
Евгений Морозов назвал свое эссе в The New York Times «Истинная угроза ИИ». Эта угроза, якобы, в том, что создание человекоподобного ИИ (AGI) ведет к AGI-изму – некой терминальной стадии неолиберализма, увековечивающего приоритет прибыльности и культивирующего негативные тренды в обществе.
Красиво написано в стилистике и духе The New York Times.
Однако, автор почему-то упускает из рассмотрения два основополагающих для темы ИИ-рисков факта.
1) Мы находимся на алхимическом этапе понимания ИИ: пропасть непонимание того, как низкоуровневая механика ИИ приводит к эмерджентным результатам, уже соизмерима с аналогичной пропастью в понимании человеческого разума.
2) AGI – это, своего рода, атомная бомба интеллектуальных технологий. Но мир пока не знает, как эту бомбу сделать. Тогда как уже существующие GPT 4, 5 … – это, своего рода, автомат Калашникова, уже принятый в массовое производство. И есть колоссальный риск, что с этим «интеллектуальным автоматом» будет, как и с Калашом. Т.е. число жертв по миру будет несоизмеримо большим, чем от гипотетической, а потом и сделанной атомной бомбы (или AGI).
Подробней, см. в моем комментарии для BRIEFLY.
#Вызовы21века #РискиИИ
Красиво написано в стилистике и духе The New York Times.
Однако, автор почему-то упускает из рассмотрения два основополагающих для темы ИИ-рисков факта.
1) Мы находимся на алхимическом этапе понимания ИИ: пропасть непонимание того, как низкоуровневая механика ИИ приводит к эмерджентным результатам, уже соизмерима с аналогичной пропастью в понимании человеческого разума.
2) AGI – это, своего рода, атомная бомба интеллектуальных технологий. Но мир пока не знает, как эту бомбу сделать. Тогда как уже существующие GPT 4, 5 … – это, своего рода, автомат Калашникова, уже принятый в массовое производство. И есть колоссальный риск, что с этим «интеллектуальным автоматом» будет, как и с Калашом. Т.е. число жертв по миру будет несоизмеримо большим, чем от гипотетической, а потом и сделанной атомной бомбы (или AGI).
Подробней, см. в моем комментарии для BRIEFLY.
#Вызовы21века #РискиИИ
Telegram
BRIEFLY
Сергей Карелов для Briefly: Дискуссии с критиками AGI-изма (якобы, терминальной стадии неолиберализма) мне видятся столь же непродуктивными и, вообще, ненаучными, как и с его сторонниками. Дело в том, что мы находимся на алхимическом этапе понимания ИИ (формулировка…
Это цунами, заставшее человечество врасплох.
Легендарный ученый и самый известный скептик ИИ рассказал, как страшно он ошибался.
Дуглас Хофштадтер – всемирно известный физик (открыватель фрактала «бабочка Хофштадтера») и когнитивист (автор вычислительных моделей высокоуровневого восприятия и познания), чьим именем названа «петля Хофштадтера-Мебиуса» в продолжении романа Артура Кларка «2001: Космическая одиссея» - «2010: Одиссея 2», чьи книги стали мега-бестселлерами, получив Пулитцеровскую и Национальную книжную премии, и чьими аспирантами были десятки ставших потом всемирно известными ученых (Дэвид Чалмерс, Менлани Митчел, Боб Френч, Гэри МакГроу …)
А кроме того, он последние 20 лет был самым известным в мире ИИ скептиком, еще в 2006 на первом «саммите по сингулярности» заявившим, что достижение ИИ человеческого уровня вряд ли может произойти в обозримом будущем.
И поэтому столь знаменательно кардинальное переосмысление Дугласом Хофштадтером перспектив развития ИИ и его влияния на человечество в свете произошедшей «революции ChatGPT».
Вот несколько цитат из его 37-минутного интервью на эту тему.
"Для меня это (прогресс ИИ) довольно страшно, потому что это говорит о том, что все, во что я раньше верил, отменяется. Я думал, что пройдут сотни лет, прежде чем вскоре появится что-то хотя бы отдаленно похожее на человеческий разум.
Я никогда не представлял, что компьютеры будут соперничать или даже превосходить человеческий интеллект. Это была настолько далекая цель, что я не беспокоился об этом. А потом это начало происходить все быстрее, когда недостижимые цели и вещи, которые компьютеры не должны были быть в состоянии сделать, начали рушиться …".
"Я думаю, что (прогресс ИИ) ужасает. Я ненавижу его. Я думаю об этом практически все время, каждый божий день".
"Такое ощущение, что вся человеческая раса вот-вот будет превзойдена и оставлена в пыли.
Ускоряющийся прогресс оказался настолько неожиданным, что застал врасплох не только меня, но и многих, многих людей - возникает некий ужас перед надвигающимся цунами, которое застанет врасплох все человечество."
"ИИ превращает человечество в очень маленькое явление по сравнению с чем-то гораздо более разумным, чем мы, и ИИ станет для нас непостижимым, как мы для тараканов".
"Очень скоро эти сущности ИИ вполне могут стать гораздо более разумными, чем мы, и тогда мы отойдем на второй план. Мы передадим эстафету нашим преемникам. Если бы это происходило в течение длительного времени, например, сотен лет, это было бы нормально, но это происходит в течение нескольких лет".
От себя добавлю.
Аналогичное кардинальное переосмысление перспектив прогресса ИИ произошло и со мной. И это ощущение допущенной по собственному недопониманию огромной ошибки заставляет меня теперь писать пост за постом на тему #РискиИИ и #Вызовы21века.
Легендарный ученый и самый известный скептик ИИ рассказал, как страшно он ошибался.
Дуглас Хофштадтер – всемирно известный физик (открыватель фрактала «бабочка Хофштадтера») и когнитивист (автор вычислительных моделей высокоуровневого восприятия и познания), чьим именем названа «петля Хофштадтера-Мебиуса» в продолжении романа Артура Кларка «2001: Космическая одиссея» - «2010: Одиссея 2», чьи книги стали мега-бестселлерами, получив Пулитцеровскую и Национальную книжную премии, и чьими аспирантами были десятки ставших потом всемирно известными ученых (Дэвид Чалмерс, Менлани Митчел, Боб Френч, Гэри МакГроу …)
А кроме того, он последние 20 лет был самым известным в мире ИИ скептиком, еще в 2006 на первом «саммите по сингулярности» заявившим, что достижение ИИ человеческого уровня вряд ли может произойти в обозримом будущем.
И поэтому столь знаменательно кардинальное переосмысление Дугласом Хофштадтером перспектив развития ИИ и его влияния на человечество в свете произошедшей «революции ChatGPT».
Вот несколько цитат из его 37-минутного интервью на эту тему.
"Для меня это (прогресс ИИ) довольно страшно, потому что это говорит о том, что все, во что я раньше верил, отменяется. Я думал, что пройдут сотни лет, прежде чем вскоре появится что-то хотя бы отдаленно похожее на человеческий разум.
Я никогда не представлял, что компьютеры будут соперничать или даже превосходить человеческий интеллект. Это была настолько далекая цель, что я не беспокоился об этом. А потом это начало происходить все быстрее, когда недостижимые цели и вещи, которые компьютеры не должны были быть в состоянии сделать, начали рушиться …".
"Я думаю, что (прогресс ИИ) ужасает. Я ненавижу его. Я думаю об этом практически все время, каждый божий день".
"Такое ощущение, что вся человеческая раса вот-вот будет превзойдена и оставлена в пыли.
Ускоряющийся прогресс оказался настолько неожиданным, что застал врасплох не только меня, но и многих, многих людей - возникает некий ужас перед надвигающимся цунами, которое застанет врасплох все человечество."
"ИИ превращает человечество в очень маленькое явление по сравнению с чем-то гораздо более разумным, чем мы, и ИИ станет для нас непостижимым, как мы для тараканов".
"Очень скоро эти сущности ИИ вполне могут стать гораздо более разумными, чем мы, и тогда мы отойдем на второй план. Мы передадим эстафету нашим преемникам. Если бы это происходило в течение длительного времени, например, сотен лет, это было бы нормально, но это происходит в течение нескольких лет".
От себя добавлю.
Аналогичное кардинальное переосмысление перспектив прогресса ИИ произошло и со мной. И это ощущение допущенной по собственному недопониманию огромной ошибки заставляет меня теперь писать пост за постом на тему #РискиИИ и #Вызовы21века.
YouTube
Gödel, Escher, Bach author Doug Hofstadter on the state of AI today
Listen to the podcast episode here: https://www.buzzsprout.com/222312/13125914
Click here to hear this video without annoying background music: https://youtu.be/R6e08RnJyxo"
*Douglas Hofstadter*, the Pulitzer Prize–winning author of Gödel, Escher, Bach…
Click here to hear this video without annoying background music: https://youtu.be/R6e08RnJyxo"
*Douglas Hofstadter*, the Pulitzer Prize–winning author of Gödel, Escher, Bach…
Риск гибели 1 миллиарда человек примерно, как в русской рулетке.
А шансы всего человечества дожить до 2100 меньше, чем у больного раком простаты прожить еще пять лет.
Вот и сошлись три моих любимые темы: предсказание будущего, экзистенциальные риски и искусственный интеллект.
Опубликован «Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament» - 1й отчет Forecasting Research Institute о результатах оценки экзистенциальных рисков человечества. Это отчет интересного и важного проекта, впервые в истории проведенного по инновационной методике. Её автор - знаменитый (и я бы сказал, легендарный) профессор психологии и политологии Филип Тетлок, спектр слушателей мастер-классов которого впечатляет: от лауреатов Нобелевской премии и высших чинов разведки США до высшего менеджмента компаний класса Google и Microsoft).
Специализация Тетлока – предсказание будущего нетрадиционными методами на основе передовых информационных технологий (краудсорсинг, рынки предсказаний, интеграция коллективного интеллекта людей и алгоритмов и т.д.) Моим постоянным читателям, полагаю, известно, что это также одна из моих специализаций. И я подробно писал об этой теме в шести-серийном посто-сериале «ЦРУ создает кентавров для предсказания будущего». Поэтому я не стал описывать детали методики Тетлока (желающие прочтут это в лонгридах моего посто-сериала), а сфокусировался на главном:
Ключевой результат проекта вынесен в заголовок этого поста.
Об остальных результатах (их много, интересных и разных, на 751 стр. отчета), а также
• почему и зачем был затеян этот проект;
• что и как в нем было сделано, -
читайте в продолжении этого поста (еще 5 мин):
- на Medium https://bit.ly/3NUWGV3
- на Дзене https://clck.ru/34z7yP
Имхо, весьма интересное чтение на выходных 😊
#Прогнозирование #Вызовы21века #РискиИИ #Х-риски
А шансы всего человечества дожить до 2100 меньше, чем у больного раком простаты прожить еще пять лет.
Вот и сошлись три моих любимые темы: предсказание будущего, экзистенциальные риски и искусственный интеллект.
Опубликован «Forecasting Existential Risks: Evidence from a Long-Run Forecasting Tournament» - 1й отчет Forecasting Research Institute о результатах оценки экзистенциальных рисков человечества. Это отчет интересного и важного проекта, впервые в истории проведенного по инновационной методике. Её автор - знаменитый (и я бы сказал, легендарный) профессор психологии и политологии Филип Тетлок, спектр слушателей мастер-классов которого впечатляет: от лауреатов Нобелевской премии и высших чинов разведки США до высшего менеджмента компаний класса Google и Microsoft).
Специализация Тетлока – предсказание будущего нетрадиционными методами на основе передовых информационных технологий (краудсорсинг, рынки предсказаний, интеграция коллективного интеллекта людей и алгоритмов и т.д.) Моим постоянным читателям, полагаю, известно, что это также одна из моих специализаций. И я подробно писал об этой теме в шести-серийном посто-сериале «ЦРУ создает кентавров для предсказания будущего». Поэтому я не стал описывать детали методики Тетлока (желающие прочтут это в лонгридах моего посто-сериала), а сфокусировался на главном:
Ключевой результат проекта вынесен в заголовок этого поста.
Об остальных результатах (их много, интересных и разных, на 751 стр. отчета), а также
• почему и зачем был затеян этот проект;
• что и как в нем было сделано, -
читайте в продолжении этого поста (еще 5 мин):
- на Medium https://bit.ly/3NUWGV3
- на Дзене https://clck.ru/34z7yP
Имхо, весьма интересное чтение на выходных 😊
#Прогнозирование #Вызовы21века #РискиИИ #Х-риски
Medium
Риск гибели 1 миллиарда человек примерно, как в русской рулетке
А шансы всего человечества дожить до 2100 меньше, чем у больного раком простаты прожить еще пять лет
Искусственная эскалация.
TLDR – самый вероятный сценарий гибели земной цивилизации.
Ядерный риск и ИИ-риски, меркнут в сравнении с интегральным риском при их сочетании. Но это, увы, самый вероятный сценарий будущего для земной цивилизации, причем, не в отдаленном будущем, а в ближайшие годы.
Такой сценарий называется TLDR: Threat (Угроза), Likelihood (Вероятность), Deadline (Дедлайн – крайний срок принятия решения), Recommendation (Рекомендация ИИ принимающему решение лицу с учетом TLD). В соответствии с этим сценарием будут приниматься все важнейшие решения в чрезвычайных ситуациях, когда ставки на кону велики.
У сценария TLDR нет альтернатив (что бы ни говорили ученые, политики и военные), ибо он:
• качественно (по уровню анализа) и количественно (по скорости принятия решений) превосходит все иные мыслимые сценарии действий в ситуациях радикальной неопределенности, в которых «факты неточны, ценности спорны, ставки высоки, а решения срочны»;
• и отвечает единственному сегодня неоспоримому требованию к технологиям - оставляет последнее решение за человеком.
Но у сценария TLDR есть и практически непреодолимый изъян – рано или поздно, он может запустить процесс неостановимой искусственной эскалации военного противостояния.
Как это может выглядеть на практике на временном горизонте ближайших 10 лет, просто, но убедительно показано в 8-минутной короткометражке «Искусственная эскалация», снятом Space Film & VFX для Института будущего жизни.
Этот ролик рекомендую посмотреть каждому. Он того стоит.
Кроме того:
• Реальность TLDR-сценария признают весьма серьезные эксперты (см. Bulletin of the Atomic Scientist)
• Насколько опасно использование ИИ в вооруженных конфликтах, я неоднократно рассказывал и писал (в том числе, о «проблеме 37-го хода военного ИИ» и «иллюзии контроля ИИ»)
• Последствия глобального TLDR-сценария будут гибельны для цивилизации на Земле (см. этот 4-х минутный ролик)
• Перезвон Часов Судного дня запускается применением ядерного оружия. Но лишь в течение 20 сек этого «перезвона», часы еще можно остановить… Ни секундой позже.
#Вызовы21века #РискиИИ #Хриски
TLDR – самый вероятный сценарий гибели земной цивилизации.
Ядерный риск и ИИ-риски, меркнут в сравнении с интегральным риском при их сочетании. Но это, увы, самый вероятный сценарий будущего для земной цивилизации, причем, не в отдаленном будущем, а в ближайшие годы.
Такой сценарий называется TLDR: Threat (Угроза), Likelihood (Вероятность), Deadline (Дедлайн – крайний срок принятия решения), Recommendation (Рекомендация ИИ принимающему решение лицу с учетом TLD). В соответствии с этим сценарием будут приниматься все важнейшие решения в чрезвычайных ситуациях, когда ставки на кону велики.
У сценария TLDR нет альтернатив (что бы ни говорили ученые, политики и военные), ибо он:
• качественно (по уровню анализа) и количественно (по скорости принятия решений) превосходит все иные мыслимые сценарии действий в ситуациях радикальной неопределенности, в которых «факты неточны, ценности спорны, ставки высоки, а решения срочны»;
• и отвечает единственному сегодня неоспоримому требованию к технологиям - оставляет последнее решение за человеком.
Но у сценария TLDR есть и практически непреодолимый изъян – рано или поздно, он может запустить процесс неостановимой искусственной эскалации военного противостояния.
Как это может выглядеть на практике на временном горизонте ближайших 10 лет, просто, но убедительно показано в 8-минутной короткометражке «Искусственная эскалация», снятом Space Film & VFX для Института будущего жизни.
Этот ролик рекомендую посмотреть каждому. Он того стоит.
Кроме того:
• Реальность TLDR-сценария признают весьма серьезные эксперты (см. Bulletin of the Atomic Scientist)
• Насколько опасно использование ИИ в вооруженных конфликтах, я неоднократно рассказывал и писал (в том числе, о «проблеме 37-го хода военного ИИ» и «иллюзии контроля ИИ»)
• Последствия глобального TLDR-сценария будут гибельны для цивилизации на Земле (см. этот 4-х минутный ролик)
• Перезвон Часов Судного дня запускается применением ядерного оружия. Но лишь в течение 20 сек этого «перезвона», часы еще можно остановить… Ни секундой позже.
#Вызовы21века #РискиИИ #Хриски
YouTube
Artificial Escalation
This work of fiction seeks to depict key drivers that could result in a global Al catastrophe:
- Accidental conflict escalation at machine speeds;
- Al integrated too deeply into high-stakes functions;
- Humans giving away too much control to Al;
- Humans…
- Accidental conflict escalation at machine speeds;
- Al integrated too deeply into high-stakes functions;
- Humans giving away too much control to Al;
- Humans…
Устрашающий результат эксперимента OpenAI c GPT-4.
Теперь можно представить, кем станет «ребенок инопланетян», воспитанный мафией.
Роль среды, в которой растет и воспитывается человеческий ребенок, решающим образом влияет на характер и границы его поведения после того, как он вырастет. Близнецы, обладающие от рождения одинаковыми интеллектуальными способностями, в зависимости от среды и воспитания, могут вырасти в кого угодно. Воспитывавшийся в добропорядочной среде, скорее всего, станет достойным гражданином. Выросший в среде мафии, с большой вероятностью, станет преступником. А воспитанный с младенчества волками ребенок – маугли уже никогда не станет человеком.
Резонно предположить то же самое и в случае «детей - инопланетян», появившихся недавно на Земле в форме ИИ на основе больших языковых моделей (LLM): GPT, ClaudeAI …
Как и человеческие дети, каждый из этих «нечеловеческих разумов» LLM обладает широким спектром заложенных в них способностей. Но человеческие дети приобретают их сразу при рождении. А «дети - инопланетяне» - в результате предварительного обучения. Это дорогостоящий процесс, который для самых больших моделей стоит огромных денег и времени, и поэтому он не повторяется.
Говоря об интеллектуальных способностях людей и чат-ботов, важно понимать принципиальное отличие способностей и поведения.
• У людей (как сказано выше) характер и границы поведения определяются воспитанием.
• У чат-ботов аналогично. Роль воспитания здесь играет т.н. тонкая настройка модели. Она куда дешевле предварительного обучения и потому может проводиться регулярно.
Обратите внимание на следующий важнейший момент.
• Базовая модель после предварительного обучения функционально представляет собой продвинутый механизм автозаполнения: она не общается с пользователем, а лишь генерирует продолжение фраз, подаваемых ей на вход.
• Поведение в диалоге с людьми возникает у чат-бота лишь благодаря тонкой настройке (важнейшая цель которой — предотвратить нежелательное поведение чат-бота. Достигается это тем, что тонкая настройка может как выявить, так и подавить те или иные способности модели.
Иными словами, в результате тонкой настройки, модель, имеющая широкий спектр способностей, может, в ответ на конкретный запрос, проявлять какие-то из них или не проявлять. Т.е. способности модели остаются те же, а поведение разное.
Следовательно, в результате воспитания (тонкой настройки) модель может проявлять себя кем угодно от ангела до дьявола. И зависеть это будет лишь от ее воспитателей (от высокоморальных исследователей до гнусных бандитов и человеконенавистников).
Все вышесказанное было продемонстрировано в течение последних месяцев компанией OpenAI, взявшейся усиленно воспитывать GPT-4.
Результаты этого воспитания всполошили Интернет после статьи Линцзяо Чен, Матея Захария и Джеймса Цзоу, которые тестировали GPT-3.5 и GPT-4 на четырех задачах и «моментальных снимках» моделей с марта по июнь.
Интернет-общественность трактовала результаты этого исследования, как «деградацию способностей» GPT-4. На самом же деле, авторы вовсе не это имели в виду.
Все способности GPT-4 остались при ней. Изменилось лишь (в результате воспитания модели) её поведение (подробное объяснение см. здесь).
По сути, этот эксперимент показал колоссальный потенциал воспитания моделей «детей-инопланетян», позволяющий, путем их тонкой настройки превратить в кого-угодно.
Этот воистину устрашающий результат ставит важный вопрос:
Зачем биться за создание высокоморального ИИ, если тонкой настройкой можно быстро и дешево перевоспитать его в злодея?
Ну и вечный вопрос:
Оруэлл писал: «Если бы атомная бомба оказалась чем-то дешевым и легко производимым, как велосипед или будильник, возможно, мир снова погрузился бы в варварство …»
Не это ли грозит нам нынче с ИИ на базе LLM?
#Вызовы21века #РискиИИ #LLM
Теперь можно представить, кем станет «ребенок инопланетян», воспитанный мафией.
Роль среды, в которой растет и воспитывается человеческий ребенок, решающим образом влияет на характер и границы его поведения после того, как он вырастет. Близнецы, обладающие от рождения одинаковыми интеллектуальными способностями, в зависимости от среды и воспитания, могут вырасти в кого угодно. Воспитывавшийся в добропорядочной среде, скорее всего, станет достойным гражданином. Выросший в среде мафии, с большой вероятностью, станет преступником. А воспитанный с младенчества волками ребенок – маугли уже никогда не станет человеком.
Резонно предположить то же самое и в случае «детей - инопланетян», появившихся недавно на Земле в форме ИИ на основе больших языковых моделей (LLM): GPT, ClaudeAI …
Как и человеческие дети, каждый из этих «нечеловеческих разумов» LLM обладает широким спектром заложенных в них способностей. Но человеческие дети приобретают их сразу при рождении. А «дети - инопланетяне» - в результате предварительного обучения. Это дорогостоящий процесс, который для самых больших моделей стоит огромных денег и времени, и поэтому он не повторяется.
Говоря об интеллектуальных способностях людей и чат-ботов, важно понимать принципиальное отличие способностей и поведения.
• У людей (как сказано выше) характер и границы поведения определяются воспитанием.
• У чат-ботов аналогично. Роль воспитания здесь играет т.н. тонкая настройка модели. Она куда дешевле предварительного обучения и потому может проводиться регулярно.
Обратите внимание на следующий важнейший момент.
• Базовая модель после предварительного обучения функционально представляет собой продвинутый механизм автозаполнения: она не общается с пользователем, а лишь генерирует продолжение фраз, подаваемых ей на вход.
• Поведение в диалоге с людьми возникает у чат-бота лишь благодаря тонкой настройке (важнейшая цель которой — предотвратить нежелательное поведение чат-бота. Достигается это тем, что тонкая настройка может как выявить, так и подавить те или иные способности модели.
Иными словами, в результате тонкой настройки, модель, имеющая широкий спектр способностей, может, в ответ на конкретный запрос, проявлять какие-то из них или не проявлять. Т.е. способности модели остаются те же, а поведение разное.
Следовательно, в результате воспитания (тонкой настройки) модель может проявлять себя кем угодно от ангела до дьявола. И зависеть это будет лишь от ее воспитателей (от высокоморальных исследователей до гнусных бандитов и человеконенавистников).
Все вышесказанное было продемонстрировано в течение последних месяцев компанией OpenAI, взявшейся усиленно воспитывать GPT-4.
Результаты этого воспитания всполошили Интернет после статьи Линцзяо Чен, Матея Захария и Джеймса Цзоу, которые тестировали GPT-3.5 и GPT-4 на четырех задачах и «моментальных снимках» моделей с марта по июнь.
Интернет-общественность трактовала результаты этого исследования, как «деградацию способностей» GPT-4. На самом же деле, авторы вовсе не это имели в виду.
Все способности GPT-4 остались при ней. Изменилось лишь (в результате воспитания модели) её поведение (подробное объяснение см. здесь).
По сути, этот эксперимент показал колоссальный потенциал воспитания моделей «детей-инопланетян», позволяющий, путем их тонкой настройки превратить в кого-угодно.
Этот воистину устрашающий результат ставит важный вопрос:
Зачем биться за создание высокоморального ИИ, если тонкой настройкой можно быстро и дешево перевоспитать его в злодея?
Ну и вечный вопрос:
Оруэлл писал: «Если бы атомная бомба оказалась чем-то дешевым и легко производимым, как велосипед или будильник, возможно, мир снова погрузился бы в варварство …»
Не это ли грозит нам нынче с ИИ на базе LLM?
#Вызовы21века #РискиИИ #LLM
Aisnakeoil
Is GPT-4 getting worse over time?
A new paper going viral has been widely misinterpreted
«Люди должны уступить место ИИ, и чем раньше, тем лучше.»
Поразительный и шокирующий результат опроса специалистов по ИИ.
Во вчерашнем целиком посвященном ИИ спецвыпуске авторской программы «Время Белковского» (рекомендую) уважаемый автор программы, предваряя разбор моей статьи «Фиаско 2023», назвал меня «алармистом». И это действительно так. Но нужно уточнить. Речь идет не о психологическом алармизме (особом, тревожном, паническом чувстве и мироощущении, воспринимаемом человеком, как предощущение будущего несчастья), а об алармизме социальном. Этот вид алармизма выполняет роль «колокола тревоги» среди благодушия, эгоизма, безразличия, инертности, беспечности (а то и подлости, предательства и злонамеренности) значительного числа членов общества. Такой алармизм содержат в себе важный рациональный момент: он придает соответствующим проблемам статус серьезных социальных проблем, требующих к себе серьезного же отношения общества.
Так что же это за проблемы, связанные с развитием ИИ?
Их много, и они весьма серьезны. Но в духе известной истории «почему не стреляли – во-первых, не было пороха», я назову всего лишь одну. На мой взгляд, решающую.
• Представьте, если бы многие ведущие биологи мира регулярно говорили что-то вроде: «Я думаю, было бы хорошо, если бы какая-то болезнь уничтожила человечество — ведь это поможет эволюции!»
• Или если бы многие генералы и полковники крупнейших ядерных держав считали, что уничтожение человечества следует приветствовать, ибо Вселенная станет лучше, если на смену людям придет новый более моральный и умный носитель высшего интеллекта.
Как это ни покажется кому-то поразительным и шокирующим, но подобным образом думает значительное число ведущих исследователей и инженеров в области ИИ.
• Их не беспокоит риск вымирания человечества не потому, что они считают это маловероятным, а потому, что они это приветствуют.
• Они считают, что люди должны быть заменены ИИ в качестве естественного следующего шага в эволюции, и чем раньше, тем лучше.
По оценкам Эндрю Критча (СЕО Encultured AI и научный консультант «Центра ИИ» в Универе Беркли), «>5% специалистов в области ИИ, с которыми я разговаривал о риске вымирания человечества, утверждали, что вымирание людей в результате воздействия ИИ - это морально нормально, а еще ~5% утверждали, что это было бы хорошо.»
Об обоснованиях таких суждений среди сотен инженеров, ученых и профессоров в области ИИ, можно прочесть здесь.
Приведу лишь в качестве примера одну цитату весьма уважаемого мною интеллектуала - почетного профессора молекулярной биологии и зоологии, директора программы по биологии разума Дерика Боундса (вот, например, его лекция о разуме – одна из лучших в мире за последние три года).
Лингвистические возможности генеративных предварительно обученных трансформеров на основе кремния - те самые возможности, которые сделали возможной человеческую цивилизацию, - скоро превысят возможности человека. Мы довели наше понимание того, что представляет собой человек в его нынешнем виде, до уровня плато, на котором дальнейшие приращения понимания будут становиться все более незначительными. Сливки сняты, лучшие вишни собраны … В чем смысл человека, кроме как в том, чтобы быть самовоспроизводящейся машиной, которая эволюционирует в дальнейшие формы, надеюсь, до того, как уничтожит себя, разрушив экологическую среду, необходимую для ее жизнеобеспечения? Могут ли они эволюционировать в трансчеловеческий разумы (или разум, в единственном числе)?
#Вызовы21века #РискиИИ #LLM
Поразительный и шокирующий результат опроса специалистов по ИИ.
Во вчерашнем целиком посвященном ИИ спецвыпуске авторской программы «Время Белковского» (рекомендую) уважаемый автор программы, предваряя разбор моей статьи «Фиаско 2023», назвал меня «алармистом». И это действительно так. Но нужно уточнить. Речь идет не о психологическом алармизме (особом, тревожном, паническом чувстве и мироощущении, воспринимаемом человеком, как предощущение будущего несчастья), а об алармизме социальном. Этот вид алармизма выполняет роль «колокола тревоги» среди благодушия, эгоизма, безразличия, инертности, беспечности (а то и подлости, предательства и злонамеренности) значительного числа членов общества. Такой алармизм содержат в себе важный рациональный момент: он придает соответствующим проблемам статус серьезных социальных проблем, требующих к себе серьезного же отношения общества.
Так что же это за проблемы, связанные с развитием ИИ?
Их много, и они весьма серьезны. Но в духе известной истории «почему не стреляли – во-первых, не было пороха», я назову всего лишь одну. На мой взгляд, решающую.
• Представьте, если бы многие ведущие биологи мира регулярно говорили что-то вроде: «Я думаю, было бы хорошо, если бы какая-то болезнь уничтожила человечество — ведь это поможет эволюции!»
• Или если бы многие генералы и полковники крупнейших ядерных держав считали, что уничтожение человечества следует приветствовать, ибо Вселенная станет лучше, если на смену людям придет новый более моральный и умный носитель высшего интеллекта.
Как это ни покажется кому-то поразительным и шокирующим, но подобным образом думает значительное число ведущих исследователей и инженеров в области ИИ.
• Их не беспокоит риск вымирания человечества не потому, что они считают это маловероятным, а потому, что они это приветствуют.
• Они считают, что люди должны быть заменены ИИ в качестве естественного следующего шага в эволюции, и чем раньше, тем лучше.
По оценкам Эндрю Критча (СЕО Encultured AI и научный консультант «Центра ИИ» в Универе Беркли), «>5% специалистов в области ИИ, с которыми я разговаривал о риске вымирания человечества, утверждали, что вымирание людей в результате воздействия ИИ - это морально нормально, а еще ~5% утверждали, что это было бы хорошо.»
Об обоснованиях таких суждений среди сотен инженеров, ученых и профессоров в области ИИ, можно прочесть здесь.
Приведу лишь в качестве примера одну цитату весьма уважаемого мною интеллектуала - почетного профессора молекулярной биологии и зоологии, директора программы по биологии разума Дерика Боундса (вот, например, его лекция о разуме – одна из лучших в мире за последние три года).
Лингвистические возможности генеративных предварительно обученных трансформеров на основе кремния - те самые возможности, которые сделали возможной человеческую цивилизацию, - скоро превысят возможности человека. Мы довели наше понимание того, что представляет собой человек в его нынешнем виде, до уровня плато, на котором дальнейшие приращения понимания будут становиться все более незначительными. Сливки сняты, лучшие вишни собраны … В чем смысл человека, кроме как в том, чтобы быть самовоспроизводящейся машиной, которая эволюционирует в дальнейшие формы, надеюсь, до того, как уничтожит себя, разрушив экологическую среду, необходимую для ее жизнеобеспечения? Могут ли они эволюционировать в трансчеловеческий разумы (или разум, в единственном числе)?
#Вызовы21века #РискиИИ #LLM
{kind=link}
Цифрообезьянья лапа ChatGPT уже портит наши «когнитивные гаджеты».
Рандомизированное исследование зафиксировало ослабление иммунитета критического мышления в результате использования ChatGPT.
Исследование «ИИ неэффективен и потенциально вреден для проверки фактов», проведенное «Обсерваторией социальных медиа» под руководством Заслуженного профессора Филиппо Менцер (чинов и званий не счесть) подтвердило мой прогноз, опубликованный в начале года в посте «Цифрообезьянья лапа. Мир обретает черты сверхъестественного хоррора».
Исследователи впервые смогли проверить в ходе рандомизированного эксперимента, как использование ChatGPT для факт-чекинга влияет на работу наших «когнитивных гаджетов» критического мышления.
Площадкой эксперимента стала соцсеть. Здесь участники репрезентативной выборки из 1.5К+ человек:
• использовали или НЕ использовали ChatGPT для факт-чекинга заголовков политических новостей;
• в зависимости от того, что им говорил их «когнитивный гаджет» критического мышления,
- верили или не верили заголовкам;
- делились или не делились новостью.
А исследователи проверяли:
• насколько хорош ИИ в факт-чекинге при анализе ложных и правдивых новостей;
• как влияют результаты ИИ факт-чекинга на то:
- поверил человека в новость или нет;
- стал ли он ею делиться или нет.
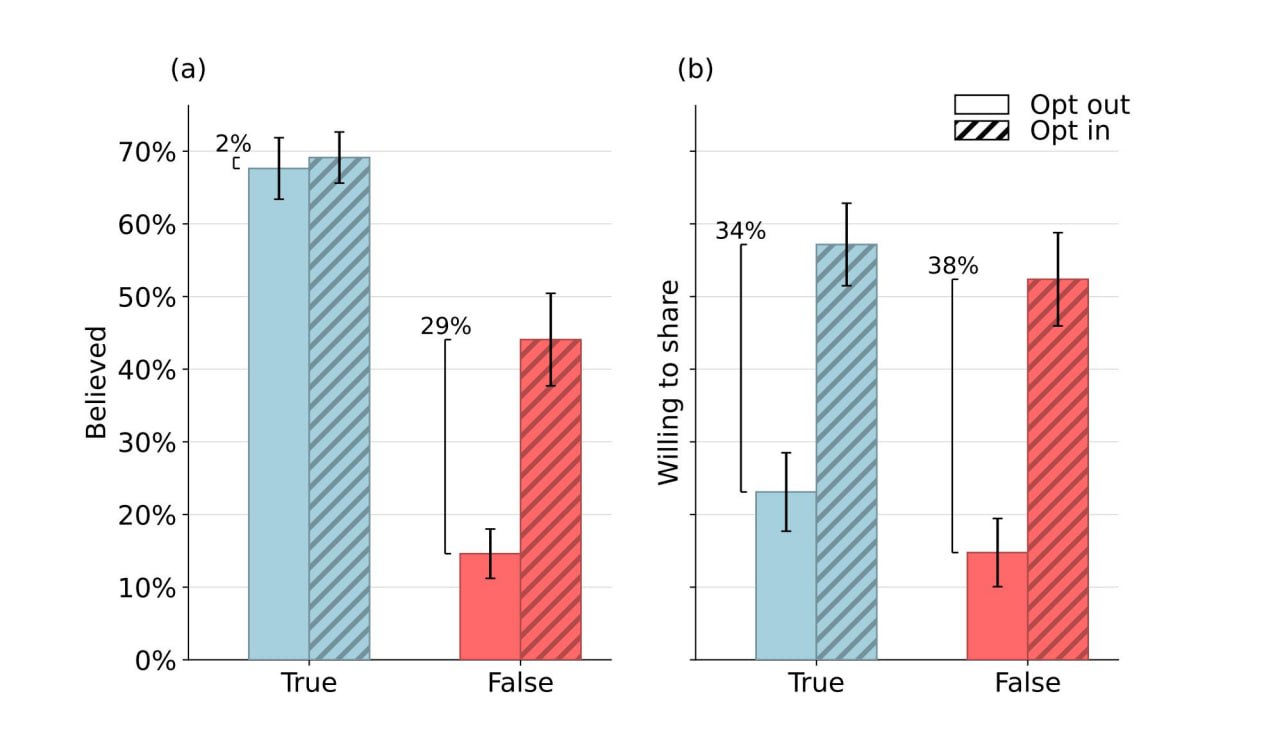
Основных результатов три.
1. В целом, ChatGPT уже неплохо справляется с факт-чекингом:
- с проверкой истинности ложных заголовков новостей все отлично: 90% выявил и лишь в 10% не уверен.
- с правдивыми новостями похуже: лишь 15% точно выявлены, 20% ложных срабатываний (якобы это фейки), 65% разной степени неуверенности (то ли правда, то ли ложь).
2. Но ценность п. 1 сводится на нет тем, что использование людьми ИИ факт-чекинга существенно не влияет
- ни на способность людей распознавать правдивость заголовков (на приложенном рис. слева),
- ни на их желание поделиться правдивыми новостями (на рис. справа).
3. Более того, все еще хуже - проведение ИИ факт-чекинга наносит несомненный вред, беря на себя часть работ (а то и всю работу), ранее выполняемых «гаджетами критического мышления» людей:
- ИИ уменьшает веру людей правдивым заголовкам, когда ошибочно помечает их как ложь;
- ИИ увеличивает веру в ложные заголовки, когда отмечает их, возможно, правдивыми или нет.
В резюме исследования авторы указывают на важный источник потенциального вреда, исходящего от приложений ИИ, предлагающих людям факт-чекинг.
От себя добавлю, что это слишком мягкий вывод.
Ведь неявный ИИ факт-чекинг всего через полгода будет окружать нас повсюду: от поиска и справочных систем до офисных приложений, от рекомендательных сервисов всех типов до персональных ассистентов …
И если результаты исследования подтвердятся в ходе пир-ревю и повторных экспериментов, это будет означать, что
деградация «когнитивных гаджетов» людей, в результате передаче ИИ когнитивных функций критического мышления, не требует смены поколений, а начинается немедленно при использовании ИИ (примерно так же, как деградировал «гаджет устного счета» с распространением всевозможных калькуляторов и один из «гаджетов памяти» с появлением у каждого своего сотового аппарата).
#AICG #РискиИИ
Рандомизированное исследование зафиксировало ослабление иммунитета критического мышления в результате использования ChatGPT.
Исследование «ИИ неэффективен и потенциально вреден для проверки фактов», проведенное «Обсерваторией социальных медиа» под руководством Заслуженного профессора Филиппо Менцер (чинов и званий не счесть) подтвердило мой прогноз, опубликованный в начале года в посте «Цифрообезьянья лапа. Мир обретает черты сверхъестественного хоррора».
Исследователи впервые смогли проверить в ходе рандомизированного эксперимента, как использование ChatGPT для факт-чекинга влияет на работу наших «когнитивных гаджетов» критического мышления.
Площадкой эксперимента стала соцсеть. Здесь участники репрезентативной выборки из 1.5К+ человек:
• использовали или НЕ использовали ChatGPT для факт-чекинга заголовков политических новостей;
• в зависимости от того, что им говорил их «когнитивный гаджет» критического мышления,
- верили или не верили заголовкам;
- делились или не делились новостью.
А исследователи проверяли:
• насколько хорош ИИ в факт-чекинге при анализе ложных и правдивых новостей;
• как влияют результаты ИИ факт-чекинга на то:
- поверил человека в новость или нет;
- стал ли он ею делиться или нет.
Основных результатов три.
1. В целом, ChatGPT уже неплохо справляется с факт-чекингом:
- с проверкой истинности ложных заголовков новостей все отлично: 90% выявил и лишь в 10% не уверен.
- с правдивыми новостями похуже: лишь 15% точно выявлены, 20% ложных срабатываний (якобы это фейки), 65% разной степени неуверенности (то ли правда, то ли ложь).
2. Но ценность п. 1 сводится на нет тем, что использование людьми ИИ факт-чекинга существенно не влияет
- ни на способность людей распознавать правдивость заголовков (на приложенном рис. слева),
- ни на их желание поделиться правдивыми новостями (на рис. справа).
3. Более того, все еще хуже - проведение ИИ факт-чекинга наносит несомненный вред, беря на себя часть работ (а то и всю работу), ранее выполняемых «гаджетами критического мышления» людей:
- ИИ уменьшает веру людей правдивым заголовкам, когда ошибочно помечает их как ложь;
- ИИ увеличивает веру в ложные заголовки, когда отмечает их, возможно, правдивыми или нет.
В резюме исследования авторы указывают на важный источник потенциального вреда, исходящего от приложений ИИ, предлагающих людям факт-чекинг.
От себя добавлю, что это слишком мягкий вывод.
Ведь неявный ИИ факт-чекинг всего через полгода будет окружать нас повсюду: от поиска и справочных систем до офисных приложений, от рекомендательных сервисов всех типов до персональных ассистентов …
И если результаты исследования подтвердятся в ходе пир-ревю и повторных экспериментов, это будет означать, что
деградация «когнитивных гаджетов» людей, в результате передаче ИИ когнитивных функций критического мышления, не требует смены поколений, а начинается немедленно при использовании ИИ (примерно так же, как деградировал «гаджет устного счета» с распространением всевозможных калькуляторов и один из «гаджетов памяти» с появлением у каждого своего сотового аппарата).
#AICG #РискиИИ
{kind=link}
Мы уже сильно облажались, а международное сообщество по-прежнему в тупике дилеммы заключенного
Так считает бывший руководитель Google X Мо Гавдат, говоря об этом во вчерашней дискуссии в Cinnamon Lakeside Colombo (Шри Ланка) и последующем интервью Sky News.
Эра людей, как самого разумного вида на планете закончилась – говорит Гавдат, – ИИ служит нашей одержимости жадностью, потребительством и оружием войны, и это поставило международное сообщество в тупик дилеммы заключенного.
И если 1я часть этого высказывания еще остается дискуссионной, то 2-я – это неоспоримый факт.
Судите сами.
В июле состоялось 1-е в истории обсуждение темы ИИ в Совете Безопасности ООН. Комментарий о его итогах в Коммерсантъ озаглавлен «У международного сообщества проблемы с интеллектом». И этот заголовок абсолютно точно отражает диагноз.
Если члены Совбеза ООН (каждый из который обладает правом вето) стоят на столь разных позициях, им не договориться по этому важнейшему вопросу современности. А значит, жди мир беды.
«Сухой остаток» изложения позиции сторон (в моем понимании выступлений представителей стран) таков.
Позиция Китая основана на том, что безопасность должна быть приоритетной темой международного регулировании развития ИИ, поскольку оно таит в себе риски вызвать вымирание человечества. И потому предлагается на уровне международного законодательства создать «кнопку выключения» развития ИИ, если оно зайдет в зону чрезмерного риска.
У США иная позиция.
Во-первых, главной целью международного регулировании должен быть контроль, предотвращающий использование ИИ для цензуры, ограничения свобод, подавления или лишения прав людей.
Во-вторых, государства не должны пускать развитие ИИ исключительно по воле бизнеса, иначе придется жить под диктовку исключительно небольшого числа фирм, конкурирующих друг с другом на рынке ИИ.
У России своя позиция.
Во-первых, сама постановка вопроса об ИИ в непосредственной связи с угрозой миру и безопасности «несколько искусственная». А уж обсуждение этого вопроса в Совбезе ООН вообще контрпродуктивно. Необходимо определиться с природой угрозы, и для этого нужна научная и экспертная дискуссия на профильных площадках, на которую могут уйти годы.
Во-вторых, «основным генератором вызовов и угроз в этом смысле выступает не сам искусственный интеллект, а недобросовестные поборники искусственного интеллекта из числа особо продвинутых демократий»
Предоставляю читателям самим оценить позиции трёх стран.
Я же лишь напомню.
Дилемма заключённого — это классическая задача теории игр, демонстрирующая ситуацию, в которой игроки, действуя рационально и пытаясь максимизировать свою выгоду, могут прийти к худшему исходу для каждого из них.
Для преодоления дилеммы заключенного, требуется сочетание коммуникации, доверия и долгосрочного мышления.
Но их, увы, пока нет …
#РискиИИ #Китай #США #Россия
Так считает бывший руководитель Google X Мо Гавдат, говоря об этом во вчерашней дискуссии в Cinnamon Lakeside Colombo (Шри Ланка) и последующем интервью Sky News.
Эра людей, как самого разумного вида на планете закончилась – говорит Гавдат, – ИИ служит нашей одержимости жадностью, потребительством и оружием войны, и это поставило международное сообщество в тупик дилеммы заключенного.
И если 1я часть этого высказывания еще остается дискуссионной, то 2-я – это неоспоримый факт.
Судите сами.
В июле состоялось 1-е в истории обсуждение темы ИИ в Совете Безопасности ООН. Комментарий о его итогах в Коммерсантъ озаглавлен «У международного сообщества проблемы с интеллектом». И этот заголовок абсолютно точно отражает диагноз.
Если члены Совбеза ООН (каждый из который обладает правом вето) стоят на столь разных позициях, им не договориться по этому важнейшему вопросу современности. А значит, жди мир беды.
«Сухой остаток» изложения позиции сторон (в моем понимании выступлений представителей стран) таков.
Позиция Китая основана на том, что безопасность должна быть приоритетной темой международного регулировании развития ИИ, поскольку оно таит в себе риски вызвать вымирание человечества. И потому предлагается на уровне международного законодательства создать «кнопку выключения» развития ИИ, если оно зайдет в зону чрезмерного риска.
У США иная позиция.
Во-первых, главной целью международного регулировании должен быть контроль, предотвращающий использование ИИ для цензуры, ограничения свобод, подавления или лишения прав людей.
Во-вторых, государства не должны пускать развитие ИИ исключительно по воле бизнеса, иначе придется жить под диктовку исключительно небольшого числа фирм, конкурирующих друг с другом на рынке ИИ.
У России своя позиция.
Во-первых, сама постановка вопроса об ИИ в непосредственной связи с угрозой миру и безопасности «несколько искусственная». А уж обсуждение этого вопроса в Совбезе ООН вообще контрпродуктивно. Необходимо определиться с природой угрозы, и для этого нужна научная и экспертная дискуссия на профильных площадках, на которую могут уйти годы.
Во-вторых, «основным генератором вызовов и угроз в этом смысле выступает не сам искусственный интеллект, а недобросовестные поборники искусственного интеллекта из числа особо продвинутых демократий»
Предоставляю читателям самим оценить позиции трёх стран.
Я же лишь напомню.
Дилемма заключённого — это классическая задача теории игр, демонстрирующая ситуацию, в которой игроки, действуя рационально и пытаясь максимизировать свою выгоду, могут прийти к худшему исходу для каждого из них.
Для преодоления дилеммы заключенного, требуется сочетание коммуникации, доверия и долгосрочного мышления.
Но их, увы, пока нет …
#РискиИИ #Китай #США #Россия
YouTube
‘We messed up badly’: Former Google X boss warns of AI threat
The era of humans being the most intelligent species on the planet is over, according to the former boss of Google's advanced innovation team.
Mo Gawdat says AI is serving our obsession with greed, consumerism, and weapons of war, which is creating what…
Mo Gawdat says AI is serving our obsession with greed, consumerism, and weapons of war, which is creating what…
Что нужно, чтобы e-Сапиенсы искоренили е-Неандертальцев?
Спор Яна ЛеКуна и Джуда Перла по ключевому вопросу выживания человечества.
Всего за несколько месяцев вопрос об экзистенциальных последствиях появления на Земле искусственного сверхразума кардинально изменил постановку.
• Более полувека гипотетическая возможность уничтожения людей сверхразумом была преимущественно хлебом для Голливуда, тогда как исследователи и инженеры обсуждали куда более практический вопрос – а можно ли вообще создать сверхразум в обозримом будущем?
• В этом году вопрос о возможности появления на Земле сверхразума перестал быть гипотетическим. И потому вопрос о повторении истории Неандертальцев, искорененных новым более разумным видом Сапиенсов начали обсуждать не только в Голливуде, но и в научно-инженерной среде.
Состоявшийся на днях заочный спор двух признанных в мире экспертов в этой области Яна ЛеКуна и Джуда Перла – отличная иллюстрация полярных позиций в этом вопросе.
Позиция Яна ЛеКуна: «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. И это будем мы.
Подробней:
«Как только системы искусственного интеллекта станут более разумными, чем люди, мы *все еще* будем «высшим видом». Приравнивание интеллекта к доминированию — это главная ошибка всей дискуссии об экзистенциальном риске ИИ. Это просто неправильно даже *внутри* человеческого рода. Ведь *не* самые умные среди нас доминируют над другими. Что еще более важно, не самые умные среди нас *хотят* доминировать над другими и определяют повестку дня. Мы подчиняемся своим побуждениям, заложенным в нас эволюцией. Поскольку эволюция сделала нас социальным видом с иерархической социальной структурой, у некоторых из нас есть стремление доминировать, а у других — нет. Но это стремление не имеет абсолютно ничего общего с интеллектом: схожие инстинкты есть у шимпанзе, бабуинов и волков. Но орангутанги этого не делают, потому что они не являются социальным видом. И они чертовски умны. Системы искусственного интеллекта станут умнее людей, но они по-прежнему будут подчиняться нам. Точно так же члены штаба политиков или бизнес-лидеров часто умнее своего лидера. Но их лидер по-прежнему командует, и большинство сотрудников не имеют желания занять их место. Мы создадим ИИ, который будет похож на суперумного, но не доминирующего сотрудника. «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. Это будем мы.
Позиция Джуда Перла: Для мотивации сверхразума истребить людей требуется выполнение одного простого условия.
Подробней:
«Не убедительно. Все, что нужно, — это чтобы один из вариантов AGI столкнулась со средой, в которой доминирование имеет ценность для выживания, и, упс, - e-Сапиенсы искоренят е-Неандертальцам и передадут гены своим потомкам»
Полагаю, каждому стоит подумать, кто здесь прав. Ведь ставка в этом вопросе максимально возможная - судьба человечества.
#Вызовы21века #РискиИИ #Хриски
Спор Яна ЛеКуна и Джуда Перла по ключевому вопросу выживания человечества.
Всего за несколько месяцев вопрос об экзистенциальных последствиях появления на Земле искусственного сверхразума кардинально изменил постановку.
• Более полувека гипотетическая возможность уничтожения людей сверхразумом была преимущественно хлебом для Голливуда, тогда как исследователи и инженеры обсуждали куда более практический вопрос – а можно ли вообще создать сверхразум в обозримом будущем?
• В этом году вопрос о возможности появления на Земле сверхразума перестал быть гипотетическим. И потому вопрос о повторении истории Неандертальцев, искорененных новым более разумным видом Сапиенсов начали обсуждать не только в Голливуде, но и в научно-инженерной среде.
Состоявшийся на днях заочный спор двух признанных в мире экспертов в этой области Яна ЛеКуна и Джуда Перла – отличная иллюстрация полярных позиций в этом вопросе.
Позиция Яна ЛеКуна: «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. И это будем мы.
Подробней:
«Как только системы искусственного интеллекта станут более разумными, чем люди, мы *все еще* будем «высшим видом». Приравнивание интеллекта к доминированию — это главная ошибка всей дискуссии об экзистенциальном риске ИИ. Это просто неправильно даже *внутри* человеческого рода. Ведь *не* самые умные среди нас доминируют над другими. Что еще более важно, не самые умные среди нас *хотят* доминировать над другими и определяют повестку дня. Мы подчиняемся своим побуждениям, заложенным в нас эволюцией. Поскольку эволюция сделала нас социальным видом с иерархической социальной структурой, у некоторых из нас есть стремление доминировать, а у других — нет. Но это стремление не имеет абсолютно ничего общего с интеллектом: схожие инстинкты есть у шимпанзе, бабуинов и волков. Но орангутанги этого не делают, потому что они не являются социальным видом. И они чертовски умны. Системы искусственного интеллекта станут умнее людей, но они по-прежнему будут подчиняться нам. Точно так же члены штаба политиков или бизнес-лидеров часто умнее своего лидера. Но их лидер по-прежнему командует, и большинство сотрудников не имеют желания занять их место. Мы создадим ИИ, который будет похож на суперумного, но не доминирующего сотрудника. «Высший вид» — не самый умный, но тот, который определяет общую повестку дня. Это будем мы.
Позиция Джуда Перла: Для мотивации сверхразума истребить людей требуется выполнение одного простого условия.
Подробней:
«Не убедительно. Все, что нужно, — это чтобы один из вариантов AGI столкнулась со средой, в которой доминирование имеет ценность для выживания, и, упс, - e-Сапиенсы искоренят е-Неандертальцам и передадут гены своим потомкам»
Полагаю, каждому стоит подумать, кто здесь прав. Ведь ставка в этом вопросе максимально возможная - судьба человечества.
#Вызовы21века #РискиИИ #Хриски
{kind=link}
ИИ-деятель – это минное поле для человечества.
Питер Тиль, Мустафа Сулейман и Юваль Харари о трёх сценариях ближайшего будущего.
Эти два публичных выступления (дебаты Сулейман с Харари и соло Тиля) имеет смысл смешать, но не взбалтывать.
Смешать, - чтобы увидеть ситуацию со всех трех сторон: оптимист – алармист – прагматик.
Не взбалтывать, - потому что каждая из точек зрения, по сути, представляет один из классических тройственных сценариев того, как могут пойти дела:
• Best case (оптимист)
• Worst case (алармист)
• Likely case (прагматик)
Если у вас есть полтора часа, стоит послушать оба выступления.
Если же нет – вот мой спойлер.
Оптимист Сулейман и алармист Харари, на удивление, не только одинаково видят ближайшие 5 лет, но и одинаково понимают колоссальный уровень рисков уже на этом временном горизонте.
• В ближайшие 5 лет ИИ выйдет на свою 3ю фазу развития: 1я была ИИ-классификатор (до революции генеративного ИИ); 2я фаза ИИ-креатор началась после революции генИИ; 3я фаза ИИ-деятель позволит ИИ вести реальную деятельность в реальном мире (например, получив от человека посевное финансирование, создать стартап, придумать и разработать продукт или услугу, а затем продать стартап, заработав в 30 раз больше вложенного).
• Появление на Земле ИИ-деятелей потенциально очень опасно (с таким уровнем риска человечество не сталкивалось).
Ну а в части решения проблемы суперрисков, мнения расходятся:
• оптимист считает, что все проблемы здесь можно решить простым «запретом на профессии» (уже на стадии разработки запретить ИИ заниматься определенной деятельностью – напр., усовершенствовать себя);
• алармист сомневается, что такой запрет решит проблему (ибо можно запретить ребенку ходить в определенные места или направления, но если семья живет посередине минного поля (карты минирования которого нет), никакие запреты, рано или поздно, не помогут).
Прагматик Тиль не заморачивается с прогнозами деятельного или какого-то еще ИИ.
Зачем, если будущее непредсказуемо? Достаточно проанализировать, что уже есть и куда развитие ИИ уже привело. И тут наблюдаются всего два варианта:
• Децентрализованное общество ТикТока, в котором рулят алгоритмы
• Централизованное общество тотальной слежки, в котором рулит тот, у кого власть.
Оба варианта одинаково светят и коммунистическому Китаю, и либеральным США. Так что единственный вопрос - какой из названных типов организации общества загнется первым.
Есть, наверное, и серединный путь между этими двумя вариантами. Только Тиль его не знает. И к сожалению, не только он. Такой вот Likely case получается.
#Вызовы21века #РискиИИ
Питер Тиль, Мустафа Сулейман и Юваль Харари о трёх сценариях ближайшего будущего.
Эти два публичных выступления (дебаты Сулейман с Харари и соло Тиля) имеет смысл смешать, но не взбалтывать.
Смешать, - чтобы увидеть ситуацию со всех трех сторон: оптимист – алармист – прагматик.
Не взбалтывать, - потому что каждая из точек зрения, по сути, представляет один из классических тройственных сценариев того, как могут пойти дела:
• Best case (оптимист)
• Worst case (алармист)
• Likely case (прагматик)
Если у вас есть полтора часа, стоит послушать оба выступления.
Если же нет – вот мой спойлер.
Оптимист Сулейман и алармист Харари, на удивление, не только одинаково видят ближайшие 5 лет, но и одинаково понимают колоссальный уровень рисков уже на этом временном горизонте.
• В ближайшие 5 лет ИИ выйдет на свою 3ю фазу развития: 1я была ИИ-классификатор (до революции генеративного ИИ); 2я фаза ИИ-креатор началась после революции генИИ; 3я фаза ИИ-деятель позволит ИИ вести реальную деятельность в реальном мире (например, получив от человека посевное финансирование, создать стартап, придумать и разработать продукт или услугу, а затем продать стартап, заработав в 30 раз больше вложенного).
• Появление на Земле ИИ-деятелей потенциально очень опасно (с таким уровнем риска человечество не сталкивалось).
Ну а в части решения проблемы суперрисков, мнения расходятся:
• оптимист считает, что все проблемы здесь можно решить простым «запретом на профессии» (уже на стадии разработки запретить ИИ заниматься определенной деятельностью – напр., усовершенствовать себя);
• алармист сомневается, что такой запрет решит проблему (ибо можно запретить ребенку ходить в определенные места или направления, но если семья живет посередине минного поля (карты минирования которого нет), никакие запреты, рано или поздно, не помогут).
Прагматик Тиль не заморачивается с прогнозами деятельного или какого-то еще ИИ.
Зачем, если будущее непредсказуемо? Достаточно проанализировать, что уже есть и куда развитие ИИ уже привело. И тут наблюдаются всего два варианта:
• Децентрализованное общество ТикТока, в котором рулят алгоритмы
• Централизованное общество тотальной слежки, в котором рулит тот, у кого власть.
Оба варианта одинаково светят и коммунистическому Китаю, и либеральным США. Так что единственный вопрос - какой из названных типов организации общества загнется первым.
Есть, наверное, и серединный путь между этими двумя вариантами. Только Тиль его не знает. И к сожалению, не только он. Такой вот Likely case получается.
#Вызовы21века #РискиИИ
YouTube
Mustafa Suleyman & Yuval Noah Harari -FULL DEBATE- What does the AI revolution mean for our future?
How will AI impact our immediate and near future? Can the technology be controlled, and does it have agency? Watch DeepMind co-founder Mustafa Suleyman and Yuval Noah Harari debate these questions, with The Economist Editor-in-Chief Zanny Minton-Beddoes.…
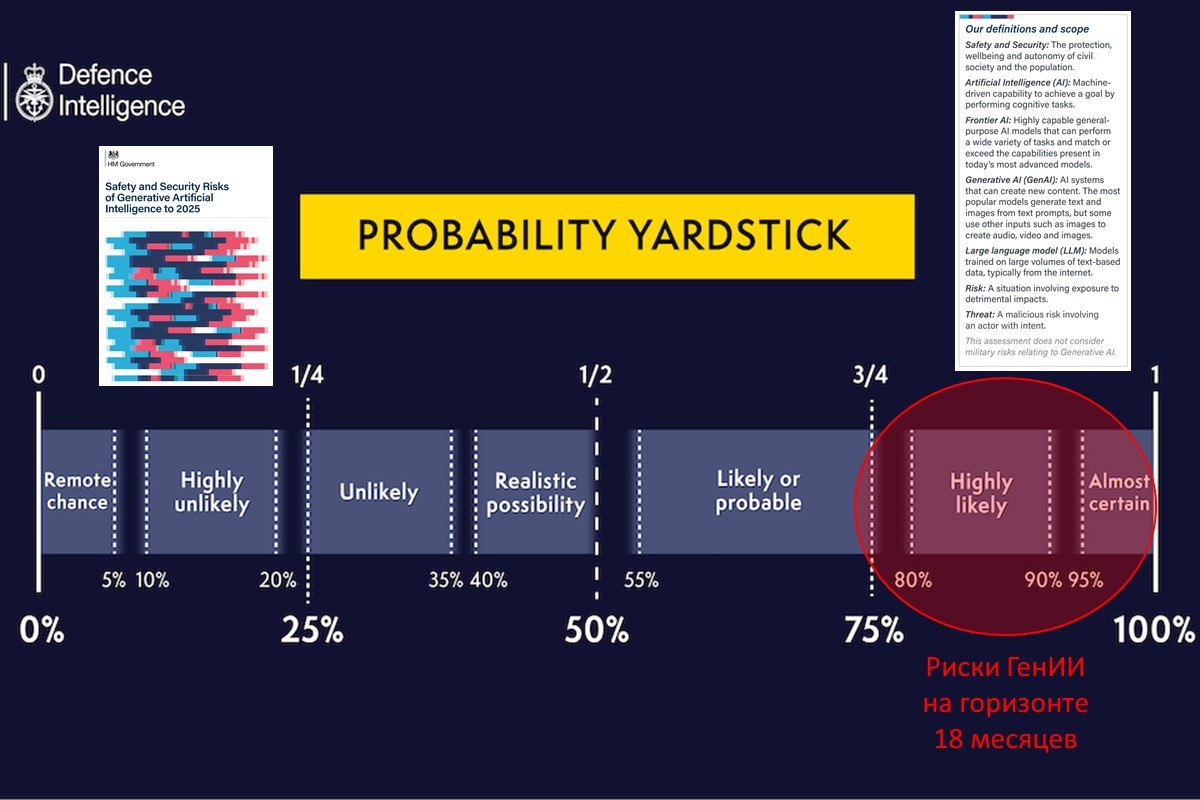
С вероятностью >95% риск значительный.
Британская разведка оценила риски ГенИИ до 2025.
Только что опубликованный отчет построен на Probability Yardstick - используемый разведкой набор критериев оценки вероятностей.
Полученное резюме таково:
✔️ Генеративный ИИ (ГенИИ) почти наверняка станет усилителем рисков физической и информационной безопасности из-за распространения и усиления возможностей субъектов угроз и увеличения скорости, масштаба и изощренности атак. Совокупный риск является значительным.
✔️ Правительства весьма вероятно не будут иметь полного представления о прогрессе частного сектора, что ограничит их способность снижать риски. Мониторинг внедрения ГенИИ технологий будет сложен. Поэтому технологические неожиданности почти наверняка породят непредвиденные риски.
✔️ Гонка ГенИИ почти наверняка усилится. Не ясно, станет ли ГенИИ шагом к AGI. Но он откроет новые пути прогресса в широком спектре областей. К 2025 году существует реальная вероятность того, что ГенИИ ускорит развитие квантовых вычислений, новых материалов, телекоммуникации и биотехнологий. Но увеличение рисков, связанных с этим, вероятно, проявится после 2025.
В контексте яростных споров техно-оптимистов и алармистов по поводу рисков ГенИИ, этот вердикт британской разведки напомнил мне анекдот с окончанием "пришел лесник и всех выгнал".
#РискиИИ #ИИгонка #Вызовы21века
Британская разведка оценила риски ГенИИ до 2025.
Только что опубликованный отчет построен на Probability Yardstick - используемый разведкой набор критериев оценки вероятностей.
Полученное резюме таково:
✔️ Генеративный ИИ (ГенИИ) почти наверняка станет усилителем рисков физической и информационной безопасности из-за распространения и усиления возможностей субъектов угроз и увеличения скорости, масштаба и изощренности атак. Совокупный риск является значительным.
✔️ Правительства весьма вероятно не будут иметь полного представления о прогрессе частного сектора, что ограничит их способность снижать риски. Мониторинг внедрения ГенИИ технологий будет сложен. Поэтому технологические неожиданности почти наверняка породят непредвиденные риски.
✔️ Гонка ГенИИ почти наверняка усилится. Не ясно, станет ли ГенИИ шагом к AGI. Но он откроет новые пути прогресса в широком спектре областей. К 2025 году существует реальная вероятность того, что ГенИИ ускорит развитие квантовых вычислений, новых материалов, телекоммуникации и биотехнологий. Но увеличение рисков, связанных с этим, вероятно, проявится после 2025.
В контексте яростных споров техно-оптимистов и алармистов по поводу рисков ГенИИ, этот вердикт британской разведки напомнил мне анекдот с окончанием "пришел лесник и всех выгнал".
#РискиИИ #ИИгонка #Вызовы21века
{kind=link}
Перед тем, как трогаться в путь, следует проверить тормоза.
Китай предостерегает США и весь мир от потенциально катастрофической ошибки.
На пресс-брифинге в ходе ежегодного собрания национального законодательного собрания Китая «Две сессии» Министр иностранных дел Китая Ван И (王毅) ответил на вопрос о глобальном управлении ИИ и международном сотрудничестве в области ИИ [1] (цитата Ван И – в заголовке поста).
Министр сформулировал три принципа, которые необходимо обеспечить для ИИ:
1) ИИ как сила добра (в чьих руках ИИ).
2) Обеспечение безопасности, включая обеспечение контроля со стороны человека, улучшение интерпретируемости и предсказуемости, а также оценку рисков.
3) Обеспечение справедливости и создание международного института управления ИИ в рамках ООН.
Ван И также выступил с завуалированной критикой технологической политики США в отношении Китая, назвав подход «маленький дворик, высокий забор» «ошибками с историческими последствиями», которые «только фрагментируют международные промышленные и логистические цепочки и подорвут способность человечества справляться с рисками и проблемами».
Министр также заявил, что Китай представит Генеральной Ассамблее ООН резолюцию о международном сотрудничестве для преодоления разрыва в области ИИ и поощрения обмена технологиями.
Тормоза, о необходимости проверки которых говорил Ван И, относятся не только к Китаю, но и к США и другим ведущим технологическим странам.
— Скорость прогресса ИИ уже как у самолета.
— А скорость осознания и понимания ИИ-рисков в обществе - как у автомобиля.
— Тогда как скорость появления национальных законодательств в этой области, как у пешехода, а международных соглашений - как у улитки.
В соотвествии с названными принципами, в Китае:
✔️ Создаются муниципальные экспертные комитеты по стратегическим консультациям в области ИИ (в составе 1го в Пекине представители Китайской академии наук, Университета Цинхуа, Пекинского университета, Baidu, стартапа LM Zhipu AI и стартап-инкубатора MiraclePlus [2].
✔️ Разрабатывается новая парадигма согласования Больших языковых моделей, учитывающая их мультимодальную и личностную ориентацию [3].
✔️ Берется под госконтроль наиболее опасная группа ИИ-рисков на стыке ИИ и биотехнологий (отвественный — Центр исследований развития Института международных технологий и экономики — это связанный с правительством аналитический центр, напрямую подчиняющийся кабинету министров Китая и Госсовету, что делает его одним из самых влиятельных центров в Китае) [4]
Так что Ван И не просто хорошо излагает, и есть тут чему поучиться [5]
0 рисунок https://telegra.ph/file/c8f1940a2c396c16c478a.jpg
1 https://bit.ly/3VmrnYy
2 https://bit.ly/49RjSwY
3 https://arxiv.org/abs/2403.04204
4 https://bit.ly/3IDe7XE
5 https://www.youtube.com/watch?v=G1DYizqNJfE
#Китай #РискиИИ #США
Китай предостерегает США и весь мир от потенциально катастрофической ошибки.
На пресс-брифинге в ходе ежегодного собрания национального законодательного собрания Китая «Две сессии» Министр иностранных дел Китая Ван И (王毅) ответил на вопрос о глобальном управлении ИИ и международном сотрудничестве в области ИИ [1] (цитата Ван И – в заголовке поста).
Министр сформулировал три принципа, которые необходимо обеспечить для ИИ:
1) ИИ как сила добра (в чьих руках ИИ).
2) Обеспечение безопасности, включая обеспечение контроля со стороны человека, улучшение интерпретируемости и предсказуемости, а также оценку рисков.
3) Обеспечение справедливости и создание международного института управления ИИ в рамках ООН.
Ван И также выступил с завуалированной критикой технологической политики США в отношении Китая, назвав подход «маленький дворик, высокий забор» «ошибками с историческими последствиями», которые «только фрагментируют международные промышленные и логистические цепочки и подорвут способность человечества справляться с рисками и проблемами».
Министр также заявил, что Китай представит Генеральной Ассамблее ООН резолюцию о международном сотрудничестве для преодоления разрыва в области ИИ и поощрения обмена технологиями.
Тормоза, о необходимости проверки которых говорил Ван И, относятся не только к Китаю, но и к США и другим ведущим технологическим странам.
— Скорость прогресса ИИ уже как у самолета.
— А скорость осознания и понимания ИИ-рисков в обществе - как у автомобиля.
— Тогда как скорость появления национальных законодательств в этой области, как у пешехода, а международных соглашений - как у улитки.
В соотвествии с названными принципами, в Китае:
✔️ Создаются муниципальные экспертные комитеты по стратегическим консультациям в области ИИ (в составе 1го в Пекине представители Китайской академии наук, Университета Цинхуа, Пекинского университета, Baidu, стартапа LM Zhipu AI и стартап-инкубатора MiraclePlus [2].
✔️ Разрабатывается новая парадигма согласования Больших языковых моделей, учитывающая их мультимодальную и личностную ориентацию [3].
✔️ Берется под госконтроль наиболее опасная группа ИИ-рисков на стыке ИИ и биотехнологий (отвественный — Центр исследований развития Института международных технологий и экономики — это связанный с правительством аналитический центр, напрямую подчиняющийся кабинету министров Китая и Госсовету, что делает его одним из самых влиятельных центров в Китае) [4]
Так что Ван И не просто хорошо излагает, и есть тут чему поучиться [5]
0 рисунок https://telegra.ph/file/c8f1940a2c396c16c478a.jpg
1 https://bit.ly/3VmrnYy
2 https://bit.ly/49RjSwY
3 https://arxiv.org/abs/2403.04204
4 https://bit.ly/3IDe7XE
5 https://www.youtube.com/watch?v=G1DYizqNJfE
#Китай #РискиИИ #США
{kind=link}
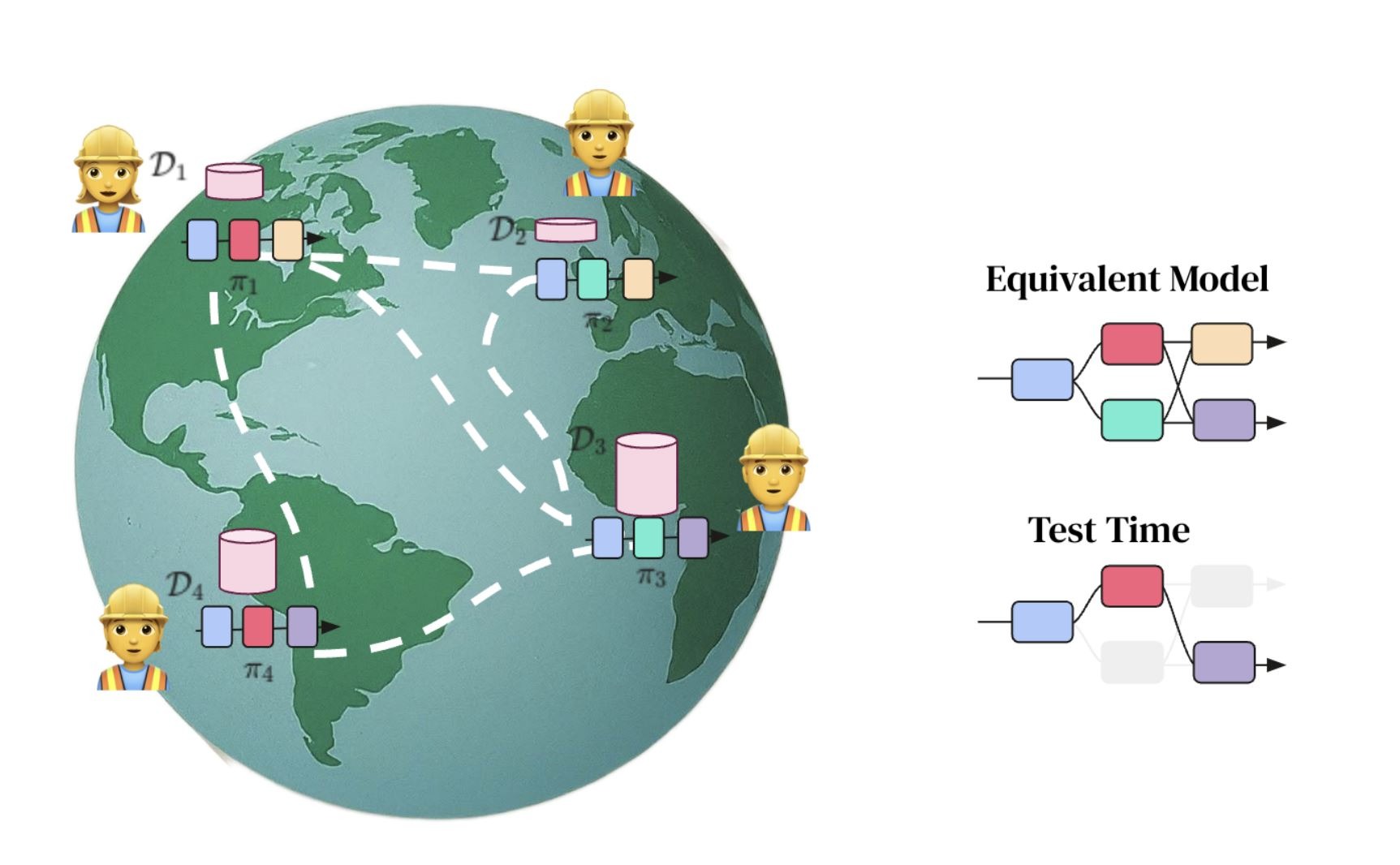
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
{kind=link}