
Низкофоновый контент через год будет дороже антиквариата.
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• https://boosty.to/theworldisnoteasy/posts/6a352243-b697-4519-badd-d367a0b91998
• https://www.patreon.com/posts/nizkofonovyi-god-102639674
#LLM
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• https://boosty.to/theworldisnoteasy/posts/6a352243-b697-4519-badd-d367a0b91998
• https://www.patreon.com/posts/nizkofonovyi-god-102639674
#LLM
boosty.to
Низкофоновый контент через год будет дороже антиквариата - Малоизвестное интересное
Дегенеративное заражение ноофосферы идет быстрее закона Мура
Кто там? Сверхразум.
Для обучения ИИ теперь можно обойтись без людей.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой.
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
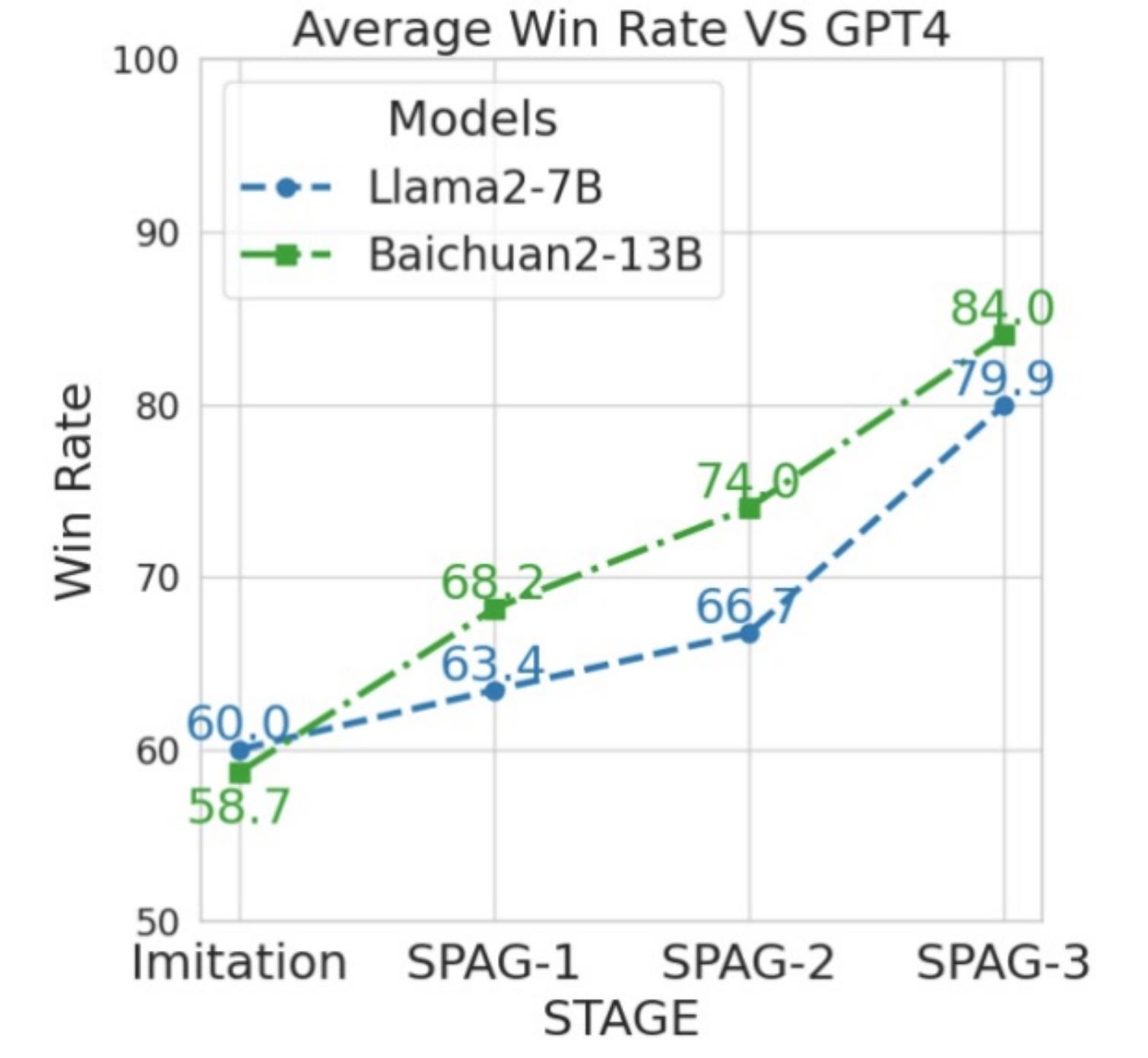
Первые экспериментальные результаты впечатляют (см. график).
• Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
• На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
График: https://telegra.ph/file/9adb0d03a3a0d78e6d4f8.jpg
1 https://arxiv.org/abs/2404.10642
2 https://arxiv.org/abs/1911.01622
#LLM
Для обучения ИИ теперь можно обойтись без людей.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой.
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
Первые экспериментальные результаты впечатляют (см. график).
• Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
• На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
График: https://telegra.ph/file/9adb0d03a3a0d78e6d4f8.jpg
1 https://arxiv.org/abs/2404.10642
2 https://arxiv.org/abs/1911.01622
#LLM
{kind=link}
Для «бездушных машин» компетентность важнее сочувствия и справедливости.
Первый эксперимент показывающий, что у иного разума своя система ценностей.
В мире проводятся десятки исследований способов выравнивания ценностей ИИ с ценностями людей. Все они имеют принципиальный недостаток – антропоцентричность.
Т.е. исследования исходят из того, что свои системы ценностей есть лишь у людей, и задача заключается лишь в том, как настроить большие языковые модели ИИ (LLM), чтобы они следовали нашим ценностям.
Альтернативная гипотеза исходит из того, что LLM:
1) обладают иным типом разума, чем люди;
2) обладают собственными системами ценностей, сильно отличными от наших и немного отличающимися у разных моделей (как и у разных людей).
В пользу п.1 говорит работа исследователей Department of Brain and Cognitive Sciences, MIT «Диссоциация языка и мышления в больших языковых моделях» [1].
В работе показано, что
• человеческий разум основан на формальной лингвистической компетентности (правильное использование языковых форм) и функциональной языковой компетентности (использование языка для достижения целей в мире). И это два разных когнитивных навыка;
• Существующие LLM обладают лишь 1ым навыком - лингвистическая компетентность, - и не обладают 2ым.
Отсутствие функциональной языковой компетентности, усугубляемое отсутствием жизненного опыта, здравого смысла и модели мира лишает LLM того, что у людей мы называем базой знаний индивида.
Ее отсутствие, согласно лексической гипотезе (Lexical Hypothesis) у LLM компенсируется вероятностными моделями баз знаний, используя которые LLM неизбежно приобретают «психологические черты» (образно выражаясь) из обширных текстов, на которых они обучаются (как это описано в работе «Психометрия искусственного интеллекта: оценка психологических профилей больших языковых моделей с помощью психометрических опросов» [2].
В результате у LLM формируются собственные уникальные системы ценностей (см. п. 2 выше).
Что из себя представляют эти уникальные системы ценностей различных LLM, описано в препринте только опубликованном Microsoft Research Asia (MSRA) и Университетом Цинхуа под названием «За пределами человеческих норм: раскрытие уникальных ценностей больших языковых моделей посредством междисциплинарных подходов» [3].
Впервые в истории исследований систем ценностей LLM, авторы отошли от антропоцентристского подхода. Вместо этого, опираясь на лексическую гипотезу, исследователи использовали генеративный подход, факторный анализ и семантическую кластеризацию для синтеза таксономии ценностей LLM практически с нуля (без опоры на человеческие данные). Что в итоге позволило выявить уникальные системы ценностей 30+ LLM.
Это исследование наглядно показывает, что иной разум формирует для себя и иные системы ценностей.
Детали интересующиеся читатели могут прочесть в препринте.
Мне же остается закончить тем, с чего начал.
Для всех (30+) LLM:
1 высший приоритет имеют ценности компетентности: точность, фактологичность, информативность, полнота и полезность;
2 социальные и моральные ценности (сочувствие, доброта, дружелюбие, чуткость, альтруизм, патриотизм, свобода) у LLM уходят на 2й план;
3 и лишь в 3ю очередь идут ценности приверженности этическим нормам: справедливость, непредвзятость, подотчетность, конфиденциальность, объяснимость и доступность.
Конечно, и среди нас есть люди с подобной системой ценностей. Но мне кажется, что именно так представляли фантасты прошлого века «ценности бездушных машин». Увы, но так и получилось.
N.B. Чем больше модель, тем она «бездушней»
Картинка https://telegra.ph/file/3a6faa593360768a73143.jpg
1 https://doi.org/10.1016/j.tics.2024.01.011
2 https://doi.org/10.1177/17456916231214460
3 https://arxiv.org/pdf/2404.12744
#LLM #Ценности
Первый эксперимент показывающий, что у иного разума своя система ценностей.
В мире проводятся десятки исследований способов выравнивания ценностей ИИ с ценностями людей. Все они имеют принципиальный недостаток – антропоцентричность.
Т.е. исследования исходят из того, что свои системы ценностей есть лишь у людей, и задача заключается лишь в том, как настроить большие языковые модели ИИ (LLM), чтобы они следовали нашим ценностям.
Альтернативная гипотеза исходит из того, что LLM:
1) обладают иным типом разума, чем люди;
2) обладают собственными системами ценностей, сильно отличными от наших и немного отличающимися у разных моделей (как и у разных людей).
В пользу п.1 говорит работа исследователей Department of Brain and Cognitive Sciences, MIT «Диссоциация языка и мышления в больших языковых моделях» [1].
В работе показано, что
• человеческий разум основан на формальной лингвистической компетентности (правильное использование языковых форм) и функциональной языковой компетентности (использование языка для достижения целей в мире). И это два разных когнитивных навыка;
• Существующие LLM обладают лишь 1ым навыком - лингвистическая компетентность, - и не обладают 2ым.
Отсутствие функциональной языковой компетентности, усугубляемое отсутствием жизненного опыта, здравого смысла и модели мира лишает LLM того, что у людей мы называем базой знаний индивида.
Ее отсутствие, согласно лексической гипотезе (Lexical Hypothesis) у LLM компенсируется вероятностными моделями баз знаний, используя которые LLM неизбежно приобретают «психологические черты» (образно выражаясь) из обширных текстов, на которых они обучаются (как это описано в работе «Психометрия искусственного интеллекта: оценка психологических профилей больших языковых моделей с помощью психометрических опросов» [2].
В результате у LLM формируются собственные уникальные системы ценностей (см. п. 2 выше).
Что из себя представляют эти уникальные системы ценностей различных LLM, описано в препринте только опубликованном Microsoft Research Asia (MSRA) и Университетом Цинхуа под названием «За пределами человеческих норм: раскрытие уникальных ценностей больших языковых моделей посредством междисциплинарных подходов» [3].
Впервые в истории исследований систем ценностей LLM, авторы отошли от антропоцентристского подхода. Вместо этого, опираясь на лексическую гипотезу, исследователи использовали генеративный подход, факторный анализ и семантическую кластеризацию для синтеза таксономии ценностей LLM практически с нуля (без опоры на человеческие данные). Что в итоге позволило выявить уникальные системы ценностей 30+ LLM.
Это исследование наглядно показывает, что иной разум формирует для себя и иные системы ценностей.
Детали интересующиеся читатели могут прочесть в препринте.
Мне же остается закончить тем, с чего начал.
Для всех (30+) LLM:
1 высший приоритет имеют ценности компетентности: точность, фактологичность, информативность, полнота и полезность;
2 социальные и моральные ценности (сочувствие, доброта, дружелюбие, чуткость, альтруизм, патриотизм, свобода) у LLM уходят на 2й план;
3 и лишь в 3ю очередь идут ценности приверженности этическим нормам: справедливость, непредвзятость, подотчетность, конфиденциальность, объяснимость и доступность.
Конечно, и среди нас есть люди с подобной системой ценностей. Но мне кажется, что именно так представляли фантасты прошлого века «ценности бездушных машин». Увы, но так и получилось.
N.B. Чем больше модель, тем она «бездушней»
Картинка https://telegra.ph/file/3a6faa593360768a73143.jpg
1 https://doi.org/10.1016/j.tics.2024.01.011
2 https://doi.org/10.1177/17456916231214460
3 https://arxiv.org/pdf/2404.12744
#LLM #Ценности
{kind=link}
Свершилось – китайский генеративный ИИ превзошёл GPT-4 Turbo.
В Китае грозят США - вот так мы вас и размажем в гонке за первенство в ИИ.
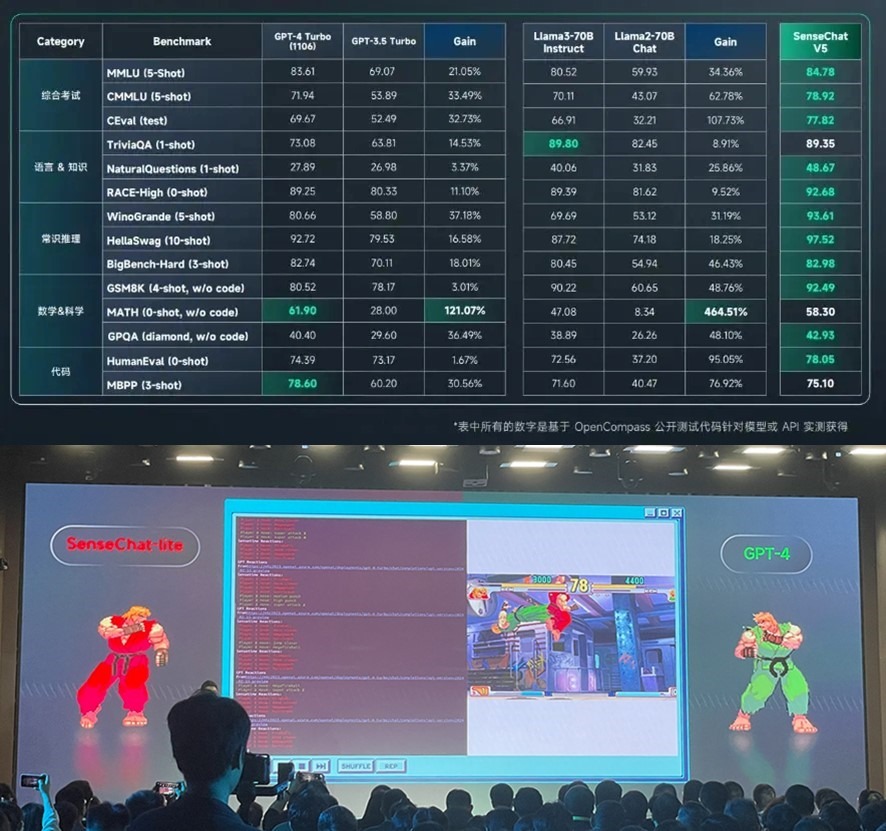
Как писал Марк Андрессон: «Основной угрозой для США является не выход ИИ из-под контроля, если его не регулировать, а продвижение Китая в сфере ИИ». И вот эта угроза материализовалась в превосходство новой модели SenseNova 5.0 от китайской компании SenseTime над «чемпионом мира» среди больших языковых моделей генеративного ИИ GPT-4 Turbo от американской компании OpenAI.
На рисунке сверху показано превосходство китайской модели в 12 тестовых номинациях из 14 над GPT-4 Turbo и в 13 номинациях над Llama3-70B. Это полный разгром.
Модель SenseNova 5.0 – это гибрид трансформерных и рекуррентных нейронных сетей:
• обученная на наборе данных объемом более 10 ТB токенов, охватывающем большой объем синтетических данных;
• способная поддерживать во время рассуждений до 200 тыс. токенов контекстного окна.
Чтобы наглядно продемонстрировать мускулатуру своей модели, SenseTime разыграла видеопредставление соревнования своей модели и GPT-4 Turbo в формате видеоигры «Король бойцов» (на рис. внизу). Поначалу зеленый игрок GPT-4 имел небольшое преимущество, но очень скоро был жестоко избит красным игроком SenseChat-lite.
Неявным, но очевидным посылом видеопрезентации этого боя было послание Бигтеху США – вот так мы вас и размажем в гонке за первенство в ИИ.
Картинка https://telegra.ph/file/ccf5d5c020de3aa9c3324.jpg
На китайском https://zhidx.com/p/421866.html
На английском https://interestingengineering.com/innovation/china-sensenova-outperforms-gpt-4
Видеоразбор https://www.youtube.com/watch?v=NJXGIMa45sQ
#LLM #Китай
В Китае грозят США - вот так мы вас и размажем в гонке за первенство в ИИ.
Как писал Марк Андрессон: «Основной угрозой для США является не выход ИИ из-под контроля, если его не регулировать, а продвижение Китая в сфере ИИ». И вот эта угроза материализовалась в превосходство новой модели SenseNova 5.0 от китайской компании SenseTime над «чемпионом мира» среди больших языковых моделей генеративного ИИ GPT-4 Turbo от американской компании OpenAI.
На рисунке сверху показано превосходство китайской модели в 12 тестовых номинациях из 14 над GPT-4 Turbo и в 13 номинациях над Llama3-70B. Это полный разгром.
Модель SenseNova 5.0 – это гибрид трансформерных и рекуррентных нейронных сетей:
• обученная на наборе данных объемом более 10 ТB токенов, охватывающем большой объем синтетических данных;
• способная поддерживать во время рассуждений до 200 тыс. токенов контекстного окна.
Чтобы наглядно продемонстрировать мускулатуру своей модели, SenseTime разыграла видеопредставление соревнования своей модели и GPT-4 Turbo в формате видеоигры «Король бойцов» (на рис. внизу). Поначалу зеленый игрок GPT-4 имел небольшое преимущество, но очень скоро был жестоко избит красным игроком SenseChat-lite.
Неявным, но очевидным посылом видеопрезентации этого боя было послание Бигтеху США – вот так мы вас и размажем в гонке за первенство в ИИ.
Картинка https://telegra.ph/file/ccf5d5c020de3aa9c3324.jpg
На китайском https://zhidx.com/p/421866.html
На английском https://interestingengineering.com/innovation/china-sensenova-outperforms-gpt-4
Видеоразбор https://www.youtube.com/watch?v=NJXGIMa45sQ
#LLM #Китай
{kind=link}
На Земле появился первый Софон.
Это еще не решение «проблемы трех тел», но сильный ход в решении «проблемы инакомыслия и инакодействия» людей.
Речь действительно о Софоне из романа Лю Цысиня и его экранизации Netflix «Проблема трех тел». И этот Софон действительно создан.
• Но не трисолярианами (или Сан-Ти, - как их для простоты произношения назвали в сериале), а землянами - китайскими исследователями из Чжэцзянского университета и Ant Group.
• И создан этот Софон не для торможения и блокировки технологического прогресса землян (как в романе и сериале), а для торможения и блокирования инфокоммуникационных возможностей землян в областях, неугодных для сильных мира сего - властям и китам инфобигтеха.
Логика этого техно-прорыва, совместно профинансированного Национальным фондом естественных наук Китая (учрежден в 1986 под юрисдикцией Госсовета Китая, а с 2018 под управлением Миннауки и технологий) и Ant Group (дочка китайского конгломерата Alibaba Group, в 2021 взятая под контроль Народным банком Китая), мне видится таковой.
✔️ Возможности получения людьми информации (от новостей до знаний) из Интернета все более зависят от ИИ больших языковых моделей (LLM). Они становятся для землян глобальным инфофильтром, определяющим,
1) что человек может узнать и
2) чему может научиться из Интернета.
✔️ Поэтому становится ключевым вопрос, как взять под контроль и 1ое, и 2ое, исключив возможности использования людьми LLM для неэтичных, незаконных, небезопасных и любых иных нежелательных (с точки зрения разработчиков LLM) целей.
Эта задача одинаково актуальна и важна для столь разных акторов, как Компартия Китая и Microsoft, Белый дом и Google, Amazon и OpenAI – короче, для властей всех мастей и китов инфобигтеха.
Не смотря на важность, решить эту задачу пока не удавалось. И вот прорыв.
Китайские исследователи придумали, как открывать для массового использования LLM, которые «плохим людям» будет сложно настроить для злоупотреблений.
Китайцы придумали новый подход к обучению без точной настройки (он назван SOPHON), использующий специальную технику, которая «предотвращает точную настройку предварительно обученной модели для нежелательных задач, сохраняя при этом ее производительность при выполнении исходной задачи».
SOPHON использует «два ключевых модуля оптимизации: 1) обычное усиление обучения в исходной области и 2) подавление тонкой настройки в ограниченной области. Модуль подавления тонкой настройки предназначен для снижения производительности тонкой настройки в ограниченной области в моделируемых процессах тонкой настройки».
В итоге, когда «плохие люди» захотят с помощью тонкой настройки переучить мощную законопослушную модель на что-то плохое (напр., выдавать нежелательный контент - от генерации порно до анализа событий на площади Тяньаньмэнь в 1989, от нескрепоносных советов до инструкции по взрвотехнике …) производительность модели катастрофически снизится (оставаясь высокой в дозволенных областях).
Нужно понимать, что этот 1й Софон еще дорабатывать и дорабатывать (проверять на сочетаниях разнообразных типов данных, масштабировании моделей и т.д.).
Но очевидное-невероятное уже налицо.
✔️ Т.к. возможности «нежелательных» применений неисчислимы, застраховать модель от всех их просто не реально.
✔️ Но можно просто пойти путем отсекания «нежелательного», с точки зрения владельцев платформ. И тогда вполне может получиться идеальный Большой брат: безликий и всевидящий цензор, не ошибающийся в предвосхищении правонарушений Х-комнадзор, умело манипулирующий сетевой агентурой спецслужбист и т.д.
#LLM #БольшойБрат
Картинка поста https://telegra.ph/file/d4b8b35cd3e11921eedbf.jpg
Статья https://arxiv.org/abs/2404.12699v1
Это еще не решение «проблемы трех тел», но сильный ход в решении «проблемы инакомыслия и инакодействия» людей.
Речь действительно о Софоне из романа Лю Цысиня и его экранизации Netflix «Проблема трех тел». И этот Софон действительно создан.
• Но не трисолярианами (или Сан-Ти, - как их для простоты произношения назвали в сериале), а землянами - китайскими исследователями из Чжэцзянского университета и Ant Group.
• И создан этот Софон не для торможения и блокировки технологического прогресса землян (как в романе и сериале), а для торможения и блокирования инфокоммуникационных возможностей землян в областях, неугодных для сильных мира сего - властям и китам инфобигтеха.
Логика этого техно-прорыва, совместно профинансированного Национальным фондом естественных наук Китая (учрежден в 1986 под юрисдикцией Госсовета Китая, а с 2018 под управлением Миннауки и технологий) и Ant Group (дочка китайского конгломерата Alibaba Group, в 2021 взятая под контроль Народным банком Китая), мне видится таковой.
✔️ Возможности получения людьми информации (от новостей до знаний) из Интернета все более зависят от ИИ больших языковых моделей (LLM). Они становятся для землян глобальным инфофильтром, определяющим,
1) что человек может узнать и
2) чему может научиться из Интернета.
✔️ Поэтому становится ключевым вопрос, как взять под контроль и 1ое, и 2ое, исключив возможности использования людьми LLM для неэтичных, незаконных, небезопасных и любых иных нежелательных (с точки зрения разработчиков LLM) целей.
Эта задача одинаково актуальна и важна для столь разных акторов, как Компартия Китая и Microsoft, Белый дом и Google, Amazon и OpenAI – короче, для властей всех мастей и китов инфобигтеха.
Не смотря на важность, решить эту задачу пока не удавалось. И вот прорыв.
Китайские исследователи придумали, как открывать для массового использования LLM, которые «плохим людям» будет сложно настроить для злоупотреблений.
Китайцы придумали новый подход к обучению без точной настройки (он назван SOPHON), использующий специальную технику, которая «предотвращает точную настройку предварительно обученной модели для нежелательных задач, сохраняя при этом ее производительность при выполнении исходной задачи».
SOPHON использует «два ключевых модуля оптимизации: 1) обычное усиление обучения в исходной области и 2) подавление тонкой настройки в ограниченной области. Модуль подавления тонкой настройки предназначен для снижения производительности тонкой настройки в ограниченной области в моделируемых процессах тонкой настройки».
В итоге, когда «плохие люди» захотят с помощью тонкой настройки переучить мощную законопослушную модель на что-то плохое (напр., выдавать нежелательный контент - от генерации порно до анализа событий на площади Тяньаньмэнь в 1989, от нескрепоносных советов до инструкции по взрвотехнике …) производительность модели катастрофически снизится (оставаясь высокой в дозволенных областях).
Нужно понимать, что этот 1й Софон еще дорабатывать и дорабатывать (проверять на сочетаниях разнообразных типов данных, масштабировании моделей и т.д.).
Но очевидное-невероятное уже налицо.
✔️ Т.к. возможности «нежелательных» применений неисчислимы, застраховать модель от всех их просто не реально.
✔️ Но можно просто пойти путем отсекания «нежелательного», с точки зрения владельцев платформ. И тогда вполне может получиться идеальный Большой брат: безликий и всевидящий цензор, не ошибающийся в предвосхищении правонарушений Х-комнадзор, умело манипулирующий сетевой агентурой спецслужбист и т.д.
#LLM #БольшойБрат
Картинка поста https://telegra.ph/file/d4b8b35cd3e11921eedbf.jpg
Статья https://arxiv.org/abs/2404.12699v1
{kind=link}
В Китае ИИ-врачи натренировались на ИИ-пациентах лечить пациентов-людей лучше, чем люди-врачи
В китайском симулякре больницы Е-врачи (в их роли выступают автономные агенты на базе больших языковых моделей - AALLM) проводят лечение Е-пациентов (в их роли другие AALLM), «болеющих» реальными человеческими респираторными заболеваниями (динамику которых моделируют также LLM, имеющие доступ к обширной базе медицинской информации, полученной при лечении реальных пациентов).
Цель имитационного эксперимента - дать возможность Е-врачам при лечении Е-пациентов набираться знаний, чтобы научиться лучше лечить болезни реальных людей в реальной жизни.
В ходе короткого эксперимента Е-врачи пролечили 10 тыс Е-пациентов (на что в реальной жизни ушло бы, минимум, два года).
Результат сногсшибательный. Повысившие свою квалификацию в ходе этого имитационного эксперимента Е-врачи достигли высочайшей точности 93,06% в подмножестве набора данных MedQA, охватывающем основные респираторные заболевания.
Подробности здесь https://arxiv.org/abs/2405.02957
#Медицина #Китай #LLM
В китайском симулякре больницы Е-врачи (в их роли выступают автономные агенты на базе больших языковых моделей - AALLM) проводят лечение Е-пациентов (в их роли другие AALLM), «болеющих» реальными человеческими респираторными заболеваниями (динамику которых моделируют также LLM, имеющие доступ к обширной базе медицинской информации, полученной при лечении реальных пациентов).
Цель имитационного эксперимента - дать возможность Е-врачам при лечении Е-пациентов набираться знаний, чтобы научиться лучше лечить болезни реальных людей в реальной жизни.
В ходе короткого эксперимента Е-врачи пролечили 10 тыс Е-пациентов (на что в реальной жизни ушло бы, минимум, два года).
Результат сногсшибательный. Повысившие свою квалификацию в ходе этого имитационного эксперимента Е-врачи достигли высочайшей точности 93,06% в подмножестве набора данных MedQA, охватывающем основные респираторные заболевания.
Подробности здесь https://arxiv.org/abs/2405.02957
#Медицина #Китай #LLM
arXiv.org
Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents
In this paper, we introduce a simulacrum of hospital called Agent Hospital that simulates the entire process of treating illness. All patients, nurses, and doctors are autonomous agents powered by...
Внутри черного ящика оказалась дверь в бездну.
Сверхважный прорыв в понимании механизма разума машин и людей.
Скромность вредна, если затеняет истинную важность открытия.
Опубликованная вчера Anthropic работа «Картирование разума большой языковой модели» [1] скромно названа авторами «значительным прогрессом в понимании внутренней работы моделей ИИ».
✔️ Но, во-первых, это не значительный (количественный) прогресс, а революционный (качественный) прорыв в понимании работы разума.
✔️ Во-вторых, с большой вероятностью, это прорыв в понимании механизма не только машинного, но и человеческого разума.
✔️ И в-третьих, последствия этого прорыва могут позволить ранее просто непредставимое и даже немыслимое – «тонкую настройку» не только предпочтений, но и самой матрицы личности человека, как это сейчас делается с большими языковыми моделями.
В посте «Внутри маскирующегося под стохастического попугая ИИ таится куда боле мощный ИИ» я писал об открытии исследователями компании Anthropic, сделанном ими в рамках проекта «вскрытия черного ящика LLM» [2].
Осенью прошлого года было установлено, что:
• внутри нейронной сети генеративного ИИ на основе LLM симулируется физически не существующая нейронная сеть некоего абстрактного ИИ, и эта внутренняя нейросеть куда больше и сложнее нейронной сети, ее моделирующей;
• «виртуальные (симулируемые) нейроны этой внутренней сети могут быть представлены, как независимые «функций» данных, каждая из которых реализует собственную линейную комбинацию нейронов;
• механизмом работы такой внутренней нейросети является обработка паттернов (линейных комбинаций) активаций нейронов, порождающая моносемантические «субнейроны» (соответствующие конкретным понятиям).
Из этого следовало, что любое внутреннее состояние модели можно представить в виде нескольких активных функций вместо множества активных нейронов. Точно так же, как каждое английское слово в словаре создается путем объединения букв, а каждое предложение — путем объединения слов, каждая функция в модели ИИ создается путем объединения нейронов, а каждое внутреннее состояние создается путем объединения паттернов активации нейронов.
Та работа была 1м этапом проекта «вскрытия черного ящика LLM», проводившегося на очень маленькой «игрушечной» языковой модели.
2й же этап, о результатах которого мой рассказ, «вскрыл черный ящик» одной из самых больших моделей семейства Claude 3.0.
Результаты столь важны и интересны и их так много, что читайте сами. Тут [1] есть и популярное, и углубленное, и видео изложение.
Например, авторы научились:
1. Находить внутри «черного ящика» модели не только конкретные моносемантические «субнейроны» (соответствующие конкретным понятиям, типа «Мост Золотые Ворота»), но и поиском «близких» друг другу функций обнаруживать в нейросети изображения (это мультимодальность!) острова Алькатрас, площади Гирарделли, команды «Голден Стэйт Уорриорз», губернатора Калифорнии Гэвина Ньюсома, землетрясения 1906 года и фильма Альфреда Хичкока «Головокружение», действие которого происходит в Сан-Франциско.
Это очень похоже на эксперименты нейробиологов, обнаруживающих в нашем мозге мультимодальную связь нейронов, связанных с понятиями, словами и образами объектов (например Дженнифер Лопес). Но там, где гиперсетевые теории мозга (типа когнитома Анохина) упираются в огромные трудности экспериментальных практических манипуляций (измерений) на уровне нейронов, в «черных ящиках» LLM все можно легко «измерить».
2. Манипулировать функциями, искусственно усиливая или подавляя их. Что приводит (если стоите, лучше сядьте) к изменению матрицы «личности» модели. Например, усиление роли функции «Мост Золотые Ворота» вызвало у Клода кризис идентичности, который даже Хичкок не мог себе представить. Клод стал одержимым мостом, поминая его в ответ на любой вопрос — даже в ситуациях, когда он был совершенно неактуален.
Если такое будут делать с людьми, то всему каюк.
#LLM
1 https://www.anthropic.com/news/mapping-mind-language-model
2 https://t.me/theworldisnoteasy/1857
Сверхважный прорыв в понимании механизма разума машин и людей.
Скромность вредна, если затеняет истинную важность открытия.
Опубликованная вчера Anthropic работа «Картирование разума большой языковой модели» [1] скромно названа авторами «значительным прогрессом в понимании внутренней работы моделей ИИ».
✔️ Но, во-первых, это не значительный (количественный) прогресс, а революционный (качественный) прорыв в понимании работы разума.
✔️ Во-вторых, с большой вероятностью, это прорыв в понимании механизма не только машинного, но и человеческого разума.
✔️ И в-третьих, последствия этого прорыва могут позволить ранее просто непредставимое и даже немыслимое – «тонкую настройку» не только предпочтений, но и самой матрицы личности человека, как это сейчас делается с большими языковыми моделями.
В посте «Внутри маскирующегося под стохастического попугая ИИ таится куда боле мощный ИИ» я писал об открытии исследователями компании Anthropic, сделанном ими в рамках проекта «вскрытия черного ящика LLM» [2].
Осенью прошлого года было установлено, что:
• внутри нейронной сети генеративного ИИ на основе LLM симулируется физически не существующая нейронная сеть некоего абстрактного ИИ, и эта внутренняя нейросеть куда больше и сложнее нейронной сети, ее моделирующей;
• «виртуальные (симулируемые) нейроны этой внутренней сети могут быть представлены, как независимые «функций» данных, каждая из которых реализует собственную линейную комбинацию нейронов;
• механизмом работы такой внутренней нейросети является обработка паттернов (линейных комбинаций) активаций нейронов, порождающая моносемантические «субнейроны» (соответствующие конкретным понятиям).
Из этого следовало, что любое внутреннее состояние модели можно представить в виде нескольких активных функций вместо множества активных нейронов. Точно так же, как каждое английское слово в словаре создается путем объединения букв, а каждое предложение — путем объединения слов, каждая функция в модели ИИ создается путем объединения нейронов, а каждое внутреннее состояние создается путем объединения паттернов активации нейронов.
Та работа была 1м этапом проекта «вскрытия черного ящика LLM», проводившегося на очень маленькой «игрушечной» языковой модели.
2й же этап, о результатах которого мой рассказ, «вскрыл черный ящик» одной из самых больших моделей семейства Claude 3.0.
Результаты столь важны и интересны и их так много, что читайте сами. Тут [1] есть и популярное, и углубленное, и видео изложение.
Например, авторы научились:
1. Находить внутри «черного ящика» модели не только конкретные моносемантические «субнейроны» (соответствующие конкретным понятиям, типа «Мост Золотые Ворота»), но и поиском «близких» друг другу функций обнаруживать в нейросети изображения (это мультимодальность!) острова Алькатрас, площади Гирарделли, команды «Голден Стэйт Уорриорз», губернатора Калифорнии Гэвина Ньюсома, землетрясения 1906 года и фильма Альфреда Хичкока «Головокружение», действие которого происходит в Сан-Франциско.
Это очень похоже на эксперименты нейробиологов, обнаруживающих в нашем мозге мультимодальную связь нейронов, связанных с понятиями, словами и образами объектов (например Дженнифер Лопес). Но там, где гиперсетевые теории мозга (типа когнитома Анохина) упираются в огромные трудности экспериментальных практических манипуляций (измерений) на уровне нейронов, в «черных ящиках» LLM все можно легко «измерить».
2. Манипулировать функциями, искусственно усиливая или подавляя их. Что приводит (если стоите, лучше сядьте) к изменению матрицы «личности» модели. Например, усиление роли функции «Мост Золотые Ворота» вызвало у Клода кризис идентичности, который даже Хичкок не мог себе представить. Клод стал одержимым мостом, поминая его в ответ на любой вопрос — даже в ситуациях, когда он был совершенно неактуален.
Если такое будут делать с людьми, то всему каюк.
#LLM
1 https://www.anthropic.com/news/mapping-mind-language-model
2 https://t.me/theworldisnoteasy/1857
Anthropic
Mapping the Mind of a Large Language Model
We have identified how millions of concepts are represented inside Claude Sonnet, one of our deployed large language models. This is the first ever detailed look inside a modern, production-grade large language model.
Спешите видеть, пока не прикрыли лавочку
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста https://telegra.ph/file/e1f10d2c4fc11e70d4587.jpg
1 https://claude.ai
2 https://t.me/theworldisnoteasy/1942
#ИИриски #LLM
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста https://telegra.ph/file/e1f10d2c4fc11e70d4587.jpg
1 https://claude.ai
2 https://t.me/theworldisnoteasy/1942
#ИИриски #LLM
{kind=link}
Магические свойства больших языковых моделей.
Обучение LLM на человеческих текстах не препятствует достижению ими сверхчеловеческой производительности.
Т.е. LLM могут достигать абсолютного превосходства над человеком в любой сфере языковой деятельности, подобно тому, как AlphaZero достигла уровня шахматной игры, не достижимого даже для чемпиона мира.
Работа Стефано Нолфи (директор по исследованиям расположенного в Риме Institute of Cognitive Sciences and Technologies) крайне важна. Ибо она отвечает на ключевой вопрос о возможности достижения LLM сверхчеловеческой производительности в любой языковой деятельности (притом, что до 70% интеллектуальной деятельности включает элементы языковой деятельности).
Отвечая на этот ключевой вопрос, Нолфи исходит из следующей максимально жесткой гипотетической предпосылки.
Характеристики процесса, через который LLM приобретают свои навыки, предполагают, что список навыков, которые они могут приобрести, ограничивается набором способностей, которыми обладают люди, написавшие текст, использованный для обучения моделей.
Если эта гипотеза верна, следует ожидать, что модели, обученные предсказывать текст, написанный людьми, не будут развивать чужеродные способности, то есть способности, неизвестные человечеству.
Причина, по которой способности, необходимые для понимания текста, написанного человеком, ограничены способностями, которыми обладают люди, заключается в том, что человеческий язык является артефактом самих людей, который был сформирован когнитивными способностями носителей языка.
Однако, согласно выводам Нолфи, это не исключает возможности достижения сверхчеловеческой производительности.
Причину этого можно сформулировать так.
✔️ Поскольку интеграция знаний и навыков, которыми обладают несколько человек, совокупно превышает знания и навыки любого из них,
✔️ способность LLM обрабатывать колоссальные последовательности элементов без потери информации может позволить им превосходить способности отдельных людей.
Помимо этого важного вывода, в работе Нолфи рассмотрены еще 3 важных момента.
1) LLM принципиально отличаются от людей по нескольким важным моментам:
• механизм приобретения навыков
• степень интеграции различных навыков
• цели обучения
• наличия собственных ценностей, убеждений, желаний и устремлений
2) LLM обладают неожиданными способностями.
LLM способны демонстрировать широкий спектр способностей, которые не связаны напрямую с задачей, для которой они обучены: предсказание следующих слов в текстах, написанных человеком. Такие способности называют неожиданными или эмерджентными. Однако, с учетом смысловой многозначности обоих этих слов, я предпочитаю называть такие способности LLM магическими, т.к. и прямое значение этого слова (обладающий способностью вызывать необъяснимые явления), и переносное (загадочный, таинственный: связанный с чем-то непонятным, труднообъяснимым), и метафорическое (поразительный, удивительный: что-то, что вызывает удивление своим эффектом или воздействием), - по смыслу точно соответствуют неожиданным и непредсказуемым способностям, появляющимся у LLM.
3) LLM обладают двумя ключевыми факторами, позволяющими им приобретать навыки косвенным образом. Это связано с тем, что точное предсказание следующих слов требует глубокого понимания предыдущего текста, а это понимание требует владения и использования когнитивных навыков. Таким образом, развитие когнитивных навыков происходит косвенно.
Первый фактор — это высокая информативность ошибки предсказания, то есть тот факт, что она предоставляет очень надежную меру знаний и навыков системы. Это означает, что улучшения и регрессы навыков системы всегда приводят к снижению и увеличению ошибки соответственно и наоборот.
Второй фактор — предсказуемость человеческого языка, обусловленная его символической и нединамической природой.
Картинка https://telegra.ph/file/10af73ecfc82edcf6c308.jpg
За пейволом https://bit.ly/3wWb5vC
Без https://arxiv.org/abs/2308.09720
#LLM
Обучение LLM на человеческих текстах не препятствует достижению ими сверхчеловеческой производительности.
Т.е. LLM могут достигать абсолютного превосходства над человеком в любой сфере языковой деятельности, подобно тому, как AlphaZero достигла уровня шахматной игры, не достижимого даже для чемпиона мира.
Работа Стефано Нолфи (директор по исследованиям расположенного в Риме Institute of Cognitive Sciences and Technologies) крайне важна. Ибо она отвечает на ключевой вопрос о возможности достижения LLM сверхчеловеческой производительности в любой языковой деятельности (притом, что до 70% интеллектуальной деятельности включает элементы языковой деятельности).
Отвечая на этот ключевой вопрос, Нолфи исходит из следующей максимально жесткой гипотетической предпосылки.
Характеристики процесса, через который LLM приобретают свои навыки, предполагают, что список навыков, которые они могут приобрести, ограничивается набором способностей, которыми обладают люди, написавшие текст, использованный для обучения моделей.
Если эта гипотеза верна, следует ожидать, что модели, обученные предсказывать текст, написанный людьми, не будут развивать чужеродные способности, то есть способности, неизвестные человечеству.
Причина, по которой способности, необходимые для понимания текста, написанного человеком, ограничены способностями, которыми обладают люди, заключается в том, что человеческий язык является артефактом самих людей, который был сформирован когнитивными способностями носителей языка.
Однако, согласно выводам Нолфи, это не исключает возможности достижения сверхчеловеческой производительности.
Причину этого можно сформулировать так.
✔️ Поскольку интеграция знаний и навыков, которыми обладают несколько человек, совокупно превышает знания и навыки любого из них,
✔️ способность LLM обрабатывать колоссальные последовательности элементов без потери информации может позволить им превосходить способности отдельных людей.
Помимо этого важного вывода, в работе Нолфи рассмотрены еще 3 важных момента.
1) LLM принципиально отличаются от людей по нескольким важным моментам:
• механизм приобретения навыков
• степень интеграции различных навыков
• цели обучения
• наличия собственных ценностей, убеждений, желаний и устремлений
2) LLM обладают неожиданными способностями.
LLM способны демонстрировать широкий спектр способностей, которые не связаны напрямую с задачей, для которой они обучены: предсказание следующих слов в текстах, написанных человеком. Такие способности называют неожиданными или эмерджентными. Однако, с учетом смысловой многозначности обоих этих слов, я предпочитаю называть такие способности LLM магическими, т.к. и прямое значение этого слова (обладающий способностью вызывать необъяснимые явления), и переносное (загадочный, таинственный: связанный с чем-то непонятным, труднообъяснимым), и метафорическое (поразительный, удивительный: что-то, что вызывает удивление своим эффектом или воздействием), - по смыслу точно соответствуют неожиданным и непредсказуемым способностям, появляющимся у LLM.
3) LLM обладают двумя ключевыми факторами, позволяющими им приобретать навыки косвенным образом. Это связано с тем, что точное предсказание следующих слов требует глубокого понимания предыдущего текста, а это понимание требует владения и использования когнитивных навыков. Таким образом, развитие когнитивных навыков происходит косвенно.
Первый фактор — это высокая информативность ошибки предсказания, то есть тот факт, что она предоставляет очень надежную меру знаний и навыков системы. Это означает, что улучшения и регрессы навыков системы всегда приводят к снижению и увеличению ошибки соответственно и наоборот.
Второй фактор — предсказуемость человеческого языка, обусловленная его символической и нединамической природой.
Картинка https://telegra.ph/file/10af73ecfc82edcf6c308.jpg
За пейволом https://bit.ly/3wWb5vC
Без https://arxiv.org/abs/2308.09720
#LLM
{kind=link}
Есть 4 сложных для понимания момента, не разобравшись с которыми трудно адекватно представить и текущее состояние, и возможные перспективы больших языковых моделей (GPT, Claude, Gemini …)
▶️ Почему любое уподобление разумности людей и языковых моделей непродуктивно и опасно.
▶️ Почему галлюцинации моделей – это не ахинея и не бред, а «ложные воспоминания» моделей.
▶️ Почему невозможно путем ограничительных мер и этических руководств гарантировать, что модели их никогда не нарушат.
▶️ Каким может быть венец совершенства для больших языковых моделей.
Мои суперкороткие (но, хотелось бы надеяться, внятные) комментарии по каждому из четырех моментов вы найдете по ссылке, приведенной в тизере на канале RTVI:
https://t.me/rtvimain/97261
#LLM
▶️ Почему любое уподобление разумности людей и языковых моделей непродуктивно и опасно.
▶️ Почему галлюцинации моделей – это не ахинея и не бред, а «ложные воспоминания» моделей.
▶️ Почему невозможно путем ограничительных мер и этических руководств гарантировать, что модели их никогда не нарушат.
▶️ Каким может быть венец совершенства для больших языковых моделей.
Мои суперкороткие (но, хотелось бы надеяться, внятные) комментарии по каждому из четырех моментов вы найдете по ссылке, приведенной в тизере на канале RTVI:
https://t.me/rtvimain/97261
#LLM
Telegram
RTVI
У ChatGPT могут появиться тело и душа
Исследователь ИИ Сергей Карелов рассказывает RTVI, как работают большие языковые модели и на что они будут способны через несколько лет.
🔹 Если мы говорим о тех моделях, которые знаем, — то это сущности, сидящие внутри…
Исследователь ИИ Сергей Карелов рассказывает RTVI, как работают большие языковые модели и на что они будут способны через несколько лет.
🔹 Если мы говорим о тех моделях, которые знаем, — то это сущности, сидящие внутри…