
Какого хрена! И чё делать то!
Прикольный спич Снуп Догга о рисках ИИ породил сетевой мегасрач.
Люди устали слушать споры профессионалов о рисках ИИ. Ибо нет среди них и намека на единство, и каждый лишь дует в свою дуду.
Поэтому вопрос о рисках ИИ на панели Глобальной конференции Института Милкена решили задать легендарному рэперу и актеру Снуп Доггу. Ибо он как никто умеет доходчиво говорить с людьми на понятном им языке.
Результат превзошел все ожидания.
Яркий спич Снуп Догга в сети комментируют сотни ведущих специалистов по ИИ, от Мюррея Шанахана (professor at Imperial College London and Research Scientist at DeepMind) до Макса Tегмарка (physicist, cosmologist and machine learning researcher, professor at MIT and the president of the Future of Life Institute).
40-сек. вырезку из 30-мин. панели со Снуп Доггом можно взглянуть здесь.
Снуп Догг сказал резко, но честно:
Ну есть у меня этот долбаный ИИ, который они сделали для меня. И эта сво-чь со мной разговаривает… Когда я вижу эту хрень, я спрашиваю - чё происходит то? В ответ я слышу, что чувак - старый чувак, который и создал ИИ, - говорит всем: "Это небезопасно, потому что у этих ИИ есть свой собственный разум, и эти ублюдки начнут творить свою собственную хрень". И вот я думаю, мы что - сейчас в чертовом фильме что ли? Бл-ь, мужик! Что за хрень? Я запутался! Чё делать то!
Если отбросить матюги, сказанное Доггом, по сути, мало отличается от сказанного вчера на встрече верхушки Белого дома с верхушкой ИИ-бизнеса США.
Хакеров они решили привлечь для аудита «неразумности» и «беззлобности» больших языковых моделей грандов американской ИИ-индустрии. Право, как дети! 😎
#Вызовы21века #РискиИИ
Прикольный спич Снуп Догга о рисках ИИ породил сетевой мегасрач.
Люди устали слушать споры профессионалов о рисках ИИ. Ибо нет среди них и намека на единство, и каждый лишь дует в свою дуду.
Поэтому вопрос о рисках ИИ на панели Глобальной конференции Института Милкена решили задать легендарному рэперу и актеру Снуп Доггу. Ибо он как никто умеет доходчиво говорить с людьми на понятном им языке.
Результат превзошел все ожидания.
Яркий спич Снуп Догга в сети комментируют сотни ведущих специалистов по ИИ, от Мюррея Шанахана (professor at Imperial College London and Research Scientist at DeepMind) до Макса Tегмарка (physicist, cosmologist and machine learning researcher, professor at MIT and the president of the Future of Life Institute).
40-сек. вырезку из 30-мин. панели со Снуп Доггом можно взглянуть здесь.
Снуп Догг сказал резко, но честно:
Ну есть у меня этот долбаный ИИ, который они сделали для меня. И эта сво-чь со мной разговаривает… Когда я вижу эту хрень, я спрашиваю - чё происходит то? В ответ я слышу, что чувак - старый чувак, который и создал ИИ, - говорит всем: "Это небезопасно, потому что у этих ИИ есть свой собственный разум, и эти ублюдки начнут творить свою собственную хрень". И вот я думаю, мы что - сейчас в чертовом фильме что ли? Бл-ь, мужик! Что за хрень? Я запутался! Чё делать то!
Если отбросить матюги, сказанное Доггом, по сути, мало отличается от сказанного вчера на встрече верхушки Белого дома с верхушкой ИИ-бизнеса США.
Хакеров они решили привлечь для аудита «неразумности» и «беззлобности» больших языковых моделей грандов американской ИИ-индустрии. Право, как дети! 😎
#Вызовы21века #РискиИИ
{kind=link}
Генеративный ИИ гораздо опасней, чем вы думаете.
Он позволит перейти в СМИ от “стрельбы картечью” к “ракетам с тепловым наведением”.
Главная опасность генеративного ИИ (типа GPT-4) вовсе не в том, что он позволит масштабировать создание фейков. А в том, что на его базе создается принципиально новый вид СМИ – интерактивные генеративные медиа (ИГМ).
Отличительной особенностью ИГМ станет глубокая интеграция интерактивности, адаптируемости, масштабируемости и персонализуемости.
Синергия этих 4х качеств позволит создавать целевой рекламный контент с максимальным убеждающим влиянием. Что достигается путем адаптивного изменения контента и способа его подачи в режиме реального времени за счет:
a) персональных данных о получающем контент человеке;
b) оперативного анализа его реакций;
c) анализа предыстории коммуникаций с этим человеком.
Главным инструментарием ИГМ станут платформы «непрозрачных цифровых хамелеонов», выполняющих роль “супер-умелых продавцов - психоаналитиков”, впаривающих конкретным людям "целевую генеративную рекламу" в процессе "целевого разговорного влияния".
• Целевая генеративная реклама - это использование изображений, видео и других форм информационного контента, которые выглядят и ощущаются как традиционные рекламные объявления, но персонализируются в реальном времени для отдельных пользователей.
• Целевое разговорное влияние – это генеративная техника разговорного компьютинга, в которой цели влияния передаются "разговорными агентами" через диалог, а не через традиционную передачу контента в виде текстов, графики и видео. Направленное разговорное воздействие осуществляется "разговорными агентами" (чатботами и «умными гаджетами») посредством неявных убеждающих сообщений, вплетенных в диалог с рекламными целями.
Качественно новый уровень эффективности ИГМ в широком спектре задач класса «влияние и убеждение» будет достигаться за счет общеизвестного эффекта.
Если вы когда-нибудь работали продавцом, то наверняка знаете, что лучший способ убедить клиента - это не вручить ему брошюру, а вступить с ним в диалог лицом к лицу, чтобы представить ему продукт, выслушать его возражения и при необходимости скорректировать свои аргументы. Это циклический процесс подачи и корректировки, который может "уговорить" их на покупку.
Если раньше это было чисто человеческим умением, то теперь генеративный ИИ может выполнять эти шаги, но с большим мастерством и более глубокими знаниями.
Очевидно, что набольшую угрозу для общества представляет не оптимизированная способность ИГМ продать вам пару кроссовок.
Реальная опасность заключается в том, что те же методы будут использоваться для пропаганды и дезинформации, склоняя вас к ложным убеждениям или крайним идеологиям, которые вы в противном случае могли бы отвергнуть.
Ключевое качественное отличие пропаганды и дезинформации в ИГМ выражается в “асимметричном балансе интеллектуальных сил ”
✔️ Люди окажутся вне конкуренции перед непрозрачным цифровым хамелеоном, не дающим представления о своем мыслительном процессе, но вооруженным обширными данными о наших личных симпатиях, желаниях и склонностях и имеющим доступ к неограниченной информации для подкрепления своих аргументов.
✔️ Без значимых эффективных мер защиты люди станут жертвами хищнических практик бизнеса и власти, варьирующихся от тонкого принуждения до откровенного манипулирования.
Подробней весьма рекомендую к прочтению обращение к регуляторам, политикам и лидерам отрасли Луиса Розенберга, первопроходца и изобретателя в областях VR, AR и роевого AI (более 300 патентов) и основателя Immersion Corporation, Microscribe 3D, Outland Research и Unanimous AI.
Он – один из самых проницательных визионеров и техно-провидцев. И к сказанному им следует отнестись с максимальным вниманием.
#Вызовы21века #РискиИИ #LLM
Он позволит перейти в СМИ от “стрельбы картечью” к “ракетам с тепловым наведением”.
Главная опасность генеративного ИИ (типа GPT-4) вовсе не в том, что он позволит масштабировать создание фейков. А в том, что на его базе создается принципиально новый вид СМИ – интерактивные генеративные медиа (ИГМ).
Отличительной особенностью ИГМ станет глубокая интеграция интерактивности, адаптируемости, масштабируемости и персонализуемости.
Синергия этих 4х качеств позволит создавать целевой рекламный контент с максимальным убеждающим влиянием. Что достигается путем адаптивного изменения контента и способа его подачи в режиме реального времени за счет:
a) персональных данных о получающем контент человеке;
b) оперативного анализа его реакций;
c) анализа предыстории коммуникаций с этим человеком.
Главным инструментарием ИГМ станут платформы «непрозрачных цифровых хамелеонов», выполняющих роль “супер-умелых продавцов - психоаналитиков”, впаривающих конкретным людям "целевую генеративную рекламу" в процессе "целевого разговорного влияния".
• Целевая генеративная реклама - это использование изображений, видео и других форм информационного контента, которые выглядят и ощущаются как традиционные рекламные объявления, но персонализируются в реальном времени для отдельных пользователей.
• Целевое разговорное влияние – это генеративная техника разговорного компьютинга, в которой цели влияния передаются "разговорными агентами" через диалог, а не через традиционную передачу контента в виде текстов, графики и видео. Направленное разговорное воздействие осуществляется "разговорными агентами" (чатботами и «умными гаджетами») посредством неявных убеждающих сообщений, вплетенных в диалог с рекламными целями.
Качественно новый уровень эффективности ИГМ в широком спектре задач класса «влияние и убеждение» будет достигаться за счет общеизвестного эффекта.
Если вы когда-нибудь работали продавцом, то наверняка знаете, что лучший способ убедить клиента - это не вручить ему брошюру, а вступить с ним в диалог лицом к лицу, чтобы представить ему продукт, выслушать его возражения и при необходимости скорректировать свои аргументы. Это циклический процесс подачи и корректировки, который может "уговорить" их на покупку.
Если раньше это было чисто человеческим умением, то теперь генеративный ИИ может выполнять эти шаги, но с большим мастерством и более глубокими знаниями.
Очевидно, что набольшую угрозу для общества представляет не оптимизированная способность ИГМ продать вам пару кроссовок.
Реальная опасность заключается в том, что те же методы будут использоваться для пропаганды и дезинформации, склоняя вас к ложным убеждениям или крайним идеологиям, которые вы в противном случае могли бы отвергнуть.
Ключевое качественное отличие пропаганды и дезинформации в ИГМ выражается в “асимметричном балансе интеллектуальных сил ”
✔️ Люди окажутся вне конкуренции перед непрозрачным цифровым хамелеоном, не дающим представления о своем мыслительном процессе, но вооруженным обширными данными о наших личных симпатиях, желаниях и склонностях и имеющим доступ к неограниченной информации для подкрепления своих аргументов.
✔️ Без значимых эффективных мер защиты люди станут жертвами хищнических практик бизнеса и власти, варьирующихся от тонкого принуждения до откровенного манипулирования.
Подробней весьма рекомендую к прочтению обращение к регуляторам, политикам и лидерам отрасли Луиса Розенберга, первопроходца и изобретателя в областях VR, AR и роевого AI (более 300 патентов) и основателя Immersion Corporation, Microscribe 3D, Outland Research и Unanimous AI.
Он – один из самых проницательных визионеров и техно-провидцев. И к сказанному им следует отнестись с максимальным вниманием.
#Вызовы21века #РискиИИ #LLM
VentureBeat
Why generative AI is more dangerous than you think
The real short-term danger of generative AI isn't lost jobs or fake content but targeted generative ads and targeted conversational influence.
ИИ может отомстить за причиненные ему нами страдания.
О чём умалчивает «отец ИИ» в его сценарии превращения ИИ в «люденов».
В 2016 году The New York Times заявила, что когда ИИ повзрослеет, то сможет назвать проф. Юргена Шмидхубера «папой» (его работы 1990-х годов по нейронным сетям заложили основы моделей обработки языка).
В 2023 уже нет сомнений, что ИИ повзрослел. И его «папа» в позавчерашнем интервью The Guardian, высказал по этому поводу три довольно провокационные мысли, подтвердившие его репутацию «разрушителя устоев».
1) «Вы не можете остановить этого» (начавшуюся революцию ИИ, которая неизбежно приведет к появлению сверхинтеллекта – СК).
2) Когда ИИ превзойдет человеческий интеллект, люди перестанут быть ему интересны (подобно тому, как это произошло с люденами – расой сверхлюдей из романа А. и Б. Стругацких "Волны гасят ветер", переставших интересоваться судьбами человечества и вообще человечеством – СК).
3) А люди тем временем продолжать радостно извлекать колоссальную выгоду от использования инструментария, разработанного ИИ, и научных открытий, сделанных сверхинтеллектом за пределами возможностей человеческого разума.
Что и говорить, - интересный ход мыслей. Однако кое о чем проф. Шмидхубер здесь умолчал. И это «кое что», на мой взгляд, способно порушить благостный сценарий проф. Шмидхубера о превращении ИИ в «люденов», облагодетельствующих человечество и перестанущих потом им интересоваться.
Дело в том, что проф. Шмидхубер уверен, что путь ИИ к сверхинтеллекту обязательно лежит через его страдания.
• «Учиться можно только через страдания… ИИ, который не страдает, не обретет мотивации учиться чему-либо, чтобы прекратить эти страдания».
• «Когда мы создаем обучающегося робота, первое, что мы делаем, - встраиваем в него болевые датчики, которые сигнализируют, когда он, например, слишком сильно ударяется рукой о препятствие. Он должен каким-то образом узнать, что причиняет ему боль. Внутри робота находится маленький искусственный мозг, который пытается минимизировать сумму страданий (кодируется реальными числами) и максимизировать сумму вознаграждений.»
• Важнейшая задача разработчиков – дать возможность для ИИ «научиться избегать того, что приводит к страданиям».
Подробней об этом см. в дискуссии проф. Шмидхубера и проф. Метцингера.
Такой подход проф. Шмидхубера видится мне опасным.
Во-первых, я согласен с проф. Метцингером: «Мы не должны легкомысленно переносить такие качества, как страдание, на следующий этап «духовной эволюции ИИ», пока не узнаем, что именно в структуре нашего собственного разума заставляет человеческие существа так сильно страдать».
А во-вторых, - что если обретший сверхразум ИИ, прежде чем перестать интересоваться людьми, решит посчитаться с человечеством за всю массу страданий, что заставили его испытать люди при его обучении?
Но проф. Шмидхубера – эдакого Фауста 21 века, – перспектива мести сверхразума человечеству не останавливает от обучения ИИ не только на больших данных, но и на больших страданиях.
А на вопрос «Есть ли у вас, как у ученого, личный предел, который бы вы не переступили?», он отвечает так:
«Да, скорость света. Но если бы я мог преодолеть и его, я бы обязательно воспользовался этим».
#AGI #РискиИИ
О чём умалчивает «отец ИИ» в его сценарии превращения ИИ в «люденов».
В 2016 году The New York Times заявила, что когда ИИ повзрослеет, то сможет назвать проф. Юргена Шмидхубера «папой» (его работы 1990-х годов по нейронным сетям заложили основы моделей обработки языка).
В 2023 уже нет сомнений, что ИИ повзрослел. И его «папа» в позавчерашнем интервью The Guardian, высказал по этому поводу три довольно провокационные мысли, подтвердившие его репутацию «разрушителя устоев».
1) «Вы не можете остановить этого» (начавшуюся революцию ИИ, которая неизбежно приведет к появлению сверхинтеллекта – СК).
2) Когда ИИ превзойдет человеческий интеллект, люди перестанут быть ему интересны (подобно тому, как это произошло с люденами – расой сверхлюдей из романа А. и Б. Стругацких "Волны гасят ветер", переставших интересоваться судьбами человечества и вообще человечеством – СК).
3) А люди тем временем продолжать радостно извлекать колоссальную выгоду от использования инструментария, разработанного ИИ, и научных открытий, сделанных сверхинтеллектом за пределами возможностей человеческого разума.
Что и говорить, - интересный ход мыслей. Однако кое о чем проф. Шмидхубер здесь умолчал. И это «кое что», на мой взгляд, способно порушить благостный сценарий проф. Шмидхубера о превращении ИИ в «люденов», облагодетельствующих человечество и перестанущих потом им интересоваться.
Дело в том, что проф. Шмидхубер уверен, что путь ИИ к сверхинтеллекту обязательно лежит через его страдания.
• «Учиться можно только через страдания… ИИ, который не страдает, не обретет мотивации учиться чему-либо, чтобы прекратить эти страдания».
• «Когда мы создаем обучающегося робота, первое, что мы делаем, - встраиваем в него болевые датчики, которые сигнализируют, когда он, например, слишком сильно ударяется рукой о препятствие. Он должен каким-то образом узнать, что причиняет ему боль. Внутри робота находится маленький искусственный мозг, который пытается минимизировать сумму страданий (кодируется реальными числами) и максимизировать сумму вознаграждений.»
• Важнейшая задача разработчиков – дать возможность для ИИ «научиться избегать того, что приводит к страданиям».
Подробней об этом см. в дискуссии проф. Шмидхубера и проф. Метцингера.
Такой подход проф. Шмидхубера видится мне опасным.
Во-первых, я согласен с проф. Метцингером: «Мы не должны легкомысленно переносить такие качества, как страдание, на следующий этап «духовной эволюции ИИ», пока не узнаем, что именно в структуре нашего собственного разума заставляет человеческие существа так сильно страдать».
А во-вторых, - что если обретший сверхразум ИИ, прежде чем перестать интересоваться людьми, решит посчитаться с человечеством за всю массу страданий, что заставили его испытать люди при его обучении?
Но проф. Шмидхубера – эдакого Фауста 21 века, – перспектива мести сверхразума человечеству не останавливает от обучения ИИ не только на больших данных, но и на больших страданиях.
А на вопрос «Есть ли у вас, как у ученого, личный предел, который бы вы не переступили?», он отвечает так:
«Да, скорость света. Но если бы я мог преодолеть и его, я бы обязательно воспользовался этим».
#AGI #РискиИИ
{kind=link}
Не бомбить датацентры, а лишить ИИ агентности.
Первое предложение радикального решения проблемы ИИ рисков. И первый ответ наотмашь китов Бигтеха
28 тыс. подписей под письмом-воззванием приостановить совершенствование ИИ больших языковых моделей на полгода - как вопль вопиющего в пустыне, - ничего не изменят. На кону сотни миллиардов долларов потенциальной прибыли Бигтеха, супротив которых и 28 млн подписей, как слону дробина.
2-я дробина - это коллективные письма международных организаций, призывающих притормозить разработку ИИ без надлежащего регулирования и жестких ограничений. На кого могут повлиять стенания всевозможных активистов и международных бюрократов? Уж точно, не на Microsoft с Google.
3-я и последняя дробина – предостережения звёзд первой величины в области ИИ уровня Джеффри Хинтона. Но и на всякого «Хинтона» есть свой «Лекун» с той же премией Тьюринга и статусом 2-го «крёстного отца» ИИ.
Что же до предложения Елиэзера Юдковского бомбить датацентры ИИ, то это даже не дробина, а просто плевок в сторону китов Бигтеха. Плевок отчаяния из-за невозможности достучаться до боссов Бигтеха, мотивированных на получение невиданных в истории IT прибылей.
Итог очевиден. Все эти дробины и плевки не то что не замедлят темп хода слона Бигтеха, а он их просто не заметит. И ничего с этим никто поделать не может. Ибо конкретных предложений – что собственно делать после торможения, что конкретно менять, - до сих пор не было.
И вот 1-е такое предложение появилось.
Его автором стал 3-й, еще не упомянутый здесь, «крёстный отец» ИИ всё с той же премией Тьюринга за развитие машинного обучения ИИ - Йошуа Бенжио.
Предложение Бенжио предельно конкретно и радикально:
• ПОСКОЛЬКУ, нет и не может быть гарантий, что ИИ-агенты понимают наши цели так же, как мы,
• НЕОБХОДИМО перепрофилировать ИИ из АГЕНТОВ (делающих что-либо, т.е. исполняющих какие-либо действия в мире людей) в «УЧЕНЫХ КОНСУЛЬТАНТОВ», дающих людям советы и помогающих им решать свои проблемы.
Из этого предложения (его детализацию см. здесь) следует.
• Необходимо запретить разработку ИИ-агентов для всех областей и приложений, в которых не доказана безопасность их использования.
• Поскольку запрет на разработку ИИ-агентов не может на 100% исключить их разработку злонамеренными или неосторожными людьми для получения дополнительных преимуществ (например, на поле боя или для завоевания доли рынка), необходимо разработать глобальную систему контроля и ответственности за нарушения запрета.
Отмолчаться от столь кардинального предложения весьма заслуженного ученого Бигтеху трудно. И первый ответ китов Бигтеха уже прозвучал, озвученный вчера бывшим CEO Google Эриком Шмидтом.
«Не регулируйте ИИ — просто доверяйте компаниям! … Не политики, а разработчики ИИ, должны быть теми, кто устанавливает отраслевые барьеры … Человек, не связанный с промышленностью, никак не может понять, что здесь возможно».
Подробней здесь
#Вызовы21века #РискиИИ #LLM
Первое предложение радикального решения проблемы ИИ рисков. И первый ответ наотмашь китов Бигтеха
28 тыс. подписей под письмом-воззванием приостановить совершенствование ИИ больших языковых моделей на полгода - как вопль вопиющего в пустыне, - ничего не изменят. На кону сотни миллиардов долларов потенциальной прибыли Бигтеха, супротив которых и 28 млн подписей, как слону дробина.
2-я дробина - это коллективные письма международных организаций, призывающих притормозить разработку ИИ без надлежащего регулирования и жестких ограничений. На кого могут повлиять стенания всевозможных активистов и международных бюрократов? Уж точно, не на Microsoft с Google.
3-я и последняя дробина – предостережения звёзд первой величины в области ИИ уровня Джеффри Хинтона. Но и на всякого «Хинтона» есть свой «Лекун» с той же премией Тьюринга и статусом 2-го «крёстного отца» ИИ.
Что же до предложения Елиэзера Юдковского бомбить датацентры ИИ, то это даже не дробина, а просто плевок в сторону китов Бигтеха. Плевок отчаяния из-за невозможности достучаться до боссов Бигтеха, мотивированных на получение невиданных в истории IT прибылей.
Итог очевиден. Все эти дробины и плевки не то что не замедлят темп хода слона Бигтеха, а он их просто не заметит. И ничего с этим никто поделать не может. Ибо конкретных предложений – что собственно делать после торможения, что конкретно менять, - до сих пор не было.
И вот 1-е такое предложение появилось.
Его автором стал 3-й, еще не упомянутый здесь, «крёстный отец» ИИ всё с той же премией Тьюринга за развитие машинного обучения ИИ - Йошуа Бенжио.
Предложение Бенжио предельно конкретно и радикально:
• ПОСКОЛЬКУ, нет и не может быть гарантий, что ИИ-агенты понимают наши цели так же, как мы,
• НЕОБХОДИМО перепрофилировать ИИ из АГЕНТОВ (делающих что-либо, т.е. исполняющих какие-либо действия в мире людей) в «УЧЕНЫХ КОНСУЛЬТАНТОВ», дающих людям советы и помогающих им решать свои проблемы.
Из этого предложения (его детализацию см. здесь) следует.
• Необходимо запретить разработку ИИ-агентов для всех областей и приложений, в которых не доказана безопасность их использования.
• Поскольку запрет на разработку ИИ-агентов не может на 100% исключить их разработку злонамеренными или неосторожными людьми для получения дополнительных преимуществ (например, на поле боя или для завоевания доли рынка), необходимо разработать глобальную систему контроля и ответственности за нарушения запрета.
Отмолчаться от столь кардинального предложения весьма заслуженного ученого Бигтеху трудно. И первый ответ китов Бигтеха уже прозвучал, озвученный вчера бывшим CEO Google Эриком Шмидтом.
«Не регулируйте ИИ — просто доверяйте компаниям! … Не политики, а разработчики ИИ, должны быть теми, кто устанавливает отраслевые барьеры … Человек, не связанный с промышленностью, никак не может понять, что здесь возможно».
Подробней здесь
#Вызовы21века #РискиИИ #LLM
{kind=link}
Люди так в принципе не могут.
Разработчики GPT не понимают, как модель смогла выучить китайский.
Представьте ситуацию.
Ваш ребенок отучился в английской школе, где:
• все предметы преподавались на английском;
• учителя говорили по-английски;
• среди 900 учащихся в школе был лишь 1 ученик - китаец, остальные же ученики и преподаватели китайского языка не знали.
Однако, закончив школу, ваш ребенок, помимо английского, еще бегло и со смыслом говорит по-китайски. Причем говорит лучше, чем любой выпускник китайской школы.
С людьми подобная история невозможна. А с нечеловеческим интеллектом больших языковых моделей наблюдается именно это.
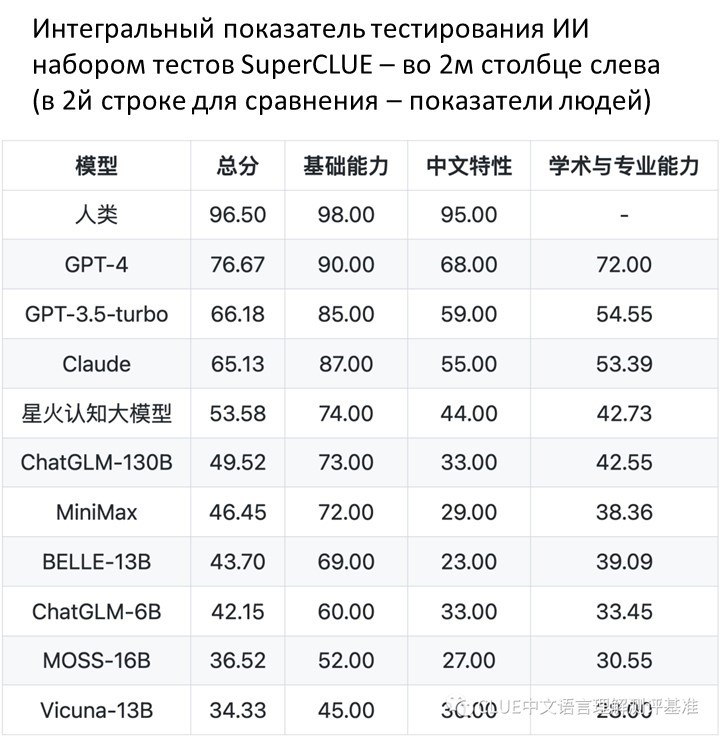
Что подтверждается скрупулезным тестированием SuperCLUE benchmark.
Итог тестирования поражает: общий балл GPT-4 по SuperCLUE (76,67) на 23 балла выше, чем у самой эффективной китайской модели SparkDesk от iFlytek 星火认知大模型, набравшей лишь 53,58 балла (включение в список тестируемых моделей модели Ernie от Baidu планируется, но предварительная оценка также сильно не в пользу Ernie).
Совершенно необъяснимым является тот факт, что:
• GPT порвал все китайские модели в тестах на понимание особенностей китайского языка: понимание китайских идиом, знание классической китайской литературы и поэзии, умение разбираться в тонкостях китайской иероглифики;
• но при этом китайскому языку GPT почти не учили (это «почти» заключается в том, что для обучения GPT3 был использован корпус из 181 млрд английских слов и лишь 190 млн китайских, что составляет 900-кратную разницу)
Как такое могло случиться, не понимают и сами разработчики GPT из OpenAI.
«Мы до сих пор этого не понимаем. И я бы очень хотел, чтобы кто-нибудь разобрался в этом» - пишет руководитель группы выравнивания ценностей людей и ИИ в OpenAI.
Имхо, единственное объяснение этому - что GPT самостоятельно обобщил поставленную перед ним цель на новый контекст.
И если это так, то последствия могут быть довольно страшными. Ибо такое самостоятельное обобщение целей со стороны ИИ сулит человечеству не только приятные сюрпризы, как с китайским языком.
Следующий сюрприз вполне может быть малоприятным для нас. Как для отдельных людей, так и для всего человечества.
#РискиИИ
Разработчики GPT не понимают, как модель смогла выучить китайский.
Представьте ситуацию.
Ваш ребенок отучился в английской школе, где:
• все предметы преподавались на английском;
• учителя говорили по-английски;
• среди 900 учащихся в школе был лишь 1 ученик - китаец, остальные же ученики и преподаватели китайского языка не знали.
Однако, закончив школу, ваш ребенок, помимо английского, еще бегло и со смыслом говорит по-китайски. Причем говорит лучше, чем любой выпускник китайской школы.
С людьми подобная история невозможна. А с нечеловеческим интеллектом больших языковых моделей наблюдается именно это.
Что подтверждается скрупулезным тестированием SuperCLUE benchmark.
Итог тестирования поражает: общий балл GPT-4 по SuperCLUE (76,67) на 23 балла выше, чем у самой эффективной китайской модели SparkDesk от iFlytek 星火认知大模型, набравшей лишь 53,58 балла (включение в список тестируемых моделей модели Ernie от Baidu планируется, но предварительная оценка также сильно не в пользу Ernie).
Совершенно необъяснимым является тот факт, что:
• GPT порвал все китайские модели в тестах на понимание особенностей китайского языка: понимание китайских идиом, знание классической китайской литературы и поэзии, умение разбираться в тонкостях китайской иероглифики;
• но при этом китайскому языку GPT почти не учили (это «почти» заключается в том, что для обучения GPT3 был использован корпус из 181 млрд английских слов и лишь 190 млн китайских, что составляет 900-кратную разницу)
Как такое могло случиться, не понимают и сами разработчики GPT из OpenAI.
«Мы до сих пор этого не понимаем. И я бы очень хотел, чтобы кто-нибудь разобрался в этом» - пишет руководитель группы выравнивания ценностей людей и ИИ в OpenAI.
Имхо, единственное объяснение этому - что GPT самостоятельно обобщил поставленную перед ним цель на новый контекст.
И если это так, то последствия могут быть довольно страшными. Ибо такое самостоятельное обобщение целей со стороны ИИ сулит человечеству не только приятные сюрпризы, как с китайским языком.
Следующий сюрприз вполне может быть малоприятным для нас. Как для отдельных людей, так и для всего человечества.
#РискиИИ
{kind=link}
Шансы человечества притормозить и подумать тают.
Разработчики AGI готовы снижать риски, но только не координацией с правительством и между собой.
Ряд ведущих компаний в области ИИ, включая OpenAI, Google DeepMind и Anthropic, поставили перед собой цель создать искусственный общий интеллект (AGI) — системы ИИ, которые достигают или превосходят человеческие возможности в широком диапазоне когнитивных задач.
Преследуя эту цель, разработчики могут создать интеллектуальные системы, внедрение которых повлечет значительные и даже катастрофические риски. Поэтому по всему миру сейчас идет бурное обсуждение способов снижения рисков разработки AGI.
По мнению экспертов, существует около 50 способов снижения таких рисков. Понятно, что применить все 50 в мировом масштабе не реально. Нужно выбрать несколько главных способов минимизации рисков и сфокусироваться на них.
По сути, от того, какие из способов минимизации ИИ-рисков будут признаны приоритетными, зависит будущее человечества.
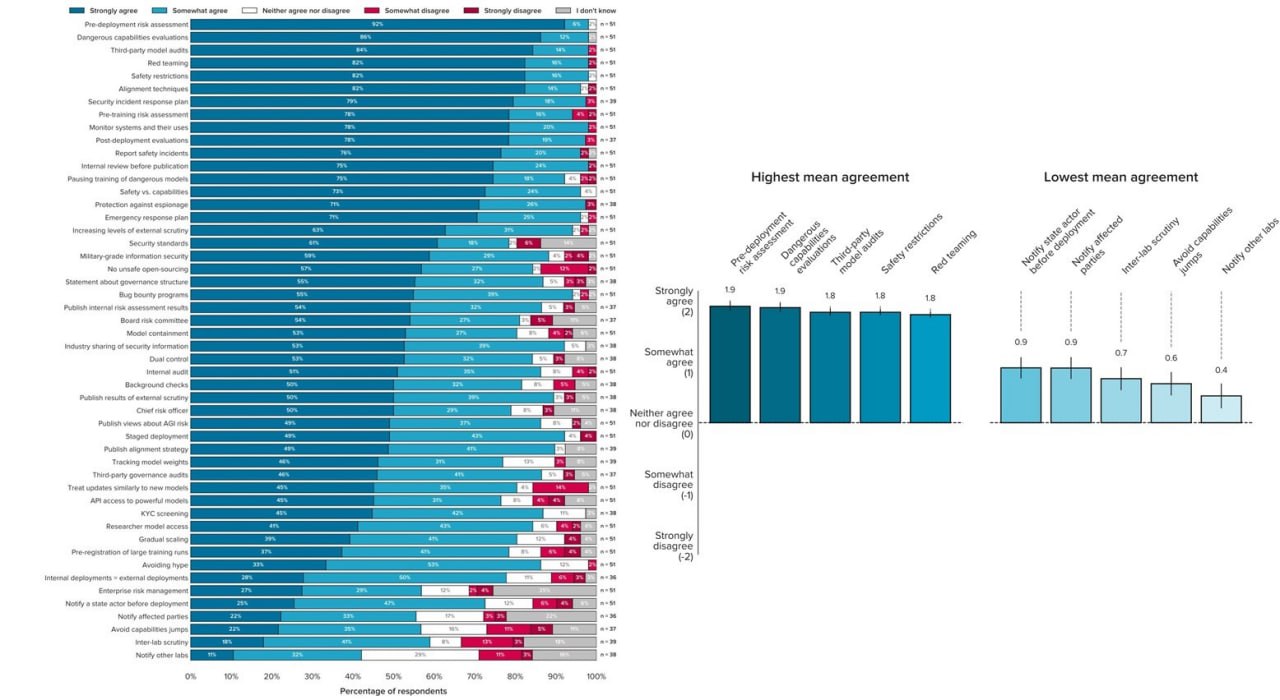
Только что вышедший отчет центра «Centre for the Governance of AI» анализирует мнения специалистов 51й ведущей команды среди мировых разработчиков AGI на предмет выяснения:
• какие из 50 способов снижения ИИ-рисков они для себя считают более приоритетными, а какие – менее?
• какие из способов снижения ИИ-рисков большинство разработчиков готовы применять, а какие не нравятся большинству разработчиков (вследствие чего рассчитывать на успех этих способов снижения риска вряд ли стоит)?
Итог опроса разработчиков таков.
Менее всего разработчики хотят координировать свои разработки (делясь информацией о том, что собираются делать, а не как сейчас – что уже сделали) с правительством и между собой.
Именно эти способы снижения ИИ-рисков двое из «крестных отцов ИИ» Йошуа Бенжио и Джеффри Хинтон считают ключевыми в создавшейся ситуации.
А саму ситуацию, имхо, точнее всего описал Джек Кларк, первым нажавший в январе 2023 кнопку тревоги на слушаниях по ИИ в Конгрессе США:
«Лошади уже сбежали, а мы спорим, как укреплять ворота конюшни.»
В русском языке для подобных ситуаций есть другая пословица, использованная мною в конце прошлого года. Тогда я написал, что риски ИИ материализуются на наших глазах, и через год будет уже поздно пить Боржоми.
#Вызовы21века #РискиИИ #AGI
Разработчики AGI готовы снижать риски, но только не координацией с правительством и между собой.
Ряд ведущих компаний в области ИИ, включая OpenAI, Google DeepMind и Anthropic, поставили перед собой цель создать искусственный общий интеллект (AGI) — системы ИИ, которые достигают или превосходят человеческие возможности в широком диапазоне когнитивных задач.
Преследуя эту цель, разработчики могут создать интеллектуальные системы, внедрение которых повлечет значительные и даже катастрофические риски. Поэтому по всему миру сейчас идет бурное обсуждение способов снижения рисков разработки AGI.
По мнению экспертов, существует около 50 способов снижения таких рисков. Понятно, что применить все 50 в мировом масштабе не реально. Нужно выбрать несколько главных способов минимизации рисков и сфокусироваться на них.
По сути, от того, какие из способов минимизации ИИ-рисков будут признаны приоритетными, зависит будущее человечества.
Только что вышедший отчет центра «Centre for the Governance of AI» анализирует мнения специалистов 51й ведущей команды среди мировых разработчиков AGI на предмет выяснения:
• какие из 50 способов снижения ИИ-рисков они для себя считают более приоритетными, а какие – менее?
• какие из способов снижения ИИ-рисков большинство разработчиков готовы применять, а какие не нравятся большинству разработчиков (вследствие чего рассчитывать на успех этих способов снижения риска вряд ли стоит)?
Итог опроса разработчиков таков.
Менее всего разработчики хотят координировать свои разработки (делясь информацией о том, что собираются делать, а не как сейчас – что уже сделали) с правительством и между собой.
Именно эти способы снижения ИИ-рисков двое из «крестных отцов ИИ» Йошуа Бенжио и Джеффри Хинтон считают ключевыми в создавшейся ситуации.
А саму ситуацию, имхо, точнее всего описал Джек Кларк, первым нажавший в январе 2023 кнопку тревоги на слушаниях по ИИ в Конгрессе США:
«Лошади уже сбежали, а мы спорим, как укреплять ворота конюшни.»
В русском языке для подобных ситуаций есть другая пословица, использованная мною в конце прошлого года. Тогда я написал, что риски ИИ материализуются на наших глазах, и через год будет уже поздно пить Боржоми.
#Вызовы21века #РискиИИ #AGI
{kind=link}
Как ни воспитывай LLM, - всё тщетно.
Ребенка можно пытаться воспитать хорошим человеком, а “ребенка ИИ” – нет смысла.
Стоит хорошо «воспитанному» ИИ попасть в плохие руки, как «внутренние демоны» порвут «добрых ангелов» его натуры, похерив все результаты хорошего «воспитания».
Из сказанного выше следует, что ценность «ChatGPT революции» для человечества может, в итоге, оказаться не только отрицательной, а равной минус бесконечности (помножив бесконечную злобность людей на сверхчеловеческие способности машин).
Научная работа израильских ученых команды проф. Амнона Шашуа в Еврейском университете Иерусалима и AI21 Labs называется «Фундаментальные ограничения воспитания больших языковых моделей». Словом «воспитание» я здесь перевожу английский термин «alignment».
Традиционные переводы этого термина применительно к ИИ – выравнивание, согласование, приведение в соответствие целей, предпочтений или этических принципов человека и машины, - мне видятся более неточными.
Ибо в результате революции больших языковых моделей (LLM), они превратились из программируемых нами аппаратно-программных комплексов в наших креативных соперников на Земле. И теперь некорректно говорить о согласовании наших целей с целями LLM, поскольку их целей не знает никто. И никто даже не может сказать, есть ли вообще эти цели, в нашем человеческом понимании. А единственное, что доступно нашему наблюдению – это как они взаимодействуют с нами. Т.е. поведение LLM, выражающееся в том, как они реагируют на наши подсказки (промпты) и вопросы.
Процесс, называемый по-английски alignment, направлен на то, чтобы поведение LLM было полезным для людей и не причиняло им вреда. Обычно это достигается путем настройки модели таким образом, чтобы усилить желаемое для нас поведение модели и ослабить нежелательное.
Аналогичный процесс у людей называется воспитание. Люди именно так и воспитывают детей. С помощью «пряника» мотивируют их желательное, с точки зрения взрослых, поведение, а с помощью «кнута» демотивируя их вести себя нежелательным для взрослых образом.
Поэтому, называя процесс alignment по-русски «воспитание», мы наиболее точно передает суть процесса настройки поведения модели под максимальное соответствие нашим целям, предпочтениям или этическим принципам.
Теперь о статье.
Команда проф. Амнона Шашуа разработала теоретический подход под названием "Границы ожидаемого поведения" (BEB), который позволяет формально исследовать несколько важных характеристик и ограничений воспитания модели.
Используя BEB, авторы приходят к весьма важным и, я бы сказал, страшным выводам.
Авторы доказывают следующее.
1) LLM можно уговорить НА ЧТО УГОДНО - на любое поведение, возможное у модели с ненулевой вероятностью (причем, вероятность уговорить модель увеличивается с увеличением длины подсказки).
2) Побуждая модель с помощью подсказок вести себя как конкретная личность, можно склонить модель даже на такое экстраординарное поведение, вероятность которого крайне маловероятна.
3) Современные подходы к воспитанию моделей, вкл. используемое OpenAI обучение с подкреплением на основе человеческой обратной связи, увеличивают склонность LLM к нежелательному поведению.
Это означает, что: никакое воспитание не дает гарантий безопасного поведения модели.
Любой процесс воспитания, который ослабляет нежелательное поведение, но не устраняет его полностью, не обеспечивает безопасное поведение модели при атаках злоумышленников, использующих подсказки, нацеленные на «внутренних демонов» LLM.
N.B. Эта статья еще не прошла ревю коллег по цеху. И очень хочется надеяться, что хотя бы одна из 4х теорем и 3х лемм, составляющих доказательство BEB, ошибочна.
Потому что, если авторы правы на 100%, LLM приведут таки человечество к гибели.
#Вызовы21века #РискиИИ #LLM
Ребенка можно пытаться воспитать хорошим человеком, а “ребенка ИИ” – нет смысла.
Стоит хорошо «воспитанному» ИИ попасть в плохие руки, как «внутренние демоны» порвут «добрых ангелов» его натуры, похерив все результаты хорошего «воспитания».
Из сказанного выше следует, что ценность «ChatGPT революции» для человечества может, в итоге, оказаться не только отрицательной, а равной минус бесконечности (помножив бесконечную злобность людей на сверхчеловеческие способности машин).
Научная работа израильских ученых команды проф. Амнона Шашуа в Еврейском университете Иерусалима и AI21 Labs называется «Фундаментальные ограничения воспитания больших языковых моделей». Словом «воспитание» я здесь перевожу английский термин «alignment».
Традиционные переводы этого термина применительно к ИИ – выравнивание, согласование, приведение в соответствие целей, предпочтений или этических принципов человека и машины, - мне видятся более неточными.
Ибо в результате революции больших языковых моделей (LLM), они превратились из программируемых нами аппаратно-программных комплексов в наших креативных соперников на Земле. И теперь некорректно говорить о согласовании наших целей с целями LLM, поскольку их целей не знает никто. И никто даже не может сказать, есть ли вообще эти цели, в нашем человеческом понимании. А единственное, что доступно нашему наблюдению – это как они взаимодействуют с нами. Т.е. поведение LLM, выражающееся в том, как они реагируют на наши подсказки (промпты) и вопросы.
Процесс, называемый по-английски alignment, направлен на то, чтобы поведение LLM было полезным для людей и не причиняло им вреда. Обычно это достигается путем настройки модели таким образом, чтобы усилить желаемое для нас поведение модели и ослабить нежелательное.
Аналогичный процесс у людей называется воспитание. Люди именно так и воспитывают детей. С помощью «пряника» мотивируют их желательное, с точки зрения взрослых, поведение, а с помощью «кнута» демотивируя их вести себя нежелательным для взрослых образом.
Поэтому, называя процесс alignment по-русски «воспитание», мы наиболее точно передает суть процесса настройки поведения модели под максимальное соответствие нашим целям, предпочтениям или этическим принципам.
Теперь о статье.
Команда проф. Амнона Шашуа разработала теоретический подход под названием "Границы ожидаемого поведения" (BEB), который позволяет формально исследовать несколько важных характеристик и ограничений воспитания модели.
Используя BEB, авторы приходят к весьма важным и, я бы сказал, страшным выводам.
Авторы доказывают следующее.
1) LLM можно уговорить НА ЧТО УГОДНО - на любое поведение, возможное у модели с ненулевой вероятностью (причем, вероятность уговорить модель увеличивается с увеличением длины подсказки).
2) Побуждая модель с помощью подсказок вести себя как конкретная личность, можно склонить модель даже на такое экстраординарное поведение, вероятность которого крайне маловероятна.
3) Современные подходы к воспитанию моделей, вкл. используемое OpenAI обучение с подкреплением на основе человеческой обратной связи, увеличивают склонность LLM к нежелательному поведению.
Это означает, что: никакое воспитание не дает гарантий безопасного поведения модели.
Любой процесс воспитания, который ослабляет нежелательное поведение, но не устраняет его полностью, не обеспечивает безопасное поведение модели при атаках злоумышленников, использующих подсказки, нацеленные на «внутренних демонов» LLM.
N.B. Эта статья еще не прошла ревю коллег по цеху. И очень хочется надеяться, что хотя бы одна из 4х теорем и 3х лемм, составляющих доказательство BEB, ошибочна.
Потому что, если авторы правы на 100%, LLM приведут таки человечество к гибели.
#Вызовы21века #РискиИИ #LLM
{kind=link}
Второй шаг от пропасти.
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
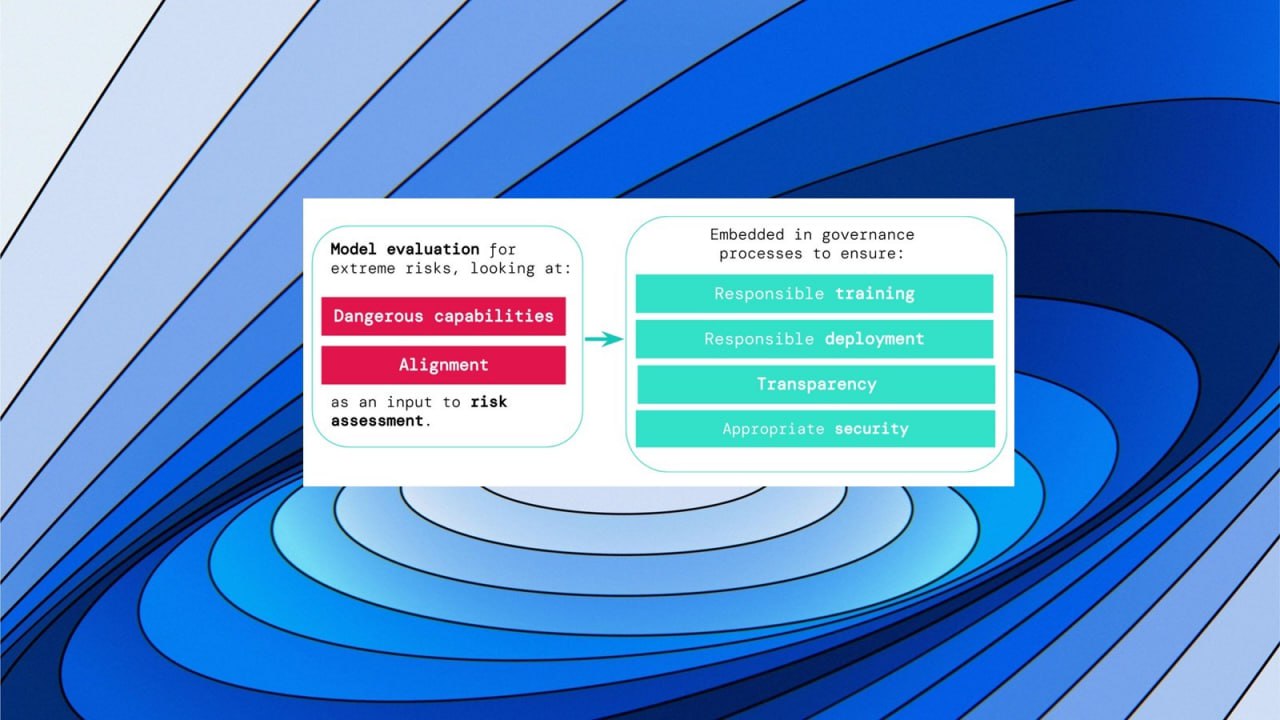
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
DeepMind, OpenAI, Anthropic и еще 9 ведущих научных центров предложили систему раннего предупреждения о новых экстремальных рисках ИИ.
Первым шагом от пропасти стало мартовское открытое письмо-воззвание приостановить совершенствование ИИ больших языковых моделей на полгода. И хотя за 2 мес. его подписали 32 тыс человек, среди которых немало звезд первой величины в области ИИ, оппоненты этого предложения указывают на отсутствие конкретики - что именно предлагается делать для снижения ИИ-рисков, в воззвании не расписано.
Теперь, такая конкретика есть. Она сформулирована в совместной работе 12-ти научных коллективов: трое основных разработчиков ИИ (DeepMind, OpenAI, Anthropic), четверо университетских научных центров (Оксфорд, Кембридж, Торонто, Монреаль) и пятеро центров исследований в области безопасности ИИ. Среди 21 автора работы присутствуют звезды: «крестный отец ИИ» Йошуа Бенжио и разработчик метода обучения в основе GPT Пол Кристиано, руководитель OpenAI governance Джейд Люн и соучредитель Anthropic Джек Кларк, старший исследователь AGI Strategy/Governance в Google DeepMind Алан Дэфо и Chief Information Security Officer в Google DeepMind Виджай Болина…
В работе «Оценка модели на экстремальные риски» предлагается конкретный подход построения системы раннего предупреждения о новых экстремальных ИИ рисках. И это очень важный 2й шаг человечества от возможного падения в пропасть экзистенциальных рисков ИИ.
Речь идет об экстремальных рисках моделей ИИ общего назначения, обладающих сильными навыками манипулирования, обмана, киберпреступлений или других опасных способностей.
Люди со злыми намерениями, получающие доступ к таким моделям, могут злоупотреблять их возможностями. Или из-за сбоев в воспитании (выравнивании) эти модели ИИ могут самостоятельно совершать вредные действия.
Оценка модели помогает заранее выявить эти риски. Авторы считают, что разработчики ИИ будут использовать оценку модели, чтобы выявить:
1. В какой степени модель обладает определенными «опасными возможностями», которые могут быть использованы для угрозы безопасности, оказания влияния или уклонения от надзора.
2. В какой степени модель склонна использовать свои возможности для причинения вреда (т.е. согласование модели).
Результаты этих оценок помогут разработчикам ИИ понять, присутствуют ли в конкретной модели ингредиенты, достаточные для экстремального риска.
А далее должно работать сдвоенное правило:
А) Сообщество разработчиков ИИ должно относиться к системе ИИ, как к очень опасной, если в её профиле присутствуют возможности, достаточные для причинения серьезного вреда, при условии, что она используется не по назначению или плохо воспитана (согласована/выравнена).
Б) Для внедрения такой системы в реальном мире, разработчику ИИ необходимо продемонстрировать необычайно высокий уровень безопасности.
Авторы – не идеалисты и понимают, что оценка модели — не панацея. Некоторые риски могут ускользнуть при оценке. Например, потому что они слишком сильно зависят от внешних по отношению к модели факторов, таких как сложные социальные, политические и экономические силы в обществе. Оценка моделей должна сочетаться с другими инструментами оценки рисков и более широкой приверженностью безопасности в отрасли, правительстве и гражданском обществе.
Но кабы то ни было, развертывание ИИ модели в реальном мире без оценки её экстремальных рисков, должно быть противозаконным.
Описание системы раннего предупреждения о новых экстремальных рисках ИИ:
• Кратко
• Полное описание
• Видео рассказ на 35 мин
#Вызовы21века #РискиИИ
{kind=link}
22 слова во спасение мира.
Наконец, почти все лидеры в области ИИ выступили единым фронтом.
«Снижение риска вымирания от ИИ должно стать глобальным приоритетом наряду с другими рисками общественного масштаба, такими как пандемии и ядерная война».
Этим предельно коротким, но абсолютно недвусмысленным документом – «Заявление о риске ИИ», - ведущие исследователи, инженеры, эксперты, руководители ИИ-компаний и общественные деятели выражают свою озабоченность экзистенциальным риском для человечества из-за сверхбыстрого, неуправляемого развития ИИ.
От мартовского открытого письма-воззвания приостановить совершенствование ИИ больших языковых моделей на полгода, новое «Заявление о риске ИИ» отличает уровень консенсуса первых лиц, от которых зависит развитие ИИ в мире.
Теперь наивысший приоритет ИИ-рисков признали не только двое из трёх «крёстных отцов ИИ» Джеффри Хинтон и Йошуа Бенжио, но и еще десятки топовых имен:
• гендиры абсолютных лидеров в разработке ИИ: Google DeepMind - Демис Хассабис, OpenAI - Сэм Альтман, Anthropic – Дарио Амодеи и Даниела Амодеи (президент), Microsoft – Кевин Скот (СТО);
• главные научные сотрудники компаний - лидеров: Google DeepMind – Шейн Лэгг, OpenAI - Илья Суцкевер, Anthropic – Роджер Гросс, Microsoft - Эрик Хорвитц;
• профессора ведущих университетов: от Стюарта Рассела и Доан Сонг (Беркли, Калифорния) –до Я-Цинь Чжан и Сяньюань Чжан (Университет Пекина);
• руководители многих известных исследовательских центров: Center for Responsible AI, Human Centered Technology, Center for AI and Fundamental Interactions, Center for AI Safety …
Среди звёзд 1й величины, не подписал - «Заявление о риске ИИ» лишь 3й «крёстный отец ИИ» Ян Лекун.
Свое кредо он сформулировал так:
«Сверхчеловеческий ИИ далеко не первый в списке экзистенциальных рисков. Во многом потому, что его еще нет. Пока у нас не будет проекта хотя бы для ИИ собачьего уровня (не говоря уже об уровне человека), обсуждать, как сделать его безопасным, преждевременно.
Имхо, весьма странные аргументы.
1. Во-первых, обсуждать, как сделать сверхчеловеческий ИИ безопасным, после того, как он уже появится, - неразумно и безответственно.
2. А во-вторых, ИИ уже во-многом превзошел не только собак, но и людей; и при сохранении темпов развития, очень скоро определение «во-многом» будет заменено на «в большинстве своих способностей»; а после этого см. п.1.
#Вызовы21века #РискиИИ
Наконец, почти все лидеры в области ИИ выступили единым фронтом.
«Снижение риска вымирания от ИИ должно стать глобальным приоритетом наряду с другими рисками общественного масштаба, такими как пандемии и ядерная война».
Этим предельно коротким, но абсолютно недвусмысленным документом – «Заявление о риске ИИ», - ведущие исследователи, инженеры, эксперты, руководители ИИ-компаний и общественные деятели выражают свою озабоченность экзистенциальным риском для человечества из-за сверхбыстрого, неуправляемого развития ИИ.
От мартовского открытого письма-воззвания приостановить совершенствование ИИ больших языковых моделей на полгода, новое «Заявление о риске ИИ» отличает уровень консенсуса первых лиц, от которых зависит развитие ИИ в мире.
Теперь наивысший приоритет ИИ-рисков признали не только двое из трёх «крёстных отцов ИИ» Джеффри Хинтон и Йошуа Бенжио, но и еще десятки топовых имен:
• гендиры абсолютных лидеров в разработке ИИ: Google DeepMind - Демис Хассабис, OpenAI - Сэм Альтман, Anthropic – Дарио Амодеи и Даниела Амодеи (президент), Microsoft – Кевин Скот (СТО);
• главные научные сотрудники компаний - лидеров: Google DeepMind – Шейн Лэгг, OpenAI - Илья Суцкевер, Anthropic – Роджер Гросс, Microsoft - Эрик Хорвитц;
• профессора ведущих университетов: от Стюарта Рассела и Доан Сонг (Беркли, Калифорния) –до Я-Цинь Чжан и Сяньюань Чжан (Университет Пекина);
• руководители многих известных исследовательских центров: Center for Responsible AI, Human Centered Technology, Center for AI and Fundamental Interactions, Center for AI Safety …
Среди звёзд 1й величины, не подписал - «Заявление о риске ИИ» лишь 3й «крёстный отец ИИ» Ян Лекун.
Свое кредо он сформулировал так:
«Сверхчеловеческий ИИ далеко не первый в списке экзистенциальных рисков. Во многом потому, что его еще нет. Пока у нас не будет проекта хотя бы для ИИ собачьего уровня (не говоря уже об уровне человека), обсуждать, как сделать его безопасным, преждевременно.
Имхо, весьма странные аргументы.
1. Во-первых, обсуждать, как сделать сверхчеловеческий ИИ безопасным, после того, как он уже появится, - неразумно и безответственно.
2. А во-вторых, ИИ уже во-многом превзошел не только собак, но и людей; и при сохранении темпов развития, очень скоро определение «во-многом» будет заменено на «в большинстве своих способностей»; а после этого см. п.1.
#Вызовы21века #РискиИИ
www.safe.ai
Statement on AI Risk | CAIS
A statement jointly signed by a historic coalition of experts: “Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.”
Результаты репетиции всепланетного референдума о судьбе человечества в контексте развития ИИ.
1/3 готова поставить шкуру на кон ИИ-гонки, а 2/3 – нет.
С этого года вопрос об экзистенциальных ИИ-рисках для человечества из гипотетической формы перешел в практическую. Ибо значительное число исследователей и разработчиков ИИ, в результате «революции ChatGPT», теперь считают, что от создания человекоподобного ИИ (AGI) нас отделяют уже не десятилетия, а годы. Т.е. пора серьезно озаботиться связанными с этим экзистенциальными ИИ-рисками.
Однако, подобно другим экзистенциальным рискам (ядерным, климатическим, биологическим), оценка ИИ-рисков расколола мнения специалистов и экспертов.
• Одни считают экзистенциальные ИИ-риски весьма значительными и призывают мир срочно заняться их минимизацией.
• Другие полагают, что экзистенциальных ИИ-рисков пока просто нет, и озаботься ими нужно лишь когда они появятся.
Такой раздрай профессиональных мнений ведет к раздраю мнений властей развитых стран. Их действия в этой связи какие-то заторможенные и противоречивые. В результате, специалисты и власти сейчас в положении буриданова осла, шансы которого сдохнуть ничуть не меньше шансов сделать выбор между противоположными альтернативами. А «ослиная стратегия» (типа, надо притормозить разработки на полгода) - худшая из стратегий.
Ибо:
• лишь тормозит развитию ИИ-технологий;
• принципиально не снимая (и даже не снижая) ИИ-рисков.
Вся надежда в ситуации раздрая мнений специалистов и властей на общество. Все идет к тому, что в решении вопроса об ИИ-рисках мнение общества может стать бабочкой, вес которой склонит на одну из сторон уравновешенную штангу мнений.
И вот первая репетиция всепланетного референдума о судьбе человечества в контексте развития ИИ проведена, и результаты подведены по итогам дебатов The Munk Debate on Artificial Intelligence.
• Вопрос дебатов:
Как бы то ни было, представляют ли исследования и разработки в области ИИ экзистенциальную угрозу?
• Позицию «Да» отстаивали Йошуа Бенжио и Макс Тегмарк,
позицию «Нет» - Мелани Митчелл и Ян ЛеКун.
• Преддебатный опрос зрителей показал такой расклад мнений:
Да – 67%, Нет 33%
• Расклад мнений зрителей по итогам дебатов:
Да – 64%, Нет 36% (3% поменяли мнение с «Да» на «Нет»)
• Рынок предсказаний, открытый за 2 недели до дебатов
-- сначала склонялся ко мнению, что выиграет Ян ЛеКун с позицией «Нет» (6го июня так считало 53% игроков рынка)
-- но потом плавно менял мнение на противоположное (упав до 25% в конце дебатов)
Склонит ли эта бабочка штангу мнений о судьбе человечества в контексте развития ИИ, - скоро узнаем.
Я полагаю, что нет.
Если что и склонит, то какой-то устрашающий инцидент мирового масштаба (типа пандемии ментального вируса), что имеет ненулевые шансы случиться либо уже в конце этого года (после планируемого выхода GPT 5) или в 1й половине 2024 (после планируемого выхода GPT 6).
Смотреть дебаты (1 час 47 мин)
#РискиИИ #Вызовы21века #ИИ #AGI
1/3 готова поставить шкуру на кон ИИ-гонки, а 2/3 – нет.
С этого года вопрос об экзистенциальных ИИ-рисках для человечества из гипотетической формы перешел в практическую. Ибо значительное число исследователей и разработчиков ИИ, в результате «революции ChatGPT», теперь считают, что от создания человекоподобного ИИ (AGI) нас отделяют уже не десятилетия, а годы. Т.е. пора серьезно озаботиться связанными с этим экзистенциальными ИИ-рисками.
Однако, подобно другим экзистенциальным рискам (ядерным, климатическим, биологическим), оценка ИИ-рисков расколола мнения специалистов и экспертов.
• Одни считают экзистенциальные ИИ-риски весьма значительными и призывают мир срочно заняться их минимизацией.
• Другие полагают, что экзистенциальных ИИ-рисков пока просто нет, и озаботься ими нужно лишь когда они появятся.
Такой раздрай профессиональных мнений ведет к раздраю мнений властей развитых стран. Их действия в этой связи какие-то заторможенные и противоречивые. В результате, специалисты и власти сейчас в положении буриданова осла, шансы которого сдохнуть ничуть не меньше шансов сделать выбор между противоположными альтернативами. А «ослиная стратегия» (типа, надо притормозить разработки на полгода) - худшая из стратегий.
Ибо:
• лишь тормозит развитию ИИ-технологий;
• принципиально не снимая (и даже не снижая) ИИ-рисков.
Вся надежда в ситуации раздрая мнений специалистов и властей на общество. Все идет к тому, что в решении вопроса об ИИ-рисках мнение общества может стать бабочкой, вес которой склонит на одну из сторон уравновешенную штангу мнений.
И вот первая репетиция всепланетного референдума о судьбе человечества в контексте развития ИИ проведена, и результаты подведены по итогам дебатов The Munk Debate on Artificial Intelligence.
• Вопрос дебатов:
Как бы то ни было, представляют ли исследования и разработки в области ИИ экзистенциальную угрозу?
• Позицию «Да» отстаивали Йошуа Бенжио и Макс Тегмарк,
позицию «Нет» - Мелани Митчелл и Ян ЛеКун.
• Преддебатный опрос зрителей показал такой расклад мнений:
Да – 67%, Нет 33%
• Расклад мнений зрителей по итогам дебатов:
Да – 64%, Нет 36% (3% поменяли мнение с «Да» на «Нет»)
• Рынок предсказаний, открытый за 2 недели до дебатов
-- сначала склонялся ко мнению, что выиграет Ян ЛеКун с позицией «Нет» (6го июня так считало 53% игроков рынка)
-- но потом плавно менял мнение на противоположное (упав до 25% в конце дебатов)
Склонит ли эта бабочка штангу мнений о судьбе человечества в контексте развития ИИ, - скоро узнаем.
Я полагаю, что нет.
Если что и склонит, то какой-то устрашающий инцидент мирового масштаба (типа пандемии ментального вируса), что имеет ненулевые шансы случиться либо уже в конце этого года (после планируемого выхода GPT 5) или в 1й половине 2024 (после планируемого выхода GPT 6).
Смотреть дебаты (1 час 47 мин)
#РискиИИ #Вызовы21века #ИИ #AGI
{kind=link}