
项目中的专用调试器如何实现?分享一些来自项目中的思考
## 背景
在数据开发场景中,为了增强可维护性,我们增强了 SQL 的语法,定义了一个简单的开发语言。但是这带来了额外的使用成本。本文讨论了如何支持增强 SQL 的代码编辑和调试,以应对日常的开发工作。
## 内容:
调试器包含主要内容:
- 执行某一步骤,实现暂停、继续等流程控制功能
- 查看或设置执行过程中的变量
- 在断点过程中执行 sql
- 查询执行状态
- 查询执行步骤信息
全文阅读,请移步: https://brightliao.com/2021/04/10/data-development-tools/
#执行 ### #SQL #sql #https #com #增强 #开发 #查询 #步骤
## 背景
在数据开发场景中,为了增强可维护性,我们增强了 SQL 的语法,定义了一个简单的开发语言。但是这带来了额外的使用成本。本文讨论了如何支持增强 SQL 的代码编辑和调试,以应对日常的开发工作。
## 内容:
调试器包含主要内容:
- 执行某一步骤,实现暂停、继续等流程控制功能
- 查看或设置执行过程中的变量
- 在断点过程中执行 sql
- 查询执行状态
- 查询执行步骤信息

全文阅读,请移步: https://brightliao.com/2021/04/10/data-development-tools/
#执行 ### #SQL #sql #https #com #增强 #开发 #查询 #步骤
兄弟们,关于 sql 优化的问题想请教一下
最近学习了一下 sql 语句的优化入门,这里有个场景存在疑惑:
比如一个简单的查询,比如
select a,b,c,d from table order by d desc limit 0,100;
在 d 字段上创建普通索引,另外由于 b 字段可能会保存很大的数据,所以我认为创建联合索引(a,b,c,d)进行索引覆盖查询可能不好?问题如下:
1.这个查询属于 filesort ,效率不高,在表数据量不大的时候不会暴露问题,但是在数据量大的时候,时间就长了,这个场景下改如何优化呢?
2.我目前只知道强制使用 d 索引,或者创建我上面说的联合索引进行索引覆盖外,还有没有别的方法呢,另外,当一个字段保存的数据较多时,有必要创建联合索引吗,好像重复了上面的疑问。。求解。。
#索引 #创建 #数据量 #查询 #联合 #场景 #优化 #覆盖 #保存 #sql
最近学习了一下 sql 语句的优化入门,这里有个场景存在疑惑:
比如一个简单的查询,比如
select a,b,c,d from table order by d desc limit 0,100;
在 d 字段上创建普通索引,另外由于 b 字段可能会保存很大的数据,所以我认为创建联合索引(a,b,c,d)进行索引覆盖查询可能不好?问题如下:
1.这个查询属于 filesort ,效率不高,在表数据量不大的时候不会暴露问题,但是在数据量大的时候,时间就长了,这个场景下改如何优化呢?
2.我目前只知道强制使用 d 索引,或者创建我上面说的联合索引进行索引覆盖外,还有没有别的方法呢,另外,当一个字段保存的数据较多时,有必要创建联合索引吗,好像重复了上面的疑问。。求解。。
#索引 #创建 #数据量 #查询 #联合 #场景 #优化 #覆盖 #保存 #sql
[数据库内核方向开发职位] [北、上、杭、深、广、西、成、remote 等] [30K~70K]
[内核开发] : 存储层(索引、事务、文件系统、高可用、容灾备份等)。SQL 层( SQL 引擎、执行器、优化器、内存计算等); [工具生态开发] [管控开发] :要求数据库存储相关业务背景(其他业务后端暂不接受);
[产品类型] :OLTP 、OLTAP 、HTAP
[招聘公司] :头部云厂商、国企、强业务属性公司、数据库创业公司等。
前程序猿懂一丢丢数据库方向技术的小猎头。 欢迎加微信聊聊天儿,认识一下~
vx:Z2VsYWl3YW5n(base64) 请备注 v2 ,说明来意,谢谢哈。
重新发一下,上次有朋友说:没说薪资范围,能给到 30K 起的薪资,不设上限~
欢迎同行可以交流,但希望别冒充求职人选,挺丢人的~~~
#数据库 #SQL #薪资 #开发 #存储 #业务 #欢迎 #执行器 #容灾 #OLTP
[内核开发] : 存储层(索引、事务、文件系统、高可用、容灾备份等)。SQL 层( SQL 引擎、执行器、优化器、内存计算等); [工具生态开发] [管控开发] :要求数据库存储相关业务背景(其他业务后端暂不接受);
[产品类型] :OLTP 、OLTAP 、HTAP
[招聘公司] :头部云厂商、国企、强业务属性公司、数据库创业公司等。
前程序猿懂一丢丢数据库方向技术的小猎头。 欢迎加微信聊聊天儿,认识一下~
vx:Z2VsYWl3YW5n(base64) 请备注 v2 ,说明来意,谢谢哈。
重新发一下,上次有朋友说:没说薪资范围,能给到 30K 起的薪资,不设上限~
欢迎同行可以交流,但希望别冒充求职人选,挺丢人的~~~
#数据库 #SQL #薪资 #开发 #存储 #业务 #欢迎 #执行器 #容灾 #OLTP
请问如何通过 Python3 向 MySQL 写入 JSON 数据
软件版本:
Python 3.10
MySQL 8.0
Python3 字典
v = {['v' : 'v']}
转换为 json 字符串
vv = json.dumps(v)
构造 sql 语句
sql = "INSERT INTO table_name (column_name) VALUES (%s)" % (vv)
写入 MySQL
db.query(sql)
报错信息:
"pymysql.err.ProgrammingError: (1064, 'You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near \'p1": [.................."
我理解应该是 json 数据没有没有转义造成的。
于是尝试
vv = ‘"""’ + vv ‘"""’
报同样的错误。
请问各位大佬有什么解决办法能直接将 json 数据写入 MySQL 吗?
#MySQL #json #vv #sql #name #your #syntax #写入 #报错 #Python
软件版本:
Python 3.10
MySQL 8.0
Python3 字典
v = {['v' : 'v']}
转换为 json 字符串
vv = json.dumps(v)
构造 sql 语句
sql = "INSERT INTO table_name (column_name) VALUES (%s)" % (vv)
写入 MySQL
db.query(sql)
报错信息:
"pymysql.err.ProgrammingError: (1064, 'You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near \'p1": [.................."
我理解应该是 json 数据没有没有转义造成的。
于是尝试
vv = ‘"""’ + vv ‘"""’
报同样的错误。
请问各位大佬有什么解决办法能直接将 json 数据写入 MySQL 吗?
#MySQL #json #vv #sql #name #your #syntax #写入 #报错 #Python
团队自己写了个 ETL 自动化测试框架,给关注自动化测试或数据测试的同学们做参考
在基于 ETL 的数据开发中,如何构建一个 ETL 自动化测试框架?
我们利用 Excel 电子表格,构建了一个轻量级的框架。它可以方便的支持测试用例编写和运行,能有效提高团队工作效率。
一个测试用例定义如下:
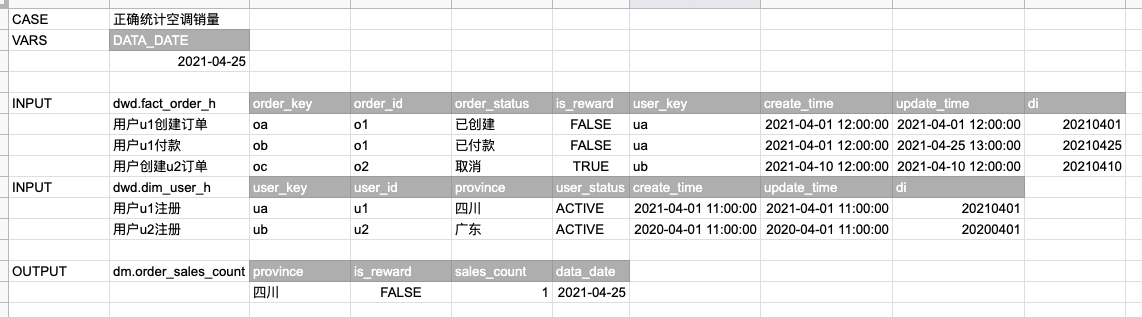
不过,ETL 测试框架虽然好用,但还需谨慎对待构建测试这件事,因为过多的测试可能会带来过高的维护成本。
有感兴趣的同学欢迎移步[这里]( https://brightliao.com/2021/04/25/data-testing-tool/)了解详情。
此测试框架已开源,项目地址为: https://github.com/easysql/easy_sql
测试相关功能介绍: https://easy-sql.readthedocs.io/en/latest/easy_sql/testing.html
#测试 #https #ETL #com #2021 #testing #easy #sql #框架 #测试用例
在基于 ETL 的数据开发中,如何构建一个 ETL 自动化测试框架?
我们利用 Excel 电子表格,构建了一个轻量级的框架。它可以方便的支持测试用例编写和运行,能有效提高团队工作效率。
一个测试用例定义如下:

不过,ETL 测试框架虽然好用,但还需谨慎对待构建测试这件事,因为过多的测试可能会带来过高的维护成本。
有感兴趣的同学欢迎移步[这里]( https://brightliao.com/2021/04/25/data-testing-tool/)了解详情。
此测试框架已开源,项目地址为: https://github.com/easysql/easy_sql
测试相关功能介绍: https://easy-sql.readthedocs.io/en/latest/easy_sql/testing.html
#测试 #https #ETL #com #2021 #testing #easy #sql #框架 #测试用例
withtyped: 写原生 SQL 即可拥有强类型 API 和客户端,数据库初始化工具,以及动态 OpenAPI 接口
新框架新概念层出不穷,业务总逃不过 CRUD 。与其加一层又一层抽象,或者是生成再同步代码,是不是可以换一个角度,直接处理数据库定义、前后端、和 API 文档之间的同步问题?
在解决完前后端的类型同步问题以后,结合最近的项目实践,我想干脆更进一步:
在 TypeScript 里写 SQL ,然后即可得到四个东西:
1. 数据库初始化工具
2. RESTful API 服务( CRUD API 开箱即用,深度定制也没问题)
3. 类型安全的 JS 客户端(基于 fetch ,并且能自动推导所有 API 的入参和出参)
4. 动态生成的 OpenAPI 接口
没有代码生成,没有同步时间 - 改一改 SQL ,上述四项就会同步变化,让 VSCode 的 IntelliSense 为你工作就行。
所有组件都是解耦的,比如可以只用路由和客户端,服务器用 Koa/Express/Next 应该都没问题。
字有点多,来张图吧:

⬇️ 项目地址
https://github.com/withtyped/withtyped
自己试了试感觉开发效率有所提升,欢迎大家拍砖讨论
#API #同步 #CRUD #SQL #https #withtyped #客户端 #数据库 #问题 #生成
新框架新概念层出不穷,业务总逃不过 CRUD 。与其加一层又一层抽象,或者是生成再同步代码,是不是可以换一个角度,直接处理数据库定义、前后端、和 API 文档之间的同步问题?
在解决完前后端的类型同步问题以后,结合最近的项目实践,我想干脆更进一步:
在 TypeScript 里写 SQL ,然后即可得到四个东西:
1. 数据库初始化工具
2. RESTful API 服务( CRUD API 开箱即用,深度定制也没问题)
3. 类型安全的 JS 客户端(基于 fetch ,并且能自动推导所有 API 的入参和出参)
4. 动态生成的 OpenAPI 接口
没有代码生成,没有同步时间 - 改一改 SQL ,上述四项就会同步变化,让 VSCode 的 IntelliSense 为你工作就行。
所有组件都是解耦的,比如可以只用路由和客户端,服务器用 Koa/Express/Next 应该都没问题。
字有点多,来张图吧:

⬇️ 项目地址
https://github.com/withtyped/withtyped
自己试了试感觉开发效率有所提升,欢迎大家拍砖讨论
#API #同步 #CRUD #SQL #https #withtyped #客户端 #数据库 #问题 #生成
请教 Springboot 接口 RPS 优化问题
目前的部署环境如下:
服务:jdk11 +springboot2.5
JVM 默认配置
阿里云 ECS 4c 16G * 2 + SLB 做负载均衡
RDS MySQL5.7 2c 8G 单机
Redis 主要做分布式锁
目前测试下来,TPS avg 500+,峰值 900+,业务异常大主要是 tryLock 没获取到锁直接 return 了。
领导说这配置理论应该能处理 5000 ,峰值可以到 8000 ?之前冷系统做的多,不太清楚,这个配置可以能到什么量级,虚心求教。sql 基本已做优化,没啥慢 sql 了。
请问下还有什么优化的方式吗?
[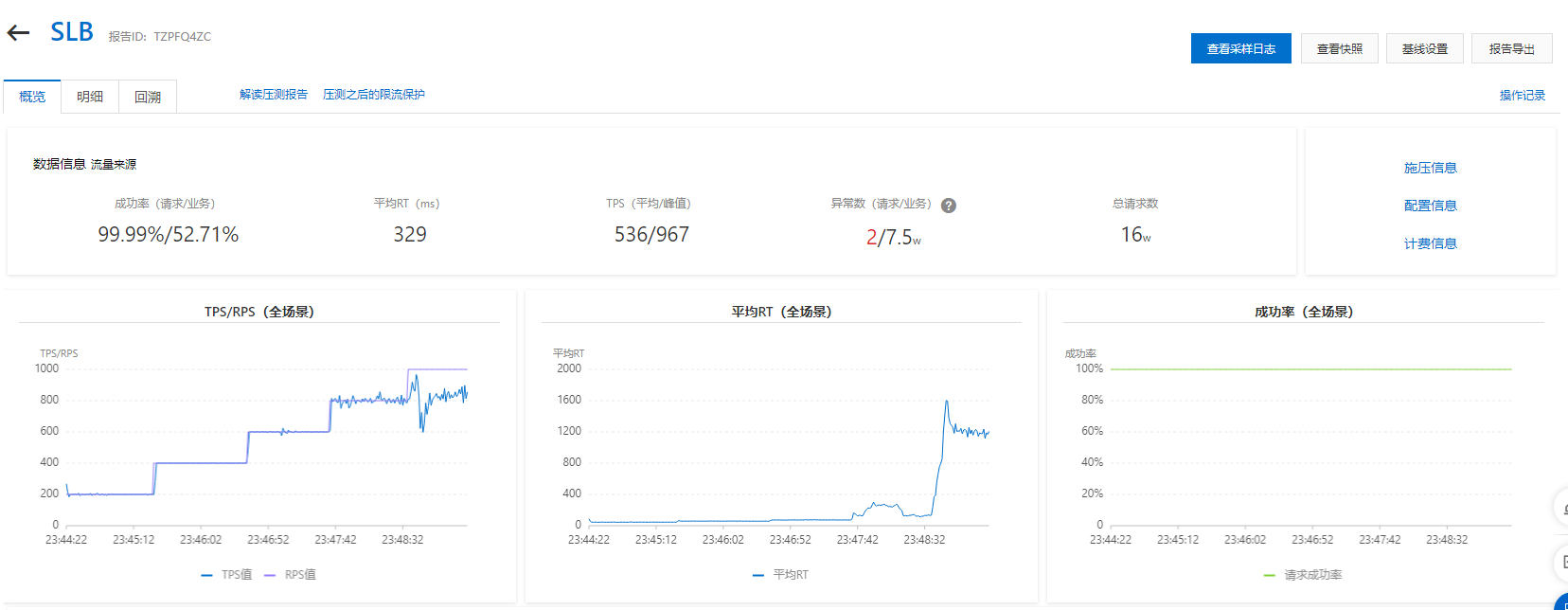]( https://imgse.com/i/zc04at)
#zc04at #sql #png #https #com #配置 #峰值 #优化 #jdk11 #springboot2.5
目前的部署环境如下:
服务:jdk11 +springboot2.5
JVM 默认配置
阿里云 ECS 4c 16G * 2 + SLB 做负载均衡
RDS MySQL5.7 2c 8G 单机
Redis 主要做分布式锁
目前测试下来,TPS avg 500+,峰值 900+,业务异常大主要是 tryLock 没获取到锁直接 return 了。
领导说这配置理论应该能处理 5000 ,峰值可以到 8000 ?之前冷系统做的多,不太清楚,这个配置可以能到什么量级,虚心求教。sql 基本已做优化,没啥慢 sql 了。
请问下还有什么优化的方式吗?
[]( https://imgse.com/i/zc04at)
#zc04at #sql #png #https #com #配置 #峰值 #优化 #jdk11 #springboot2.5
Python 调用 mysql 能否一次执行多条语句
现有一文件,其中存储大量 sql 语句,操作多个表,需要 python 读取并执行。
使用 mysqlclient 库,似乎只能一次执行一条语句,执行 100 条语句需要 100 次网络通信;
如果将语句用分号连接,调用 cursor.execute 会报:
MySQLdb._exceptions.ProgrammingError: (2014, "Commands out of sync; you can't run this command now")
cursor.executemany 方法只能对同一个表进行插入,不适用多表的情形。并且查看 executemany 的源码发现也是逐条请求的。
请问,一次网络请求执行多条 sql 语句,能否实现?
#语句 #sql #100 #cursor #executemany #执行 #请求 #多表 #源码 #python
现有一文件,其中存储大量 sql 语句,操作多个表,需要 python 读取并执行。
使用 mysqlclient 库,似乎只能一次执行一条语句,执行 100 条语句需要 100 次网络通信;
如果将语句用分号连接,调用 cursor.execute 会报:
MySQLdb._exceptions.ProgrammingError: (2014, "Commands out of sync; you can't run this command now")
cursor.executemany 方法只能对同一个表进行插入,不适用多表的情形。并且查看 executemany 的源码发现也是逐条请求的。
请问,一次网络请求执行多条 sql 语句,能否实现?
#语句 #sql #100 #cursor #executemany #执行 #请求 #多表 #源码 #python
后端开发工程师(远程工作岗位+海外本地生活业务)
工作职责:
- 负责后端业务分析、系统设计及优化,功能开发、把各类复杂业务拆解并实现;
- 理解业务需求,负责业务项目的分析拆解、架构设计、抽象实现、以及质量把控;
- 持续优化服务性能,优化服务架构,提升系统稳定性;
基本要求:
- 3 年以上后端开发经验;
- 熟练掌握 Java/PHP/Go 之一(Java 优先)开发语言及相关框架和开源库;
- 对基础数据结构与算法了解,熟悉常用设计模式,善于抽象、分析、归纳
- 熟悉 SQL 语法,对数据库的原理了解,具备常用的 SQL 优化能力,了解 NoSQL 及使用场景;
- 熟悉 HTTP 协议、缓存、线程模型、多线程编程等;
- 了解区块链及基础应用
- 主动积极,认真负责,良好的团队协作精神;
- 大并发背景开发者优先;
- 有区块链业务背景开发者优先;
- 本地生活应用背景开发者优先。
收入:
- 每月基础底薪:2w-4w ;
- 每月项目提成
产品类型:
- 海外美团、海外租房类型 app
面试:
- 联系邮箱: mengmeng77renshi@gmail.com
#开发者 #优先 #优化 #业务 #Java #SQL #区块 #了解 #拆解 #熟悉
工作职责:
- 负责后端业务分析、系统设计及优化,功能开发、把各类复杂业务拆解并实现;
- 理解业务需求,负责业务项目的分析拆解、架构设计、抽象实现、以及质量把控;
- 持续优化服务性能,优化服务架构,提升系统稳定性;
基本要求:
- 3 年以上后端开发经验;
- 熟练掌握 Java/PHP/Go 之一(Java 优先)开发语言及相关框架和开源库;
- 对基础数据结构与算法了解,熟悉常用设计模式,善于抽象、分析、归纳
- 熟悉 SQL 语法,对数据库的原理了解,具备常用的 SQL 优化能力,了解 NoSQL 及使用场景;
- 熟悉 HTTP 协议、缓存、线程模型、多线程编程等;
- 了解区块链及基础应用
- 主动积极,认真负责,良好的团队协作精神;
- 大并发背景开发者优先;
- 有区块链业务背景开发者优先;
- 本地生活应用背景开发者优先。
收入:
- 每月基础底薪:2w-4w ;
- 每月项目提成
产品类型:
- 海外美团、海外租房类型 app
面试:
- 联系邮箱: mengmeng77renshi@gmail.com
#开发者 #优先 #优化 #业务 #Java #SQL #区块 #了解 #拆解 #熟悉
springboot+mybatis 查询 oracle 无响应,直接执行 sql 正常返回结果
最近生产上碰到这么一个问题,百思不得其解。
一张表数据量大了,就做了按月分区。具体做法是先重命名旧表,然后新建分区表,后从旧表往新表导数据。
刚开始没注意,后面就发现,程序提交的```SELECT COUNT(*)```语句就是查不到结果,一直无响应最后接口请求超时,这个 SELECT 语句关联了三张表,包含上面新建的分区表。
奇怪的是,从日志中将 sql 拎出来直接执行,又能得到结果。但是从程序日志里看这个 sql 就是一直没有查到结果。
通过查询 V$SESSION 、V$SQL 等表,发现程序提交的 sql 都处在 ACTIVE 状态,事件类型是```'latch:cache buffers chains```,把会话杀掉也试过,还是不行,依旧是程序发起的查询无响应,直接执行 sql 就可以。
后来问公司 DBA ,他让执行下 ```analyze table 表名 compute statistics```,几张关联表都执行了下,后面就正常了。
这是什么原理?有懂的大神帮忙解答下吗?
#sql #分区表 #程序 #旧表 #SELECT #执行 #日志 #语句 #查询 #提交
最近生产上碰到这么一个问题,百思不得其解。
一张表数据量大了,就做了按月分区。具体做法是先重命名旧表,然后新建分区表,后从旧表往新表导数据。
刚开始没注意,后面就发现,程序提交的```SELECT COUNT(*)```语句就是查不到结果,一直无响应最后接口请求超时,这个 SELECT 语句关联了三张表,包含上面新建的分区表。
奇怪的是,从日志中将 sql 拎出来直接执行,又能得到结果。但是从程序日志里看这个 sql 就是一直没有查到结果。
通过查询 V$SESSION 、V$SQL 等表,发现程序提交的 sql 都处在 ACTIVE 状态,事件类型是```'latch:cache buffers chains```,把会话杀掉也试过,还是不行,依旧是程序发起的查询无响应,直接执行 sql 就可以。
后来问公司 DBA ,他让执行下 ```analyze table 表名 compute statistics```,几张关联表都执行了下,后面就正常了。
这是什么原理?有懂的大神帮忙解答下吗?
#sql #分区表 #程序 #旧表 #SELECT #执行 #日志 #语句 #查询 #提交
Liquibase 使用姿势求教
想通过 Liquibase 维护各个开发机 local 环境数据库结构的一致性,分别尝试了 maven plugin 和添加到 dependency 的方法。
不同工具 update 之后的 `DATABASECHANGELOG.FILENAME` 是不同的,比如用 `mvn liquibase:update` 得到 `src/main/resources/db/changelog/changelog.sql`。
启动 Spring Boot 程序的时候 Liquibase 读到的 changelog 文件路径是 `classpath:db/changelog/changelog.sql`,这两个路径差异会导致 `liquibase.changelog.filter.ShouldRunChangeSetFilter#changeSetsMatch` 方法返回 False ,让 Liquibase 认为这个 changeset 没有应用过,试图执行 SQL 语句创建表然后失败。
想问下一般生产实践都是怎么做的?禁止不同方法混用?
maven plugin 和 dependency 的版本都是 4.17.2 。
#changelog #Liquibase #maven #plugin #dependency #update #liquibase #db #sql #路径
想通过 Liquibase 维护各个开发机 local 环境数据库结构的一致性,分别尝试了 maven plugin 和添加到 dependency 的方法。
不同工具 update 之后的 `DATABASECHANGELOG.FILENAME` 是不同的,比如用 `mvn liquibase:update` 得到 `src/main/resources/db/changelog/changelog.sql`。
启动 Spring Boot 程序的时候 Liquibase 读到的 changelog 文件路径是 `classpath:db/changelog/changelog.sql`,这两个路径差异会导致 `liquibase.changelog.filter.ShouldRunChangeSetFilter#changeSetsMatch` 方法返回 False ,让 Liquibase 认为这个 changeset 没有应用过,试图执行 SQL 语句创建表然后失败。
想问下一般生产实践都是怎么做的?禁止不同方法混用?
maven plugin 和 dependency 的版本都是 4.17.2 。
#changelog #Liquibase #maven #plugin #dependency #update #liquibase #db #sql #路径
公司项目光对接口,有没有什么快速对接口的方法?
公司项目总是在不停的对接口,加解密还好,涉及到字段非常多的报文,挨个处理 json 、数据库、实体太费劲了,现在是手动把表建出来,然后用若依的代码生成器批量生成、下载、复制、粘贴,尤其是 spring 还得处理 dto 、entity 、vo 啥的,还要搞 service 、serviceImpl ,效率太低了
有没有什么快速对接口的方法?现在是准备用 nextjs 写个代码生成器,根据 json 自动生成主子表的 sql 、mapper 、bean 、controller 、vue components ,打包发布,已经完成了,sql 、mapper 、bean 的创建
是否还有其他更好 /效率更高的方式去对接口?
因为除了对接口还有写 vue 界面,无聊的一批
#对接口 #代码生成 #json #sql #mapper #bean #vue #效率 #生成 #加解密
公司项目总是在不停的对接口,加解密还好,涉及到字段非常多的报文,挨个处理 json 、数据库、实体太费劲了,现在是手动把表建出来,然后用若依的代码生成器批量生成、下载、复制、粘贴,尤其是 spring 还得处理 dto 、entity 、vo 啥的,还要搞 service 、serviceImpl ,效率太低了
有没有什么快速对接口的方法?现在是准备用 nextjs 写个代码生成器,根据 json 自动生成主子表的 sql 、mapper 、bean 、controller 、vue components ,打包发布,已经完成了,sql 、mapper 、bean 的创建
是否还有其他更好 /效率更高的方式去对接口?
因为除了对接口还有写 vue 界面,无聊的一批
#对接口 #代码生成 #json #sql #mapper #bean #vue #效率 #生成 #加解密
关于 MySQL 的全文查询,是不是没有高效的办法限定在一个结果集里搜全文?
打算给 App 加个简单的搜索功能,不想搞得太复杂,所以就先试了下 MySQL 内置的全文,
比如我要限定在一个用户的文章里搜:
```sql
select * from article
where
user_id = ?
match (title) against ('+???' in boolean mode)
```
这么干的话貌似会先用全文索引搜索全部用户的文章,然后按用户 ID 一行行过滤,我试了下性能似乎不太好,在千万非 SSD 表上要个 0.5 秒。
然后我看了下 MySQL 可以同时搜索二个关键词,那我建一列 meta ,放用户 ID,然后我同时搜索这个用户 ID 和关键词:
```sql
select * from article
where match (meta, title) against ('+??? +USERID_???' in boolean mode)
```
发现性能几乎完全一致也要 0.5 秒。
但我单搜一个关键词就非常快 0.001 秒级别的。
```sql
select * from article
where match (meta, title) against ('+???' in boolean mode)
```
所以 MySQL 的全文搜索就是只能搜索一个条件是非常快的,其它的条件都是在前一个搜索结果里过滤?
所以这是 MySQL 全文的限制还是别的全文方案也是只能搜索一个关键词才是快的?
所以你们实现搜索某用户的文章是用的什么办法?
#搜索 #MySQL #用户 #sql #select #article #where #match #title #against
打算给 App 加个简单的搜索功能,不想搞得太复杂,所以就先试了下 MySQL 内置的全文,
比如我要限定在一个用户的文章里搜:
```sql
select * from article
where
user_id = ?
match (title) against ('+???' in boolean mode)
```
这么干的话貌似会先用全文索引搜索全部用户的文章,然后按用户 ID 一行行过滤,我试了下性能似乎不太好,在千万非 SSD 表上要个 0.5 秒。
然后我看了下 MySQL 可以同时搜索二个关键词,那我建一列 meta ,放用户 ID,然后我同时搜索这个用户 ID 和关键词:
```sql
select * from article
where match (meta, title) against ('+??? +USERID_???' in boolean mode)
```
发现性能几乎完全一致也要 0.5 秒。
但我单搜一个关键词就非常快 0.001 秒级别的。
```sql
select * from article
where match (meta, title) against ('+???' in boolean mode)
```
所以 MySQL 的全文搜索就是只能搜索一个条件是非常快的,其它的条件都是在前一个搜索结果里过滤?
所以这是 MySQL 全文的限制还是别的全文方案也是只能搜索一个关键词才是快的?
所以你们实现搜索某用户的文章是用的什么办法?
#搜索 #MySQL #用户 #sql #select #article #where #match #title #against
mysql or 关键字的执行问题
关于 mysql 的 or 查询,比如 select...from...where name=xxx or age =xxx 。这一条 sql 语句,在 mysql 执行的时候,是把 sql 拆分为 select...from...where name=xxx 拿到结果临时存起来再执行 select...from...where age =xxx 再跟前面的结果进行合并呢,还是 就当做一条语句执行?因为,在看关于 or 的索引失效的问题,解决方案是 or 前后的字段都需要加索引,我感觉是把 select...from...where name=xxx or age =xxx 拆分开执行的?有没有大佬跟我讲解下。谢谢
#... #xxx #select #where #name #age #mysql #sql #执行 #语句
关于 mysql 的 or 查询,比如 select...from...where name=xxx or age =xxx 。这一条 sql 语句,在 mysql 执行的时候,是把 sql 拆分为 select...from...where name=xxx 拿到结果临时存起来再执行 select...from...where age =xxx 再跟前面的结果进行合并呢,还是 就当做一条语句执行?因为,在看关于 or 的索引失效的问题,解决方案是 or 前后的字段都需要加索引,我感觉是把 select...from...where name=xxx or age =xxx 拆分开执行的?有没有大佬跟我讲解下。谢谢
#... #xxx #select #where #name #age #mysql #sql #执行 #语句