
这个 trojan 脚本大佬的 trojan 怎么和 nginx 共用 443 的哈~
是这个大佬的脚本 ->https://github.com/jinwyp/one_click_script
我看星星很多,想去抄抄配置,没想美白哈
这 nginx 主配置
```
# user www-data www-data;
user root;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" "$http_x_forwarded_for"';
access_log /nginxweb/nginx-access.log main;
error_log /nginxweb/nginx-error.log;
sendfile on;
#tcp_nopush on;
keepalive_timeout 120;
client_max_body_size 20m;
gzip on;
include /etc/nginx/conf.d/*.conf;
}
```
这是网站的 nginx 配置
```
server {
listen 80;
server_name domain.net;
root /nginxweb/html;
index index.php index.html index.htm;
location /75f0d3d7 {
proxy_pass http://127.0.0.1:27493;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
```
这是 trojan 的配置
```
{
"run_type": "server",
"local_addr": "0.0.0.0",
"local_port": 443,
"remote_addr": "127.0.0.1",
"remote_port": 80,
"password": [
"123",
"12345"
],
"log_level": 1,
"log_file": "/root/trojan-access.log",
"ssl": {
"verify": true,
"verify_hostname": true,
"cert": "/nginxweb/cert/fullchain.cer",
"key": "/nginxweb/cert/private.key",
"sni": "domain.net",
"fallback_addr": "127.0.0.1",
"fallback_port": 80,
"fingerprint": "chrome"
},
"websocket": {
"enabled": true,
"path": "/0a195182",
"host": "domain.net"
}
}
```
netstat -tlnp|grep 27493 也没看到 27493 端口有啥活动哈,链接不上的感觉哈~
#log #nginx #http #proxy #remote #addr #nginxweb #set #header #user
是这个大佬的脚本 ->https://github.com/jinwyp/one_click_script
我看星星很多,想去抄抄配置,没想美白哈
这 nginx 主配置
```
# user www-data www-data;
user root;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" "$http_x_forwarded_for"';
access_log /nginxweb/nginx-access.log main;
error_log /nginxweb/nginx-error.log;
sendfile on;
#tcp_nopush on;
keepalive_timeout 120;
client_max_body_size 20m;
gzip on;
include /etc/nginx/conf.d/*.conf;
}
```
这是网站的 nginx 配置
```
server {
listen 80;
server_name domain.net;
root /nginxweb/html;
index index.php index.html index.htm;
location /75f0d3d7 {
proxy_pass http://127.0.0.1:27493;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
```
这是 trojan 的配置
```
{
"run_type": "server",
"local_addr": "0.0.0.0",
"local_port": 443,
"remote_addr": "127.0.0.1",
"remote_port": 80,
"password": [
"123",
"12345"
],
"log_level": 1,
"log_file": "/root/trojan-access.log",
"ssl": {
"verify": true,
"verify_hostname": true,
"cert": "/nginxweb/cert/fullchain.cer",
"key": "/nginxweb/cert/private.key",
"sni": "domain.net",
"fallback_addr": "127.0.0.1",
"fallback_port": 80,
"fingerprint": "chrome"
},
"websocket": {
"enabled": true,
"path": "/0a195182",
"host": "domain.net"
}
}
```
netstat -tlnp|grep 27493 也没看到 27493 端口有啥活动哈,链接不上的感觉哈~
#log #nginx #http #proxy #remote #addr #nginxweb #set #header #user
nftables 防火墙问题,请大佬指教!
这是目前设定的规则
```bash
table inet filter {
chain input {
type filter hook input priority filter; policy drop;
ct state established,related counter accept
ct state invalid counter packets drop
ip protocol icmp accept
icmpv6 type { destination-unreachable, packet-too-big, time-exceeded, parameter-problem, echo-request, mld-listener-query, nd-router-solicit, nd-router-advert, nd-neighbor-solicit, nd-neighbor-advert } accept
iifname "lo" counter packets 0 bytes 0 accept
tcp dport xxx counter accept
meta nftrace set 1
}
chain ips {
type filter hook input priority filter - 2; policy accept;
ip saddr 1.1.1.1 counter accept
}
}
```
这是 tracing 调试日志( drop 日志)
```bash
trace id ab8ac050 inet filter ips packet: iif "eth0" ether saddr 00:2a:6a:a4:0c:c1 ether daddr 00:16:3e:73:d4:5a ip saddr 1.1.1.1 ip daddr 2.2.2.2 ip dscp 0x01 ip ecn not-ect ip ttl 113 ip id 4681 ip protocol tcp ip length 52 tcp sport 10551 tcp dport 23237 tcp flags == syn tcp window 64240
trace id ab8ac050 inet filter ips rule meta nftrace set 1 (verdict continue)
trace id ab8ac050 inet filter ips verdict continue
trace id ab8ac050 inet filter ips policy accept
trace id ab8ac050 inet filter input packet: iif "eth0" ether saddr 00:2a:6a:a4:0c:c1 ether daddr 00:16:3e:73:d4:5a ip saddr 1.1.1.1 ip daddr 2.2.2.2 ip dscp 0x01 ip ecn not-ect ip ttl 113 ip id 4681 ip protocol tcp ip length 52 tcp sport 10551 tcp dport 23237 tcp flags == syn tcp window 64240
trace id ab8ac050 inet filter input rule meta nftrace set 1 (verdict continue)
trace id ab8ac050 inet filter input verdict continue
trace id ab8ac050 inet filter input policy drop
```
这是 tracing 调试日志( accept 日志)
```bash
trace id b1cb1361 inet filter ips packet: iif "eth0" ether saddr 00:2a:6a:a4:0c:c1 ether daddr 00:16:3e:73:d4:5a ip saddr 3.3.3.3 ip daddr 2.2.2.2 ip dscp 0x01 ip ecn not-ect ip ttl 113 ip id 19123 ip protocol tcp ip length 64 tcp sport 6678 tcp dport 23237 tcp flags == 0x18 tcp window 1026
trace id b1cb1361 inet filter ips rule meta nftrace set 1 (verdict continue)
trace id b1cb1361 inet filter ips verdict continue
trace id b1cb1361 inet filter ips policy accept
trace id b1cb1361 inet filter input packet: iif "eth0" ether saddr 00:2a:6a:a4:0c:c1 ether daddr 00:16:3e:73:d4:5a ip saddr 3.3.3.3 ip daddr 2.2.2.2 ip dscp 0x01 ip ecn not-ect ip ttl 113 ip id 19123 ip protocol tcp ip length 64 tcp sport 6678 tcp dport 23237 tcp flags == 0x18 tcp window 1026
trace id b1cb1361 inet filter input rule ct state established,related counter packets 1262 bytes 160127 accept (verdict accept)
```
描述:3.3.3.3 已经通过 ssh 登录到 2.2.2.2 服务器,accept 日志最后检查 tcp 状态通过了防火墙
我的问题是:ips chain 里面的 IP 无法通过防火墙,请大佬指点!
#ip #tcp #filter #id #inet #trace #accept #ips #2.2 #input
这是目前设定的规则
```bash
table inet filter {
chain input {
type filter hook input priority filter; policy drop;
ct state established,related counter accept
ct state invalid counter packets drop
ip protocol icmp accept
icmpv6 type { destination-unreachable, packet-too-big, time-exceeded, parameter-problem, echo-request, mld-listener-query, nd-router-solicit, nd-router-advert, nd-neighbor-solicit, nd-neighbor-advert } accept
iifname "lo" counter packets 0 bytes 0 accept
tcp dport xxx counter accept
meta nftrace set 1
}
chain ips {
type filter hook input priority filter - 2; policy accept;
ip saddr 1.1.1.1 counter accept
}
}
```
这是 tracing 调试日志( drop 日志)
```bash
trace id ab8ac050 inet filter ips packet: iif "eth0" ether saddr 00:2a:6a:a4:0c:c1 ether daddr 00:16:3e:73:d4:5a ip saddr 1.1.1.1 ip daddr 2.2.2.2 ip dscp 0x01 ip ecn not-ect ip ttl 113 ip id 4681 ip protocol tcp ip length 52 tcp sport 10551 tcp dport 23237 tcp flags == syn tcp window 64240
trace id ab8ac050 inet filter ips rule meta nftrace set 1 (verdict continue)
trace id ab8ac050 inet filter ips verdict continue
trace id ab8ac050 inet filter ips policy accept
trace id ab8ac050 inet filter input packet: iif "eth0" ether saddr 00:2a:6a:a4:0c:c1 ether daddr 00:16:3e:73:d4:5a ip saddr 1.1.1.1 ip daddr 2.2.2.2 ip dscp 0x01 ip ecn not-ect ip ttl 113 ip id 4681 ip protocol tcp ip length 52 tcp sport 10551 tcp dport 23237 tcp flags == syn tcp window 64240
trace id ab8ac050 inet filter input rule meta nftrace set 1 (verdict continue)
trace id ab8ac050 inet filter input verdict continue
trace id ab8ac050 inet filter input policy drop
```
这是 tracing 调试日志( accept 日志)
```bash
trace id b1cb1361 inet filter ips packet: iif "eth0" ether saddr 00:2a:6a:a4:0c:c1 ether daddr 00:16:3e:73:d4:5a ip saddr 3.3.3.3 ip daddr 2.2.2.2 ip dscp 0x01 ip ecn not-ect ip ttl 113 ip id 19123 ip protocol tcp ip length 64 tcp sport 6678 tcp dport 23237 tcp flags == 0x18 tcp window 1026
trace id b1cb1361 inet filter ips rule meta nftrace set 1 (verdict continue)
trace id b1cb1361 inet filter ips verdict continue
trace id b1cb1361 inet filter ips policy accept
trace id b1cb1361 inet filter input packet: iif "eth0" ether saddr 00:2a:6a:a4:0c:c1 ether daddr 00:16:3e:73:d4:5a ip saddr 3.3.3.3 ip daddr 2.2.2.2 ip dscp 0x01 ip ecn not-ect ip ttl 113 ip id 19123 ip protocol tcp ip length 64 tcp sport 6678 tcp dport 23237 tcp flags == 0x18 tcp window 1026
trace id b1cb1361 inet filter input rule ct state established,related counter packets 1262 bytes 160127 accept (verdict accept)
```
描述:3.3.3.3 已经通过 ssh 登录到 2.2.2.2 服务器,accept 日志最后检查 tcp 状态通过了防火墙
我的问题是:ips chain 里面的 IP 无法通过防火墙,请大佬指点!
#ip #tcp #filter #id #inet #trace #accept #ips #2.2 #input
OpenWRT 路由器疑似干扰了 IPv6 的 TCP 连接,应该如何排查?有偿。
环境:Nano Pi R2S / OpenWrt 21.02.1
现象:经过路由器的 IPv6 TCP 连接,不管流量大小,随机时间后会被掐断,具体表现是触发重传,然后 Client 会向 Server 发送一个 RST 包导致连接断开。
这个 TCP 连接可以不经过公网,例如我的 LAN 网络和 Wireguard 虚拟网络中的设备通讯,也会出现上述问题,故排除了宽带运营商的锅(我的 Wireguard 接入点是 IPv4 的)。
这种情况应该怎么排查?附图是我 Wireguard 网络中的设备连接 LAN 中的设备,SSH 协议,client 和 server 的抓包情况。
其他说明:
1. 这个问题是两个月前才出现的,此前 IPv6 使用良好,两个月间搬过家、更新过某些 opkg 包
2. ICMPv6 确定不受影响,UDP 理论上也不受影响(未测试)
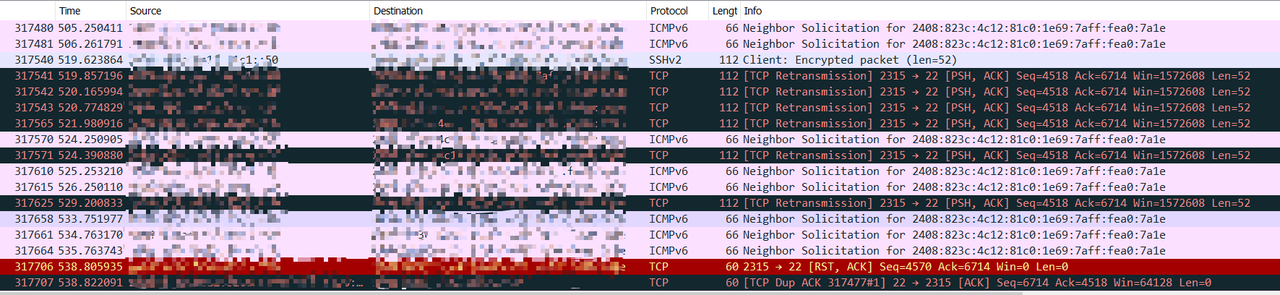
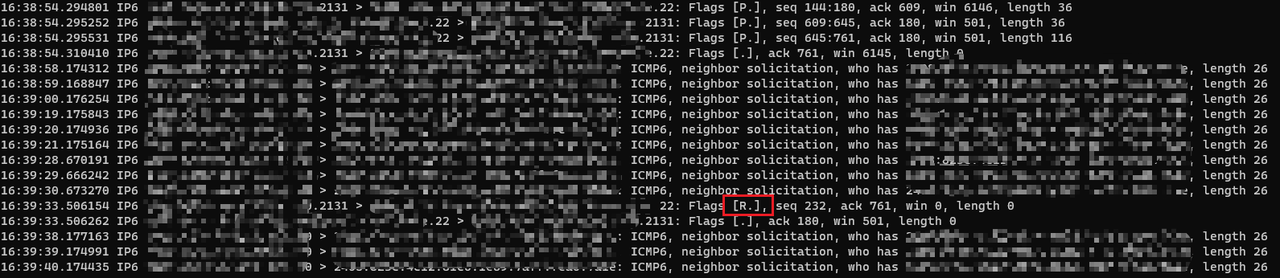
如果能帮忙解决,发 50RMB 以上支付宝红包。
#Wireguard #连接 #IPv6 #TCP #LAN #https #v2ex #co #png #网络
环境:Nano Pi R2S / OpenWrt 21.02.1
现象:经过路由器的 IPv6 TCP 连接,不管流量大小,随机时间后会被掐断,具体表现是触发重传,然后 Client 会向 Server 发送一个 RST 包导致连接断开。
这个 TCP 连接可以不经过公网,例如我的 LAN 网络和 Wireguard 虚拟网络中的设备通讯,也会出现上述问题,故排除了宽带运营商的锅(我的 Wireguard 接入点是 IPv4 的)。
这种情况应该怎么排查?附图是我 Wireguard 网络中的设备连接 LAN 中的设备,SSH 协议,client 和 server 的抓包情况。
其他说明:
1. 这个问题是两个月前才出现的,此前 IPv6 使用良好,两个月间搬过家、更新过某些 opkg 包
2. ICMPv6 确定不受影响,UDP 理论上也不受影响(未测试)


如果能帮忙解决,发 50RMB 以上支付宝红包。
#Wireguard #连接 #IPv6 #TCP #LAN #https #v2ex #co #png #网络
笑死,自己把自己焊死了,求解
真就像那个段子了。
https://i.imgur.com/bk5frOO.png
情况是:我在国内某主流云平台的 vps 上,装了个火绒,然后设置了禁止所有 tcp 连入。当我退出远程桌面后,下次再也登陆不了了。
https://i.imgur.com/tlg6ksD.png
急求解决办法。
#https #imgur #com #png #连入 #bk5frOO #vps #tcp #远程桌面 #tlg6ksD
真就像那个段子了。
https://i.imgur.com/bk5frOO.png
情况是:我在国内某主流云平台的 vps 上,装了个火绒,然后设置了禁止所有 tcp 连入。当我退出远程桌面后,下次再也登陆不了了。
https://i.imgur.com/tlg6ksD.png
急求解决办法。
#https #imgur #com #png #连入 #bk5frOO #vps #tcp #远程桌面 #tlg6ksD
求助:实验《动手测试单机百万连接》只能达到 102610 个连接
我按照[《动手测试单机百万连接》]( https://mp.weixin.qq.com/s/f_CMt2ni0vegB3-pf2BTTg)教程在 2 台 vps ( 2 核 4G ,ubuntu 22.04 )上做,每次都只能建立 102610 个连接,有碰到相同问题的吗?
2 台 vps 的内核配置最终是:
```
# sysctl net.ipv4.ip_local_port_range fs.file-max fs.nr_open net.ipv4.tcp_max_orphans net.ipv4.tcp_max_syn_backlog net.ipv4.tcp_mem net.ipv4.tcp_rmem net.ipv4.tcp_wmem
net.ipv4.ip_local_port_range = 5000 65000
fs.file-max = 1100000
fs.nr_open = 1100000
net.ipv4.tcp_max_orphans = 1000000
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_mem = 600000 800000 1000000
net.ipv4.tcp_rmem = 4096 4096 6291456
net.ipv4.tcp_wmem = 4096 4096 6291456
# ulimit -n
1000000
```
实验是根据教程的方案二来的,vps1 起 20 个 server 进程监听 20 个端口,vps2 起 20 个 client 一一对应,每个 client 发起 5w 个连接。
实验启动后查看连接的状态:
```
# ss -s
Total: 102808
TCP: 102635 (estab 102610, closed 0, orphaned 0, timewait 0)
# netstat -ant|awk '{print $4}'|sort|uniq -c|sort -nr
5557 172.31.27.20:8103
5553 172.31.27.20:8100
5537 172.31.27.20:8105
5253 172.31.27.20:8106
5207 172.31.27.20:8114
5196 172.31.27.20:8113
5101 172.31.27.20:8116
5096 172.31.27.20:8101
5044 172.31.27.20:8117
5040 172.31.27.20:8107
5033 172.31.27.20:8104
4999 172.31.27.20:8119
4999 172.31.27.20:8118
4999 172.31.27.20:8115
4999 172.31.27.20:8112
4999 172.31.27.20:8111
4999 172.31.27.20:8110
4999 172.31.27.20:8109
4999 172.31.27.20:8108
4999 172.31.27.20:8102
```
可以看到每个 server 只建立了 5000 左右的连接,离 5w 还差很远。另外此时两台 vps 执行`curl baidu.com`都会 hang 住,此时 vps 应该是既不能 accept 又不能 connect 。不知道哪里还需要配置才能成功。
#172.31 #27.20 #net #ipv4 #tcp #4999 #max #4096 #vps #fs
我按照[《动手测试单机百万连接》]( https://mp.weixin.qq.com/s/f_CMt2ni0vegB3-pf2BTTg)教程在 2 台 vps ( 2 核 4G ,ubuntu 22.04 )上做,每次都只能建立 102610 个连接,有碰到相同问题的吗?
2 台 vps 的内核配置最终是:
```
# sysctl net.ipv4.ip_local_port_range fs.file-max fs.nr_open net.ipv4.tcp_max_orphans net.ipv4.tcp_max_syn_backlog net.ipv4.tcp_mem net.ipv4.tcp_rmem net.ipv4.tcp_wmem
net.ipv4.ip_local_port_range = 5000 65000
fs.file-max = 1100000
fs.nr_open = 1100000
net.ipv4.tcp_max_orphans = 1000000
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_mem = 600000 800000 1000000
net.ipv4.tcp_rmem = 4096 4096 6291456
net.ipv4.tcp_wmem = 4096 4096 6291456
# ulimit -n
1000000
```
实验是根据教程的方案二来的,vps1 起 20 个 server 进程监听 20 个端口,vps2 起 20 个 client 一一对应,每个 client 发起 5w 个连接。
实验启动后查看连接的状态:
```
# ss -s
Total: 102808
TCP: 102635 (estab 102610, closed 0, orphaned 0, timewait 0)
# netstat -ant|awk '{print $4}'|sort|uniq -c|sort -nr
5557 172.31.27.20:8103
5553 172.31.27.20:8100
5537 172.31.27.20:8105
5253 172.31.27.20:8106
5207 172.31.27.20:8114
5196 172.31.27.20:8113
5101 172.31.27.20:8116
5096 172.31.27.20:8101
5044 172.31.27.20:8117
5040 172.31.27.20:8107
5033 172.31.27.20:8104
4999 172.31.27.20:8119
4999 172.31.27.20:8118
4999 172.31.27.20:8115
4999 172.31.27.20:8112
4999 172.31.27.20:8111
4999 172.31.27.20:8110
4999 172.31.27.20:8109
4999 172.31.27.20:8108
4999 172.31.27.20:8102
```
可以看到每个 server 只建立了 5000 左右的连接,离 5w 还差很远。另外此时两台 vps 执行`curl baidu.com`都会 hang 住,此时 vps 应该是既不能 accept 又不能 connect 。不知道哪里还需要配置才能成功。
#172.31 #27.20 #net #ipv4 #tcp #4999 #max #4096 #vps #fs
求助 iptables 开放端口无效
系统是 centos7 ,firewall 关闭了的
```
[root@localhost init.d]# systemctl status firewalld.service
● firewalld.service
Loaded: masked (/dev/null; bad)
Active: inactive (dead) since 四 2022-10-27 15:08:38 CST; 2 months 7 days ago
Main PID: 7533 (code=exited, status=0/SUCCESS)
Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.
```
有一个 iptables 可以使用,但并不是 service
```
[root@localhost init.d]# service iptables save
The service command supports only basic LSB actions (start, stop, restart, try-restart, reload, force-reload, status). For other actions, please try to use systemctl.
[root@localhost init.d]# iptables -nvL
Chain INPUT (policy ACCEPT 382K packets, 216M bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:3307
0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:1881
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER-USER all -- * * 0.0.0.0/0 0.0.0.0/0
0 0 DOCKER-ISOLATION-STAGE-1 all -- * * 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- * docker0 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
0 0 DOCKER all -- * docker0 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- docker0 !docker0 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- docker0 docker0 0.0.0.0/0 0.0.0.0/0
Chain OUTPUT (policy ACCEPT 206K packets, 190M bytes)
pkts bytes target prot opt in out source destination
Chain DOCKER (1 references)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.2 tcp dpt:9000
0 0 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.3 tcp dpt:6379
0 0 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.4 tcp dpt:9000
Chain DOCKER-ISOLATION-STAGE-1 (1 references)
pkts bytes target prot opt in out source destination
0 0 DOCKER-ISOLATION-STAGE-2 all -- docker0 !docker0 0.0.0.0/0 0.0.0.0/0
0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
Chain DOCKER-ISOLATION-STAGE-2 (1 references)
pkts bytes target prot opt in out source destination
0 0 DROP all -- * docker0 0.0.0.0/0 0.0.0.0/0
0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
Chain DOCKER-USER (1 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
```
诡异的是扫描端口,发现 1881 和 3307 没有通,1880 通了的
如果 yum 重新安装 iptables.service ,配置开通 3307 和 1881 后再扫描端口,发现 1880 和 1881 、3307 的 tcp 全部是关闭状态
求大佬解惑
#0.0 #-- #docker0 #ACCEPT #tcp #bytes #DOCKER #Chain #pkts #target
系统是 centos7 ,firewall 关闭了的
```
[root@localhost init.d]# systemctl status firewalld.service
● firewalld.service
Loaded: masked (/dev/null; bad)
Active: inactive (dead) since 四 2022-10-27 15:08:38 CST; 2 months 7 days ago
Main PID: 7533 (code=exited, status=0/SUCCESS)
Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.
```
有一个 iptables 可以使用,但并不是 service
```
[root@localhost init.d]# service iptables save
The service command supports only basic LSB actions (start, stop, restart, try-restart, reload, force-reload, status). For other actions, please try to use systemctl.
[root@localhost init.d]# iptables -nvL
Chain INPUT (policy ACCEPT 382K packets, 216M bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:3307
0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:1881
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER-USER all -- * * 0.0.0.0/0 0.0.0.0/0
0 0 DOCKER-ISOLATION-STAGE-1 all -- * * 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- * docker0 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
0 0 DOCKER all -- * docker0 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- docker0 !docker0 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- docker0 docker0 0.0.0.0/0 0.0.0.0/0
Chain OUTPUT (policy ACCEPT 206K packets, 190M bytes)
pkts bytes target prot opt in out source destination
Chain DOCKER (1 references)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.2 tcp dpt:9000
0 0 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.3 tcp dpt:6379
0 0 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.4 tcp dpt:9000
Chain DOCKER-ISOLATION-STAGE-1 (1 references)
pkts bytes target prot opt in out source destination
0 0 DOCKER-ISOLATION-STAGE-2 all -- docker0 !docker0 0.0.0.0/0 0.0.0.0/0
0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
Chain DOCKER-ISOLATION-STAGE-2 (1 references)
pkts bytes target prot opt in out source destination
0 0 DROP all -- * docker0 0.0.0.0/0 0.0.0.0/0
0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
Chain DOCKER-USER (1 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
```
诡异的是扫描端口,发现 1881 和 3307 没有通,1880 通了的
如果 yum 重新安装 iptables.service ,配置开通 3307 和 1881 后再扫描端口,发现 1880 和 1881 、3307 的 tcp 全部是关闭状态
求大佬解惑
#0.0 #-- #docker0 #ACCEPT #tcp #bytes #DOCKER #Chain #pkts #target
mariadb galera cluster 集群因网络 MTU 崩溃
mariadb galera cluster 集群因网络 MTU 崩溃,无法故障处理。
今天遇到一个问题,因为 mariadb galera cluster 节点之间的 MTU 过小,导致互相直接一直在重连,无法正常同步,但还是认为对方活着。最重要是影响全体使用。(所有节点无法正常使用)
请问有什么解决办法吗? 当出现 MTU 过小的时候,可以不因此问题导致单个使用。
```
2023-01-06 12:17:03 0 [Note] WSREP: (1a9adc34-9906, 'tcp://0.0.0.0:4567') turning message relay requesting off
2023-01-06 12:17:03 0 [Note] WSREP: (1a9adc34-9906, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://172.16.0.1:4567
2023-01-06 12:17:04 0 [Note] WSREP: (1a9adc34-9906, 'tcp://0.0.0.0:4567') connection established to 3c9235aa-a356 tcp://172.16.0.1:4567
```
一直会刷新此日志。
#0.0 #tcp #4567 #MTU #2023 #01 #06 #12 #17 #Note
mariadb galera cluster 集群因网络 MTU 崩溃,无法故障处理。
今天遇到一个问题,因为 mariadb galera cluster 节点之间的 MTU 过小,导致互相直接一直在重连,无法正常同步,但还是认为对方活着。最重要是影响全体使用。(所有节点无法正常使用)
请问有什么解决办法吗? 当出现 MTU 过小的时候,可以不因此问题导致单个使用。
```
2023-01-06 12:17:03 0 [Note] WSREP: (1a9adc34-9906, 'tcp://0.0.0.0:4567') turning message relay requesting off
2023-01-06 12:17:03 0 [Note] WSREP: (1a9adc34-9906, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://172.16.0.1:4567
2023-01-06 12:17:04 0 [Note] WSREP: (1a9adc34-9906, 'tcp://0.0.0.0:4567') connection established to 3c9235aa-a356 tcp://172.16.0.1:4567
```
一直会刷新此日志。
#0.0 #tcp #4567 #MTU #2023 #01 #06 #12 #17 #Note
请教大家一个关于前端项目部署的问题
目前的环境:
两个 windows 虚拟机 A,B
A 是安装了 nginx ,并且在 nginx 下的 html 放了一个名为 Bi 的文件夹,里面是前端项目打包后的 dist 文件
问题:
在 A 服务器本地访问 localhost 或者本机 ip 可以正确的打开界面,但是在 B 虚拟机里访问 A 的 ip 地址(模拟用户访问)打开的界面却是空白,看了 network 有成功访问到 index.htmlwen 文件。请问这是哪里出了问题?
nginx 配置:
```text
user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
location / {
root D:/nginx-1.26.1/html/Bi;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
```
前端项目 config
```js
export default defineConfig({
outputPath: 'dist',
publicPath: '/',
manifest: {
basePath: '/',
},
routes: [
{ path: "/", component: "@/pages/index/index.tsx" },
],
npmClient: 'yarn',
});
```
目前的环境:
两个 windows 虚拟机 A,B
A 是安装了 nginx ,并且在 nginx 下的 html 放了一个名为 Bi 的文件夹,里面是前端项目打包后的 dist 文件
问题:
在 A 服务器本地访问 localhost 或者本机 ip 可以正确的打开界面,但是在 B 虚拟机里访问 A 的 ip 地址(模拟用户访问)打开的界面却是空白,看了 network 有成功访问到 index.htmlwen 文件。请问这是哪里出了问题?
nginx 配置:
```text
user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
location / {
root D:/nginx-1.26.1/html/Bi;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
```
前端项目 config
```js
export default defineConfig({
outputPath: 'dist',
publicPath: '/',
manifest: {
basePath: '/',
},
routes: [
{ path: "/", component: "@/pages/index/index.tsx" },
],
npmClient: 'yarn',
});
```