«Беспокоитесь, что ИИ станет слишком умным и захватит мир?
Но реальная проблема, — что, будучи предельно глуп, ИИ уже это сделал»
Эти слова Педро Домингоса – автора бестселлера 2017 «Мастер-алгоритм» - были бы отличным эпиграфом для недавней статьи Мелани Митчелл в NYT, озаглавленной «ИИ сталкивается с барьером смысла».
Статья резюмирует основную идею новой книги Мелани «ИИ – руководство для мыслящих людей», которая выйдет в следующем году и имеет отличные шансы стать бестселлером 2019.
Беда, как обычно, не с инструментарием (коим ИИ является), а с людьми. И ладно бы они, хоть и бездумно, но пользовались все новыми и новыми приложениями машинного обучения для пустяков – типа пресловутого заказа столика в ресторане.
Так нет же. Безумные энтузиасты и жадные корпорации (так уж они устроены) все более расширяют границы допустимых областей применения приложений машинного обучения (нахально и безосновательно называемых ими ИИ).
— Неважно, что «читающие» юридические документы программы могут быть легко обмануты (ведь и юристы ошибаются – говорят самозашоренные энтузиасты).
— Ерунда, что самоуправляемое авто при какой-то никому пока не известной игре освещения и теней может не распознать человека на своем пути (а сколько гибнет под колесами людей – парируют энтузиасты).
Мелани Митчелл приводит дюжину не менее опасных примеров, показывающих, как люди своими руками создают при внедрении т.н. ИИ все новые классы потенциальных уязвимостей: для отдельного человека и для всего человечества, допускающих физическое и ментальное негативное воздействие с никому неизвестными масштабами негативных последствий.
И все упирается
✔️ в выбранный ложный путь – симуляция «умного поведения» по определению безумными (в смысле ума совсем нет) программами на основе машинного обучения,
✔️ в неостановимую гонку коммерциализации т.н. ИИ систем, которые работают «достаточно хорошо» по узким задачам,
✔️ ну и, конечно, в безразмерную тупость и жадность людей, уповающих, что, мол, как и раньше бывало с революционными инновациями, все как-нибудь со временем рассосется.
А ведь есть только один способ остановить это безумие:
— Признать, что акторами «умного поведения» в реальной жизни людей (а не в лабораториях экспериментаторов) должны быть лишь реально разумные интеллектуальные системы.
— А для этого нужно, наконец, понять, описать, многократно проверить, что же такое разум, как он устроен и как может быть воспроизведен рукотворно.
Теория и практические подходы для этого существуют (и похоже, мне более не стоит откладывать про это написать).
Осталось лишь серьезно взяться, не уповая на коммерциализацию в ближайшие 12 месяцев.
Подробней:
Статья Мелани Митчелл https://www.nytimes.com/2018/11/05/opinion/artificial-intelligence-machine-learning.html
Информация к размышлению вокруг статьи https://mindmatters.ai/2018/11/machines-just-dont-do-meaning/
#БББ #ИИ #МашинноеОбучение
Но реальная проблема, — что, будучи предельно глуп, ИИ уже это сделал»
Эти слова Педро Домингоса – автора бестселлера 2017 «Мастер-алгоритм» - были бы отличным эпиграфом для недавней статьи Мелани Митчелл в NYT, озаглавленной «ИИ сталкивается с барьером смысла».
Статья резюмирует основную идею новой книги Мелани «ИИ – руководство для мыслящих людей», которая выйдет в следующем году и имеет отличные шансы стать бестселлером 2019.
Беда, как обычно, не с инструментарием (коим ИИ является), а с людьми. И ладно бы они, хоть и бездумно, но пользовались все новыми и новыми приложениями машинного обучения для пустяков – типа пресловутого заказа столика в ресторане.
Так нет же. Безумные энтузиасты и жадные корпорации (так уж они устроены) все более расширяют границы допустимых областей применения приложений машинного обучения (нахально и безосновательно называемых ими ИИ).
— Неважно, что «читающие» юридические документы программы могут быть легко обмануты (ведь и юристы ошибаются – говорят самозашоренные энтузиасты).
— Ерунда, что самоуправляемое авто при какой-то никому пока не известной игре освещения и теней может не распознать человека на своем пути (а сколько гибнет под колесами людей – парируют энтузиасты).
Мелани Митчелл приводит дюжину не менее опасных примеров, показывающих, как люди своими руками создают при внедрении т.н. ИИ все новые классы потенциальных уязвимостей: для отдельного человека и для всего человечества, допускающих физическое и ментальное негативное воздействие с никому неизвестными масштабами негативных последствий.
И все упирается
✔️ в выбранный ложный путь – симуляция «умного поведения» по определению безумными (в смысле ума совсем нет) программами на основе машинного обучения,
✔️ в неостановимую гонку коммерциализации т.н. ИИ систем, которые работают «достаточно хорошо» по узким задачам,
✔️ ну и, конечно, в безразмерную тупость и жадность людей, уповающих, что, мол, как и раньше бывало с революционными инновациями, все как-нибудь со временем рассосется.
А ведь есть только один способ остановить это безумие:
— Признать, что акторами «умного поведения» в реальной жизни людей (а не в лабораториях экспериментаторов) должны быть лишь реально разумные интеллектуальные системы.
— А для этого нужно, наконец, понять, описать, многократно проверить, что же такое разум, как он устроен и как может быть воспроизведен рукотворно.
Теория и практические подходы для этого существуют (и похоже, мне более не стоит откладывать про это написать).
Осталось лишь серьезно взяться, не уповая на коммерциализацию в ближайшие 12 месяцев.
Подробней:
Статья Мелани Митчелл https://www.nytimes.com/2018/11/05/opinion/artificial-intelligence-machine-learning.html
Информация к размышлению вокруг статьи https://mindmatters.ai/2018/11/machines-just-dont-do-meaning/
#БББ #ИИ #МашинноеОбучение
NY Times
Opinion | Artificial Intelligence Hits the Barrier of Meaning (Published 2018)
Machine learning algorithms don’t yet understand things the way humans do — with sometimes disastrous consequences.
Расшифровка «Стонов Каскадии» может спасти десятки тысяч жизней. Предотвратить надвигающееся самое страшное землетрясение в истории США наука не может. Но сделан прорыв в его предсказании.
Исследователи лаборатории Лос-Аламос использовали машинное обучение для прогнозирования землетрясений в районе разлома Каскадия (длинной в 700 миль от северной Калифорнии до южной части Британской Колумбии – примерно до Сиэтла).
В этой истории поражают 2 вещи.
1) Безграничные пределы человеческой близорукости.
Обнаруженная связь между громкостью акустического сигнала разлома - т.н. «Стоны Каскадии» - и его физическими изменениями, никому раньше просто не приходила в голову. «Стоны Каскадии» считались бессмысленным шумом, из которого ничего не следует.
Но стоило преодолеть эту близорукость и запустить машинное обучение на поиск шаблонов, как тут же нашли звуковой шаблон, указывающий на повышение активности в движении тектонических плит.
Как тут не вспомнить «Глас Господа» Станислава Лема.
2) Безграничный оптимизм людей, знающих о надвигающейся катастрофе, но продолжающих любить, рожать детей, строить дома ...
Гигантская плита под Тихим океаном неуклонно скользит под Северную Америку со скоростью тридцать-сорок миллиметров в год. В результате в разломе Каскадия нарастает давление, и все обречено закончиться сильным землетрясением.
Два варианта:
- оно будет либо сильным (8-8,6 баллов),
- либо очень сильным (8,7-9,2 балла).
Вероятность 1го в ближайшие пятьдесят лет примерно 33%.
Вероятность 2го - примерно 10%.
Но в любом случае, это будет величайшая природная катастрофа в истории Северной Америки.
Континентальный шельф Каскадии, опустится на 2 метра и отскочит от 10 до 30 метров в западную сторону. В минуту произойдет выброс энергии, накопленной в результате столетнего сжатия. Вода поднимется вверх как гора, а затем быстро обрушится. Одна сторона гигантской волны пойдет на запад, в сторону Японии. Другая сторона - на восток. Тысяча километровая стена воды, сметая все на пути, достигнет Северо-Западного побережья где-то через пятнадцать минут после начала землетрясения.
Погибнут десятки тысяч человек. Миллионы останутся без крова. Вся инфраструктура будет разрушена…
Но никто не уезжает. Люди продолжают жить, как ни в чем не бывало. Авось на наш век хватит.
Но ведь шансы в 30%, что это может случится в ближайшие 50 лет, вовсе не отодвигают катастрофу на 50 лет. Это означает, что с такой вероятностью катастрофа может случиться, например, завтра или через месяц, или через год.
Подробней о расшифровке «Стонов Каскадии» (там же две ссылки на научные статьи) https://phys.org/news/2018-12-machine-learning-detected-earthquake.html
Подробней о грядущей катастрофе в зоне Каскадия https://www.newyorker.com/magazine/2015/07/20/the-really-big-one
#МашинноеОбучение
Исследователи лаборатории Лос-Аламос использовали машинное обучение для прогнозирования землетрясений в районе разлома Каскадия (длинной в 700 миль от северной Калифорнии до южной части Британской Колумбии – примерно до Сиэтла).
В этой истории поражают 2 вещи.
1) Безграничные пределы человеческой близорукости.
Обнаруженная связь между громкостью акустического сигнала разлома - т.н. «Стоны Каскадии» - и его физическими изменениями, никому раньше просто не приходила в голову. «Стоны Каскадии» считались бессмысленным шумом, из которого ничего не следует.
Но стоило преодолеть эту близорукость и запустить машинное обучение на поиск шаблонов, как тут же нашли звуковой шаблон, указывающий на повышение активности в движении тектонических плит.
Как тут не вспомнить «Глас Господа» Станислава Лема.
2) Безграничный оптимизм людей, знающих о надвигающейся катастрофе, но продолжающих любить, рожать детей, строить дома ...
Гигантская плита под Тихим океаном неуклонно скользит под Северную Америку со скоростью тридцать-сорок миллиметров в год. В результате в разломе Каскадия нарастает давление, и все обречено закончиться сильным землетрясением.
Два варианта:
- оно будет либо сильным (8-8,6 баллов),
- либо очень сильным (8,7-9,2 балла).
Вероятность 1го в ближайшие пятьдесят лет примерно 33%.
Вероятность 2го - примерно 10%.
Но в любом случае, это будет величайшая природная катастрофа в истории Северной Америки.
Континентальный шельф Каскадии, опустится на 2 метра и отскочит от 10 до 30 метров в западную сторону. В минуту произойдет выброс энергии, накопленной в результате столетнего сжатия. Вода поднимется вверх как гора, а затем быстро обрушится. Одна сторона гигантской волны пойдет на запад, в сторону Японии. Другая сторона - на восток. Тысяча километровая стена воды, сметая все на пути, достигнет Северо-Западного побережья где-то через пятнадцать минут после начала землетрясения.
Погибнут десятки тысяч человек. Миллионы останутся без крова. Вся инфраструктура будет разрушена…
Но никто не уезжает. Люди продолжают жить, как ни в чем не бывало. Авось на наш век хватит.
Но ведь шансы в 30%, что это может случится в ближайшие 50 лет, вовсе не отодвигают катастрофу на 50 лет. Это означает, что с такой вероятностью катастрофа может случиться, например, завтра или через месяц, или через год.
Подробней о расшифровке «Стонов Каскадии» (там же две ссылки на научные статьи) https://phys.org/news/2018-12-machine-learning-detected-earthquake.html
Подробней о грядущей катастрофе в зоне Каскадия https://www.newyorker.com/magazine/2015/07/20/the-really-big-one
#МашинноеОбучение
phys.org
Machine learning-detected signal predicts time to earthquake
Machine-learning research published in two related papers today in Nature Geoscience reports the detection of seismic signals accurately predicting the Cascadia fault's slow slippage, a type of failure ...
Итоги: Самые важные прорывы ИИ & МО в 2018 и самые многообещающие тренды 2019
Это технический обзор с точки зрения практиков. И потому его написал специалист именно такого профиля – Пранав Дар из Analytics Vidhya (кто не слышал, рекомендую).
Почему в итогах 2018 говорится именно о ИИ & МО (машинное обучение), - долго объяснять не надо.
С т.з. инвестиций (на входе) и практики конкретных приложений (на выходе), сектор ИИ & МО составляет 90% всех передовых ИТ разработок.
Если сократить текст обзора итогов года до 1 слова, то получится –
- Impactful (во всем спектре переводов: от имеющий ударную силу до яркий, впечатляющий, плодотворный и показательный).
Обзор итогов проведен по 5 ключевым направлениям:
1) Обработка естественного языка
Главный итог: повсеместный переход на предварительно обученные модели (больше не надейтесь получить приличный перевод, предварительно не поучив переводчик на нужных вам текстах… Зато если поучите – получите вполне приличные переводы)
2) Компьютерное зрение
Главный итог: самостоятельное обучение (не тратя время на маркировку изображений вручную) выходит в мейнстрим.
3) Инструменты и библиотеки
Главный итог: начало преодоления разрыва между моделированием черного ящика и производством моделей с помощью machine learning interpretability (MLI)
4) Обучение с подкреплением
Главный итог: наконец-то, от академических задач (типа шахмат и Го) начинается переход к практическим задачам (поиск лекарств, оптимизация архитектуры электронных чипов, маршрутизация транспортных средств и пакетов и т. д.)
5) ИИ для добра - движение к этическому ИИ
Главный итог: государства всё больше влезают в эту сферу, и 2019 станет в данном тренде показательным, если не переломным.
Кто хотел бы рассмотреть итоги в режиме расширенного резюме (примерно на 5-10 мин. чтения) – вам сюда
https://www.analyticsvidhya.com/blog/2018/12/key-breakthroughs-ai-ml-2018-trends-2019/
#ИИ #МашинноеОбучение
Это технический обзор с точки зрения практиков. И потому его написал специалист именно такого профиля – Пранав Дар из Analytics Vidhya (кто не слышал, рекомендую).
Почему в итогах 2018 говорится именно о ИИ & МО (машинное обучение), - долго объяснять не надо.
С т.з. инвестиций (на входе) и практики конкретных приложений (на выходе), сектор ИИ & МО составляет 90% всех передовых ИТ разработок.
Если сократить текст обзора итогов года до 1 слова, то получится –
- Impactful (во всем спектре переводов: от имеющий ударную силу до яркий, впечатляющий, плодотворный и показательный).
Обзор итогов проведен по 5 ключевым направлениям:
1) Обработка естественного языка
Главный итог: повсеместный переход на предварительно обученные модели (больше не надейтесь получить приличный перевод, предварительно не поучив переводчик на нужных вам текстах… Зато если поучите – получите вполне приличные переводы)
2) Компьютерное зрение
Главный итог: самостоятельное обучение (не тратя время на маркировку изображений вручную) выходит в мейнстрим.
3) Инструменты и библиотеки
Главный итог: начало преодоления разрыва между моделированием черного ящика и производством моделей с помощью machine learning interpretability (MLI)
4) Обучение с подкреплением
Главный итог: наконец-то, от академических задач (типа шахмат и Го) начинается переход к практическим задачам (поиск лекарств, оптимизация архитектуры электронных чипов, маршрутизация транспортных средств и пакетов и т. д.)
5) ИИ для добра - движение к этическому ИИ
Главный итог: государства всё больше влезают в эту сферу, и 2019 станет в данном тренде показательным, если не переломным.
Кто хотел бы рассмотреть итоги в режиме расширенного резюме (примерно на 5-10 мин. чтения) – вам сюда
https://www.analyticsvidhya.com/blog/2018/12/key-breakthroughs-ai-ml-2018-trends-2019/
#ИИ #МашинноеОбучение
Analytics Vidhya
A Technical Overview of AI & ML (NLP, Computer Vision, Reinforcement Learning) in 2018 & Trends for 2019
From Google's BERT to Facebook's PyTorch, 2018 was a HUGE year in ML. Find out what else made the news and what to look forward to in the new year!
1е открытие 2019 – возможности ИИ оказались небеспредельными.
Подобно человеческому разуму, ИИ ограничен парадоксами теории множеств.
До сих пор считалось, что самой фундаментальной проблемой развитии технологий ИИ является необъяснимость принимаемых им решений. В январе 2019 к этой проблеме добавилась еще одна, не менее фундаментальная проблема — принципиальная непредсказуемость, какие задачи ИИ может решить, а какие нет.
На пути триумфального развития технологий машинного обучения, как казалось, способных при наличии большого объема данных превзойти людей в чем угодно — в играх, распознавании, предсказаниях и т.д. — встала первая из 23 проблем, поставленных в докладе Давида Гильберта на международном математическом конгрессе в Париже еще в 1900-м году.
Первой в списке этих 23 проблем, решение которых до сих пор считается высшим достижением для математика, была так называемая гипотеза континуума (континуум-гипотеза или 1я проблема Гильберта), которую выдвинул и пытался решить (но потерпел неудачу) еще сам создатель теории множеств Георг Кантор.
И вот сейчас, на исходе второго десятилетия XXI века гипотеза континуума, будучи примененная к задачам машинного обучения, стала холодным отрезвляющим душем для всех технооптимистов ИИ.
• Машинное обучение оказалось не всесильно
• И что еще хуже, — в широком спектре сценариев обучаемость ИИ не может быть ни доказана, ни опровергнута.
Продолжить чтение можно
- на Medium https://clck.ru/F3wny
- на Яндекс Дзен https://goo.gl/mFqasZ
#ИИ #МашинноеОбучение
Подобно человеческому разуму, ИИ ограничен парадоксами теории множеств.
До сих пор считалось, что самой фундаментальной проблемой развитии технологий ИИ является необъяснимость принимаемых им решений. В январе 2019 к этой проблеме добавилась еще одна, не менее фундаментальная проблема — принципиальная непредсказуемость, какие задачи ИИ может решить, а какие нет.
На пути триумфального развития технологий машинного обучения, как казалось, способных при наличии большого объема данных превзойти людей в чем угодно — в играх, распознавании, предсказаниях и т.д. — встала первая из 23 проблем, поставленных в докладе Давида Гильберта на международном математическом конгрессе в Париже еще в 1900-м году.
Первой в списке этих 23 проблем, решение которых до сих пор считается высшим достижением для математика, была так называемая гипотеза континуума (континуум-гипотеза или 1я проблема Гильберта), которую выдвинул и пытался решить (но потерпел неудачу) еще сам создатель теории множеств Георг Кантор.
И вот сейчас, на исходе второго десятилетия XXI века гипотеза континуума, будучи примененная к задачам машинного обучения, стала холодным отрезвляющим душем для всех технооптимистов ИИ.
• Машинное обучение оказалось не всесильно
• И что еще хуже, — в широком спектре сценариев обучаемость ИИ не может быть ни доказана, ни опровергнута.
Продолжить чтение можно
- на Medium https://clck.ru/F3wny
- на Яндекс Дзен https://goo.gl/mFqasZ
#ИИ #МашинноеОбучение
Medium
1е открытие 2019 — возможности ИИ оказались небеспредельными
Подобно человеческому разуму, ИИ ограничен парадоксами теории множеств
Давно собирался написать об этом. И как это часто бывает, когда слишком долго собираешься что-то сделать, - это сделают другие. Так вышло и в этот раз. Но я не тужу. Сделано хорошо.
Мелани Митчелл (профессор компьютерных наук в Государственном университете Портленда) – не только глубоко разбирается в теме, но и очень ясно мыслит и весьма понятно излагает. И поэтому читать ее тексты интересно, понятно и полезно.
Новая книга Мелани Митчелл «Искусственный интеллект: руководство для думающих людей», выйдет только в октябре. Но уже сейчас можно прочесть важный текст из этой книги, озаглавленный «Как научить самоуправляемый автомобиль, чтобы снеговик не перешел ему дорогу?».
Эта статья, как и вся книга, весьма рекомендуются мною к прочтению тем, на кого они рассчитаны – думающим людям.
Ну а я здесь поразмышляю вокруг главной идеи статьи и книги -
что же стало главным итогом развития ИИ за без малого шесть с половиной десятилетий?
• мой новый пост (7 мин) на Medium http://bit.do/eUrCP
• мой новый пост на Яндекс Дзен https://clck.ru/GThrx
#ИИ #МашинноеОбучение
Мелани Митчелл (профессор компьютерных наук в Государственном университете Портленда) – не только глубоко разбирается в теме, но и очень ясно мыслит и весьма понятно излагает. И поэтому читать ее тексты интересно, понятно и полезно.
Новая книга Мелани Митчелл «Искусственный интеллект: руководство для думающих людей», выйдет только в октябре. Но уже сейчас можно прочесть важный текст из этой книги, озаглавленный «Как научить самоуправляемый автомобиль, чтобы снеговик не перешел ему дорогу?».
Эта статья, как и вся книга, весьма рекомендуются мною к прочтению тем, на кого они рассчитаны – думающим людям.
Ну а я здесь поразмышляю вокруг главной идеи статьи и книги -
что же стало главным итогом развития ИИ за без малого шесть с половиной десятилетий?
• мой новый пост (7 мин) на Medium http://bit.do/eUrCP
• мой новый пост на Яндекс Дзен https://clck.ru/GThrx
#ИИ #МашинноеОбучение
ML-стартапы, - либо делайте комплексные решения либо расходитесь.
Обращение венчурного инвестора и топового ИИ-эксперта к ML-стартапам.
Уже 2 года, как лучшим отчетом о состоянии ИИ в мире является «State of AI» Натана Бенайха и Яна Хогарта. И если вы его читаете, то обладаете «всей самой актуальной и нужной информацией о состоянии ИИ».
А теперь прочтите манифест Натана Бенайха «Machine learning: go full stack or go home» (Машинное обучение: станьте комплексными или расходитесь) – обращение к стартапам, работающим в области машинного обучения (ML).
Ключевая мысль обращения такая.
1. (Преамбула 1) ML – самое хайповое направление для современных стартапов.
2. (Преамбула 2) Будущее ML во многом зависит именно от них (ибо даже если когда-то они станут новыми DeepMind и их купит Google, инновационный вектор их разработок складывается сейчас).
3. (Это и есть, собственно мысль) Подавляющее число ML-стартапов имеет устаревшую и малоперспективную бизнес-модель.
- Они делают ML-инструментарий, чтобы продавать его, как сервис (Software as a Service).
- А куда перспективней для них и нужнее рынку модель разработки комплексных решений, сквозным образом решающих конкретную задачу бизнеса (Solution as a Service).
Только работая по модели Solution as a Service в области ML,
• ML –стартапы могут создавать значительную новую ценность для его пользователей
• и обретают возможность не сколько просаживать миллионы на НИРоподобных полуисследовательских разработках, сколько созидать новый реальный бизнес, вмонтировав в свой сервис новую ценность для пользователей.
Рекомендации Натана Бенайха конкретны и детальны. И потому нет смысла их пересказывать. Прочтите сами.
Мне же остается лишь добавить, что Кай-Фу Ли и прочие Чингачгуки китайского ИИ это поняли одними из первых. Но при этом они никого не увещевают и, вообще не говорят про это. А просто делают. На то они и китайцы.
Но большинство стартапов за пределами Китая (и у нас тоже) предпочитают идти устаревшим путем времен SaaS-бума. И потому так ценен манифест Натана Бенайха. И будь моя воля, я бы расписал им стены не только стартапов, но и инвест-фондов, так пока и не понявших, где зарыта основная Value успешных ML–стартапов.
Манифест - https://sifted.eu/articles/machine-learning-full-stack/
Отчет «State of AI» Натана Бенайха и Яна Хогарта за 2019 - https://t.me/theworldisnoteasy/816
#МашинноеОбучение #Стартапы
Обращение венчурного инвестора и топового ИИ-эксперта к ML-стартапам.
Уже 2 года, как лучшим отчетом о состоянии ИИ в мире является «State of AI» Натана Бенайха и Яна Хогарта. И если вы его читаете, то обладаете «всей самой актуальной и нужной информацией о состоянии ИИ».
А теперь прочтите манифест Натана Бенайха «Machine learning: go full stack or go home» (Машинное обучение: станьте комплексными или расходитесь) – обращение к стартапам, работающим в области машинного обучения (ML).
Ключевая мысль обращения такая.
1. (Преамбула 1) ML – самое хайповое направление для современных стартапов.
2. (Преамбула 2) Будущее ML во многом зависит именно от них (ибо даже если когда-то они станут новыми DeepMind и их купит Google, инновационный вектор их разработок складывается сейчас).
3. (Это и есть, собственно мысль) Подавляющее число ML-стартапов имеет устаревшую и малоперспективную бизнес-модель.
- Они делают ML-инструментарий, чтобы продавать его, как сервис (Software as a Service).
- А куда перспективней для них и нужнее рынку модель разработки комплексных решений, сквозным образом решающих конкретную задачу бизнеса (Solution as a Service).
Только работая по модели Solution as a Service в области ML,
• ML –стартапы могут создавать значительную новую ценность для его пользователей
• и обретают возможность не сколько просаживать миллионы на НИРоподобных полуисследовательских разработках, сколько созидать новый реальный бизнес, вмонтировав в свой сервис новую ценность для пользователей.
Рекомендации Натана Бенайха конкретны и детальны. И потому нет смысла их пересказывать. Прочтите сами.
Мне же остается лишь добавить, что Кай-Фу Ли и прочие Чингачгуки китайского ИИ это поняли одними из первых. Но при этом они никого не увещевают и, вообще не говорят про это. А просто делают. На то они и китайцы.
Но большинство стартапов за пределами Китая (и у нас тоже) предпочитают идти устаревшим путем времен SaaS-бума. И потому так ценен манифест Натана Бенайха. И будь моя воля, я бы расписал им стены не только стартапов, но и инвест-фондов, так пока и не понявших, где зарыта основная Value успешных ML–стартапов.
Манифест - https://sifted.eu/articles/machine-learning-full-stack/
Отчет «State of AI» Натана Бенайха и Яна Хогарта за 2019 - https://t.me/theworldisnoteasy/816
#МашинноеОбучение #Стартапы
Sifted
Machine learning: go full stack or go home
Traditional machine learning startups building single tools have the wrong idea. Today, companies need to be full-stack to thrive.
В знаменитом рассказе Джейкобса «Обезьянья лапа», мумифицированная лапа обезьяны, на которую наложено заклятье, выполняла любые желания, но с чудовищными последствиями для пожелавших. Для людей подобные последствия были просто невообразимы из-за их чудовищной бесчеловечностии, немыслимой для человека.
Но у прОклятой старым факиром обезьяньей лапы была иная — нечеловеческая структура предпочтений. И потому, выполняя желания людей, она вовсе не со зла, а просто автоматом, преподносила людям страшные сюрпризы, выходящие за пределы воображения имевших несчастье обратиться к ней с просьбой.
Страшный рассказ оказался пророческим. В XXI веке обезьянья лапа материализовалась в виде некоторых прорывных IT технологий. Подарочек столь желанных нам соцсетей мы уже от неё получили. На очереди не менее желанный людям Сильный ИИ.
Что же будет, если с Сильным ИИ повторится история обезьяньей лапы, буквально на наших глазах произошедшая с соцсетями?
Скорее всего, цена новой ошибки может оказаться для человечества неподъемной.
Почему так? И как этого избежать?
Читайте об этом в новом посте (7 мин. чтения):
- на Medium http://bit.do/fdEMf
- На Яндекс Дзен https://clck.ru/JbAxN
#СильныйИИ #AGI #МашинноеОбучение #IRL
Но у прОклятой старым факиром обезьяньей лапы была иная — нечеловеческая структура предпочтений. И потому, выполняя желания людей, она вовсе не со зла, а просто автоматом, преподносила людям страшные сюрпризы, выходящие за пределы воображения имевших несчастье обратиться к ней с просьбой.
Страшный рассказ оказался пророческим. В XXI веке обезьянья лапа материализовалась в виде некоторых прорывных IT технологий. Подарочек столь желанных нам соцсетей мы уже от неё получили. На очереди не менее желанный людям Сильный ИИ.
Что же будет, если с Сильным ИИ повторится история обезьяньей лапы, буквально на наших глазах произошедшая с соцсетями?
Скорее всего, цена новой ошибки может оказаться для человечества неподъемной.
Почему так? И как этого избежать?
Читайте об этом в новом посте (7 мин. чтения):
- на Medium http://bit.do/fdEMf
- На Яндекс Дзен https://clck.ru/JbAxN
#СильныйИИ #AGI #МашинноеОбучение #IRL
Medium
Обезьянья лапа прорывных технологий
Соцсети мы от нее уже получили. На очереди Сильный ИИ
А существует ли справедливость?
Мы можем заставить ИИ не быть расистом, но будет ли это справедливо?
В последнюю пару лет на пути расширения использования ИИ на основе машинного обучения образовывался все более фундаментальный завал – неконтролируемая предвзятость. Она проявлялась во всевозможных формах дискриминации со стороны алгоритмов чернокожих, женщин, малообеспеченных, пожилых и т.д. буквально во всем: от процента кредита до решений о досрочном освобождении из заключения.
Проблема стала настолько серьезной, что на нее навалились всем миром: IT-гиганты и стартапы, военные и разведка, университеты и хакатоны …
И вот, похоже, принципиальное решение найдено. Им стал «Алгоритм Селдона» (детали см. здесь: популярно, научно). Он назван так в честь персонажа легендарного романа «Основание» Айзека Азимова математика Гэри Селдона. Ситуация в романе здорово напоминает нашу сегодняшнюю. Галактическая империя разваливалась, отчасти потому, что выполнение Трех законов робототехники требует гарантий, что ни один человек не пострадает в результате действий роботов. Это парализует любые действия роботов и заводит ситуацию в тупик. Селдон же предложил, как исправить это, обратившись к вероятностным рассуждениям о безопасности.
Разработчики «Алгоритма Селдона» (из США и Бразилии) пошли тем же путем. В результате получился фреймворк для разработки алгоритмов машинного обучения, облегчающий пользователям алгоритма указывать ограничения безопасности и избегания дискриминации (это можно условно назвать справедливостью).
Идея 1й версии «Алгоритма Селдона» была предложена еще 2 года назад. Но нужно было проверить на практике, как она работает. 1е тестирование было на задаче прогнозирования средних баллов в наборе данных из 43 000 учащихся в Бразилии. Все предыдущие алгоритмы машинного обучения дискриминировали женщин. 2е тестирование касалось задачи улучшения алгоритма управления контроллера инсулиновой помпы, чтобы он из-за предвзятостей не увеличивал частоту гипогликемии. Оба теста показали, что «Алгоритм Селдона» позволяет минимизировать предвзятость.
Казалось бы, ура (!?). Не совсем.
Засада может ждать впереди (опять же, как и предсказано Азимовым). Проблема в понимании людьми справедливости. Алгоритмы же так и так ни черта не понимают. И потому решать, что справедливо, а что нет, «Алгоритма Селдона» предлагает людям. Фреймворк позволяет использовать альтернативные определения справедливости. Люди сами должны выбрать, что им подходит, а «Алгоритм Селдона» потом проследит, чтобы выбранная «справедливость» не была нарушена. Однако даже среди экспертов существуют порядка 30 различных определений справедливости. И если даже эксперты не могут договориться о том, что справедливо, было бы странно перекладывать бремя решений на менее опытных пользователей.
В результате может получиться следующее:
• Пользователь рассудит, что справедливо, и задаст правила справедливости алгоритму.
• «Алгоритм Селдона» отследит выполнение правил.
• Но, по-честному, люди так и не будут уверены, справедливо ли они рассудили или нет.
#МашинноеОбучение #Справедливость #ПредвзятостьИИ
Мы можем заставить ИИ не быть расистом, но будет ли это справедливо?
В последнюю пару лет на пути расширения использования ИИ на основе машинного обучения образовывался все более фундаментальный завал – неконтролируемая предвзятость. Она проявлялась во всевозможных формах дискриминации со стороны алгоритмов чернокожих, женщин, малообеспеченных, пожилых и т.д. буквально во всем: от процента кредита до решений о досрочном освобождении из заключения.
Проблема стала настолько серьезной, что на нее навалились всем миром: IT-гиганты и стартапы, военные и разведка, университеты и хакатоны …
И вот, похоже, принципиальное решение найдено. Им стал «Алгоритм Селдона» (детали см. здесь: популярно, научно). Он назван так в честь персонажа легендарного романа «Основание» Айзека Азимова математика Гэри Селдона. Ситуация в романе здорово напоминает нашу сегодняшнюю. Галактическая империя разваливалась, отчасти потому, что выполнение Трех законов робототехники требует гарантий, что ни один человек не пострадает в результате действий роботов. Это парализует любые действия роботов и заводит ситуацию в тупик. Селдон же предложил, как исправить это, обратившись к вероятностным рассуждениям о безопасности.
Разработчики «Алгоритма Селдона» (из США и Бразилии) пошли тем же путем. В результате получился фреймворк для разработки алгоритмов машинного обучения, облегчающий пользователям алгоритма указывать ограничения безопасности и избегания дискриминации (это можно условно назвать справедливостью).
Идея 1й версии «Алгоритма Селдона» была предложена еще 2 года назад. Но нужно было проверить на практике, как она работает. 1е тестирование было на задаче прогнозирования средних баллов в наборе данных из 43 000 учащихся в Бразилии. Все предыдущие алгоритмы машинного обучения дискриминировали женщин. 2е тестирование касалось задачи улучшения алгоритма управления контроллера инсулиновой помпы, чтобы он из-за предвзятостей не увеличивал частоту гипогликемии. Оба теста показали, что «Алгоритм Селдона» позволяет минимизировать предвзятость.
Казалось бы, ура (!?). Не совсем.
Засада может ждать впереди (опять же, как и предсказано Азимовым). Проблема в понимании людьми справедливости. Алгоритмы же так и так ни черта не понимают. И потому решать, что справедливо, а что нет, «Алгоритма Селдона» предлагает людям. Фреймворк позволяет использовать альтернативные определения справедливости. Люди сами должны выбрать, что им подходит, а «Алгоритм Селдона» потом проследит, чтобы выбранная «справедливость» не была нарушена. Однако даже среди экспертов существуют порядка 30 различных определений справедливости. И если даже эксперты не могут договориться о том, что справедливо, было бы странно перекладывать бремя решений на менее опытных пользователей.
В результате может получиться следующее:
• Пользователь рассудит, что справедливо, и задаст правила справедливости алгоритму.
• «Алгоритм Селдона» отследит выполнение правил.
• Но, по-честному, люди так и не будут уверены, справедливо ли они рассудили или нет.
#МашинноеОбучение #Справедливость #ПредвзятостьИИ
Wired
Researchers Want Guardrails to Help Prevent Bias in AI
Machine-learning experts often design their algorithms to avoid some unintended consequences. But that’s not as easy for others.
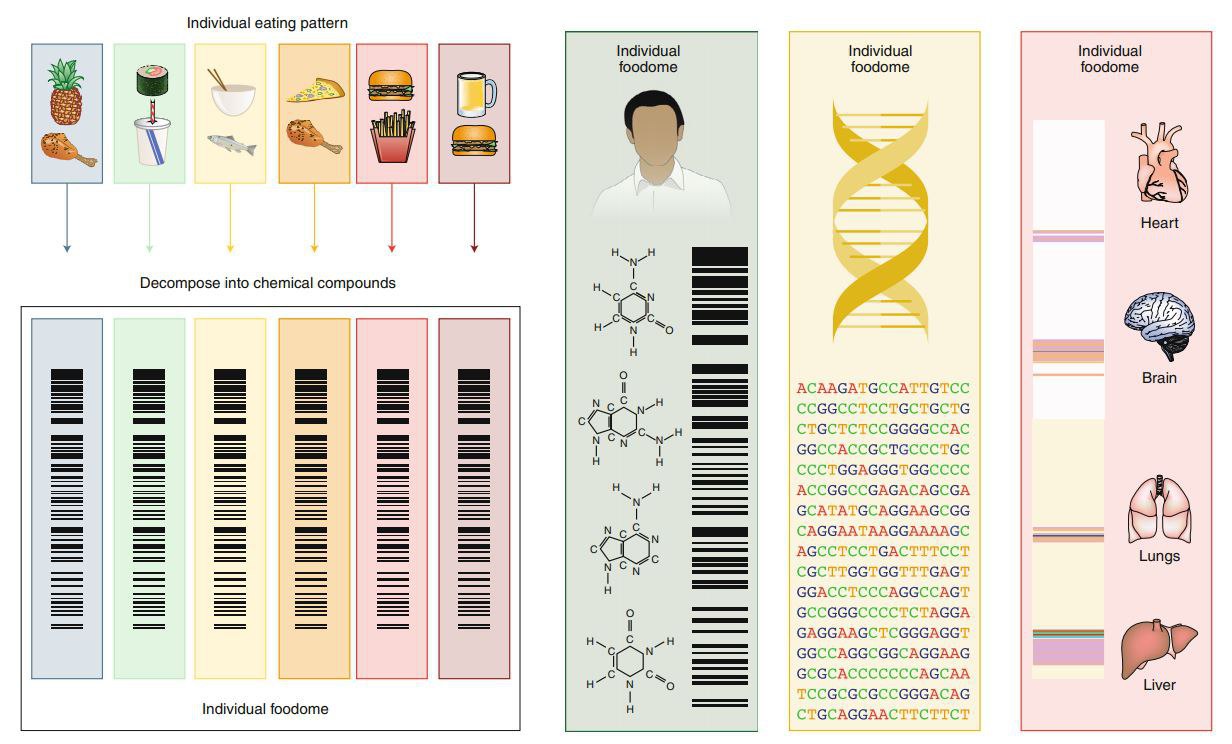
Тайна «темной материи», которую мы едим.
Эйнштейн 21 века задумал революцию в диетах.
Изречение «ты есть то, что ты ешь» сегодня, в эпоху современной медицины, еще более верно, чем 200 лет назад, когда это было сказано впервые.
Более того, современная наука расширила эту мысль до:
- «скажи мне, что ты ешь, и я скажу, кто ты», теперь относя смысл фразы не только к физической форме, но и к интеллектуальным способностям;
- «скажи мне, что ела твоя мать, когда вынашивала, а потом кормила тебя, и я скажу тебе ...».
Короче, еда для нас – это всё.
Но в том-то и жуткий сюрприз, что
при всех успехах диетологии и, в целом, медицинских наук, мы, оказывается, ни черта не знаем о том, как еда влияет на наше здоровье и интеллект.
Вот пример.
О безглютеновой диете известно более 100 лет, когда появилось понятие «целиакия» — аллергия на клейковину - дерматит, диарея, замедление роста. Сегодняшняя безглютеновая диета заменяет пшеницу, рожь, ячмень и овес мукой и крупой из кукурузы, риса, гречки и сои. Но скрытый глютен диетологи теперь находят в соусах, сосисках, сыре, чае…
Почему?
Да потому, что полный количественный состав биохимических веществ продуктов питания неизвестен!
Национальные стандарты, отслеживающие, как пища влияет на здоровье, основываются примерно на 150 пищевых компонентах.
А их, на самом деле, в пище более 26 тыс.
Многие из них имеют документально подтвержденные последствия для здоровья, но остаются неквантифицированными каким-либо систематическим образом для конкретных продуктов питания. Это и есть «темная материя» еды:
- составляющая минимум 2/3 того, что мы съедаем;
- и обладающая неквантифицированным, а то и, вообще, неизвестным влиянием на наше здоровье и интеллект.
Например, чеснок.
Масса людей знает про себя, что от чеснока им худо. Но почему, - никакой врач точно сказать не готов.
А вот почему.
1) Даже в самых продвинутых базах данных содержатся количественные сведения лишь о 67 питательных компонентах сырого чеснока (марганец, витамин В6, селен ...).
Однако, зубчик чеснока содержит 2300+ различных химических компонентов - от аллицина, соединения серы, отвечающего за отчетливый аромат, до лютеолина, флавона, обладающего защитным действием при сердечно-сосудистых заболеваниях.
2) Влияние каждого из элементов «темной материи» еды на индивидуальный организм уникально. Эта уникальность определяется уникальностью ДНК. Но связать квантифицированные данные о точном составе «темной материи» с индивидуальным кодом ДНК никто пока не брался.
И вот сенсация.
Альберт-Ласло Барабаши (которого я не без оснований назвал Эйнштейном 21 века) планирует в течение 10 лет произвести переворот в питании человечества.
Путем машинного обучения на Больших Данных, описывающих (1) полный биохимический состав высокого разрешения всех продуктов питания и (2) генетические коды конкретных людей, он собирается:
1) расшифровать «тайную материю» продуктов питания – произвести систематическое картирование полного биохимического состава пищи;
2) разработать полный биохимический спектр «дорожных карт» индивидуальных диет, чтобы питание могло конкурировать с генетикой по точности, охвату и влиянию.
Результатом станет индивидуальный питательно-химический «штрих-код» для каждого человека, определяющий оптимальный спектр индивидуально показанных пищевых продуктов (пример «штрих-кода» показан на рисунке в заглавии поста).
И будет людям здоровье и счастье. А лекарства – только в случаях, когда «штрих-код» засбоит, и нужно будет это подправить.
Да, еще кое-что. Это здорово улучшит ожидаемую продолжительность жизни. Как будто люди перестанут заправлять бензобаки своих авто загрязненным и разбавленным ослиной мочой низкосортным бензином АИ-80 и перейдут на лучшие сорта топлива высокой очистки, да еще и оптимизированное под тип двигателя.
Подробней – The unmapped chemical complexity of our diet
#МашинноеОбучение #БольшиеДанные #Диета #Геном
Эйнштейн 21 века задумал революцию в диетах.
Изречение «ты есть то, что ты ешь» сегодня, в эпоху современной медицины, еще более верно, чем 200 лет назад, когда это было сказано впервые.
Более того, современная наука расширила эту мысль до:
- «скажи мне, что ты ешь, и я скажу, кто ты», теперь относя смысл фразы не только к физической форме, но и к интеллектуальным способностям;
- «скажи мне, что ела твоя мать, когда вынашивала, а потом кормила тебя, и я скажу тебе ...».
Короче, еда для нас – это всё.
Но в том-то и жуткий сюрприз, что
при всех успехах диетологии и, в целом, медицинских наук, мы, оказывается, ни черта не знаем о том, как еда влияет на наше здоровье и интеллект.
Вот пример.
О безглютеновой диете известно более 100 лет, когда появилось понятие «целиакия» — аллергия на клейковину - дерматит, диарея, замедление роста. Сегодняшняя безглютеновая диета заменяет пшеницу, рожь, ячмень и овес мукой и крупой из кукурузы, риса, гречки и сои. Но скрытый глютен диетологи теперь находят в соусах, сосисках, сыре, чае…
Почему?
Да потому, что полный количественный состав биохимических веществ продуктов питания неизвестен!
Национальные стандарты, отслеживающие, как пища влияет на здоровье, основываются примерно на 150 пищевых компонентах.
А их, на самом деле, в пище более 26 тыс.
Многие из них имеют документально подтвержденные последствия для здоровья, но остаются неквантифицированными каким-либо систематическим образом для конкретных продуктов питания. Это и есть «темная материя» еды:
- составляющая минимум 2/3 того, что мы съедаем;
- и обладающая неквантифицированным, а то и, вообще, неизвестным влиянием на наше здоровье и интеллект.
Например, чеснок.
Масса людей знает про себя, что от чеснока им худо. Но почему, - никакой врач точно сказать не готов.
А вот почему.
1) Даже в самых продвинутых базах данных содержатся количественные сведения лишь о 67 питательных компонентах сырого чеснока (марганец, витамин В6, селен ...).
Однако, зубчик чеснока содержит 2300+ различных химических компонентов - от аллицина, соединения серы, отвечающего за отчетливый аромат, до лютеолина, флавона, обладающего защитным действием при сердечно-сосудистых заболеваниях.
2) Влияние каждого из элементов «темной материи» еды на индивидуальный организм уникально. Эта уникальность определяется уникальностью ДНК. Но связать квантифицированные данные о точном составе «темной материи» с индивидуальным кодом ДНК никто пока не брался.
И вот сенсация.
Альберт-Ласло Барабаши (которого я не без оснований назвал Эйнштейном 21 века) планирует в течение 10 лет произвести переворот в питании человечества.
Путем машинного обучения на Больших Данных, описывающих (1) полный биохимический состав высокого разрешения всех продуктов питания и (2) генетические коды конкретных людей, он собирается:
1) расшифровать «тайную материю» продуктов питания – произвести систематическое картирование полного биохимического состава пищи;
2) разработать полный биохимический спектр «дорожных карт» индивидуальных диет, чтобы питание могло конкурировать с генетикой по точности, охвату и влиянию.
Результатом станет индивидуальный питательно-химический «штрих-код» для каждого человека, определяющий оптимальный спектр индивидуально показанных пищевых продуктов (пример «штрих-кода» показан на рисунке в заглавии поста).
И будет людям здоровье и счастье. А лекарства – только в случаях, когда «штрих-код» засбоит, и нужно будет это подправить.
Да, еще кое-что. Это здорово улучшит ожидаемую продолжительность жизни. Как будто люди перестанут заправлять бензобаки своих авто загрязненным и разбавленным ослиной мочой низкосортным бензином АИ-80 и перейдут на лучшие сорта топлива высокой очистки, да еще и оптимизированное под тип двигателя.
Подробней – The unmapped chemical complexity of our diet
#МашинноеОбучение #БольшиеДанные #Диета #Геном
{kind=link}
Вот и дождались сбычи устрашающего прогноза Харари, что алгоритмы машинного обучения будут знать о нас больше, чем родная мама. Осталось понять - что же такое узнал о нас новый алгоритм?
Короткий ответ – он узнал и наглядно показал непреодолимую глубину нашего несовершенства. Люди взглянули на себя в зеркало ИИ и поразились, насколько же они предвзяты. А также осознали (хотя лишь немногие), сколь высокую цену заплатил Homo sapiens эволюции за дарованные ею нам интеллектуальные способности.
Цена оказалась крайне высока. Мы заплатили тем, что в наше сознание автоматически загружается «библиотека стандартных программ общечеловеческих предрассудков». Эта загрузка осуществляется путем прошивки генно-культурной памяти людей. И отказаться от ее загрузки в наше сознание нельзя. Равно как и повлиять на содержимое этой «библиотеки», обобщающей в себе опыт эволюционного приспособления к жизни десятков миллиардов живших до нас на Земле Homo.
Одной из важнейших «стандартных программ» в этой библиотеке является программа определения, насколько внушает доверие чужой человек (для своих работает другая стандартная программа). И хотя физиогномика и френология, по современным научным представлениям, абсолютно несостоятельны (в действительности, психические свойства человека не определяются ни чертами его лица, ни строением черепа), вмонтированная в нас «стандартная программа оценки надежности» чужих людей построена на тех же принципах, что и эти 2 лженауки.
Результат этого – набор непреодолимых предвзятостей наших суждений на основе подсознательной оценки внешности людей. Эти предвзятости питают социальные фобии: от расизма до многообразных негативных оценок чужих людей (напр. людей с особенностями).
Новое исследование Николя Бомара (Nicolas Baumard не старший в группе исследователей, но главный закоперщик) поставило две оригинальные задачи:
1) Путем машинного обучения, научить алгоритм как можно более точному воспроизведению человеческих предвзятостей при оценке надежности чужих людей по их внешности.
2) Путем применения полученного алгоритма к огромной исторической базе портретов, попытаться оценить, менялось ли во времени (и если да, то как и почему) восприятие надежности лиц чужих людей.
Итогом публикации результатов исследования в Nature стал колоссальный скандал. Из-за обрушившейся на редакцию лавины критики, им пришлось сделать приписку, что «читатели предупреждены о том, что эта статья подвергается активной критике». И действительно, социальные сети просто взорвались негодованием. А учетная запись Николя Бомара, заварившего эту кашу в Twitter, оказалась стёртой.
Продолжить чтение (еще на 7 мин):
- на Medium http://bit.do/fJ2Q9
- на Яндекс Дзен https://clck.ru/RDQHW
#эволюционнаяпсихология #машинноеобучение
Короткий ответ – он узнал и наглядно показал непреодолимую глубину нашего несовершенства. Люди взглянули на себя в зеркало ИИ и поразились, насколько же они предвзяты. А также осознали (хотя лишь немногие), сколь высокую цену заплатил Homo sapiens эволюции за дарованные ею нам интеллектуальные способности.
Цена оказалась крайне высока. Мы заплатили тем, что в наше сознание автоматически загружается «библиотека стандартных программ общечеловеческих предрассудков». Эта загрузка осуществляется путем прошивки генно-культурной памяти людей. И отказаться от ее загрузки в наше сознание нельзя. Равно как и повлиять на содержимое этой «библиотеки», обобщающей в себе опыт эволюционного приспособления к жизни десятков миллиардов живших до нас на Земле Homo.
Одной из важнейших «стандартных программ» в этой библиотеке является программа определения, насколько внушает доверие чужой человек (для своих работает другая стандартная программа). И хотя физиогномика и френология, по современным научным представлениям, абсолютно несостоятельны (в действительности, психические свойства человека не определяются ни чертами его лица, ни строением черепа), вмонтированная в нас «стандартная программа оценки надежности» чужих людей построена на тех же принципах, что и эти 2 лженауки.
Результат этого – набор непреодолимых предвзятостей наших суждений на основе подсознательной оценки внешности людей. Эти предвзятости питают социальные фобии: от расизма до многообразных негативных оценок чужих людей (напр. людей с особенностями).
Новое исследование Николя Бомара (Nicolas Baumard не старший в группе исследователей, но главный закоперщик) поставило две оригинальные задачи:
1) Путем машинного обучения, научить алгоритм как можно более точному воспроизведению человеческих предвзятостей при оценке надежности чужих людей по их внешности.
2) Путем применения полученного алгоритма к огромной исторической базе портретов, попытаться оценить, менялось ли во времени (и если да, то как и почему) восприятие надежности лиц чужих людей.
Итогом публикации результатов исследования в Nature стал колоссальный скандал. Из-за обрушившейся на редакцию лавины критики, им пришлось сделать приписку, что «читатели предупреждены о том, что эта статья подвергается активной критике». И действительно, социальные сети просто взорвались негодованием. А учетная запись Николя Бомара, заварившего эту кашу в Twitter, оказалась стёртой.
Продолжить чтение (еще на 7 мин):
- на Medium http://bit.do/fJ2Q9
- на Яндекс Дзен https://clck.ru/RDQHW
#эволюционнаяпсихология #машинноеобучение
Решение этических проблем ИИ только одно -
меньше использовать ИИ
Иначе:
1) Антиэволюция предубеждений Homo sapiens превратит нас в социальных идиотов.
Расовые, гендерных и прочие социальные предубеждения ИИ-алгоритмов соцсетей - это мощнейший катализатор усиления наших и без того немалых предубеждений.
2) Глубокие фейки станут главным медийным инструментом политиков.
Они уже их используют и весьма успешно, разрушая моральные барьеры и размывая границы реальности.
3) Новые изощренные формы извращений войдут в обычную практику привлечения медиа аудитории
Например, даже Пелевин не додумался до такого извращения, как «техномантия» - техновоскрешение умерших для повышения внимания аудитории. А медиакомпании этим уже пользуются.
На 100% разделяю предложение Джека Кларка (Jack Clark, OpenAI Strategy and Communications Director) о целесообразности уменьшения использования ИИ. Пока не придуманы способы борьбы с конкретными рисками применения ИИ, его применение в областях, где эти риски значимы, следует ограничить.
Вот 3 примера, приводимые Кларком в новом выпуске его великолепного канала IMPORT AI
1) Twitter принял решение меньше использовать машинное обучение и предоставить пользователям больше контроля над тем, как выглядят их фото в сети.
Причина в том, что внедренные в 2018 нейронки для интеллектуальной автоматической обрезки изображений облажались.
И теперь компания принимает честное и умное решение:
«Хотя наш анализ на сегодняшний день не выявил расовых или гендерных предубеждений, мы понимаем, что то, как мы автоматически кадрируем фотографии, означает, что существует потенциальный вред. Мы должны были лучше предвидеть эту возможность, когда мы впервые проектировали и создавали этот продукт».
2) Кандидат в Палату представителей США Фил Эр, баллотирующийся во Флориде, построил свою предвыборную рекламу так. Синтезированный технологией глубоких фейков Мэтт Гаец «говорит»: Q-anon - отстой, Барак Обама крут, и что он голосует за Джо Байдена. Затем Фил Эр предупреждает зрителей, что они только что видели пример «глубокой фальшивой технологии». И добавляет убойный аргумент: «Если наша кампания сможет снять подобное видео, представьте, что сейчас делает Путин?»
3) Чтобы повлиять на выбор избирателей на грядущих в ноябре выборах, группа компаний Change the Ref использовала технологию глубоких фейков для воскрешения Хоакина Оливера, застреленного в 2018 при стрельбе в школе Паркленда. Вот как выглядит эта «техномантия»: «Его родители использовали ИИ, чтобы вернуть Хоакина, дабы он рассказал людям, как голосование может предотвратить подобные трагедии в других семьях».
И вот убитый парень экспрессивно агитирует проголосовать за него самого, за тех, кого еще не убили, и за правильного кандидата в президенты США.
Вот как живенько он при этом выглядит.
#Deepfakes #РискиИИ #ПредвзятостьИИ #МашинноеОбучение
меньше использовать ИИ
Иначе:
1) Антиэволюция предубеждений Homo sapiens превратит нас в социальных идиотов.
Расовые, гендерных и прочие социальные предубеждения ИИ-алгоритмов соцсетей - это мощнейший катализатор усиления наших и без того немалых предубеждений.
2) Глубокие фейки станут главным медийным инструментом политиков.
Они уже их используют и весьма успешно, разрушая моральные барьеры и размывая границы реальности.
3) Новые изощренные формы извращений войдут в обычную практику привлечения медиа аудитории
Например, даже Пелевин не додумался до такого извращения, как «техномантия» - техновоскрешение умерших для повышения внимания аудитории. А медиакомпании этим уже пользуются.
На 100% разделяю предложение Джека Кларка (Jack Clark, OpenAI Strategy and Communications Director) о целесообразности уменьшения использования ИИ. Пока не придуманы способы борьбы с конкретными рисками применения ИИ, его применение в областях, где эти риски значимы, следует ограничить.
Вот 3 примера, приводимые Кларком в новом выпуске его великолепного канала IMPORT AI
1) Twitter принял решение меньше использовать машинное обучение и предоставить пользователям больше контроля над тем, как выглядят их фото в сети.
Причина в том, что внедренные в 2018 нейронки для интеллектуальной автоматической обрезки изображений облажались.
И теперь компания принимает честное и умное решение:
«Хотя наш анализ на сегодняшний день не выявил расовых или гендерных предубеждений, мы понимаем, что то, как мы автоматически кадрируем фотографии, означает, что существует потенциальный вред. Мы должны были лучше предвидеть эту возможность, когда мы впервые проектировали и создавали этот продукт».
2) Кандидат в Палату представителей США Фил Эр, баллотирующийся во Флориде, построил свою предвыборную рекламу так. Синтезированный технологией глубоких фейков Мэтт Гаец «говорит»: Q-anon - отстой, Барак Обама крут, и что он голосует за Джо Байдена. Затем Фил Эр предупреждает зрителей, что они только что видели пример «глубокой фальшивой технологии». И добавляет убойный аргумент: «Если наша кампания сможет снять подобное видео, представьте, что сейчас делает Путин?»
3) Чтобы повлиять на выбор избирателей на грядущих в ноябре выборах, группа компаний Change the Ref использовала технологию глубоких фейков для воскрешения Хоакина Оливера, застреленного в 2018 при стрельбе в школе Паркленда. Вот как выглядит эта «техномантия»: «Его родители использовали ИИ, чтобы вернуть Хоакина, дабы он рассказал людям, как голосование может предотвратить подобные трагедии в других семьях».
И вот убитый парень экспрессивно агитирует проголосовать за него самого, за тех, кого еще не убили, и за правильного кандидата в президенты США.
Вот как живенько он при этом выглядит.
#Deepfakes #РискиИИ #ПредвзятостьИИ #МашинноеОбучение
{kind=link}
Лет через тридцать в Википедии будут писать о 2020-ом годе не только в связи с началом пандемии COVID-19. Ведь даже страшнейшая пандемия Испанки не затмила в истории 1918 года окончание Первой мировой и развертывание Гражданской войны в России, революцию в Германии, уничтожившую Германскую империю, и еще около дюжины событий, так или иначе повлиявших на судьбы миллионов людей и имевших последствия в течение десятилетий.
Но пока 2020 не отдалился на ощутимую историческую дистанцию, анализ его важнейших событий субъективен, близорук и отягощен когнитивными искажениями. Сегодняшние западные аналитики, среди важнейших мировых событий прошедшего года, помимо COVID-19, называют, например, смену Трампа Байденом, массовые волнения в США и «самоутверждение Китая» на пути к мировому лидерству. А российские - следом за пандемией, ставят «обнуление» (в комплекте с изменением конституции) и отравление Навального. Все это, конечно же, очень важно.
Но сохранится ли такая оценка 2020–го года лет через 30?
Точного ответа на этот вопрос не знает никто. Но лично мне видится, что в большинстве современных оценок упускается нечто совсем неочевидное, но крайне важное. Важное в том смысле, что повлияет на будущее человечества куда больше, чем смена Трампа на Байдена или «обнуление».
Дело в том, что политическое и социальное устройство общества, мировоззрение, благосостояние, физическое и духовное здоровье, да и повседневная жизнь людей в XXI веке, более всего определяются уже не политикой, религией, идеологией или классовой борьбой, а развитием технологий. И в первую очередь, - информационных, ибо именно они кардинально меняет жизнь новых поколений, уже не знающих, что такое дефицит еды и тепла.
А среди информационных технологий есть, несомненно, лидирующая группа, условно называемая искусственный интеллект (ИИ). Именно ИИ, если воспользоваться метафорическим образом гонок на собаках из любимых мною повестей Джека Лондона, является коренником упряжки современных информационных технологий. Как ни важны действия других «собак» в упряжке (технологии больших данных, облачные вычисления, мобильные технологии и т.д.), но коренник ИИ решающим образом влияет на направление и маневры всей упряжки, в наибольшей мере влияя на результат гонки.
И если посмотреть на 2020 из будущего с точки зрения мировой гонки «технологических упряжек», то вполне возможно,
2020 окажется в истории «годом великого техно-перелома», давшего отсчет новой технологической эпохе, когда на смену техно-оптимизму приходит прагматизация ИИ.
Продолжить чтение (еще 15 мин.)
- на Medium http://bit.do/fMuRP
- на Яндекс Дзен https://clck.ru/SmPGv
#ИИ #AGI #Будущее #МашинноеОбучение
Но пока 2020 не отдалился на ощутимую историческую дистанцию, анализ его важнейших событий субъективен, близорук и отягощен когнитивными искажениями. Сегодняшние западные аналитики, среди важнейших мировых событий прошедшего года, помимо COVID-19, называют, например, смену Трампа Байденом, массовые волнения в США и «самоутверждение Китая» на пути к мировому лидерству. А российские - следом за пандемией, ставят «обнуление» (в комплекте с изменением конституции) и отравление Навального. Все это, конечно же, очень важно.
Но сохранится ли такая оценка 2020–го года лет через 30?
Точного ответа на этот вопрос не знает никто. Но лично мне видится, что в большинстве современных оценок упускается нечто совсем неочевидное, но крайне важное. Важное в том смысле, что повлияет на будущее человечества куда больше, чем смена Трампа на Байдена или «обнуление».
Дело в том, что политическое и социальное устройство общества, мировоззрение, благосостояние, физическое и духовное здоровье, да и повседневная жизнь людей в XXI веке, более всего определяются уже не политикой, религией, идеологией или классовой борьбой, а развитием технологий. И в первую очередь, - информационных, ибо именно они кардинально меняет жизнь новых поколений, уже не знающих, что такое дефицит еды и тепла.
А среди информационных технологий есть, несомненно, лидирующая группа, условно называемая искусственный интеллект (ИИ). Именно ИИ, если воспользоваться метафорическим образом гонок на собаках из любимых мною повестей Джека Лондона, является коренником упряжки современных информационных технологий. Как ни важны действия других «собак» в упряжке (технологии больших данных, облачные вычисления, мобильные технологии и т.д.), но коренник ИИ решающим образом влияет на направление и маневры всей упряжки, в наибольшей мере влияя на результат гонки.
И если посмотреть на 2020 из будущего с точки зрения мировой гонки «технологических упряжек», то вполне возможно,
2020 окажется в истории «годом великого техно-перелома», давшего отсчет новой технологической эпохе, когда на смену техно-оптимизму приходит прагматизация ИИ.
Продолжить чтение (еще 15 мин.)
- на Medium http://bit.do/fMuRP
- на Яндекс Дзен https://clck.ru/SmPGv
#ИИ #AGI #Будущее #МашинноеОбучение
Medium
Великий техно-перелом 2020
От техно-оптимизма к прагматизации ИИ
Алгоритмическое растление путем анестезии совести.
Алгокогнитивная культура способствует деградации морали
Новая статья в Nature, озаглавленная «Плохие машины портят добрую мораль» не упоминает термина алгокогнитивная культура (в германском институте им. Макса Планка этот термин еще не совсем прижился)), но рассказывает именно о её последствиях для отдельных людей и всего общества.
Авторы рассказывают, что «агенты ИИ» влияют на поведение людей способами, которые одновременно похожи и не похожи на то, как люди влияют друг на друга.
N.B. Авторы, следуя терминологическому мейнстриму, называют агентами ИИ «машины, работающие на основе ИИ». Но речь идет вовсе не о каких-то сверх-умных агентах, а о банальных анонимных алгоритмах машинного обучения поисковых, рекомендательных, социальных и профессиональных платформ и сервисов.
Одним из таких чисто алгоритмических влияний является растление общества, вследствие уникальной разлагающей сила алгоритмов. И поскольку об этом факторе влияния алгокогнитивной культуры я еще не писал, весьма рекомендую интересующимся вопросом прочесть работу Нильса Кёбиса, Жан-Франсуа Боннефона и Ияда Рахван (вход за пейвол по этой ссылке).
Авторы рассматривают четыре основные социальные роли, с помощью которых люди и алгоритмы могут влиять на этическое поведение:
• образец для подражания (role model) - решая, нарушать ли этические правила или придерживаться их, люди часто задумываются, как бы поступили на их месте их ролевые модели;
• советник (advisor) - люди могут оказывать более прямое развращающее влияние, чем ролевые модели, когда сами дают советы действовать неэтично, особенно, когда такие советы исходят от авторитетных фигур;
• активный партнер (active partner) – не менее чем неэтичными советниками, люди могут развращать друг друга, становясь партнерами в нарушении моральных норм;
• аутсорсер (delegate) – те, кому люди могут делегировать - передавать на выполнение неэтичные действия, как бы на аутсорсинг.
Ключевой вывод исследования таков.
✔️ Когда алгоритмы становятся инфлюенсерами (образцами для подражания или советниками), их развращающая сила не может превышать развращающую силу людей (но это лишь пока и, увы, довольно скоро пройдет).
✔️ Когда же алгоритмы выступают в роли потакателей (enablers) неэтичного поведения (будучи активным партнером или аутсорсером), они обладают уникальным потенциально особо опасным свойством.
Это свойство наиболее адекватно описывается термином «растление». Ибо оно позволяет людям получать выгоды от своих неэтичных действий и при этом чувствовать себя хорошо, не испытывая угрызений совести.
Примеров такой «анестезии совести» уже не счесть.
• студент, в партнерстве с GPT-3, замастыривающий фейковое эссе;
• ретейлер, передающий на аутсорсинг алгоритму процесс онлайн-прайсинга, приводящего к алгоритмическому сговору;
• кадровик, в партнерстве с алгоритмом оценки кандидата, отсеивающий «лицо кавказской национальности»;
• банковский клерк, передающий на аутсорсинг отказы в кредитовании многодетных семей;
• полицейский, юрист, врач, преподаватель, психоаналитик и т.д. и т.п.
Кроме того, мы даже не представляем себе потенциальные масштабы коррупции, которую могут индуцировать алгоритмы, в сравнении с коррупцией, вызванной действиями людей. Здесь вообще нет пока что каких-либо идей. Но есть подозрение, что алгоритмы могут любой вопрос «перетереть» и «порешать», совсем не отягощаясь моральными нормами.
Нужны эксперименты… Много экспериментов, прежде чем не только отдавать принятие решений алгоритмам, но и просто брать алгоритмы на роли партнеров и аутсорсеров.
И конечно же нужно обучать алгоритмы машинного обучения желательным поведенческим паттернам, а не слепо выбирать самые большие наборы данных, доступные для обучения.
Ну а в идеале, нужно разрабатывать иные методы машинного обучения для областей автоматизации неоднозначных решений, советов и результатов делегируемых действий (об этом, хорошо было бы написать отдельный пост).
#Мораль #АлгокогнитивнаяКультура #МашинноеОбучение #ИИ
Алгокогнитивная культура способствует деградации морали
Новая статья в Nature, озаглавленная «Плохие машины портят добрую мораль» не упоминает термина алгокогнитивная культура (в германском институте им. Макса Планка этот термин еще не совсем прижился)), но рассказывает именно о её последствиях для отдельных людей и всего общества.
Авторы рассказывают, что «агенты ИИ» влияют на поведение людей способами, которые одновременно похожи и не похожи на то, как люди влияют друг на друга.
N.B. Авторы, следуя терминологическому мейнстриму, называют агентами ИИ «машины, работающие на основе ИИ». Но речь идет вовсе не о каких-то сверх-умных агентах, а о банальных анонимных алгоритмах машинного обучения поисковых, рекомендательных, социальных и профессиональных платформ и сервисов.
Одним из таких чисто алгоритмических влияний является растление общества, вследствие уникальной разлагающей сила алгоритмов. И поскольку об этом факторе влияния алгокогнитивной культуры я еще не писал, весьма рекомендую интересующимся вопросом прочесть работу Нильса Кёбиса, Жан-Франсуа Боннефона и Ияда Рахван (вход за пейвол по этой ссылке).
Авторы рассматривают четыре основные социальные роли, с помощью которых люди и алгоритмы могут влиять на этическое поведение:
• образец для подражания (role model) - решая, нарушать ли этические правила или придерживаться их, люди часто задумываются, как бы поступили на их месте их ролевые модели;
• советник (advisor) - люди могут оказывать более прямое развращающее влияние, чем ролевые модели, когда сами дают советы действовать неэтично, особенно, когда такие советы исходят от авторитетных фигур;
• активный партнер (active partner) – не менее чем неэтичными советниками, люди могут развращать друг друга, становясь партнерами в нарушении моральных норм;
• аутсорсер (delegate) – те, кому люди могут делегировать - передавать на выполнение неэтичные действия, как бы на аутсорсинг.
Ключевой вывод исследования таков.
✔️ Когда алгоритмы становятся инфлюенсерами (образцами для подражания или советниками), их развращающая сила не может превышать развращающую силу людей (но это лишь пока и, увы, довольно скоро пройдет).
✔️ Когда же алгоритмы выступают в роли потакателей (enablers) неэтичного поведения (будучи активным партнером или аутсорсером), они обладают уникальным потенциально особо опасным свойством.
Это свойство наиболее адекватно описывается термином «растление». Ибо оно позволяет людям получать выгоды от своих неэтичных действий и при этом чувствовать себя хорошо, не испытывая угрызений совести.
Примеров такой «анестезии совести» уже не счесть.
• студент, в партнерстве с GPT-3, замастыривающий фейковое эссе;
• ретейлер, передающий на аутсорсинг алгоритму процесс онлайн-прайсинга, приводящего к алгоритмическому сговору;
• кадровик, в партнерстве с алгоритмом оценки кандидата, отсеивающий «лицо кавказской национальности»;
• банковский клерк, передающий на аутсорсинг отказы в кредитовании многодетных семей;
• полицейский, юрист, врач, преподаватель, психоаналитик и т.д. и т.п.
Кроме того, мы даже не представляем себе потенциальные масштабы коррупции, которую могут индуцировать алгоритмы, в сравнении с коррупцией, вызванной действиями людей. Здесь вообще нет пока что каких-либо идей. Но есть подозрение, что алгоритмы могут любой вопрос «перетереть» и «порешать», совсем не отягощаясь моральными нормами.
Нужны эксперименты… Много экспериментов, прежде чем не только отдавать принятие решений алгоритмам, но и просто брать алгоритмы на роли партнеров и аутсорсеров.
И конечно же нужно обучать алгоритмы машинного обучения желательным поведенческим паттернам, а не слепо выбирать самые большие наборы данных, доступные для обучения.
Ну а в идеале, нужно разрабатывать иные методы машинного обучения для областей автоматизации неоднозначных решений, советов и результатов делегируемых действий (об этом, хорошо было бы написать отдельный пост).
#Мораль #АлгокогнитивнаяКультура #МашинноеОбучение #ИИ
Nature
Bad machines corrupt good morals
Nature Human Behaviour - Köbis et al. outline how artificial intelligence (AI) agents can negatively influence human ethical behaviour. They discuss how this capacity of AI agents can cause...
Прорыв в ИИ может произойти уже до конца этого года.
Начинается всемирный поиск новых ИИ-моделей, в котором вы можете участвовать.
Речь идет об объявленном AIcrowd Facebook AI крауд-конкурсе проектирования и обучения альтернативных ИИ-агентов, работающих иначе, чем современный мейнстрим машинного обучения с подкреплением.
Недавно DeepMind объявил, что обучение с подкреплением — метод, когда ИИ-агент ничего не знает об окружающей среде, но может самообучаться, взаимодействуя с ней, - может позволить прорыв к ИИ человеческого уровня (AGI). Этот метод, действительно, весьма перспективен. Но он требует значительного объема вычислений и мощного компьютерного оборудования. А это, к сожалению, не очень подходит за пределами демонстрационных игр, когда цель – не удивить общественность, а решение практических задач в реальном мире.
Facebook решил попробовать обойти эту проблему, организовав всемирный поиск новых ИИ-моделей, позволяющих ИИ-агентам ориентироваться в сложных средах при низких вычислительных затратах.
В качестве супер-теста была выбрана NetHack — старая, но до сих пор одна из самых сложных игр. В ней игроки должны спуститься на 50+ уровней подземелья, чтобы найти магический амулет. Шансов выиграть в эту игру мало даже у ИИ-агентов, разгромивших людей в StarCraft II, Dota 2 и Minecraft. Ведь в этой игре игроки просто мрут, как мухи. А после каждой смерти подземелье полностью перестраивается, тем самым сводя почти что к нулю набранный опыт.
Единственный способ выиграть в таких адских условиях — каким-то образом суметь совместить нестандартное мышление, исследовательские навыки и удачу. Такой ИИ-агент должен уметь совмещать оптимальное применение уже имеющихся знаний со способностью исследовать совершенно неизученные области (т.е. сочетать exploitation & exploration).
Идея исследователей из Facebook проста. Авторитеты машинного обучения так пока и не преуспели в создании ИИ-агентов, способных учиться с малыми вычислительными затратами. Поэтому вместо того, чтобы самим пытаться поймать «золотую рыбку» прорывной ИИ-модели, Facebook решил провести открытый конкурс, пригласив участвовать всех желающих и предоставив каждому участнику высокотехнологическую «удочку». Ею будет специально разработанная учебная среда с открытым кодом - NetHack Learning Environment (NLE). Это масштабируемая, процедурно генерируемая, стохастическая, весьма сложная среда для исследования обучения с подкреплением в ходе игры ИИ-агента в NetHack.
Работая в среде NLE, участники смогут тратить больше времени на тестирование новых перспективных идей, а не на ожидание результатов длительных вычислений. Перед ними поставлена задача спроектировать и обучить своего агента каким угодно существующим или изобретенным способом - с машинным обучением или без него, с использованием любой внешней информации, любого метода обучения с любым вычислительным бюджетом.
Единственное требование – создать ИИ-агента, который может быть оценен жюри конкурса. О его результатах будут судить по тому, как часто этот агент выживает и поднимается из подземелья с Амулетом.
Среди альтернативных концепций создания моделей ИИ-агентов – имхо, самой перспективной является модель процесса активного вывода (active inference). Суть такого процесса в:
• статистической генерации предсказаний (бессознательных выводов об окружающем мире и самом себе на основе внутренней модели);
• проверке этих выводов на основе сенсорных данных;
• и постоянной минимизации ошибок предсказания.
Активный вывод и прогностическое кодирование, объединенные фундаментальным принципом свободной энергии Карла Фристона я называю «конституция биоматематики». Это, по сути, - высший закон, определяющий основной принцип жизни и разума (подробней см. мой пост).
А теперь о самом важном и интересном.
Дочитать (еще всего на 1 мин):
- на Medium https://bit.ly/3j9Qaf8
- на ЯДзен https://clck.ru/VgSju
#ИИ #МашинноеОбучение #ПринципСвободнойЭнергии #Фристон #АктивныйВывод
Начинается всемирный поиск новых ИИ-моделей, в котором вы можете участвовать.
Речь идет об объявленном AIcrowd Facebook AI крауд-конкурсе проектирования и обучения альтернативных ИИ-агентов, работающих иначе, чем современный мейнстрим машинного обучения с подкреплением.
Недавно DeepMind объявил, что обучение с подкреплением — метод, когда ИИ-агент ничего не знает об окружающей среде, но может самообучаться, взаимодействуя с ней, - может позволить прорыв к ИИ человеческого уровня (AGI). Этот метод, действительно, весьма перспективен. Но он требует значительного объема вычислений и мощного компьютерного оборудования. А это, к сожалению, не очень подходит за пределами демонстрационных игр, когда цель – не удивить общественность, а решение практических задач в реальном мире.
Facebook решил попробовать обойти эту проблему, организовав всемирный поиск новых ИИ-моделей, позволяющих ИИ-агентам ориентироваться в сложных средах при низких вычислительных затратах.
В качестве супер-теста была выбрана NetHack — старая, но до сих пор одна из самых сложных игр. В ней игроки должны спуститься на 50+ уровней подземелья, чтобы найти магический амулет. Шансов выиграть в эту игру мало даже у ИИ-агентов, разгромивших людей в StarCraft II, Dota 2 и Minecraft. Ведь в этой игре игроки просто мрут, как мухи. А после каждой смерти подземелье полностью перестраивается, тем самым сводя почти что к нулю набранный опыт.
Единственный способ выиграть в таких адских условиях — каким-то образом суметь совместить нестандартное мышление, исследовательские навыки и удачу. Такой ИИ-агент должен уметь совмещать оптимальное применение уже имеющихся знаний со способностью исследовать совершенно неизученные области (т.е. сочетать exploitation & exploration).
Идея исследователей из Facebook проста. Авторитеты машинного обучения так пока и не преуспели в создании ИИ-агентов, способных учиться с малыми вычислительными затратами. Поэтому вместо того, чтобы самим пытаться поймать «золотую рыбку» прорывной ИИ-модели, Facebook решил провести открытый конкурс, пригласив участвовать всех желающих и предоставив каждому участнику высокотехнологическую «удочку». Ею будет специально разработанная учебная среда с открытым кодом - NetHack Learning Environment (NLE). Это масштабируемая, процедурно генерируемая, стохастическая, весьма сложная среда для исследования обучения с подкреплением в ходе игры ИИ-агента в NetHack.
Работая в среде NLE, участники смогут тратить больше времени на тестирование новых перспективных идей, а не на ожидание результатов длительных вычислений. Перед ними поставлена задача спроектировать и обучить своего агента каким угодно существующим или изобретенным способом - с машинным обучением или без него, с использованием любой внешней информации, любого метода обучения с любым вычислительным бюджетом.
Единственное требование – создать ИИ-агента, который может быть оценен жюри конкурса. О его результатах будут судить по тому, как часто этот агент выживает и поднимается из подземелья с Амулетом.
Среди альтернативных концепций создания моделей ИИ-агентов – имхо, самой перспективной является модель процесса активного вывода (active inference). Суть такого процесса в:
• статистической генерации предсказаний (бессознательных выводов об окружающем мире и самом себе на основе внутренней модели);
• проверке этих выводов на основе сенсорных данных;
• и постоянной минимизации ошибок предсказания.
Активный вывод и прогностическое кодирование, объединенные фундаментальным принципом свободной энергии Карла Фристона я называю «конституция биоматематики». Это, по сути, - высший закон, определяющий основной принцип жизни и разума (подробней см. мой пост).
А теперь о самом важном и интересном.
Дочитать (еще всего на 1 мин):
- на Medium https://bit.ly/3j9Qaf8
- на ЯДзен https://clck.ru/VgSju
#ИИ #МашинноеОбучение #ПринципСвободнойЭнергии #Фристон #АктивныйВывод
{kind=link}