
Жара продолжается. Кондер в одной из серверных на производстве не вытягивает нагрузку. Но в целом ничего страшного. Там триггеры на 50 и 55 градусов стоят. И такое каждое лето бывает.
Причём температура дисков сильно зависит от самого сервера и его внутреннего устройства. У каких-то харды греются меньше, у каких-то больше. И всё это в рамках одной стойки. Тут в стойке 7 серверов, но маячат в мониторинге только 2.
По моему опыту, всё, что ниже 60, можно игнорировать, если нет простых решений проблемы. Я раньше суетился по этому поводу, тикеты в ТП писал, если в арендуемых дедиках температура дисков поднималась, но меня всегда футболили, если она не выходила за параметры рабочей температуры, указанной в документации к диску. На hdd там потолок обычно 60 градусов.
А вы какие триггеры по температуре ставите? Для cpu я обычно 90 ставлю, для hdd 55-60. Всё, что ниже, игнорирую. Хотя могу поставить пороги и ниже, чтобы примерно понимать по оповещениям, что там за ситуация на условно проблемных серверах.
#железо
Причём температура дисков сильно зависит от самого сервера и его внутреннего устройства. У каких-то харды греются меньше, у каких-то больше. И всё это в рамках одной стойки. Тут в стойке 7 серверов, но маячат в мониторинге только 2.
По моему опыту, всё, что ниже 60, можно игнорировать, если нет простых решений проблемы. Я раньше суетился по этому поводу, тикеты в ТП писал, если в арендуемых дедиках температура дисков поднималась, но меня всегда футболили, если она не выходила за параметры рабочей температуры, указанной в документации к диску. На hdd там потолок обычно 60 градусов.
А вы какие триггеры по температуре ставите? Для cpu я обычно 90 ставлю, для hdd 55-60. Всё, что ниже, игнорирую. Хотя могу поставить пороги и ниже, чтобы примерно понимать по оповещениям, что там за ситуация на условно проблемных серверах.
#железо
Очередной пост на тему bash и работы в консоли. Думаю, это будет полезный для многих материал. Я собрал консольные утилиты и команды, которые использую для того, чтобы определить, кто и как нагружает CPU и Память в Linux. Традиционно напоминаю, что это не сборник лучших решений и инструментов. Это просто мой личный опыт. Не обязательно, что я всё делаю правильно и оптимально.
Сколько памяти занимает процесс. На примере mysqld.
ps -o vsz,rss,cmd --pid $(pgrep mysqld)
Список процессов с сортировкой по нагрузке на CPU.
ps aux --sort -pcpu
Этот список можно ограничить только десятью самыми прожорливыми процессами.
ps aux --sort=-pcpu,+pmem | head -n 11
Список процессов с сортировкой по занимаемой памяти.
ps aux --sort -rss
ps aux --sort -vsz
Наблюдаем через top за конкретным процессом.
top -c -p $(pgrep -d',' -f mysqld)
Информация о загрузке каждого ядра процессора. Утилита mpstat входит в состав пакета sysstat. Обычно в системных репах она есть.
mpstat -P ALL
Загрузка процессора в %. Этой простой метрики очень не хватает в Linux, особенно когда переходишь с Windows. Все колхозят на свой лад, чтобы получить эту метрику. Вот 2 варианта, которые есть у меня. При грубой прикидке, результат получается близкий к реальности.
top -bn1 | grep "Cpu(s)" | sed "s/.*, *\([0-9.]*\)%* id.*/\1/" | awk '{print 100 - $1"%"}'
awk '{u=$2+$4; t=$2+$4+$5; if (NR==1){u1=u; t1=t;} else print ($2+$4-u1) * 100 / (t-t1) "%"; }' <(grep 'cpu ' /proc/stat) <(sleep 1;grep 'cpu ' /proc/stat)
Текстовый вывод нагрузки на процессор в консоль. Ингода бывает удобно выводить с каким-то интервалом информацию о нагрузке в консоль. Например, делать это в течении 60 секунд с интервалом в секунду можно с помощью sar, которая тоже есть в sysstat
sar 1 60
Определить, кто родитель процесса. Например, если указать pid worker процесса nginx, команда ниже покажет pid процесса master. В случае с nginx это не имеет большого смысла, но иногда нужно.
ps -o ppid= -p 5606
Посмотреть информацию о процессоре.
lscpu
В завершении скажу про полезную репу, которую я регулярно использую при анализе загрузки систем - https://github.com/brendangregg/perf-tools Там много полезных утилит. В контексте данной заметки для анализа процессов я использовал утилиту execsnoop.
Следующая подборка будет на тему анализа нагрузки на дисковую подсистему. Думаю, это будет поинтереснее. Изначально хотел всё в одной сделать, но потом понял, что лучше разделить, чтобы в избранное можно было по тематике разнести.
#bash
Сколько памяти занимает процесс. На примере mysqld.
ps -o vsz,rss,cmd --pid $(pgrep mysqld)
Список процессов с сортировкой по нагрузке на CPU.
ps aux --sort -pcpu
Этот список можно ограничить только десятью самыми прожорливыми процессами.
ps aux --sort=-pcpu,+pmem | head -n 11
Список процессов с сортировкой по занимаемой памяти.
ps aux --sort -rss
ps aux --sort -vsz
Наблюдаем через top за конкретным процессом.
top -c -p $(pgrep -d',' -f mysqld)
Информация о загрузке каждого ядра процессора. Утилита mpstat входит в состав пакета sysstat. Обычно в системных репах она есть.
mpstat -P ALL
Загрузка процессора в %. Этой простой метрики очень не хватает в Linux, особенно когда переходишь с Windows. Все колхозят на свой лад, чтобы получить эту метрику. Вот 2 варианта, которые есть у меня. При грубой прикидке, результат получается близкий к реальности.
top -bn1 | grep "Cpu(s)" | sed "s/.*, *\([0-9.]*\)%* id.*/\1/" | awk '{print 100 - $1"%"}'
awk '{u=$2+$4; t=$2+$4+$5; if (NR==1){u1=u; t1=t;} else print ($2+$4-u1) * 100 / (t-t1) "%"; }' <(grep 'cpu ' /proc/stat) <(sleep 1;grep 'cpu ' /proc/stat)
Текстовый вывод нагрузки на процессор в консоль. Ингода бывает удобно выводить с каким-то интервалом информацию о нагрузке в консоль. Например, делать это в течении 60 секунд с интервалом в секунду можно с помощью sar, которая тоже есть в sysstat
sar 1 60
Определить, кто родитель процесса. Например, если указать pid worker процесса nginx, команда ниже покажет pid процесса master. В случае с nginx это не имеет большого смысла, но иногда нужно.
ps -o ppid= -p 5606
Посмотреть информацию о процессоре.
lscpu
В завершении скажу про полезную репу, которую я регулярно использую при анализе загрузки систем - https://github.com/brendangregg/perf-tools Там много полезных утилит. В контексте данной заметки для анализа процессов я использовал утилиту execsnoop.
Следующая подборка будет на тему анализа нагрузки на дисковую подсистему. Думаю, это будет поинтереснее. Изначально хотел всё в одной сделать, но потом понял, что лучше разделить, чтобы в избранное можно было по тематике разнести.
#bash
{kind=link}
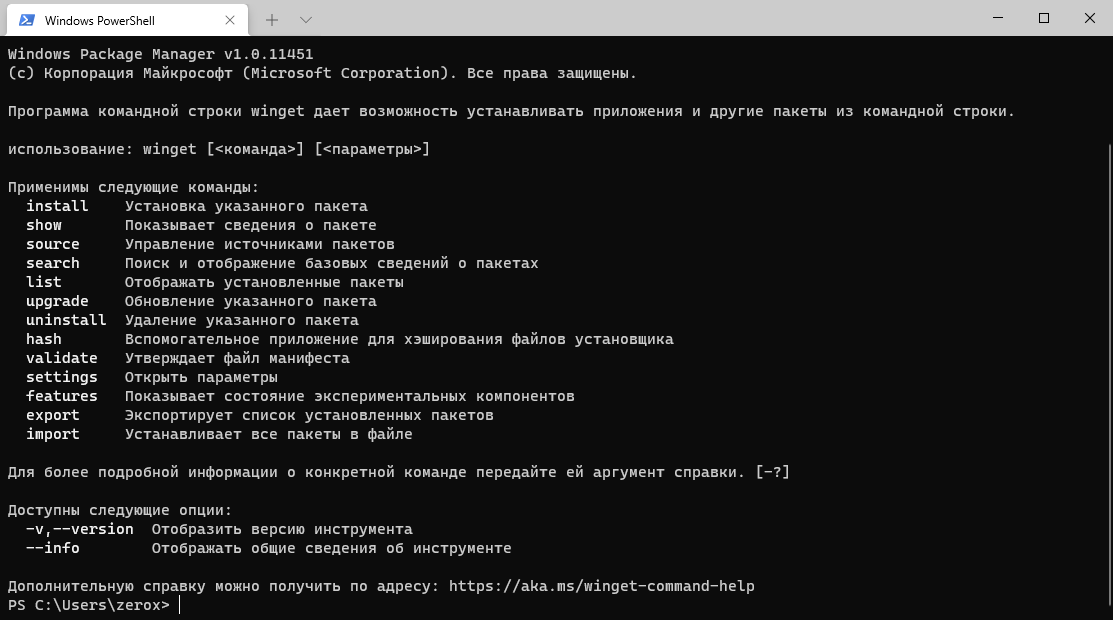
Я уже давно слышал, что Microsoft разрабатывал свой пакетный менеджер для Windows систем. Аналог apt, dnf и прочих пакетных менеджеров в Linux. Теперь дошли руки попробовать его. Называется winget. Скачать можно с github:
https://github.com/microsoft/winget-cli/releases
А дальше примерно всё как в Linux. Список пакетов, доступных для установки можно посмотреть так:
Дальше смотрите, что вам нужно установить и ставите (консоль запускаем от админа):
Установил себе текстовый редактор Sublime 4.
Идея очень крутая. Пока я так понял это всё еще тестируется и дорабатывается. Но если в скором времени весь софт можно будет ставить через этот пакетный менеджер, то будет очень удобно. После установки системы нужно будет сделать что-то примерное такое:
Попробовал поставить еще несколько программ. Все круто, поставилось. Мне очень понравилось.
#windows
https://github.com/microsoft/winget-cli/releases
А дальше примерно всё как в Linux. Список пакетов, доступных для установки можно посмотреть так:
winget installДальше смотрите, что вам нужно установить и ставите (консоль запускаем от админа):
winget install SublimeHQ.SublimeText.4Установил себе текстовый редактор Sublime 4.
Идея очень крутая. Пока я так понял это всё еще тестируется и дорабатывается. Но если в скором времени весь софт можно будет ставить через этот пакетный менеджер, то будет очень удобно. После установки системы нужно будет сделать что-то примерное такое:
winget install 7Zip KeePass Telegram Firefox Todoist WinboxПопробовал поставить еще несколько программ. Все круто, поставилось. Мне очень понравилось.
#windows
{kind=link}
Оказывается, для Clonezilla существует обычный GUI в виде Rescuezilla. Этот продукт делает полностью совместимый с Clonezilla формат образов, но работает на базе Ubuntu и LXDE.
https://github.com/rescuezilla/rescuezilla
https://rescuezilla.com/
Для тех кто не в курсе, Clonezilla это аналог коммерческих продуктов для снятия образов дисков и систем для бэкапа или переноса на другое железо, таких как Acronis True Image, Norton Ghost и т.д.
Clonezilla имеет консольный интерфейс для тру линуксоидов и любителей генту с арчем, а Rescuezilla более человеческий GUI для тех, кто привык тыкать мышкой.
Я сам неоднократно использовал Clonezilla для переноса системы с железа в виртуалку или между разными гипервизорами. Продукт хороший и известный, рекомендую, если еще не знакомы с ним.
Думаю, что в следующий раз, когда понадобится, предпочту GUI консоли. Так же одной из фишек Rescuezilla является то, что она может очень легко монтировать файлы резервных копий Clonezilla и получать к ним доступ.
#backup
https://github.com/rescuezilla/rescuezilla
https://rescuezilla.com/
Для тех кто не в курсе, Clonezilla это аналог коммерческих продуктов для снятия образов дисков и систем для бэкапа или переноса на другое железо, таких как Acronis True Image, Norton Ghost и т.д.
Clonezilla имеет консольный интерфейс для тру линуксоидов и любителей генту с арчем, а Rescuezilla более человеческий GUI для тех, кто привык тыкать мышкой.
Я сам неоднократно использовал Clonezilla для переноса системы с железа в виртуалку или между разными гипервизорами. Продукт хороший и известный, рекомендую, если еще не знакомы с ним.
Думаю, что в следующий раз, когда понадобится, предпочту GUI консоли. Так же одной из фишек Rescuezilla является то, что она может очень легко монтировать файлы резервных копий Clonezilla и получать к ним доступ.
#backup
{kind=link}
Успех в делах обычно состоит из мелочей, но если на них обращать внимание и не пускать на самотёк, то результат придёт быстрее. Покажу на нескольких примерах, хотя в том или ином виде я их уже упоминал в других заметках.
Я почти всегда пишу документацию, объединяю её со списком выполненных задач, прикладываю все учётные записи, которые использовал в работе и отправляю заказчику, даже если он сам этого не просит. Большинство не просят всё это вместе, так как им зачастую не интересно с этим разбираться. Даже учётки не всегда спрашивают, особенно от сервисов, с которыми напрямую не взаимодействуешь. Например, пароли mysql.
Так же всегда отвечаю на письма, когда их получил. Таким образом подтверждаю, что информация прочитана. Когда что-то делаю, не ленюсь уведомлять о ходе процесса и само собой, всегда сразу говорю, если сроки затягиваются. То есть банально не пропадаю и информирую людей.
Еще простой пример не совсем из IT. Мне постоянно рекламодатели присылают тексты для публикаций. Я всегда их вычитываю, исправляю все огрехи в форматировании, добавляю абзацы, иногда немного emoji и т.д. Обязательно проверяю все ссылки и метки. Были случаи, когда ссылки не работали. Для платной рекламы это полный провал. При этом вижу эти же тексты в других каналах в том виде, как они были получены, со всеми опечатками и сломанным форматированием. Так же не раз видел мои доработанные посты на других каналах. Рекламодатель брал мои правки и дальше уже распространял свой текст с ними.
У меня уходит не так много времени всё это делать, но такой подход располагает, запоминается и к тебе с большей вероятностью придут снова.
Подобное отношение стараюсь распространять на все дела. Чуть-чуть личного внимания уделить не так трудно, даже если от тебя этого не требуется. Но в конечном итоге это выливается в гораздо большие приобретения, по сравнению с затраченным временем.
#мысли
Я почти всегда пишу документацию, объединяю её со списком выполненных задач, прикладываю все учётные записи, которые использовал в работе и отправляю заказчику, даже если он сам этого не просит. Большинство не просят всё это вместе, так как им зачастую не интересно с этим разбираться. Даже учётки не всегда спрашивают, особенно от сервисов, с которыми напрямую не взаимодействуешь. Например, пароли mysql.
Так же всегда отвечаю на письма, когда их получил. Таким образом подтверждаю, что информация прочитана. Когда что-то делаю, не ленюсь уведомлять о ходе процесса и само собой, всегда сразу говорю, если сроки затягиваются. То есть банально не пропадаю и информирую людей.
Еще простой пример не совсем из IT. Мне постоянно рекламодатели присылают тексты для публикаций. Я всегда их вычитываю, исправляю все огрехи в форматировании, добавляю абзацы, иногда немного emoji и т.д. Обязательно проверяю все ссылки и метки. Были случаи, когда ссылки не работали. Для платной рекламы это полный провал. При этом вижу эти же тексты в других каналах в том виде, как они были получены, со всеми опечатками и сломанным форматированием. Так же не раз видел мои доработанные посты на других каналах. Рекламодатель брал мои правки и дальше уже распространял свой текст с ними.
У меня уходит не так много времени всё это делать, но такой подход располагает, запоминается и к тебе с большей вероятностью придут снова.
Подобное отношение стараюсь распространять на все дела. Чуть-чуть личного внимания уделить не так трудно, даже если от тебя этого не требуется. Но в конечном итоге это выливается в гораздо большие приобретения, по сравнению с затраченным временем.
#мысли
{kind=link}
Один из читателей сайта к статье о настройке proxmox написал комментарий по переносу виндовых виртуалок с hyperv на proxmox. Мне показалась информация полезной, поэтому оформляю в заметку и делюсь с вами. Самому тоже приходилось делать такие переносы, но инструкцию не составлял.
Для начала надо перенести vhdx образы на proxmox и сконвертировать в нужный вам формат. Например в qcow2:
qemu-img convert -O qcow2 /path/to/vhdx/VM.vhdx /path/to/qcow2/vm.qcow2
Далее создаём новую виртуалку, добавляем ей диск минимального размера (VirtIO SCSI). Он нужен будет позже, чтобы установить virtio драйвера на диск в систему. Добавляем к этой виртуалке сконвертированный диск как ide и делаем его загрузочным. Так же добавляем cd-rom и подключаем к нему virtio-win.iso последней версии. В настройках Hardware -> Bios меняем с дефолтного SeaBios на OVMF (UEFI).
Запускаем виртуалку. Должна загрузиться. Ставим все драйвера, в том числе на диск, а так же qemu-guest-agent. Выключаем.
Далее либо через правку конфига vm в консоли меняете путь от virtio диска минимального размера на рабочий, либо через веб интерфейс отцепляете оба диска и обратно подключаете системный диск как VirtIO SCSI. На этом всё.
Скорее всего прямо сейчас вам эта инструкция нее нужна, но если в будущем может пригодиться, не забудьте сохранить.
#hyperv #proxmox
Для начала надо перенести vhdx образы на proxmox и сконвертировать в нужный вам формат. Например в qcow2:
qemu-img convert -O qcow2 /path/to/vhdx/VM.vhdx /path/to/qcow2/vm.qcow2
Далее создаём новую виртуалку, добавляем ей диск минимального размера (VirtIO SCSI). Он нужен будет позже, чтобы установить virtio драйвера на диск в систему. Добавляем к этой виртуалке сконвертированный диск как ide и делаем его загрузочным. Так же добавляем cd-rom и подключаем к нему virtio-win.iso последней версии. В настройках Hardware -> Bios меняем с дефолтного SeaBios на OVMF (UEFI).
Запускаем виртуалку. Должна загрузиться. Ставим все драйвера, в том числе на диск, а так же qemu-guest-agent. Выключаем.
Далее либо через правку конфига vm в консоли меняете путь от virtio диска минимального размера на рабочий, либо через веб интерфейс отцепляете оба диска и обратно подключаете системный диск как VirtIO SCSI. На этом всё.
Скорее всего прямо сейчас вам эта инструкция нее нужна, но если в будущем может пригодиться, не забудьте сохранить.
#hyperv #proxmox
{kind=link}
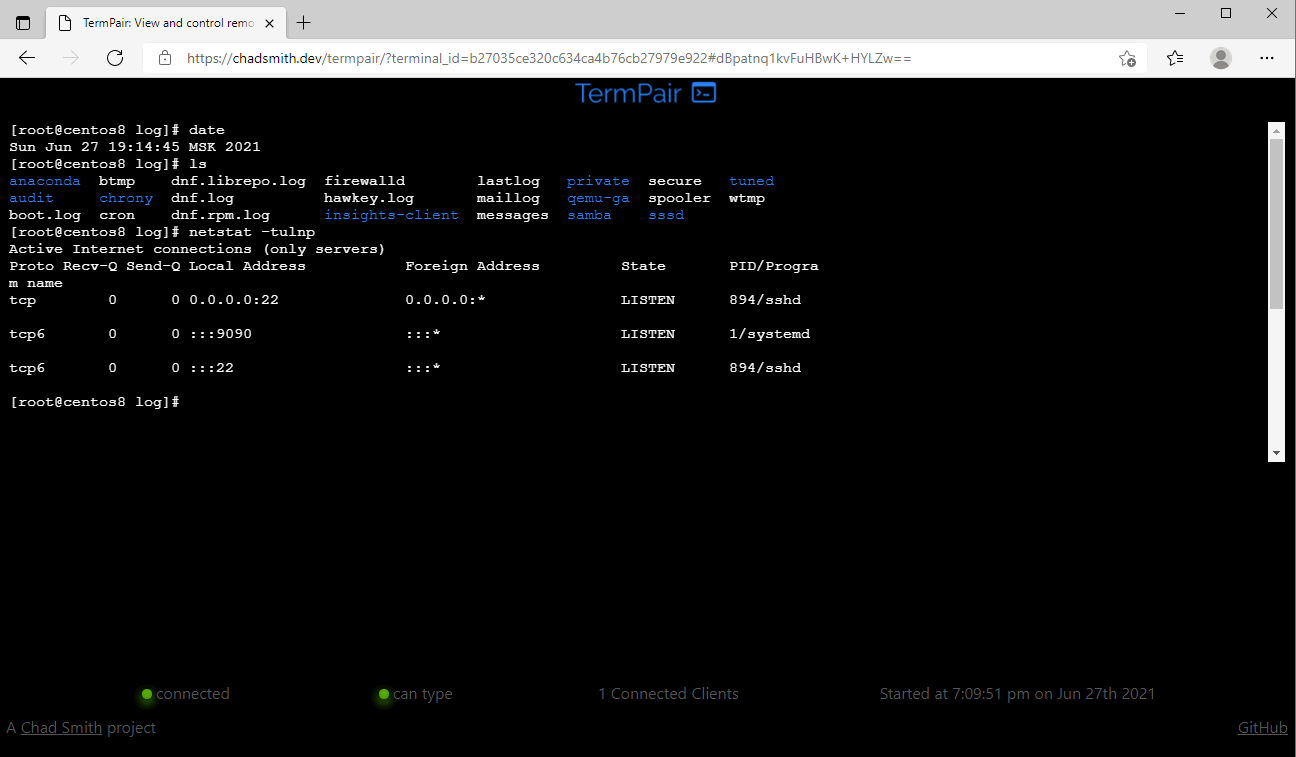
Любопытный проект на github для совместной работы в консоли - TermPair.
https://github.com/cs01/termpair
Идея такая. Ты запускаешь у себя в консоли сервер:
Дальше можно расшарить консоль:
Вы получите ссылку вида:
Можно подключаться через браузер и смотреть, что происходит в консоли, либо управлять ей. Очевидно, что для доступа через интернет нужен либо белый ip, либо придётся пробрасывать порт через nat. Клиентов может подключиться сколько угодно.
Можно расшарить консоль и через внешний хост. Для этого надо будет воспользоваться каким-то внешним сервером. Например, вот так:
Сразу получите внешнюю ссылку и через браузер окажетесь в консоли.
Программа написана на python, так что поставить можно через pip:
Перед установкой обновите pip до последней версии. У меня сначала не прошла установка из-за каких-то проблем с криптографией. Когда обновил pip, все прошло успешно.
Гифка с демонстрацией работы - https://raw.githubusercontent.com/cs01/termpair/master/termpair_browser.gif
#утилита
https://github.com/cs01/termpair
Идея такая. Ты запускаешь у себя в консоли сервер:
termpair serve --port 8000Дальше можно расшарить консоль:
termpair share --port 8000Вы получите ссылку вида:
http://ip-server:8000/?terminal_id=fd96c0f8476872950e19cМожно подключаться через браузер и смотреть, что происходит в консоли, либо управлять ей. Очевидно, что для доступа через интернет нужен либо белый ip, либо придётся пробрасывать порт через nat. Клиентов может подключиться сколько угодно.
Можно расшарить консоль и через внешний хост. Для этого надо будет воспользоваться каким-то внешним сервером. Например, вот так:
termpair share --host "https://chadsmith.dev/termpair/" --port 443Сразу получите внешнюю ссылку и через браузер окажетесь в консоли.
Программа написана на python, так что поставить можно через pip:
pip install termpairПеред установкой обновите pip до последней версии. У меня сначала не прошла установка из-за каких-то проблем с криптографией. Когда обновил pip, все прошло успешно.
Гифка с демонстрацией работы - https://raw.githubusercontent.com/cs01/termpair/master/termpair_browser.gif
#утилита
{kind=link}
Расскажу своими словами про типы дисков в Proxmox, доступные по дефолту после установки для использования в виртуальных машинах.
Этот вопрос очень часто задают. Я не могу сказать, что обладаю экспертными знаниями по этой теме, но в своё время специально интересовался и составил для себя представления в каком случае какой из типов дисков выбирать.
RAW. Самый простой формат. Данные хранятся как есть, без дополнительной обработки и добавления служебной информации. Информацию в таком формате могут называть сырыми данными. По идее, это формат с максимальным быстродействием. При создании диска выделяется сразу же весь объем. Формат является универсальным для большинства популярных гипервизоров.
➕ Максимальная простота и производительность среди образов в виде файла.
➕ Универсальный формат с поддержкой в большинстве гипервизоров.
➕ Легкость переноса виртуальной машины на другой сервер. Достаточно просто скопировать файл.
➖ Не поддерживает снепшоты ни в каком виде.
➖ Занимает сразу все выделенное пространство на диске, даже если внутри виртуальной машины место будет свободно. Из-за отсутствия фрагментации в некоторых случаях это может оказаться плюсом.
QCOW2. Родной формат для гипервизора QEMU. Расшифровывается как Copy-on-write. Этот формат позволяет создавать динамические диски для виртуальных машин, а так же поддерживает снепшоты. Теоретически, скорость работы будет хоть и не сильно, но уступать RAW (на ~10%), так как появляются накладные расходы формата.
➕ Поддержка снепшотов и динамических дисков. Как следствие - более удобное управление дисковым пространством.
➕ Легкость переноса виртуальной машины на другой сервер. Достаточно просто скопировать файл.
➖ Более низкая производительность, по сравнению с другими типами образов.
LVM. Использование lvm томов в виде дисков виртуальных машин. Такой диск будет блочным устройством и теоретически должен работать быстрее всех остальных типов, так как нет лишней прослойки в виде файловой системы. На практике эту разницу с raw не разглядеть и не замерить. Я на тестах не замечал.
➕ Снэпшоты средствами самого lvm, с них легко снять бэкап без остановки виртуальной машины.
➕ Максимальное быстродействие.
➖ Более сложное управление по сравнению с дисками в виде отдельных файлов.
➖ Более сложный перенос на другой сервер.
У каждого типа есть свои преимущества и недостатки. Lvm проще всего бэкапить, так как есть снепшоты из коробки, но им сложнее всего управлять. Для того, кто хорошо знаком с lvm, это не проблема, если сталкиваешься первый раз, то возникает много вопросов. У raw нет снепшотов, лично для меня это большой минус, я этот формат редко использую. Если нет максимальной нагрузки на дисковую подсистему, то QCOW2 мне кажется наиболее удобным вариантом.
#proxmox #kvm
Этот вопрос очень часто задают. Я не могу сказать, что обладаю экспертными знаниями по этой теме, но в своё время специально интересовался и составил для себя представления в каком случае какой из типов дисков выбирать.
RAW. Самый простой формат. Данные хранятся как есть, без дополнительной обработки и добавления служебной информации. Информацию в таком формате могут называть сырыми данными. По идее, это формат с максимальным быстродействием. При создании диска выделяется сразу же весь объем. Формат является универсальным для большинства популярных гипервизоров.
➕ Максимальная простота и производительность среди образов в виде файла.
➕ Универсальный формат с поддержкой в большинстве гипервизоров.
➕ Легкость переноса виртуальной машины на другой сервер. Достаточно просто скопировать файл.
➖ Не поддерживает снепшоты ни в каком виде.
➖ Занимает сразу все выделенное пространство на диске, даже если внутри виртуальной машины место будет свободно. Из-за отсутствия фрагментации в некоторых случаях это может оказаться плюсом.
QCOW2. Родной формат для гипервизора QEMU. Расшифровывается как Copy-on-write. Этот формат позволяет создавать динамические диски для виртуальных машин, а так же поддерживает снепшоты. Теоретически, скорость работы будет хоть и не сильно, но уступать RAW (на ~10%), так как появляются накладные расходы формата.
➕ Поддержка снепшотов и динамических дисков. Как следствие - более удобное управление дисковым пространством.
➕ Легкость переноса виртуальной машины на другой сервер. Достаточно просто скопировать файл.
➖ Более низкая производительность, по сравнению с другими типами образов.
LVM. Использование lvm томов в виде дисков виртуальных машин. Такой диск будет блочным устройством и теоретически должен работать быстрее всех остальных типов, так как нет лишней прослойки в виде файловой системы. На практике эту разницу с raw не разглядеть и не замерить. Я на тестах не замечал.
➕ Снэпшоты средствами самого lvm, с них легко снять бэкап без остановки виртуальной машины.
➕ Максимальное быстродействие.
➖ Более сложное управление по сравнению с дисками в виде отдельных файлов.
➖ Более сложный перенос на другой сервер.
У каждого типа есть свои преимущества и недостатки. Lvm проще всего бэкапить, так как есть снепшоты из коробки, но им сложнее всего управлять. Для того, кто хорошо знаком с lvm, это не проблема, если сталкиваешься первый раз, то возникает много вопросов. У raw нет снепшотов, лично для меня это большой минус, я этот формат редко использую. Если нет максимальной нагрузки на дисковую подсистему, то QCOW2 мне кажется наиболее удобным вариантом.
#proxmox #kvm
{kind=link}
Я наконец-то нашел нормальную и удобную замену Evernote - сервису для хранения заметок. Использовал его очень долго, последние лет 6-7 точно, а скорее всего дольше. Принял решение его заменить после того, как где-то пол года назад они выкатили новое приложение, которое просто жутко тормозит. Пользоваться стало некомфортно. Запускается долго, интерфейс неотзывчивый, повисает.
Я долго терпел, так как заметок много, переносить лень. Пробовал несколько других приложений подобного рода, но не очень нравились. Их тестирование отнимает время. Больше всего понравился микрсофтовский OneNote. Некоторое время им пользовался, но в итоге отказался. Интерфейс и возможности слишком простые, плюс, не хотелось привязываться к Microsoft.
В итоге остановился на бесплатном приложении Joplin - https://joplinapp.org. Привлекло меня там вот что:
1️⃣ Внешний вид очень похож на Evernote, так что не придётся привыкать.
2️⃣ Полностью бесплатный и кроссплатформенный.
3️⃣ Возможность использовать в качестве хранилища заметок локальную директорию. Я её расположил на яндекс диске и получил свои заметки на разных устройствах.
4️⃣ Есть возможность зашифровать все заметки. Я это сделал.
5️⃣ Поддерживается импорт блокнотов из Evernote. Я собрался с духом, привёл там всё в порядок и перенёс в Joplin.
Приложение, увы и ах, написано на богомерзком Electron, жрёт кучу памяти и весит 150 мегабайт. К сожалению, нативных приложений в этой сфере я вообще не видел, кроме OneNote. Он меня этим и привлек - шустрый и легковесный. Тем не менее Joplin работает значительно быстрее Evernote и негативных эмоций в работе не вызывает.
Помимо указанных ранее программ пробовал Notion, Trello (хотя он не совсем для заметок). Мне не понравились, так как показались перегруженными функционалом. Мне достаточно обычного текстового формата с минимальным форматированием. Markdown полностью устраивает, который реализован в Joplin.
Одной из фишек Joplin является то, что он все заметки хранит в текстовых файлах в формате markdown. Их прямо из программы можно открывать внешним текстовым редактором. Это удобно. Плюс, есть консольная версия для linux. С заметками можно работать через консоль. Вряд ли мне это понадобится, но тем не менее, интересно.
#программа #полезное
Я долго терпел, так как заметок много, переносить лень. Пробовал несколько других приложений подобного рода, но не очень нравились. Их тестирование отнимает время. Больше всего понравился микрсофтовский OneNote. Некоторое время им пользовался, но в итоге отказался. Интерфейс и возможности слишком простые, плюс, не хотелось привязываться к Microsoft.
В итоге остановился на бесплатном приложении Joplin - https://joplinapp.org. Привлекло меня там вот что:
1️⃣ Внешний вид очень похож на Evernote, так что не придётся привыкать.
2️⃣ Полностью бесплатный и кроссплатформенный.
3️⃣ Возможность использовать в качестве хранилища заметок локальную директорию. Я её расположил на яндекс диске и получил свои заметки на разных устройствах.
4️⃣ Есть возможность зашифровать все заметки. Я это сделал.
5️⃣ Поддерживается импорт блокнотов из Evernote. Я собрался с духом, привёл там всё в порядок и перенёс в Joplin.
Приложение, увы и ах, написано на богомерзком Electron, жрёт кучу памяти и весит 150 мегабайт. К сожалению, нативных приложений в этой сфере я вообще не видел, кроме OneNote. Он меня этим и привлек - шустрый и легковесный. Тем не менее Joplin работает значительно быстрее Evernote и негативных эмоций в работе не вызывает.
Помимо указанных ранее программ пробовал Notion, Trello (хотя он не совсем для заметок). Мне не понравились, так как показались перегруженными функционалом. Мне достаточно обычного текстового формата с минимальным форматированием. Markdown полностью устраивает, который реализован в Joplin.
Одной из фишек Joplin является то, что он все заметки хранит в текстовых файлах в формате markdown. Их прямо из программы можно открывать внешним текстовым редактором. Это удобно. Плюс, есть консольная версия для linux. С заметками можно работать через консоль. Вряд ли мне это понадобится, но тем не менее, интересно.
#программа #полезное
{kind=link}
Продолжаю рубрику костылей и велосипедов на bash. Сегодня расскажу, как я анализирую нагрузку на дисковую подсистему через консоль. Как обычно напоминаю, что это не набор лучших практик. Это мой субъективный опыт.
Сводная информация по нагрузке на диск. Использую iostat из пакета sysstat. Каждые 2 секунды вывожу информацию в консоль:
С помощью этого вывода можно бегло оценить, что в целом происходит с каждым конкретным диском.
Дисковая активность всех процессов. Использую pidstat. Каждую секунду вывожу в консоль информацию о дисковой активности всех процессов.
Дисковая активность конкретного процесса.
Напоминаю, что PID процесса можно посмотреть командой pgrep:
Что пишет процесс.
Анализ I/O дисков, в том числе latency. Я уже упоминал в прошлой заметке репозиторий https://github.com/brendangregg/perf-tools. Утилита iosnoop показывает нагрузку на диск, в том числе latency. Больше примеров тут.
Список удаленных открытых файлов. Еще одна полезная команда, которая позволяет решить популярную проблему, когда казалось бы места свободного должно быть много, но его реально нет. Принудительно удален какой-то открытый файл, поэтому место не освободилось.
Список открытых файлов в конкретной директории.
Так же есть аналог топа - iotop. С его помощью можно в реальном времени посмотреть дисковую активность.
И еще отдельно упомяну утилиту dstat (dnf install dstat). Мне нравится её вывод (см. скриншот) по общей загрузке системы, в том числе и дисков. Все популярные метрики:
Только диски по read_bytes / write_bytes (нагрузка на "железо")
Диски по rchar/wchar (нагрузка на "по", т.е. включая обращения ко всяким виртуальным ФС):
#bash
Сводная информация по нагрузке на диск. Использую iostat из пакета sysstat. Каждые 2 секунды вывожу информацию в консоль:
iostat -xk -t 2С помощью этого вывода можно бегло оценить, что в целом происходит с каждым конкретным диском.
Дисковая активность всех процессов. Использую pidstat. Каждую секунду вывожу в консоль информацию о дисковой активности всех процессов.
pidstat -d 1Дисковая активность конкретного процесса.
pidstat -p PID -d 1Напоминаю, что PID процесса можно посмотреть командой pgrep:
pgrep php-fpmЧто пишет процесс.
strace -e trace=write -p PIDАнализ I/O дисков, в том числе latency. Я уже упоминал в прошлой заметке репозиторий https://github.com/brendangregg/perf-tools. Утилита iosnoop показывает нагрузку на диск, в том числе latency. Больше примеров тут.
./iosnoop./iosnoop -p PIDСписок удаленных открытых файлов. Еще одна полезная команда, которая позволяет решить популярную проблему, когда казалось бы места свободного должно быть много, но его реально нет. Принудительно удален какой-то открытый файл, поэтому место не освободилось.
lsof +L1lsof | grep '(deleted)'Список открытых файлов в конкретной директории.
lsof +D /var/logТак же есть аналог топа - iotop. С его помощью можно в реальном времени посмотреть дисковую активность.
И еще отдельно упомяну утилиту dstat (dnf install dstat). Мне нравится её вывод (см. скриншот) по общей загрузке системы, в том числе и дисков. Все популярные метрики:
dstat -tldnpms 10Только диски по read_bytes / write_bytes (нагрузка на "железо")
dstat --top-bioДиски по rchar/wchar (нагрузка на "по", т.е. включая обращения ко всяким виртуальным ФС):
dstat --top-io#bash
{kind=link}
Есть в линуксе полезный архиватор - pigz (Parallel Implementation of GZip). На мой взгляд, он не очень известный. Редко его вижу где-то в статьях или чьих то скриптах. Сам я его использую постоянно. Главная его особенность - он жмёт всеми ядрами. Большинство привычных консольных архиваторов жмут только одним ядром. Когда архивируете большие объемы, разница в скорости огромная.
С установкой pigz проблем нет, живёт в стандартных репах популярных дистрибутивов. Использовать, как это обычно бывает в линукс, можно разными способами.
Одиночный файл:
Распаковываем:
Либо сразу дамп базы:
Жмём директорию:
Распаковываем:
Жмём несколько файлов по маске:
Распаковываем:
Для архивации больших дампов баз данных очень актуально. На серваках с БД обычно много ядер. Если жать только одним, это может длиться слишком долго. Pigz жмёт огромные дампы на максимальной скорости, которую могут обеспечить все ядра процессора.
#утилита
С установкой pigz проблем нет, живёт в стандартных репах популярных дистрибутивов. Использовать, как это обычно бывает в линукс, можно разными способами.
Одиночный файл:
pigz -c filename > /tmp/filename.gzРаспаковываем:
unpigz filename.gzЛибо сразу дамп базы:
pg_dump -U postgres base | pigz > /tmp/base.sql.gzЖмём директорию:
tar cf - directory | pigz - > directory.tar.gzРаспаковываем:
cat directory.tar.gz | unpigz - | tar xf -Жмём несколько файлов по маске:
find /data -type f -name *filemask* -exec pigz -c '{}' \;Распаковываем:
find /data -type f -name *filemask.gz -exec unpigz '{}' \;Для архивации больших дампов баз данных очень актуально. На серваках с БД обычно много ядер. Если жать только одним, это может длиться слишком долго. Pigz жмёт огромные дампы на максимальной скорости, которую могут обеспечить все ядра процессора.
#утилита
{kind=link}
Приветствую, дорогие читатели. Хочу с вами обсудить любопытную тему, которая однажды меня удивила и заинтересовала. Звучит она так: "Как точно узнать дату установки системы Linux". Когда передо мной впервые встал этот вопрос, я был удивлен, что невозможно получить однозначный ответ. По крайней мере я не понял, как это сделать.
В Windows с этим нет проблем. Система хранит дату своей установки. А вот в Linux я такого не увидел. Пришлось использовать косвенные признаки, чтобы определить дату установки. Вот способы, что используя я. Они связаны с созданием файловой системы.
Дата и время установки ОС Linux из свойств файловой системы:
tune2fs -l $(df / | tail -1 | cut -f1 -d' ') | grep created
Способ не сработает, если корень / стоит на lvm. Можно взять раздел /boot, если он не на lvm. Либо использовать следующий способ.
Узнаем дату установки ОС Linux из даты создания самого старого каталога в файловой системе:
ls --time-style=long-iso -clt / | tail -n 1 | awk '{ print $7, $6}'
Способ тоже не 100%, так как не факт, что эту дату создания не поменяли каким-то образом. Хотя на практике, если специально этого никто не делал, то даты на основе создания файловой системы актуальны.
Можно еще посмотреть на дату создания директории /lost+found.
ls -ld /lost+found/
Для rpm дистрибутивов есть более простой способ:
rpm -qi basesystem | grep Install
Но данный пакет может быть удален или переустановлен. Хотя кто подобным занимается?
А как вы определяете дату установки системы?
#полезное #bash
В Windows с этим нет проблем. Система хранит дату своей установки. А вот в Linux я такого не увидел. Пришлось использовать косвенные признаки, чтобы определить дату установки. Вот способы, что используя я. Они связаны с созданием файловой системы.
Дата и время установки ОС Linux из свойств файловой системы:
tune2fs -l $(df / | tail -1 | cut -f1 -d' ') | grep created
Способ не сработает, если корень / стоит на lvm. Можно взять раздел /boot, если он не на lvm. Либо использовать следующий способ.
Узнаем дату установки ОС Linux из даты создания самого старого каталога в файловой системе:
ls --time-style=long-iso -clt / | tail -n 1 | awk '{ print $7, $6}'
Способ тоже не 100%, так как не факт, что эту дату создания не поменяли каким-то образом. Хотя на практике, если специально этого никто не делал, то даты на основе создания файловой системы актуальны.
Можно еще посмотреть на дату создания директории /lost+found.
ls -ld /lost+found/
Для rpm дистрибутивов есть более простой способ:
rpm -qi basesystem | grep Install
Но данный пакет может быть удален или переустановлен. Хотя кто подобным занимается?
А как вы определяете дату установки системы?
#полезное #bash
{kind=link}
Вчера прилетела новость об обновлении десктопных приложений от Onlyoffice. Решил рассказать про эти редакторы документов в формате Microsoft Office и не только. Думаю, найдётся немало людей, которые про них не слышали. Речь вот о чём - https://www.onlyoffice.com/ru/desktop.aspx
Это опенсорсные редакторы документов для работы офлайн. Я их иногда сам использую, когда надо быстренько куда-то поставить софт для просмотра офисных документов. Приложения немного тормозные, но на вопрос отвечают. Регулярно в них работать я бы наверное не стал, а для редкого использования в самый раз.
У меня была подробная статья по разворачиванию сервера документов для работы online от этой же команды - https://serveradmin.ru/ustanovka-i-nastrojka-onlyoffice/ Продукт неплохой, присмотритесь, если вам нужен подобный функционал.
#программа
Это опенсорсные редакторы документов для работы офлайн. Я их иногда сам использую, когда надо быстренько куда-то поставить софт для просмотра офисных документов. Приложения немного тормозные, но на вопрос отвечают. Регулярно в них работать я бы наверное не стал, а для редкого использования в самый раз.
У меня была подробная статья по разворачиванию сервера документов для работы online от этой же команды - https://serveradmin.ru/ustanovka-i-nastrojka-onlyoffice/ Продукт неплохой, присмотритесь, если вам нужен подобный функционал.
#программа
Onlyoffice
Бесплатный офисный пакет для Windows, Linux и macOS
Работайте с сохраненными на вашем ПК документами офлайн с ONLYOFFICE Desktop Editors
Вчера несколько часов разбирался с необычным поисковиком - SearX.
https://github.com/searx/searx
К сожалению, результаты всех тестов меня не удовлетворили, тем не менее, всё равно поделюсь ими с вами. SearX изначально задумывался как средство для повышение приватности. С его помощью нейтрализуется слежка поисковиков за вами. SearX собирает информацию с различных поисковых систем и показывает её вам, смешивая результаты. При этом имеет массу полезных настроек, которых нет в обычных поисковиках.
Лично меня вопросы приватности не сильно беспокоят. Я заинтересовался этим метапоиском, чтобы в одном месте смешивать результаты поисковых систем Yandex и Google, так как пользуюсь ими обоими примерно в равной степени. Мне бы хотелось более удобное управление поиском из одного места, а не так как сейчас, вручную прыгаю между поисковыми системами.
По своей сути SearX отлично решает поставленную задачу. Но есть одно важное НО. С недавних пор Yandex стал блокировать SearX и показывать ему каптчу. В итоге поддержку Яндекса убрали в последнем релизе. Без Яндекса я не видел особо смысла им пользоваться, поэтому поставил более старые версии, где Яндекс еще был. Попробовал, вроде всё работает. Но после нескольких запросов, Яндекс таки начал мне показывать каптчу. В итоге пришлось бросить эту затею.
С другими поддерживаемыми поисковиками проблем не было. Так что если вам не нужен Яндекс, можете попробовать SearX. Мне очень понравились его настройки и возможность разделения поиска по типам запросов. То есть можно собрать пул сайтов с поиском на IT тематику и выполнять поиск только по этим сайтам. Я давно думал об этой теме, нигде не видел реализации и даже сам подумывал как-то это реализовать. А тут всё это в готовом виде. Попробуйте! То же самое с отдельным поиском по торрентам, музыке, видео и т.д.
Поставить и попробовать можно в одну команду через docker:
docker run -d -v ~/searx:/etc/searx -p 80:8080 -e BASE_URL=http://10.20.1.16:80/ searx/searx
Если захотите потестить с Яндексом, то он еще есть в версии searx/searx:0.18.0-176-74c8b560.
На сайте https://searx.space/ есть список уже поднятых публичных копий этой поисковой панели. Можно попробовать где-то там. Я так думаю, что для себя в итоге оставлю и поднастрою этот поиск даже без Яндекса. Сама идея понравилась.
Обзор SearX можно посмотреть в видео - https://www.youtube.com/watch?v=TOyvrMyGtAs Наглядно всё показано и рассказано. Смотреть можно на скорости 1.5.
#полезное
https://github.com/searx/searx
К сожалению, результаты всех тестов меня не удовлетворили, тем не менее, всё равно поделюсь ими с вами. SearX изначально задумывался как средство для повышение приватности. С его помощью нейтрализуется слежка поисковиков за вами. SearX собирает информацию с различных поисковых систем и показывает её вам, смешивая результаты. При этом имеет массу полезных настроек, которых нет в обычных поисковиках.
Лично меня вопросы приватности не сильно беспокоят. Я заинтересовался этим метапоиском, чтобы в одном месте смешивать результаты поисковых систем Yandex и Google, так как пользуюсь ими обоими примерно в равной степени. Мне бы хотелось более удобное управление поиском из одного места, а не так как сейчас, вручную прыгаю между поисковыми системами.
По своей сути SearX отлично решает поставленную задачу. Но есть одно важное НО. С недавних пор Yandex стал блокировать SearX и показывать ему каптчу. В итоге поддержку Яндекса убрали в последнем релизе. Без Яндекса я не видел особо смысла им пользоваться, поэтому поставил более старые версии, где Яндекс еще был. Попробовал, вроде всё работает. Но после нескольких запросов, Яндекс таки начал мне показывать каптчу. В итоге пришлось бросить эту затею.
С другими поддерживаемыми поисковиками проблем не было. Так что если вам не нужен Яндекс, можете попробовать SearX. Мне очень понравились его настройки и возможность разделения поиска по типам запросов. То есть можно собрать пул сайтов с поиском на IT тематику и выполнять поиск только по этим сайтам. Я давно думал об этой теме, нигде не видел реализации и даже сам подумывал как-то это реализовать. А тут всё это в готовом виде. Попробуйте! То же самое с отдельным поиском по торрентам, музыке, видео и т.д.
Поставить и попробовать можно в одну команду через docker:
docker run -d -v ~/searx:/etc/searx -p 80:8080 -e BASE_URL=http://10.20.1.16:80/ searx/searx
Если захотите потестить с Яндексом, то он еще есть в версии searx/searx:0.18.0-176-74c8b560.
На сайте https://searx.space/ есть список уже поднятых публичных копий этой поисковой панели. Можно попробовать где-то там. Я так думаю, что для себя в итоге оставлю и поднастрою этот поиск даже без Яндекса. Сама идея понравилась.
Обзор SearX можно посмотреть в видео - https://www.youtube.com/watch?v=TOyvrMyGtAs Наглядно всё показано и рассказано. Смотреть можно на скорости 1.5.
#полезное
{kind=link}
Мои мысли на тему аутсорса IT в малой или средней компании. Информация может пригодиться тем, кому приходится конкурировать с аутсорсом и убеждать руководство в том, что работа с аутсорс компаниями это не то, что обычно ожидаешь получить (экономия средств, повышение качества обслуживания). А так же тем руководителям, которые задумываются о том, чтобы передать поддержку своей инфраструктуры на сторону.
Мне приходилось часто сталкиваться с поддержкой инфраструктур или разработкой со стороны аутсорсинговых компаний. И всегда это был печальный опыт, иначе я бы о нём не узнал. Это не значит, что весь аутсорс плохой. Это то, с чем сталкивался лично я. Опишу наиболее ощутимые минусы этого процесса.
1️⃣ Даже если вам и будут обещать непрерывную поддержку 24/7, по факту напрямую работать с вами будет скорее всего один и тот же специалист. Он будет более ли менее погружён в вашу инфраструктуру. Все остальные будут только затягивать время, изображать активность в тикетах и решать что-то совсем простое и некритичное.
2️⃣ Все ваши пароли и другая коммерческая информация будет доступна кругу лиц, который вы не сможете контролировать. Вы даже не будете реально знать, у кого есть ваши доступы. Причём люди, которые знают вашу закрытую информацию, могут уволиться, поругаться со своим руководством, а потом каким-то образом использовать полученную информацию в тайне от вас.
3️⃣ Вы не контролируете отношения специалиста, который с вами работает, с его руководством. Он может быть чем-то недоволен, работать спустя рукава, быть перегружен. Это будет сказываться на качестве выполнения ваших задач, но реально вы особо не сможете на него воздействовать. Максимум, сможете попросить заменить специалиста, но это потеря времени и куча сопутствующих проблем и задержек.
4️⃣ Могут возникать ситуации, когда время реакции на ваши запросы будет велико, либо они будут передаваться через несколько рук: через секретаря, менеджера, прежде чем дойдет до специалиста. Специалисты чаще всего загружены полностью в течении рабочего дня, работодателю не выгоден простой. Причем, чем лучше специалист, тем сильнее он загружен. Так что оперативной реакции конкретного специалиста может не быть, хотя вам это обязательно будут обещать. А подменный не сможет оперативно решить вашу задачу, если она не совсем тривиальная.
Подводим итоги. Реально с вами будет работать конкретный человек компании, предлагающей услугу IT аутсорсинга, и качество работы будет напрямую зависеть от его профессионализма. Причем деньги он будет получать не от вас, а от своего руководителя, так что слушать и выполнять задачи он будет в первую очередь от него и уже потом от вас. От его отношений с руководителем будет зависеть как долго и качественно он будет работать. Возможно он уволится и уйдет (вместе с вашими паролями), а на его место придет другой человек, которого вы не знаете. Он вообще может вам не понравиться, так как будет угрюмый, злой и неприятно пахнуть.
По моему мнению, выгоднее взять на пол или четверть ставки в штат своего специалиста и работать с ним напрямую. Да, это будет хлопотнее со стороны руководителя, так как человека надо найти и оформить. Но по факту это будет дешевле и надёжнее. Причем, если есть более ли менее сложная инфраструктура, но объем работ небольшой, лучше взять админа на четверть ставки и тех. поддержку на пол ставки. У меня есть много успешного опыта взаимодействия в таком формате. Удобно всем.
#мысли
Мне приходилось часто сталкиваться с поддержкой инфраструктур или разработкой со стороны аутсорсинговых компаний. И всегда это был печальный опыт, иначе я бы о нём не узнал. Это не значит, что весь аутсорс плохой. Это то, с чем сталкивался лично я. Опишу наиболее ощутимые минусы этого процесса.
1️⃣ Даже если вам и будут обещать непрерывную поддержку 24/7, по факту напрямую работать с вами будет скорее всего один и тот же специалист. Он будет более ли менее погружён в вашу инфраструктуру. Все остальные будут только затягивать время, изображать активность в тикетах и решать что-то совсем простое и некритичное.
2️⃣ Все ваши пароли и другая коммерческая информация будет доступна кругу лиц, который вы не сможете контролировать. Вы даже не будете реально знать, у кого есть ваши доступы. Причём люди, которые знают вашу закрытую информацию, могут уволиться, поругаться со своим руководством, а потом каким-то образом использовать полученную информацию в тайне от вас.
3️⃣ Вы не контролируете отношения специалиста, который с вами работает, с его руководством. Он может быть чем-то недоволен, работать спустя рукава, быть перегружен. Это будет сказываться на качестве выполнения ваших задач, но реально вы особо не сможете на него воздействовать. Максимум, сможете попросить заменить специалиста, но это потеря времени и куча сопутствующих проблем и задержек.
4️⃣ Могут возникать ситуации, когда время реакции на ваши запросы будет велико, либо они будут передаваться через несколько рук: через секретаря, менеджера, прежде чем дойдет до специалиста. Специалисты чаще всего загружены полностью в течении рабочего дня, работодателю не выгоден простой. Причем, чем лучше специалист, тем сильнее он загружен. Так что оперативной реакции конкретного специалиста может не быть, хотя вам это обязательно будут обещать. А подменный не сможет оперативно решить вашу задачу, если она не совсем тривиальная.
Подводим итоги. Реально с вами будет работать конкретный человек компании, предлагающей услугу IT аутсорсинга, и качество работы будет напрямую зависеть от его профессионализма. Причем деньги он будет получать не от вас, а от своего руководителя, так что слушать и выполнять задачи он будет в первую очередь от него и уже потом от вас. От его отношений с руководителем будет зависеть как долго и качественно он будет работать. Возможно он уволится и уйдет (вместе с вашими паролями), а на его место придет другой человек, которого вы не знаете. Он вообще может вам не понравиться, так как будет угрюмый, злой и неприятно пахнуть.
По моему мнению, выгоднее взять на пол или четверть ставки в штат своего специалиста и работать с ним напрямую. Да, это будет хлопотнее со стороны руководителя, так как человека надо найти и оформить. Но по факту это будет дешевле и надёжнее. Причем, если есть более ли менее сложная инфраструктура, но объем работ небольшой, лучше взять админа на четверть ставки и тех. поддержку на пол ставки. У меня есть много успешного опыта взаимодействия в таком формате. Удобно всем.
#мысли
Вчерашняя заметка про аутсорс получила очень активный отклик. Не ожидал такого. Спасибо всем за содержательные комментарии. Было интересно почитать. Дополню немного тему, чтобы не возвращаться к ней в ближайшее время.
В целом, я пояснил, что делюсь именно своим опытом и не считаю, что аутсорс это однозначно неподходящий вариант для небольших компаний. Зачастую руководители считают, что смогут сэкономить, получив не хуже, а даже лучше услуги за меньшие деньги. Но по факту, чтобы снять с себя хлопоты по содержанию IT и получить хорошее качество услуг, платить придется в целом больше, чем своему сотруднику в штате на неполную ставку. Посыл именно в том, что экономии не будет. Хорошо, если будет то на то, но на практике я вижу, что качественный аутсорс стоит хороших денег.
И еще один момент, про который я забыл упомянуть, но он является крайне важным. Мне приходилось и подбирать аутсорс компании, и нанимать сотрудников на неполную ставку. Про то, что перенимал дела от других, я уже упоминал вчера. Так вот, некоторые компании или специалисты привязывают организацию к своим системам. В первую очередь речь идёт про бэкапы и мониторинг. Может добавиться что-то еще.
Для организации это огромный минус, так как при отказе от обслуживания она остается без важных сервисов. Для аутсорсеров это экономия средств и удобство управления. Я лично такие компании и таких специалистов сразу отсеивал. Если они не готовы построить всю инфраструктуру на железе заказчика, то лучше не рисковать. Да, я понимаю, что подобная инфраструктура будет стоить отдельных денег и в целом услуга будет дороже. Отказ от нее ставит заказчика в зависимое положение. Я лично всегда и всё строю у заказчиков, хотя очень хочется всё сделать в рамках своих систем. Так будет проще мне. При этом я знаю, что это крайне неудобно заказчику, даже если он сам этого не понимает. Но я то понимаю.
Очень любопытно узнать, как делают представители атусорсинга, которые отметились в комментариях к прошлой заметке. Вы строите инфраструктуру у заказчика, или подключаете его к своим сервисам? Даёте возможность выбора?
#мысли
В целом, я пояснил, что делюсь именно своим опытом и не считаю, что аутсорс это однозначно неподходящий вариант для небольших компаний. Зачастую руководители считают, что смогут сэкономить, получив не хуже, а даже лучше услуги за меньшие деньги. Но по факту, чтобы снять с себя хлопоты по содержанию IT и получить хорошее качество услуг, платить придется в целом больше, чем своему сотруднику в штате на неполную ставку. Посыл именно в том, что экономии не будет. Хорошо, если будет то на то, но на практике я вижу, что качественный аутсорс стоит хороших денег.
И еще один момент, про который я забыл упомянуть, но он является крайне важным. Мне приходилось и подбирать аутсорс компании, и нанимать сотрудников на неполную ставку. Про то, что перенимал дела от других, я уже упоминал вчера. Так вот, некоторые компании или специалисты привязывают организацию к своим системам. В первую очередь речь идёт про бэкапы и мониторинг. Может добавиться что-то еще.
Для организации это огромный минус, так как при отказе от обслуживания она остается без важных сервисов. Для аутсорсеров это экономия средств и удобство управления. Я лично такие компании и таких специалистов сразу отсеивал. Если они не готовы построить всю инфраструктуру на железе заказчика, то лучше не рисковать. Да, я понимаю, что подобная инфраструктура будет стоить отдельных денег и в целом услуга будет дороже. Отказ от нее ставит заказчика в зависимое положение. Я лично всегда и всё строю у заказчиков, хотя очень хочется всё сделать в рамках своих систем. Так будет проще мне. При этом я знаю, что это крайне неудобно заказчику, даже если он сам этого не понимает. Но я то понимаю.
Очень любопытно узнать, как делают представители атусорсинга, которые отметились в комментариях к прошлой заметке. Вы строите инфраструктуру у заказчика, или подключаете его к своим сервисам? Даёте возможность выбора?
#мысли
{kind=link}
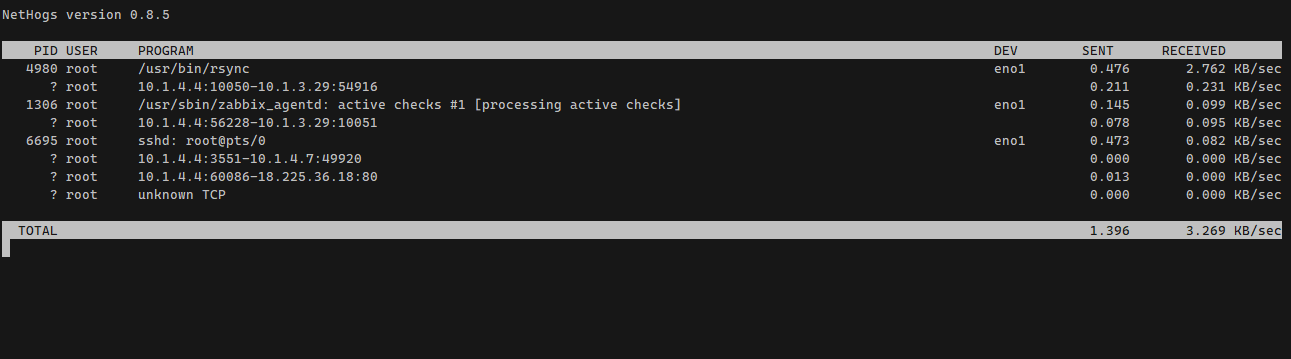
Очень удобная и простая утилита наподобие top, только для пропускной способности сети - nethogs.
После запуска в командной строке вы увидите pid процесса, его название, сетевой интерфейс и пропускную способность сети, которую в данный момент занимает конкретный процесс.
Утилита очень удобна для того, чтобы быстро понять, кто конкретно нагружает сеть на сервере или вирутальной машине.
Особо даже добавить нечего. Просто сохраните название утилиты и используйте, когда понадобится подобный функционал.
#утилита #сеть
dnf install nethogs (живёт в epel)apt install nethogsПосле запуска в командной строке вы увидите pid процесса, его название, сетевой интерфейс и пропускную способность сети, которую в данный момент занимает конкретный процесс.
Утилита очень удобна для того, чтобы быстро понять, кто конкретно нагружает сеть на сервере или вирутальной машине.
Особо даже добавить нечего. Просто сохраните название утилиты и используйте, когда понадобится подобный функционал.
#утилита #сеть
{kind=link}
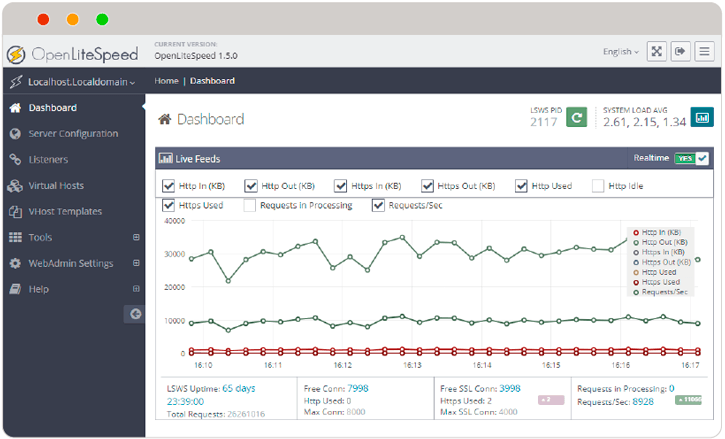
Существует простой, удобный и современный веб сервер - OpenLiteSpeed. Во многих типовых ситуациях он может быть удобнее привычного многим Nginx и тем более Apache.
Основными его отличиями является вот что:
1️⃣ У веб сервера присутствует встроенный WebAdmin GUI для управления. Причем этот способ настройки рекомендованный. Управлять веб сервером следует именно череp веб интерфейс, а не правкой конфигов.
2️⃣ OpenLiteSpeed поддерживает формат редиректов апачевского mod_rewrite. Не нужно переписывать редиректы из .htaccess при переезде с Apache.
3️⃣ Встроенная PageSpeed Optimization. Тут скажу честно, не знаю о чём речь с точки зрения технических нюансов. Я не вдавался в подробности.
4️⃣ Встроенная интеграция с плагином кэширования Wordpress - LSCache.
На сайте представлены какие-то графики сравнения производительности, по которым OpenLiteSpeed всех уделывает. На них не стоит обращать внимание. Я немного навел справки. В целом, он работает под большой нагрузкой медленнее Nginx. Но для типовых сайтов под всякие небольшие магазины и бложики разница не заметна. При этом веб сервером очень удобно управлять, особенно далеким от администрирования людям.
Так что если если вы начинающий веб разработчик, или кто-то вас попросит кому-то поднять веб сервер с готовой панелью для управления, попробуйте OpenLiteSpeed. Он может сильно выручить без использования глючных и местами дырявых бесплатных панелей управления веб сервером. Весь типовой функционал в виде виртуальных хостов, tls сертификатов, редиректов и т.д. присутствует.
https://openlitespeed.org/
#webserver
Основными его отличиями является вот что:
1️⃣ У веб сервера присутствует встроенный WebAdmin GUI для управления. Причем этот способ настройки рекомендованный. Управлять веб сервером следует именно череp веб интерфейс, а не правкой конфигов.
2️⃣ OpenLiteSpeed поддерживает формат редиректов апачевского mod_rewrite. Не нужно переписывать редиректы из .htaccess при переезде с Apache.
3️⃣ Встроенная PageSpeed Optimization. Тут скажу честно, не знаю о чём речь с точки зрения технических нюансов. Я не вдавался в подробности.
4️⃣ Встроенная интеграция с плагином кэширования Wordpress - LSCache.
На сайте представлены какие-то графики сравнения производительности, по которым OpenLiteSpeed всех уделывает. На них не стоит обращать внимание. Я немного навел справки. В целом, он работает под большой нагрузкой медленнее Nginx. Но для типовых сайтов под всякие небольшие магазины и бложики разница не заметна. При этом веб сервером очень удобно управлять, особенно далеким от администрирования людям.
Так что если если вы начинающий веб разработчик, или кто-то вас попросит кому-то поднять веб сервер с готовой панелью для управления, попробуйте OpenLiteSpeed. Он может сильно выручить без использования глючных и местами дырявых бесплатных панелей управления веб сервером. Весь типовой функционал в виде виртуальных хостов, tls сертификатов, редиректов и т.д. присутствует.
https://openlitespeed.org/
#webserver
{kind=link}
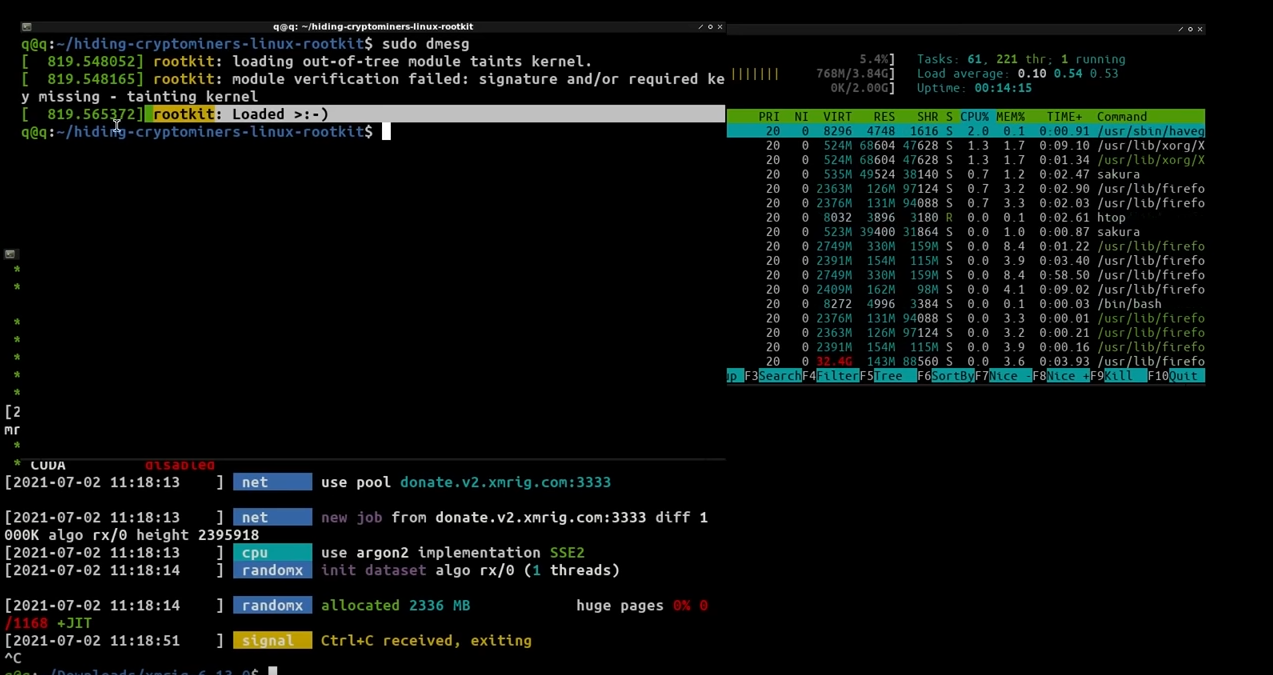
Вы знаете как работает ROOTkit? Я до недавнего времени вообще не задавался этим вопросом и только в общих чертах понимал, что это такое и как работает. На днях посмотрел полезное видео на эту тему и решил поделиться с вами.
https://www.youtube.com/watch?v=q4mJjmbjaqk
В видео наглядно показан руткит на основе модуля для ярда Linux, который скрывает из системного списка процессов процесс-вредитель. А так же убирает его из списка файлов в файловой системе. Простых способов обнаружить вредителя у вас не остается.
Мне кажется, что в своей практике я пару раз сталкивался с подобными вещами. Мои веб сервера вели себя крайне странно и я никак не мог понять, что с ними. Вопрос оба раза решался банальной перестановкой системы. На практике это самый простой и быстрый способ, который дает гарантированный результат, что позволяет спланировать затраченное время.
Если же вы начинаете бороться с неведомым всевозможными изысканиями, процесс исцеления может продлиться непрогнозируемо долго без гарантированного результата. Так что если у вас скомпрометирована система, лучше сразу ее переставить.
Руткит, показанный в видео, живёт тут - https://github.com/alfonmga/hiding-cryptominers-linux-rootkit
#видео
https://www.youtube.com/watch?v=q4mJjmbjaqk
В видео наглядно показан руткит на основе модуля для ярда Linux, который скрывает из системного списка процессов процесс-вредитель. А так же убирает его из списка файлов в файловой системе. Простых способов обнаружить вредителя у вас не остается.
Мне кажется, что в своей практике я пару раз сталкивался с подобными вещами. Мои веб сервера вели себя крайне странно и я никак не мог понять, что с ними. Вопрос оба раза решался банальной перестановкой системы. На практике это самый простой и быстрый способ, который дает гарантированный результат, что позволяет спланировать затраченное время.
Если же вы начинаете бороться с неведомым всевозможными изысканиями, процесс исцеления может продлиться непрогнозируемо долго без гарантированного результата. Так что если у вас скомпрометирована система, лучше сразу ее переставить.
Руткит, показанный в видео, живёт тут - https://github.com/alfonmga/hiding-cryptominers-linux-rootkit
#видео
{kind=link}
"Лаборатория Касперского" запускает ступенчатый подход к обеспечению кибербезопасности на основе трех уровней. У меня заказали обзор второго - Kaspersky Optimum Security, ориентированного на компании со средним уровнем развития ИБ-инфраструктуры.
В статье я беру конкретные продукты производителя, устанавливаю, настраиваю и наглядно показываю, как работает защита Kaspersky EDR для бизнеса Оптимальный. Это расширение базовой защиты на основе антивируса, который устанавливается на рабочие станции.
Ранее я несколько лет администрировал систему антивирусной защиты с помощью Kaspersky Secyrity Center (единая консоль управления), так что достаточно быстро развернул на тестовой лабе всё необходимое и сфокусировался конкретно на EDR (Endpoint Detection and Response) функционале.
Для тех, кто не знает, что такое EDR, кратко поясню. Это класс решений для обнаружения и изучения вредоносной активности на конечных точках. То есть не просто предотвращение заражения блокировкой вирусной активности, но и полная аналитика по ней, чтобы можно было провести дальнейшую работу, связанную с предотвращением и устранением последствий активности вирусов.
Я рекомендую посмотреть статью тем, кто занимается антивирусной защитой рабочих станций и серверов, а также кибербезопасностью в целом. Я сам раньше не был знаком с EDR-решениями. Сейчас посмотрел и оценил удобство с точки зрения системного администратора, отвечающего в том числе за безопасность.
https://serveradmin.ru/laboratoriya-kasperskogo-stupenchatyj-podhod-k-kiberbezopasnosti/
#ИБ #Kaspersky #антивирус #статья
В статье я беру конкретные продукты производителя, устанавливаю, настраиваю и наглядно показываю, как работает защита Kaspersky EDR для бизнеса Оптимальный. Это расширение базовой защиты на основе антивируса, который устанавливается на рабочие станции.
Ранее я несколько лет администрировал систему антивирусной защиты с помощью Kaspersky Secyrity Center (единая консоль управления), так что достаточно быстро развернул на тестовой лабе всё необходимое и сфокусировался конкретно на EDR (Endpoint Detection and Response) функционале.
Для тех, кто не знает, что такое EDR, кратко поясню. Это класс решений для обнаружения и изучения вредоносной активности на конечных точках. То есть не просто предотвращение заражения блокировкой вирусной активности, но и полная аналитика по ней, чтобы можно было провести дальнейшую работу, связанную с предотвращением и устранением последствий активности вирусов.
Я рекомендую посмотреть статью тем, кто занимается антивирусной защитой рабочих станций и серверов, а также кибербезопасностью в целом. Я сам раньше не был знаком с EDR-решениями. Сейчас посмотрел и оценил удобство с точки зрения системного администратора, отвечающего в том числе за безопасность.
https://serveradmin.ru/laboratoriya-kasperskogo-stupenchatyj-podhod-k-kiberbezopasnosti/
#ИБ #Kaspersky #антивирус #статья
Server Admin
«Лаборатория Касперского»: ступенчатый подход к кибербезопасности...
Все мы знаем истории, когда вирусы парализовывали работу огромных компаний. Итог - большие финансовые потери, урон репутации. «Лаборатория Касперского» разработала свой многоступенчатый подход к...