
不用第三方 auth 库纯手写的情况下,怎么处理例如 passwd 或 token 之类的敏感信息?
因为有需要通过 keycloak 进行授权的需求,一开始是想找看有没有官方提供的 lib ,结果发现因为各种原因(比如说框架太新、依赖没更上等)并没有能用的,强行找一个的结果就是出现各种诡异的错误(比如说 userid 始终为 null )。
然后考虑能不能直接调用 http 请求,自行拼接 header 和 body……postman 测试完全可以,只要自己记得保存 access_token 和 refresh_token 就行了。但是问题来了……
把登入时需要的信息保存下来,也就是大概会创建一个长这样的 store:
```
{
client_id: string, client_secret: string, ...
}
```
而且在调用 http request 的时候,也会把用户名和密码直接传过去。如果在浏览器里面打断点的话,可以直接取得当前的用户名和密码。就算是 app client ,也是可以通过 hack 进内存的方式获得这些敏感信息的吧。
如果把这些 passwd 和 token 在 store 里面 encrypt 的话,问题在于和 keycloak 通信的时候需要传输这个 token 本身,也就是说 encrypt 的内容必须能够被解密,在已知源代码或源代码产生物的时候,这样就意味着白加密了。
那么一般对待这些敏感信息的话,该用什么方式来处理以防止信息泄漏呢?
话说过来也看了一下现在在用的客户端开发的框架里面的非官方 keycloak 封装库……感觉就是直接在 http api 上封装了一层,压根没有讨论到加密的内容……所以大概也是不符合要求的了。
#token #keycloak #http #client #源代码 #store #string #encrypt #用户名 #信息
因为有需要通过 keycloak 进行授权的需求,一开始是想找看有没有官方提供的 lib ,结果发现因为各种原因(比如说框架太新、依赖没更上等)并没有能用的,强行找一个的结果就是出现各种诡异的错误(比如说 userid 始终为 null )。
然后考虑能不能直接调用 http 请求,自行拼接 header 和 body……postman 测试完全可以,只要自己记得保存 access_token 和 refresh_token 就行了。但是问题来了……
把登入时需要的信息保存下来,也就是大概会创建一个长这样的 store:
```
{
client_id: string, client_secret: string, ...
}
```
而且在调用 http request 的时候,也会把用户名和密码直接传过去。如果在浏览器里面打断点的话,可以直接取得当前的用户名和密码。就算是 app client ,也是可以通过 hack 进内存的方式获得这些敏感信息的吧。
如果把这些 passwd 和 token 在 store 里面 encrypt 的话,问题在于和 keycloak 通信的时候需要传输这个 token 本身,也就是说 encrypt 的内容必须能够被解密,在已知源代码或源代码产生物的时候,这样就意味着白加密了。
那么一般对待这些敏感信息的话,该用什么方式来处理以防止信息泄漏呢?
话说过来也看了一下现在在用的客户端开发的框架里面的非官方 keycloak 封装库……感觉就是直接在 http api 上封装了一层,压根没有讨论到加密的内容……所以大概也是不符合要求的了。
#token #keycloak #http #client #源代码 #store #string #encrypt #用户名 #信息
RK3399PRO Android9 上调试 GC2053 报错无法打开摄像头问题
我处一款 RK3399PRO Android 9 产品,摄像头客户用 GC2053 ,这个摄像头在相同的硬件上跑 Debian 系统时工作是正常的,现将 Debian Linux Kernel (内核) 中的驱动移到 Android 9 上,从跟踪情况下内核驱动工作正常。Android 平台上的 camera3_profiles.xml 和 IQ 文件(gc2053_default_default.xml ,Android12 平台上有 GC2053 的配置,copy 过来用的)。运行系统内置的 Camera 应用时异常。暂时没找到异常原因
这个是摄像头 dts : http://gofile.me/4ZJ1m/W6eTeq0GT 密码 123456
这个是 dmesg: http://gofile.me/4ZJ1m/YC9rExA70 密码 123456
设备平台 rk3399pro, android9, 使用摄像头 gc2053
#摄像头 #Android #GC2053 #Debian #xml #gc2053 #default #http #gofile #me
我处一款 RK3399PRO Android 9 产品,摄像头客户用 GC2053 ,这个摄像头在相同的硬件上跑 Debian 系统时工作是正常的,现将 Debian Linux Kernel (内核) 中的驱动移到 Android 9 上,从跟踪情况下内核驱动工作正常。Android 平台上的 camera3_profiles.xml 和 IQ 文件(gc2053_default_default.xml ,Android12 平台上有 GC2053 的配置,copy 过来用的)。运行系统内置的 Camera 应用时异常。暂时没找到异常原因
这个是摄像头 dts : http://gofile.me/4ZJ1m/W6eTeq0GT 密码 123456
这个是 dmesg: http://gofile.me/4ZJ1m/YC9rExA70 密码 123456
设备平台 rk3399pro, android9, 使用摄像头 gc2053
#摄像头 #Android #GC2053 #Debian #xml #gc2053 #default #http #gofile #me
Python 折腾 web 交互的痛
py 折腾数据可视化是真的痛。各花了一个小时去看 pywebio 和 nicegui 的文档和魔改 demo ,但是发现还是不太舒服。
先说我的需求: 一个监控系统,用于显示任务进度信息(例如,当前进度,日志显示,脚本变量); 大体上可以看作搞一个 prometheus+tensorboard 的 GUI 。
想着是开一个 HTTP 服务器监听任务信息,然后套一个前端做可视化; 前端获取任务信息进行动态更新。
pywebio 和 nicegui ,或者说其他库,例如 streamlit 啥的都是基于多会话设计,也就是访问之间没有多大关联。然后实现上来说,同一个脚本开一个 HTTP 服务器监听,然后再跑一个 UI 框架是行不通。
换句话说,监听任务信息的 HTTP 服务器单独一个脚本,然后 UI 框架再额外一个脚本,之间使用 HTTP 或者数据库进行通信。这样折腾下来不仅部署挺麻烦,还要受限与 UI 框架。
目前得出来结论是,用 jQuery+Bootstrap+Ajax 是最合适。最大的痛点是 UI 控件以及要熟悉 CSS 排版。
如果弄 react/vue 什么的,UI 控件齐全,但是环境搭建好的时候,用前面的方法应该已经做完了。本身一共就不超过 300 行代码,折腾来折腾去不就是为了省时间。
不知道 dalao 们有什么其他想法?
#UI #HTTP #折腾 #监听 #服务器 #脚本 #控件 #一个 #pywebio #nicegui
py 折腾数据可视化是真的痛。各花了一个小时去看 pywebio 和 nicegui 的文档和魔改 demo ,但是发现还是不太舒服。
先说我的需求: 一个监控系统,用于显示任务进度信息(例如,当前进度,日志显示,脚本变量); 大体上可以看作搞一个 prometheus+tensorboard 的 GUI 。
想着是开一个 HTTP 服务器监听任务信息,然后套一个前端做可视化; 前端获取任务信息进行动态更新。
pywebio 和 nicegui ,或者说其他库,例如 streamlit 啥的都是基于多会话设计,也就是访问之间没有多大关联。然后实现上来说,同一个脚本开一个 HTTP 服务器监听,然后再跑一个 UI 框架是行不通。
换句话说,监听任务信息的 HTTP 服务器单独一个脚本,然后 UI 框架再额外一个脚本,之间使用 HTTP 或者数据库进行通信。这样折腾下来不仅部署挺麻烦,还要受限与 UI 框架。
目前得出来结论是,用 jQuery+Bootstrap+Ajax 是最合适。最大的痛点是 UI 控件以及要熟悉 CSS 排版。
如果弄 react/vue 什么的,UI 控件齐全,但是环境搭建好的时候,用前面的方法应该已经做完了。本身一共就不超过 300 行代码,折腾来折腾去不就是为了省时间。
不知道 dalao 们有什么其他想法?
#UI #HTTP #折腾 #监听 #服务器 #脚本 #控件 #一个 #pywebio #nicegui
微信在跟别人打电话的时候其他人给你打电话不占线了
微信在跟别人打电话的时候其他人给你打电话不占线了
rt ,怎么发图,会正常进线图片在这里 http://tieba.baidu.com/p/8205727418?&share=9105&fr=sharewise&is_video=false&unique=9E7BF2A34E2C1745F594458F606FBB1B&st=1672582831&client_type=1&client_version=12.32.1.1&sfc=copy&share_from=post&source=12_16_sharecard_a
#share #client #打电话 #微信 #不占线 #rt #发图 #http #tieba #baidu
微信在跟别人打电话的时候其他人给你打电话不占线了
rt ,怎么发图,会正常进线图片在这里 http://tieba.baidu.com/p/8205727418?&share=9105&fr=sharewise&is_video=false&unique=9E7BF2A34E2C1745F594458F606FBB1B&st=1672582831&client_type=1&client_version=12.32.1.1&sfc=copy&share_from=post&source=12_16_sharecard_a
#share #client #打电话 #微信 #不占线 #rt #发图 #http #tieba #baidu
vue3 vite3 gzip 提示 Failed to load module script
Failed to load module script: Expected a JavaScript module script but the server responded with a MIME type of “text/html”. Strict MIME type checking is enforced for module scripts per HTML spec
这是 nginx 配置
```
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
server_names_hash_bucket_size 3526;
server_names_hash_max_size 4096;
log_format combined_realip '$remote_addr $http_x_forwarded_for [$time_local]'
'$host "$request_uri" $status'
'"$http_referer" "$http_user_agent"';
sendfile on;
tcp_nopush on;
keepalive_timeout 300;
client_header_timeout 3m;
client_body_timeout 3m;
send_timeout 3m;
connection_pool_size 256;
client_header_buffer_size 16k;
large_client_header_buffers 8 4k;
request_pool_size 4k;
output_buffers 4 32k;
postpone_output 1460;
client_max_body_size 100m;
client_body_buffer_size 256k;
fastcgi_intercept_errors on;
tcp_nodelay on;
gzip on;
gzip_buffers 4 16k;
gzip_types text/plain application/javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
gzip_vary on;
upstream serveraddress{
server *****:8100;
}
server {
listen 8080;
root /usr/local/nginx/html/dist;
index index.html;
location / {
try_files $uri $uri/ @router;
index index.html;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location @router {
rewrite ^.*$ /index.html last;
}
location ~^/apis/{
rewrite ^/apis/(.*)$ /$1 break;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://serveraddress;
proxy_read_timeout 300s;
proxy_send_timeout 300s;
}
}
}
```
#proxy #header #log #size #error #timeout #client #server #html #http
Failed to load module script: Expected a JavaScript module script but the server responded with a MIME type of “text/html”. Strict MIME type checking is enforced for module scripts per HTML spec
这是 nginx 配置
```
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
server_names_hash_bucket_size 3526;
server_names_hash_max_size 4096;
log_format combined_realip '$remote_addr $http_x_forwarded_for [$time_local]'
'$host "$request_uri" $status'
'"$http_referer" "$http_user_agent"';
sendfile on;
tcp_nopush on;
keepalive_timeout 300;
client_header_timeout 3m;
client_body_timeout 3m;
send_timeout 3m;
connection_pool_size 256;
client_header_buffer_size 16k;
large_client_header_buffers 8 4k;
request_pool_size 4k;
output_buffers 4 32k;
postpone_output 1460;
client_max_body_size 100m;
client_body_buffer_size 256k;
fastcgi_intercept_errors on;
tcp_nodelay on;
gzip on;
gzip_buffers 4 16k;
gzip_types text/plain application/javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
gzip_vary on;
upstream serveraddress{
server *****:8100;
}
server {
listen 8080;
root /usr/local/nginx/html/dist;
index index.html;
location / {
try_files $uri $uri/ @router;
index index.html;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location @router {
rewrite ^.*$ /index.html last;
}
location ~^/apis/{
rewrite ^/apis/(.*)$ /$1 break;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://serveraddress;
proxy_read_timeout 300s;
proxy_send_timeout 300s;
}
}
}
```
#proxy #header #log #size #error #timeout #client #server #html #http
社保基数涨了 24%
http://bbs.xmfish.com/attachment/2023_01/0bf5a3d4d03bdb9e9188d71ec3d59929.jpg
除了医保其他的真不想交,工资没涨社保涨这么多,还有以前问了社保转移只能转个人部分,公司部分还被统筹了,等于大半白交了。
厦门今年社保基数涨幅到 24%,其他地方社保有涨吗?
#社保 #http #bbs #xmfish #com #attachment #2023 #01 #0bf5a3d4d03bdb9e9188d71ec3d59929 #jpg
http://bbs.xmfish.com/attachment/2023_01/0bf5a3d4d03bdb9e9188d71ec3d59929.jpg
除了医保其他的真不想交,工资没涨社保涨这么多,还有以前问了社保转移只能转个人部分,公司部分还被统筹了,等于大半白交了。
厦门今年社保基数涨幅到 24%,其他地方社保有涨吗?
#社保 #http #bbs #xmfish #com #attachment #2023 #01 #0bf5a3d4d03bdb9e9188d71ec3d59929 #jpg
suricata http.request_body 和 http_client_body 的区别?
我现在的工作是写入侵检测规则,suricata 关于 http 协议关键字部分也好好看了,但依然有问题不太懂。
官方手册 v6.0.9 中章节 6.12.20 中指出:
`http.request_body` replaces the previous keyword name: `http_client_body`. You may continue +to use the previous name, but it’s recommended that rules be converted to use +the new name.
实际上,我测试了一下,似乎不能直接替代:
```
# 没问题
alert http any any -> any any (msg:"Victure WR1200 系统命令执行漏洞 (CVE-2021-43283)"; flow:to_server,established; content:"password="; http_client_body; nocase; sid:650013; rev:1; gid:879013; priority:4;)
# 单纯只是把上面的 http_client_body 替换成了 http.request_body 报 error:nocase needs preceding content option
# 翻译过来是:nocase 需要前面的内容选项
alert http any any -> any any (msg:"Victure WR1200 系统命令执行漏洞 (CVE-2021-43283)"; flow:to_server,established; content:"password="; http.request_body; nocase; sid:650014; rev:1; gid:879014; priority:4;)
# 如果把 nocase 放到 content 的后面。报 error:rule 650015 setup buffer http_client_body but didn't add matches to it
# 翻译过来是:规则 650015 设置缓冲区 http_client_body 但没有添加匹配项
alert http any any -> any any (msg:"Victure WR1200 系统命令执行漏洞 (CVE-2021-43283)"; flow:to_server,established; content:"password="; nocase; http.request_body; sid:650015; rev:1; gid:879015; priority:4;)
# 如果把 http.request_body 放到 content 的前面,无报错
alert http any any -> any any (msg:"Victure WR1200 系统命令执行漏洞 (CVE-2021-43283)"; flow:to_server,established; http.request_body; content:"password="; nocase; sid:650016; rev:1; gid:879016; priority:4;)
```
所以,我感觉 http_client_body 是 content modifier ,而 http.request_body 是 sticky buffer 。
不知道我的理解对不对?
#http #any #body #content #request #nocase #client #alert #msg #Victure
我现在的工作是写入侵检测规则,suricata 关于 http 协议关键字部分也好好看了,但依然有问题不太懂。
官方手册 v6.0.9 中章节 6.12.20 中指出:
`http.request_body` replaces the previous keyword name: `http_client_body`. You may continue +to use the previous name, but it’s recommended that rules be converted to use +the new name.
实际上,我测试了一下,似乎不能直接替代:
```
# 没问题
alert http any any -> any any (msg:"Victure WR1200 系统命令执行漏洞 (CVE-2021-43283)"; flow:to_server,established; content:"password="; http_client_body; nocase; sid:650013; rev:1; gid:879013; priority:4;)
# 单纯只是把上面的 http_client_body 替换成了 http.request_body 报 error:nocase needs preceding content option
# 翻译过来是:nocase 需要前面的内容选项
alert http any any -> any any (msg:"Victure WR1200 系统命令执行漏洞 (CVE-2021-43283)"; flow:to_server,established; content:"password="; http.request_body; nocase; sid:650014; rev:1; gid:879014; priority:4;)
# 如果把 nocase 放到 content 的后面。报 error:rule 650015 setup buffer http_client_body but didn't add matches to it
# 翻译过来是:规则 650015 设置缓冲区 http_client_body 但没有添加匹配项
alert http any any -> any any (msg:"Victure WR1200 系统命令执行漏洞 (CVE-2021-43283)"; flow:to_server,established; content:"password="; nocase; http.request_body; sid:650015; rev:1; gid:879015; priority:4;)
# 如果把 http.request_body 放到 content 的前面,无报错
alert http any any -> any any (msg:"Victure WR1200 系统命令执行漏洞 (CVE-2021-43283)"; flow:to_server,established; http.request_body; content:"password="; nocase; sid:650016; rev:1; gid:879016; priority:4;)
```
所以,我感觉 http_client_body 是 content modifier ,而 http.request_body 是 sticky buffer 。
不知道我的理解对不对?
#http #any #body #content #request #nocase #client #alert #msg #Victure
家庭宽带对于 HTTP 流量的禁止策略到底是怎样的?会不会禁止高位端口的 HTTP?
家庭宽带有公网 IP ,希望可以直接暴露非 80 和 443 端口的 HTTP(S) 服务(使用高位端口)。感觉套一层 OpenVPN 还是有一点太麻烦,Tailscale 和 zerotier 有时候打洞没那么“智能”。
希望大家可以分享一下自己的经验,运营商到底是只关了 80 和 443 端口,还是说会禁止一切的 HTTP 出站流量?如果只是封特定端口的话,高位端口的 HTTPS 是否可以完全绕过这个限制?
#端口 #80 #443 #HTTP #高位 #公网 #IP #OpenVPN #Tailscale #zerotier
家庭宽带有公网 IP ,希望可以直接暴露非 80 和 443 端口的 HTTP(S) 服务(使用高位端口)。感觉套一层 OpenVPN 还是有一点太麻烦,Tailscale 和 zerotier 有时候打洞没那么“智能”。
希望大家可以分享一下自己的经验,运营商到底是只关了 80 和 443 端口,还是说会禁止一切的 HTTP 出站流量?如果只是封特定端口的话,高位端口的 HTTPS 是否可以完全绕过这个限制?
#端口 #80 #443 #HTTP #高位 #公网 #IP #OpenVPN #Tailscale #zerotier
调查大陆访问套 CF 网速
在这个 https://www.v2ex.com/t/905693 帖子中,经提醒发现 http 与 https 速度差异巨大,部分地区 https 被 QoS 非常严重,甚至只有 0.x Mbps ,而 http 却可以跑到 60+ Mbps.
麻烦大家用 http 和 https 分别测试。
http://cn-http.speed.ga
https://cn-https.speed.ga
#https #http #Mbps #cn #speed #ga #www #v2ex #com #905693
在这个 https://www.v2ex.com/t/905693 帖子中,经提醒发现 http 与 https 速度差异巨大,部分地区 https 被 QoS 非常严重,甚至只有 0.x Mbps ,而 http 却可以跑到 60+ Mbps.
麻烦大家用 http 和 https 分别测试。
http://cn-http.speed.ga
https://cn-https.speed.ga
#https #http #Mbps #cn #speed #ga #www #v2ex #com #905693
成都移动 1000M 测速
成都移动 1000M 宽带,用了几年了,其实还不错。国际出口也还可以。
附上一张测速,晚上 10 点测出来的,用的是移动自家的测速网 http://speed.sc.chinamobile.com/speedtest/task.html#/speedTest

#W0s8U #png #测速 #移动 #1000M #10 #点测 #http #speed #sc
成都移动 1000M 宽带,用了几年了,其实还不错。国际出口也还可以。
附上一张测速,晚上 10 点测出来的,用的是移动自家的测速网 http://speed.sc.chinamobile.com/speedtest/task.html#/speedTest

#W0s8U #png #测速 #移动 #1000M #10 #点测 #http #speed #sc
分享一个简约不小气的 Web 自建图床程序 sapic
时隔快 1000 天,引用之前 [/t/679950]( https://www.v2ex.com/t/679950) 帖子也有很多更新,再宣发一次。
正式名:sapic
一个自建 Web 图床程序,摒弃 Python 2 ,全面拥抱 Python 3 。
基于 Flask 的 Web 自建图床,默认存储在本地, 插件式支持又拍云、七牛云、腾讯云、阿里云、GitHub+jsDelivr 、Gitee 、S3 、[sm.ms]( http://sm.ms/) 、[superbed.cn]( http://superbed.cn/) 等,自由灵活的上传接口,多种上传方式(客户端、命令行、网页、用户脚本采集)。
- 项目地址: https://github.com/sapicd/sapic
- 文档地址: https://sapic.rtfd.vip
- 后续计划:重构、多端聚合、分组限定、小程序等
- 演示站点:[demo.sapicd.com - 账密是 demo/123456]( http://demo.sapicd.com)
- 截图:
- 首页上传
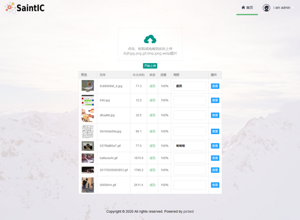
- 我的图片
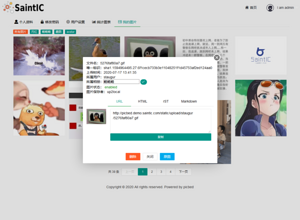
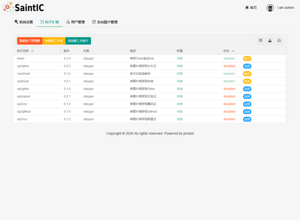
- 后台-钩子管理
#com #https #sapic #http #sapicd #demo #static #saintic #picbed #staugur
时隔快 1000 天,引用之前 [/t/679950]( https://www.v2ex.com/t/679950) 帖子也有很多更新,再宣发一次。
正式名:sapic
一个自建 Web 图床程序,摒弃 Python 2 ,全面拥抱 Python 3 。
基于 Flask 的 Web 自建图床,默认存储在本地, 插件式支持又拍云、七牛云、腾讯云、阿里云、GitHub+jsDelivr 、Gitee 、S3 、[sm.ms]( http://sm.ms/) 、[superbed.cn]( http://superbed.cn/) 等,自由灵活的上传接口,多种上传方式(客户端、命令行、网页、用户脚本采集)。
- 项目地址: https://github.com/sapicd/sapic
- 文档地址: https://sapic.rtfd.vip
- 后续计划:重构、多端聚合、分组限定、小程序等
- 演示站点:[demo.sapicd.com - 账密是 demo/123456]( http://demo.sapicd.com)
- 截图:
- 首页上传

- 我的图片

- 后台-钩子管理

#com #https #sapic #http #sapicd #demo #static #saintic #picbed #staugur
svn 有 git 的 url insteadof 功能吗?
git config --global url."http://192.168.1.10/".insteadof "https://www.test.cn/"
git 有上面这种功能,不知道 svn 有吗?
因为有几个 go 模块是在公司的 svn 服务器上,地址是 ip 形式的,而模块名是 xxx.com/xxx 形式的,又不想用 replace
#git #svn #xxx #模块 #config #-- #global #url #http #192.168
git config --global url."http://192.168.1.10/".insteadof "https://www.test.cn/"
git 有上面这种功能,不知道 svn 有吗?
因为有几个 go 模块是在公司的 svn 服务器上,地址是 ip 形式的,而模块名是 xxx.com/xxx 形式的,又不想用 replace
#git #svn #xxx #模块 #config #-- #global #url #http #192.168
鱼哈皮 一个轻松高效英语记单词和背单词的网站
[鱼哈皮]( http://www.yuhappy.com)记单词 [www.yuhappy.com]( http://www.yuhappy.com)
**使用键盘输入拼写代替传统手写的方式,实现 单词、短语 听写一体高效记忆**
适用人群:程序员、高考、四六级、考研、出国留学等需要强化记忆单词的非常有帮助
在开始介绍功能之前,让我们回忆一下当初考四六级的场景,在考试前的几个月,会使用手机或平板,打开一个记单词的 APP 或现在流行的随身带单词机, 然后选好一本词书,为了单词记忆更牢固,都会一边听读音同时拿着纸和笔抄写一遍单词和中文释义,尤其四六级、专四专八比较长的单词,不多听和抄写几遍是很难记住的
相信下面这张图应该可以勾引很多人的回忆,意志力不强大的人很难坚持下来
鱼哈皮记单词系统专为解决这些难题而生,与现有很多同质化的[记单词]( http://www.yuhappy.com)产品不同,**本产品的不同点如下**:
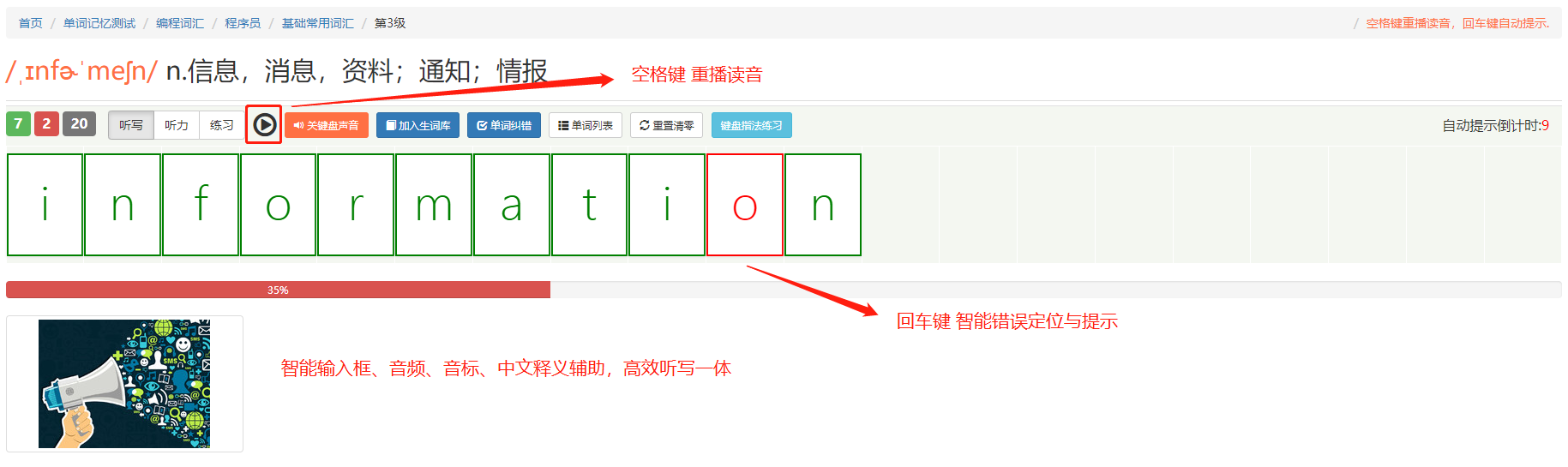
1. 使用输入框打字的形式来代替传统的手抄,辅以音频、音标、中文释义、图片, 极大加深并提高记忆效率。
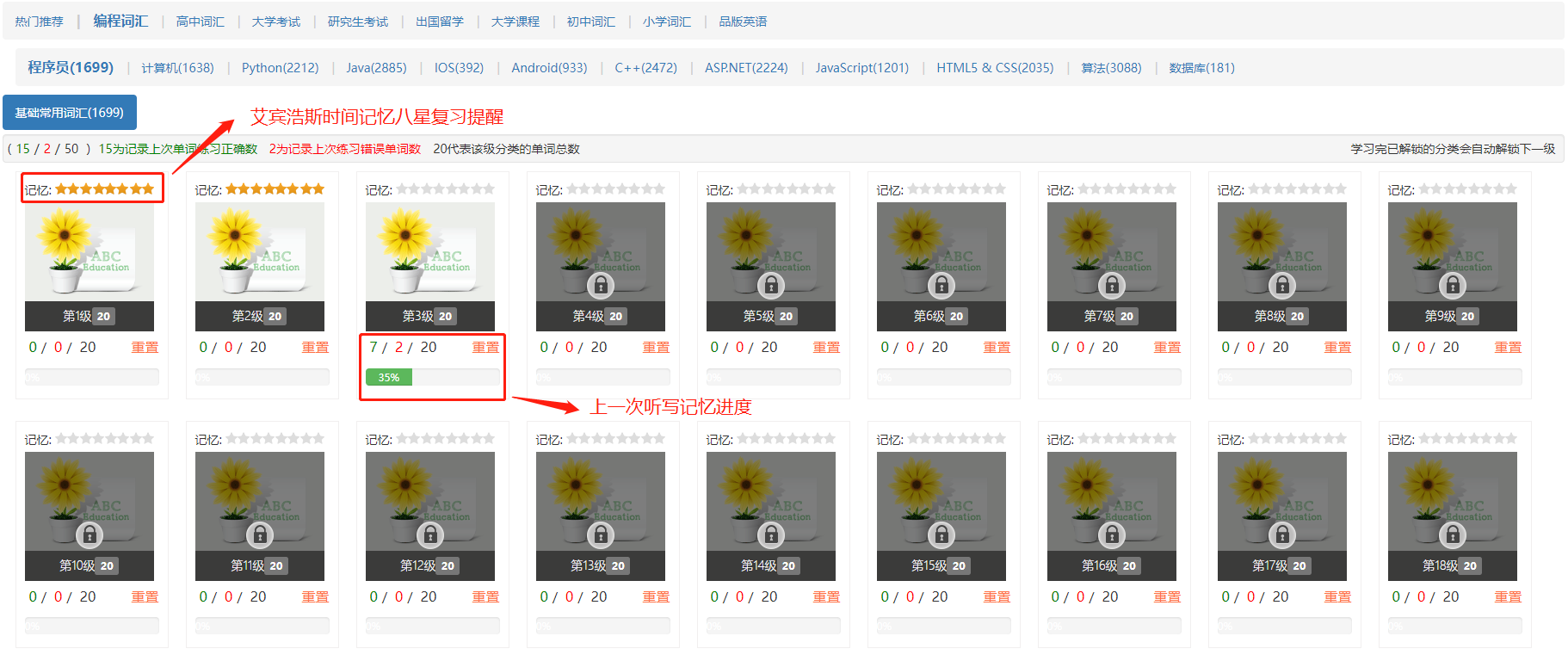
2. 以游戏关卡解锁的方式循序渐进记忆, 只有完成当前解锁的分类,才会解锁下一步分类继续学习。
3. 时间只花在记忆不牢固的单词上,输对的单词一次过本级不会再出现,对于不熟的单词,按下回车键,系统会精准定位单词单个字母级的错误高亮提示,且强制进入重复循环听写,直到一遍输对正确才会进入下一步单词,再长再难记的单词两三次回车键就轻松搞定。
4. 对于按下回车键的单词,系统除了强制重复拼写外,同时会加入 10 个错误单词的队列,当错误听写累计达到 10 个或到达本级最后一个单词时,都会进入错误单词队列,再次强制重复听写引导您进一步巩固记忆不牢的单词。
4. 引入艾宾浩斯遗忘曲线 8 星记忆提醒功能,一目了然地知道学过的词书分类需要重习了
目前系统单词书已覆盖精选编程、四六级、考研、雅思、托福完整的单词词库系统,适用于各阶段
选好一本词书,每天坚持 1 级或半小时,轻松高效记单词
不友好的地方,目前只有网站,小程序和手机 APP 多端正在规化中
限免中,欢迎各位大神大驾光临体验指导工作
#单词 #yuhappy #com #study #记忆 #听写 #www #四六级 #http #词书
[鱼哈皮]( http://www.yuhappy.com)记单词 [www.yuhappy.com]( http://www.yuhappy.com)
**使用键盘输入拼写代替传统手写的方式,实现 单词、短语 听写一体高效记忆**
适用人群:程序员、高考、四六级、考研、出国留学等需要强化记忆单词的非常有帮助
在开始介绍功能之前,让我们回忆一下当初考四六级的场景,在考试前的几个月,会使用手机或平板,打开一个记单词的 APP 或现在流行的随身带单词机, 然后选好一本词书,为了单词记忆更牢固,都会一边听读音同时拿着纸和笔抄写一遍单词和中文释义,尤其四六级、专四专八比较长的单词,不多听和抄写几遍是很难记住的
相信下面这张图应该可以勾引很多人的回忆,意志力不强大的人很难坚持下来

鱼哈皮记单词系统专为解决这些难题而生,与现有很多同质化的[记单词]( http://www.yuhappy.com)产品不同,**本产品的不同点如下**:
1. 使用输入框打字的形式来代替传统的手抄,辅以音频、音标、中文释义、图片, 极大加深并提高记忆效率。
2. 以游戏关卡解锁的方式循序渐进记忆, 只有完成当前解锁的分类,才会解锁下一步分类继续学习。
3. 时间只花在记忆不牢固的单词上,输对的单词一次过本级不会再出现,对于不熟的单词,按下回车键,系统会精准定位单词单个字母级的错误高亮提示,且强制进入重复循环听写,直到一遍输对正确才会进入下一步单词,再长再难记的单词两三次回车键就轻松搞定。
4. 对于按下回车键的单词,系统除了强制重复拼写外,同时会加入 10 个错误单词的队列,当错误听写累计达到 10 个或到达本级最后一个单词时,都会进入错误单词队列,再次强制重复听写引导您进一步巩固记忆不牢的单词。
4. 引入艾宾浩斯遗忘曲线 8 星记忆提醒功能,一目了然地知道学过的词书分类需要重习了

目前系统单词书已覆盖精选编程、四六级、考研、雅思、托福完整的单词词库系统,适用于各阶段

选好一本词书,每天坚持 1 级或半小时,轻松高效记单词
不友好的地方,目前只有网站,小程序和手机 APP 多端正在规化中
限免中,欢迎各位大神大驾光临体验指导工作
#单词 #yuhappy #com #study #记忆 #听写 #www #四六级 #http #词书
宝塔反向代理 Frp 的网站后根目录工作正常,其他资源都 404?
在家里电脑(家宽) 0.0.0.0:5000 绑定了一个服务,并用 frp 映射到了远程云主机的 127.0.0.1:5001
现在想要在云电脑上用 nginx 反代把 5001 暴露到公网,再绑定一个域名,这样就可以直接访问家里的服务。nginx 是用宝塔挂的。
遇到问题是,域名解析、反代和上证书看似都成功了。访问 home.example.com 是能正确接收到该服务根目录的 html 的,但是网页无法渲染,因为类似 home.example.com/assets/main.js 这种路由全都会跳 404 ,这是咋回事呢?(检查了一下云主机本地 wget 127.0.0.10:5001/assets/main.js 是可以正常获取文件的,frp 部分应该是工作正常)
网站完整配置:
```
server
{
listen 80;
listen 443 ssl http2;
server_name home.example.com;
root /www/wwwroot/home.example.com;
#SSL-START SSL 相关配置,请勿删除或修改下一行带注释的 404 规则
#error_page 404/404.html;
#HTTP_TO_HTTPS_START
if ($server_port !~ 443){
rewrite ^(/.*)$ https://$host$1 permanent;
}
#HTTP_TO_HTTPS_END
ssl_certificate /www/server/panel/vhost/cert/home.example.com/fullchain.pem;
ssl_certificate_key /www/server/panel/vhost/cert/home.example.com/privkey.pem;
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers EECDH+CHACHA20:EECDH+CHACHA20-draft:EECDH+AES128:RSA+AES128:EECDH+AES256:RSA+AES256:EECDH+3DES:RSA+3DES:!MD5;
ssl_prefer_server_ciphers on;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 10m;
add_header Strict-Transport-Security "max-age=31536000";
error_page 497 https://$host$request_uri;
#SSL-END
#PHP-INFO-START PHP 引用配置,可以注释或修改
include enable-php-00.conf;
#PHP-INFO-END
#REWRITE-START URL 重写规则引用,修改后将导致面板设置的伪静态规则失效
include /www/server/panel/vhost/rewrite/home.example.com.conf;
#REWRITE-END
location / {
proxy_pass http://127.0.0.1:5001/;
proxy_http_version 1.1;
client_max_body_size 100M;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
#禁止访问的文件或目录
location ~ ^/(\.user.ini|\.htaccess|\.git|\.svn|\.project|LICENSE|README.md)
{
return 404;
}
#一键申请 SSL 证书验证目录相关设置
location ~ \.well-known{
allow all;
}
location ~ .*\.(js|css)?$
{
expires 12h;
error_log /dev/null;
access_log /dev/null;
}
access_log /www/wwwlogs/home.example.com.log;
error_log /www/wwwlogs/home.example.com.error.log;
}
```
在家里电脑(家宽) 0.0.0.0:5000 绑定了一个服务,并用 frp 映射到了远程云主机的 127.0.0.1:5001
现在想要在云电脑上用 nginx 反代把 5001 暴露到公网,再绑定一个域名,这样就可以直接访问家里的服务。nginx 是用宝塔挂的。
遇到问题是,域名解析、反代和上证书看似都成功了。访问 home.example.com 是能正确接收到该服务根目录的 html 的,但是网页无法渲染,因为类似 home.example.com/assets/main.js 这种路由全都会跳 404 ,这是咋回事呢?(检查了一下云主机本地 wget 127.0.0.10:5001/assets/main.js 是可以正常获取文件的,frp 部分应该是工作正常)
网站完整配置:
```
server
{
listen 80;
listen 443 ssl http2;
server_name home.example.com;
root /www/wwwroot/home.example.com;
#SSL-START SSL 相关配置,请勿删除或修改下一行带注释的 404 规则
#error_page 404/404.html;
#HTTP_TO_HTTPS_START
if ($server_port !~ 443){
rewrite ^(/.*)$ https://$host$1 permanent;
}
#HTTP_TO_HTTPS_END
ssl_certificate /www/server/panel/vhost/cert/home.example.com/fullchain.pem;
ssl_certificate_key /www/server/panel/vhost/cert/home.example.com/privkey.pem;
ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers EECDH+CHACHA20:EECDH+CHACHA20-draft:EECDH+AES128:RSA+AES128:EECDH+AES256:RSA+AES256:EECDH+3DES:RSA+3DES:!MD5;
ssl_prefer_server_ciphers on;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 10m;
add_header Strict-Transport-Security "max-age=31536000";
error_page 497 https://$host$request_uri;
#SSL-END
#PHP-INFO-START PHP 引用配置,可以注释或修改
include enable-php-00.conf;
#PHP-INFO-END
#REWRITE-START URL 重写规则引用,修改后将导致面板设置的伪静态规则失效
include /www/server/panel/vhost/rewrite/home.example.com.conf;
#REWRITE-END
location / {
proxy_pass http://127.0.0.1:5001/;
proxy_http_version 1.1;
client_max_body_size 100M;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
#禁止访问的文件或目录
location ~ ^/(\.user.ini|\.htaccess|\.git|\.svn|\.project|LICENSE|README.md)
{
return 404;
}
#一键申请 SSL 证书验证目录相关设置
location ~ \.well-known{
allow all;
}
location ~ .*\.(js|css)?$
{
expires 12h;
error_log /dev/null;
access_log /dev/null;
}
access_log /www/wwwlogs/home.example.com.log;
error_log /www/wwwlogs/home.example.com.error.log;
}
```
CloudFlare Workers 可以直接获取 TLS 握手的 JA3 或 Client Hello 数据吗?
AWS 的 CloudFront 直接可以在 Header 中拿到 https://aws.amazon.com/cn/about-aws/whats-new/2022/11/amazon-cloudfront-supports-ja3-fingerprint-headers/ 而且是免费功能;找了一圈,发现 CF 虽然提供 `cf-ja3-hash` 这个请求头,但是仅企业用户可以获取。
https://developers.cloudflare.com/rules/transform/managed-transforms/reference/#http-request-headers
AWS 的 CloudFront 直接可以在 Header 中拿到 https://aws.amazon.com/cn/about-aws/whats-new/2022/11/amazon-cloudfront-supports-ja3-fingerprint-headers/ 而且是免费功能;找了一圈,发现 CF 虽然提供 `cf-ja3-hash` 这个请求头,但是仅企业用户可以获取。
https://developers.cloudflare.com/rules/transform/managed-transforms/reference/#http-request-headers
puppeteer 设置代理 IP 无法访问 www.google.com
const puppeteer = require('puppeteer');
(async () => {
const proxyServer = '代理服务器地址';
const proxyUser = '代理用户名';
const proxyPass = '代理密码';
const browser = await puppeteer.launch({
headless: false, // 非无头模式
args: [`--proxy-server=${proxyServer}`], // 设置代理服务器
});
const page = await browser.newPage();
// 配置代理认证
await page.authenticate({
username: proxyUser,
password: proxyPass
});
// 导航到指定页面
await page.goto("https://google.com", {waitUntil: "networkidle2"});
})();
puppeteer 设置代理 IP 无法打开 www.google.com
Error: net::ERR_CONNECTION_RESET at https://google.com
但是访问 https://ipinfo.io/又是正常的,请问是怎么回事呢?
- - - - - -- - - - - -
qping:建议用 Playwright,
设置 httpProxy 也很简单
https://playwright.dev/docs/network#http-proxy
jettzhang:@qping 现在才换 Playwright ,代价有点大
2024-01-06 14:23:38
const puppeteer = require('puppeteer');
(async () => {
const proxyServer = '代理服务器地址';
const proxyUser = '代理用户名';
const proxyPass = '代理密码';
const browser = await puppeteer.launch({
headless: false, // 非无头模式
args: [`--proxy-server=${proxyServer}`], // 设置代理服务器
});
const page = await browser.newPage();
// 配置代理认证
await page.authenticate({
username: proxyUser,
password: proxyPass
});
// 导航到指定页面
await page.goto("https://google.com", {waitUntil: "networkidle2"});
})();
puppeteer 设置代理 IP 无法打开 www.google.com
Error: net::ERR_CONNECTION_RESET at https://google.com
但是访问 https://ipinfo.io/又是正常的,请问是怎么回事呢?
- - - - - -- - - - - -
qping:建议用 Playwright,
设置 httpProxy 也很简单
https://playwright.dev/docs/network#http-proxy
jettzhang:@qping 现在才换 Playwright ,代价有点大
2024-01-06 14:23:38
今日分享,每日不定期分享开源技术,前端、后端/Go、运维/DevOps/云原生等,关注本帖
#今日分享 #HTTPClient #Fetch #Axios #Requests #Go #Node.js #Python
[go-zoox/fetch]( https://github.com/go-zoox/fetch) - 简单、好用、强大的 Go HTTP Client ,已经用在很多项目生产环境中,同时被收录到 [awesome-go]( https://github.com/avelino/awesome-go?tab=readme-ov-file#http-clients) ,已推荐到[阮一峰 Weekly]( https://github.com/ruanyf/weekly/issues/2607) ...
* 类别:Go
* 项目标题:简单、好用、强大的 Go HTTP Client
* 项目描述:
* 它是一个基于 Go HTTP Client 的上层应用,方便开发者使用,特别适合有前端 / Node.js 开发经验的开发者
* 支持 HTTP 基础方法
* 支持动态 JSON
* 支持超时/重试机制
* 支持取消机制
* 支持自定义代理
* 支持一键 Upload / Download
* 支持进度条等
更多用法,请访问 GitHub 查看
GitHub: https://github.com/go-zoox/fetch
#今日分享 #HTTPClient #Fetch #Axios #Requests #Go #Node.js #Python
[go-zoox/fetch]( https://github.com/go-zoox/fetch) - 简单、好用、强大的 Go HTTP Client ,已经用在很多项目生产环境中,同时被收录到 [awesome-go]( https://github.com/avelino/awesome-go?tab=readme-ov-file#http-clients) ,已推荐到[阮一峰 Weekly]( https://github.com/ruanyf/weekly/issues/2607) ...
* 类别:Go
* 项目标题:简单、好用、强大的 Go HTTP Client
* 项目描述:
* 它是一个基于 Go HTTP Client 的上层应用,方便开发者使用,特别适合有前端 / Node.js 开发经验的开发者
* 支持 HTTP 基础方法
* 支持动态 JSON
* 支持超时/重试机制
* 支持取消机制
* 支持自定义代理
* 支持一键 Upload / Download
* 支持进度条等
更多用法,请访问 GitHub 查看
GitHub: https://github.com/go-zoox/fetch