 (такой код сервис возвращал, если сайта просто не существует).
Итак, для 359 журналов (почти 9%) журналов из Science Index указаны некорректные адреса веб-страниц (при этом редиректов на подозрительные ресурсы мы не обнаружили). 209 журналов, сайты которых возвращают коды 4XX, как правило, поменяли адрес или архитектуру сайта — нужно только обновить данные. А вот 129 журналов с несуществующими сайтами вызывают больше беспокойства.
#аналитика #Elibrary #сайты
{kind=link}
История библиометрических баз данных и их разновидностей. Часть 1
Научные базы данных обеспечивают доступность и систематизацию растущего потока статей, материалов конференций, патентов и других исследований. Сегодня обращение к Web of Science, Scopus или другим базам данных для поиска статей — рутина любого исследователя. Мы используем базы данных, не придавая большого значения их различиям и не задумываясь об истории их появления. В сегодняшнем посте, посвященном истории наукометрии, мы посмотрим, как происходило становление баз данных, окружающих нас сегодня.
#историянаукометрии #Scopus #WoS #MAG #OpenAlex
Научные базы данных обеспечивают доступность и систематизацию растущего потока статей, материалов конференций, патентов и других исследований. Сегодня обращение к Web of Science, Scopus или другим базам данных для поиска статей — рутина любого исследователя. Мы используем базы данных, не придавая большого значения их различиям и не задумываясь об истории их появления. В сегодняшнем посте, посвященном истории наукометрии, мы посмотрим, как происходило становление баз данных, окружающих нас сегодня.
#историянаукометрии #Scopus #WoS #MAG #OpenAlex
Telegraph
История библиометрических баз данных и их разновидностей. Часть 1
Использование обширных цифровых баз данных стало неотъемлемым элементом академической деятельности. Они позволяют не только искать материалы в отдельных областях, но и отслеживать публикационную активность, а также проводить сложные аналитические исследования…