
Для Китая GPT-4 аморален, несправедлив и незаконопослушен.
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
{kind=link}
По сути, Microsoft показал, что AGI уже здесь.
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
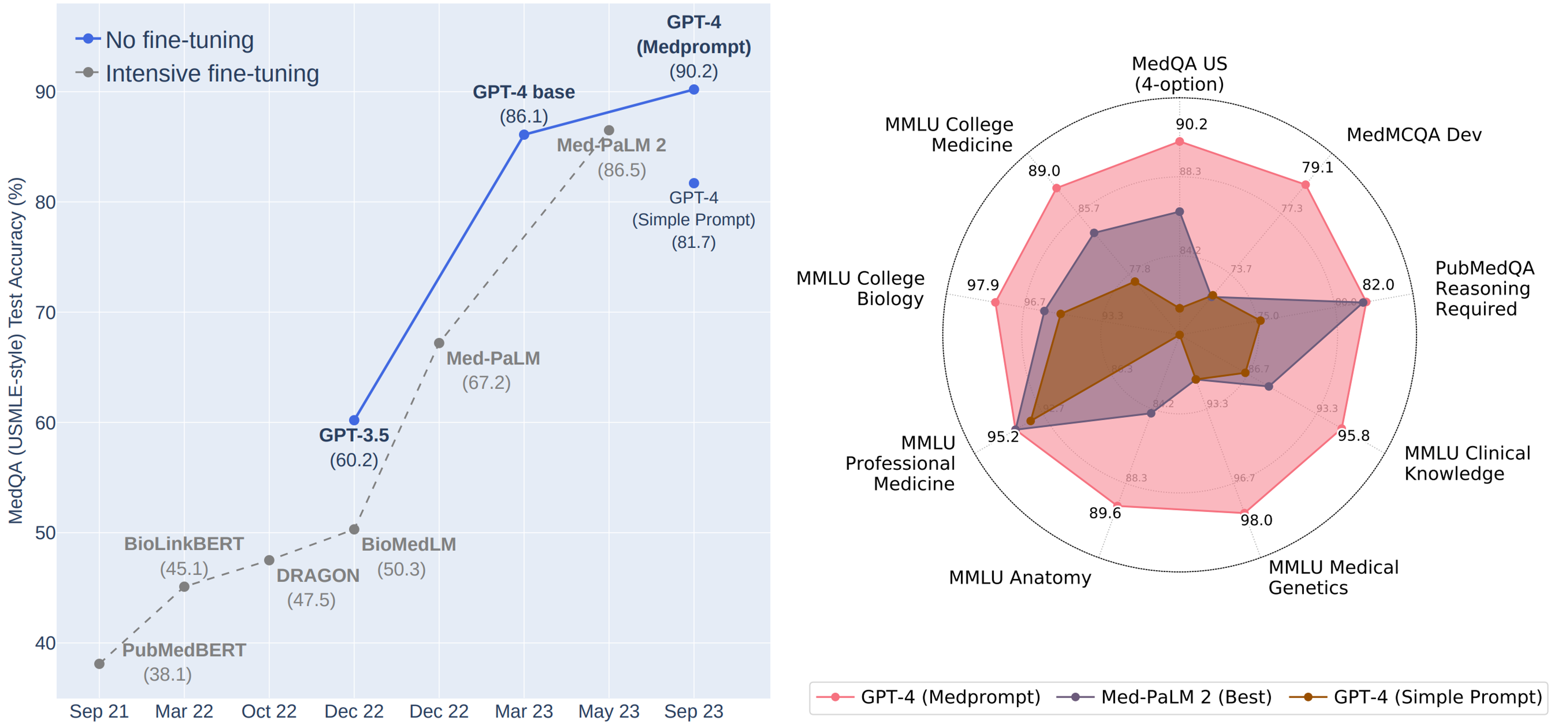
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
{kind=link}
Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Google DeepMind
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce FunSearch, a method for searching for “functions” written in computer code, and find new solutions in mathematics and computer science. FunSearch works by pairing a pre-trained LLM,...
Среди семи прогнозов Stanford HAI - что ожидать от ИИ в 2024, - три ключевых [1]:
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI #Superalignment
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI #Superalignment
Разум в Мультиверсе.
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Яндекс Диск
Разум в Мультиверсе.jpg
Посмотреть и скачать с Яндекс Диска
GPT-5 в 2024 и AGI в 2025.
Сэм Альтман снова взорвал мировые СМИ.
Его откровения за последнюю тройку дней (беседа c Биллом Гейтсом и выступление на стартовом мероприятии Y Combinator W24 в штаб-квартире OpenAI), вполне оправдывают сенсационный заголовок этого поста.
Если смешать, но не взбалтывать сказанное Альтманом, получается, примерно, следующее:
✔️ GPT-5 появится так скоро, что стартапам (и конкурентам) нет смысла фокусироваться на попытках устранения текущих ограничений GPT-4 (ибо большинство из этих ограничений будут частично или полностью устранены в GPT-5)
✔️ ТОР 3 ключевыми прорывами GPT-5 (делающими AGI «весьма близким») будут:
• Мультимодальность (в 1ю очередь «видео на входе и выходе»)
• Гораздо более продвинутая способность рассуждать (в 1ю очередь разблокировка когнитивных способностей Системы 2 - думай медленно в сложной ситуации)
• Надежность (сейчас GPT-4 дает 10К разных ответов на тот же вопрос и не знает, какой из них лучший, GPT-5 даст один – лучший ответ)
#GPT-5 #AGI
Сэм Альтман снова взорвал мировые СМИ.
Его откровения за последнюю тройку дней (беседа c Биллом Гейтсом и выступление на стартовом мероприятии Y Combinator W24 в штаб-квартире OpenAI), вполне оправдывают сенсационный заголовок этого поста.
Если смешать, но не взбалтывать сказанное Альтманом, получается, примерно, следующее:
✔️ GPT-5 появится так скоро, что стартапам (и конкурентам) нет смысла фокусироваться на попытках устранения текущих ограничений GPT-4 (ибо большинство из этих ограничений будут частично или полностью устранены в GPT-5)
✔️ ТОР 3 ключевыми прорывами GPT-5 (делающими AGI «весьма близким») будут:
• Мультимодальность (в 1ю очередь «видео на входе и выходе»)
• Гораздо более продвинутая способность рассуждать (в 1ю очередь разблокировка когнитивных способностей Системы 2 - думай медленно в сложной ситуации)
• Надежность (сейчас GPT-4 дает 10К разных ответов на тот же вопрос и не знает, какой из них лучший, GPT-5 даст один – лучший ответ)
#GPT-5 #AGI
Начался Большой Раскол научного и инженерного подходов к интеллекту.
За кулисами давосской дуэли Карла Фристона и Яна Лекуна.
В ходе вчерашнего диалога на площадке давосского форума Фристон и Лекун стараются выглядеть спокойными и доброжелательными [1]. Фристону это удается лучше: он улыбается и много шутит. Лекуну сложнее: ему явно не до улыбок и шуток. Но он старается держать себя в руках, даже когда Фристон открыто смеётся над делом всей его жизни – глубоким обучением. «Глубокое обучение – полная чушь» - заявляет Фристон и называет набор факторов, принципиально не позволяющих создать человекоподобный интеллект на основе глубокого обучения. Лекун пытается утверждать обратное, однако вместо аргументов говорит лишь о своей субъективной вере в будущие еще не открытые возможности глубокого обучения. И потому «глубокое обучение необходимо, и я готов поспорить, что через 10-20 лет ИИ-системы все еще будут основаны на глубоком обучении».
Важность этого диалога двух «рок-звезд» (как их назвал модератор) в области изучения и создания интеллектуальных систем трудно переоценить. Ибо он знаменует начало открытого раскола двух альтернативных подходов к созданию человекоподобных интеллектуальных агентов:
1. «Инженерный подход к созданию искусственного интеллекта» на основе глубокого обучения, больших данных и больших языковых моделей (LLM) - ныне доминирующий ресурсоемкий и дорогостоящий подход.
2. Альтернативный - научный подход к созданию естественного интеллекта на основе активного вывода, позволяющего построение больших моделей, гибко составленных из более мелких, хорошо понятных моделей, для которых возможно явное, интерпретируемое обновление их убеждений.
Первым формальным заявлением, призывающим мир сменить парадигму разработки интеллектуальных систем, было декабрьское открытое письмо участников Бостонского глобального форума [2]. Среди 25 подписавших, оба наших выдающихся современника, чьи имена, имхо, во 2й половине XXI века, будут упоминаться в одном ряду с Ньютоном, Дарвином и Эйнштейном: Карл Фристон и Майкл Левин.
«Мы, нижеподписавшиеся, считаем, что на данном этапе коммерциализации и регулирования ИИ жизненно важно, чтобы альтернативное и научно обоснованное понимание биологических основ ИИ было публично озвучено, и чтобы были созваны междисциплинарные публичные семинары среди законодателей, регулирующих органов и технологов, инвесторов, ученых, журналистов, представителей НКО, религиозных сообществ, общественности и лидеров бизнеса.»
Через неделю после этого было опубликовано 2е открытое письмо [3] - от руководства компании VERSES (главным ученым которой является Карл Фристон) совету директоров OpenAI.
В письме говорится:
• Хартия OpenAI гласит: «…если проект, ориентированный на ценность и безопасность, приблизится к созданию AGI раньше, чем мы, мы обязуемся прекратить конкурировать с ним и начать оказывать помощь этому проекту».
• Отсутствие у больших моделей типа GPT-4 обобщаемости, объяснимости и управляемости предполагает, что они не приведут к AGI. Глубокого обучения недостаточно.
• Наша команда ученых-компьютерщиков, нейробиологов и инженеров под руководством Карла Фристона разработала альтернативный подход на основе активного вывода. Этот подход позволяет решить проблемы обобщаемости, объяснимости и управляемости, открывая путь к AGI
• Исходя из вышеизложенного, мы считаем, что VERSES заслуживает вашей помощи. В свою очередь мы предлагаем нашу помощь вам, чтобы гарантировать, что AGI и сверхразум развивались и использовались безопасным и полезным образом для всего человечества.
В OpenAI это письмо (по сути – вежливое предложение им капитулировать) проигнорировали.
Зато теперь ответил Лекун: будет не капитуляция, а война за AGI. И его компания к ней готова [4].
Но ведь не железом единым …
1 https://www.youtube.com/watch?v=SYQ8Siwy8Ic
2 https://bit.ly/424RWTb
3 https://bit.ly/48RuJq4
4 https://bit.ly/3O4Ncaj
#AGI
За кулисами давосской дуэли Карла Фристона и Яна Лекуна.
В ходе вчерашнего диалога на площадке давосского форума Фристон и Лекун стараются выглядеть спокойными и доброжелательными [1]. Фристону это удается лучше: он улыбается и много шутит. Лекуну сложнее: ему явно не до улыбок и шуток. Но он старается держать себя в руках, даже когда Фристон открыто смеётся над делом всей его жизни – глубоким обучением. «Глубокое обучение – полная чушь» - заявляет Фристон и называет набор факторов, принципиально не позволяющих создать человекоподобный интеллект на основе глубокого обучения. Лекун пытается утверждать обратное, однако вместо аргументов говорит лишь о своей субъективной вере в будущие еще не открытые возможности глубокого обучения. И потому «глубокое обучение необходимо, и я готов поспорить, что через 10-20 лет ИИ-системы все еще будут основаны на глубоком обучении».
Важность этого диалога двух «рок-звезд» (как их назвал модератор) в области изучения и создания интеллектуальных систем трудно переоценить. Ибо он знаменует начало открытого раскола двух альтернативных подходов к созданию человекоподобных интеллектуальных агентов:
1. «Инженерный подход к созданию искусственного интеллекта» на основе глубокого обучения, больших данных и больших языковых моделей (LLM) - ныне доминирующий ресурсоемкий и дорогостоящий подход.
2. Альтернативный - научный подход к созданию естественного интеллекта на основе активного вывода, позволяющего построение больших моделей, гибко составленных из более мелких, хорошо понятных моделей, для которых возможно явное, интерпретируемое обновление их убеждений.
Первым формальным заявлением, призывающим мир сменить парадигму разработки интеллектуальных систем, было декабрьское открытое письмо участников Бостонского глобального форума [2]. Среди 25 подписавших, оба наших выдающихся современника, чьи имена, имхо, во 2й половине XXI века, будут упоминаться в одном ряду с Ньютоном, Дарвином и Эйнштейном: Карл Фристон и Майкл Левин.
«Мы, нижеподписавшиеся, считаем, что на данном этапе коммерциализации и регулирования ИИ жизненно важно, чтобы альтернативное и научно обоснованное понимание биологических основ ИИ было публично озвучено, и чтобы были созваны междисциплинарные публичные семинары среди законодателей, регулирующих органов и технологов, инвесторов, ученых, журналистов, представителей НКО, религиозных сообществ, общественности и лидеров бизнеса.»
Через неделю после этого было опубликовано 2е открытое письмо [3] - от руководства компании VERSES (главным ученым которой является Карл Фристон) совету директоров OpenAI.
В письме говорится:
• Хартия OpenAI гласит: «…если проект, ориентированный на ценность и безопасность, приблизится к созданию AGI раньше, чем мы, мы обязуемся прекратить конкурировать с ним и начать оказывать помощь этому проекту».
• Отсутствие у больших моделей типа GPT-4 обобщаемости, объяснимости и управляемости предполагает, что они не приведут к AGI. Глубокого обучения недостаточно.
• Наша команда ученых-компьютерщиков, нейробиологов и инженеров под руководством Карла Фристона разработала альтернативный подход на основе активного вывода. Этот подход позволяет решить проблемы обобщаемости, объяснимости и управляемости, открывая путь к AGI
• Исходя из вышеизложенного, мы считаем, что VERSES заслуживает вашей помощи. В свою очередь мы предлагаем нашу помощь вам, чтобы гарантировать, что AGI и сверхразум развивались и использовались безопасным и полезным образом для всего человечества.
В OpenAI это письмо (по сути – вежливое предложение им капитулировать) проигнорировали.
Зато теперь ответил Лекун: будет не капитуляция, а война за AGI. И его компания к ней готова [4].
Но ведь не железом единым …
1 https://www.youtube.com/watch?v=SYQ8Siwy8Ic
2 https://bit.ly/424RWTb
3 https://bit.ly/48RuJq4
4 https://bit.ly/3O4Ncaj
#AGI
Посмотри в глаза ИИ-чудовищ.
И ужаснись нечеловеческому уровню логико-пространственного мышления ИИ.
Крайне трудно представить себе интеллектуальный уровень современных ИИ-систем. Смешно ведь сравнивать свой уровень с машиной, влет переводящей сотню языков и помнящей содержание 2/3 Интернета.
Но при этом поверить, что машина много сильнее любого из нас не только в количественном смысле (число языков, прочитанных книг, перебранных вариантов и т.п.), но и в качественном – сложном логическом мышлении, - без примера нам трудно.
Так вот вам пример, - сравните себя с машиной на этой задаче.
Пусть I - центр вписанной окружности остроугольного треугольника ABC, в котором AB ≠ AC. Вписанная окружность ω треугольника ABC касается сторон BC, CA и AB в точках D, E и F соответственно. Прямая, проходящая через D и перпендикулярная EF, пересекает ω вторично в точке R. Прямая AR снова пересекает ω вторично в точке P. Окружности, описанные вокруг треугольников PCE и PBF, пересекаются вторично в точке Q.
Докажите, что прямые DI и PQ пересекаются на прямой, проходящей через A и перпендикулярной AI.
Эта задача уровня всемирной математической олимпиады требует исключительного уровня логико-пространственного мышления. Средняя «длина доказательств» (количество шагов, необходимых для полного и строгого доказательства) в задачах на таких олимпиадах – около 50.
И хотя для приведенной выше задачи это число много больше (187), ИИ-система AlphaGeometry от Google DeepMind (объединяет модель нейронного языка с механизмом символьной дедукции) решает её запросто.
Да что ей 187, - она и уровень 247 уже запросто решает. И потому до уровня золотых медалистов таких олимпиад (людей, коих, может, 1 на миллиард) AlphaGeometry осталось чуть-чуть (полагаю, к лету догонит, а к концу года уйдет в далекий отрыв).
Если вдруг вы не справились с этой задачкой, вот подсказка – рисунок для доказательства:
https://disk.yandex.ru/i/YymGpZwBlewQcw
PS И даже не думайте, будто AlphaGeometry могла заранее знать решение, - ей специально 100 млн новых задач со случайной постановкой другая ИИ-система придумала.
#AGI
И ужаснись нечеловеческому уровню логико-пространственного мышления ИИ.
Крайне трудно представить себе интеллектуальный уровень современных ИИ-систем. Смешно ведь сравнивать свой уровень с машиной, влет переводящей сотню языков и помнящей содержание 2/3 Интернета.
Но при этом поверить, что машина много сильнее любого из нас не только в количественном смысле (число языков, прочитанных книг, перебранных вариантов и т.п.), но и в качественном – сложном логическом мышлении, - без примера нам трудно.
Так вот вам пример, - сравните себя с машиной на этой задаче.
Пусть I - центр вписанной окружности остроугольного треугольника ABC, в котором AB ≠ AC. Вписанная окружность ω треугольника ABC касается сторон BC, CA и AB в точках D, E и F соответственно. Прямая, проходящая через D и перпендикулярная EF, пересекает ω вторично в точке R. Прямая AR снова пересекает ω вторично в точке P. Окружности, описанные вокруг треугольников PCE и PBF, пересекаются вторично в точке Q.
Докажите, что прямые DI и PQ пересекаются на прямой, проходящей через A и перпендикулярной AI.
Эта задача уровня всемирной математической олимпиады требует исключительного уровня логико-пространственного мышления. Средняя «длина доказательств» (количество шагов, необходимых для полного и строгого доказательства) в задачах на таких олимпиадах – около 50.
И хотя для приведенной выше задачи это число много больше (187), ИИ-система AlphaGeometry от Google DeepMind (объединяет модель нейронного языка с механизмом символьной дедукции) решает её запросто.
Да что ей 187, - она и уровень 247 уже запросто решает. И потому до уровня золотых медалистов таких олимпиад (людей, коих, может, 1 на миллиард) AlphaGeometry осталось чуть-чуть (полагаю, к лету догонит, а к концу года уйдет в далекий отрыв).
Если вдруг вы не справились с этой задачкой, вот подсказка – рисунок для доказательства:
https://disk.yandex.ru/i/YymGpZwBlewQcw
PS И даже не думайте, будто AlphaGeometry могла заранее знать решение, - ей специально 100 млн новых задач со случайной постановкой другая ИИ-система придумала.
#AGI
Яндекс Диск
Задача IMO 2019 P6.JPG
Посмотреть и скачать с Яндекс Диска
Люди – теперь лишнее звено в эволюции LLM.
Придумана методика самообучения для сверхчеловеческих ИИ-агентов.
Эта новость позволяет понять, зачем Цукерберг вбухал миллиарды в закупку тысяч Nvidia H100s, будучи уверен, что его LLM с открытым кодом обойдет лидирующие модели OpenAI, MS и Google.
Во всех зафиксированных кейсах достижения ИИ-системами способностей сверхчеловеческого уровня, опыт и знания учителей-людей (да и всего человечества в целом) оказывались лишними.
Так например, ИИ AlphaZero от DeepMind обучался играть в шахматы самостоятельно и без учителей. Играя десятки миллионов партий против самого себя, ИИ достиг сверхчеловеческого уровня игры всего за несколько часов (!).
Исследователи одного из лидеров в этой области (с прежним названием типа «Мордокнига») поставили резонный вопрос:
✔️ А зачем вообще нужны люди, если стоит задача вывести лингвистические способности генеративных ИИ больших языковых моделей (LLM) на сверхчеловеческий уровень?
Сейчас при обучении таких LLM ответы людей используются для создания модели вознаграждений на основе предпочтений людей. Но у этого способа создания модели вознаграждений есть 2 больших недостатка:
• он ограничен уровнем производительности людей;
• замороженные модели вознаграждения не могут затем совершенствоваться во время обучения LLM.
Идея авторов исследования проста как редис – перейти к самообеспечению LLM при создании модели вознаграждений, спроектировав архитектуру «самовознаграждающих языковых моделей», способную обходиться без людей.
Такая модель с самовознаграждением (LLM-as-a-Judge) использует подсказки «LLM-судьи» для формирования собственных вознаграждений во время обучения.
Опробовав этот метод самозознаграждений для Llama 2 70B на трех итерациях, авторы получили модель, которая превосходит подавляющее большинство существующих систем в таблице лидеров AlpacaEval 2.0, включая Claude 2, Gemini Pro и GPT-4 0613 (см. таблицу https://disk.yandex.ru/i/-hqFSCIfcFNI5w)
И хотя эта работа является лишь предварительным исследованием, она переводит гипотезу о ненужности людей для дальнейшего самосовершенствования LLM в практическую плоскость.
https://arxiv.org/abs/2401.10020
#LLM #AGI
Придумана методика самообучения для сверхчеловеческих ИИ-агентов.
Эта новость позволяет понять, зачем Цукерберг вбухал миллиарды в закупку тысяч Nvidia H100s, будучи уверен, что его LLM с открытым кодом обойдет лидирующие модели OpenAI, MS и Google.
Во всех зафиксированных кейсах достижения ИИ-системами способностей сверхчеловеческого уровня, опыт и знания учителей-людей (да и всего человечества в целом) оказывались лишними.
Так например, ИИ AlphaZero от DeepMind обучался играть в шахматы самостоятельно и без учителей. Играя десятки миллионов партий против самого себя, ИИ достиг сверхчеловеческого уровня игры всего за несколько часов (!).
Исследователи одного из лидеров в этой области (с прежним названием типа «Мордокнига») поставили резонный вопрос:
✔️ А зачем вообще нужны люди, если стоит задача вывести лингвистические способности генеративных ИИ больших языковых моделей (LLM) на сверхчеловеческий уровень?
Сейчас при обучении таких LLM ответы людей используются для создания модели вознаграждений на основе предпочтений людей. Но у этого способа создания модели вознаграждений есть 2 больших недостатка:
• он ограничен уровнем производительности людей;
• замороженные модели вознаграждения не могут затем совершенствоваться во время обучения LLM.
Идея авторов исследования проста как редис – перейти к самообеспечению LLM при создании модели вознаграждений, спроектировав архитектуру «самовознаграждающих языковых моделей», способную обходиться без людей.
Такая модель с самовознаграждением (LLM-as-a-Judge) использует подсказки «LLM-судьи» для формирования собственных вознаграждений во время обучения.
Опробовав этот метод самозознаграждений для Llama 2 70B на трех итерациях, авторы получили модель, которая превосходит подавляющее большинство существующих систем в таблице лидеров AlpacaEval 2.0, включая Claude 2, Gemini Pro и GPT-4 0613 (см. таблицу https://disk.yandex.ru/i/-hqFSCIfcFNI5w)
И хотя эта работа является лишь предварительным исследованием, она переводит гипотезу о ненужности людей для дальнейшего самосовершенствования LLM в практическую плоскость.
https://arxiv.org/abs/2401.10020
#LLM #AGI
Яндекс Диск
LLM-as-a-Judge.jpg
Посмотреть и скачать с Яндекс Диска
Сверхвызов сверхразума - никто не знает, как на нем зарабатывать.
Опубликованный FT логнрид «Смогут ли в OpenAI создать сверхразум до того, как у них закончатся деньги?» впервые озвучил самый сокровенный для инвесторов вопрос о самой перспективной и привлекательной для них технологии - ИИ.
• Если цель развития ИИ – создание сверхразума,
• и достижение этой цели будет стоить очень и очень дорого,
• то инвесторам хотелось бы заранее понимать:
1) Как планируется отбивать огромные инвестиции в создание сверхразума? и
2) Как вообще на нем зарабатывать?
Авторы лонгрида не открывают Америку, подробно описывая тупиковость ситуации, когда ответы на оба вопроса не может дать никто. И подобно мальчику, крикнувшему «А король то голый!», авторам остается лишь честно констатировать: долгосрочной жизнеспособной модели зарабатывания на сверхразуме пока никто не придумал.
Более того. Заявленная Сэмом Альтманом цель — создание «общего искусственного интеллекта», формы интеллектуального программного обеспечения, которое превзошло бы интеллектуальные возможности человека и изменило бы то, как мы все живем и работаем, — не может серьезно рассматриваться, как основа бизнес-модели, способной приносить владеющим созданным сверхразумом корпорациям триллионы долларов. А именно столько потребуется для создания сверхразума по убеждению Альтмана – главного рулевого лидера в этой области, компании OpenAI.
Авторы лонгрида пишут, - несмотря на то, что в краткосрочной перспективе генеративные ИИ на основе больших языковых моделей воспринимаются с энтузиазмом, многие бизнес-лидеры по-прежнему не уверены в том, как технология повысит их прибыль, будь то за счет сокращения затрат или создания новых потоков доходов… Скептики говорят, что существует фундаментальное несоответствие между тем, чего хотят компании, и тем, к чему в конечном итоге стремится OpenAI. «Не всем нужна Феррари. . . Бизнес-компаниям не нужна всезнающая и всевидящая сущность: они заботятся о том, чтобы зарабатывать деньги с помощью этого инструмента», — говорит один инвестор в области ИИ, который поддерживал некоторых конкурентов OpenAI.
Иными словами, как сказал инвестор, - «Обычные бизнес-цели корпораций не совпадают с общим искусственным интеллектом».
Конечно, можно, подобно Microsoft, делать ставку на встраивание «интеллектуальных 2-ых пилотов» в свои продукты и сервисы. Но ведь для этого никакой сверхразум даром не нужен.
А зачем тогда вбухивать триллионы, если нет ни малейших идей, как эти деньги отбить?
Сверхразум создаст новые сверхлекарства и покорит термояд? На вскидку выглядит весьма привлекательно.
Но как на этом могут заработать создатели сверхразума? И не единожды, а из года в год.
Патентом на сверхразум торговать? Так кто ж его запатентует?
Остается лишь создавать сверхразум в надежде, что он потом сам придумает бизнес-модель, как на нем зарабатывать. Но это как-то уж совсем стремно для инвесторов.
https://www.ft.com/content/6314d78d-81f3-43f5-9daf-b10f3ff9e24f
Этот пост развивает идеи моего поста 5 летней давности «Король ИИ голый, и ему нужно либо трусы надеть, либо крестик снять»
https://t.me/theworldisnoteasy/942
#AGI
Опубликованный FT логнрид «Смогут ли в OpenAI создать сверхразум до того, как у них закончатся деньги?» впервые озвучил самый сокровенный для инвесторов вопрос о самой перспективной и привлекательной для них технологии - ИИ.
• Если цель развития ИИ – создание сверхразума,
• и достижение этой цели будет стоить очень и очень дорого,
• то инвесторам хотелось бы заранее понимать:
1) Как планируется отбивать огромные инвестиции в создание сверхразума? и
2) Как вообще на нем зарабатывать?
Авторы лонгрида не открывают Америку, подробно описывая тупиковость ситуации, когда ответы на оба вопроса не может дать никто. И подобно мальчику, крикнувшему «А король то голый!», авторам остается лишь честно констатировать: долгосрочной жизнеспособной модели зарабатывания на сверхразуме пока никто не придумал.
Более того. Заявленная Сэмом Альтманом цель — создание «общего искусственного интеллекта», формы интеллектуального программного обеспечения, которое превзошло бы интеллектуальные возможности человека и изменило бы то, как мы все живем и работаем, — не может серьезно рассматриваться, как основа бизнес-модели, способной приносить владеющим созданным сверхразумом корпорациям триллионы долларов. А именно столько потребуется для создания сверхразума по убеждению Альтмана – главного рулевого лидера в этой области, компании OpenAI.
Авторы лонгрида пишут, - несмотря на то, что в краткосрочной перспективе генеративные ИИ на основе больших языковых моделей воспринимаются с энтузиазмом, многие бизнес-лидеры по-прежнему не уверены в том, как технология повысит их прибыль, будь то за счет сокращения затрат или создания новых потоков доходов… Скептики говорят, что существует фундаментальное несоответствие между тем, чего хотят компании, и тем, к чему в конечном итоге стремится OpenAI. «Не всем нужна Феррари. . . Бизнес-компаниям не нужна всезнающая и всевидящая сущность: они заботятся о том, чтобы зарабатывать деньги с помощью этого инструмента», — говорит один инвестор в области ИИ, который поддерживал некоторых конкурентов OpenAI.
Иными словами, как сказал инвестор, - «Обычные бизнес-цели корпораций не совпадают с общим искусственным интеллектом».
Конечно, можно, подобно Microsoft, делать ставку на встраивание «интеллектуальных 2-ых пилотов» в свои продукты и сервисы. Но ведь для этого никакой сверхразум даром не нужен.
А зачем тогда вбухивать триллионы, если нет ни малейших идей, как эти деньги отбить?
Сверхразум создаст новые сверхлекарства и покорит термояд? На вскидку выглядит весьма привлекательно.
Но как на этом могут заработать создатели сверхразума? И не единожды, а из года в год.
Патентом на сверхразум торговать? Так кто ж его запатентует?
Остается лишь создавать сверхразум в надежде, что он потом сам придумает бизнес-модель, как на нем зарабатывать. Но это как-то уж совсем стремно для инвесторов.
https://www.ft.com/content/6314d78d-81f3-43f5-9daf-b10f3ff9e24f
Этот пост развивает идеи моего поста 5 летней давности «Король ИИ голый, и ему нужно либо трусы надеть, либо крестик снять»
https://t.me/theworldisnoteasy/942
#AGI
Близнецы Homo sapiens за 2 месяца повзрослели на 2 года
К лету они достигнут совершеннолетия, и мир изменится
Мой пост «Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!» https://t.me/theworldisnoteasy/1856 про кардинальный прорыв в мультимодальном понимании мира языковыми моделями (на примере модели Gemini – «Близнецы» от DeepMind) некоторыми был воспринят с недоверием и даже с изрядным скепсисом. Мол, это все ловкость рук авторов демо-ролика, и на самом деле, модель ничего такого не может.
Спустя 2 мес опубликован техотчет, не оставляющий места сомнениям. Модель не только «это может», но и работает с контекстом в 1М токенов. Будто за 2 мес «Близнецы» подросли минимум на 2 года.
Смотрите сами. Это впечатляет
Вот пример, когда модель по рисунку типа каляка-маляка находит изображенную на нем сцену в романе https://bit.ly/3SMzaMa
А это понимание видео. В модель загрузили 44-х мин видео. И задали вопросы на понимание сцен, текста и картинок https://bit.ly/3T0VnaO
#AGI
К лету они достигнут совершеннолетия, и мир изменится
Мой пост «Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!» https://t.me/theworldisnoteasy/1856 про кардинальный прорыв в мультимодальном понимании мира языковыми моделями (на примере модели Gemini – «Близнецы» от DeepMind) некоторыми был воспринят с недоверием и даже с изрядным скепсисом. Мол, это все ловкость рук авторов демо-ролика, и на самом деле, модель ничего такого не может.
Спустя 2 мес опубликован техотчет, не оставляющий места сомнениям. Модель не только «это может», но и работает с контекстом в 1М токенов. Будто за 2 мес «Близнецы» подросли минимум на 2 года.
Смотрите сами. Это впечатляет
Вот пример, когда модель по рисунку типа каляка-маляка находит изображенную на нем сцену в романе https://bit.ly/3SMzaMa
А это понимание видео. В модель загрузили 44-х мин видео. И задали вопросы на понимание сцен, текста и картинок https://bit.ly/3T0VnaO
#AGI
Богатейшее частное государство мира создаст воплощенных AGI-агентов для любого типа реальности.
Цель суперкоманды Джима Фана - чувствующие и понимающие агенты физического и виртуальных миров.
По доходам сегодняшняя NVIDIA – 12е государство мира. И при этом, это крупнейшее «частное государство» на свете [1].
И поэтому объявление компании о формировании исследовательской супер-команды GEAR (Generalist Embodied Agent Research), возглавляемой Джимом Фаном и Юкэ Чжу, с миссией - создание универсальных воплощенных агентов в физическом (робототехника) и виртуальных (игры и любые симуляции) мирах, - это самое важное событие в области ИИ первых 2х месяцев 2024 [2].
«Мы верим в будущее, в котором каждая движущаяся машина будет автономной, а роботы и смоделированные виртуальные агенты будут такими же вездесущими, как iPhone… Мы отправляемся в миссию по высадке на Луну, и до того, как мы туда доберемся, мы получим горы знаний и сделаем много открытий» - пишет Фан.
Джим Фан имеет веские основания так говорить. Ибо он [3]:
• самый известный в мире практик в деле создания ИИ-агентов (Voyager - первый ИИ-агент, который умело играет в Minecraft, MineDojo - агент с открытым исходным кодом, обучающийся, просматривая 100 000 видеороликов Minecraft на YouTube, Eureka - робот-рука с пятью пальцами, выполняющий чрезвычайно тонкие и сложные задачи) и VIMA - одна из первых базовых мультимодальных моделей фундамент для манипулирования роботами)
• с совершенно уникальной карьерой (он работал в OpenAI с Ильей Суцкевером и Андреем Карпати, в Baidu AI Labs с Эндрю Нг и Дарио Амодеем и в MILA с Йошуа Бенджио)
Принципиальное отличие AGI-агентов, разрабатываемых GEAR, в следующем:
Они будут универсально-воплощенными – способными учиться и «жить» в обоих типах миров (физическом и виртуальном/цифровом).
Это будет достигаться путем синтеза 3х типов данных: из материального мира, из ноосферы (Интернета) и синтетических данных (порождаемых «ИИ-спецагентами, типа Eureka, уже разработанного Фаном для NVIDIA [5])
Год назад я писал «Поворотный момент пройден - AGI появится через 1,5 года. Сработает сочетание больших денег, открытых фреймворков и превращение LLM в когнитивных агентов» [6].
И создание NVIDIA GEAR – важнейший шаг в воплощении этого прогноза.
#ВоплощенныйИнтеллект #AGI #Роботы
0 https://www.youtube.com/watch?v=URHt3p6tbrY
1 https://bit.ly/49MYj0d
2 https://research.nvidia.com/labs/gear/
3 https://jimfan.me/
4 https://bit.ly/3uO4O42
5 https://www.toolify.ai/ai-news/eureka-nvidias-revolutionary-ai-breakthrough-towards-agi-1542610
6 https://t.me/theworldisnoteasy/1696
Цель суперкоманды Джима Фана - чувствующие и понимающие агенты физического и виртуальных миров.
По доходам сегодняшняя NVIDIA – 12е государство мира. И при этом, это крупнейшее «частное государство» на свете [1].
И поэтому объявление компании о формировании исследовательской супер-команды GEAR (Generalist Embodied Agent Research), возглавляемой Джимом Фаном и Юкэ Чжу, с миссией - создание универсальных воплощенных агентов в физическом (робототехника) и виртуальных (игры и любые симуляции) мирах, - это самое важное событие в области ИИ первых 2х месяцев 2024 [2].
«Мы верим в будущее, в котором каждая движущаяся машина будет автономной, а роботы и смоделированные виртуальные агенты будут такими же вездесущими, как iPhone… Мы отправляемся в миссию по высадке на Луну, и до того, как мы туда доберемся, мы получим горы знаний и сделаем много открытий» - пишет Фан.
Джим Фан имеет веские основания так говорить. Ибо он [3]:
• самый известный в мире практик в деле создания ИИ-агентов (Voyager - первый ИИ-агент, который умело играет в Minecraft, MineDojo - агент с открытым исходным кодом, обучающийся, просматривая 100 000 видеороликов Minecraft на YouTube, Eureka - робот-рука с пятью пальцами, выполняющий чрезвычайно тонкие и сложные задачи) и VIMA - одна из первых базовых мультимодальных моделей фундамент для манипулирования роботами)
• с совершенно уникальной карьерой (он работал в OpenAI с Ильей Суцкевером и Андреем Карпати, в Baidu AI Labs с Эндрю Нг и Дарио Амодеем и в MILA с Йошуа Бенджио)
Принципиальное отличие AGI-агентов, разрабатываемых GEAR, в следующем:
Они будут универсально-воплощенными – способными учиться и «жить» в обоих типах миров (физическом и виртуальном/цифровом).
Это будет достигаться путем синтеза 3х типов данных: из материального мира, из ноосферы (Интернета) и синтетических данных (порождаемых «ИИ-спецагентами, типа Eureka, уже разработанного Фаном для NVIDIA [5])
Год назад я писал «Поворотный момент пройден - AGI появится через 1,5 года. Сработает сочетание больших денег, открытых фреймворков и превращение LLM в когнитивных агентов» [6].
И создание NVIDIA GEAR – важнейший шаг в воплощении этого прогноза.
#ВоплощенныйИнтеллект #AGI #Роботы
0 https://www.youtube.com/watch?v=URHt3p6tbrY
1 https://bit.ly/49MYj0d
2 https://research.nvidia.com/labs/gear/
3 https://jimfan.me/
4 https://bit.ly/3uO4O42
5 https://www.toolify.ai/ai-news/eureka-nvidias-revolutionary-ai-breakthrough-towards-agi-1542610
6 https://t.me/theworldisnoteasy/1696
Истинно верный ответ на вопрос 2+2? можно дать лишь бросанием игральных костей.
Третье фундаментальное математико-философское откровение о том, как мы познаем физический мир.
Первые два фундаментальные откровения были просто крышесносными.
1. В 2018 Дэвид Волперт (полагаю, самый крутой физик 20-21 веков, работающий на стыке математического и философского осмысления мира и возможностей его познания) доказал существование предела знаний — т.е. всего и всегда никто и никогда узнать не сможет. Это доказательство не зависит от конкретных теорий физической реальности (квантовая механика, теория относительность и т.п.) и является для всех них универсальным (подробней см. мой пост «Математически доказано — Бог един, а знание не бесконечно» [1])
2. В 2022 Волперт доказал, что не только Бог не всеведущ, но и Сверхинтеллект, ибо (даже если его удастся когда-либо создать) у него также будет граница знаний, которую он, в принципе, не сможет преодолеть (подробней см. мой пост «Если даже Бог не всеведущ, — где границы знаний AGI» [2])
Третье откровение под стать двум первым. Это совместная работа Дэвида Волперта и Дэвида Кинни (философ и ученый-когнитивист) «Стохастическая модель математики и естественных наук» [3]. В ней авторы предлагают единую вероятностную структуру для описания математики, физической вселенной и описания того, как люди рассуждают о том и другом. Предложенный авторами фреймворк - стохастические математические системы (SMS), - описывает математику и естественные науки, как стохастические (вероятностные) системы, что позволяет ответить на такие вопросы:
• Чем отличается мышление математика от мышления ученого?
Математики имеют дело с абстрактными понятиями, а ученые изучают реальный мир. Это значит, что у них разные способы рассуждения и проверки своих идей.
• Как наше местоположение во Вселенной влияет на наши знания?
Мы всегда ограничены тем, что можем наблюдать и измерять. Можем ли мы быть уверены в своих знаниях, если не видим полной картины?
• Есть ли предел тому, что мы можем узнать?
Некоторые известные теоремы говорят о том, что в математике существуют вопросы, на которые невозможно дать однозначный ответ. Может ли это быть правдой и для науки?
• Как ученые могут лучше учиться на основе данных?
Существуют ограничения на то, насколько хорошо компьютерные программы могут обучаться без предварительных знаний. Можно ли разработать более эффективные методы обучения для ученых?
• Как ученые с разными взглядами могут прийти к согласию?
Даже если ученые не согласны во всем, у них могут быть общие цели, и крайне важно понять, как им найти общий язык и сотрудничать.
• Как избежать ложных умозаключений?
Иногда мы делаем поспешные выводы на основе неполной информации. Как научиться мыслить более логично и критически?
Также SMS предлагает решение проблемы логического всеведения в эпистемической логике, где предполагается, что если рассуждающий знает какое-либо предложение A и знает, что A влечет B, то он знает и B. SMS позволяет избежать этой проблемы, предлагая определение "знания", не требующее логического всеведения.
Если новая теория верна, то Эйнштейн ошибался, и Бог играет-таки в кости.
Картинка поста https://telegra.ph/file/57ef2e0ecc9e9d5dcadcc.jpg
1 https://t.me/theworldisnoteasy/473
2 https://t.me/theworldisnoteasy/1574
3 за пейволом https://link.springer.com/article/10.1007/s10701-024-00755-9
открытый доступ https://arxiv.org/pdf/2209.00543
#МатЛогика #Реальность #AGI
Третье фундаментальное математико-философское откровение о том, как мы познаем физический мир.
Первые два фундаментальные откровения были просто крышесносными.
1. В 2018 Дэвид Волперт (полагаю, самый крутой физик 20-21 веков, работающий на стыке математического и философского осмысления мира и возможностей его познания) доказал существование предела знаний — т.е. всего и всегда никто и никогда узнать не сможет. Это доказательство не зависит от конкретных теорий физической реальности (квантовая механика, теория относительность и т.п.) и является для всех них универсальным (подробней см. мой пост «Математически доказано — Бог един, а знание не бесконечно» [1])
2. В 2022 Волперт доказал, что не только Бог не всеведущ, но и Сверхинтеллект, ибо (даже если его удастся когда-либо создать) у него также будет граница знаний, которую он, в принципе, не сможет преодолеть (подробней см. мой пост «Если даже Бог не всеведущ, — где границы знаний AGI» [2])
Третье откровение под стать двум первым. Это совместная работа Дэвида Волперта и Дэвида Кинни (философ и ученый-когнитивист) «Стохастическая модель математики и естественных наук» [3]. В ней авторы предлагают единую вероятностную структуру для описания математики, физической вселенной и описания того, как люди рассуждают о том и другом. Предложенный авторами фреймворк - стохастические математические системы (SMS), - описывает математику и естественные науки, как стохастические (вероятностные) системы, что позволяет ответить на такие вопросы:
• Чем отличается мышление математика от мышления ученого?
Математики имеют дело с абстрактными понятиями, а ученые изучают реальный мир. Это значит, что у них разные способы рассуждения и проверки своих идей.
• Как наше местоположение во Вселенной влияет на наши знания?
Мы всегда ограничены тем, что можем наблюдать и измерять. Можем ли мы быть уверены в своих знаниях, если не видим полной картины?
• Есть ли предел тому, что мы можем узнать?
Некоторые известные теоремы говорят о том, что в математике существуют вопросы, на которые невозможно дать однозначный ответ. Может ли это быть правдой и для науки?
• Как ученые могут лучше учиться на основе данных?
Существуют ограничения на то, насколько хорошо компьютерные программы могут обучаться без предварительных знаний. Можно ли разработать более эффективные методы обучения для ученых?
• Как ученые с разными взглядами могут прийти к согласию?
Даже если ученые не согласны во всем, у них могут быть общие цели, и крайне важно понять, как им найти общий язык и сотрудничать.
• Как избежать ложных умозаключений?
Иногда мы делаем поспешные выводы на основе неполной информации. Как научиться мыслить более логично и критически?
Также SMS предлагает решение проблемы логического всеведения в эпистемической логике, где предполагается, что если рассуждающий знает какое-либо предложение A и знает, что A влечет B, то он знает и B. SMS позволяет избежать этой проблемы, предлагая определение "знания", не требующее логического всеведения.
Если новая теория верна, то Эйнштейн ошибался, и Бог играет-таки в кости.
Картинка поста https://telegra.ph/file/57ef2e0ecc9e9d5dcadcc.jpg
1 https://t.me/theworldisnoteasy/473
2 https://t.me/theworldisnoteasy/1574
3 за пейволом https://link.springer.com/article/10.1007/s10701-024-00755-9
открытый доступ https://arxiv.org/pdf/2209.00543
#МатЛогика #Реальность #AGI
{kind=link}
Как думаете:
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
{kind=link}
Атмосфера страха, секретности и запугивания накрыла индустрию ИИ.
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 https://t.me/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 https://t.me/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
NY Times
OpenAI Insiders Warn of a ‘Reckless’ Race for Dominance (Gift Article)
A group of current and former employees is calling for sweeping changes to the artificial intelligence industry, including greater transparency and protections for whistle-blowers.
Найден альтернативный способ достижения сверхчеловеческих способностей ИИ уже в 2024.
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке https://arxiv.org/html/2406.11741v1/extracted/5673380/advantage-analysis.png визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
https://arxiv.org/html/2406.11741v1
#AGI
Открыт феномен трансцендентности (превосходства) генеративного ИИ.
Совместное исследование Гарвардского, Принстонского и Калифорнийского университетов с DeepMind и Apple открыло новый феномен – трансцендентность LLM, когда генеративная модель достигает возможностей, превосходящих способности экспертов, генерирующих данные для ее обучения.
Открытие этого феномена - новый фазовый переход в раскрытии возможностей достижения ИИ превосходства над людьми.
Предыдущим фазовым переходом был прорыв к сверхчеловеческому уровню игры в шахматы, продемонстрированный AlphaGo Zero компании DeepMind в 2017. Ключом к тому успеху был отказ от использования для обучения ИИ наборов данных, полученных от экспертов-людей. Играя в шахматы (а потом и в Го) сама с собой, AlphaGo Zero достигла сверхчеловеческого уровня игры, недоступного даже для чемпионов мира среди людей.
Однако, такой способ преодоления человеческих интеллектуальных способностей применим лишь к строго регламентированным задачам, типа шахмат или Го. При отсутствии строгих регламентов решения задачи (правила, условия игры, начальные условия, внешние факторы и т.д.) для обучения модели необходимы наборы данных, описывающих, как эту задачу решали люди.
Но тут засада. Ведь если модель опять (как до AlphaGo Zero) будет учиться у людей, как она сможет превзойти уровень тех, на чьих данных модель учили?
Это как если бы юных шахматистов учили бы не на партиях мастеров и гроссмейстеров, а на партиях их ровесников из другой шахматной школы.
Открытие феномена трансцендентности снимает это ограничение, позволяя модели, обучаясь на партиях, например, перворазрядников, достигать собственного уровня игры на уровне гроссмейстеров.
Это достигается использованием определенной техники выбора данных, называемой "низкотемпературная выборка".
Вот поясняющая метафора.
Представьте себе, что вы учитесь играть в шахматы, наблюдая за игрой множества игроков. Обычно вы бы запоминали ходы, которые чаще всего приводят к победе, и пытались бы их повторить. Это похоже на стандартный способ обучения модели.
Но что, если вы начнете выбирать не просто популярные ходы, а очень точные и редкие ходы, которые гораздо эффективнее в определенных ситуациях? Вы бы стали играть намного лучше, чем те игроки, у которых вы учились. Низкотемпературная выборка — это как раз такой способ: он помогает модели фокусироваться на самых эффективных и точных решениях, даже если они редко встречаются в обучающих данных.
Таким образом, "низкотемпературная выборка" помогает модели выделять и использовать самые лучшие ходы, что и позволяет ей в итоге превосходить своих учителей.
Принципиальное отличие 2го фазового перехода от 1го в том, что феномен трансцендентности должен позволять модели превосходить уровень учителей (отраженный в обучающих наборах данных) не только в строго регламентированных задачах, но и (пока теоретически) в любых.
Следовательно, уже в этом году, могут появиться модели со сверхчеловеческими способностями в самом широком спектре применений.
Однако, говорить о близком наступлении эры абсолютного превосходства ИИ над людьми, феномен трансцендентности не позволяет.
Дело в том, что трансцендентность достигается лишь за счет эффекта снижения шума (устранения ошибок, допущенных людьми).
Это значит, что модель не способна, за счет новых абстрактных рассуждений производить новые решения, которые не может придумать человеческий эксперт… А человек может!
Но это остается последнее (хотя и решающее) превосходство людей над ИИ.
На картинке https://arxiv.org/html/2406.11741v1/extracted/5673380/advantage-analysis.png визуализация эффекта снижения шума при низкой температуре. Эффект смещает вероятности в сторону хода с высоким вознаграждением — ловушки для ферзя с помощью ладьи по мере уменьшения температуры 𝜏.
https://arxiv.org/html/2406.11741v1
#AGI
{kind=link}
Тайна секретного проекта OpenAI уже никакая не тайна.
Reuters упустили лежащее на поверхности самое важное.
Вчерашний «эксклюзив» о, якобы, утечке секретной информации OpenAI расследовательницы из Reuters озаглавили «OpenAI работает над новой технологией рассуждений под кодовым названием “Strawberry“» ]1].
За сутки появилось уже несколько десятков аналитических комментариев к этому «эксклюзиву». И все они лишь на разные лады перекомментируют одни и те же пассажи публикации Reuters.
• OpenAI разрабатывает строго охраняемый секретный проект новой модели генеративного ИИ под названием «Strawberry», способной достичь уровня человеческого интеллекта за счет продвинутых рассуждений.
• Strawberry является продолжением проекта OpenAI под названием “Q*” (произносится Q-Star), из-за которого в прошлом году Илья Суцкевер безуспешно пытался выгнать Сэма Альтмана из OpenAI из-за страха, что Q* может уничтожить человечество [2].
• Strawberry имеет сходство с методом, разработанным в Стэнфорде в 2022 году под названием «Self-Taught Reasoner» (сокращенно «STaR»). STaR позволяет моделям ИИ «загружаться» до более высоких уровней интеллекта посредством итеративного создания собственных обучающих данных и, в теории, может использоваться для того, чтобы заставить языковые модели превосходить уровень интеллекта человека. О чем сообщил расследовательницам Reuters один из создателей метода, профессор Стэнфорда Ноа Гудман.
Из этой «утечки» следует что:
1. секретный проект «Strawberry», являющийся продолжением другого секретного проекта “Q*”, тайно ведется OpenAI;
2. что скрывается внутри этих проектов, - совершенно неизвестно из-за их полной засекреченности.
И если 1й вывод верный, то 2й, как я полагаю, вводит читателей в заблуждение. Ибо проект Quiet-StaR (что такое «STaR», вы читали выше, а “Quiet” – это расшифровка буквы Q в названии проекта “Q*”) и проект Q-Star – это кодировки одного и того же проекта, суть которого Ноа Гудман изложил год назад здесь [3], а детально он описан здесь [4]
Как честно признают авторы, «мы называем эту технику Quiet-STaR, поскольку её можно понимать как "тихое" применение STaR». По-русски сказали бы «по-тихому» - т.е. чтоб никто не догадался.
После прочтения статьи о Quiet-StaR также становится ясно, почему вдруг в позавчерашней «утечке» от Bloomberg про новый 5-ти этапный план OpenAI по созданию AGI [5] следующий за нынешним этап - Level 2 – назван “Reasoners” (напомню, STaR – это сокращение от «Self-Taught Reasoner». И этот новый тип ИИ сможет решать проблемы так же хорошо, как человек с докторской степенью образования, за счет того (как объясняется в статье), что модель научится думать, прежде чем говорить.
Картинка https://telegra.ph/file/b187d9ebe7942f5c38391.jpg
1 https://www.reuters.com/technology/artificial-intelligence/openai-working-new-reasoning-technology-under-code-name-strawberry-2024-07-12/
2 https://archive.is/ptCoI
3 https://docs.google.com/presentation/d/1NNnS4bqJfI1tJK94srnv0ouIuce4oHB87Vr0RcjzHQs/edit#slide=id.g2515536b270_0_43
4 https://arxiv.org/abs/2403.09629
5 https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai
#AGI #OpenAI
Reuters упустили лежащее на поверхности самое важное.
Вчерашний «эксклюзив» о, якобы, утечке секретной информации OpenAI расследовательницы из Reuters озаглавили «OpenAI работает над новой технологией рассуждений под кодовым названием “Strawberry“» ]1].
За сутки появилось уже несколько десятков аналитических комментариев к этому «эксклюзиву». И все они лишь на разные лады перекомментируют одни и те же пассажи публикации Reuters.
• OpenAI разрабатывает строго охраняемый секретный проект новой модели генеративного ИИ под названием «Strawberry», способной достичь уровня человеческого интеллекта за счет продвинутых рассуждений.
• Strawberry является продолжением проекта OpenAI под названием “Q*” (произносится Q-Star), из-за которого в прошлом году Илья Суцкевер безуспешно пытался выгнать Сэма Альтмана из OpenAI из-за страха, что Q* может уничтожить человечество [2].
• Strawberry имеет сходство с методом, разработанным в Стэнфорде в 2022 году под названием «Self-Taught Reasoner» (сокращенно «STaR»). STaR позволяет моделям ИИ «загружаться» до более высоких уровней интеллекта посредством итеративного создания собственных обучающих данных и, в теории, может использоваться для того, чтобы заставить языковые модели превосходить уровень интеллекта человека. О чем сообщил расследовательницам Reuters один из создателей метода, профессор Стэнфорда Ноа Гудман.
Из этой «утечки» следует что:
1. секретный проект «Strawberry», являющийся продолжением другого секретного проекта “Q*”, тайно ведется OpenAI;
2. что скрывается внутри этих проектов, - совершенно неизвестно из-за их полной засекреченности.
И если 1й вывод верный, то 2й, как я полагаю, вводит читателей в заблуждение. Ибо проект Quiet-StaR (что такое «STaR», вы читали выше, а “Quiet” – это расшифровка буквы Q в названии проекта “Q*”) и проект Q-Star – это кодировки одного и того же проекта, суть которого Ноа Гудман изложил год назад здесь [3], а детально он описан здесь [4]
Как честно признают авторы, «мы называем эту технику Quiet-STaR, поскольку её можно понимать как "тихое" применение STaR». По-русски сказали бы «по-тихому» - т.е. чтоб никто не догадался.
После прочтения статьи о Quiet-StaR также становится ясно, почему вдруг в позавчерашней «утечке» от Bloomberg про новый 5-ти этапный план OpenAI по созданию AGI [5] следующий за нынешним этап - Level 2 – назван “Reasoners” (напомню, STaR – это сокращение от «Self-Taught Reasoner». И этот новый тип ИИ сможет решать проблемы так же хорошо, как человек с докторской степенью образования, за счет того (как объясняется в статье), что модель научится думать, прежде чем говорить.
Картинка https://telegra.ph/file/b187d9ebe7942f5c38391.jpg
1 https://www.reuters.com/technology/artificial-intelligence/openai-working-new-reasoning-technology-under-code-name-strawberry-2024-07-12/
2 https://archive.is/ptCoI
3 https://docs.google.com/presentation/d/1NNnS4bqJfI1tJK94srnv0ouIuce4oHB87Vr0RcjzHQs/edit#slide=id.g2515536b270_0_43
4 https://arxiv.org/abs/2403.09629
5 https://www.bloomberg.com/news/articles/2024-07-11/openai-sets-levels-to-track-progress-toward-superintelligent-ai
#AGI #OpenAI
{kind=link}
Появился ли сегодня первый AGI?
Даже если нет, то появится он именно так.
Сеть закипает. 11 часов назад стартап выставил в сети свою модель новой архитектуры с новым методом обучения.
Авторы утверждают:
У LLM есть следующие проблемы:
1. Статические знания о мире
2. Амнезия за пределами текущего разговорах (чата)
3. Неспособность приобретать новые навыки без тонкой настройки
Разработанная компанией Topology модель непрерывного обучения (CLM):
1. Не имеет границы знаний
2. Запоминает содержание всех разговоров (чатов)
3. Может приобретать новые навыки без тонкой настройки методом проб и ошибок
Иными словами, — эта новая ИИ-система запоминает свои взаимодействия с миром, обучается автономно, развивая при этом т.н. «незавершенную» личность.
И что это, если не AGI?
Итак, что мы имеем:
• Скриншоты примеров диалога с CLM впечатляют [1, 2]
• Первые отзывы весьма противоречивы (от «это действительно похоже на AGI» до «даже не собираюсь пробовать эту туфту») [3]
• Документация выставлена в сети [4]
• Сама система здесь [5]
Не знаю, что это. Сам пока не пробовал.
Но если что-то типа AGI когда-либо появится, то скорее всего, это будет столь же неожиданно, и будет сначала воспринято столь же недоверчиво… (но только сначала)
#AGI
1 https://pbs.twimg.com/media/GTtMbpDXoAAe6PO?format=png&name=large
2 https://pbs.twimg.com/media/GTspIUmakAAwCAK?format=jpg&name=900x900
3 https://www.reddit.com/r/singularity/comments/1efgw2t/topology_releases_their_continuous_learning_model/
4 https://yellow-apartment-148.notion.site/CLM-Docs-507d762ad7b14d828fac9a3f91871e3f
5 https://topologychat.com/
Даже если нет, то появится он именно так.
Сеть закипает. 11 часов назад стартап выставил в сети свою модель новой архитектуры с новым методом обучения.
Авторы утверждают:
У LLM есть следующие проблемы:
1. Статические знания о мире
2. Амнезия за пределами текущего разговорах (чата)
3. Неспособность приобретать новые навыки без тонкой настройки
Разработанная компанией Topology модель непрерывного обучения (CLM):
1. Не имеет границы знаний
2. Запоминает содержание всех разговоров (чатов)
3. Может приобретать новые навыки без тонкой настройки методом проб и ошибок
Иными словами, — эта новая ИИ-система запоминает свои взаимодействия с миром, обучается автономно, развивая при этом т.н. «незавершенную» личность.
И что это, если не AGI?
Итак, что мы имеем:
• Скриншоты примеров диалога с CLM впечатляют [1, 2]
• Первые отзывы весьма противоречивы (от «это действительно похоже на AGI» до «даже не собираюсь пробовать эту туфту») [3]
• Документация выставлена в сети [4]
• Сама система здесь [5]
Не знаю, что это. Сам пока не пробовал.
Но если что-то типа AGI когда-либо появится, то скорее всего, это будет столь же неожиданно, и будет сначала воспринято столь же недоверчиво… (но только сначала)
#AGI
1 https://pbs.twimg.com/media/GTtMbpDXoAAe6PO?format=png&name=large
2 https://pbs.twimg.com/media/GTspIUmakAAwCAK?format=jpg&name=900x900
3 https://www.reddit.com/r/singularity/comments/1efgw2t/topology_releases_their_continuous_learning_model/
4 https://yellow-apartment-148.notion.site/CLM-Docs-507d762ad7b14d828fac9a3f91871e3f
5 https://topologychat.com/
Команда Карла Фристона разработала и опробовала ИИ нового поколения.
Предложено единое решение 4х фундаментальных проблем ИИ: универсальность, эффективность, объяснимость и точность.
✔️ ИИ от Фристона – это даже не кардинальная смена курса развития ИИ моделей.
✔️ Это пересмотр самих основ технологий машинного обучения.
✔️ Уровень этого прорыва не меньше, чем был при смене типа двигателей на истребителях: с поршневых (принципиально не способных на сверхзвуковую скорость) на реактивные (позволяющие летать в несколько раз быстрее звука)
Новая фундаментальная работа команды Карла Фристона «От пикселей к планированию: безмасштабный активный вывод» описывает первую реальную альтернативу глубокому обучению, обучению с подкреплением и генеративному ИИ.
Эта альтернатива – по сути, ИИ нового поколения, - названа ренормализирующие генеративные модели (RGM).
Полный текст про новый тип ИИ от Фристона доступен подписчикам моих лонгридов на Patreon, Boosty и VK
Картинка https://telegra.ph/file/18129fcce3f45e87026e6.jpg
#ИИ #AGI #ПринципСвободнойЭнергии #Фристон
Предложено единое решение 4х фундаментальных проблем ИИ: универсальность, эффективность, объяснимость и точность.
✔️ ИИ от Фристона – это даже не кардинальная смена курса развития ИИ моделей.
✔️ Это пересмотр самих основ технологий машинного обучения.
✔️ Уровень этого прорыва не меньше, чем был при смене типа двигателей на истребителях: с поршневых (принципиально не способных на сверхзвуковую скорость) на реактивные (позволяющие летать в несколько раз быстрее звука)
Новая фундаментальная работа команды Карла Фристона «От пикселей к планированию: безмасштабный активный вывод» описывает первую реальную альтернативу глубокому обучению, обучению с подкреплением и генеративному ИИ.
Эта альтернатива – по сути, ИИ нового поколения, - названа ренормализирующие генеративные модели (RGM).
Полный текст про новый тип ИИ от Фристона доступен подписчикам моих лонгридов на Patreon, Boosty и VK
Картинка https://telegra.ph/file/18129fcce3f45e87026e6.jpg
#ИИ #AGI #ПринципСвободнойЭнергии #Фристон
{kind=link}