
Выбирая между софтовым или железным рейдом, я чаще всего выберу софтовый, если не будет остро стоять вопрос быстродействия дисковой подсистемы. А в бюджетном сегменте обычно и выбирать не приходится. Хотя и дорогой сервер могу взять без встроенного рейд контроллера, особенно если там быстрые ssd или nvme диски.
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
и выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
Получаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
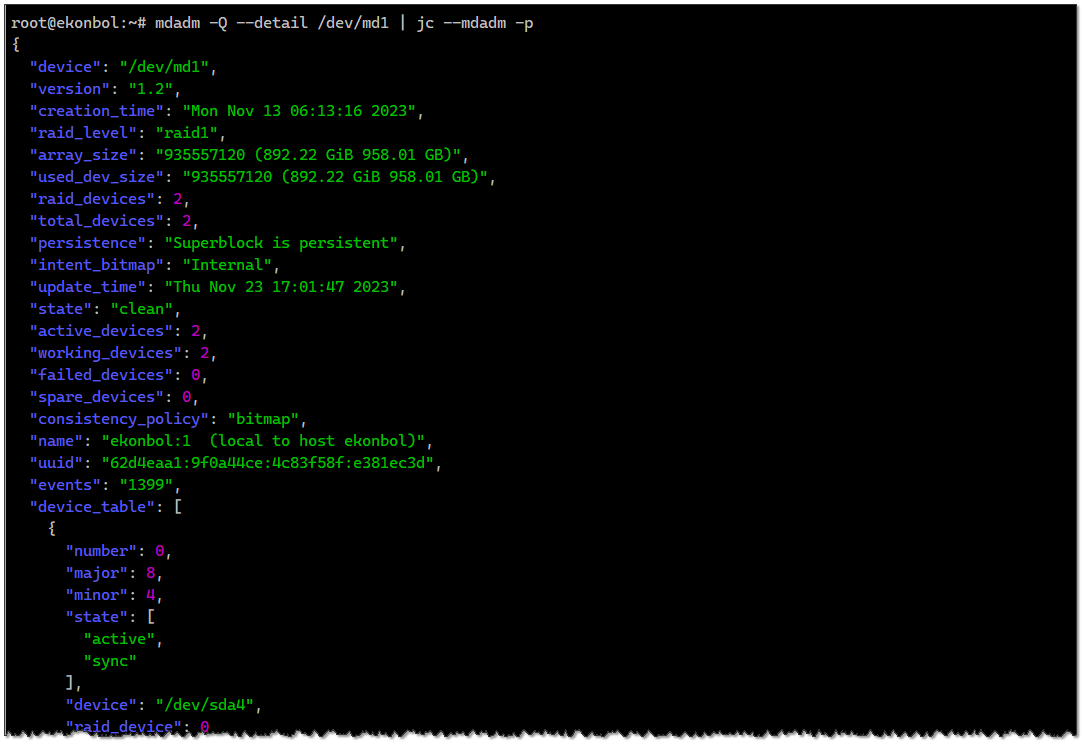
То же самое с mdadm. Смотрим состояние:
Добавляем утилиту jc:
Выгружаем полную информацию о массиве в формате json:
И отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
# apt install smartmontoolsи выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
# smartctl -i /dev/sdd -j# smartctl -A /dev/sdd -jПолучаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
То же самое с mdadm. Смотрим состояние:
# mdadm -Q --detail /dev/md1Добавляем утилиту jc:
# apt install jcВыгружаем полную информацию о массиве в формате json:
# mdadm -Q --detail /dev/md1 | jc --mdadm -pИ отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
{kind=link}
Несмотря на то, что mdadm хоронят уже много лет, например, те же разработчики Proxmox, я успешно и повсеместно его использую. Он меня полностью устраивает в плане надёжности и предсказуемости. Берёшь любой бюджетный сервер на 2 или 4 SSD или NVME диска и собираешь RAID1 или RAID10, ставишь на все диски загрузчик и больше не переживаешь за выход из строя одного из дисков.
Я уже десятки раз заменял вышедшие из строя диски и никогда не имел с mdadm проблем (постучал по дереву). Буквально вчера утром получил уведомление с одного из серверов о выходе из строя диска (картинка с ошибкой и данными из мониторинга внизу) и вечером заказал замену у техподдержки дедика. В этот раз собрал практически все возможные проблемы, так что оформлю в короткую шпаргалку.
Вышел из строя диск
Я получил ошибку:
В данном случае в тексте ошибки присутствует uuid одного из разделов оставшегося диска
Чтобы исправить ошибку выше, надо вывести из состава массивов разделы диска
Так для всех массивов. В моём случае их было 3:
Теперь команда
После этого сервер можно выключить и написать в техподдержку, чтобы выполнили замену. Внимательно укажите серийный номер сбойного диска. У меня он всегда в Zabbix остаётся. Отдельно не веду каталог дисков. Просто настраиваю мониторинг. Обычно этого достаточно.
После того, как поддержка заменит диск и включит сервер, можно добавлять новый диск в массив. Проверяем его:
Убеждаемся, что диск подходящего размера и он чистый, без разметки. У меня на подобных серверах обычно mbr разметка, так как SSD диски не очень большие. Разделы с работающего диска на новый копирую так:
Скопировали с
Теперь добавляем разделы нового диска в массив:
Наблюдаем синхронизацию в режиме реального времени:
Один из массивов у меня был остановлен:
Не получалось к нему добавить недостающий раздел. Перед этим его пришлось запустить:
После этого благополучно добавил недостающий раздел:
Не знаю, с чем связано то, что иногда массивы останавливаются. Хорошо, что в данном случае это был не корневой или загрузочный раздел. Как-то раз у меня остановился корневой раздел. Пришлюсь грузиться с livecd, запускать массив и добавлять в него раздел. После этого нормально загрузилась система. Случается такое редко. Добавляет некоторую нервозность ко всему процессу замены диска. Всегда есть шанс, что понадобится livecd или доступ к консоли сервера.
После замены диска не забываем установить загрузчик на новый диск
Обязательно убедитесь, что ошибок нет. Если есть, сразу их решайте, не откладывайте на потом.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#mdadm
Я уже десятки раз заменял вышедшие из строя диски и никогда не имел с mdadm проблем (постучал по дереву). Буквально вчера утром получил уведомление с одного из серверов о выходе из строя диска (картинка с ошибкой и данными из мониторинга внизу) и вечером заказал замену у техподдержки дедика. В этот раз собрал практически все возможные проблемы, так что оформлю в короткую шпаргалку.
Вышел из строя диск
/dev/sda , который входит в состав RAID1 из двух дисков. Это первый диск, с которого грузился загрузчик. Перед заменой обязательно проверяем, что есть загрузчик на втором диске:# dpkg-reconfigure grub-pc Я получил ошибку:
grub-pc: Running grub-install ...Installing for i386-pc platform.grub-install.real: error: disk `mduuid/fe51668460b267542c1d5c1adb4e7680' not found. grub-install failure for /dev/sdbВ данном случае в тексте ошибки присутствует uuid одного из разделов оставшегося диска
/dev/sdb, который входит в массив mdadm, который из-за выхода из строя диска /dev/sda находится в состоянии Degraded. Я точно знал, что ранее на /dev/sdb уже ставил загрузчик, но решил перестраховаться. Чтобы исправить ошибку выше, надо вывести из состава массивов разделы диска
/dev/sda:# mdadm /dev/md126 --fail /dev/sda1# mdadm /dev/md126 --remove /dev/sda1Так для всех массивов. В моём случае их было 3:
/, /boot и swap. Я swap никогда в раздел не выношу, храню в файле, но это был шаблон от хостера. Там такая разбивка по умолчанию. Теперь команда
dpkg-reconfigure grub-pc отработала без ошибок, поставила загрузчик на /dev/sdb.После этого сервер можно выключить и написать в техподдержку, чтобы выполнили замену. Внимательно укажите серийный номер сбойного диска. У меня он всегда в Zabbix остаётся. Отдельно не веду каталог дисков. Просто настраиваю мониторинг. Обычно этого достаточно.
После того, как поддержка заменит диск и включит сервер, можно добавлять новый диск в массив. Проверяем его:
# smartctl -i /dev/sda# fdisk -l | grep /dev/sdaУбеждаемся, что диск подходящего размера и он чистый, без разметки. У меня на подобных серверах обычно mbr разметка, так как SSD диски не очень большие. Разделы с работающего диска на новый копирую так:
# sfdisk -d /dev/sdb | sfdisk /dev/sdaСкопировали с
/dev/sdb на /dev/sda. Не перепутайте диски и не обнулите разметку старого диска. Убеждаемся, что разметка на /dev/sda идентична /dev/sdb:# fdisk -lТеперь добавляем разделы нового диска в массив:
# mdadm --add /dev/md126 /dev/sda1Наблюдаем синхронизацию в режиме реального времени:
# watch cat /proc/mdstatОдин из массивов у меня был остановлен:
md127 : inactive sdb3[1](S)Не получалось к нему добавить недостающий раздел. Перед этим его пришлось запустить:
# mdadm --run /dev/md127mdadm: started array /dev/md/installrescue:43После этого благополучно добавил недостающий раздел:
# mdadm --add /dev/md127 /dev/sda3mdadm: added /dev/sda3Не знаю, с чем связано то, что иногда массивы останавливаются. Хорошо, что в данном случае это был не корневой или загрузочный раздел. Как-то раз у меня остановился корневой раздел. Пришлюсь грузиться с livecd, запускать массив и добавлять в него раздел. После этого нормально загрузилась система. Случается такое редко. Добавляет некоторую нервозность ко всему процессу замены диска. Всегда есть шанс, что понадобится livecd или доступ к консоли сервера.
После замены диска не забываем установить загрузчик на новый диск
/dev/sda:# dpkg-reconfigure grub-pcОбязательно убедитесь, что ошибок нет. Если есть, сразу их решайте, не откладывайте на потом.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#mdadm
В заметках про Bit Rot, которое приводит к повреждению файлов при долговременном хранении, не хватало информации о том, как вообще можно смоделировать ситуацию, чтобы проверить настроенное хранилище.
Воздействовать на физическом уровне на устройства - задача нетривиальная. Но мне кажется, что можно действовать по-другому и получить схожий результат. Показываю по шагам свой эксперимент.
1️⃣ Для ускорения проведения экспериментов предлагаю всё делать на маленьких разделах диска. Покажу на примере mdadm raid1:
2️⃣ Заполняем весь раздел файлом:
Команда остановится с ошибкой, как только на диске закончится место.
3️⃣ Вычисляем хэш файла:
4️⃣ Запишем что-нибудь напрямую на блочное устройство. Чтобы точно попасть в созданный файл, я и сделал его во весь объём раздела.
Записали 1 блок размером 10 байт, отступив от начала 10 МБ или 100 МБ. Не помню точно, считается этот отступ в байтах или в размере блока.
5️⃣ Ещё раз проверяем хэш:
На удивление, он остался тем же. Я ожидал, что изменится.
6️⃣ Запускаем проверку целостности данных в массиве и когда закончится, смотрим результат:
У нас 128 несинхронизированных секторов. Точную причину проблем не посмотреть, но мы в данном случае знаем, что причина в том, что мы напрямую изменили часть данных.
7️⃣ Запускаем исправление ошибок:
Ждём по логу ядра окончание ремонта и смотрим ещё раз на количество ошибок:
Проверяем исходный файл:
Хэш не поменялся.
Я проводил несколько подобных экспериментов, меняя разные участки на блочном устройстве. Не всегда один repair приводил к исчезновению ошибок синхронизации, но после 2-х, 3-х раз они пропадали. И хэш файла всё время был один и тот же. Но если я через dd писал напрямую в md0:
То хэш неизменно менялся. Этот способ изменения файлов реально их меняет, хэш становится другим.
То же самое пробовал делать с массивом с включённым dm-integrity. Как и ожидается, массив получает ошибку хэша в определённом секторе:
А вот дальше я сталкивался в разных экспериментах с разным результатом. Это может не приводить ни к каким ошибкам, возникающие на некоторое время ошибки синхронизации через несколько минут сами пропадают без запуска принудительной синхронизации через repair. Хэш файла не меняется.
Но один раз я получил ошибку чтения файла, а в логе было следующее:
И так далее по кругу. То есть сектор был определён как повреждённый. Шла попытка взять его с другого диска, но там он тоже был с изменённой checksum. Не знаю, с чем это связано. Как-будто мое изменение успело синхронизироваться на второй диск и блока с правильным хэшем просто не осталось. В итоге файл вообще перестал открываться (Input/output error), его хэш нельзя было посмотреть.
Методику для тестов я вам показал. Можете помучать свои хранилища перед внедрением в эксплуатацию.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#mdadm #backup
Воздействовать на физическом уровне на устройства - задача нетривиальная. Но мне кажется, что можно действовать по-другому и получить схожий результат. Показываю по шагам свой эксперимент.
# apt-get install mdadm# mdadm --create /dev/md0 -l 1 -n 2 /dev/sdb /dev/sdс# mkfs.ext4 /dev/md0# mount /dev/md0 /mnt# dd if=/dev/urandom of=/mnt/testfileКоманда остановится с ошибкой, как только на диске закончится место.
# md5sum /mnt/testfile4b1f1e62670849f08c975e9cab8cfd10 /mnt/testfile# dd if=/dev/urandom of=/dev/sdb seek=10000000 count=1 bs=10 conv=notruncЗаписали 1 блок размером 10 байт, отступив от начала 10 МБ или 100 МБ. Не помню точно, считается этот отступ в байтах или в размере блока.
# md5sum /mnt/testfile4b1f1e62670849f08c975e9cab8cfd10 /mnt/testfileНа удивление, он остался тем же. Я ожидал, что изменится.
# echo 'check' > /sys/block/md0/md/sync_action# cat /sys/block/md0/md/mismatch_cnt 128У нас 128 несинхронизированных секторов. Точную причину проблем не посмотреть, но мы в данном случае знаем, что причина в том, что мы напрямую изменили часть данных.
# echo 'repair' > /sys/block/md0/md/sync_actionЖдём по логу ядра окончание ремонта и смотрим ещё раз на количество ошибок:
# cat /sys/block/md0/md/mismatch_cnt0Проверяем исходный файл:
# md5sum /mnt/testfile4b1f1e62670849f08c975e9cab8cfd10 /mnt/testfileХэш не поменялся.
Я проводил несколько подобных экспериментов, меняя разные участки на блочном устройстве. Не всегда один repair приводил к исчезновению ошибок синхронизации, но после 2-х, 3-х раз они пропадали. И хэш файла всё время был один и тот же. Но если я через dd писал напрямую в md0:
# dd if=/dev/urandom of=/dev/md0 seek=10000000 count=1 bs=10 conv=notruncТо хэш неизменно менялся. Этот способ изменения файлов реально их меняет, хэш становится другим.
То же самое пробовал делать с массивом с включённым dm-integrity. Как и ожидается, массив получает ошибку хэша в определённом секторе:
device-mapper: integrity: dm-0: Checksum failed at sector 0xe88b8А вот дальше я сталкивался в разных экспериментах с разным результатом. Это может не приводить ни к каким ошибкам, возникающие на некоторое время ошибки синхронизации через несколько минут сами пропадают без запуска принудительной синхронизации через repair. Хэш файла не меняется.
Но один раз я получил ошибку чтения файла, а в логе было следующее:
device-mapper: integrity: dm-0: Checksum failed at sector 0x2b4f8
md/raid1:md0: dm-0: rescheduling sector 175144
device-mapper: integrity: dm-0: Checksum failed at sector 0x2b4f8
device-mapper: integrity: dm-1: Checksum failed at sector 0x2b4f8
md/raid1:md0: redirecting sector 175144 to other mirror: dm-1
device-mapper: integrity: dm-1: Checksum failed at sector 0x2b4f8И так далее по кругу. То есть сектор был определён как повреждённый. Шла попытка взять его с другого диска, но там он тоже был с изменённой checksum. Не знаю, с чем это связано. Как-будто мое изменение успело синхронизироваться на второй диск и блока с правильным хэшем просто не осталось. В итоге файл вообще перестал открываться (Input/output error), его хэш нельзя было посмотреть.
Методику для тестов я вам показал. Можете помучать свои хранилища перед внедрением в эксплуатацию.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#mdadm #backup
Please open Telegram to view this post
VIEW IN TELEGRAM