
Google в своём блоге опубликовали пост про ALBERT, улучшенную версию Берта. Рекомендую к прочтению, если вам интересны детали, изложенные довольно простым языком.
https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html
https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html
Google Research
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
Posted by Radu Soricut and Zhenzhong Lan, Research Scientists, Google Research Ever since the advent of BERT a year ago, natural language research...
Reformer: The Efficient Transformer
Новогодние праздники ожидаемо привели к периоду затишья - давно не было интересных публикаций. И вот первая ласточка в этом году, да еще и на достаточно важную тему.
Относительно небольшой размер окна или ограниченная длина поддерживаемых текстов другими словами - это одна из ключевых проблем трансформерной архитектуры. Вычислительная сложность моделей растет пропорционально квадрату количества входных токенов (так уж устроен механизм внимания) и как следствие все распространённые трансформеры ограничены текстами размеров условного абзаца (3-5 предложений). Это делает их плохо применимым для обработки длинных текстов, приходится идти на всяческие ухищрения и компромиссы, которые серьезно снижают качество результата.
К данной проблеме ризерчеры подступаются с середины прошлого года, тот же Transformer XL целиком и полностью про эту проблему. Придумываются всякие механизмы долговременной памяти. Свежая работа подступается к этой проблеме с другой стороны. Также приятно видеть соотечественника в авторах.
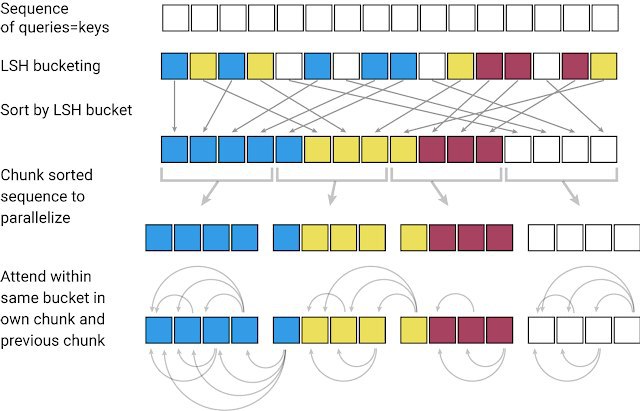
В Реформере эксплуатируется тот факт, что в трансформерах активации внимания бьются на довольно заметные кластеры и это можно использовать для того, чтобы сгруппировать входные токены в кластеры на основе Locality Sensitive Hashing (LSH) и считать внимание для кластеров, а не отдельных токенов что снижает вычислительную сложность слоев и соответственно позволяет увеличить размер входа при той же сложности.
Еще один хак для снижения требуемой слоями памяти это применение так называемых обратимых слоев (reversible layers), которые вместо хранения входов слоев которые нужны для back propagation позволяют их просто рассчитать.
В итоге авторы получили интересные результаты на текстах длиной в 64K, а также изображениях в 12Kb, которые по качеству сравнимы с классическими трансформерами (та же perplexity), но требуют гораздо меньше памяти и FLOPS.
Ну и отдельное спасибо, что вместе с работой опубликовали исходники и даже ноутбук в Колабе с примером
https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
https://arxiv.org/abs/2001.04451
https://colab.research.google.com/github/google/trax/blob/master/trax/intro.ipynb
https://github.com/google/trax
Новогодние праздники ожидаемо привели к периоду затишья - давно не было интересных публикаций. И вот первая ласточка в этом году, да еще и на достаточно важную тему.
Относительно небольшой размер окна или ограниченная длина поддерживаемых текстов другими словами - это одна из ключевых проблем трансформерной архитектуры. Вычислительная сложность моделей растет пропорционально квадрату количества входных токенов (так уж устроен механизм внимания) и как следствие все распространённые трансформеры ограничены текстами размеров условного абзаца (3-5 предложений). Это делает их плохо применимым для обработки длинных текстов, приходится идти на всяческие ухищрения и компромиссы, которые серьезно снижают качество результата.
К данной проблеме ризерчеры подступаются с середины прошлого года, тот же Transformer XL целиком и полностью про эту проблему. Придумываются всякие механизмы долговременной памяти. Свежая работа подступается к этой проблеме с другой стороны. Также приятно видеть соотечественника в авторах.
В Реформере эксплуатируется тот факт, что в трансформерах активации внимания бьются на довольно заметные кластеры и это можно использовать для того, чтобы сгруппировать входные токены в кластеры на основе Locality Sensitive Hashing (LSH) и считать внимание для кластеров, а не отдельных токенов что снижает вычислительную сложность слоев и соответственно позволяет увеличить размер входа при той же сложности.
Еще один хак для снижения требуемой слоями памяти это применение так называемых обратимых слоев (reversible layers), которые вместо хранения входов слоев которые нужны для back propagation позволяют их просто рассчитать.
В итоге авторы получили интересные результаты на текстах длиной в 64K, а также изображениях в 12Kb, которые по качеству сравнимы с классическими трансформерами (та же perplexity), но требуют гораздо меньше памяти и FLOPS.
Ну и отдельное спасибо, что вместе с работой опубликовали исходники и даже ноутбук в Колабе с примером
https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
https://arxiv.org/abs/2001.04451
https://colab.research.google.com/github/google/trax/blob/master/trax/intro.ipynb
https://github.com/google/trax
{kind=link}
Семнадцатикратное (17x) ускорение BERT от Microsoft
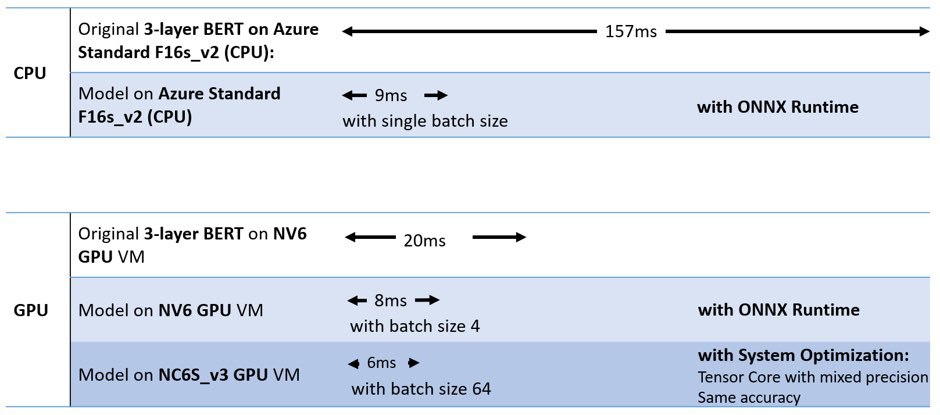
Отличная новость от Microsoft сегодня. Они выложили в открытый доступ свои оптимизированные версии Берта для вывода (inference) на CPU и GPU. Заявляют 17x ускорение на CPU (🔥🔥🔥) и всего лишь 3х на GPU без потери в качестве. Модели сделаны под ONNX Runtime. Говорится, что те же самые модельки используются в Бинге для реранжирования миллионов документов в секунду.
Круто чо. Будем смотреть.
https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
Отличная новость от Microsoft сегодня. Они выложили в открытый доступ свои оптимизированные версии Берта для вывода (inference) на CPU и GPU. Заявляют 17x ускорение на CPU (🔥🔥🔥) и всего лишь 3х на GPU без потери в качестве. Модели сделаны под ONNX Runtime. Говорится, что те же самые модельки используются в Бинге для реранжирования миллионов документов в секунду.
Круто чо. Будем смотреть.
https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
{kind=link}
Две статьи с разницей в один день и простой и казалось бы очевидной идеей. Тот случай когда думаешь почему этого никто не сделал раньше:
Efficient Document Re-Ranking for Transformers by Precomputing Term Representations - https://arxiv.org/abs/2004.14255
EARL: Speedup Transformer-based Rankers with Pre-computed Representation - https://arxiv.org/abs/2004.13313
Производительность трансформеров на инфиренсе уже набила оскомину, они с трудом заходят в real-time задачи такие как, например, реранжирование результатов. Масса усилий тратится на дистилляцию, прунинг, квантизацию с результатами которые на практике не влияют качественно на скорость вывода.
Авторы статей независимо друг от друга предлагают простой подход который позволяет ускорить реранжирование документов в поисковых задачах в несколько раз (заявляют 40x). Подход эксплуатирует особенность задачи реранжирования, когда одни и те же документы прогоняются для разных запросов много раз и наоборот для одного запроса оцениваются сотни разных документов,
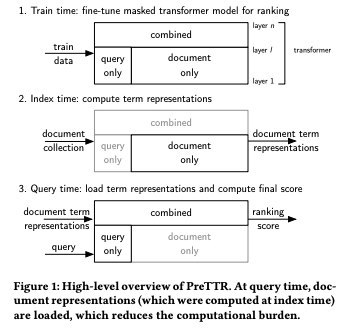
В классическом варианте для каждой пары запрос-документ формируется вход трансформера и прогоняется через все слои. Тем самым для одного и того же запроса его векторное представление рассчитывается сотни раз, а в случае множества запросов то же самое происходит для документов. Авторы предлагают немного затюнить классический трансформер и выделить в нем явно модули рассчитывающие представление запроса и документа, так чтобы вместо их расчета каждый раз результат можно было закешировать и использовать для повторных расчетов избегая массы ненужных вычислений. Такой подход позволил добиться ускорения реранжирования в 40 раз без заметной потери в качестве. В первой статье результаты оценивали на WebTrack 2012, во второй на MS Marco. Результаты сравнивали с Vanilla BERT.
Из интересного еще эксперименты авторов с кэшированием представлений с разных слоев трансформера. Практика показала, что без ущерба для качества можно кэшировать все кроме последнего 12-го уровня.
Efficient Document Re-Ranking for Transformers by Precomputing Term Representations - https://arxiv.org/abs/2004.14255
EARL: Speedup Transformer-based Rankers with Pre-computed Representation - https://arxiv.org/abs/2004.13313
Производительность трансформеров на инфиренсе уже набила оскомину, они с трудом заходят в real-time задачи такие как, например, реранжирование результатов. Масса усилий тратится на дистилляцию, прунинг, квантизацию с результатами которые на практике не влияют качественно на скорость вывода.
Авторы статей независимо друг от друга предлагают простой подход который позволяет ускорить реранжирование документов в поисковых задачах в несколько раз (заявляют 40x). Подход эксплуатирует особенность задачи реранжирования, когда одни и те же документы прогоняются для разных запросов много раз и наоборот для одного запроса оцениваются сотни разных документов,
В классическом варианте для каждой пары запрос-документ формируется вход трансформера и прогоняется через все слои. Тем самым для одного и того же запроса его векторное представление рассчитывается сотни раз, а в случае множества запросов то же самое происходит для документов. Авторы предлагают немного затюнить классический трансформер и выделить в нем явно модули рассчитывающие представление запроса и документа, так чтобы вместо их расчета каждый раз результат можно было закешировать и использовать для повторных расчетов избегая массы ненужных вычислений. Такой подход позволил добиться ускорения реранжирования в 40 раз без заметной потери в качестве. В первой статье результаты оценивали на WebTrack 2012, во второй на MS Marco. Результаты сравнивали с Vanilla BERT.
Из интересного еще эксперименты авторов с кэшированием представлений с разных слоев трансформера. Практика показала, что без ущерба для качества можно кэшировать все кроме последнего 12-го уровня.
{kind=link}
Всем привет!
Пришло время оживить этот канал и поводом для этого стал утром вопрос в личку от @SevaUstinov с просьбой расшарить один из моих постов в одном очень крутом приватном чатике.
Я конечно же не против, но вот сослаться на меня негде совершенно. Выпал на 5+ лет из публичного пространства. За это время очень много интересного произошло со мной и вокруг меня. В последний год часто подмывало, но никак не решался, не хотел брать на себя дополнительных обязательств, а тут прямо знак.
Сева, спасибо за этот пинок под задницу. Ну и раз уж пошла такая пьянка обязательная ссылка на Савин канал. Я его читаю давно от корочки до корочки потому что Сева ввязался в агентскую тему также рано как и я, но у него очень высокая насмотренность и интересные кейсы постоянно идут в канале.
https://t.me/vsevolodustinovchannel
Пришло время оживить этот канал и поводом для этого стал утром вопрос в личку от @SevaUstinov с просьбой расшарить один из моих постов в одном очень крутом приватном чатике.
Я конечно же не против, но вот сослаться на меня негде совершенно. Выпал на 5+ лет из публичного пространства. За это время очень много интересного произошло со мной и вокруг меня. В последний год часто подмывало, но никак не решался, не хотел брать на себя дополнительных обязательств, а тут прямо знак.
Сева, спасибо за этот пинок под задницу. Ну и раз уж пошла такая пьянка обязательная ссылка на Савин канал. Я его читаю давно от корочки до корочки потому что Сева ввязался в агентскую тему также рано как и я, но у него очень высокая насмотренность и интересные кейсы постоянно идут в канале.
https://t.me/vsevolodustinovchannel
Telegram
Всеволод Устинов (канал про ai и стартапы)
🚀 Строю https://Plurio.AI (ex-Elly), $4,5M raised
✅ Построил IT-Agency.ru и внедрил самоуправление
📍 Живу в SF
S16, F4F, SLP, Burning Man, Luna, Эволюция, ВМК
тг @SevaUstinov
instagram.com/sevaustinov.me
linkedin.com/in/sevaustinov
Реклама от 1250$
✅ Построил IT-Agency.ru и внедрил самоуправление
📍 Живу в SF
S16, F4F, SLP, Burning Man, Luna, Эволюция, ВМК
тг @SevaUstinov
instagram.com/sevaustinov.me
linkedin.com/in/sevaustinov
Реклама от 1250$
Очень кратко о себе. Теперь я - cлавянокиприот, технологический предприниматель, теперь уже серийный, математик, технарь, отец и триатлет.
Из основных достижений so far крепкая семья с тремя детьми (было 25 лет свадьбы в прошлом году), построенная с нуля и проданная в 2020 году компания Knoema (search engine for data) с миллионами пользователей по всему миру, несколько друзей (не так много как хотелось бы, но зато настоящие), ну и на закуску 5x Ironman включая экстремальный Patagonman.
О своих текущих проектах буду рассказывать постепенно, а в целом буду писать исключительно про личный опыт и делится исключительно собственными мыслями.
Из основных достижений so far крепкая семья с тремя детьми (было 25 лет свадьбы в прошлом году), построенная с нуля и проданная в 2020 году компания Knoema (search engine for data) с миллионами пользователей по всему миру, несколько друзей (не так много как хотелось бы, но зато настоящие), ну и на закуску 5x Ironman включая экстремальный Patagonman.
О своих текущих проектах буду рассказывать постепенно, а в целом буду писать исключительно про личный опыт и делится исключительно собственными мыслями.
Темы которые меня не просто интересуют, а именно волнуют следующие:
- физическое и ментальное здоровье и их связь с циклическими видами спорта, стоицизм и улучшение физики и менталки в 50 лет )
- накатывающая ИИ-сингулярность и все что с этим связано, каждый божий день испытываю смешанные чувства восхищения и ужаса от того что наблюдаю вокруг, ну и конечно все не так однозначно
- аналитика, данные и визуальная эстетика – темы которыми я профессионально занимаюсь и интересуюсь уже почти 30 лет
- менеджмент в айти и почему аджайл зло )
- всяческие байки из миров айтишнегов, предпринимателей, триатлетов, родителей
- философские мысли о мире и будущем
- физическое и ментальное здоровье и их связь с циклическими видами спорта, стоицизм и улучшение физики и менталки в 50 лет )
- накатывающая ИИ-сингулярность и все что с этим связано, каждый божий день испытываю смешанные чувства восхищения и ужаса от того что наблюдаю вокруг, ну и конечно все не так однозначно
- аналитика, данные и визуальная эстетика – темы которыми я профессионально занимаюсь и интересуюсь уже почти 30 лет
- менеджмент в айти и почему аджайл зло )
- всяческие байки из миров айтишнегов, предпринимателей, триатлетов, родителей
- философские мысли о мире и будущем
Channel name was changed to «43D: Все оттенки Бугая - эстетика, триатлон, родительство, предпринимательство и ИИ, вот так!»
Полетели! 🚀🚀🚀
У меня есть хобби-проект https://fragmata.info, напишу про него чуть позже подробнее. Захотелось мне про него рассказать всем кипрским СМИ. Надо найти контакты редакторов, авторов, сделать три версии материала на русском, английском, греческом и разослать. Вот для меня руками такое нудятина непосильная, не могу таким заниматься просто.
А сейчас за меня это делает Клодкод, снабженный контекстом и полным доступом в мою почту. И оно работает причем не с точки зрения процесса даже, а получения результатов. Вот пример статья в онлайн-издании https://cyprusbutterfly.com.cy/news/fragmata-besplatnyij-dashbord-pokazyivaet-situacziyu-s-presnoj-vodoj-na-kipre.
По сути у меня теперь есть собственный диджитал пиарщик )
Статью к слову тоже написал Клодкод, я ее только чуть подредактировал.
А сейчас за меня это делает Клодкод, снабженный контекстом и полным доступом в мою почту. И оно работает причем не с точки зрения процесса даже, а получения результатов. Вот пример статья в онлайн-издании https://cyprusbutterfly.com.cy/news/fragmata-besplatnyij-dashbord-pokazyivaet-situacziyu-s-presnoj-vodoj-na-kipre.
По сути у меня теперь есть собственный диджитал пиарщик )
Статью к слову тоже написал Клодкод, я ее только чуть подредактировал.
fragmata.info
Cyprus Dam & Reservoir Water Levels Today | Fragmata
Live dam and reservoir water levels across all 21 Cyprus dams. Current storage capacity, daily inflow data, drought forecasts, and interactive map for Kouris, Asprokremmos, Evretou, and more.
❤1🔥1
Кофейные заметки
Иными словами: культурное соответствие создает комфортную однородность. Культурный вклад создает продуктивное разнообразие. Первое приятно для команды, второе полезно для бизнеса. Очень хочется выбирать первое. Но надо - второе.
Меня уже давно очень интересуют параллели между естественным интеллектом и искусственным. Уж больно много возникает их в обучении и воспитании детей и тренировке языковых моделей )
С утра на глаза попались одна большая статья и один не очень длинный пост.
Вот статья - это обзор на методы обучения с подкреплением для LLM-ок
https://aweers.de/blog/2026/rl-for-llms/
А вот пост от уважаемого Дмитрия Волошина про culture fit и людей в корпоративных средах.
https://t.me/coffee_notes/1958
Может показаться какая между ними связь может быть вообще?
А связь абсолютно прямая, буквально в лоб. Проблема одна и та же - дизайн вознаграждения для обучения в определенной среде. Желающие могут прочитать оба и найти полное соответствие если очень захотят.
Ну и Дмитрий красавчик, отлично пояснил почему оптимизация на culture fit в организациях это зло. В нейросетках есть похожий эффект который называется коллапс репрезентаций )
Спасибо за внимание!
С утра на глаза попались одна большая статья и один не очень длинный пост.
Вот статья - это обзор на методы обучения с подкреплением для LLM-ок
https://aweers.de/blog/2026/rl-for-llms/
А вот пост от уважаемого Дмитрия Волошина про culture fit и людей в корпоративных средах.
https://t.me/coffee_notes/1958
Может показаться какая между ними связь может быть вообще?
А связь абсолютно прямая, буквально в лоб. Проблема одна и та же - дизайн вознаграждения для обучения в определенной среде. Желающие могут прочитать оба и найти полное соответствие если очень захотят.
Ну и Дмитрий красавчик, отлично пояснил почему оптимизация на culture fit в организациях это зло. В нейросетках есть похожий эффект который называется коллапс репрезентаций )
Спасибо за внимание!
aweers.de
State of RL for reasoning LLMs | A. Weers
PhD student
👍1
Если что в канале будет много как и глубоко технического контента, так и философско-предпринимательского. Я много читаю всякого, сохраняю для себя и буду делиться самым интересным тут. Собственно этот канал 6 лет назад таким и был с уклоном в техническое конечно.
Плюс буду рассказывать о своих проектах без купюр. Чистая практика и дистиллированный опыт который уверен многим будет интересен и полезен.
Плюс буду рассказывать о своих проектах без купюр. Чистая практика и дистиллированный опыт который уверен многим будет интересен и полезен.
❤1
SKILL.md
3.5 KB
Чат, делюсь одним очень маленьким, но прикольным скиллом, который сделал для себя. Называется a-ha skill и его задача замечать и фиксировать а-ха моменты во взаимодействии с агентом.
Я часто ловлю себя на мысли "блять, как ахуенно это надо сохранить для мемуаров и опционально поделиться с человечеством", но в угаре естественно забываешь и забиваешь. Вот и сделал скилл для этого. Можно вызвать явно через /aha плюс он сам ловит такие моменты и фиксирует в документик что вызвало ахуй и почему, уточняя если не очевидно из контекста. В итоге копится позитивчик и клевые кейсы.
Ну и искренне теперь думаю что это должна быть встроенная функция CC потому что такие штуки для RL бесценны.
Я часто ловлю себя на мысли "блять, как ахуенно это надо сохранить для мемуаров и опционально поделиться с человечеством", но в угаре естественно забываешь и забиваешь. Вот и сделал скилл для этого. Можно вызвать явно через /aha плюс он сам ловит такие моменты и фиксирует в документик что вызвало ахуй и почему, уточняя если не очевидно из контекста. В итоге копится позитивчик и клевые кейсы.
Ну и искренне теперь думаю что это должна быть встроенная функция CC потому что такие штуки для RL бесценны.