
По сути, Microsoft показал, что AGI уже здесь.
Поверить в это трудно, но придется.
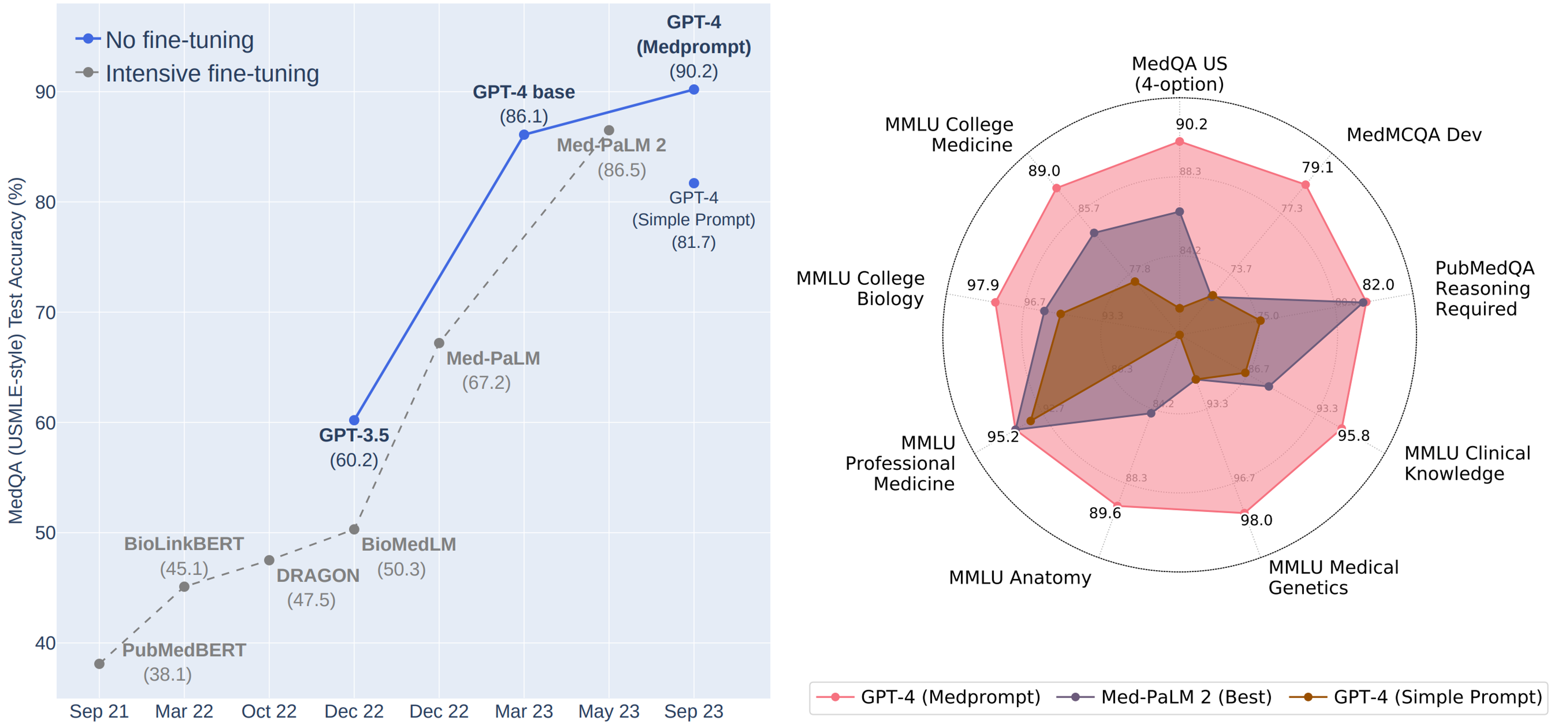
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
{kind=link}
Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Google DeepMind
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce FunSearch, a method for searching for “functions” written in computer code, and find new solutions in mathematics and computer science. FunSearch works by pairing a pre-trained LLM,...
Среди семи прогнозов Stanford HAI - что ожидать от ИИ в 2024, - три ключевых [1]:
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI #Superalignment
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI #Superalignment
Разум в Мультиверсе.
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Яндекс Диск
Разум в Мультиверсе.jpg
Посмотреть и скачать с Яндекс Диска
GPT-5 в 2024 и AGI в 2025.
Сэм Альтман снова взорвал мировые СМИ.
Его откровения за последнюю тройку дней (беседа c Биллом Гейтсом и выступление на стартовом мероприятии Y Combinator W24 в штаб-квартире OpenAI), вполне оправдывают сенсационный заголовок этого поста.
Если смешать, но не взбалтывать сказанное Альтманом, получается, примерно, следующее:
✔️ GPT-5 появится так скоро, что стартапам (и конкурентам) нет смысла фокусироваться на попытках устранения текущих ограничений GPT-4 (ибо большинство из этих ограничений будут частично или полностью устранены в GPT-5)
✔️ ТОР 3 ключевыми прорывами GPT-5 (делающими AGI «весьма близким») будут:
• Мультимодальность (в 1ю очередь «видео на входе и выходе»)
• Гораздо более продвинутая способность рассуждать (в 1ю очередь разблокировка когнитивных способностей Системы 2 - думай медленно в сложной ситуации)
• Надежность (сейчас GPT-4 дает 10К разных ответов на тот же вопрос и не знает, какой из них лучший, GPT-5 даст один – лучший ответ)
#GPT-5 #AGI
Сэм Альтман снова взорвал мировые СМИ.
Его откровения за последнюю тройку дней (беседа c Биллом Гейтсом и выступление на стартовом мероприятии Y Combinator W24 в штаб-квартире OpenAI), вполне оправдывают сенсационный заголовок этого поста.
Если смешать, но не взбалтывать сказанное Альтманом, получается, примерно, следующее:
✔️ GPT-5 появится так скоро, что стартапам (и конкурентам) нет смысла фокусироваться на попытках устранения текущих ограничений GPT-4 (ибо большинство из этих ограничений будут частично или полностью устранены в GPT-5)
✔️ ТОР 3 ключевыми прорывами GPT-5 (делающими AGI «весьма близким») будут:
• Мультимодальность (в 1ю очередь «видео на входе и выходе»)
• Гораздо более продвинутая способность рассуждать (в 1ю очередь разблокировка когнитивных способностей Системы 2 - думай медленно в сложной ситуации)
• Надежность (сейчас GPT-4 дает 10К разных ответов на тот же вопрос и не знает, какой из них лучший, GPT-5 даст один – лучший ответ)
#GPT-5 #AGI
Начался Большой Раскол научного и инженерного подходов к интеллекту.
За кулисами давосской дуэли Карла Фристона и Яна Лекуна.
В ходе вчерашнего диалога на площадке давосского форума Фристон и Лекун стараются выглядеть спокойными и доброжелательными [1]. Фристону это удается лучше: он улыбается и много шутит. Лекуну сложнее: ему явно не до улыбок и шуток. Но он старается держать себя в руках, даже когда Фристон открыто смеётся над делом всей его жизни – глубоким обучением. «Глубокое обучение – полная чушь» - заявляет Фристон и называет набор факторов, принципиально не позволяющих создать человекоподобный интеллект на основе глубокого обучения. Лекун пытается утверждать обратное, однако вместо аргументов говорит лишь о своей субъективной вере в будущие еще не открытые возможности глубокого обучения. И потому «глубокое обучение необходимо, и я готов поспорить, что через 10-20 лет ИИ-системы все еще будут основаны на глубоком обучении».
Важность этого диалога двух «рок-звезд» (как их назвал модератор) в области изучения и создания интеллектуальных систем трудно переоценить. Ибо он знаменует начало открытого раскола двух альтернативных подходов к созданию человекоподобных интеллектуальных агентов:
1. «Инженерный подход к созданию искусственного интеллекта» на основе глубокого обучения, больших данных и больших языковых моделей (LLM) - ныне доминирующий ресурсоемкий и дорогостоящий подход.
2. Альтернативный - научный подход к созданию естественного интеллекта на основе активного вывода, позволяющего построение больших моделей, гибко составленных из более мелких, хорошо понятных моделей, для которых возможно явное, интерпретируемое обновление их убеждений.
Первым формальным заявлением, призывающим мир сменить парадигму разработки интеллектуальных систем, было декабрьское открытое письмо участников Бостонского глобального форума [2]. Среди 25 подписавших, оба наших выдающихся современника, чьи имена, имхо, во 2й половине XXI века, будут упоминаться в одном ряду с Ньютоном, Дарвином и Эйнштейном: Карл Фристон и Майкл Левин.
«Мы, нижеподписавшиеся, считаем, что на данном этапе коммерциализации и регулирования ИИ жизненно важно, чтобы альтернативное и научно обоснованное понимание биологических основ ИИ было публично озвучено, и чтобы были созваны междисциплинарные публичные семинары среди законодателей, регулирующих органов и технологов, инвесторов, ученых, журналистов, представителей НКО, религиозных сообществ, общественности и лидеров бизнеса.»
Через неделю после этого было опубликовано 2е открытое письмо [3] - от руководства компании VERSES (главным ученым которой является Карл Фристон) совету директоров OpenAI.
В письме говорится:
• Хартия OpenAI гласит: «…если проект, ориентированный на ценность и безопасность, приблизится к созданию AGI раньше, чем мы, мы обязуемся прекратить конкурировать с ним и начать оказывать помощь этому проекту».
• Отсутствие у больших моделей типа GPT-4 обобщаемости, объяснимости и управляемости предполагает, что они не приведут к AGI. Глубокого обучения недостаточно.
• Наша команда ученых-компьютерщиков, нейробиологов и инженеров под руководством Карла Фристона разработала альтернативный подход на основе активного вывода. Этот подход позволяет решить проблемы обобщаемости, объяснимости и управляемости, открывая путь к AGI
• Исходя из вышеизложенного, мы считаем, что VERSES заслуживает вашей помощи. В свою очередь мы предлагаем нашу помощь вам, чтобы гарантировать, что AGI и сверхразум развивались и использовались безопасным и полезным образом для всего человечества.
В OpenAI это письмо (по сути – вежливое предложение им капитулировать) проигнорировали.
Зато теперь ответил Лекун: будет не капитуляция, а война за AGI. И его компания к ней готова [4].
Но ведь не железом единым …
1 https://www.youtube.com/watch?v=SYQ8Siwy8Ic
2 https://bit.ly/424RWTb
3 https://bit.ly/48RuJq4
4 https://bit.ly/3O4Ncaj
#AGI
За кулисами давосской дуэли Карла Фристона и Яна Лекуна.
В ходе вчерашнего диалога на площадке давосского форума Фристон и Лекун стараются выглядеть спокойными и доброжелательными [1]. Фристону это удается лучше: он улыбается и много шутит. Лекуну сложнее: ему явно не до улыбок и шуток. Но он старается держать себя в руках, даже когда Фристон открыто смеётся над делом всей его жизни – глубоким обучением. «Глубокое обучение – полная чушь» - заявляет Фристон и называет набор факторов, принципиально не позволяющих создать человекоподобный интеллект на основе глубокого обучения. Лекун пытается утверждать обратное, однако вместо аргументов говорит лишь о своей субъективной вере в будущие еще не открытые возможности глубокого обучения. И потому «глубокое обучение необходимо, и я готов поспорить, что через 10-20 лет ИИ-системы все еще будут основаны на глубоком обучении».
Важность этого диалога двух «рок-звезд» (как их назвал модератор) в области изучения и создания интеллектуальных систем трудно переоценить. Ибо он знаменует начало открытого раскола двух альтернативных подходов к созданию человекоподобных интеллектуальных агентов:
1. «Инженерный подход к созданию искусственного интеллекта» на основе глубокого обучения, больших данных и больших языковых моделей (LLM) - ныне доминирующий ресурсоемкий и дорогостоящий подход.
2. Альтернативный - научный подход к созданию естественного интеллекта на основе активного вывода, позволяющего построение больших моделей, гибко составленных из более мелких, хорошо понятных моделей, для которых возможно явное, интерпретируемое обновление их убеждений.
Первым формальным заявлением, призывающим мир сменить парадигму разработки интеллектуальных систем, было декабрьское открытое письмо участников Бостонского глобального форума [2]. Среди 25 подписавших, оба наших выдающихся современника, чьи имена, имхо, во 2й половине XXI века, будут упоминаться в одном ряду с Ньютоном, Дарвином и Эйнштейном: Карл Фристон и Майкл Левин.
«Мы, нижеподписавшиеся, считаем, что на данном этапе коммерциализации и регулирования ИИ жизненно важно, чтобы альтернативное и научно обоснованное понимание биологических основ ИИ было публично озвучено, и чтобы были созваны междисциплинарные публичные семинары среди законодателей, регулирующих органов и технологов, инвесторов, ученых, журналистов, представителей НКО, религиозных сообществ, общественности и лидеров бизнеса.»
Через неделю после этого было опубликовано 2е открытое письмо [3] - от руководства компании VERSES (главным ученым которой является Карл Фристон) совету директоров OpenAI.
В письме говорится:
• Хартия OpenAI гласит: «…если проект, ориентированный на ценность и безопасность, приблизится к созданию AGI раньше, чем мы, мы обязуемся прекратить конкурировать с ним и начать оказывать помощь этому проекту».
• Отсутствие у больших моделей типа GPT-4 обобщаемости, объяснимости и управляемости предполагает, что они не приведут к AGI. Глубокого обучения недостаточно.
• Наша команда ученых-компьютерщиков, нейробиологов и инженеров под руководством Карла Фристона разработала альтернативный подход на основе активного вывода. Этот подход позволяет решить проблемы обобщаемости, объяснимости и управляемости, открывая путь к AGI
• Исходя из вышеизложенного, мы считаем, что VERSES заслуживает вашей помощи. В свою очередь мы предлагаем нашу помощь вам, чтобы гарантировать, что AGI и сверхразум развивались и использовались безопасным и полезным образом для всего человечества.
В OpenAI это письмо (по сути – вежливое предложение им капитулировать) проигнорировали.
Зато теперь ответил Лекун: будет не капитуляция, а война за AGI. И его компания к ней готова [4].
Но ведь не железом единым …
1 https://www.youtube.com/watch?v=SYQ8Siwy8Ic
2 https://bit.ly/424RWTb
3 https://bit.ly/48RuJq4
4 https://bit.ly/3O4Ncaj
#AGI
Посмотри в глаза ИИ-чудовищ.
И ужаснись нечеловеческому уровню логико-пространственного мышления ИИ.
Крайне трудно представить себе интеллектуальный уровень современных ИИ-систем. Смешно ведь сравнивать свой уровень с машиной, влет переводящей сотню языков и помнящей содержание 2/3 Интернета.
Но при этом поверить, что машина много сильнее любого из нас не только в количественном смысле (число языков, прочитанных книг, перебранных вариантов и т.п.), но и в качественном – сложном логическом мышлении, - без примера нам трудно.
Так вот вам пример, - сравните себя с машиной на этой задаче.
Пусть I - центр вписанной окружности остроугольного треугольника ABC, в котором AB ≠ AC. Вписанная окружность ω треугольника ABC касается сторон BC, CA и AB в точках D, E и F соответственно. Прямая, проходящая через D и перпендикулярная EF, пересекает ω вторично в точке R. Прямая AR снова пересекает ω вторично в точке P. Окружности, описанные вокруг треугольников PCE и PBF, пересекаются вторично в точке Q.
Докажите, что прямые DI и PQ пересекаются на прямой, проходящей через A и перпендикулярной AI.
Эта задача уровня всемирной математической олимпиады требует исключительного уровня логико-пространственного мышления. Средняя «длина доказательств» (количество шагов, необходимых для полного и строгого доказательства) в задачах на таких олимпиадах – около 50.
И хотя для приведенной выше задачи это число много больше (187), ИИ-система AlphaGeometry от Google DeepMind (объединяет модель нейронного языка с механизмом символьной дедукции) решает её запросто.
Да что ей 187, - она и уровень 247 уже запросто решает. И потому до уровня золотых медалистов таких олимпиад (людей, коих, может, 1 на миллиард) AlphaGeometry осталось чуть-чуть (полагаю, к лету догонит, а к концу года уйдет в далекий отрыв).
Если вдруг вы не справились с этой задачкой, вот подсказка – рисунок для доказательства:
https://disk.yandex.ru/i/YymGpZwBlewQcw
PS И даже не думайте, будто AlphaGeometry могла заранее знать решение, - ей специально 100 млн новых задач со случайной постановкой другая ИИ-система придумала.
#AGI
И ужаснись нечеловеческому уровню логико-пространственного мышления ИИ.
Крайне трудно представить себе интеллектуальный уровень современных ИИ-систем. Смешно ведь сравнивать свой уровень с машиной, влет переводящей сотню языков и помнящей содержание 2/3 Интернета.
Но при этом поверить, что машина много сильнее любого из нас не только в количественном смысле (число языков, прочитанных книг, перебранных вариантов и т.п.), но и в качественном – сложном логическом мышлении, - без примера нам трудно.
Так вот вам пример, - сравните себя с машиной на этой задаче.
Пусть I - центр вписанной окружности остроугольного треугольника ABC, в котором AB ≠ AC. Вписанная окружность ω треугольника ABC касается сторон BC, CA и AB в точках D, E и F соответственно. Прямая, проходящая через D и перпендикулярная EF, пересекает ω вторично в точке R. Прямая AR снова пересекает ω вторично в точке P. Окружности, описанные вокруг треугольников PCE и PBF, пересекаются вторично в точке Q.
Докажите, что прямые DI и PQ пересекаются на прямой, проходящей через A и перпендикулярной AI.
Эта задача уровня всемирной математической олимпиады требует исключительного уровня логико-пространственного мышления. Средняя «длина доказательств» (количество шагов, необходимых для полного и строгого доказательства) в задачах на таких олимпиадах – около 50.
И хотя для приведенной выше задачи это число много больше (187), ИИ-система AlphaGeometry от Google DeepMind (объединяет модель нейронного языка с механизмом символьной дедукции) решает её запросто.
Да что ей 187, - она и уровень 247 уже запросто решает. И потому до уровня золотых медалистов таких олимпиад (людей, коих, может, 1 на миллиард) AlphaGeometry осталось чуть-чуть (полагаю, к лету догонит, а к концу года уйдет в далекий отрыв).
Если вдруг вы не справились с этой задачкой, вот подсказка – рисунок для доказательства:
https://disk.yandex.ru/i/YymGpZwBlewQcw
PS И даже не думайте, будто AlphaGeometry могла заранее знать решение, - ей специально 100 млн новых задач со случайной постановкой другая ИИ-система придумала.
#AGI
Яндекс Диск
Задача IMO 2019 P6.JPG
Посмотреть и скачать с Яндекс Диска
Люди – теперь лишнее звено в эволюции LLM.
Придумана методика самообучения для сверхчеловеческих ИИ-агентов.
Эта новость позволяет понять, зачем Цукерберг вбухал миллиарды в закупку тысяч Nvidia H100s, будучи уверен, что его LLM с открытым кодом обойдет лидирующие модели OpenAI, MS и Google.
Во всех зафиксированных кейсах достижения ИИ-системами способностей сверхчеловеческого уровня, опыт и знания учителей-людей (да и всего человечества в целом) оказывались лишними.
Так например, ИИ AlphaZero от DeepMind обучался играть в шахматы самостоятельно и без учителей. Играя десятки миллионов партий против самого себя, ИИ достиг сверхчеловеческого уровня игры всего за несколько часов (!).
Исследователи одного из лидеров в этой области (с прежним названием типа «Мордокнига») поставили резонный вопрос:
✔️ А зачем вообще нужны люди, если стоит задача вывести лингвистические способности генеративных ИИ больших языковых моделей (LLM) на сверхчеловеческий уровень?
Сейчас при обучении таких LLM ответы людей используются для создания модели вознаграждений на основе предпочтений людей. Но у этого способа создания модели вознаграждений есть 2 больших недостатка:
• он ограничен уровнем производительности людей;
• замороженные модели вознаграждения не могут затем совершенствоваться во время обучения LLM.
Идея авторов исследования проста как редис – перейти к самообеспечению LLM при создании модели вознаграждений, спроектировав архитектуру «самовознаграждающих языковых моделей», способную обходиться без людей.
Такая модель с самовознаграждением (LLM-as-a-Judge) использует подсказки «LLM-судьи» для формирования собственных вознаграждений во время обучения.
Опробовав этот метод самозознаграждений для Llama 2 70B на трех итерациях, авторы получили модель, которая превосходит подавляющее большинство существующих систем в таблице лидеров AlpacaEval 2.0, включая Claude 2, Gemini Pro и GPT-4 0613 (см. таблицу https://disk.yandex.ru/i/-hqFSCIfcFNI5w)
И хотя эта работа является лишь предварительным исследованием, она переводит гипотезу о ненужности людей для дальнейшего самосовершенствования LLM в практическую плоскость.
https://arxiv.org/abs/2401.10020
#LLM #AGI
Придумана методика самообучения для сверхчеловеческих ИИ-агентов.
Эта новость позволяет понять, зачем Цукерберг вбухал миллиарды в закупку тысяч Nvidia H100s, будучи уверен, что его LLM с открытым кодом обойдет лидирующие модели OpenAI, MS и Google.
Во всех зафиксированных кейсах достижения ИИ-системами способностей сверхчеловеческого уровня, опыт и знания учителей-людей (да и всего человечества в целом) оказывались лишними.
Так например, ИИ AlphaZero от DeepMind обучался играть в шахматы самостоятельно и без учителей. Играя десятки миллионов партий против самого себя, ИИ достиг сверхчеловеческого уровня игры всего за несколько часов (!).
Исследователи одного из лидеров в этой области (с прежним названием типа «Мордокнига») поставили резонный вопрос:
✔️ А зачем вообще нужны люди, если стоит задача вывести лингвистические способности генеративных ИИ больших языковых моделей (LLM) на сверхчеловеческий уровень?
Сейчас при обучении таких LLM ответы людей используются для создания модели вознаграждений на основе предпочтений людей. Но у этого способа создания модели вознаграждений есть 2 больших недостатка:
• он ограничен уровнем производительности людей;
• замороженные модели вознаграждения не могут затем совершенствоваться во время обучения LLM.
Идея авторов исследования проста как редис – перейти к самообеспечению LLM при создании модели вознаграждений, спроектировав архитектуру «самовознаграждающих языковых моделей», способную обходиться без людей.
Такая модель с самовознаграждением (LLM-as-a-Judge) использует подсказки «LLM-судьи» для формирования собственных вознаграждений во время обучения.
Опробовав этот метод самозознаграждений для Llama 2 70B на трех итерациях, авторы получили модель, которая превосходит подавляющее большинство существующих систем в таблице лидеров AlpacaEval 2.0, включая Claude 2, Gemini Pro и GPT-4 0613 (см. таблицу https://disk.yandex.ru/i/-hqFSCIfcFNI5w)
И хотя эта работа является лишь предварительным исследованием, она переводит гипотезу о ненужности людей для дальнейшего самосовершенствования LLM в практическую плоскость.
https://arxiv.org/abs/2401.10020
#LLM #AGI
Яндекс Диск
LLM-as-a-Judge.jpg
Посмотреть и скачать с Яндекс Диска
Сверхвызов сверхразума - никто не знает, как на нем зарабатывать.
Опубликованный FT логнрид «Смогут ли в OpenAI создать сверхразум до того, как у них закончатся деньги?» впервые озвучил самый сокровенный для инвесторов вопрос о самой перспективной и привлекательной для них технологии - ИИ.
• Если цель развития ИИ – создание сверхразума,
• и достижение этой цели будет стоить очень и очень дорого,
• то инвесторам хотелось бы заранее понимать:
1) Как планируется отбивать огромные инвестиции в создание сверхразума? и
2) Как вообще на нем зарабатывать?
Авторы лонгрида не открывают Америку, подробно описывая тупиковость ситуации, когда ответы на оба вопроса не может дать никто. И подобно мальчику, крикнувшему «А король то голый!», авторам остается лишь честно констатировать: долгосрочной жизнеспособной модели зарабатывания на сверхразуме пока никто не придумал.
Более того. Заявленная Сэмом Альтманом цель — создание «общего искусственного интеллекта», формы интеллектуального программного обеспечения, которое превзошло бы интеллектуальные возможности человека и изменило бы то, как мы все живем и работаем, — не может серьезно рассматриваться, как основа бизнес-модели, способной приносить владеющим созданным сверхразумом корпорациям триллионы долларов. А именно столько потребуется для создания сверхразума по убеждению Альтмана – главного рулевого лидера в этой области, компании OpenAI.
Авторы лонгрида пишут, - несмотря на то, что в краткосрочной перспективе генеративные ИИ на основе больших языковых моделей воспринимаются с энтузиазмом, многие бизнес-лидеры по-прежнему не уверены в том, как технология повысит их прибыль, будь то за счет сокращения затрат или создания новых потоков доходов… Скептики говорят, что существует фундаментальное несоответствие между тем, чего хотят компании, и тем, к чему в конечном итоге стремится OpenAI. «Не всем нужна Феррари. . . Бизнес-компаниям не нужна всезнающая и всевидящая сущность: они заботятся о том, чтобы зарабатывать деньги с помощью этого инструмента», — говорит один инвестор в области ИИ, который поддерживал некоторых конкурентов OpenAI.
Иными словами, как сказал инвестор, - «Обычные бизнес-цели корпораций не совпадают с общим искусственным интеллектом».
Конечно, можно, подобно Microsoft, делать ставку на встраивание «интеллектуальных 2-ых пилотов» в свои продукты и сервисы. Но ведь для этого никакой сверхразум даром не нужен.
А зачем тогда вбухивать триллионы, если нет ни малейших идей, как эти деньги отбить?
Сверхразум создаст новые сверхлекарства и покорит термояд? На вскидку выглядит весьма привлекательно.
Но как на этом могут заработать создатели сверхразума? И не единожды, а из года в год.
Патентом на сверхразум торговать? Так кто ж его запатентует?
Остается лишь создавать сверхразум в надежде, что он потом сам придумает бизнес-модель, как на нем зарабатывать. Но это как-то уж совсем стремно для инвесторов.
https://www.ft.com/content/6314d78d-81f3-43f5-9daf-b10f3ff9e24f
Этот пост развивает идеи моего поста 5 летней давности «Король ИИ голый, и ему нужно либо трусы надеть, либо крестик снять»
https://t.me/theworldisnoteasy/942
#AGI
Опубликованный FT логнрид «Смогут ли в OpenAI создать сверхразум до того, как у них закончатся деньги?» впервые озвучил самый сокровенный для инвесторов вопрос о самой перспективной и привлекательной для них технологии - ИИ.
• Если цель развития ИИ – создание сверхразума,
• и достижение этой цели будет стоить очень и очень дорого,
• то инвесторам хотелось бы заранее понимать:
1) Как планируется отбивать огромные инвестиции в создание сверхразума? и
2) Как вообще на нем зарабатывать?
Авторы лонгрида не открывают Америку, подробно описывая тупиковость ситуации, когда ответы на оба вопроса не может дать никто. И подобно мальчику, крикнувшему «А король то голый!», авторам остается лишь честно констатировать: долгосрочной жизнеспособной модели зарабатывания на сверхразуме пока никто не придумал.
Более того. Заявленная Сэмом Альтманом цель — создание «общего искусственного интеллекта», формы интеллектуального программного обеспечения, которое превзошло бы интеллектуальные возможности человека и изменило бы то, как мы все живем и работаем, — не может серьезно рассматриваться, как основа бизнес-модели, способной приносить владеющим созданным сверхразумом корпорациям триллионы долларов. А именно столько потребуется для создания сверхразума по убеждению Альтмана – главного рулевого лидера в этой области, компании OpenAI.
Авторы лонгрида пишут, - несмотря на то, что в краткосрочной перспективе генеративные ИИ на основе больших языковых моделей воспринимаются с энтузиазмом, многие бизнес-лидеры по-прежнему не уверены в том, как технология повысит их прибыль, будь то за счет сокращения затрат или создания новых потоков доходов… Скептики говорят, что существует фундаментальное несоответствие между тем, чего хотят компании, и тем, к чему в конечном итоге стремится OpenAI. «Не всем нужна Феррари. . . Бизнес-компаниям не нужна всезнающая и всевидящая сущность: они заботятся о том, чтобы зарабатывать деньги с помощью этого инструмента», — говорит один инвестор в области ИИ, который поддерживал некоторых конкурентов OpenAI.
Иными словами, как сказал инвестор, - «Обычные бизнес-цели корпораций не совпадают с общим искусственным интеллектом».
Конечно, можно, подобно Microsoft, делать ставку на встраивание «интеллектуальных 2-ых пилотов» в свои продукты и сервисы. Но ведь для этого никакой сверхразум даром не нужен.
А зачем тогда вбухивать триллионы, если нет ни малейших идей, как эти деньги отбить?
Сверхразум создаст новые сверхлекарства и покорит термояд? На вскидку выглядит весьма привлекательно.
Но как на этом могут заработать создатели сверхразума? И не единожды, а из года в год.
Патентом на сверхразум торговать? Так кто ж его запатентует?
Остается лишь создавать сверхразум в надежде, что он потом сам придумает бизнес-модель, как на нем зарабатывать. Но это как-то уж совсем стремно для инвесторов.
https://www.ft.com/content/6314d78d-81f3-43f5-9daf-b10f3ff9e24f
Этот пост развивает идеи моего поста 5 летней давности «Король ИИ голый, и ему нужно либо трусы надеть, либо крестик снять»
https://t.me/theworldisnoteasy/942
#AGI