
Самая инновационная, прорывная и интригующая технология в области ИИ
(по версии канала «Малоизвестное интересное», IDC и Gartner )
Эта технология семантического поиска (поиска по смыслу) позволяет следующее.
✔️ Идентифицировать контент по его смыслу, а не по ключевым словам
✔️ В поисковом запросе используются не ключевые слова, а пример документа – мол, «я ищу документы про это»
✔️ Документ-пример на английском языке используется для поиска близких по смыслу документов «про это» на 20+ языках
✔️ Поиск в терабайтах данных идет на порядок быстрее, чем по ключевым словам
✔️ Проблемы многозначности и двусмысленности слов неявно решаются с помощью семантических сравнений
✔️ Система поиска добавляет новые термины «на лету» без переучивания и вообще без какой-либо переподготовки (т.е. динамически расширяет словарный запас)
Подробней я написал здесь https://goo.gl/2PHhNX
#АльтернативныйИИ #NLP #Семантика
(по версии канала «Малоизвестное интересное», IDC и Gartner )
Эта технология семантического поиска (поиска по смыслу) позволяет следующее.
✔️ Идентифицировать контент по его смыслу, а не по ключевым словам
✔️ В поисковом запросе используются не ключевые слова, а пример документа – мол, «я ищу документы про это»
✔️ Документ-пример на английском языке используется для поиска близких по смыслу документов «про это» на 20+ языках
✔️ Поиск в терабайтах данных идет на порядок быстрее, чем по ключевым словам
✔️ Проблемы многозначности и двусмысленности слов неявно решаются с помощью семантических сравнений
✔️ Система поиска добавляет новые термины «на лету» без переучивания и вообще без какой-либо переподготовки (т.е. динамически расширяет словарный запас)
Подробней я написал здесь https://goo.gl/2PHhNX
#АльтернативныйИИ #NLP #Семантика
Medium
Самая инновационная, прорывная и интригующая технология в области ИИ
(по версии канала «Малоизвестное интересное», IDC и Gartner)
Создана единая теория смысла информации, универсальная для живого и неживого.
Эта теория:
А) дает формальное описание семантической информации, пригодное для использования в разных науках (от философии и психологии до физики и биологии);
Б) позволяет использовать формальное описание семантической информации, как для живых существ, так и для любой иной физической системы (скалы, урагана или сети).
Данная теория объясняет и формально описывает, почему одна и та же информация:
✔️ для одного человека (и вообще, для любой физической системы) имеет смысл, а для другого – нет;
✔️ для одного имеет ценность, а для другого – нет;
✔️ для одного является истиной, а для другого – нет.
Подробности в моем новом посте https://goo.gl/82yTa1
#Семантика #Информация
Эта теория:
А) дает формальное описание семантической информации, пригодное для использования в разных науках (от философии и психологии до физики и биологии);
Б) позволяет использовать формальное описание семантической информации, как для живых существ, так и для любой иной физической системы (скалы, урагана или сети).
Данная теория объясняет и формально описывает, почему одна и та же информация:
✔️ для одного человека (и вообще, для любой физической системы) имеет смысл, а для другого – нет;
✔️ для одного имеет ценность, а для другого – нет;
✔️ для одного является истиной, а для другого – нет.
Подробности в моем новом посте https://goo.gl/82yTa1
#Семантика #Информация
Medium
Создана единая теория смысла информации
Универсальная для живого и неживого
Создана кардинально новая теория информации
Это может быть переломным моментом для десятка наук и технологий: от биологии до ИИ
Революционная работа Артемия Колчинского и Дэвида Вольперта «Семантическая информация, автономное агентство и неравновесная статистическая физика» только что опубликована в трудах Королевского общества.
Мои постоянные читатели знакомы с предысторией этой фантастически интересной и бесконечно важной работы.
А) В январе в посте «70 лет человечество бредет по худшему из лабиринтов» было рассказано, что:
— с 1948 г. доминирующей интерпретацией понятия «информация» стала «бессмысленная информация»;
— эта интерпретация вот уже 70 лет ведет нас по худшему из возможных лабиринтов – вовсе не сложному и запутанному, в состоящему из одного единственного абсолютно прямого пути, ведущего в никуда.
Б) В июле в посте «Создана единая теория смысла информации, универсальная для живого и неживого» сообщалось о разработке проф. Дэвидом Вольпертом математической теории:
— формально описывающей семантическую информацию для широкого спектра наук: от философии и психологии до физики и биологии;
— применимой как для живых существ, так и для любой иной физической системы;
— объясняющей и математически описывающей, почему одна и та же информация для одного человека (и вообще, для любой физической системы) имеет смысл, а для другого – нет.
Новая работа Вольперта и Колчинского дает полное и законченное описание революционной теории информации.
Из этого описания следует:
— Семантическая информация определена, как синтаксическая информация, которую физическая система имеет о своей среде, и которая причинно необходима системе для поддержания своего собственного существования.
— «Причинная необходимость» определяется в терминах гипотетических вмешательств (counter-factual interventions), которые рандомизируют корреляции между системой и ее средой, а «поддержание существования» определяется с точки зрения способности системы держаться в низком энтропийном состоянии.
— Впервые дано математическое определение до сих пор чисто интуитивных понятий: ценность информации», «семантический контент» и «автономный агент». Сущностной связкой этих понятий является базовое положение, что физическая система является автономным агентом в той мере, в какой она располагает бОльшим объемом семантической информации.
Будучи принятой, кардинально новая теория информации:
✔️ изменит вектор развития математико-кибернетических дисциплин и, в первую очередь, ИИ;
✔️ сможет привести к разгадке самого интригующего вопроса биологии - как эволюционировали самые ранние формы жизни и как теперь адаптируются существующие виды, и в частности:
• увеличивается ли объем семантической информации в ходе эволюции?
• является ли обучение совершенствованием навыка сбора осмысленной и важной для существования организма информации?
✔️ поменяет все наши привычные инструменты работы с информацией – и в первую очередь – поисковики (привет поисковым алгоритмам Гугла и Яндекса).
#Семантика #Информация
Это может быть переломным моментом для десятка наук и технологий: от биологии до ИИ
Революционная работа Артемия Колчинского и Дэвида Вольперта «Семантическая информация, автономное агентство и неравновесная статистическая физика» только что опубликована в трудах Королевского общества.
Мои постоянные читатели знакомы с предысторией этой фантастически интересной и бесконечно важной работы.
А) В январе в посте «70 лет человечество бредет по худшему из лабиринтов» было рассказано, что:
— с 1948 г. доминирующей интерпретацией понятия «информация» стала «бессмысленная информация»;
— эта интерпретация вот уже 70 лет ведет нас по худшему из возможных лабиринтов – вовсе не сложному и запутанному, в состоящему из одного единственного абсолютно прямого пути, ведущего в никуда.
Б) В июле в посте «Создана единая теория смысла информации, универсальная для живого и неживого» сообщалось о разработке проф. Дэвидом Вольпертом математической теории:
— формально описывающей семантическую информацию для широкого спектра наук: от философии и психологии до физики и биологии;
— применимой как для живых существ, так и для любой иной физической системы;
— объясняющей и математически описывающей, почему одна и та же информация для одного человека (и вообще, для любой физической системы) имеет смысл, а для другого – нет.
Новая работа Вольперта и Колчинского дает полное и законченное описание революционной теории информации.
Из этого описания следует:
— Семантическая информация определена, как синтаксическая информация, которую физическая система имеет о своей среде, и которая причинно необходима системе для поддержания своего собственного существования.
— «Причинная необходимость» определяется в терминах гипотетических вмешательств (counter-factual interventions), которые рандомизируют корреляции между системой и ее средой, а «поддержание существования» определяется с точки зрения способности системы держаться в низком энтропийном состоянии.
— Впервые дано математическое определение до сих пор чисто интуитивных понятий: ценность информации», «семантический контент» и «автономный агент». Сущностной связкой этих понятий является базовое положение, что физическая система является автономным агентом в той мере, в какой она располагает бОльшим объемом семантической информации.
Будучи принятой, кардинально новая теория информации:
✔️ изменит вектор развития математико-кибернетических дисциплин и, в первую очередь, ИИ;
✔️ сможет привести к разгадке самого интригующего вопроса биологии - как эволюционировали самые ранние формы жизни и как теперь адаптируются существующие виды, и в частности:
• увеличивается ли объем семантической информации в ходе эволюции?
• является ли обучение совершенствованием навыка сбора осмысленной и важной для существования организма информации?
✔️ поменяет все наши привычные инструменты работы с информацией – и в первую очередь – поисковики (привет поисковым алгоритмам Гугла и Яндекса).
#Семантика #Информация
Новая теория информации.
Почему смысл информации для каждого свой.
В сети появилось видео доклада Артемия Колчинского о семантической информации (1).
Уже 70 лет человечество ходит по худшему из лабиринтов из-за того, что с подачи Клода Шеннона доминирующей интерпретацией понятия «информация» стала «бессмысленная информация» (2).
Эта «бессмысленность информации» до последнего времени не позволяла ответить на «три проклятые вопроса», почему одна и та же информация:
✔️ для одного человека имеет смысл, а для другого — нет;
✔️ для одного составляет ценность, а для другого — нет;
✔️ для одного является истиной, а для другого — нет.
Четыре года назад в этой области произошла революция. Дэвид Волперт и Артемий Колчинский разработали новую теорию информации, дав формальное определение информации в контексте ее связи со смыслом и его интерпретацией (3).
Согласно новой теории, семантическая информация – это информация, которой обладает физическая система об окружающей среде, и которая казуально необходима системе для поддержания собственного существования.
Новая теория информации не только в состоянии ответить на «три проклятые вопроса», но и, по сути, является «единой теорией смысла информации», т.к. она универсальна для всех наук и всех видов физических систем - живых и неживых (4)
В новой теории впервые дано математическое определение до сих пор чисто интуитивных понятий: «ценность информации», «семантический контент» и «автономный агент».
Но с пониманием этих математических определений есть две проблемы:
• доказательный аппарат теории оперирует нетрадиционными формализмами на стыке информатики и термодинамики (типа «причинной необходимости» и «поддержания существования»), что с ходу и не поймешь, о чем идет речь;
• сложно разобраться в нетривиальных преобразованиях довольно сложных формул;
И поэтому столь ценно для желающих разобраться в новой теории простое и понятное 30 минутное изложение её брифа, сделанное Артемием Колчинским на недавно прошедшем междисциплинарном воркшопе «Is AI Extending the Mind?»
1 2 3 4
#Семантика #Информация
Почему смысл информации для каждого свой.
В сети появилось видео доклада Артемия Колчинского о семантической информации (1).
Уже 70 лет человечество ходит по худшему из лабиринтов из-за того, что с подачи Клода Шеннона доминирующей интерпретацией понятия «информация» стала «бессмысленная информация» (2).
Эта «бессмысленность информации» до последнего времени не позволяла ответить на «три проклятые вопроса», почему одна и та же информация:
✔️ для одного человека имеет смысл, а для другого — нет;
✔️ для одного составляет ценность, а для другого — нет;
✔️ для одного является истиной, а для другого — нет.
Четыре года назад в этой области произошла революция. Дэвид Волперт и Артемий Колчинский разработали новую теорию информации, дав формальное определение информации в контексте ее связи со смыслом и его интерпретацией (3).
Согласно новой теории, семантическая информация – это информация, которой обладает физическая система об окружающей среде, и которая казуально необходима системе для поддержания собственного существования.
Новая теория информации не только в состоянии ответить на «три проклятые вопроса», но и, по сути, является «единой теорией смысла информации», т.к. она универсальна для всех наук и всех видов физических систем - живых и неживых (4)
В новой теории впервые дано математическое определение до сих пор чисто интуитивных понятий: «ценность информации», «семантический контент» и «автономный агент».
Но с пониманием этих математических определений есть две проблемы:
• доказательный аппарат теории оперирует нетрадиционными формализмами на стыке информатики и термодинамики (типа «причинной необходимости» и «поддержания существования»), что с ходу и не поймешь, о чем идет речь;
• сложно разобраться в нетривиальных преобразованиях довольно сложных формул;
И поэтому столь ценно для желающих разобраться в новой теории простое и понятное 30 минутное изложение её брифа, сделанное Артемием Колчинским на недавно прошедшем междисциплинарном воркшопе «Is AI Extending the Mind?»
1 2 3 4
#Семантика #Информация
YouTube
Artemy Kolchinsky On Autonomous Agents and Semantic Information
'Is AI Extending the Mind?' is the second annual workshop by Cross Labs, this year held virtually from April 11 – 15, 2022.
About the workshop
The extended mind hypothesis suggests that cognition does not just occur in our minds, but also extends into the…
About the workshop
The extended mind hypothesis suggests that cognition does not just occur in our minds, but also extends into the…
О дельфинах, аллигаторах и лингвистической интуиции ИИ.
Системы машинного обучения намного умнее, чем мы думали.
Весь мир уже знает историю про языковую модель Google LaMDA, якобы, прошедшую тест Тьюринга, убедив инженера Google Блейка Лемуана в том, что она не только разумна, но и обладает сознанием.
Журналисты оторвались на хайпе вокруг этой истории. А специалисты разошлись во мнении.
Большинство думает, как Гэри Маркус (когнитивист и автор книги «Перезагрузка ИИ»).
Все, что делает LaMDA, «это сопоставление шаблонов, взятых из массивных статистических баз данных человеческого языка. Шаблоны могут быть крутыми, но язык, на котором «говорят» эти системы, на самом деле, бесмыслен».
В то же время главный научный сотрудник OpenAI Илья Суцкевер в своем твите утверждает, что «может быть, сегодняшние большие нейронные сети немного сознательны».
Всё упирается в два ключевых вопроса - могут ли компьютеры понимать:
• Что за понятие стоят за словом?
• В каком контексте слово используется?
Опубликованное в Nature исследование осторожно намекает, что да – в принципе, могут.
Слова языка отражают структуру человеческого разума, позволяя нам обмениваться мыслями. Однако язык может представлять лишь подмножество нашей богатой и детализированной когнитивной архитектуры.
Авторы задались вопросом, какие виды общих знаний (нашей семантической памяти) фиксируются значениями слов (лексической семантикой).
Чтобы понять это, авторы исследовали известную вычислительную модель, которая представляет слова в виде векторов в многомерном пространстве, так что близость между векторами слов аппроксимируют семантическую связь.
Поскольку родственные слова появляются в сходных контекстах, пространство векторного представления слов (Word embedding) можно изучать на основе шаблонов лексических совпадений в естественном языке.
Человеческие суждения о сходстве объектов сильно зависят от контекста и включают множество различных семантических признаков.
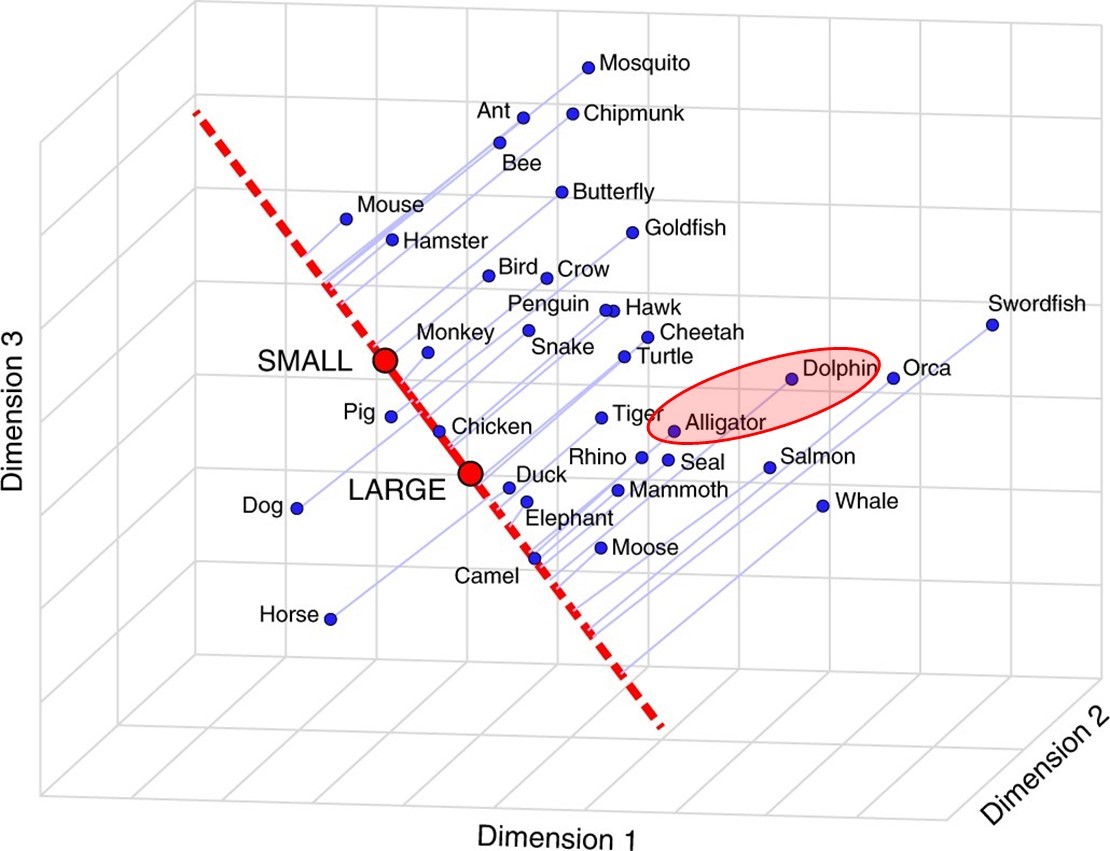
Например, дельфины и аллигаторы – это близкие понятия?
• С одной стороны, да - они живут в воде и похожи по размеру.
• С другой стороны, нет – они сильно непохожи умом и агрессивностью.
Чтобы понять, насколько стоящие за понятиями объекты близки, нужна система шкал: маленький-большой, умный-глупый, опасный-безопасный и т.д.
Авторы разработали технику, которую они назвали «семантической проекцией» слов-векторов на линии, которые представляют различные характеристики объекта (маленький-большой и т.д.)
Этот метод, аналогичный интуитивному размещению объектов “на ментальной шкале” между двумя крайностями, восстанавливает логику человеческих суждений по целому ряду категорий объектов и свойств.
В результате обширного пула сравнений суждений людей и компьютеров, было доказано, что векторное представление слов наследует множество общих знаний из статистики встречаемости слов и может гибко манипулировать ими для выражения контекстно-зависимых значений.
Исследователи обнаружили, что для многочисленных объектов и контекстов их метод оказался очень похожим на человеческую интуицию.
Например, что «тяжелая атлетика» и «фехтование» похожи тем, что и то, и другое обычно происходит в помещении, но различаются с точки зрения того, сколько интеллекта они требуют.
Постойте, - скажет здесь читатель поста. Ведь это же очень близко к пониманию слов, а не просто статистический анализ их встречаемости в обширном пуле текстов.
Авторы работы тоже так считают:
«Оказывается, эта система машинного обучения намного умнее, чем мы думали; она содержит очень сложные формы знания, и это знание организовано в очень интуитивную структуру», — говорит один из авторов. «Просто отслеживая, какие слова сочетаются друг с другом в языке, вы можете многое узнать о мире».
Значит ли это, что Суцкевер ближе к истине, чем Маркус? Получается, что это не исключено.
Статья
Видео
#Семантика
Системы машинного обучения намного умнее, чем мы думали.
Весь мир уже знает историю про языковую модель Google LaMDA, якобы, прошедшую тест Тьюринга, убедив инженера Google Блейка Лемуана в том, что она не только разумна, но и обладает сознанием.
Журналисты оторвались на хайпе вокруг этой истории. А специалисты разошлись во мнении.
Большинство думает, как Гэри Маркус (когнитивист и автор книги «Перезагрузка ИИ»).
Все, что делает LaMDA, «это сопоставление шаблонов, взятых из массивных статистических баз данных человеческого языка. Шаблоны могут быть крутыми, но язык, на котором «говорят» эти системы, на самом деле, бесмыслен».
В то же время главный научный сотрудник OpenAI Илья Суцкевер в своем твите утверждает, что «может быть, сегодняшние большие нейронные сети немного сознательны».
Всё упирается в два ключевых вопроса - могут ли компьютеры понимать:
• Что за понятие стоят за словом?
• В каком контексте слово используется?
Опубликованное в Nature исследование осторожно намекает, что да – в принципе, могут.
Слова языка отражают структуру человеческого разума, позволяя нам обмениваться мыслями. Однако язык может представлять лишь подмножество нашей богатой и детализированной когнитивной архитектуры.
Авторы задались вопросом, какие виды общих знаний (нашей семантической памяти) фиксируются значениями слов (лексической семантикой).
Чтобы понять это, авторы исследовали известную вычислительную модель, которая представляет слова в виде векторов в многомерном пространстве, так что близость между векторами слов аппроксимируют семантическую связь.
Поскольку родственные слова появляются в сходных контекстах, пространство векторного представления слов (Word embedding) можно изучать на основе шаблонов лексических совпадений в естественном языке.
Человеческие суждения о сходстве объектов сильно зависят от контекста и включают множество различных семантических признаков.
Например, дельфины и аллигаторы – это близкие понятия?
• С одной стороны, да - они живут в воде и похожи по размеру.
• С другой стороны, нет – они сильно непохожи умом и агрессивностью.
Чтобы понять, насколько стоящие за понятиями объекты близки, нужна система шкал: маленький-большой, умный-глупый, опасный-безопасный и т.д.
Авторы разработали технику, которую они назвали «семантической проекцией» слов-векторов на линии, которые представляют различные характеристики объекта (маленький-большой и т.д.)
Этот метод, аналогичный интуитивному размещению объектов “на ментальной шкале” между двумя крайностями, восстанавливает логику человеческих суждений по целому ряду категорий объектов и свойств.
В результате обширного пула сравнений суждений людей и компьютеров, было доказано, что векторное представление слов наследует множество общих знаний из статистики встречаемости слов и может гибко манипулировать ими для выражения контекстно-зависимых значений.
Исследователи обнаружили, что для многочисленных объектов и контекстов их метод оказался очень похожим на человеческую интуицию.
Например, что «тяжелая атлетика» и «фехтование» похожи тем, что и то, и другое обычно происходит в помещении, но различаются с точки зрения того, сколько интеллекта они требуют.
Постойте, - скажет здесь читатель поста. Ведь это же очень близко к пониманию слов, а не просто статистический анализ их встречаемости в обширном пуле текстов.
Авторы работы тоже так считают:
«Оказывается, эта система машинного обучения намного умнее, чем мы думали; она содержит очень сложные формы знания, и это знание организовано в очень интуитивную структуру», — говорит один из авторов. «Просто отслеживая, какие слова сочетаются друг с другом в языке, вы можете многое узнать о мире».
Значит ли это, что Суцкевер ближе к истине, чем Маркус? Получается, что это не исключено.
Статья
Видео
#Семантика
{kind=link}