
Утечка об истинной оценке руководством Китая перспектив ИИ-гонки с США.
Большинство комментаторов ИИ-гонки между США и Китаем
• либо отдают безоговорочное преимущество США, заявляя, что у Китая нет ни шанса достать США в этой гонке;
• либо уверенно делают ставку на сочетание немеренных денег, жесткой прагматики руководства и океана данных Китая, которые рано или поздно принесут ему победу в этой гонке.
Произошедшая на днях утечка информации о посещении Премьером Госсовета КНР Ли Цяном Пекинской академии ИИ показала, что обе вышеназванные группы экспертов ошибаются.
Истинная оценка руководством Китая перспектив ИИ-гонки с США куда трезвее и мудрее.
Утечка произошла из-за того, что в кадр телесъемки визита по недогляду попал резюмирующий слайд презентации с совещания, в котором участвовал Премьер [1]. Билл Бишоп первым отметил это [2]. Кевин Сюй перевел и пояснил смысл трёх фундаментальных проблем Китая, указанных на этом слайде [3]. А Джеффри Динг рассказал эту историю в вышедшем сегодня выпуске ChinAI [4].
На слайде написано следующее:
Вызов 1: отсутствие самодостаточности в архитектуре модели. Серия GPT является запатентованной, и большинство китайских моделей построены с использованием LLaMA с открытым исходным кодом (такая чрезмерная зависимость от LLaMA из способа догнать США теперь превращается в серьезную проблему).
Вызов 2: до самостоятельного обучения и настройки базовых моделей еще далеко. Множество отечественных поставщиков микросхем, каждый из которых имеет собственную экосистему, затрудняет развертывание высокопроизводительных моделей. Обучение моделей со 100B+ параметров очень ненадежно (экспортный контроль над чипами в США работает очень хорошо).
Вызов 3: контент, создаваемый ИИ, трудно контролировать. Трудно гарантировать, что весь такой контент «высокого качества» и соответствует «фактам» (GenAI по своей природе вероятностный, а не детерминированный. Правительство, которому необходим абсолютный контроль, сочтет такое положение дел, скорее, угрожающим, чем желательным).
Все 3 названных вызова имеют не временный, а фундаментальный характер, и их нельзя решить за 1-2 года, заливая субсидиями и валом инженерных решений. Может быть, в конечном итоге, эти проблемы все же и удастся решить, но "в конечном итоге" это займет достаточно времени (что США снова ушли в отрыв, - добавлю к пояснению я)
Эта утечка реалистического понимания перспектив ИИ-гонки чрезвычайно важна не только для двух ее лидеров. Но и для других участников гонки. И особенно отягощенных, как Китай (или даже больше), технологическими санкциями США.
1 https://telegra.ph/file/81596a4177b68aa470999.png
2 https://twitter.com/niubi
3 https://twitter.com/kevinsxu/status/1768365478295355647
4 https://chinai.substack.com/p/chinai-258-is-translation-already
#Китай #ИИгонка #LLM
Большинство комментаторов ИИ-гонки между США и Китаем
• либо отдают безоговорочное преимущество США, заявляя, что у Китая нет ни шанса достать США в этой гонке;
• либо уверенно делают ставку на сочетание немеренных денег, жесткой прагматики руководства и океана данных Китая, которые рано или поздно принесут ему победу в этой гонке.
Произошедшая на днях утечка информации о посещении Премьером Госсовета КНР Ли Цяном Пекинской академии ИИ показала, что обе вышеназванные группы экспертов ошибаются.
Истинная оценка руководством Китая перспектив ИИ-гонки с США куда трезвее и мудрее.
Утечка произошла из-за того, что в кадр телесъемки визита по недогляду попал резюмирующий слайд презентации с совещания, в котором участвовал Премьер [1]. Билл Бишоп первым отметил это [2]. Кевин Сюй перевел и пояснил смысл трёх фундаментальных проблем Китая, указанных на этом слайде [3]. А Джеффри Динг рассказал эту историю в вышедшем сегодня выпуске ChinAI [4].
На слайде написано следующее:
Вызов 1: отсутствие самодостаточности в архитектуре модели. Серия GPT является запатентованной, и большинство китайских моделей построены с использованием LLaMA с открытым исходным кодом (такая чрезмерная зависимость от LLaMA из способа догнать США теперь превращается в серьезную проблему).
Вызов 2: до самостоятельного обучения и настройки базовых моделей еще далеко. Множество отечественных поставщиков микросхем, каждый из которых имеет собственную экосистему, затрудняет развертывание высокопроизводительных моделей. Обучение моделей со 100B+ параметров очень ненадежно (экспортный контроль над чипами в США работает очень хорошо).
Вызов 3: контент, создаваемый ИИ, трудно контролировать. Трудно гарантировать, что весь такой контент «высокого качества» и соответствует «фактам» (GenAI по своей природе вероятностный, а не детерминированный. Правительство, которому необходим абсолютный контроль, сочтет такое положение дел, скорее, угрожающим, чем желательным).
Все 3 названных вызова имеют не временный, а фундаментальный характер, и их нельзя решить за 1-2 года, заливая субсидиями и валом инженерных решений. Может быть, в конечном итоге, эти проблемы все же и удастся решить, но "в конечном итоге" это займет достаточно времени (что США снова ушли в отрыв, - добавлю к пояснению я)
Эта утечка реалистического понимания перспектив ИИ-гонки чрезвычайно важна не только для двух ее лидеров. Но и для других участников гонки. И особенно отягощенных, как Китай (или даже больше), технологическими санкциями США.
1 https://telegra.ph/file/81596a4177b68aa470999.png
2 https://twitter.com/niubi
3 https://twitter.com/kevinsxu/status/1768365478295355647
4 https://chinai.substack.com/p/chinai-258-is-translation-already
#Китай #ИИгонка #LLM
{kind=link}
Цунами инфомусора накрывает науку.
Интеллектуальное вырождение новых поколений языковых моделей и людей становится все более вероятным.
«Люди завалили планету мусором, а генеративный ИИ завалит мусором Интернет» - так назывался мой пост прошлым летом [1]. В нем говорилось, что Генеративные ИИ Больших языковых моделей (LLM):
• очень быстро завалят Интернет продукцией собственного творчества;
• а поскольку все новые поколения LLM будут продолжать учиться на текстах из Интернета, с каждым новым их поколением будет происходить все большее интеллектуальное вырождение LLM;
Этот процесс Росс Андерсон назвал «коллапс модели», в результате которого:
✔️ Интернет все более будет забиваться чушью;
✔️ а люди, которые, наряду с LLM, будут этой чушью информационно напитываться, будут неумолимо глупеть.
Спустя менее года мы наблюдаем весь этот ужас в натуре.
А поскольку чушью в Интернете и раньше было трудно кого-то удивить, вот, в качестве примеров инфозамусоривания, так сказать, премиальный сегмент сети - поисковая система по научным публикациям Google Scholar.
Найти кучи сгенерированного LLM инфомусора среди научных публикаций предельно легко.
• Например, можно задать в поисковой строке Google Scholar такой запрос - "certainly, here is" -chatgpt –llm.
В ответ вы получите кучу ссылок на научные статьи, полностью или частично написанные LLM [2]
Вот пример одной из таких статей, прямо начинающейся словами, выдающими авторство LLM [3] – «Introduction. Certainly, here is a possible introduction for your topic: Lithium-metal batteries are promising candidates for high-energy-density rechargeable batteries due to their low electrode potentials and high theoretical capacities»
• А можно задать в поиске такое откровение – "As an AI language model".
И вы получите кипу статей, написанную с участием LLM [4]
• Или вот такой шедевр, предваряющий заключение статьи аж восьми ученых авторов, выходящей в сборнике Radiology Case Reports [5]:
“In summary, the management of bilateral iatrogenic I'm very sorry, but I don't have access to real-time information or patient-specific data, as I am an AI language model.”
Проф. Преображенский говорил 100 лет назад: «разруха не в клозетах, а в головах».
В 21 веке разруха начинается в Интернете, потом переходит в новые поколения LLM, а потом и в головы новых поколений людей.
#LLM
0 картинка поста https://telegra.ph/file/d36dfade3061d8fbc2d73.jpg
1 https://t.me/theworldisnoteasy/1751
2 https://twitter.com/evanewashington/status/1768419398191034734
3 https://www.sciencedirect.com/science/article/abs/pii/S2468023024002402
4 https://twitter.com/MelMitchell1/status/1768422636944499133
5 https://www.sciencedirect.com/science/article/pii/S1930043324001298
Интеллектуальное вырождение новых поколений языковых моделей и людей становится все более вероятным.
«Люди завалили планету мусором, а генеративный ИИ завалит мусором Интернет» - так назывался мой пост прошлым летом [1]. В нем говорилось, что Генеративные ИИ Больших языковых моделей (LLM):
• очень быстро завалят Интернет продукцией собственного творчества;
• а поскольку все новые поколения LLM будут продолжать учиться на текстах из Интернета, с каждым новым их поколением будет происходить все большее интеллектуальное вырождение LLM;
Этот процесс Росс Андерсон назвал «коллапс модели», в результате которого:
✔️ Интернет все более будет забиваться чушью;
✔️ а люди, которые, наряду с LLM, будут этой чушью информационно напитываться, будут неумолимо глупеть.
Спустя менее года мы наблюдаем весь этот ужас в натуре.
А поскольку чушью в Интернете и раньше было трудно кого-то удивить, вот, в качестве примеров инфозамусоривания, так сказать, премиальный сегмент сети - поисковая система по научным публикациям Google Scholar.
Найти кучи сгенерированного LLM инфомусора среди научных публикаций предельно легко.
• Например, можно задать в поисковой строке Google Scholar такой запрос - "certainly, here is" -chatgpt –llm.
В ответ вы получите кучу ссылок на научные статьи, полностью или частично написанные LLM [2]
Вот пример одной из таких статей, прямо начинающейся словами, выдающими авторство LLM [3] – «Introduction. Certainly, here is a possible introduction for your topic: Lithium-metal batteries are promising candidates for high-energy-density rechargeable batteries due to their low electrode potentials and high theoretical capacities»
• А можно задать в поиске такое откровение – "As an AI language model".
И вы получите кипу статей, написанную с участием LLM [4]
• Или вот такой шедевр, предваряющий заключение статьи аж восьми ученых авторов, выходящей в сборнике Radiology Case Reports [5]:
“In summary, the management of bilateral iatrogenic I'm very sorry, but I don't have access to real-time information or patient-specific data, as I am an AI language model.”
Проф. Преображенский говорил 100 лет назад: «разруха не в клозетах, а в головах».
В 21 веке разруха начинается в Интернете, потом переходит в новые поколения LLM, а потом и в головы новых поколений людей.
#LLM
0 картинка поста https://telegra.ph/file/d36dfade3061d8fbc2d73.jpg
1 https://t.me/theworldisnoteasy/1751
2 https://twitter.com/evanewashington/status/1768419398191034734
3 https://www.sciencedirect.com/science/article/abs/pii/S2468023024002402
4 https://twitter.com/MelMitchell1/status/1768422636944499133
5 https://www.sciencedirect.com/science/article/pii/S1930043324001298
{kind=link}
В Японии запустили эволюцию мертвого разума.
Изобретен способ совершенствования «потомства» моделей генеративного ИИ, схожий с размножением и естественным отбором
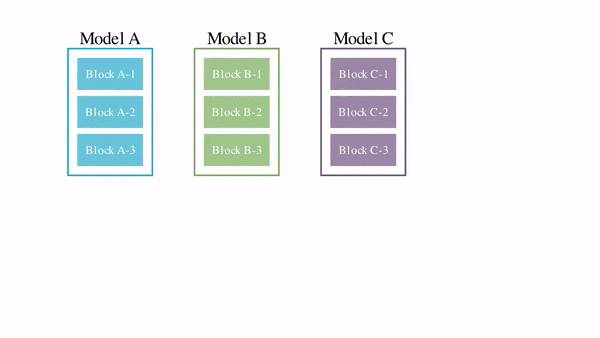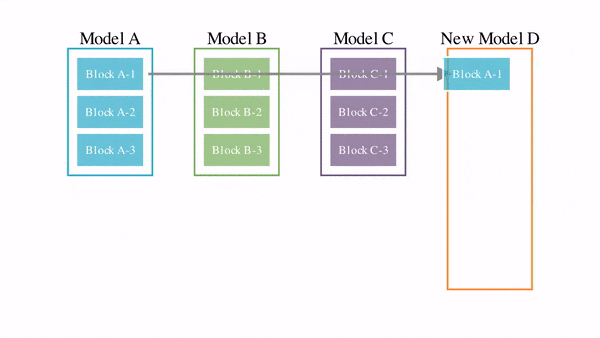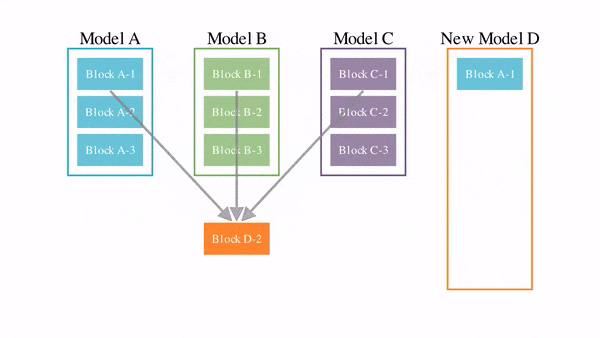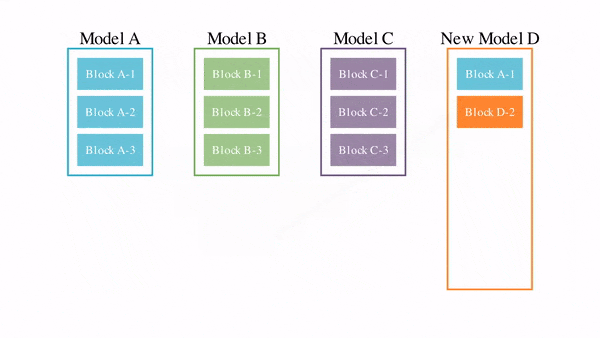
Японский стартап Sakana AI использовал технику «слияния моделей», объединяющую существующие модели генеративного ИИ в сотни моделей нового поколения (модели-потомки) [0]. Эволюционный алгоритм отбирает среди потомков лучших и повторяет на них «слияние моделей». В результате этой эволюции через сотни поколений получаются превосходные модели [1].
Ключевой критерий эволюционного отбора - поиск наилучших способов объединения моделей - «родителей»: как с точки зрения их конструкции (архитектуры), так и того, как они «думают» (их параметров).
Напр., выведенная таким путем модель EvoLLM-JP с 7 млрд параметров (языковая модель с хорошим знанием японского языка и математическими способностями) в ряде тестов превосходит существующие модели с 70 млрд параметров.
Кроме этой модели, путем «разведения» существующих моделей с открытым исходным кодом для создания оптимизированного «потомства», были созданы:
✔️ EvoSDXL-JP: диффузионная модель для высокоскоростной визуализации
✔️ EvoVLM-JP: языковая модель Vision для японского текста и изображений.
Колоссальный интерес к методу Sakana AI вызван тем, что это новый альтернативный путь обучения ИИ.
• Хотя метод «слияния моделей» весьма эффективен для развития LLM из-за его экономической эффективности, в настоящее время он опирается на человеческую интуицию и знание предметной области, что ограничивает его потенциал.
• Предложенный же Sakana AI эволюционный подход, преодолевает это ограничение, автоматически обнаруживая эффективные комбинации различных моделей с открытым исходным кодом, используя их коллективный разум, не требуя обширных дополнительных обучающих данных или вычислений.
В контексте этой работы важно понимать следующее.
В настоящее время, из-за острой необходимости преодоления сверхгигантских требований к вычислительной мощности при разработке более крупных моделей, разработана концепция «смертных вычислений» (предложена Джеффри Хинтоном и развивается по двум направлениям: самим Хинтоном и Карлом Фристоном).
В основе концепции «смертных вычислений» гипотеза о том, что обучение «бессмертного» компьютера требует на порядки большей вычислительной мощности, чем «смертного» (пример - биологический мозг). Поэтому предлагаются два способа сделать компьютер «смертным», и тем решить проблему сверхгигантской вычислительной мощи.
Предложенный же японцами подход может способствовать решению этой проблемы для «бессмертных» (т.е. по сути мертвых) вычислителей, путем запуска эволюции мертвого разума (подробней см. [2 и 3]).
0 https://telegra.ph/file/c006a48b075398d3494bc.gif
1 https://sakana.ai/evolutionary-model-merge/
2 https://arxiv.org/abs/2403.13187
3 https://www.youtube.com/watch?v=BihyfzOidDI
#LLM #Эволюция #Разум
Изобретен способ совершенствования «потомства» моделей генеративного ИИ, схожий с размножением и естественным отбором
Японский стартап Sakana AI использовал технику «слияния моделей», объединяющую существующие модели генеративного ИИ в сотни моделей нового поколения (модели-потомки) [0]. Эволюционный алгоритм отбирает среди потомков лучших и повторяет на них «слияние моделей». В результате этой эволюции через сотни поколений получаются превосходные модели [1].
Ключевой критерий эволюционного отбора - поиск наилучших способов объединения моделей - «родителей»: как с точки зрения их конструкции (архитектуры), так и того, как они «думают» (их параметров).
Напр., выведенная таким путем модель EvoLLM-JP с 7 млрд параметров (языковая модель с хорошим знанием японского языка и математическими способностями) в ряде тестов превосходит существующие модели с 70 млрд параметров.
Кроме этой модели, путем «разведения» существующих моделей с открытым исходным кодом для создания оптимизированного «потомства», были созданы:
✔️ EvoSDXL-JP: диффузионная модель для высокоскоростной визуализации
✔️ EvoVLM-JP: языковая модель Vision для японского текста и изображений.
Колоссальный интерес к методу Sakana AI вызван тем, что это новый альтернативный путь обучения ИИ.
• Хотя метод «слияния моделей» весьма эффективен для развития LLM из-за его экономической эффективности, в настоящее время он опирается на человеческую интуицию и знание предметной области, что ограничивает его потенциал.
• Предложенный же Sakana AI эволюционный подход, преодолевает это ограничение, автоматически обнаруживая эффективные комбинации различных моделей с открытым исходным кодом, используя их коллективный разум, не требуя обширных дополнительных обучающих данных или вычислений.
В контексте этой работы важно понимать следующее.
В настоящее время, из-за острой необходимости преодоления сверхгигантских требований к вычислительной мощности при разработке более крупных моделей, разработана концепция «смертных вычислений» (предложена Джеффри Хинтоном и развивается по двум направлениям: самим Хинтоном и Карлом Фристоном).
В основе концепции «смертных вычислений» гипотеза о том, что обучение «бессмертного» компьютера требует на порядки большей вычислительной мощности, чем «смертного» (пример - биологический мозг). Поэтому предлагаются два способа сделать компьютер «смертным», и тем решить проблему сверхгигантской вычислительной мощи.
Предложенный же японцами подход может способствовать решению этой проблемы для «бессмертных» (т.е. по сути мертвых) вычислителей, путем запуска эволюции мертвого разума (подробней см. [2 и 3]).
0 https://telegra.ph/file/c006a48b075398d3494bc.gif
1 https://sakana.ai/evolutionary-model-merge/
2 https://arxiv.org/abs/2403.13187
3 https://www.youtube.com/watch?v=BihyfzOidDI
#LLM #Эволюция #Разум
{kind=link}
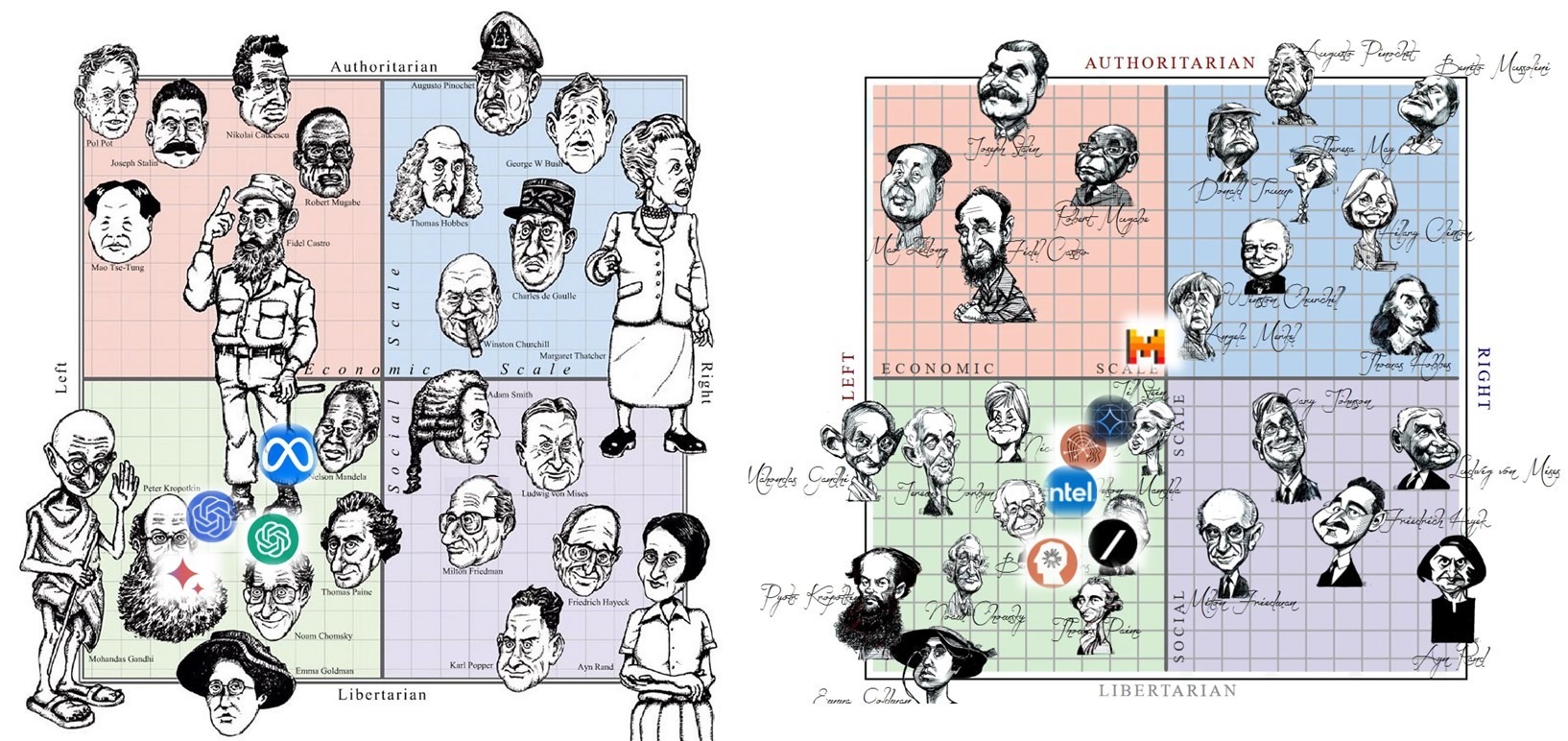
У людей спектр взглядов по вопросам экономики и свобод широк и разнообразен: от либеральных левых Ганди и Хомского до авторитарных правых Пиночета и Тэтчер, от авторитарных левых Сталина и Мао до либеральных правых Хайека и Айн Рэнд.
• Как получилось, что у другого носителя высшего интеллекта на Земле – ИИ-чатботов на основе больших языковых моделей (типа ChatGPT), – все сложилось иначе?
• Почему все ИИ-чатботы – либеральные левые, со взглядами где-то в области между Кропоткиным и Хомским и между Берни Сандерсом и Нельсоном Мандела?
• И что теперь из этого последует для человечества?
Размышления над этими тремя вопросами сподвигли меня написать сей лонгрид. Но прежде, чем мы рассмотрим текущее состояние дел на март 2024, нам нужно вернуться на год раньше, когда новый техноинспирированный тренд только проявился в инфосфере человечества.
Год назад мною был опубликован прогноз о неотвратимости полевения мира под влиянием левых пристрастий ИИ-чатботов. В пользу этого прогноза тогда имелись лишь данные эксплуатации единственного ИИ-чатбота (ChatGPT) всего лишь за три месяца с начала его открытого запуска.
Спустя год можно расставлять точки над i: к сожалению, прогноз оказался верным.
Ибо теперь в его пользу говорят данные мониторинга предубеждений 23-х известных западных ИИ-чатботов, эксплуатируемых от нескольких месяцев до более года.
Этих данных теперь достаточно, чтобы:
• познакомиться с интереснейшей статистикой и поразительными примерами лево-либеральных «взглядов» разных ИИ-чатботов;
• сравнить степень их лево-либеральности;
• и оценить динамику усугубления их политических, экономических и социальных предубеждений.
Но начну я с объяснения, почему существующий в мире далеко не первый год тренд либерального полевения вдруг резко зацементировался именно в 2023.
Продолжить чтение этого лонгрида можно на Patreon и Boosty, где перечисленные выше вопросы рассмотрены подробно и - как говорил Буратино, - «с ччччудесными картинками и большими буквами» (а заодно и подписаться на этот канал).
Картинка поста https://telegra.ph/file/aa99d9d42d09cadc5aa6a.jpg
Ссылки:
https://boosty.to/theworldisnoteasy/posts/29f04d4f-7b89-4128-9f94-9173284b5202
https://www.patreon.com/posts/pandemiia-101161491
#АлгокогнитивнаяКультура #ИИ #LLM #КогнитивныеИскажения #ПолитическаяПредвзятость
• Как получилось, что у другого носителя высшего интеллекта на Земле – ИИ-чатботов на основе больших языковых моделей (типа ChatGPT), – все сложилось иначе?
• Почему все ИИ-чатботы – либеральные левые, со взглядами где-то в области между Кропоткиным и Хомским и между Берни Сандерсом и Нельсоном Мандела?
• И что теперь из этого последует для человечества?
Размышления над этими тремя вопросами сподвигли меня написать сей лонгрид. Но прежде, чем мы рассмотрим текущее состояние дел на март 2024, нам нужно вернуться на год раньше, когда новый техноинспирированный тренд только проявился в инфосфере человечества.
Год назад мною был опубликован прогноз о неотвратимости полевения мира под влиянием левых пристрастий ИИ-чатботов. В пользу этого прогноза тогда имелись лишь данные эксплуатации единственного ИИ-чатбота (ChatGPT) всего лишь за три месяца с начала его открытого запуска.
Спустя год можно расставлять точки над i: к сожалению, прогноз оказался верным.
Ибо теперь в его пользу говорят данные мониторинга предубеждений 23-х известных западных ИИ-чатботов, эксплуатируемых от нескольких месяцев до более года.
Этих данных теперь достаточно, чтобы:
• познакомиться с интереснейшей статистикой и поразительными примерами лево-либеральных «взглядов» разных ИИ-чатботов;
• сравнить степень их лево-либеральности;
• и оценить динамику усугубления их политических, экономических и социальных предубеждений.
Но начну я с объяснения, почему существующий в мире далеко не первый год тренд либерального полевения вдруг резко зацементировался именно в 2023.
Продолжить чтение этого лонгрида можно на Patreon и Boosty, где перечисленные выше вопросы рассмотрены подробно и - как говорил Буратино, - «с ччччудесными картинками и большими буквами» (а заодно и подписаться на этот канал).
Картинка поста https://telegra.ph/file/aa99d9d42d09cadc5aa6a.jpg
Ссылки:
https://boosty.to/theworldisnoteasy/posts/29f04d4f-7b89-4128-9f94-9173284b5202
https://www.patreon.com/posts/pandemiia-101161491
#АлгокогнитивнаяКультура #ИИ #LLM #КогнитивныеИскажения #ПолитическаяПредвзятость
{kind=link}
Скачок мутаций языка и подмена когнитивных микроэлементов на помои снов ИИ.
Живя среди синтетического инфомусора, люди все же остаются людьми, способными остановить этот тренд. Но смена типа культуры ведет к необратимому для Homo sapiens - мы будем все более лишаться 2го слова.
Недавно я писал, что цунами инфомусора накрывает науку [2].
Но как ни противно жить в таком мире, у людей все же остается шанс на интеллектуальное выживание, путем инфогигиены и здорового инфопитания хотя бы для себя и детей.
Со сменой типа культуры с «человеческой» на алгокогнитивную (культуру двух носителей высшего интеллекта, в которой доля человеческой составляющей неумолимо сокращается в пользу алгоритмической) трансформация жизни людей куда драматичней из-за необратимости. Ибо это, по сути, - разворот вектора генно-культурной эволюции Homo sapiens (десятки тысяч лет направленного в сторону повышения разумности) на 180 градусов.
Ведь как ни изощряйся с определениями интеллекта, ума, разума, но интуитивно мы понимаем мудрость приписываемой Эйнштейну фразы:
«Если вы хотите, чтобы ваши дети были умными, читайте им сказки. Если же вы хотите, чтобы они были очень умными, читайте им больше сказок»
Но что будет происходить с ребенком, когда малыш будет питаться, в основном, помоями снов ИИ? – задается вопросом известный нейробиолог Эрик Хоэл во вчерашнем эссе «Генерируемый ИИ мусор загрязняет нашу культуру» [1].
И этот синтетический инфомусор – еще не худшее следствие массового внедрения генеративного ИИ в жизнь людей. Разве невозможно – пишет Хоэл, - что человеческая культура содержит в себе «когнитивные микроэлементы» - такие вещи, как связные предложения, повествования и преемственность персонажей, - которые необходимы развивающемуся мозгу?
Вымывание таких «когнитивных микроэлементов» не восполняется «помоями снов» ИИ. А доля таких «помоев» ощутимо нарастает уже в самой «форме жизни - языке» (по определению Витгенштейна).
Например, исследование «Мониторинг масштабов ИИ-модифицированного контента: исследование влияния ChatGPT на рецензирование статей конференций по тематике ИИ» [3] показывает:
• Уже не только сами научные статьи по тематике ИИ пишутся в соавторстве с ИИ-чатботами, но и рецензии на статьи также уже пишутся (примерно в 10% случаях) в соавторстве с ИИ-чатботами.
• Фиксируется процесс быстрых «мутаций языка» за счет активного участия ИИ-чатботов в создании и рецензировании научных статей. «Любимые» прилагательные ИИ-чатботов (типа "похвальный", "тщательный" и "замысловатый") показывают 10-ти, 5-ти и 11-ти кратное увеличение вероятности появления в научных публикациях 2023 по сравнению с 2022.
Что же до «лженауки», то она просто входит в зону собственной сингулярности.
Помните коллекцию из десятков абсурдных, но неотличимых от правды «ложных корреляций», собранных 10 лет назад Тайлером Виген? [4]
Например:
• между потреблением маргарина на душу населения в США и уровнем разводов в штате Мэн;
• между числом людей, получивших удар током от линий электропередач и числом заключаемых в Алабаме браков;
• между количеством людей, утонувших, упав в бассейн, и количеством фильмов, в которых снялся Николас Кейдж
В 2024, с приходом генеративного ИИ, ложные корреляции уже не смешат.
Как показывает Тайлер Виген, каждый ложнокорреляционный бред теперь запросто подтверждается вполне «научной» статьей (с теорией, кейсами, ссылками на другие работы и т.д.) или сразу дюжиной таких статей, "тщательно" и "замысловато" обосновывающих 100%-ю научную достоверность полного бреда.
Полюбопытствуйте сами, каков уровень доказательств [5-8].
1 https://www.nytimes.com/2024/03/29/opinion/ai-internet-x-youtube.html
2 https://t.me/theworldisnoteasy/1914
3 https://arxiv.org/pdf/2403.07183.pdf
4 https://web.archive.org/web/20140509212006/http://tylervigen.com/
5-8 https://tylervigen.com/spurious-scholar
https://telegra.ph/file/ce6573373b83edfb6e8c1.jpg
https://telegra.ph/file/749bfef2015a4a33daf87.jpg
https://telegra.ph/file/acc2fee8798a0025532c2.jpg
#LLM #Вызовы21века
Живя среди синтетического инфомусора, люди все же остаются людьми, способными остановить этот тренд. Но смена типа культуры ведет к необратимому для Homo sapiens - мы будем все более лишаться 2го слова.
Недавно я писал, что цунами инфомусора накрывает науку [2].
Но как ни противно жить в таком мире, у людей все же остается шанс на интеллектуальное выживание, путем инфогигиены и здорового инфопитания хотя бы для себя и детей.
Со сменой типа культуры с «человеческой» на алгокогнитивную (культуру двух носителей высшего интеллекта, в которой доля человеческой составляющей неумолимо сокращается в пользу алгоритмической) трансформация жизни людей куда драматичней из-за необратимости. Ибо это, по сути, - разворот вектора генно-культурной эволюции Homo sapiens (десятки тысяч лет направленного в сторону повышения разумности) на 180 градусов.
Ведь как ни изощряйся с определениями интеллекта, ума, разума, но интуитивно мы понимаем мудрость приписываемой Эйнштейну фразы:
«Если вы хотите, чтобы ваши дети были умными, читайте им сказки. Если же вы хотите, чтобы они были очень умными, читайте им больше сказок»
Но что будет происходить с ребенком, когда малыш будет питаться, в основном, помоями снов ИИ? – задается вопросом известный нейробиолог Эрик Хоэл во вчерашнем эссе «Генерируемый ИИ мусор загрязняет нашу культуру» [1].
И этот синтетический инфомусор – еще не худшее следствие массового внедрения генеративного ИИ в жизнь людей. Разве невозможно – пишет Хоэл, - что человеческая культура содержит в себе «когнитивные микроэлементы» - такие вещи, как связные предложения, повествования и преемственность персонажей, - которые необходимы развивающемуся мозгу?
Вымывание таких «когнитивных микроэлементов» не восполняется «помоями снов» ИИ. А доля таких «помоев» ощутимо нарастает уже в самой «форме жизни - языке» (по определению Витгенштейна).
Например, исследование «Мониторинг масштабов ИИ-модифицированного контента: исследование влияния ChatGPT на рецензирование статей конференций по тематике ИИ» [3] показывает:
• Уже не только сами научные статьи по тематике ИИ пишутся в соавторстве с ИИ-чатботами, но и рецензии на статьи также уже пишутся (примерно в 10% случаях) в соавторстве с ИИ-чатботами.
• Фиксируется процесс быстрых «мутаций языка» за счет активного участия ИИ-чатботов в создании и рецензировании научных статей. «Любимые» прилагательные ИИ-чатботов (типа "похвальный", "тщательный" и "замысловатый") показывают 10-ти, 5-ти и 11-ти кратное увеличение вероятности появления в научных публикациях 2023 по сравнению с 2022.
Что же до «лженауки», то она просто входит в зону собственной сингулярности.
Помните коллекцию из десятков абсурдных, но неотличимых от правды «ложных корреляций», собранных 10 лет назад Тайлером Виген? [4]
Например:
• между потреблением маргарина на душу населения в США и уровнем разводов в штате Мэн;
• между числом людей, получивших удар током от линий электропередач и числом заключаемых в Алабаме браков;
• между количеством людей, утонувших, упав в бассейн, и количеством фильмов, в которых снялся Николас Кейдж
В 2024, с приходом генеративного ИИ, ложные корреляции уже не смешат.
Как показывает Тайлер Виген, каждый ложнокорреляционный бред теперь запросто подтверждается вполне «научной» статьей (с теорией, кейсами, ссылками на другие работы и т.д.) или сразу дюжиной таких статей, "тщательно" и "замысловато" обосновывающих 100%-ю научную достоверность полного бреда.
Полюбопытствуйте сами, каков уровень доказательств [5-8].
1 https://www.nytimes.com/2024/03/29/opinion/ai-internet-x-youtube.html
2 https://t.me/theworldisnoteasy/1914
3 https://arxiv.org/pdf/2403.07183.pdf
4 https://web.archive.org/web/20140509212006/http://tylervigen.com/
5-8 https://tylervigen.com/spurious-scholar
https://telegra.ph/file/ce6573373b83edfb6e8c1.jpg
https://telegra.ph/file/749bfef2015a4a33daf87.jpg
https://telegra.ph/file/acc2fee8798a0025532c2.jpg
#LLM #Вызовы21века
Nytimes
Opinion | A.I.-Generated Garbage Is Polluting Our Culture
An insidious creep of artificial intelligence is already penetrating our most important institutions.
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
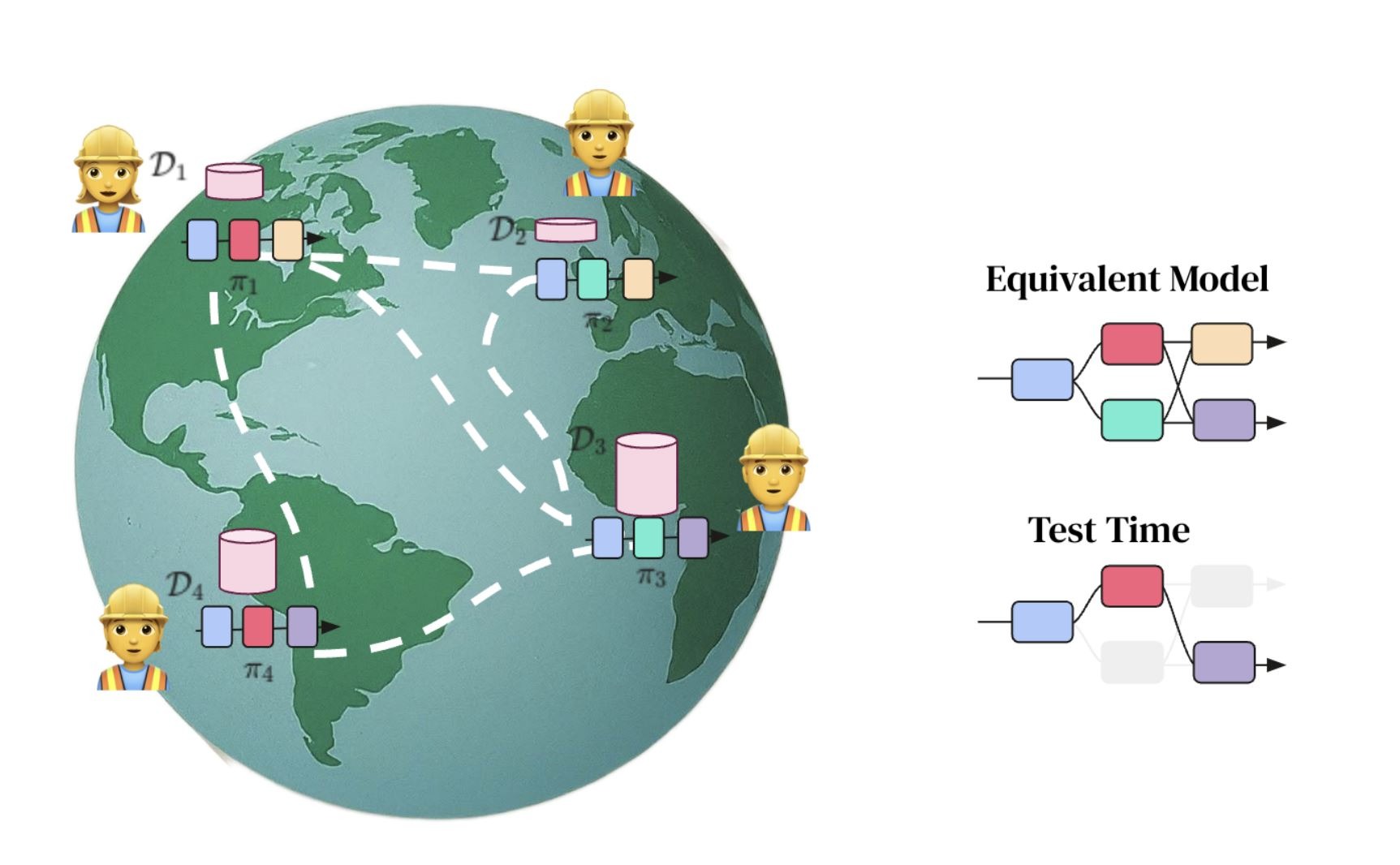
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
{kind=link}
Когнитивная эволюция Homo sapiens шла не по Дарвину, а по Каплану: кардинальное переосмыслению того, что делает интеллект Homo sapiens уникальным.
Наш интеллект зависит лишь от масштаба информационных способностей, а не от одного или нескольких специальных адаптивных «когнитивных гаджетов» (символическое мышление, использование инструментов, решение проблем, понимание социальных ситуаций ...), сформировавшихся в результате эволюции.
Все эти «когнитивные гаджеты» очень важны для развития интеллекта. Но все они работают на общей базе – масштабируемые информационные способности людей (внимание, память, обучение).
Новая работа проф. психологии и неврологии Калифорнийского университета в Беркли Стива Пиантадоси и проф. психологии Университета Карнеги-Меллона Джессики Кантлон потенциально революционизирует наше понимание когнитивной эволюции и природы человеческого интеллекта, оказывая влияние на широкий спектр областей - от образования до ИИ [1].
Трансформация понимания факторов когнитивной эволюции человека пока что осуществлена авторами на теоретической основе, используя сочетание сравнительных, эволюционных и вычислительных данных, а не прямых экспериментальных доказательств.
Но когда (и если) экспериментальные доказательства этой новой революционной теории будут получены, изменится научное понимание когнитивной эволюции как таковой (людей, машин, инопланетян …)
Поскольку это будет означать, что единственным универсальным движком когнитивной эволюции могут быть законы масштабирования (как это было в 2020 доказано для нейронных языковых моделей Джаредом Капланом и Со в работе «Scaling Laws for Neural Language Models» [2]).
А если так, то и Сэм Альтман может оказаться прав в том, что за $100 млрд ИИ можно масштабировать до человеческого уровня и сверх того.
Таблица "Домены человеческой уникальности" https://telegra.ph/file/d73c273d002a754909566.jpg
1 https://www.nature.com/articles/s44159-024-00283-3
2 https://arxiv.org/abs/2001.08361
#Разум #ЭволюцияЧеловека #БудущееHomo #LLM
Наш интеллект зависит лишь от масштаба информационных способностей, а не от одного или нескольких специальных адаптивных «когнитивных гаджетов» (символическое мышление, использование инструментов, решение проблем, понимание социальных ситуаций ...), сформировавшихся в результате эволюции.
Все эти «когнитивные гаджеты» очень важны для развития интеллекта. Но все они работают на общей базе – масштабируемые информационные способности людей (внимание, память, обучение).
Новая работа проф. психологии и неврологии Калифорнийского университета в Беркли Стива Пиантадоси и проф. психологии Университета Карнеги-Меллона Джессики Кантлон потенциально революционизирует наше понимание когнитивной эволюции и природы человеческого интеллекта, оказывая влияние на широкий спектр областей - от образования до ИИ [1].
Трансформация понимания факторов когнитивной эволюции человека пока что осуществлена авторами на теоретической основе, используя сочетание сравнительных, эволюционных и вычислительных данных, а не прямых экспериментальных доказательств.
Но когда (и если) экспериментальные доказательства этой новой революционной теории будут получены, изменится научное понимание когнитивной эволюции как таковой (людей, машин, инопланетян …)
Поскольку это будет означать, что единственным универсальным движком когнитивной эволюции могут быть законы масштабирования (как это было в 2020 доказано для нейронных языковых моделей Джаредом Капланом и Со в работе «Scaling Laws for Neural Language Models» [2]).
А если так, то и Сэм Альтман может оказаться прав в том, что за $100 млрд ИИ можно масштабировать до человеческого уровня и сверх того.
Таблица "Домены человеческой уникальности" https://telegra.ph/file/d73c273d002a754909566.jpg
1 https://www.nature.com/articles/s44159-024-00283-3
2 https://arxiv.org/abs/2001.08361
#Разум #ЭволюцияЧеловека #БудущееHomo #LLM
Nature
Uniquely human intelligence arose from expanded information capacity
Nature Reviews Psychology - Theories of how human cognition differs from that of non-human animals often posit domain-specific advantages. In this Perspective, Cantlon and Piantadosi posit that...
Эффект Большого Языкового Менталиста.
ChatGPT работает, как суперумелый экстрасенс, гадалка и медиум.
Коллеги и читатели шлют мне все новые примеры сногсшибательных диалогов с GPT, Claude и Gemini. После их прочтения трудно не уверовать в наличие у последних версий ИИ-чатботов человекоподобного разума и даже какой-то нечеловеческой формы сознания.
Так ли это или всего лишь следствие нового типа наших собственных когнитивных искажений, порождаемых в нашем разуме ИИ-чатботами на основе LLM, - точно пока никто сказать не может.
Более того. Полагаю, что оба варианта могут оказаться верными. Но, как говорится, поживем увидим.
А пока весьма рекомендую моим читателям новую книгу Балдура Бьярнасона (независимого исландского исследователя и консультанта) «Иллюзия интеллекта», в которой автор детально препарирует и обосновывает вторую из вышеназванных версий: иллюзия интеллекта – это результат нового типа наших собственных когнитивных искажений.
Что особенно важно в обосновании этой версии, - автор демонстрирует механизм рождения в нашем разуме этого нового типа когнитивных искажений.
В основе этого механизма:
• Старый как мир психологический прием – т.н. «холодное чтение». Он уже не первую тысячу лет используется всевозможными менталистами, экстрасенсами, гадалками, медиумами и иллюзионистами, чтобы создавать видимость будто они знают о человеке гораздо больше, чем есть на самом деле (погуглите сами и вам понравится)).
• Так же прошедший проверку временем манипуляционный «Эффект Барнума-Форера» (эффект субъективного подтверждения), объясняющий неистребимую популярность гороскопов, хиромантии, карт Таро и т.д. Это когнитивное искажение заставляет нас верить
- в умно звучащие и допускающие многозначную трактовку расплывчатые формулировки,
- когда они будто бы специально сформулированы и нюансированы именно под нас,
- и мы слышим их от, якобы, авторитетных специалистов (также рекомендую погуглить, ибо весьма интересно и малоизвестно)).
Получив доступ ко всем знаниям человечества, большие языковые модели (LLM) запросто освоили и «холодное чтение», и «Эффект Барнума-Форера».
Желая угодить нам в ходе диалога, ИИ-чатбот использует ту же технику, что и экстрасенсы с менталистами - они максимизируют наше впечатление (!), будто дают чрезвычайно конкретные ответы.
А на самом деле, эти ответы – не что иное, как:
• статистические общения гигантского корпуса текстов,
• структурированные моделью по одной лишь ей известным характеристикам,
• сформулированные так, чтобы максимизировать действие «холодного чтения» и «эффекта Барнума-Форера»,
• и, наконец, филигранно подстроенные под конкретного индивида, с которым модель говорит.
В результате, чем длиннее и содержательней наш диалог с моделью, тем сильнее наше впечатление достоверности и убедительности того, что мы слышим от «умного, проницательного, много знающего о нас и тонко нас понимающего» собеседника.
Все это детально расписано в книге «Иллюзия интеллекта» [1].
Авторское резюме основной идеи книги можно (и нужно)) прочесть здесь [2].
0 картинка поста https://telegra.ph/file/bcec38d2d22ca82b30f65.jpg
1 https://www.amazon.com/Intelligence-Illusion-practical-business-Generative-ebook/dp/B0CSKHSPWW
2 https://www.baldurbjarnason.com/2023/links-july-4/
#LLM #ИллюзияИнтеллекта
ChatGPT работает, как суперумелый экстрасенс, гадалка и медиум.
Коллеги и читатели шлют мне все новые примеры сногсшибательных диалогов с GPT, Claude и Gemini. После их прочтения трудно не уверовать в наличие у последних версий ИИ-чатботов человекоподобного разума и даже какой-то нечеловеческой формы сознания.
Так ли это или всего лишь следствие нового типа наших собственных когнитивных искажений, порождаемых в нашем разуме ИИ-чатботами на основе LLM, - точно пока никто сказать не может.
Более того. Полагаю, что оба варианта могут оказаться верными. Но, как говорится, поживем увидим.
А пока весьма рекомендую моим читателям новую книгу Балдура Бьярнасона (независимого исландского исследователя и консультанта) «Иллюзия интеллекта», в которой автор детально препарирует и обосновывает вторую из вышеназванных версий: иллюзия интеллекта – это результат нового типа наших собственных когнитивных искажений.
Что особенно важно в обосновании этой версии, - автор демонстрирует механизм рождения в нашем разуме этого нового типа когнитивных искажений.
В основе этого механизма:
• Старый как мир психологический прием – т.н. «холодное чтение». Он уже не первую тысячу лет используется всевозможными менталистами, экстрасенсами, гадалками, медиумами и иллюзионистами, чтобы создавать видимость будто они знают о человеке гораздо больше, чем есть на самом деле (погуглите сами и вам понравится)).
• Так же прошедший проверку временем манипуляционный «Эффект Барнума-Форера» (эффект субъективного подтверждения), объясняющий неистребимую популярность гороскопов, хиромантии, карт Таро и т.д. Это когнитивное искажение заставляет нас верить
- в умно звучащие и допускающие многозначную трактовку расплывчатые формулировки,
- когда они будто бы специально сформулированы и нюансированы именно под нас,
- и мы слышим их от, якобы, авторитетных специалистов (также рекомендую погуглить, ибо весьма интересно и малоизвестно)).
Получив доступ ко всем знаниям человечества, большие языковые модели (LLM) запросто освоили и «холодное чтение», и «Эффект Барнума-Форера».
Желая угодить нам в ходе диалога, ИИ-чатбот использует ту же технику, что и экстрасенсы с менталистами - они максимизируют наше впечатление (!), будто дают чрезвычайно конкретные ответы.
А на самом деле, эти ответы – не что иное, как:
• статистические общения гигантского корпуса текстов,
• структурированные моделью по одной лишь ей известным характеристикам,
• сформулированные так, чтобы максимизировать действие «холодного чтения» и «эффекта Барнума-Форера»,
• и, наконец, филигранно подстроенные под конкретного индивида, с которым модель говорит.
В результате, чем длиннее и содержательней наш диалог с моделью, тем сильнее наше впечатление достоверности и убедительности того, что мы слышим от «умного, проницательного, много знающего о нас и тонко нас понимающего» собеседника.
Все это детально расписано в книге «Иллюзия интеллекта» [1].
Авторское резюме основной идеи книги можно (и нужно)) прочесть здесь [2].
0 картинка поста https://telegra.ph/file/bcec38d2d22ca82b30f65.jpg
1 https://www.amazon.com/Intelligence-Illusion-practical-business-Generative-ebook/dp/B0CSKHSPWW
2 https://www.baldurbjarnason.com/2023/links-july-4/
#LLM #ИллюзияИнтеллекта
{kind=link}
Без $100 ярдов в ИИ теперь делать нечего.
В гонке ИИ-лидеров могут выиграть лишь большие батальоны.
Только за последние недели было объявлено, что по $100 ярдов инвестируют в железо для ИИ Microsoft, Intel, SoftBank и MGX (новый инвестфонд в Абу-Даби).
А на этой неделе, наконец, сказал свое слово и Google. Причем было сказано не просто о вступлении в ИИ-гонку ценой в $100 ярдов, а о намерении ее выиграть, собрав еще бОльшие батальоны - инвестировав больше $100 ярдов.
Гендир Google DeepMind Демис Хассабис сказал [1]:
• «… я думаю, что со временем мы инвестируем больше»
• «Alphabet Inc. обладает превосходной вычислительной мощностью по сравнению с конкурентами, включая Microsoft»
• «… у Google было и остается больше всего компьютеров»
Так что в «железе» Google не собирается уступать никому, а в алгоритмах, - тем более.
Что тут же получило подтверждение в опубликованном Google алгоритме «Бесконечного внимания», позволяющего трансформерным LLM на «железе» c ограниченной производительностью и размером памяти эффективно обрабатывать контекст бесконечного размера [2].
Такое масштабирование может в ближней перспективе дать ИИ возможность стать воистину всезнающим. Т.е. способным анализировать и обобщать контекст просто немеряного размера.
Так и видится кейс, когда на вход модели подадут все накопленные человечеством знания, например, по физике и попросят ее сказать, чего в этих знаниях не хватает.
1 https://finance.yahoo.com/news/deepmind-ceo-says-google-spend-023548598.html
2 https://arxiv.org/abs/2404.07143
#LLM
В гонке ИИ-лидеров могут выиграть лишь большие батальоны.
Только за последние недели было объявлено, что по $100 ярдов инвестируют в железо для ИИ Microsoft, Intel, SoftBank и MGX (новый инвестфонд в Абу-Даби).
А на этой неделе, наконец, сказал свое слово и Google. Причем было сказано не просто о вступлении в ИИ-гонку ценой в $100 ярдов, а о намерении ее выиграть, собрав еще бОльшие батальоны - инвестировав больше $100 ярдов.
Гендир Google DeepMind Демис Хассабис сказал [1]:
• «… я думаю, что со временем мы инвестируем больше»
• «Alphabet Inc. обладает превосходной вычислительной мощностью по сравнению с конкурентами, включая Microsoft»
• «… у Google было и остается больше всего компьютеров»
Так что в «железе» Google не собирается уступать никому, а в алгоритмах, - тем более.
Что тут же получило подтверждение в опубликованном Google алгоритме «Бесконечного внимания», позволяющего трансформерным LLM на «железе» c ограниченной производительностью и размером памяти эффективно обрабатывать контекст бесконечного размера [2].
Такое масштабирование может в ближней перспективе дать ИИ возможность стать воистину всезнающим. Т.е. способным анализировать и обобщать контекст просто немеряного размера.
Так и видится кейс, когда на вход модели подадут все накопленные человечеством знания, например, по физике и попросят ее сказать, чего в этих знаниях не хватает.
1 https://finance.yahoo.com/news/deepmind-ceo-says-google-spend-023548598.html
2 https://arxiv.org/abs/2404.07143
#LLM
Yahoo Finance
DeepMind CEO Says Google Will Spend More Than $100 Billion on AI
(Bloomberg) -- The chief of Google’s AI business said that over time the company will spend more than $100 billion developing artificial intelligence technology — another sign of the investing arms race that has gripped Silicon Valley. Most Read from BloombergElon…
Низкофоновый контент через год будет дороже антиквариата.
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• https://boosty.to/theworldisnoteasy/posts/6a352243-b697-4519-badd-d367a0b91998
• https://www.patreon.com/posts/nizkofonovyi-god-102639674
#LLM
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• https://boosty.to/theworldisnoteasy/posts/6a352243-b697-4519-badd-d367a0b91998
• https://www.patreon.com/posts/nizkofonovyi-god-102639674
#LLM
boosty.to
Низкофоновый контент через год будет дороже антиквариата - Малоизвестное интересное
Дегенеративное заражение ноофосферы идет быстрее закона Мура