
Хочу познакомить вас с простой и крайне полезной консольной утилитой в Linux — basename. Я её регулярно использую при написании bash скриптов для различных задач. В примерах, которыми я с вами делился здесь, она тоже встречалась.
С помощью basename удобно извлечь имя файла из полного пути.
Вместо полного пути к файлу вы получаете только его имя. Можете сразу убрать расширение файла, если оно вам не нужно:
Вот пример из реального скрипта, которым пользуюсь. Мне нужно было с помощью rsync передать с одного сервера на другой бэкапы прошлого дня. Более старые не трогать. Забирать файлы нужно было строго со стороннего сервера, а не копировать их со стороны исходного, где лежат файлы. При этом нужно было добавить еще и исключение в файлах, чтобы забрать только то, что нужно. Сделал так:
Список нужных файлов для копирования формирую на удаленном сервере с помощью find, оставляю только имена через basename, добавляю исключение через egrep и передаю этот список на целевой сервер через параметр rysnc
Сходу не вспомнил ещё свои примеры с basename. Обычно она как раз с find используется. Причём, не удивлюсь, если у find есть какой-то ключ, чтобы вывести список файлов без полных путей. Я привык в итоге использовать basename. Ещё пример был недавно с импровизированной корзиной в Linux, где я тоже использовал basename, чтобы все удалённые файлы класть в отдельную папку в общую кучу, без сохранения путей. Мне так показалось удобнее.
С помощью basename можно однострочником сменить расширение у всех файлов .txt на .log в директории:
Очевидно, что это не самый оптимальный и быстрый способ. Показал просто для примера. То же самое можно сделать с помощью rename, которая не везде есть по умолчанию, может понадобится установить отдельно.
Или ещё раз то же самое, только с помощью find, sed, xargs:
Скрипты в Linux — бесконечный простор для творчества, особенно если писать их в bash. Там можно десяток различных способов придумать для решения одной и той же задачи. Чем больше утилит знаешь, тем больше вариантов.
#bash #script
С помощью basename удобно извлечь имя файла из полного пути.
# basename /var/log/auth.logauth.logВместо полного пути к файлу вы получаете только его имя. Можете сразу убрать расширение файла, если оно вам не нужно:
# basename /var/log/auth.log .logauthВот пример из реального скрипта, которым пользуюсь. Мне нужно было с помощью rsync передать с одного сервера на другой бэкапы прошлого дня. Более старые не трогать. Забирать файлы нужно было строго со стороннего сервера, а не копировать их со стороны исходного, где лежат файлы. При этом нужно было добавить еще и исключение в файлах, чтобы забрать только то, что нужно. Сделал так:
# rsync -av --files-from=<(ssh root@10.20.1.50 '/usr/bin/find /var/lib/pgpro/backup -type f -mtime -1 -exec basename {} \; | egrep -v timestamp') root@10.20.1.5:/var/lib/pgpro/backup/ /data/backup/Список нужных файлов для копирования формирую на удаленном сервере с помощью find, оставляю только имена через basename, добавляю исключение через egrep и передаю этот список на целевой сервер через параметр rysnc
--files-from. Сходу не вспомнил ещё свои примеры с basename. Обычно она как раз с find используется. Причём, не удивлюсь, если у find есть какой-то ключ, чтобы вывести список файлов без полных путей. Я привык в итоге использовать basename. Ещё пример был недавно с импровизированной корзиной в Linux, где я тоже использовал basename, чтобы все удалённые файлы класть в отдельную папку в общую кучу, без сохранения путей. Мне так показалось удобнее.
С помощью basename можно однострочником сменить расширение у всех файлов .txt на .log в директории:
# for file in *.txt; do mv -- "$file" "$(basename $file .txt).log"; doneОчевидно, что это не самый оптимальный и быстрый способ. Показал просто для примера. То же самое можно сделать с помощью rename, которая не везде есть по умолчанию, может понадобится установить отдельно.
# rename 's/.txt/.log/g' *.txtИли ещё раз то же самое, только с помощью find, sed, xargs:
# find . -type f | sed 'p;s:.txt:.log:g' | xargs -n2 mvСкрипты в Linux — бесконечный простор для творчества, особенно если писать их в bash. Там можно десяток различных способов придумать для решения одной и той же задачи. Чем больше утилит знаешь, тем больше вариантов.
#bash #script
{kind=link}
Ранее я уже затрагивал тему работы с регулярными выражениями, рассказав про сервис regex101.com. Хочу её немного развить и дополнить ещё несколькими полезными ссылками, которые имеет смысл собрать в одном месте, чтобы воспользоваться, когда нужно будет написать очередную регулярку.
Есть очень удобный сервис, который на основе введённых вами данных сам напишет регулярку. Звучит, как фантастика, но он действительно это умеет. Это программа grex, которую можно запустить у себя, либо воспользоваться публичным сервисом — https://pemistahl.github.io/grex-js.
Приведу простой пример для наглядности. Вам нужна регулярка, которая покрывает IP адреса из подсети 192.168.0.0/24. Мне не очевидно, как её сделать. А с помощью этого сервиса никаких проблем. Пишу простой скрипт, который мне сформирует строку со всеми 256 адресами:
Копирую полученную строку в grex, получаю регулярку:
Для проверки прогоняю её через regex101.com и убеждаюсь, что пример рабочий.
Конечно, какие-то сложные выражения с помощью этого сервиса не составить, но что-то простое запросто можно сделать, особенно если вы не особо разбираетесь в самостоятельном написании. Я буквально за 5 минут решил поставленную задачу. Сам бы точно ковырялся дольше с составлением.
И ещё несколько ссылок. Сервис https://regexper.com наглядно разбирает регулярку с картинками. Удобно для изучения и понимания. А в сервисе https://ihateregex.io можно посмотреть примеры наиболее востребованных регулярок тоже с примерами разбора правил. Также хочу порекомендовать вам хороший бесплатный курс по изучению регулярных выражений — https://stepik.org/course/107335/promo.
📌 А теперь всё кратко одним списком:
▪ regex101.com — проверка регулярных выражений
▪ grex — автоматическое составление регулярок
▪ regexper.com — схематическое изображение регулярок
▪ ihateregex.io — готовые примеры регулярных выражений
▪ stepik.org — бесплатный курс для изучения регулярок
#regex #сервис
Есть очень удобный сервис, который на основе введённых вами данных сам напишет регулярку. Звучит, как фантастика, но он действительно это умеет. Это программа grex, которую можно запустить у себя, либо воспользоваться публичным сервисом — https://pemistahl.github.io/grex-js.
Приведу простой пример для наглядности. Вам нужна регулярка, которая покрывает IP адреса из подсети 192.168.0.0/24. Мне не очевидно, как её сделать. А с помощью этого сервиса никаких проблем. Пишу простой скрипт, который мне сформирует строку со всеми 256 адресами:
#!/bin/bashcount=1while [ $count -le 256 ]doecho 192.168.0.$countcount=$(( $count + 1 ))doneКопирую полученную строку в grex, получаю регулярку:
^192\.168\.0\.(?:2(?:5[0-6]|[6-9])|(?:1[0-9]|2[0-4]|[3-9])[0-9]?|25?|1)$Для проверки прогоняю её через regex101.com и убеждаюсь, что пример рабочий.
Конечно, какие-то сложные выражения с помощью этого сервиса не составить, но что-то простое запросто можно сделать, особенно если вы не особо разбираетесь в самостоятельном написании. Я буквально за 5 минут решил поставленную задачу. Сам бы точно ковырялся дольше с составлением.
И ещё несколько ссылок. Сервис https://regexper.com наглядно разбирает регулярку с картинками. Удобно для изучения и понимания. А в сервисе https://ihateregex.io можно посмотреть примеры наиболее востребованных регулярок тоже с примерами разбора правил. Также хочу порекомендовать вам хороший бесплатный курс по изучению регулярных выражений — https://stepik.org/course/107335/promo.
📌 А теперь всё кратко одним списком:
▪ regex101.com — проверка регулярных выражений
▪ grex — автоматическое составление регулярок
▪ regexper.com — схематическое изображение регулярок
▪ ihateregex.io — готовые примеры регулярных выражений
▪ stepik.org — бесплатный курс для изучения регулярок
#regex #сервис
{kind=link}
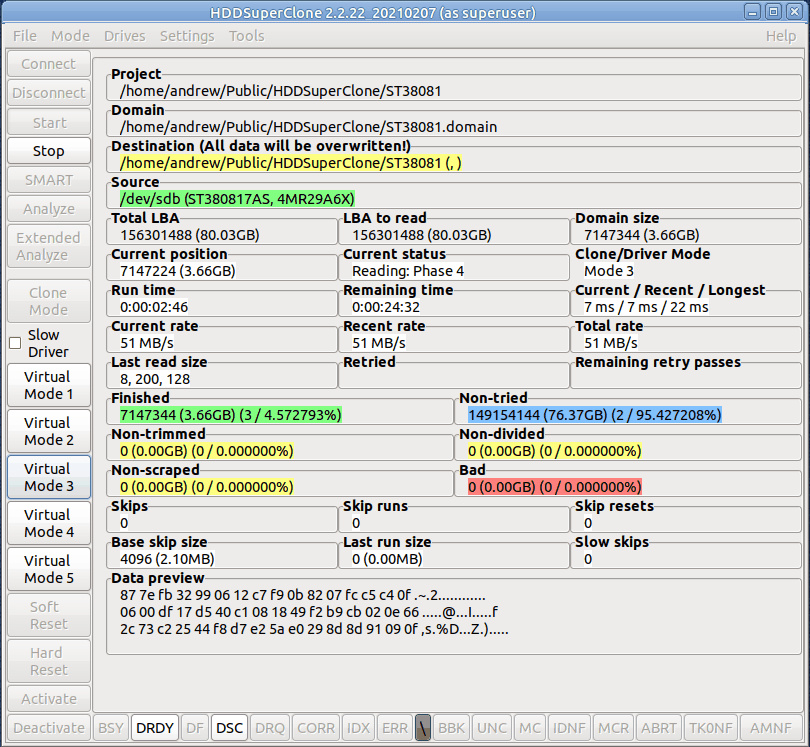
Летом была новость, что у платной программы HDDSuperClone были открыты исходники. Она стала полностью бесплатной, в том числе Pro версия. Я сейчас кратко поясню в чём её особенность и предложу вам связку из двух программ, сохранить себе на чёрный день, если вдруг понадобится восстановить данные с обычных дисков. Их хоть активно и заменяют SSD, но тем не мнее, HDD ещё используются. У меня как-то в NAS накрылся обычный диск, пришлось восстанавливать данные. Писал статью об этом.
Как ясно из названия, HDDSuperClone предназначена для клонирования неисправных жёстких дисков. Подобного рода программ много, но у этой есть некоторые особенности. Она умеет напрямую обращаться к жёстким дискам и, к примеру, перезапускать их по питанию в случае зависания. Также у неё есть собственный драйвер для работы с дисками.
Принцип работы драйвера следующий. Во время чтения с диска различными программами по восстановлению данных, всё, что удалось прочитать, драйвер пишет на виртуальный диск. А те данные, что нестабильны или их не удаётся сразу прочитать, считываются с диска. Таким образом, увеличивается шанс восстановления данных с минимальным беспокойством сбойного диска. Всё, что удалось с него прочитать и сохранить, считывается с копии, а всё остальное пробуют прочитать с него. Это функционал в прошлом платной версии. Сейчас она бесплатна.
На сайте популярной бесплатной программы для восстановления данных R-Linux есть подробная статья с описанием восстановления данных с умирающего жёсткого диска с помощью связки R-Studio и HDDSuperClone. Сохраните себе эту информацию, чтобы потом не пришлось искать и подбирать программы для этих целей.
⇨ Сайт / Исходники / R-Studio и HDDSuperClone / Видеоинструкции
#restore
Как ясно из названия, HDDSuperClone предназначена для клонирования неисправных жёстких дисков. Подобного рода программ много, но у этой есть некоторые особенности. Она умеет напрямую обращаться к жёстким дискам и, к примеру, перезапускать их по питанию в случае зависания. Также у неё есть собственный драйвер для работы с дисками.
Принцип работы драйвера следующий. Во время чтения с диска различными программами по восстановлению данных, всё, что удалось прочитать, драйвер пишет на виртуальный диск. А те данные, что нестабильны или их не удаётся сразу прочитать, считываются с диска. Таким образом, увеличивается шанс восстановления данных с минимальным беспокойством сбойного диска. Всё, что удалось с него прочитать и сохранить, считывается с копии, а всё остальное пробуют прочитать с него. Это функционал в прошлом платной версии. Сейчас она бесплатна.
На сайте популярной бесплатной программы для восстановления данных R-Linux есть подробная статья с описанием восстановления данных с умирающего жёсткого диска с помощью связки R-Studio и HDDSuperClone. Сохраните себе эту информацию, чтобы потом не пришлось искать и подбирать программы для этих целей.
⇨ Сайт / Исходники / R-Studio и HDDSuperClone / Видеоинструкции
#restore
{kind=link}
На днях писал про CIS. Решил не откладывать задачу и проработать документ с рекомендациями по Nginx. Делюсь с вами краткой выжимкой. Я буду брать более ли менее актуальные рекомендации для среднетиповых веб серверов. Например, отключать все лишние модули и делать свою сборку в обход готовых пакетов я не вижу для себя смыла.
📌Проверяем наличие настройки autoindex. В большинстве случаев она не нужна. С её помощью работает автоматический обзор содержимого директорий, если в них напрямую зайти, минуя конкретный или индексный файл.
Не должно быть настройки
📌Обращения на несуществующие домены или по ip адресу лучше сразу отклонять. По умолчанию отдаётся приветственная страница. Проверить можно так:
Если в ответ показывает приветственную страницу или что-то отличное от 404, то надо добавить в самую первую секцию server следующие настройки:
Можно просто удалить конфиг с дефолтным хостом, а приведённый код добавить в основной nginx.conf. Тогда это точно будет первая секция server. В остальных секциях server везде должны быть явно указаны
📌Параметр keep-alive timeout имеет смысл сделать 10 секунд или меньше. По умолчанию он не указан и им управляет подключающийся.
То же самое имеет смысл сделать для send_timeout.
Скрываем версию сервера параметром server_tokens. Проверяем так:
Отключаем:
📌Дефолтные страницы index.html и error page лучше отредактировать, удалив всё лишнее. Обычно они хранятся в директориях /usr/share/nginx/html или /var/www/html.
📌Запрещаем доступ к скрытым файлам и директориям, начинающимся с точки. Для этого в добавляем в самое начало виртуального хоста location:
Если нужно исключение, например для директории .well-known, которую использует let's encrypt для выпуска сертификатов, то добавьте его выше предыдущего правила.
📌Скрываем proxy headers. Добавляем в location:
📌Не забываем про настройку логирования. Логи нужны, но настройка сильно индивидуальна. Если логи хранятся локально, то обязательно настроить ротацию не только с привязкой ко времени, но и к занимаемому объёму. В идеале, логи должны храниться где-то удалённо без доступа к ним с веб сервера.
📌Настраиваем передачу реального IP адреса клиента в режиме работы Nginx в качестве прокси.
📌Ограничиваем версию TLS только актуальными 1.2 и 1.3. Если используется режим проксирования, то надо убедиться, что эти версии совпадают на прокси и на сервере. Если не уверены, что все ваши клиенты используют современные версии TLS, то оставьте поддержку более старых, но это не рекомендуется. Настройка для секции http в nginx.conf
📌Настраиваем ssl_ciphers. Список нужно уточнять, вот пример из документа CIS:
Дальше идут более узкие рекомендации типа ограничения доступа по IP, отдельных методов, настройка лимитов, более тонкие настройки таймаутов и т.д. В общем случае это не всегда требует настройки.
Ничего особо нового в документе не увидел. Большую часть представленных настроек я и раньше всегда делал. В дополнение к этому материалу будет актуальна ссылка на предыдущую заметку по настройке Nginx. Надо будет всё свести в общий типовой конфиг для Nginx и опубликовать.
#cis #nginx #security
📌Проверяем наличие настройки autoindex. В большинстве случаев она не нужна. С её помощью работает автоматический обзор содержимого директорий, если в них напрямую зайти, минуя конкретный или индексный файл.
# egrep -i '^\s*autoindex\s+' /etc/nginx/nginx.conf # egrep -i '^\s*autoindex\s+' /etc/nginx/conf.d/*# egrep -i '^\s*autoindex\s+' /etc/nginx/sites-available/*Не должно быть настройки
autoindex on. Если увидите, отключите. 📌Обращения на несуществующие домены или по ip адресу лучше сразу отклонять. По умолчанию отдаётся приветственная страница. Проверить можно так:
# curl -k -v https://127.0.0.1 -H 'Host: invalid.host.com'Если в ответ показывает приветственную страницу или что-то отличное от 404, то надо добавить в самую первую секцию server следующие настройки:
server { return 404;}Можно просто удалить конфиг с дефолтным хостом, а приведённый код добавить в основной nginx.conf. Тогда это точно будет первая секция server. В остальных секциях server везде должны быть явно указаны
server_name. 📌Параметр keep-alive timeout имеет смысл сделать 10 секунд или меньше. По умолчанию он не указан и им управляет подключающийся.
keepalive_timeout 10;То же самое имеет смысл сделать для send_timeout.
send_timeout 10;Скрываем версию сервера параметром server_tokens. Проверяем так:
# curl -I 127.0.0.1 | grep -i serverОтключаем:
server { ... server_tokens off; ... }📌Дефолтные страницы index.html и error page лучше отредактировать, удалив всё лишнее. Обычно они хранятся в директориях /usr/share/nginx/html или /var/www/html.
📌Запрещаем доступ к скрытым файлам и директориям, начинающимся с точки. Для этого в добавляем в самое начало виртуального хоста location:
location ~ /\. { deny all; return 404; }Если нужно исключение, например для директории .well-known, которую использует let's encrypt для выпуска сертификатов, то добавьте его выше предыдущего правила.
location ~ /\.well-known\/acme-challenge { allow all; }📌Скрываем proxy headers. Добавляем в location:
location /docs { .... proxy_hide_header X-Powered-By; proxy_hide_header Server; .... }📌Не забываем про настройку логирования. Логи нужны, но настройка сильно индивидуальна. Если логи хранятся локально, то обязательно настроить ротацию не только с привязкой ко времени, но и к занимаемому объёму. В идеале, логи должны храниться где-то удалённо без доступа к ним с веб сервера.
📌Настраиваем передачу реального IP адреса клиента в режиме работы Nginx в качестве прокси.
server { ... location / { proxy_pass 127.0.0.1:8080); proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; }}📌Ограничиваем версию TLS только актуальными 1.2 и 1.3. Если используется режим проксирования, то надо убедиться, что эти версии совпадают на прокси и на сервере. Если не уверены, что все ваши клиенты используют современные версии TLS, то оставьте поддержку более старых, но это не рекомендуется. Настройка для секции http в nginx.conf
ssl_protocols TLSv1.2 TLSv1.3;📌Настраиваем ssl_ciphers. Список нужно уточнять, вот пример из документа CIS:
ssl_ciphers ALL:!EXP:!NULL:!ADH:!LOW:!SSLv2:!SSLv3:!MD5:!RC4;Дальше идут более узкие рекомендации типа ограничения доступа по IP, отдельных методов, настройка лимитов, более тонкие настройки таймаутов и т.д. В общем случае это не всегда требует настройки.
Ничего особо нового в документе не увидел. Большую часть представленных настроек я и раньше всегда делал. В дополнение к этому материалу будет актуальна ссылка на предыдущую заметку по настройке Nginx. Надо будет всё свести в общий типовой конфиг для Nginx и опубликовать.
#cis #nginx #security
{kind=link}
Давно не писал ничего на тему программ для бэкапа, потому что все наиболее популярные и удобные программы я уже описывал. Рекомендую посмотреть мои прошлые заметки по тэгу #backup, вот эту заметку с подборкой или статью на сайте. Там всё в одном месте собрано. Только не хватает программы restic, писал про неё позже.
Я узнал и попробовал программу bup, про которую раньше не слышал. Она мне понравилась и показалась очень полезной, поэтому решил написать и поделиться с вами. Bup использует тот же алгоритм, что и rsync для деления файлов на фрагменты и проверки контрольных сумм, так что производительность у него на хорошем уровне.
Особенность bup в том, что она использует гитовский формат хранения данных в репозиториях. При этом не возникает проблем с огромным числом файлов и большим объёмом. Плюс такого хранения в том, что легко создаются инкрементные копии, причём данные могут быть совсем разные с разных хостов. Но если они одинаковые, то станут частью инкрементной копии. Это хорошо экономит дисковое пространство.
Bup умеет делать как локальные бэкапы, так и ходить за ними на удалённые серверы по SSH. Есть простенький встроенный веб интерфейс. Всё управление через консоль. Это в первую очередь консольный инструмент для самостоятельного велосипедостроения. Показываю, как его установить на Debian.
Теперь надо выполнить инициализацию репозитория. По умолчанию, он будет в ~/.bup. Задать его можно через переменную окружения BUP_DIR. Добавим её сразу в .bashrc и применим изменения:
Инициализируем репозиторий:
Создаём индекс бэкапа. Для примера возьму директорию /etc на сервере:
Делаем бэкап, назвав его etc с помощью параметра -n:
Посмотреть список репозиториев, файлов или бэкапов можно вот так:
Бэкап удалённой машины делается примерно так:
Доступ к серверу надо настроить по ключам.
Восстановление данных:
Восстановили директорию /etc с ветки latest бэкапа local-etc в директорию /.dest. Соответственно, выбирая разные ветки, вы восстанавливаете данные с того или иного инкрементного бэкапа.
Очень необычная для бэкапов, но при этом весьма удобная схема хранения и работы с данными, точно так же, как с обычными git репозиториями.
У bup есть простенький веб интерфейс, через который можно посмотреть и скачать файлы. По умолчанию он запускается на localhost, поэтому явно указываю интерфейс и порт:
Если кто-то пользуется bup, поделитесь впечатлением. Программа старая и известная, но я про неё ранее не слышал и не пользовался.
⇨ Сайт / Исходники
#backup
Я узнал и попробовал программу bup, про которую раньше не слышал. Она мне понравилась и показалась очень полезной, поэтому решил написать и поделиться с вами. Bup использует тот же алгоритм, что и rsync для деления файлов на фрагменты и проверки контрольных сумм, так что производительность у него на хорошем уровне.
Особенность bup в том, что она использует гитовский формат хранения данных в репозиториях. При этом не возникает проблем с огромным числом файлов и большим объёмом. Плюс такого хранения в том, что легко создаются инкрементные копии, причём данные могут быть совсем разные с разных хостов. Но если они одинаковые, то станут частью инкрементной копии. Это хорошо экономит дисковое пространство.
Bup умеет делать как локальные бэкапы, так и ходить за ними на удалённые серверы по SSH. Есть простенький встроенный веб интерфейс. Всё управление через консоль. Это в первую очередь консольный инструмент для самостоятельного велосипедостроения. Показываю, как его установить на Debian.
# git clone https://github.com/bup/bup# cd bup# git checkout 0.33# apt-get build-dep bup# apt install python3-pip# pip install tornado# make# make installТеперь надо выполнить инициализацию репозитория. По умолчанию, он будет в ~/.bup. Задать его можно через переменную окружения BUP_DIR. Добавим её сразу в .bashrc и применим изменения:
export BUP_DIR=/mnt/backup# source ~./bashrcИнициализируем репозиторий:
# bup initСоздаём индекс бэкапа. Для примера возьму директорию /etc на сервере:
# bup index /etcДелаем бэкап, назвав его etc с помощью параметра -n:
# bup save -n local-etc /etcПосмотреть список репозиториев, файлов или бэкапов можно вот так:
# bup ls# bup ls local-etc# bup ls local-etc/2023-01-31-190941Бэкап удалённой машины делается примерно так:
# bup index /etc# bup save -r SERVER -n backupname /etcДоступ к серверу надо настроить по ключам.
Восстановление данных:
# bup restore -C ./dest local-etc/latest/etcВосстановили директорию /etc с ветки latest бэкапа local-etc в директорию /.dest. Соответственно, выбирая разные ветки, вы восстанавливаете данные с того или иного инкрементного бэкапа.
Очень необычная для бэкапов, но при этом весьма удобная схема хранения и работы с данными, точно так же, как с обычными git репозиториями.
У bup есть простенький веб интерфейс, через который можно посмотреть и скачать файлы. По умолчанию он запускается на localhost, поэтому явно указываю интерфейс и порт:
# bup web 172.25.84.75:8080Если кто-то пользуется bup, поделитесь впечатлением. Программа старая и известная, но я про неё ранее не слышал и не пользовался.
⇨ Сайт / Исходники
#backup
{kind=link}
Когда искал в сети материалы по Loki, наткнулся на интересную статью, где автор хранит в Loki все введённые команды в bash. Понравился подход, поэтому решил его приспособить под свои нужды. Я большого смысла для себя не вижу собирать эти логи где-то во вне, поэтому проработал момент только с сохранением их локально в лог с помощью syslog.
Подход тут простой. Используется переменная bash PROMPT_COMMAND. Её содержимое выполняется после каждой введённой интерактивной команды. Так что достаточно указать выполнение нужного кода в этой переменной, чтобы собирать логи. Я предлагаю такой вариант:
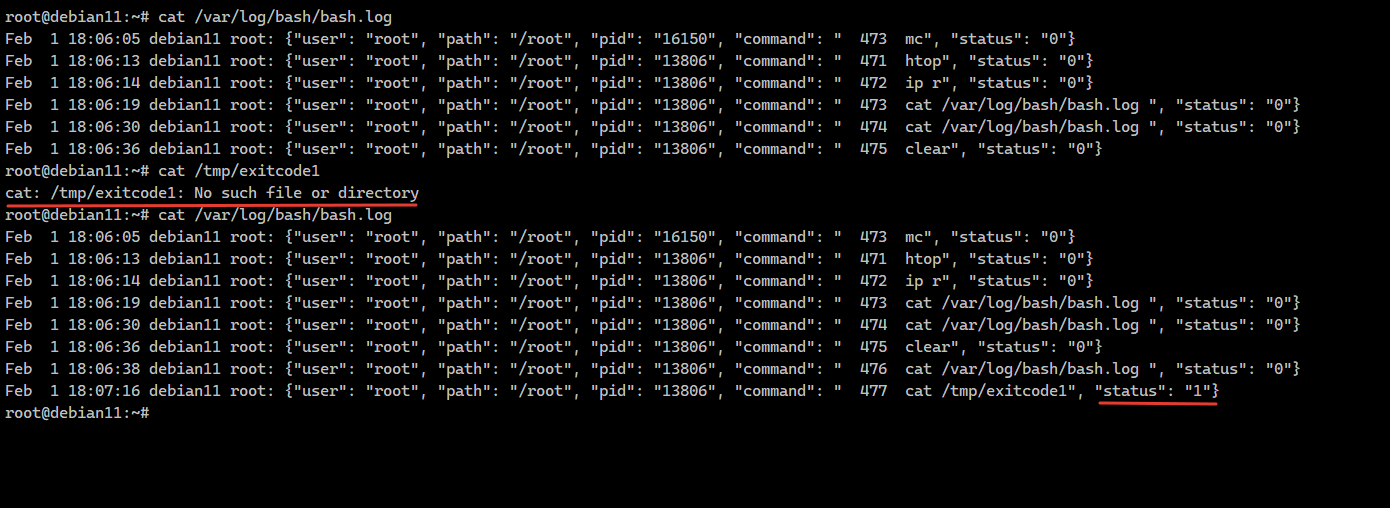
Эту переменную нужно добавить в файл ~/.bashrc и применить изменения, либо просто перезайти пользователем. Данная команда сохраняет имя пользователя, путь, откуда выполнялась команда, pid процесса (в данном случае это всегда будет pid баша, не уверен, что эта информация где-то нужна), сама команда, которая берётся из history, и статус её выполнения. Всё это отправляется в syslog в local6.debug.
Теперь нам надо перехватить этот local6.debug. Добавляем в конфиг /etc/rsyslog.conf одну строку:
создаём директорию и перезапускаем его:
Вот, в принципе, и всё. Теперь после выполнения команды в консоли, она будет сразу улетать в лог. Формат лога - json. Можете его подредактировать для своего удобства.
В статье автор также рассказывает, как можно сохранять вывод команды, но у меня не получилось настроить по его инструкции. Не смог разобраться, как это делать. Да и у него на всех скринах эта функция тоже не работает. А было бы неплохо это реализовать. Если кто-то знает или видел, как это делают, подскажите.
И ещё есть один момент. Если вы работаете в MC, то в историю команд будет прилетать много мусора. Это типичная проблема MC и сохранения истории. Она постоянно возникает, когда пользуешься этим файловым менеджером. Ещё со времён Freebsd с этим сталкивался, так как у MC есть своя отдельная баш консоль, куда залетают команды во время перемещения по директориям.
Напомню ещё способы логирования консольных команд:
◽snoopy
◽log-user-session
Решение с PROMPT_COMMAND наиболее простое и универсальное, так как не требует стороннего софта. Logger и syslog обычно присутствуют во всех популярных дистрибутивах.
#bash #terminal #linux #security
Подход тут простой. Используется переменная bash PROMPT_COMMAND. Её содержимое выполняется после каждой введённой интерактивной команды. Так что достаточно указать выполнение нужного кода в этой переменной, чтобы собирать логи. Я предлагаю такой вариант:
export PROMPT_COMMAND='RETRN_VAL=$?; logger -S 10000 -p local6.debug "{\"user\": \"$(whoami)\", \"path\": \"$(pwd)\", \"pid\": \"$$\", \"command\": \"$(history 1)\", \"status\": \"$RETRN_VAL\"}";'Эту переменную нужно добавить в файл ~/.bashrc и применить изменения, либо просто перезайти пользователем. Данная команда сохраняет имя пользователя, путь, откуда выполнялась команда, pid процесса (в данном случае это всегда будет pid баша, не уверен, что эта информация где-то нужна), сама команда, которая берётся из history, и статус её выполнения. Всё это отправляется в syslog в local6.debug.
Теперь нам надо перехватить этот local6.debug. Добавляем в конфиг /etc/rsyslog.conf одну строку:
local6.* /var/log/bash/bash.logсоздаём директорию и перезапускаем его:
# mkdir -p /var/log/bash# systemctl restart rsyslogВот, в принципе, и всё. Теперь после выполнения команды в консоли, она будет сразу улетать в лог. Формат лога - json. Можете его подредактировать для своего удобства.
В статье автор также рассказывает, как можно сохранять вывод команды, но у меня не получилось настроить по его инструкции. Не смог разобраться, как это делать. Да и у него на всех скринах эта функция тоже не работает. А было бы неплохо это реализовать. Если кто-то знает или видел, как это делают, подскажите.
И ещё есть один момент. Если вы работаете в MC, то в историю команд будет прилетать много мусора. Это типичная проблема MC и сохранения истории. Она постоянно возникает, когда пользуешься этим файловым менеджером. Ещё со времён Freebsd с этим сталкивался, так как у MC есть своя отдельная баш консоль, куда залетают команды во время перемещения по директориям.
Напомню ещё способы логирования консольных команд:
◽snoopy
◽log-user-session
Решение с PROMPT_COMMAND наиболее простое и универсальное, так как не требует стороннего софта. Logger и syslog обычно присутствуют во всех популярных дистрибутивах.
#bash #terminal #linux #security
{kind=link}
Серверы для бизнеса и частных проектов 📱
EKACOD. Data Center предлагает выделенные серверы в аренду от 4990 руб./мес.
Собственная инфраструктура в Екатеринбурге 🇷🇺, уровень Tier III, SLA от 99,98%, опыт работы с 2013 года.
✅ 70+ готовых к работе конфигураций или любая сборка из 1000+ комплектующих;
✅ Полный доступ к управлению сервером: личный кабинет, KVM-консоль, установка ОС, статистика по трафику;
✅ Техническая поддержка 24/7, помощь в настройке и переносе проектов;
✅ Бесплатная замена любых вышедших из строя комплектующих;
✅ Решения для бизнес задач: серверы с GPU, для 1С-Битрикс и 1С:Бухгалтерии;
✅ Сопутствующие услуги ЦОД: каналы связи, диск для бэкапов, защита от DDOS-атак.
Работаем с юридическими и физическими лицами, поддерживаем ЭДО Диадок.
Оформите заказ в несколько кликов на 👉 https://ekacod.ru/
Или напишите нам, мы подберем нужный сервер для ваших задач по выгодной цене.
#реклама
EKACOD. Data Center предлагает выделенные серверы в аренду от 4990 руб./мес.
Собственная инфраструктура в Екатеринбурге 🇷🇺, уровень Tier III, SLA от 99,98%, опыт работы с 2013 года.
✅ 70+ готовых к работе конфигураций или любая сборка из 1000+ комплектующих;
✅ Полный доступ к управлению сервером: личный кабинет, KVM-консоль, установка ОС, статистика по трафику;
✅ Техническая поддержка 24/7, помощь в настройке и переносе проектов;
✅ Бесплатная замена любых вышедших из строя комплектующих;
✅ Решения для бизнес задач: серверы с GPU, для 1С-Битрикс и 1С:Бухгалтерии;
✅ Сопутствующие услуги ЦОД: каналы связи, диск для бэкапов, защита от DDOS-атак.
Работаем с юридическими и физическими лицами, поддерживаем ЭДО Диадок.
Оформите заказ в несколько кликов на 👉 https://ekacod.ru/
Или напишите нам, мы подберем нужный сервер для ваших задач по выгодной цене.
#реклама
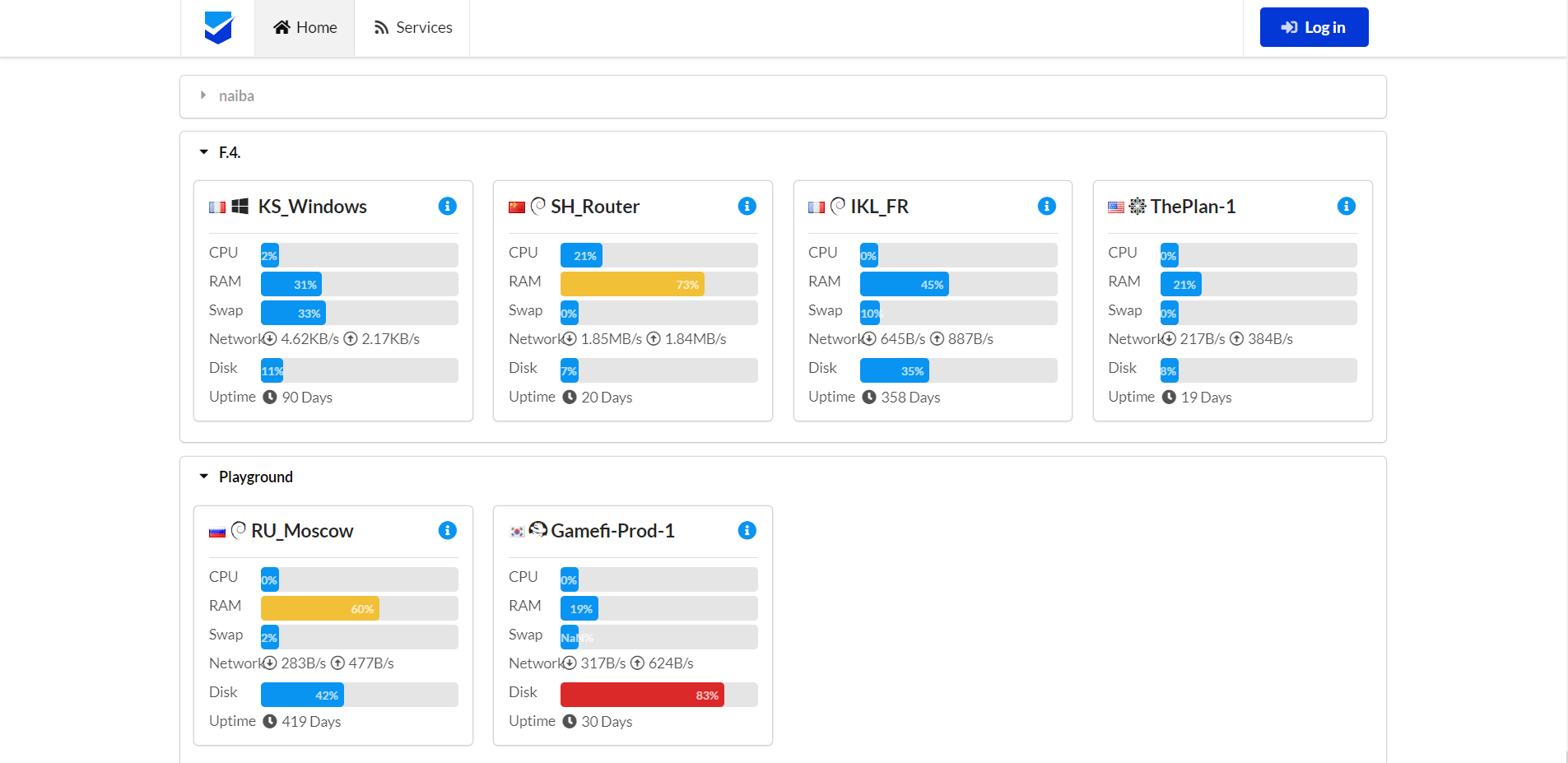
Предлагаю вашему вниманию необычный мониторинг от китайских программистов. Сразу уточню, что поддержка английского языка там есть, так что китайские корни не являются проблемой. А сам мониторинг необычен своей визуализацией. Выглядит непривычно, но интересно и функционально.
Речь идёт про open source проект nezha. Можете сразу оценить функционал в публичном demo - https://ops.naibahq.com. Данный мониторинг поддерживает следующие метрики:
▪ базовые системные метрики (cpu, mem, disik, network)
▪ HTTP, в том числе TLS сертификаты
▪ TCP порты и ICMP проверки
То есть это простой, легковесный мониторинг на GO, который можно развернуть у себя. Проект живой, регулярно обновляется. Попробовать можно в докере, есть готовый образ - ghcr.io/naiba/nezha-dashboard, либо воспользоваться установщиком в виде bash скрипта.
Все инструкции живут в на отдельном сайте - https://nezha.wiki/en_US/index.html. Единственное, что я не понял — аутентификацию в панели зачем-то привязали к Github. Не знаю, в чём тут фишка. Может кто-то считает это удобным, но точно не я. Скрипт установки попросит Client ID и Secret, которые можно получить в github developers, создав новый OAuth app. В принципе, ничего сложного нет и делается за 3 минуты, но я как-то не оценил. Зато после этого доступ можно выдавать на основе учёток Github.
Метрики с серверов собираются с помощью агентов (поддерживаются Windows, Linux, macOS, Synology, OpenWRT). Установить его очень просто. Достаточно добавить новый сервер в панель, и для него появится ссылка для скачивания агента. После установки агента данные автоматически появятся в панели управления. То есть сами агенты настраивать не надо. На серверы с агентами можно зайти по SSH через веб интерфейс панели управления.
Мониторинг максимально простой и удобный, кроме привязки к Github. Если бы не она, можно было смело рекомендовать как вариант простого легко настраиваемого мониторинга. А так решать вам, подходит такой вариант или нет.
#мониторинг
Речь идёт про open source проект nezha. Можете сразу оценить функционал в публичном demo - https://ops.naibahq.com. Данный мониторинг поддерживает следующие метрики:
▪ базовые системные метрики (cpu, mem, disik, network)
▪ HTTP, в том числе TLS сертификаты
▪ TCP порты и ICMP проверки
То есть это простой, легковесный мониторинг на GO, который можно развернуть у себя. Проект живой, регулярно обновляется. Попробовать можно в докере, есть готовый образ - ghcr.io/naiba/nezha-dashboard, либо воспользоваться установщиком в виде bash скрипта.
# bash curl -L \ https://raw.githubusercontent.com/naiba/nezha/master/script/install_en.sh \-o nezha.sh && chmod +x nezha.sh && ./nezha.shВсе инструкции живут в на отдельном сайте - https://nezha.wiki/en_US/index.html. Единственное, что я не понял — аутентификацию в панели зачем-то привязали к Github. Не знаю, в чём тут фишка. Может кто-то считает это удобным, но точно не я. Скрипт установки попросит Client ID и Secret, которые можно получить в github developers, создав новый OAuth app. В принципе, ничего сложного нет и делается за 3 минуты, но я как-то не оценил. Зато после этого доступ можно выдавать на основе учёток Github.
Метрики с серверов собираются с помощью агентов (поддерживаются Windows, Linux, macOS, Synology, OpenWRT). Установить его очень просто. Достаточно добавить новый сервер в панель, и для него появится ссылка для скачивания агента. После установки агента данные автоматически появятся в панели управления. То есть сами агенты настраивать не надо. На серверы с агентами можно зайти по SSH через веб интерфейс панели управления.
Мониторинг максимально простой и удобный, кроме привязки к Github. Если бы не она, можно было смело рекомендовать как вариант простого легко настраиваемого мониторинга. А так решать вам, подходит такой вариант или нет.
#мониторинг
{kind=link}
Делюсь с вами историей из практики, которая случилась на днях. Она вышла типовой и показательной, поэтому рассказываю. Поясню, что я участвовал в рамках платной консультации и настройками не занимался. Только предлагал разные варианты на основе своего опыта.
Ко мне обратился владелец сервиса со средней нагрузкой примерно в 600 rps (запросов в секунду). Использовался типовой стек на базе Nginx, Php-fpm, MySQL и некоторых вспомогательных сервисов. Все запросы клиентов стекались в один php скрипт. Частично был настроен мониторинг на базе Prometheus и Grafana, но сделан был для галочки и большая часть нужных метрик там отсутствовала (по nginx и php-fpm ничего не было). MySQL сервер был отдельной VPS, запросы к нему шли через ProxySQL.
Проблема была на первый взгляд простая. Часть клиентов получали 502 ошибку, которая в nginx выглядела вот так:
connect() to unix:/run/php-fpm/www.sock failed (11: Resource temporarily unavailable) while connecting to upstream
Обычно это следствие нехватки php-fpm воркеров. Если ресурсы сервера позволяют, то надо увеличить их количество. Ресурсов было много. Из 16 ядер и 32 Гб памяти занято было от силы 3-4 ядра и 3-4 Гб памяти. При этом в php-fpm был настроен статичный запуск воркеров, а их кол-во всего 32, что по моим представлениям очень мало для подобной задачи и сервера.
Дальше началось самое интересное. Увеличение числа воркеров не приводило к исчезновению ошибки об их нехватке в nginx. Более того, чем больше добавляешь воркеров, тем больше 502 ошибок у пользователей и тем меньше 200 ответов.
После того, как поиграли с числом воркеров php-fpm, я понял, что узкое место не со стороны веб сервера, но так как мониторинга не было, не понятно, куда смотреть. На всякий случай проверили лимиты операционной системы на подключения к unix сокетам, сетевым подключениям, файловым дескрипторам. Проблем не было. Потом таймауты nginx и fastcgi. На первый взгляд тоже всё в порядке. Настроили быстро мониторинг php-fpm и через консоль вручную смотрели метрики, но ничего полезного там не увидели.
Для эксперимента я предложил сменить режим работы php-fpm с unix сокета на tcp и добавить много воркеров, штук 100-200, можно было бы и 500, сервер тянул. Ошибка в Nginx изменилась, но суть осталась прежней. Там просто по таймауту отваливались подключения к воркерам. Увеличение количества воркеров не решало проблему.
На этом этапе я уже окончательно убедился, что проблема не с веб сервером. У меня были две идеи: либо не тянет БД, либо в php скрипте какой-то замкнутый цикл, который с ростом числа воркеров просто плодит паразитную нагрузку, а запросы клиентов так и остаются с ошибками. Для БД был какой-то мониторинг, но он толком ничего не показывал. Были метрики числа и времени выполнения запросов, число столбцов, участвовавших в них и что-то ещё. Эти метрики показывали ровные линии, без всплесков и провалов. Каких-то базовых метрик на тему производительности не было, поэтому трудно было оценить, что там вообще происходит. По htop повышенная нагрузка не просматривалась.
В завершении я предположил, что в ProxySQL стоит ограничение на входящие запросы, поэтому сверх лимита они все отбрасываются, либо висят в очереди, поэтому нагрузка на MySQL ровная. На всякий случай ещё проверил количество TCP подключений к серверу, нет ли там узкого места. Его не было, коннектов не сказать, что сильно много и ни в какие лимиты они не упирались. На этом распрощались.
Потом заказчик добавил ещё один веб сервер и часть запросов отправил туда, но это не помогло. Проблема решилась просто — увеличили в 2 раза ресурсы MySQL сервера и всё поехало, как надо.
💡Написал я всё это к чему. Всегда надо делать хороший мониторинг. Без него решать подобные задачи трудно, уходит много времени, результат непредсказуем. Настройка мониторинга заняла бы меньше времени, чем в итоге решение всего лишь одной проблемы. Весь софт, который участвует в работе системы, должен мониториться, и не для галочки, а нужными метриками.
#мониторинг
Ко мне обратился владелец сервиса со средней нагрузкой примерно в 600 rps (запросов в секунду). Использовался типовой стек на базе Nginx, Php-fpm, MySQL и некоторых вспомогательных сервисов. Все запросы клиентов стекались в один php скрипт. Частично был настроен мониторинг на базе Prometheus и Grafana, но сделан был для галочки и большая часть нужных метрик там отсутствовала (по nginx и php-fpm ничего не было). MySQL сервер был отдельной VPS, запросы к нему шли через ProxySQL.
Проблема была на первый взгляд простая. Часть клиентов получали 502 ошибку, которая в nginx выглядела вот так:
connect() to unix:/run/php-fpm/www.sock failed (11: Resource temporarily unavailable) while connecting to upstream
Обычно это следствие нехватки php-fpm воркеров. Если ресурсы сервера позволяют, то надо увеличить их количество. Ресурсов было много. Из 16 ядер и 32 Гб памяти занято было от силы 3-4 ядра и 3-4 Гб памяти. При этом в php-fpm был настроен статичный запуск воркеров, а их кол-во всего 32, что по моим представлениям очень мало для подобной задачи и сервера.
Дальше началось самое интересное. Увеличение числа воркеров не приводило к исчезновению ошибки об их нехватке в nginx. Более того, чем больше добавляешь воркеров, тем больше 502 ошибок у пользователей и тем меньше 200 ответов.
После того, как поиграли с числом воркеров php-fpm, я понял, что узкое место не со стороны веб сервера, но так как мониторинга не было, не понятно, куда смотреть. На всякий случай проверили лимиты операционной системы на подключения к unix сокетам, сетевым подключениям, файловым дескрипторам. Проблем не было. Потом таймауты nginx и fastcgi. На первый взгляд тоже всё в порядке. Настроили быстро мониторинг php-fpm и через консоль вручную смотрели метрики, но ничего полезного там не увидели.
Для эксперимента я предложил сменить режим работы php-fpm с unix сокета на tcp и добавить много воркеров, штук 100-200, можно было бы и 500, сервер тянул. Ошибка в Nginx изменилась, но суть осталась прежней. Там просто по таймауту отваливались подключения к воркерам. Увеличение количества воркеров не решало проблему.
На этом этапе я уже окончательно убедился, что проблема не с веб сервером. У меня были две идеи: либо не тянет БД, либо в php скрипте какой-то замкнутый цикл, который с ростом числа воркеров просто плодит паразитную нагрузку, а запросы клиентов так и остаются с ошибками. Для БД был какой-то мониторинг, но он толком ничего не показывал. Были метрики числа и времени выполнения запросов, число столбцов, участвовавших в них и что-то ещё. Эти метрики показывали ровные линии, без всплесков и провалов. Каких-то базовых метрик на тему производительности не было, поэтому трудно было оценить, что там вообще происходит. По htop повышенная нагрузка не просматривалась.
В завершении я предположил, что в ProxySQL стоит ограничение на входящие запросы, поэтому сверх лимита они все отбрасываются, либо висят в очереди, поэтому нагрузка на MySQL ровная. На всякий случай ещё проверил количество TCP подключений к серверу, нет ли там узкого места. Его не было, коннектов не сказать, что сильно много и ни в какие лимиты они не упирались. На этом распрощались.
Потом заказчик добавил ещё один веб сервер и часть запросов отправил туда, но это не помогло. Проблема решилась просто — увеличили в 2 раза ресурсы MySQL сервера и всё поехало, как надо.
💡Написал я всё это к чему. Всегда надо делать хороший мониторинг. Без него решать подобные задачи трудно, уходит много времени, результат непредсказуем. Настройка мониторинга заняла бы меньше времени, чем в итоге решение всего лишь одной проблемы. Весь софт, который участвует в работе системы, должен мониториться, и не для галочки, а нужными метриками.
#мониторинг
Старый мем из комментариев к одной статье на сайте. Я его публиковал уже пару лет назад, когда тут читателей раз в 5 меньше было. Читать диалог снизу вверх.
Как обычно, мемы в комментариях приветствуются. Я все просмотрел к прошлому посту.
#мем
Как обычно, мемы в комментариях приветствуются. Я все просмотрел к прошлому посту.
#мем
❓ Ко мне поступил вопрос, ответ на который я знаю. Более того, он реализован в виде статьи, по которой можно решить похожие задачи по аналогии. Я не буду копировать вопрос слово в слово, сокращу, оставив суть.
Zabbix мониторит инфраструктуру, метрики собираются, триггеры работают. Но хочется получать больше фактической информации в момент срабатывания триггера. Например, при срабатывании триггера на нехватку места на диске, сразу же пройтись по серверу командой:
И результат отправить в уведомление или где-то сохранить для просмотра.
Желание понятное. Я сам одно время задумался над такой же задачей и реализовал её в лоб. Мне захотелось, чтобы вместе с оповещением триггера о том, что высокая нагрузка на CPU, мне сразу же прилетела информация о топ 10 самых нагруженных процессов.
У Zabbix нет готовых инструментов для реализации такой задачи. Я реализовал следующим образом:
1️⃣ Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
2️⃣ Разрешаю на zabbix agent запуск внешних команд.
3️⃣ Настраиваю на Zabbix Server действие при срабатывании одного из нужных мне триггеров. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
В моём случае я отправлял результат работы команды:
По аналогии решается любая похожая задача.
Подробности рассказывать здесь не буду, так как всё это наглядно по шагам описано в статье:
⇨ https://serveradmin.ru/monitoring-spiska-zapushhennyh-proczessov-v-zabbix/
#вопрос_читателя #zabbix
Zabbix мониторит инфраструктуру, метрики собираются, триггеры работают. Но хочется получать больше фактической информации в момент срабатывания триггера. Например, при срабатывании триггера на нехватку места на диске, сразу же пройтись по серверу командой:
find -type f -exec du -Sh {} + | sort -rh | head -n 10И результат отправить в уведомление или где-то сохранить для просмотра.
Желание понятное. Я сам одно время задумался над такой же задачей и реализовал её в лоб. Мне захотелось, чтобы вместе с оповещением триггера о том, что высокая нагрузка на CPU, мне сразу же прилетела информация о топ 10 самых нагруженных процессов.
У Zabbix нет готовых инструментов для реализации такой задачи. Я реализовал следующим образом:
1️⃣ Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
2️⃣ Разрешаю на zabbix agent запуск внешних команд.
3️⃣ Настраиваю на Zabbix Server действие при срабатывании одного из нужных мне триггеров. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
В моём случае я отправлял результат работы команды:
# ps aux --sort=-pcpu,+pmem | awk 'NR<=10'По аналогии решается любая похожая задача.
Подробности рассказывать здесь не буду, так как всё это наглядно по шагам описано в статье:
⇨ https://serveradmin.ru/monitoring-spiska-zapushhennyh-proczessov-v-zabbix/
#вопрос_читателя #zabbix
Server Admin
Мониторинг списка запущенных процессов в Zabbix | serveradmin.ru
Получение информации о топ 10 нагруженных процессов в Linux в момент срабатывания триггера в Zabbix на нагрузку CPU.
Закрою тему с регулярными выражениями ещё парой полезных ссылок, которыми поделились в комментариях. Первое — сервис на основе OpenAI, который английский текст переводит в регулярные выражения. Причём делает он это неплохо.
⇨ https://www.autoregex.xyz
Я попробовал пару примеров. Сделать регулярку по маске телефона +7903ххххххх. Прям так и написал в запрос: Phone number regexp by mask +7903ххххххх. Выдал ответ:
Вот ещё пример. Минимум восемь символов, по крайней мере, одна заглавная английская буква, одна строчная английская буква, одна цифра и один специальный символ. Запрос написал так: Minimum eight characters, at least one upper case English letter, one lower case English letter, one number and one special character. Регулярку получил такую 😱:
Проверил через regex101.com, регулярка верная. По крайней мере не смог подобрать неподходящий вариант. Спецсимволы, как я понял, перечислены тут - [@$!%*#?&]
И ещё одна полезная ссылка:
⇨ https://regexlearn.com/ru
Это хорошая обучающая программа на русском языке для изучения регулярок. По своей сути это open source проект, переведённый на разные языки.
📌 Все ресурсы по regexp одним списком:
▪️ regex101.com — проверка регулярных выражений
▪️ grex — автоматическое составление регулярок
▪️ regexper.com — схематическое изображение регулярок
▪️ ihateregex.io — готовые примеры регулярных выражений
▪️ autoregex.xyz — построение регулярок с помощью ИИ
▪️ stepik.org — бесплатный курс для изучения регулярок
▪️ regexlearn.com — обучение regex на русском языке
#regex
⇨ https://www.autoregex.xyz
Я попробовал пару примеров. Сделать регулярку по маске телефона +7903ххххххх. Прям так и написал в запрос: Phone number regexp by mask +7903ххххххх. Выдал ответ:
\+7903\d{6}. В целом верно, только должно быть \+7903\d{7}. Вот ещё пример. Минимум восемь символов, по крайней мере, одна заглавная английская буква, одна строчная английская буква, одна цифра и один специальный символ. Запрос написал так: Minimum eight characters, at least one upper case English letter, one lower case English letter, one number and one special character. Регулярку получил такую 😱:
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*#?&])[A-Za-z\d@$!#%*?&]{8,}$Проверил через regex101.com, регулярка верная. По крайней мере не смог подобрать неподходящий вариант. Спецсимволы, как я понял, перечислены тут - [@$!%*#?&]
И ещё одна полезная ссылка:
⇨ https://regexlearn.com/ru
Это хорошая обучающая программа на русском языке для изучения регулярок. По своей сути это open source проект, переведённый на разные языки.
📌 Все ресурсы по regexp одним списком:
▪️ regex101.com — проверка регулярных выражений
▪️ grex — автоматическое составление регулярок
▪️ regexper.com — схематическое изображение регулярок
▪️ ihateregex.io — готовые примеры регулярных выражений
▪️ autoregex.xyz — построение регулярок с помощью ИИ
▪️ stepik.org — бесплатный курс для изучения регулярок
▪️ regexlearn.com — обучение regex на русском языке
#regex
{kind=link}
На днях нужно было с API поработать. Поставил, как обычно, Postman. Я уже писал о нём. Раньше всегда его использовал, а на новом ноуте ещё не приходилось. Скачал последнюю версию, запустил. Заметил, что он как-то потяжелел. Решил посмотреть на аналоги.
Сразу скажу, что наиболее известный аналог — Insomnia.rest. Я не стал его пробовать, так как слышал про плагин для VSCode — REST Client. Решил попробовать его, так как постоянно использую VSCode. В целом, можно подёргать апишку одиночными запросами, посмотреть результат, но мне не очень понравился предложенный формат работы в интерфейсе VSCode. Так что вернулся на Postman.
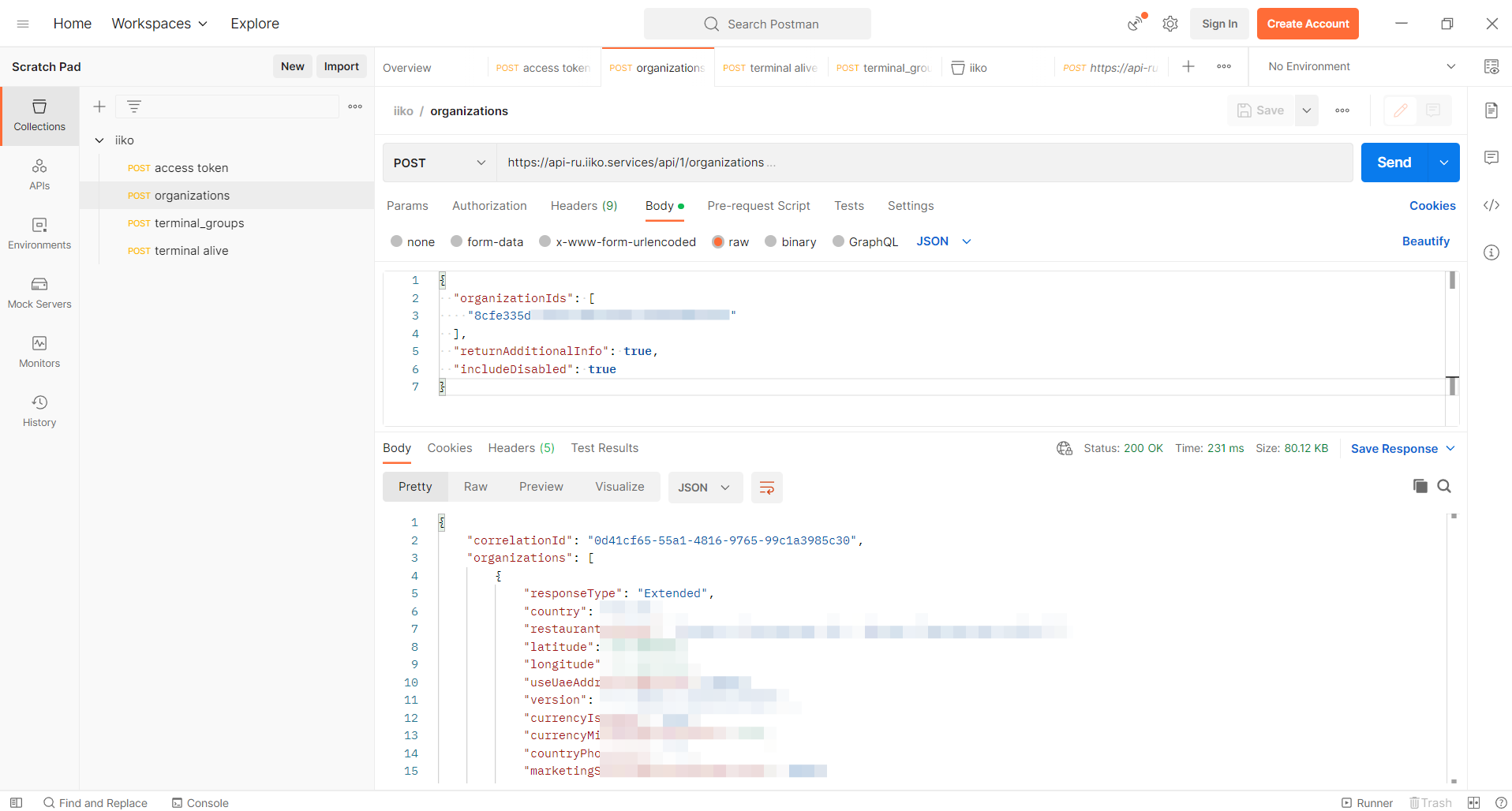
Покажу пример, как его использую я. Допустим, надо замониторить какие-то метрики из API. Сначала надо всё проверить, посмотреть ответы, форматы данных и т.д. Доступ к API часто по временным токенам, которые надо постоянно обновлять. В Postman удобно сделать переменные, записать туда токен или какую-то ещё меняющуюся информацию (uid и т.д.) и потом во всех запросах использовать эту переменную. Запросы все сохраняются, открываются в разных вкладках. Один раз настроив все переменные и запросы, можно сохранить проект и потом к нему вернуться.
Это удобно, в отличие от работы с апишками через curl в консоли. Я долгое время именно так и работал с api. Потом попробовал Postman и стал пользоваться им, если нужно что-то более, чем сделать несколько одиночных запросов. Так что рекомендую, если ещё не пробовали.
Postman кучу всего умеет делать. Он и историю хранит, и постобработку делает, и скрипты автоматических проверок с его помощью можно писать. По идее всё это избыточно в рамках моей работы, но мне нравится эта программа. Из минусов, это жирненький Electron. При установке вообще ничего не спрашивает. Просто ставится после запуска установщика с настройками по умолчанию.
#api #devops
Сразу скажу, что наиболее известный аналог — Insomnia.rest. Я не стал его пробовать, так как слышал про плагин для VSCode — REST Client. Решил попробовать его, так как постоянно использую VSCode. В целом, можно подёргать апишку одиночными запросами, посмотреть результат, но мне не очень понравился предложенный формат работы в интерфейсе VSCode. Так что вернулся на Postman.
Покажу пример, как его использую я. Допустим, надо замониторить какие-то метрики из API. Сначала надо всё проверить, посмотреть ответы, форматы данных и т.д. Доступ к API часто по временным токенам, которые надо постоянно обновлять. В Postman удобно сделать переменные, записать туда токен или какую-то ещё меняющуюся информацию (uid и т.д.) и потом во всех запросах использовать эту переменную. Запросы все сохраняются, открываются в разных вкладках. Один раз настроив все переменные и запросы, можно сохранить проект и потом к нему вернуться.
Это удобно, в отличие от работы с апишками через curl в консоли. Я долгое время именно так и работал с api. Потом попробовал Postman и стал пользоваться им, если нужно что-то более, чем сделать несколько одиночных запросов. Так что рекомендую, если ещё не пробовали.
Postman кучу всего умеет делать. Он и историю хранит, и постобработку делает, и скрипты автоматических проверок с его помощью можно писать. По идее всё это избыточно в рамках моей работы, но мне нравится эта программа. Из минусов, это жирненький Electron. При установке вообще ничего не спрашивает. Просто ставится после запуска установщика с настройками по умолчанию.
#api #devops
{kind=link}
Хочу подкинуть вам идею, которая может когда-нибудь пригодиться. Подключение к NFS серверу можно организовать через проброс портов по SSH и это нормально работает. Когда есть sshfs, может показаться, что в этом нет никакого смысла. Могу привести свой пример, когда мне это пригодилось.
Мне нужно было перекинуть бэкапы виртуалок с внешнего сервера Proxmox домой на мой NFS сервер. Тут вариант либо порты пробрасывать на домашний сервер, но это если у тебя белый IP, либо как раз воспользоваться пробросом портов, подключившись из дома к внешнему серверу по SSH.
Настраивать тут особо ничего не надо. Если NFS сервер уже настроен, то достаточно сделать обратный проброс локального порта 2049 на внешний сервер:
Если на той стороне уже есть nfs сервер и порт 2049 занят, то можно указать другой. Только надо аккуратно поменять ровно то, что нужно. Я обычно путаюсь в пробросе портов по SSH, так как тут неинтуитивно. Должно быть вот так:
Останется только на удалённом сервере подмонтировать том:
Тут ещё стоит понимать, что nfs и sshfs принципиально разные вещи. Первое — это полноценная сетевая файловая система со своими службами, хранением метаданных и т.д., а второе — реализация доступа к файлам по протоколу SFTP на базе FUSE (Filesystem in Userspace). SFTP обычно используется для разовой передачи файлов. NFS же можно ставить на постоянку. Это стабильное решение (но не через SSH 😀).
#nfs #ssh #fileserver
Мне нужно было перекинуть бэкапы виртуалок с внешнего сервера Proxmox домой на мой NFS сервер. Тут вариант либо порты пробрасывать на домашний сервер, но это если у тебя белый IP, либо как раз воспользоваться пробросом портов, подключившись из дома к внешнему серверу по SSH.
Настраивать тут особо ничего не надо. Если NFS сервер уже настроен, то достаточно сделать обратный проброс локального порта 2049 на внешний сервер:
# ssh -R 2049:127.0.0.1:2049 root@server-ipЕсли на той стороне уже есть nfs сервер и порт 2049 занят, то можно указать другой. Только надо аккуратно поменять ровно то, что нужно. Я обычно путаюсь в пробросе портов по SSH, так как тут неинтуитивно. Должно быть вот так:
# ssh -R 3049:127.0.0.1:2049 root@server-ipОстанется только на удалённом сервере подмонтировать том:
# mount -t nfs -o port=3049 localhost:/data /mnt/nfs-shareТут ещё стоит понимать, что nfs и sshfs принципиально разные вещи. Первое — это полноценная сетевая файловая система со своими службами, хранением метаданных и т.д., а второе — реализация доступа к файлам по протоколу SFTP на базе FUSE (Filesystem in Userspace). SFTP обычно используется для разовой передачи файлов. NFS же можно ставить на постоянку. Это стабильное решение (но не через SSH 😀).
#nfs #ssh #fileserver
Те, кто постоянно работают с Postgresql наверняка знают про такой параметр, как stats_temp_directory. В самой документации по СУБД сказано, что его перенос в ОЗУ снизит нагрузку на файловое хранилище и увеличит быстродействие.
Я в обязательном порядке переносил это хранилище для временных данных статистики в tmpfs, потому что при использовании SSD этот каталог очень быстро съедал его ресурс. И это не пустые опасения, как часто бывает с SSD. Я реально видел по мониторингу, как утекал ресурс. Там идёт постоянная активная перезапись.
Хорошая новость в том, что в Postgres 15 больше не потребуется это делать. Там все подсчёты статистики выполняются в памяти по умолчанию. Такого параметра, как stats_temp_directory больше нет.
Сейчас уже активно обновляют или ставят 1С вместе с Postgres 15, так что информирую. Сборку postgresql для 1С можно скачать тут - https://1c.postgres.ru. 15-я уже в наличии.
#postgresql
Я в обязательном порядке переносил это хранилище для временных данных статистики в tmpfs, потому что при использовании SSD этот каталог очень быстро съедал его ресурс. И это не пустые опасения, как часто бывает с SSD. Я реально видел по мониторингу, как утекал ресурс. Там идёт постоянная активная перезапись.
Хорошая новость в том, что в Postgres 15 больше не потребуется это делать. Там все подсчёты статистики выполняются в памяти по умолчанию. Такого параметра, как stats_temp_directory больше нет.
Сейчас уже активно обновляют или ставят 1С вместе с Postgres 15, так что информирую. Сборку postgresql для 1С можно скачать тут - https://1c.postgres.ru. 15-я уже в наличии.
#postgresql
Недавно на официальном канале Zabbix были опубликованы несколько интересных видео с митапа на английском языке. Основная тема — мониторинг облачных структур и Kubernetes. Там прям с конкретными примерами внедрения (по куберу). Что, как и куда ставили, какие метрики собирали и т.д. Всё это с реальными картинками. Получилось информативно.
Если вам интересна эта тема, то рекомендую.
▪ Kubernetes monitoring with Zabbix - Initial configuration
▪ Monitoring Kubernetes with Zabbix
▪ Cloud monitoring with Zabbix
▪ Monitoring O365 Defender and other Azure cloud resources
Также напоминаю, что Zabbix регулярно проводит вебинары на русском языке по базовым темам. Завтра в 11 по мск должен быть вебинар Установите и настройте Zabbix за 5 минут.
#zabbix #видео
Если вам интересна эта тема, то рекомендую.
▪ Kubernetes monitoring with Zabbix - Initial configuration
▪ Monitoring Kubernetes with Zabbix
▪ Cloud monitoring with Zabbix
▪ Monitoring O365 Defender and other Azure cloud resources
Также напоминаю, что Zabbix регулярно проводит вебинары на русском языке по базовым темам. Завтра в 11 по мск должен быть вебинар Установите и настройте Zabbix за 5 минут.
#zabbix #видео
{kind=link}
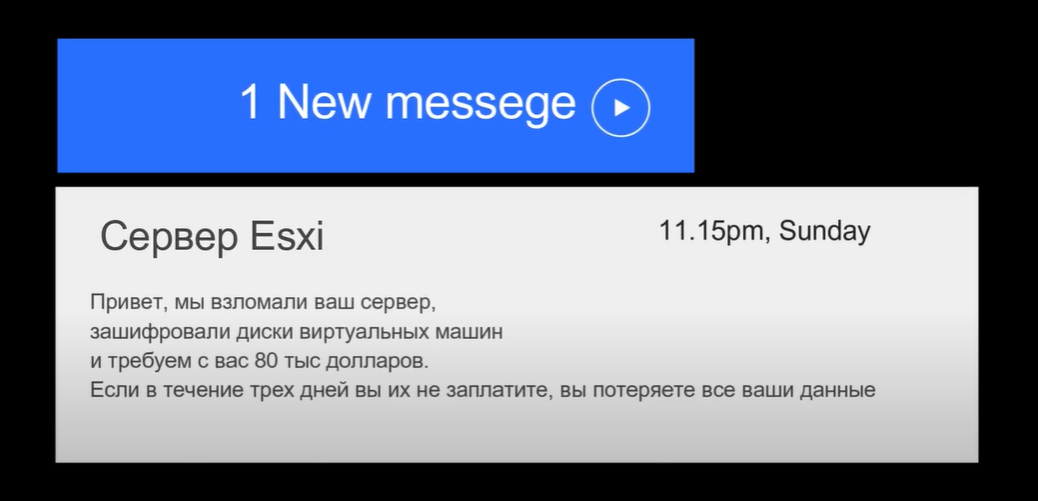
Вчера посмотрел очень любопытные видео про взлом гипервизора Esxi и шифрование виртуалок. Вот они:
⇨ Esxi: меня взломали! Лечим и понимаем причину.
⇨ Esxi: меня взломали! Лечим и понимаем причину, часть 2
Там прям со всеми подробностями всё описано и рассказано. И как "шифровали" и как "расшифровывали". Это история со счастливым концом, но так бывает не всегда.
Я вообще не удивлён такой истории, так как лет 5 назад один мой знакомый точно так же в один прекрасный момент получил полностью зашифрованный набитый виртуалками гипервизор Esxi. Потом дня 3 лил на него бэкапы (хорошо, что были), восстанавливал работоспособность. Гипервизор обслуживал работу реального производства.
Любые массовые программные продукты всегда под прицелом взломщиков. Поэтому если есть возможность, всегда нужно ограничивать доступ, даже если вы своевременно ставите все обновления. Дырки сначала находят, а потом делают закладки. В интервале, когда уязвимость нашли и когда к ней вышел патч, может пострадать большое количество пользователей.
В истории из видео всё как по учебникам вредных советов. Обновления не ставились, доступ был отовсюду и это на массовый продукт. И ещё один важный момент. Автор не видел, что его фаервол на самом деле не работал. Он видел список правил, мог их менять, но как оказалось, в интерфейсе управления правилами фаервола не было вообще никакой информации о том, что он запущен.❗️По факту получилось, что правила были настроены, а фаервол выключен.
Из-за таких историй с фаерволами, в которые я тоже попадал, я уже неоднократно делал заметки на тему nmap и других похожих программ. Периодически делайте тестирование своей инфраструктуры откуда-то извне. Так у вас есть шанс заметить то, что не должно быть в публичном доступе. Хотя бы простенький скрипт используйте, который я описывал в статье или программный продукт, типа простенького flan или более серьезных OpenVAS и Nessus Scanner.
Лично я давно уже все SSH доступы, а особенно доступы к интерфейсам управления гипервизорами, закрываю белыми списками IP адресов. Даже если у вас нет статического IP, добавьте всю подсеть своего домашнего провайдера. А вообще советую вам завести 2-3 максимально дешёвые VPS именно для получения статического внешнего IP. Это если вам его больше взять неоткуда.
Кому-нибудь ещё зашифровали гипервизор? Я так понял, что история получилась массовая.
#security
⇨ Esxi: меня взломали! Лечим и понимаем причину.
⇨ Esxi: меня взломали! Лечим и понимаем причину, часть 2
Там прям со всеми подробностями всё описано и рассказано. И как "шифровали" и как "расшифровывали". Это история со счастливым концом, но так бывает не всегда.
Я вообще не удивлён такой истории, так как лет 5 назад один мой знакомый точно так же в один прекрасный момент получил полностью зашифрованный набитый виртуалками гипервизор Esxi. Потом дня 3 лил на него бэкапы (хорошо, что были), восстанавливал работоспособность. Гипервизор обслуживал работу реального производства.
Любые массовые программные продукты всегда под прицелом взломщиков. Поэтому если есть возможность, всегда нужно ограничивать доступ, даже если вы своевременно ставите все обновления. Дырки сначала находят, а потом делают закладки. В интервале, когда уязвимость нашли и когда к ней вышел патч, может пострадать большое количество пользователей.
В истории из видео всё как по учебникам вредных советов. Обновления не ставились, доступ был отовсюду и это на массовый продукт. И ещё один важный момент. Автор не видел, что его фаервол на самом деле не работал. Он видел список правил, мог их менять, но как оказалось, в интерфейсе управления правилами фаервола не было вообще никакой информации о том, что он запущен.❗️По факту получилось, что правила были настроены, а фаервол выключен.
Из-за таких историй с фаерволами, в которые я тоже попадал, я уже неоднократно делал заметки на тему nmap и других похожих программ. Периодически делайте тестирование своей инфраструктуры откуда-то извне. Так у вас есть шанс заметить то, что не должно быть в публичном доступе. Хотя бы простенький скрипт используйте, который я описывал в статье или программный продукт, типа простенького flan или более серьезных OpenVAS и Nessus Scanner.
Лично я давно уже все SSH доступы, а особенно доступы к интерфейсам управления гипервизорами, закрываю белыми списками IP адресов. Даже если у вас нет статического IP, добавьте всю подсеть своего домашнего провайдера. А вообще советую вам завести 2-3 максимально дешёвые VPS именно для получения статического внешнего IP. Это если вам его больше взять неоткуда.
Кому-нибудь ещё зашифровали гипервизор? Я так понял, что история получилась массовая.
#security
{kind=link}
Расскажу вам про полезный инструмент, которым с одной стороны можно будет пользоваться самим, а с другой стороны для понимания того, как этот инструмент могут использовать другие. В том числе и против вас.
Речь пойдёт про сервис для обмена файлами pwndrop, который можно развернуть у себя. Это open source проект, исходники на github. В базе это простой и удобный сервис для обмена файлами. Ставится в пару действий, имеет простой конфиг, приятный и удобный веб интерфейс. Служба написана на Go, веб интерфейс на JavaScript. Работает шустро.
Основной функционал у pwndrop типичный для таких сервисов. Загружаете файл, получаете ссылку и делитесь ею с другими людьми. Причём загрузить ваш файл они могут как по http, так и по webdav. Из удобств — автоматически получает сертификат от let's encrypt, если развёрнут на реальном доменном имени с DNS записью.
А теперь его особенности, так как позиционируется он как инструмент для пентестеров. Я не буду перечислять всё, что в есть в описании, так как некоторые вещи не понимаю. Расскажу, что попробовал сам.
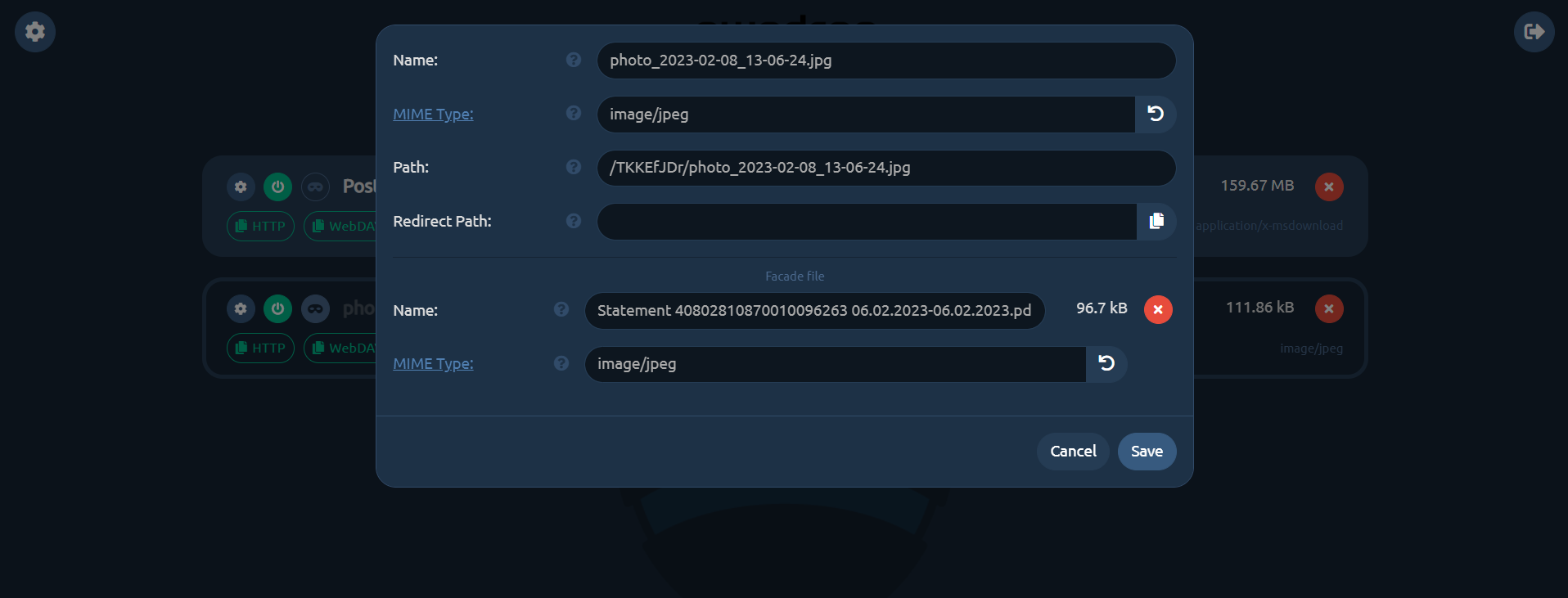
◽У pwndrop можно изменить url админки, чтобы скрыть её от посторонних глаз. Обращение на основной домен можно перенаправить в любое другое место. То есть наличие самого сервиса на конкретном домене можно спрятать, оставив только доступ по прямым ссылкам, которые заранее известны.
◽Pwndrop умеет подменять изначально загруженный файл на какой-то другой. То есть вы можете загрузить файл, отдать кому-то ссылку. А потом в настройках доступа к этому файлу указать для загрузки другой файл. В итоге по одной и той же ссылке в разное время можно загружать разные файлы. Всё это управляется из админки и может включаться и выключаться по вашему усмотрению.
◽В настройках загруженного файла можно указать любой другой url, куда будет выполняться редирект при обращении по ссылке на скачивание. То есть вместо подмены файла, описанной выше, происходит редирект на произвольный url.
На примере подобного сервиса можно легко понять, как загружая по известной ссылке какой-то файл, можно получить совсем не то, что ожидаешь. Понятно, что подобные вещи не представляют какой-то особой сложности и при желании всегда можно сделать такую подмену. Но с такими готовыми серверами, это доступно любому школьнику. Так что будьте внимательны.
Pwndrop ставится скриптом, либо вручную скачиванием архива со всеми файлами. По умолчанию он устанавливает себя в /usr/local/pwndrop, там и конфиг, и бинарник. Также создаёт systemd службу. Формат конфига очень простой, примеры настроек есть в репозитории. Их буквально несколько штук (порты, директории, ip и т.д.). Также запустить сервер можно в Docker с помощью готового образа от linuxserver.io.
Я попробовал. Сервис реально простой, удобный, легко ставится, легко настраивается. Может оказаться полезным и для личного использования, и для совместной работы с кем-то. Веб интерфейс адаптивен для смартфонов.
⇨ Сайт / Исходники
#fileserver
Речь пойдёт про сервис для обмена файлами pwndrop, который можно развернуть у себя. Это open source проект, исходники на github. В базе это простой и удобный сервис для обмена файлами. Ставится в пару действий, имеет простой конфиг, приятный и удобный веб интерфейс. Служба написана на Go, веб интерфейс на JavaScript. Работает шустро.
Основной функционал у pwndrop типичный для таких сервисов. Загружаете файл, получаете ссылку и делитесь ею с другими людьми. Причём загрузить ваш файл они могут как по http, так и по webdav. Из удобств — автоматически получает сертификат от let's encrypt, если развёрнут на реальном доменном имени с DNS записью.
А теперь его особенности, так как позиционируется он как инструмент для пентестеров. Я не буду перечислять всё, что в есть в описании, так как некоторые вещи не понимаю. Расскажу, что попробовал сам.
◽У pwndrop можно изменить url админки, чтобы скрыть её от посторонних глаз. Обращение на основной домен можно перенаправить в любое другое место. То есть наличие самого сервиса на конкретном домене можно спрятать, оставив только доступ по прямым ссылкам, которые заранее известны.
◽Pwndrop умеет подменять изначально загруженный файл на какой-то другой. То есть вы можете загрузить файл, отдать кому-то ссылку. А потом в настройках доступа к этому файлу указать для загрузки другой файл. В итоге по одной и той же ссылке в разное время можно загружать разные файлы. Всё это управляется из админки и может включаться и выключаться по вашему усмотрению.
◽В настройках загруженного файла можно указать любой другой url, куда будет выполняться редирект при обращении по ссылке на скачивание. То есть вместо подмены файла, описанной выше, происходит редирект на произвольный url.
На примере подобного сервиса можно легко понять, как загружая по известной ссылке какой-то файл, можно получить совсем не то, что ожидаешь. Понятно, что подобные вещи не представляют какой-то особой сложности и при желании всегда можно сделать такую подмену. Но с такими готовыми серверами, это доступно любому школьнику. Так что будьте внимательны.
Pwndrop ставится скриптом, либо вручную скачиванием архива со всеми файлами. По умолчанию он устанавливает себя в /usr/local/pwndrop, там и конфиг, и бинарник. Также создаёт systemd службу. Формат конфига очень простой, примеры настроек есть в репозитории. Их буквально несколько штук (порты, директории, ip и т.д.). Также запустить сервер можно в Docker с помощью готового образа от linuxserver.io.
Я попробовал. Сервис реально простой, удобный, легко ставится, легко настраивается. Может оказаться полезным и для личного использования, и для совместной работы с кем-то. Веб интерфейс адаптивен для смартфонов.
⇨ Сайт / Исходники
#fileserver
{kind=link}
Мне казалось, что когда-то я уже делал публикацию на тему софта на смартфоне для системного администратора, но не смог её найти 🤷🏻♂️ Может мне это приснилось 🤫 Решил поднять ещё раз эту тему и собрать обратную связь.
Сам я практически не использую смартфон в качестве рабочего инструмента, тем не менее, на нём стоит много софта, который иногда используется для рабочих моментов. Идея для сегодняшней публикации возникла в связи с одной программой, о которой я скажу в конце отдельно. А сейчас просто приведу краткий список тех программ, что в разное время стояли на моём смартфоне и использовались для дел, связанных с системным администрированием.
✅Первый список того, что стоит прямо сейчас:
◽RD Client — RDP клиент от Microsoft. Пользуюсь регулярно для разных задач.
◽OpenVPN Connect — обычный ovpn клиент.
◽Total Commander — просто люблю этот файловый менеджер, использую постоянно, особенно lan плагин, чтобы копировать по smb с NAS.
◽Todoist — про этот сервис упоминал не раз, использую в качестве списка дел, пользуюсь постоянно, но на смартфоне на крайний случай стоит.
◽MikroTik — приложение для управления Микротиками.
◽KPass — стоит на всякий случай, если придётся глянуть пароли. Пользуюсь редко, постоянно файл с паролями на смартфоне не лежит, надо сначала скачать.
◽Joplin — клиент для просмотра заметок, пользуюсь на смартфоне редко, но иногда надо.
◽Planyway — приложение от одноименного сервиса, использую для календаря с планированием, рассказывал о нём отдельно.
◽ProxMon — ставил, когда писал заметку, на практике не возникла ни одно ситуации, что мне пришлось бы им воспользоваться.
◽UptimeRobot — приложение от одноимённого сервиса мониторинга, а котором рассказывал отдельно.
💡Теперь то, что было полезным и стояло в разное время:
◽Wifi manager — позволяет быстро и наглядно оценить загруженность частоты wifi по каналам.
◽Wifi Analyzer — с его помощью я проверял работу capsman от микротик. С помощью программы можно увидеть множество точек за одним SSID и подключаться к ним по MAC адресу. Это одна из возможностей, которая интересна лично мне. В программе много других полезных функций.
◽Zadarma — клиент sip телефонии. Использую, когда настраиваю asterisk. Сервис задарма удобен в качестве тестового транка на время настройки и тестирования.
◽Клавиатура для паролей — простое приложение, которое позволяет легко вводить пароли, которые придуманы в русской раскладке, но вводятся на английском языке. Сам я такие не люблю использовать, но приходится работать и с ними. Без русской клавиатуры их вводить очень неудобно.
◽JuiceSSH — ssh клиент. Пользовался редко, так как через смартфон работать по ssh очень неудобно, хоть какой клиент ни возьми.
◽PingTools — набор полезных сетевых утилит. Можно пингануть, трассерунть что-то прямо из смартфона.
🎓Отдельно расскажу про приложение Linux Command Library, которое можно поставить из Google Play. Это огромная база данных по командам, утилитам, однострочникам в Linux. Хоть и не часто, но иногда приходится что-то искать, смотреть в смартфоне, особенно когда в серверную за консоль приходишь. В ней удобно подсмотреть какие-то команды, вместо того, чтобы их гуглить. Там всё удобно разбито по темам. В общем, сами посмотрите, приложение популярное.
❗️А теперь хотел бы у вас спросить, что из нашей тематики у вас есть в смартфонах под Android? Если будет много полезных комментариев с программами, то сделаю ещё один общий список.
#смартфон #разное #android
Сам я практически не использую смартфон в качестве рабочего инструмента, тем не менее, на нём стоит много софта, который иногда используется для рабочих моментов. Идея для сегодняшней публикации возникла в связи с одной программой, о которой я скажу в конце отдельно. А сейчас просто приведу краткий список тех программ, что в разное время стояли на моём смартфоне и использовались для дел, связанных с системным администрированием.
✅Первый список того, что стоит прямо сейчас:
◽RD Client — RDP клиент от Microsoft. Пользуюсь регулярно для разных задач.
◽OpenVPN Connect — обычный ovpn клиент.
◽Total Commander — просто люблю этот файловый менеджер, использую постоянно, особенно lan плагин, чтобы копировать по smb с NAS.
◽Todoist — про этот сервис упоминал не раз, использую в качестве списка дел, пользуюсь постоянно, но на смартфоне на крайний случай стоит.
◽MikroTik — приложение для управления Микротиками.
◽KPass — стоит на всякий случай, если придётся глянуть пароли. Пользуюсь редко, постоянно файл с паролями на смартфоне не лежит, надо сначала скачать.
◽Joplin — клиент для просмотра заметок, пользуюсь на смартфоне редко, но иногда надо.
◽Planyway — приложение от одноименного сервиса, использую для календаря с планированием, рассказывал о нём отдельно.
◽ProxMon — ставил, когда писал заметку, на практике не возникла ни одно ситуации, что мне пришлось бы им воспользоваться.
◽UptimeRobot — приложение от одноимённого сервиса мониторинга, а котором рассказывал отдельно.
💡Теперь то, что было полезным и стояло в разное время:
◽Wifi manager — позволяет быстро и наглядно оценить загруженность частоты wifi по каналам.
◽Wifi Analyzer — с его помощью я проверял работу capsman от микротик. С помощью программы можно увидеть множество точек за одним SSID и подключаться к ним по MAC адресу. Это одна из возможностей, которая интересна лично мне. В программе много других полезных функций.
◽Zadarma — клиент sip телефонии. Использую, когда настраиваю asterisk. Сервис задарма удобен в качестве тестового транка на время настройки и тестирования.
◽Клавиатура для паролей — простое приложение, которое позволяет легко вводить пароли, которые придуманы в русской раскладке, но вводятся на английском языке. Сам я такие не люблю использовать, но приходится работать и с ними. Без русской клавиатуры их вводить очень неудобно.
◽JuiceSSH — ssh клиент. Пользовался редко, так как через смартфон работать по ssh очень неудобно, хоть какой клиент ни возьми.
◽PingTools — набор полезных сетевых утилит. Можно пингануть, трассерунть что-то прямо из смартфона.
🎓Отдельно расскажу про приложение Linux Command Library, которое можно поставить из Google Play. Это огромная база данных по командам, утилитам, однострочникам в Linux. Хоть и не часто, но иногда приходится что-то искать, смотреть в смартфоне, особенно когда в серверную за консоль приходишь. В ней удобно подсмотреть какие-то команды, вместо того, чтобы их гуглить. Там всё удобно разбито по темам. В общем, сами посмотрите, приложение популярное.
❗️А теперь хотел бы у вас спросить, что из нашей тематики у вас есть в смартфонах под Android? Если будет много полезных комментариев с программами, то сделаю ещё один общий список.
#смартфон #разное #android
{kind=link}
Старенький мемчик, но мне он очень нравится. Может потому, что тут собака. В интернете принято умиляться котиками, но я их не очень люблю. Другое дело собака, обожаю их.
Пока не было семьи, где-то год почти каждые выходные ездил в собачий приют и там проводил время с собаками. В квартире не завожу, считаю, что это неподходящее место для любых крупных домашних животных. Во дворах всё обоссано, обосрано собаками. Я такое не понимаю. Собака — животное для загородного дома. Нет дома, не надо собаку заводить.
#мем
Пока не было семьи, где-то год почти каждые выходные ездил в собачий приют и там проводил время с собаками. В квартире не завожу, считаю, что это неподходящее место для любых крупных домашних животных. Во дворах всё обоссано, обосрано собаками. Я такое не понимаю. Собака — животное для загородного дома. Нет дома, не надо собаку заводить.
#мем