
WordPress 测试支持 SQLite

WordPress 是至今最流行的内容管理系统,被广泛用于从个人到电商在内的各种类型的网站。W3Techs 的统计显示,它的市场占有率一直高居 43% 左右,而距离它最近的竞争对手是 Shopify 只有 4%。至今为止 WordPress 一直是基于 PHP 和 MySQL/MariaDB 数据库,但不是所有网站都需要功能全面的 MySQL 。WordPress 现在开始测试对 SQLite 数据库的支持。SQLite 是一大优势是直接集成在 PHP 中,WordPress 网站可以不需要额外的数据库服务器,有助于降低托管费用,减少能耗。
[转自]( https://t.me/kejiqu/578)
#WordPress #数据库 #https #PHP #MySQL #SQLite #网站 #电商 #tva1 #sinaimg

WordPress 是至今最流行的内容管理系统,被广泛用于从个人到电商在内的各种类型的网站。W3Techs 的统计显示,它的市场占有率一直高居 43% 左右,而距离它最近的竞争对手是 Shopify 只有 4%。至今为止 WordPress 一直是基于 PHP 和 MySQL/MariaDB 数据库,但不是所有网站都需要功能全面的 MySQL 。WordPress 现在开始测试对 SQLite 数据库的支持。SQLite 是一大优势是直接集成在 PHP 中,WordPress 网站可以不需要额外的数据库服务器,有助于降低托管费用,减少能耗。
[转自]( https://t.me/kejiqu/578)
#WordPress #数据库 #https #PHP #MySQL #SQLite #网站 #电商 #tva1 #sinaimg
数据库迁移从 MySQL 到 HBase
作为开发人员,我们有很大概率会遇到需要将当前正在使用的数据库迁移到另一个数据库的场景。比如你在项目早期选择了 MySQL 作为数据库 ,虽然它已经能满足大多数业务场景和性能要求,但随着你的数据量越来越大业务日趋复杂,继续使用 MySQL 则可能成为瓶颈,这时候你可能要开始考虑将 MySQL 替换为更适合的数据库比如 HBase (或 Cassandra...)。
对于一个在线业务系统来说,迁移数据库的挑战在于不仅要做到不停机无缝迁移还要保证迁移过程风险可控,这也正是本文要分享的内容,介绍如何使用功能开关无缝、安全地实现数据库迁移。
## 迁移案例:将 MySQL 迁移到 HBase
接下来将通过一个案例介绍整个迁移的实现过程。某个在线消息业务由于受限于 **MySQL** 性能和存储瓶颈,所以需要将数据迁移到 **HBase** 以便于进一步扩大业务规模。
### 1 、使用功能开关实现迁移控制
我们这里假设应用程序逻辑都是通过 DAO (数据存取对象)来查询 /读取 MySQL 持久化数据。为了能将数据存取切换到 HBase 中,所以第一步是编写一个针对 HBase 的 DAO ,并且和 MySQL DAO 实现相同的接口以提供相同数据读写能力。
现在已经有两种 DAO 接口实现,一种有支持 MySQL ,另一种是支持 HBase 。此时开始引入我们的功能开关管理服务 FeatureProbe 。
先在 eatureProbe 上创建四个 Boolean 类型功能开关来独立控制对 MySQL 和 HBase 的读写,以其中一个开关(**messages-mysql-write**)为例配置如下所示:

接下来我们对外统一提供 **saveMessage** 方法保存一个消息,代码如下所示:
```
public void storeMessage(Message message, FPUser fpUser) {
if(fpClient.booleanValue('messages-mysql-write', fpUser, true)) {
mysqlMesseageDao.save(message)
}
if(fpclient.BooleanValue('messages-hbase-write', fpUser, true)) {
hbaseMesseageDao.save(message)
}
}
```
需要注意的是,我们允许同一消息可能会保存在两个地方,其目的是保证了旧存储( MySQL )的完整性的同时开始将消息写入新数据存储。对于读取来说其实现思路大致和存储类似,例如实现一个能根据 ID 查询消息的方法,代码如下所示:
```
public Message findMessageById(Long id, FPUser fpUser) {
// 同时获取查询 mysql 和 hbase 的开关结果
boolean shouldReadMySQL = fpClient.booleanValue('events-mysql-read', fpUser, true)
boolean shouldReadHbase = fpClient.booleanValue('events-hbase-read', fpUser, true)
if (shouldReadMySQL && shouldReadHbase) { // 当开关被同时开启时,将对比两者结果,但仍然返回旧存储数据
mysqlMessage = mysqlMessageDao.findMessageById(id)
hbaseMessage = hbaseMessageDao.findMessageById(id)
if(deepEqualsEntity(mysqlMessage, hbaseMessage)) {
logger.error(
"MySQL and Hbase message differ: mysql: {}, hbase: {}",
mysqlMessage,
hbaseMessage)
}
return mysqlMessage
} else if (shouldReadMySQL) { // 只从 MySQL 查询
return mysqlMessageDao.findMessageById(id)
} else { // 只从 HBase 中查询
return hbaseMessageDao.findMessageById(id)
}
}
```
这里的点在于,我们检查两个“读取”的开关结果,当发现两者都启用时,我们会分别两个数据库读取数据,并比较结果是否一致,当发现不一致时,我们会记录错误,并最终返回旧存储( MySQL )中的数据。
### 2 、渐进式放量迁移
现在我们已经将从新老存储读写的代码封装在功能开关中,接下来需要部署代码并进行测试。此时只需要关闭 HBase 读写开关,并打开 mysql 读写开关,便可以安全地将代码部署上线。
我们测试迁移时,只需要在 FeatureProbe 上修改 HBase “写开关”的人群规则,仅为特定用户 QA 开启 ,此时只有 QA 的消息会存储到 HBase ,过程中观察性能指标和错误日志,如果一切符合预期,进一步修改人群规则将写 HBase 在更多的用户上生效,直到所有用户的 “写操作” 均同时写入了两个数据库。
当我们写入性能感到满意时,此时可以开始为一小部分用户打开 HBase 的读取开关,然后再次观察性能指标和错误日志,其中特别需要关注是否有** “MySQL and Hbase message differ...”的日志来确保两个存储数据的一致性。当然,这里即便我们看到数据不一致的错误日志,对用户也不会产生任何影响,因为他们仍在使用旧数据存储中的数据。如果数据和指标均符合预期,您可以为部分用户关闭 MySQL 的读关开,将使用 HBase 的数据,并最终直到所有用户均从 HBase 中读取。
最后,当我们向所有用户开启 HBase 读取和写入操作后,应该将所有旧数据从旧数据存储迁移到新数据存储(确保以幂等方式执行此操作)来保证数据的整体完整性。
可见,通过上述功能开关渐进式放量迁移的方式,不仅让使得迁移可以无缝进行(对用户无感知),还有效保障的迁移的安全性。
### 3 、收尾工作
最后一步,我们需要确保关闭了旧数据库(MySQL)的读写开关,同时删除代码中对所有四个开关的所有引用,使代码中最终只剩下对 HBase (新数据库)的读 /写。再次部署上线后,便完成了整个数据库的迁移工作。
在 FeatureProbe 开关管理也很简单,由于以上四个开关已经完成了数据库迁移的使命,对于已经过期、已完成工作的开关都可以使用下线操作进行管理。
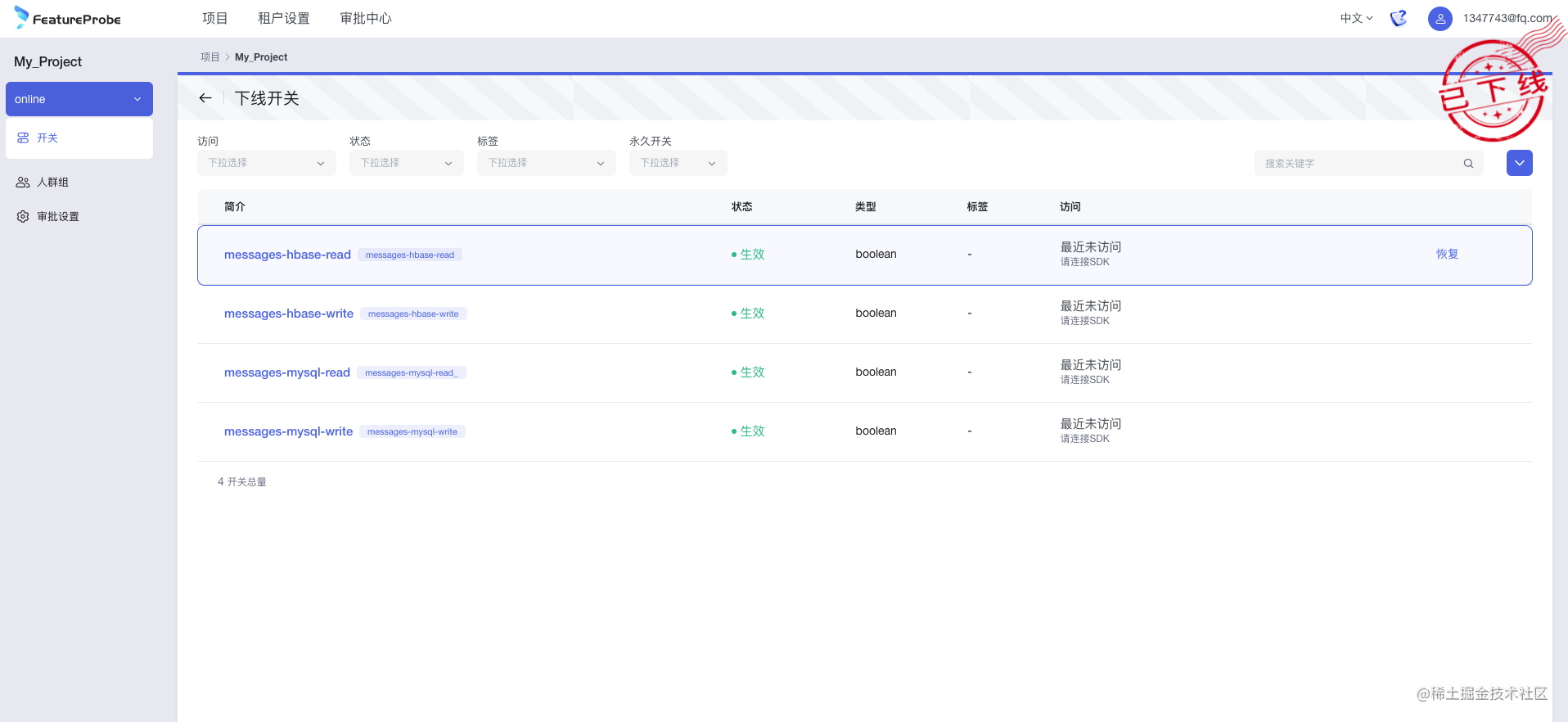
FeatureProbe 就是一个高效的功能管理 **( Feature management )** 开源服务,它提供了灰度放量、AB 实验、实时配置变更等针对功能粒度的一系列管理能力。目前 FeatureProbe 使用 Apache 2.0 License 协议已经完全开源, 开源地址: https://github.com/FeatureProbe/FeatureProbe 。
#HBase #MySQL #开关 #迁移 #数据库 #存储 #FeatureProbe #数据 #mysql #fpUser
作为开发人员,我们有很大概率会遇到需要将当前正在使用的数据库迁移到另一个数据库的场景。比如你在项目早期选择了 MySQL 作为数据库 ,虽然它已经能满足大多数业务场景和性能要求,但随着你的数据量越来越大业务日趋复杂,继续使用 MySQL 则可能成为瓶颈,这时候你可能要开始考虑将 MySQL 替换为更适合的数据库比如 HBase (或 Cassandra...)。
对于一个在线业务系统来说,迁移数据库的挑战在于不仅要做到不停机无缝迁移还要保证迁移过程风险可控,这也正是本文要分享的内容,介绍如何使用功能开关无缝、安全地实现数据库迁移。
## 迁移案例:将 MySQL 迁移到 HBase
接下来将通过一个案例介绍整个迁移的实现过程。某个在线消息业务由于受限于 **MySQL** 性能和存储瓶颈,所以需要将数据迁移到 **HBase** 以便于进一步扩大业务规模。
### 1 、使用功能开关实现迁移控制
我们这里假设应用程序逻辑都是通过 DAO (数据存取对象)来查询 /读取 MySQL 持久化数据。为了能将数据存取切换到 HBase 中,所以第一步是编写一个针对 HBase 的 DAO ,并且和 MySQL DAO 实现相同的接口以提供相同数据读写能力。
现在已经有两种 DAO 接口实现,一种有支持 MySQL ,另一种是支持 HBase 。此时开始引入我们的功能开关管理服务 FeatureProbe 。
先在 eatureProbe 上创建四个 Boolean 类型功能开关来独立控制对 MySQL 和 HBase 的读写,以其中一个开关(**messages-mysql-write**)为例配置如下所示:

接下来我们对外统一提供 **saveMessage** 方法保存一个消息,代码如下所示:
```
public void storeMessage(Message message, FPUser fpUser) {
if(fpClient.booleanValue('messages-mysql-write', fpUser, true)) {
mysqlMesseageDao.save(message)
}
if(fpclient.BooleanValue('messages-hbase-write', fpUser, true)) {
hbaseMesseageDao.save(message)
}
}
```
需要注意的是,我们允许同一消息可能会保存在两个地方,其目的是保证了旧存储( MySQL )的完整性的同时开始将消息写入新数据存储。对于读取来说其实现思路大致和存储类似,例如实现一个能根据 ID 查询消息的方法,代码如下所示:
```
public Message findMessageById(Long id, FPUser fpUser) {
// 同时获取查询 mysql 和 hbase 的开关结果
boolean shouldReadMySQL = fpClient.booleanValue('events-mysql-read', fpUser, true)
boolean shouldReadHbase = fpClient.booleanValue('events-hbase-read', fpUser, true)
if (shouldReadMySQL && shouldReadHbase) { // 当开关被同时开启时,将对比两者结果,但仍然返回旧存储数据
mysqlMessage = mysqlMessageDao.findMessageById(id)
hbaseMessage = hbaseMessageDao.findMessageById(id)
if(deepEqualsEntity(mysqlMessage, hbaseMessage)) {
logger.error(
"MySQL and Hbase message differ: mysql: {}, hbase: {}",
mysqlMessage,
hbaseMessage)
}
return mysqlMessage
} else if (shouldReadMySQL) { // 只从 MySQL 查询
return mysqlMessageDao.findMessageById(id)
} else { // 只从 HBase 中查询
return hbaseMessageDao.findMessageById(id)
}
}
```
这里的点在于,我们检查两个“读取”的开关结果,当发现两者都启用时,我们会分别两个数据库读取数据,并比较结果是否一致,当发现不一致时,我们会记录错误,并最终返回旧存储( MySQL )中的数据。
### 2 、渐进式放量迁移
现在我们已经将从新老存储读写的代码封装在功能开关中,接下来需要部署代码并进行测试。此时只需要关闭 HBase 读写开关,并打开 mysql 读写开关,便可以安全地将代码部署上线。
我们测试迁移时,只需要在 FeatureProbe 上修改 HBase “写开关”的人群规则,仅为特定用户 QA 开启 ,此时只有 QA 的消息会存储到 HBase ,过程中观察性能指标和错误日志,如果一切符合预期,进一步修改人群规则将写 HBase 在更多的用户上生效,直到所有用户的 “写操作” 均同时写入了两个数据库。
当我们写入性能感到满意时,此时可以开始为一小部分用户打开 HBase 的读取开关,然后再次观察性能指标和错误日志,其中特别需要关注是否有** “MySQL and Hbase message differ...”的日志来确保两个存储数据的一致性。当然,这里即便我们看到数据不一致的错误日志,对用户也不会产生任何影响,因为他们仍在使用旧数据存储中的数据。如果数据和指标均符合预期,您可以为部分用户关闭 MySQL 的读关开,将使用 HBase 的数据,并最终直到所有用户均从 HBase 中读取。
最后,当我们向所有用户开启 HBase 读取和写入操作后,应该将所有旧数据从旧数据存储迁移到新数据存储(确保以幂等方式执行此操作)来保证数据的整体完整性。
可见,通过上述功能开关渐进式放量迁移的方式,不仅让使得迁移可以无缝进行(对用户无感知),还有效保障的迁移的安全性。
### 3 、收尾工作
最后一步,我们需要确保关闭了旧数据库(MySQL)的读写开关,同时删除代码中对所有四个开关的所有引用,使代码中最终只剩下对 HBase (新数据库)的读 /写。再次部署上线后,便完成了整个数据库的迁移工作。
在 FeatureProbe 开关管理也很简单,由于以上四个开关已经完成了数据库迁移的使命,对于已经过期、已完成工作的开关都可以使用下线操作进行管理。

FeatureProbe 就是一个高效的功能管理 **( Feature management )** 开源服务,它提供了灰度放量、AB 实验、实时配置变更等针对功能粒度的一系列管理能力。目前 FeatureProbe 使用 Apache 2.0 License 协议已经完全开源, 开源地址: https://github.com/FeatureProbe/FeatureProbe 。
#HBase #MySQL #开关 #迁移 #数据库 #存储 #FeatureProbe #数据 #mysql #fpUser
关于 MySQL 的全文查询,是不是没有高效的办法限定在一个结果集里搜全文?
打算给 App 加个简单的搜索功能,不想搞得太复杂,所以就先试了下 MySQL 内置的全文,
比如我要限定在一个用户的文章里搜:
```sql
select * from article
where
user_id = ?
match (title) against ('+???' in boolean mode)
```
这么干的话貌似会先用全文索引搜索全部用户的文章,然后按用户 ID 一行行过滤,我试了下性能似乎不太好,在千万非 SSD 表上要个 0.5 秒。
然后我看了下 MySQL 可以同时搜索二个关键词,那我建一列 meta ,放用户 ID,然后我同时搜索这个用户 ID 和关键词:
```sql
select * from article
where match (meta, title) against ('+??? +USERID_???' in boolean mode)
```
发现性能几乎完全一致也要 0.5 秒。
但我单搜一个关键词就非常快 0.001 秒级别的。
```sql
select * from article
where match (meta, title) against ('+???' in boolean mode)
```
所以 MySQL 的全文搜索就是只能搜索一个条件是非常快的,其它的条件都是在前一个搜索结果里过滤?
所以这是 MySQL 全文的限制还是别的全文方案也是只能搜索一个关键词才是快的?
所以你们实现搜索某用户的文章是用的什么办法?
#搜索 #MySQL #用户 #sql #select #article #where #match #title #against
打算给 App 加个简单的搜索功能,不想搞得太复杂,所以就先试了下 MySQL 内置的全文,
比如我要限定在一个用户的文章里搜:
```sql
select * from article
where
user_id = ?
match (title) against ('+???' in boolean mode)
```
这么干的话貌似会先用全文索引搜索全部用户的文章,然后按用户 ID 一行行过滤,我试了下性能似乎不太好,在千万非 SSD 表上要个 0.5 秒。
然后我看了下 MySQL 可以同时搜索二个关键词,那我建一列 meta ,放用户 ID,然后我同时搜索这个用户 ID 和关键词:
```sql
select * from article
where match (meta, title) against ('+??? +USERID_???' in boolean mode)
```
发现性能几乎完全一致也要 0.5 秒。
但我单搜一个关键词就非常快 0.001 秒级别的。
```sql
select * from article
where match (meta, title) against ('+???' in boolean mode)
```
所以 MySQL 的全文搜索就是只能搜索一个条件是非常快的,其它的条件都是在前一个搜索结果里过滤?
所以这是 MySQL 全文的限制还是别的全文方案也是只能搜索一个关键词才是快的?
所以你们实现搜索某用户的文章是用的什么办法?
#搜索 #MySQL #用户 #sql #select #article #where #match #title #against
mysql or 关键字的执行问题
关于 mysql 的 or 查询,比如 select...from...where name=xxx or age =xxx 。这一条 sql 语句,在 mysql 执行的时候,是把 sql 拆分为 select...from...where name=xxx 拿到结果临时存起来再执行 select...from...where age =xxx 再跟前面的结果进行合并呢,还是 就当做一条语句执行?因为,在看关于 or 的索引失效的问题,解决方案是 or 前后的字段都需要加索引,我感觉是把 select...from...where name=xxx or age =xxx 拆分开执行的?有没有大佬跟我讲解下。谢谢
#... #xxx #select #where #name #age #mysql #sql #执行 #语句
关于 mysql 的 or 查询,比如 select...from...where name=xxx or age =xxx 。这一条 sql 语句,在 mysql 执行的时候,是把 sql 拆分为 select...from...where name=xxx 拿到结果临时存起来再执行 select...from...where age =xxx 再跟前面的结果进行合并呢,还是 就当做一条语句执行?因为,在看关于 or 的索引失效的问题,解决方案是 or 前后的字段都需要加索引,我感觉是把 select...from...where name=xxx or age =xxx 拆分开执行的?有没有大佬跟我讲解下。谢谢
#... #xxx #select #where #name #age #mysql #sql #执行 #语句
[ Java 后端工程师] [全职,海外远程 ] [WFH]
Salary : 4000USDT UP
工作內容
1. 负责大型网站后端服务的开发、设计与维护
2. 了解使用者需求,并进行相关分析与设计
3. 负责内外部平台的功能界接及整合、程式撰写、测试修改、后续修订
4. 跨国团队合作,提供专业的技术建议
岗位要求
1. 资讯电脑或相关理工科系大学或以上
2. 擅长工具: #git 、#java 、#springcloud 、#mysql 、#redis 、#kafka 、#mongoDB
3. 具备 5 年以上的软体开发经验
4. 架构及模组分析设计经验
5. 熟悉云端开发语言 Java 、springcloud 、golang
6. 在工作中具有主动性,具备快速开发效率,并勇于承担任务与团队合作精神
vx : Sam_869
Salary : 4000USDT UP
工作內容
1. 负责大型网站后端服务的开发、设计与维护
2. 了解使用者需求,并进行相关分析与设计
3. 负责内外部平台的功能界接及整合、程式撰写、测试修改、后续修订
4. 跨国团队合作,提供专业的技术建议
岗位要求
1. 资讯电脑或相关理工科系大学或以上
2. 擅长工具: #git 、#java 、#springcloud 、#mysql 、#redis 、#kafka 、#mongoDB
3. 具备 5 年以上的软体开发经验
4. 架构及模组分析设计经验
5. 熟悉云端开发语言 Java 、springcloud 、golang
6. 在工作中具有主动性,具备快速开发效率,并勇于承担任务与团队合作精神
vx : Sam_869