
В выходные прочитал любопытную статью про новый тип DNS записей - HTTPS и SVCB. Речь о них ведётся давно. Я вроде раньше уже слышал что-то подобное, но не разбирался, как это работает. Каким образом новая DNS запись HTTPS должна улучшить нашу жизнь? Посмотрел подробности. Расскажу вам простыми словами.
Новая DNS запись HTTPS призвана уменьшить такой параметр, как time-to-first-packet. В общем случае он не сильно знаком админам, но лично я его хорошо знаю с точки зрения SEO. Это один из факторов ранжирования у поисковиков. Чем быстрее сервер отвечает клиенту, тем лучше.
Принцип работы этой записи довольно простой. Она содержит в себе следующую информацию:
◽доменное имя;
◽версия HTTP протокола;
◽IP адрес сервера.
Выглядит это примерно так:
Запрос на получение этой DNS записи делает браузер. В итоге он сразу же получает всю нужную информацию, чтобы выполнить подключение к целевому веб серверу и конкретному урлу без необходимости дополнительных согласований.
Если нет этой записи, то браузер действует следующим образом:
1️⃣ Запрашивает А запись, чтобы выполнить преобразование доменного имени в IP.
2️⃣ Обращается к веб серверу по IP, передав в заголовке имя домена. Выполняет привычные TLS согласования, возможно в процессе изменяет версию протокола HTTP.
3️⃣ Если на сервере настроен редирект, то идёт по этому редиректу. В HTTPS записи можно сразу указать нужный url, на которой пойдёт браузер при обращении к конкретному домену.
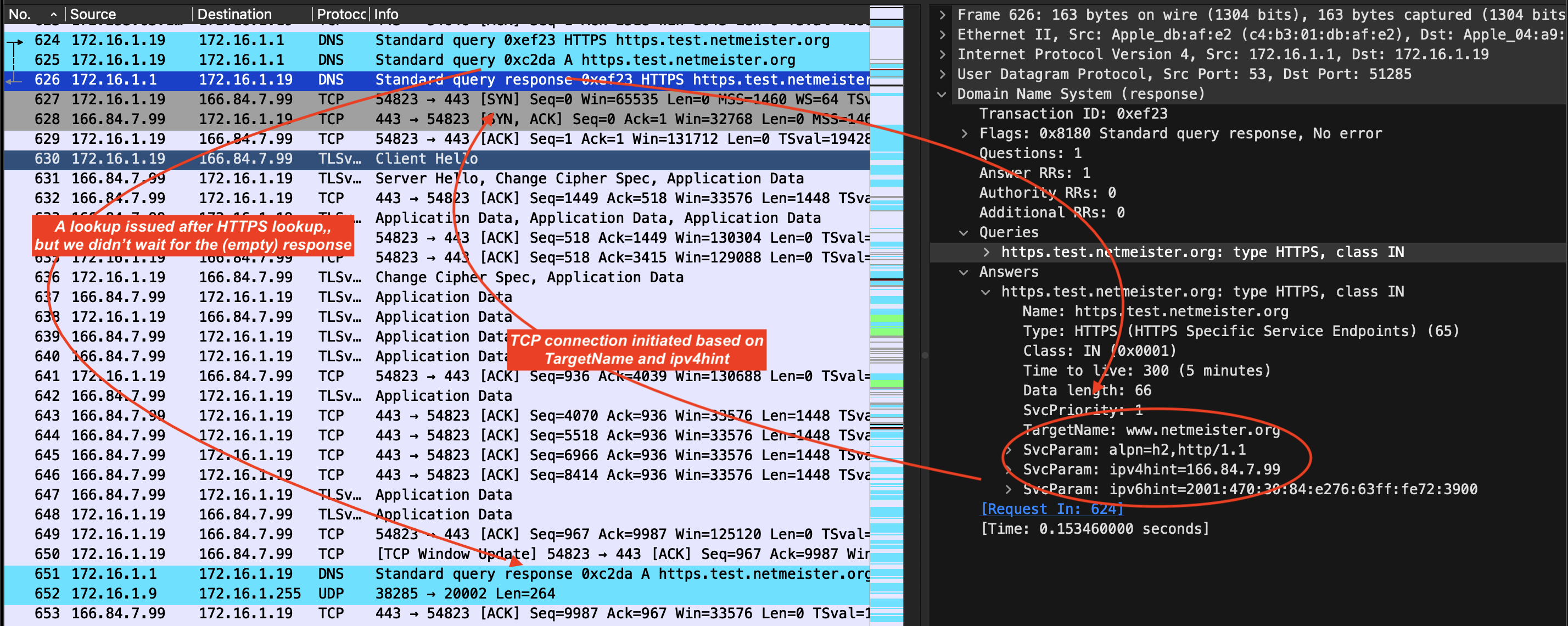
В статье приведён пример с доменом https.test.netmeister.org и соответствующей HTTPS записью:
Браузер при обращении к урлу https.test.netmeister.org сразу же идёт на сервер 166.84.7.99 по протоколу h2 и просит урл www.netmeister.org, не дожидаясь редиректа веб сервера. При этом A записи нет вообще. При наличии HTTPS записи она становится не нужна. В статье в том числе показан сетевой дамп при выполнении подобного запроса.
В целом, поддержка HTTPS записей уже принята и описана в RFC. Например, утилита
Может кто-то уже использует эти записи и знает хостеров, которые их поддерживают?
#dns
Новая DNS запись HTTPS призвана уменьшить такой параметр, как time-to-first-packet. В общем случае он не сильно знаком админам, но лично я его хорошо знаю с точки зрения SEO. Это один из факторов ранжирования у поисковиков. Чем быстрее сервер отвечает клиенту, тем лучше.
Принцип работы этой записи довольно простой. Она содержит в себе следующую информацию:
◽доменное имя;
◽версия HTTP протокола;
◽IP адрес сервера.
Выглядит это примерно так:
example.com. 1800 IN HTTPS 1 . alpn=h3,h2 ipv4hint=1.2.3.4 ipv6hint=2001:470:30:84:e276:63ff:fe72:3900 Запрос на получение этой DNS записи делает браузер. В итоге он сразу же получает всю нужную информацию, чтобы выполнить подключение к целевому веб серверу и конкретному урлу без необходимости дополнительных согласований.
Если нет этой записи, то браузер действует следующим образом:
1️⃣ Запрашивает А запись, чтобы выполнить преобразование доменного имени в IP.
2️⃣ Обращается к веб серверу по IP, передав в заголовке имя домена. Выполняет привычные TLS согласования, возможно в процессе изменяет версию протокола HTTP.
3️⃣ Если на сервере настроен редирект, то идёт по этому редиректу. В HTTPS записи можно сразу указать нужный url, на которой пойдёт браузер при обращении к конкретному домену.
В статье приведён пример с доменом https.test.netmeister.org и соответствующей HTTPS записью:
www.netmeister.org. alpn="h2,http/1.1" ipv4hint=166.84.7.99Браузер при обращении к урлу https.test.netmeister.org сразу же идёт на сервер 166.84.7.99 по протоколу h2 и просит урл www.netmeister.org, не дожидаясь редиректа веб сервера. При этом A записи нет вообще. При наличии HTTPS записи она становится не нужна. В статье в том числе показан сетевой дамп при выполнении подобного запроса.
В целом, поддержка HTTPS записей уже принята и описана в RFC. Например, утилита
dig их поддерживает. Я проверил. Современные браузеры тоже поддерживают. Зашёл к DNS хостингам, которыми пользуюсь. Там возможности добавить HTTPS запись нет. То есть на практике пока не получается ими пользоваться. А так удобно сделано. Как только появится поддержка у хостеров, надо будет настроить.Может кто-то уже использует эти записи и знает хостеров, которые их поддерживают?
#dns
{kind=link}
Решил не откладывать в долгий ящик и перевести один из веб серверов на Angie. Как и обещали разработчики, с конфигами Nginx полная совместимость. Установил Angie и скопировал основной конфиг сервиса, а также виртуальных хостов. Виртуальные хосты вообще не трогал, а основной конфиг немного подредактировал, изменив в include пути с
Остановил Nginx, запустил Angie. Никаких проблем. Всё мгновенно подхватилось новым веб серверов. Простой пару секунд.
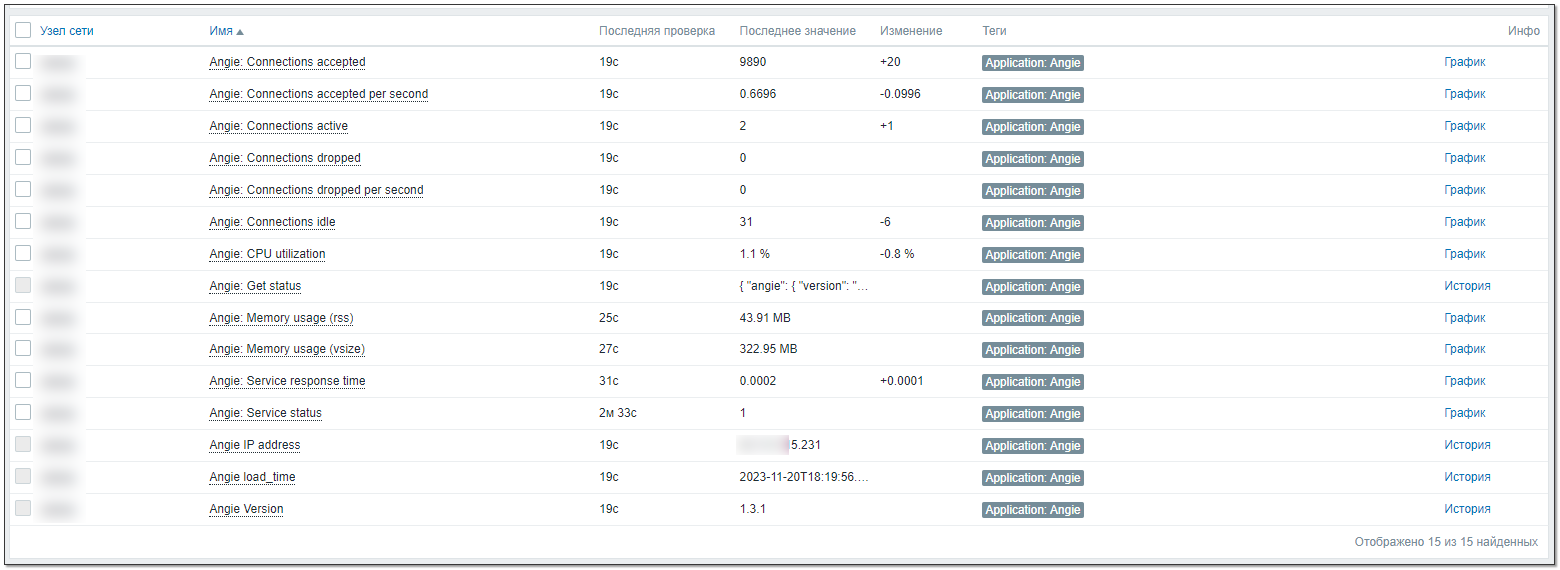
Заметку пишу не про переход, а про мониторинг. Согласно документации настроил передачу метрик сервера через API, веб консоль и метрики Prometheus. С прометеусом пока не разбирался, веб консоль просто для красоты включил, а внимание уделил API. Настроил шаблон Zabbix для сбора метрик через API. Сделал по аналогии с Nginx, но кое-что изменил по своему усмотрению. Шаблон можно скачать тут. Это первая версия. Немного попользуюсь и надеюсь, что оформлю всё это в полноценную статью с какими-то правками, которые наверняка накопятся по мере использования.
В шаблоне используются 2 макроса:
◽{$STATUS_HOST} - ip адрес сервера
◽{$STATUS_PATH} - часть урла для API.
У меня доступ к API настроен по IP, а полный путь выглядит так: http://1.2.3.4/status/. Соответственно, первый макрос - 1.2.3.4, второй - /status/.
На картинке ниже метрики, которые я посчитал полезными и добавил в шаблон. Триггера сделал три: не отвечает внешний порт веб сервера, нет ни одного процесса angie на сервере, не поступают данные от API в мониторинг. Также добавил 4 графика и оформил всё в панель. Картинку панели покажу в комментариях.
#angie #zabbix
/etc/nginx на /etc/angie. Ещё параметр pid изменил с /var/run/nginx.pid на /run/angie.pid. Больше ничего не менял. Остановил Nginx, запустил Angie. Никаких проблем. Всё мгновенно подхватилось новым веб серверов. Простой пару секунд.
Заметку пишу не про переход, а про мониторинг. Согласно документации настроил передачу метрик сервера через API, веб консоль и метрики Prometheus. С прометеусом пока не разбирался, веб консоль просто для красоты включил, а внимание уделил API. Настроил шаблон Zabbix для сбора метрик через API. Сделал по аналогии с Nginx, но кое-что изменил по своему усмотрению. Шаблон можно скачать тут. Это первая версия. Немного попользуюсь и надеюсь, что оформлю всё это в полноценную статью с какими-то правками, которые наверняка накопятся по мере использования.
В шаблоне используются 2 макроса:
◽{$STATUS_HOST} - ip адрес сервера
◽{$STATUS_PATH} - часть урла для API.
У меня доступ к API настроен по IP, а полный путь выглядит так: http://1.2.3.4/status/. Соответственно, первый макрос - 1.2.3.4, второй - /status/.
На картинке ниже метрики, которые я посчитал полезными и добавил в шаблон. Триггера сделал три: не отвечает внешний порт веб сервера, нет ни одного процесса angie на сервере, не поступают данные от API в мониторинг. Также добавил 4 графика и оформил всё в панель. Картинку панели покажу в комментариях.
#angie #zabbix
{kind=link}
Я вроде бы уже когда-то упоминал про англоязычную рассылку devopsweekly.com, но не могу найти этой записи. Возможно и нет. В общем, это такая олдскульная рассылка на почту в текстовом формате раз в неделю с некоторыми новостями. Я её давно уже читаю, более двух лет.
Мне нравится такой формат, когда раз в неделю, в воскресенье, приходят новости по определённой тематике. Читаю я там далеко не всё, но просматриваю регулярно. Я как раз в воскресенье вечером сажусь за компьютер, проверить и подготовить список основных дел на неделю. Заодно читаю эту рассылку.
Вчерашнюю заметку про HTTPS записи DNS как раз там повстречал. Было бы круто, если бы кто-то ещё начал вести подобные рассылки по разным направлениям: безопасность, сети, обновления, Windows, Linux и т.д. Можно в Telegram. А лучше и здесь, и по почте.
Дарю готовую идею 😀 Я сам когда-то думал подобное вести, но у меня нет на это времени. Данный канал всё занимает. В таких подборках важно, чтобы они выходили не чаще раза в неделю. В качестве монетизации можно одну новость делать рекламную.
Если кто-то знает похожие рассылки, не обязательно на русском языке, поделитесь.
#devops
Мне нравится такой формат, когда раз в неделю, в воскресенье, приходят новости по определённой тематике. Читаю я там далеко не всё, но просматриваю регулярно. Я как раз в воскресенье вечером сажусь за компьютер, проверить и подготовить список основных дел на неделю. Заодно читаю эту рассылку.
Вчерашнюю заметку про HTTPS записи DNS как раз там повстречал. Было бы круто, если бы кто-то ещё начал вести подобные рассылки по разным направлениям: безопасность, сети, обновления, Windows, Linux и т.д. Можно в Telegram. А лучше и здесь, и по почте.
Дарю готовую идею 😀 Я сам когда-то думал подобное вести, но у меня нет на это времени. Данный канал всё занимает. В таких подборках важно, чтобы они выходили не чаще раза в неделю. В качестве монетизации можно одну новость делать рекламную.
Если кто-то знает похожие рассылки, не обязательно на русском языке, поделитесь.
#devops
{kind=link}
Если у вас есть потребность в автоматизации сетевой установки операционных систем на компьютеры или виртуальные машины, то решить эту задачу можно с помощью бесплатного сервера Cobbler. С его помощью можно организовать единый сервер сетевой установки Linux и Windows систем, которые будут загружаться с помощью технологии PXE (Preboot eXecution Environment).
Работает это следующим образом. Распишу сразу наиболее продвинутую конфигурацию. Вы разворачиваете сервер Cobbler вместе с DHCP (isc-dhcp-server) и DNS (bind) серверами. Cobbler имеет шаблоны и инструменты для автоматического управления этими службами. Готовите на сервере образ системы либо для ручной установки, либо сразу с файлами ответов для полностью автоматического разворачивания.
Когда сервер готов, запускаете машину с настроенной загрузкой по PXE. Если это реальное железо, то настройки выполняются в BIOS, в свойствах сетевой карты и опциях загрузки. Если речь идёт про виртуальную машину, то в boot меню виртуалки выбирается загрузка по PXE. Машина стартует, запускается PXE, на основе MAC адреса по DHCP получает соответствующие настройки с указанием адреса загрузочного образа. Загружается с этого образа по сети и запускается установка основной ОС в зависимости от её настроек. Можно сразу настроить установку сетевых параметров и имени машины с автоматическим добавлением этих данных в DNS.
С помощью подобной технологии можно не только выполнять установку ОС, но и создавать образы для бездисковой работы на рабочих станциях. Например, когда-то давно я лично настраивал бездисковые рабочие станции с загрузкой по PXE, для того, чтобы они могли подключиться по RDP к терминальному серверу. Готовилась простая сборка системы с загрузкой в оперативную память и автоматическим подключением с помощью FreeRDP. Локальные диски вообще не использовались (были вынуты).
Сразу могу сказать, что настройка подобной системы сложна. Без понимания работы всех смежных технологий настроить будет трудно. Это инструмент для тех, кто понимает и знает, зачем ему всё это нужно. Изначально Cobbler ориентирован на rpm дистрибутивы, но так как написан на Python, с некоторыми правками запускается и на Debian. Я использовал официальную инструкцию и статью под Debian. Статья уже устарела и простым копипастом не настроить, но основные моменты где и что нужно будет поправить можно посмотреть. Также список пакетов под Debian там актуальный, не хватает только
Когда я настраивал Cobbler, усиленно пытался вспомнить, на что он похож. Я подобный софт уже видел. В конце вспомнил. Это аналог FOG Project. Он решает схожую задачу, используя те же технологии, но при этом проще в настройках, но и возможностей в нём поменьше. Cobbler более функциональный, так как может работать в связке с DHCP и DNS сервером, да и других более тонких настроек в нём больше.
⇨ Сайт / Исходники
#pxe
Работает это следующим образом. Распишу сразу наиболее продвинутую конфигурацию. Вы разворачиваете сервер Cobbler вместе с DHCP (isc-dhcp-server) и DNS (bind) серверами. Cobbler имеет шаблоны и инструменты для автоматического управления этими службами. Готовите на сервере образ системы либо для ручной установки, либо сразу с файлами ответов для полностью автоматического разворачивания.
Когда сервер готов, запускаете машину с настроенной загрузкой по PXE. Если это реальное железо, то настройки выполняются в BIOS, в свойствах сетевой карты и опциях загрузки. Если речь идёт про виртуальную машину, то в boot меню виртуалки выбирается загрузка по PXE. Машина стартует, запускается PXE, на основе MAC адреса по DHCP получает соответствующие настройки с указанием адреса загрузочного образа. Загружается с этого образа по сети и запускается установка основной ОС в зависимости от её настроек. Можно сразу настроить установку сетевых параметров и имени машины с автоматическим добавлением этих данных в DNS.
С помощью подобной технологии можно не только выполнять установку ОС, но и создавать образы для бездисковой работы на рабочих станциях. Например, когда-то давно я лично настраивал бездисковые рабочие станции с загрузкой по PXE, для того, чтобы они могли подключиться по RDP к терминальному серверу. Готовилась простая сборка системы с загрузкой в оперативную память и автоматическим подключением с помощью FreeRDP. Локальные диски вообще не использовались (были вынуты).
Сразу могу сказать, что настройка подобной системы сложна. Без понимания работы всех смежных технологий настроить будет трудно. Это инструмент для тех, кто понимает и знает, зачем ему всё это нужно. Изначально Cobbler ориентирован на rpm дистрибутивы, но так как написан на Python, с некоторыми правками запускается и на Debian. Я использовал официальную инструкцию и статью под Debian. Статья уже устарела и простым копипастом не настроить, но основные моменты где и что нужно будет поправить можно посмотреть. Также список пакетов под Debian там актуальный, не хватает только
python3-schema. И вот это обсуждение ошибки пригодится, если будете пакет под debian собирать. Когда я настраивал Cobbler, усиленно пытался вспомнить, на что он похож. Я подобный софт уже видел. В конце вспомнил. Это аналог FOG Project. Он решает схожую задачу, используя те же технологии, но при этом проще в настройках, но и возможностей в нём поменьше. Cobbler более функциональный, так как может работать в связке с DHCP и DNS сервером, да и других более тонких настроек в нём больше.
⇨ Сайт / Исходники
#pxe
{kind=link}
Казалось бы, что может быть проще копирования файлов из одной директории в другую. Тем не менее в консоли Linux это не всегда простая и очевидная процедура. Для этого существует небольшая утилита
Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
Но так скопируются только файлы, без вложенных директорий. Добавляем ключ
По моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
На длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
Ещё засаду с
Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
Тут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
cp, которая обычно присутствует во всех дистрибутивах. Лично у меня сложности возникают с тем, что я начинаю вспоминать, нужно ли использовать *, ставить или нет слеш на конце директории и т.д. Всё это влияет на конечный результат. Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
# cp /dir_a/* /dir_bНо так скопируются только файлы, без вложенных директорий. Добавляем ключ
-r или сразу -a, чтобы и все атрибуты скопировать:# cp -a /dir_a/* /dir_bПо моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
# cp -a /dir_a/file1 /dir_a/file2 /dir_a/file3 ...... /dir_bНа длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
* в командах, запускаемых в bash, работает именно так.Ещё засаду с
cp можно получить, если в директории будут файлы, начинающиеся с точки. Те же .htaccess. Если скопируем предложенной выше командой со *, то все файлы с точкой в начале имени потеряем. Будет неприятно. Это опять же особенность bash, которая по умолчанию трактует такие файлы как скрытые. Такое поведение можно изменить.Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
* :# cp -aT /dir_a /dir_bТут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
Вчера в заметке про копирование с помощью
Мы всё содержимое директории
В Linux, как и в DOS кстати, существуют некие псевдопапки-ссылки на текущую и вышестоящую директории. Точка - это, соответственно, текущая директория, а две точки - вышестоящая по отношению к текущей. Обращаться к ним можно так же, как и к обычным папкам. Они, собственно, на вид ничем от остальных и не отличаются. Если сделать
Можно сделать:
и остаться в текущем каталоге, либо:
и перейти в вышестоящий, родительский каталог для текущего.
Отсюда становится понятно, почему для запуска скрипта в текущем каталоге, мы используем точку:
Явно указываем на скрипт, который запускаем. Иначе оболочка проверит
Две точки часто используют в скриптах, чтобы обращаться в родительский каталог, когда надо оперировать файлами не только текущего. А так как мы не можем точно знать без дополнительных проверок, как называется родительский каталог, то две точки это удобный вариант.
Создали файл в вышестоящем каталоге, ничего не зная про него. Без двух точек нам сначала пришлось бы выяснить, где мы находимся, чтобы определить родительский каталог. А так всё делаем сразу.
Если я не ошибаюсь, то точка и две точки это просто ссылки на inode конкретных директорий. Так что их наличие будет зависеть от файловой системы. В наиболее популярных они присутствуют.
#bash
cp в комментариях справедливо привели ещё один вариант копирования. Причём самый простой и удобный. Я про него знал, но не стал упоминать, потому что нужны будут пояснения для тех, кто не знает про некоторые особенности псевдопапок в виде точки или двух точек. Речь идёт о примерно такой конструкции:# cp -a /dir_a/. /dir_bМы всё содержимое директории
dir_a со всеми скрытыми файлами скопировали в dir_b. В Linux, как и в DOS кстати, существуют некие псевдопапки-ссылки на текущую и вышестоящую директории. Точка - это, соответственно, текущая директория, а две точки - вышестоящая по отношению к текущей. Обращаться к ним можно так же, как и к обычным папкам. Они, собственно, на вид ничем от остальных и не отличаются. Если сделать
ls -la, то мы их увидим вместе с остальными директориями:# ls -latotal 56drwx------ 8 root root 4096 Nov 22 21:37 .drwxr-xr-x 18 root root 4096 Oct 13 12:30 ..-rw------- 1 root root 6115 Nov 22 16:02 .bash_history-rw-r--r-- 1 root root 571 Apr 10 2021 .bashrcdrwx------ 3 root root 4096 Dec 9 2022 .cachedrwx------ 4 root root 4096 Nov 16 21:22 .config-rw-r--r-- 1 root root 56 Nov 15 00:19 .gitconfigdrwx------ 3 root root 4096 Dec 9 2022 .local-rw-r--r-- 1 root root 161 Jul 9 2019 .profile-rw-r--r-- 1 root root 72 Dec 9 2022 .selected_editordrwx------ 2 root root 4096 Nov 15 00:21 .sshМожно сделать:
# cd .и остаться в текущем каталоге, либо:
# cd .. и перейти в вышестоящий, родительский каталог для текущего.
Отсюда становится понятно, почему для запуска скрипта в текущем каталоге, мы используем точку:
# ./script.shЯвно указываем на скрипт, который запускаем. Иначе оболочка проверит
$PATH, там не окажется текущего каталога и скрипт не будет выполнен. Так что надо написать либо полный путь, либо использовать точку, если скрипт в текущем каталоге. Точно помню, что вот эту тему с точкой я очень долго не понимал и просто использовал. Даже мысли не было, что это я текущий каталог указываю. Думал, это какой-то признак исполняемого файла.Две точки часто используют в скриптах, чтобы обращаться в родительский каталог, когда надо оперировать файлами не только текущего. А так как мы не можем точно знать без дополнительных проверок, как называется родительский каталог, то две точки это удобный вариант.
# touch ../file.nameСоздали файл в вышестоящем каталоге, ничего не зная про него. Без двух точек нам сначала пришлось бы выяснить, где мы находимся, чтобы определить родительский каталог. А так всё делаем сразу.
Если я не ошибаюсь, то точка и две точки это просто ссылки на inode конкретных директорий. Так что их наличие будет зависеть от файловой системы. В наиболее популярных они присутствуют.
#bash
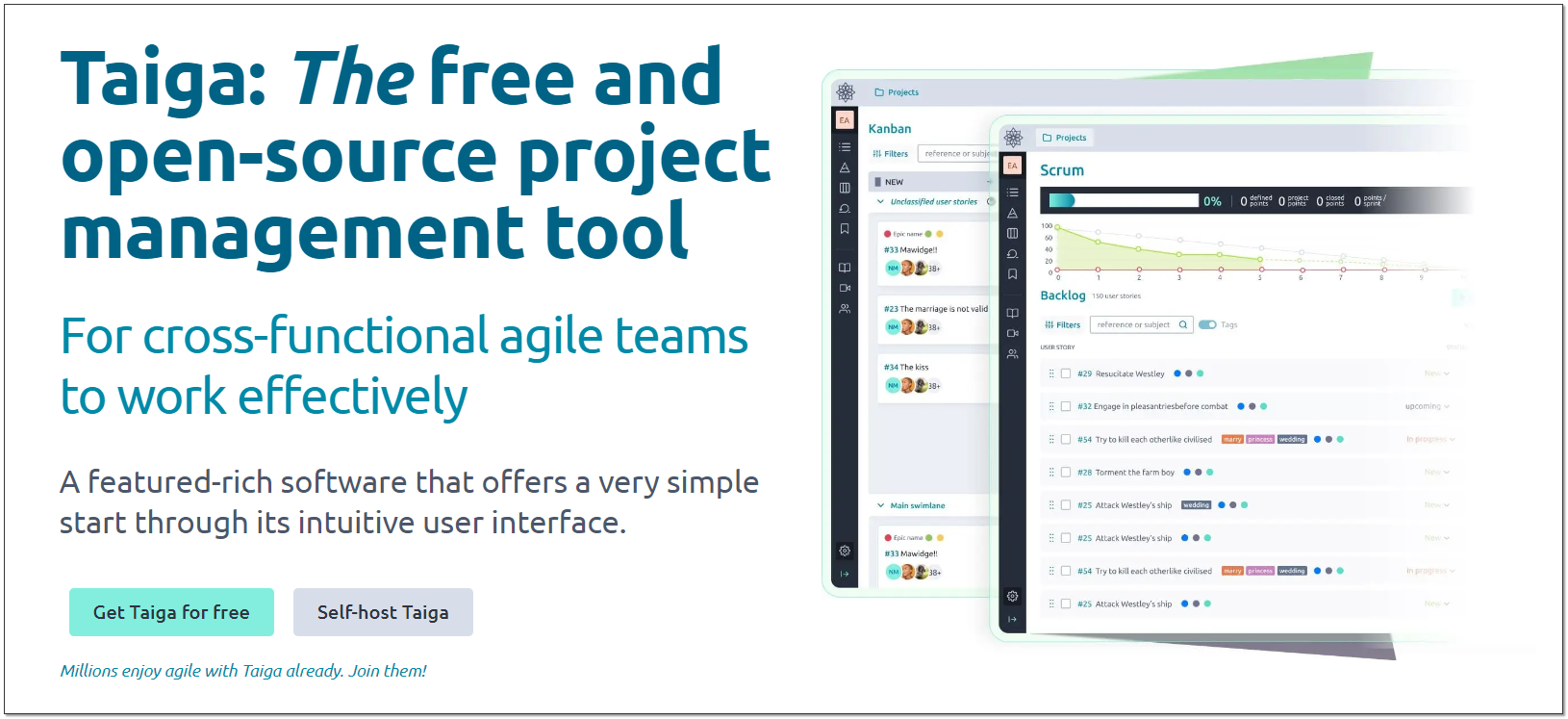
Знакомы ли вам такие современные понятия как Agile, Kanban, Scrum? Если совсем не знакомы, то у вас есть отличный шанс погрузиться в эту замечательную прогрессивную и развитую среду современной разработки и управления проектами с помощью бесплатного инструмента Taiga. Впрочем, если знакомы, то шанс тоже есть. Это open source проект для поднятия собственного self-hosted движка по управлению проектами. Условно можно назвать его современным аналогом Redmine или Youtrack. Условно, потому что по возможностям они сильно различаются, но в целом направлены на решение схожих задач.
Название Taiga меня сначала сбило с толку. Я думал, это что-то с корнями из России, Сибири, тайги. Но нет, это продукт испанской компании Kaleidos Ventures. Попробовать её можно разными способами: установить себе self-hosted версию или воспользоваться бесплатным тарифным планом облачной версии. Я покажу, как Тайгу установить у себя. Под капотом там следующий стек технологий:
◽Python - бэк, JavaScript - фронт.
◽СУБД PostgreSQL
◽RabbitMQ
Можно считать, что стандартный набор.
Ставить будем Docker версию из репозитория разработчиков:
В файле
Создаём пользователя. После этого идём по адресу сервера на порт 9000 и логинимся под созданной учёткой. Это вариант тестовой установки. Если будете ставить в прод, то в этой статье даны все необходимые рекомендации по настройке, в том числе по размещению за nginx proxy, использованию https, отправки почты и т.д.
Система прикольная. Выглядит современно, работает шустро. Есть youtube канал, где можно посмотреть, как она вживую выглядит. Раньше вроде бы было какое-то неофициальное приложение для смартфона на Android, но сейчас оно заброшено. Как я понял, интерфейс и так нормально адаптирован под смартфоны, так что большой нужды в приложении нет.
Немного почитал отзывы и статьи о Taiga. В основном положительные. Её называют бесплатной альтернативой Trello или Jira. Проект существует давно. Как минимум с 2014 года есть упоминания.
#управление_проектами
Название Taiga меня сначала сбило с толку. Я думал, это что-то с корнями из России, Сибири, тайги. Но нет, это продукт испанской компании Kaleidos Ventures. Попробовать её можно разными способами: установить себе self-hosted версию или воспользоваться бесплатным тарифным планом облачной версии. Я покажу, как Тайгу установить у себя. Под капотом там следующий стек технологий:
◽Python - бэк, JavaScript - фронт.
◽СУБД PostgreSQL
◽RabbitMQ
Можно считать, что стандартный набор.
Ставить будем Docker версию из репозитория разработчиков:
# git clone https://github.com/kaleidos-ventures/taiga-docker# cd taiga-docker/# git checkout stableВ файле
.env в переменной TAIGA_DOMAIN замените localhost на IP адрес сервера, если запускаете не на своей машине.# ./launch-all.sh# ./taiga-manage.sh createsuperuserСоздаём пользователя. После этого идём по адресу сервера на порт 9000 и логинимся под созданной учёткой. Это вариант тестовой установки. Если будете ставить в прод, то в этой статье даны все необходимые рекомендации по настройке, в том числе по размещению за nginx proxy, использованию https, отправки почты и т.д.
Система прикольная. Выглядит современно, работает шустро. Есть youtube канал, где можно посмотреть, как она вживую выглядит. Раньше вроде бы было какое-то неофициальное приложение для смартфона на Android, но сейчас оно заброшено. Как я понял, интерфейс и так нормально адаптирован под смартфоны, так что большой нужды в приложении нет.
Немного почитал отзывы и статьи о Taiga. В основном положительные. Её называют бесплатной альтернативой Trello или Jira. Проект существует давно. Как минимум с 2014 года есть упоминания.
#управление_проектами
{kind=link}
Выбирая между софтовым или железным рейдом, я чаще всего выберу софтовый, если не будет остро стоять вопрос быстродействия дисковой подсистемы. А в бюджетном сегменте обычно и выбирать не приходится. Хотя и дорогой сервер могу взять без встроенного рейд контроллера, особенно если там быстрые ssd или nvme диски.
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
и выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
Получаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
То же самое с mdadm. Смотрим состояние:
Добавляем утилиту jc:
Выгружаем полную информацию о массиве в формате json:
И отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
# apt install smartmontoolsи выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
# smartctl -i /dev/sdd -j# smartctl -A /dev/sdd -jПолучаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
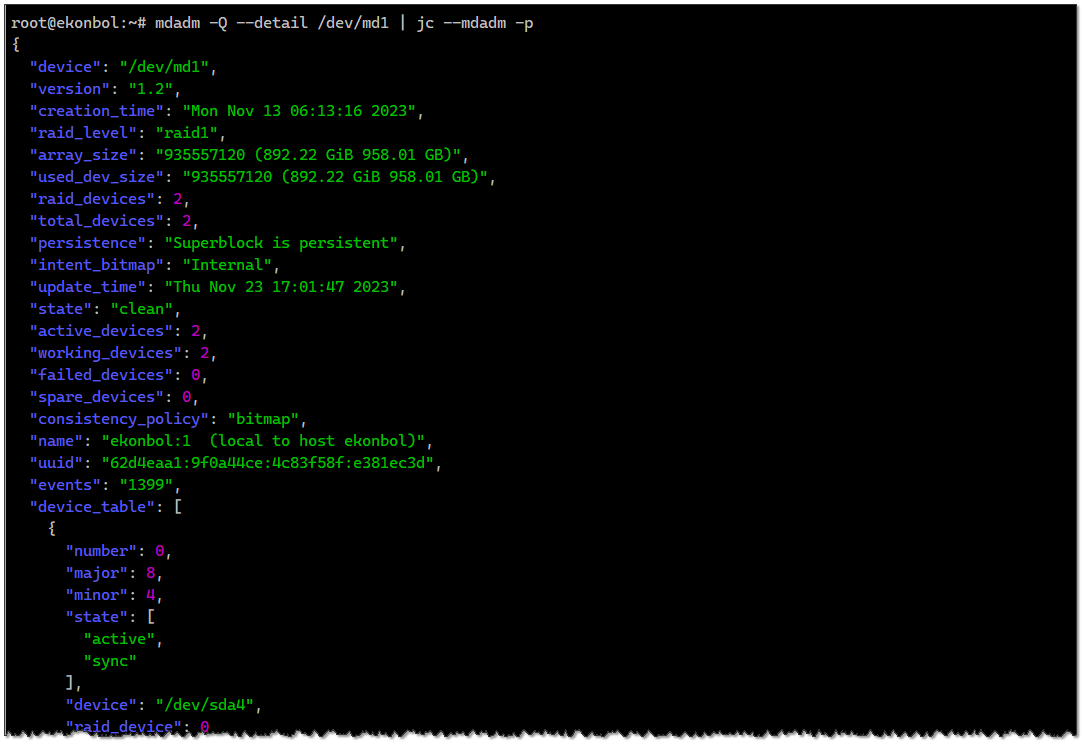
То же самое с mdadm. Смотрим состояние:
# mdadm -Q --detail /dev/md1Добавляем утилиту jc:
# apt install jcВыгружаем полную информацию о массиве в формате json:
# mdadm -Q --detail /dev/md1 | jc --mdadm -pИ отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Что такое Devops 😂
https://www.youtube.com/watch?v=NXwtcjOdaHw
Work-life balance ставишь 0.
Не понял только одно. Зачем докер контейнер упаковали в zip?
#юмор #devops
https://www.youtube.com/watch?v=NXwtcjOdaHw
Work-life balance ставишь 0.
Не понял только одно. Зачем докер контейнер упаковали в zip?
#юмор #devops
Очередная тема выходного дня. Хочу вернуться к своей старой заметке, написанной более 2,5 лет назад на тему того, как подходить к любому делу. Прежде чем продолжать чтение этой, прочитайте ту. Она не потеряла актуальность, и я не изменил своё мнение, более того, ещё больше убедился в правоте написанного. Говорю об этом, потому что получил подтверждение в том числе на основании опыта последних лет.
Во всех делах, которые я задумал и начал, неизменно продвинулся вперёд. Где-то больше, где-то меньше, но самое главное, что есть движение. Даже очень маленькие регулярные шажки по совершенно незнакомой теме приводят к результату. Главное, загрузить в голову какую-то мысль и снабжать её небольшими (можно и большими) порциями материала.
У меня это выглядит до банальности просто. Когда мне нужно решить какую-то задачу или что-то изучить, я делаю плейлисты из тематических видео в ютубе. И просто смотрю это либо целенаправленно, либо в фоне, когда куда-то еду на машине или в метро. Мозг начинает потихоньку получать и обрабатывать информацию. Потом ты целенаправленно или случайно (а все случайности на самом деле не случайны) получаешь расширение этой информации в виде новой информации или, что значительно лучше, контакты и знакомства по теме. Поэтому я не игнорирую очное посещение различных мероприятий (выстави, семинары, конференции и т.д.).
Я не знаю, как это работает. Разные люди объясняют это про разному. Кто-то говорит, что вселенная подсказывает. Кто-то, что мозг излучает какие-то волны и фиксируется на похожем излучении, когда видит тематическую информацию. Кто-то считает, что это участие бога. Не суть важно. Главное, что это работает. Жизненный опыт подтверждает, а как это на самом деле работает - вторично. Возможно, с нашего уровня развития это вообще нельзя изучить.
Приведу несколько своих примеров. Про этот канал я уже писал 2,5 года назад. Просто 2 публикации в день в течении нескольких лет и этот канал читают тысячи людей. Когда родился первый ребёнок, я не понимал, как вытянуть ещё больше. Но мне хотелось детей. В итоге жду сейчас четвертого. Всё само как-то устраивается потихонечку.
Начал строить дом вообще ничего не понимая и не зная. Косяков было море, крышу переделывал полностью (неправильно рассчитали стропильную систему). Какие только проблемы я не решал: потёкший котёл, постоянная влага в подполе, неправильная вентиляция, замёрзший ввод воды и т.д. Всё и не упомнишь уже. Тем не менее, шаг за шагом всё получилось. Дом достроен, а я параллельно освоил ещё одну профессию. Работал на стройке прорабом и технадзором для 5-ти разных бригад.
С воспитанием детей и семейной жизнью то же самое. Потихоньку изучаешь материалы, общаешься со специалистами, посещаешь тематические мероприятия. И все проблемы решаются, дела налаживаются, результат приходит.
Медицина - такая же история. Я сейчас прохожу новое лечение своей спины. Наконец-то удалось найти причину болей, поставить нормальный диагноз. Просто потихонечку крутил в голове мысли на эту тему, делал тут заметки. Одна из заметок и помогла. Там дали ссылку на канал Епифанова (на самом деле шарлатан), но через него я попал на настоящего врача и дела начали налаживаться. Кто много мается болями в спине, обратите внимание на заболевание миофасциальный синдром. Им много кто страдает, но врачи почему-то очень мало про него знают и почти не ставят такой диагноз.
В общем, так во всём: в работе, личных делах, в обучении и т.д. Просто сгружаешь в голову информацию и потихоньку обдумываешь, делаешь небольшие шажки, но регулярно. В этом сильно мешает различное ютубовское развлекалово. Это пустышка, которой люди забивают своё время, а некоторые вообще всё время. Я бью себя по руками и постоянно ограничиваю просмотр бесполезных вещей. Если надо отдохнуть и расслабиться, провожу время с детьми или гуляю.
Если вам интересно, могу каждый из перечисленных примеров подробно раскрыть отдельной заметкой. Пишите об этом и ставьте реакцию к посту, чтобы я понимал, писать или нет.
#мысли
Во всех делах, которые я задумал и начал, неизменно продвинулся вперёд. Где-то больше, где-то меньше, но самое главное, что есть движение. Даже очень маленькие регулярные шажки по совершенно незнакомой теме приводят к результату. Главное, загрузить в голову какую-то мысль и снабжать её небольшими (можно и большими) порциями материала.
У меня это выглядит до банальности просто. Когда мне нужно решить какую-то задачу или что-то изучить, я делаю плейлисты из тематических видео в ютубе. И просто смотрю это либо целенаправленно, либо в фоне, когда куда-то еду на машине или в метро. Мозг начинает потихоньку получать и обрабатывать информацию. Потом ты целенаправленно или случайно (а все случайности на самом деле не случайны) получаешь расширение этой информации в виде новой информации или, что значительно лучше, контакты и знакомства по теме. Поэтому я не игнорирую очное посещение различных мероприятий (выстави, семинары, конференции и т.д.).
Я не знаю, как это работает. Разные люди объясняют это про разному. Кто-то говорит, что вселенная подсказывает. Кто-то, что мозг излучает какие-то волны и фиксируется на похожем излучении, когда видит тематическую информацию. Кто-то считает, что это участие бога. Не суть важно. Главное, что это работает. Жизненный опыт подтверждает, а как это на самом деле работает - вторично. Возможно, с нашего уровня развития это вообще нельзя изучить.
Приведу несколько своих примеров. Про этот канал я уже писал 2,5 года назад. Просто 2 публикации в день в течении нескольких лет и этот канал читают тысячи людей. Когда родился первый ребёнок, я не понимал, как вытянуть ещё больше. Но мне хотелось детей. В итоге жду сейчас четвертого. Всё само как-то устраивается потихонечку.
Начал строить дом вообще ничего не понимая и не зная. Косяков было море, крышу переделывал полностью (неправильно рассчитали стропильную систему). Какие только проблемы я не решал: потёкший котёл, постоянная влага в подполе, неправильная вентиляция, замёрзший ввод воды и т.д. Всё и не упомнишь уже. Тем не менее, шаг за шагом всё получилось. Дом достроен, а я параллельно освоил ещё одну профессию. Работал на стройке прорабом и технадзором для 5-ти разных бригад.
С воспитанием детей и семейной жизнью то же самое. Потихоньку изучаешь материалы, общаешься со специалистами, посещаешь тематические мероприятия. И все проблемы решаются, дела налаживаются, результат приходит.
Медицина - такая же история. Я сейчас прохожу новое лечение своей спины. Наконец-то удалось найти причину болей, поставить нормальный диагноз. Просто потихонечку крутил в голове мысли на эту тему, делал тут заметки. Одна из заметок и помогла. Там дали ссылку на канал Епифанова (на самом деле шарлатан), но через него я попал на настоящего врача и дела начали налаживаться. Кто много мается болями в спине, обратите внимание на заболевание миофасциальный синдром. Им много кто страдает, но врачи почему-то очень мало про него знают и почти не ставят такой диагноз.
В общем, так во всём: в работе, личных делах, в обучении и т.д. Просто сгружаешь в голову информацию и потихоньку обдумываешь, делаешь небольшие шажки, но регулярно. В этом сильно мешает различное ютубовское развлекалово. Это пустышка, которой люди забивают своё время, а некоторые вообще всё время. Я бью себя по руками и постоянно ограничиваю просмотр бесполезных вещей. Если надо отдохнуть и расслабиться, провожу время с детьми или гуляю.
Если вам интересно, могу каждый из перечисленных примеров подробно раскрыть отдельной заметкой. Пишите об этом и ставьте реакцию к посту, чтобы я понимал, писать или нет.
#мысли
{kind=link}
Когда вы настраиваете VPN, встаёт вопрос выбора размера MTU (maximum transmission unit) внутри туннеля. Это размер полезного блока с данными в одном пакете. Как известно, в сетевом пакете часть информации уходит для служебной информации в заголовках. Различные технологии VPN используют разный объём служебных заголовков. А если VPN пущен поверх другого VPN канала, то этот вопрос встаёт особенно остро.
Если ошибиться с размером MTU, то пакеты начнут разбиваться на несколько, чтобы передать полезный блок с данными. Это очень сильно снижает скорость передачи данных. Минимум в 2 раза, но на деле гораздо больше.
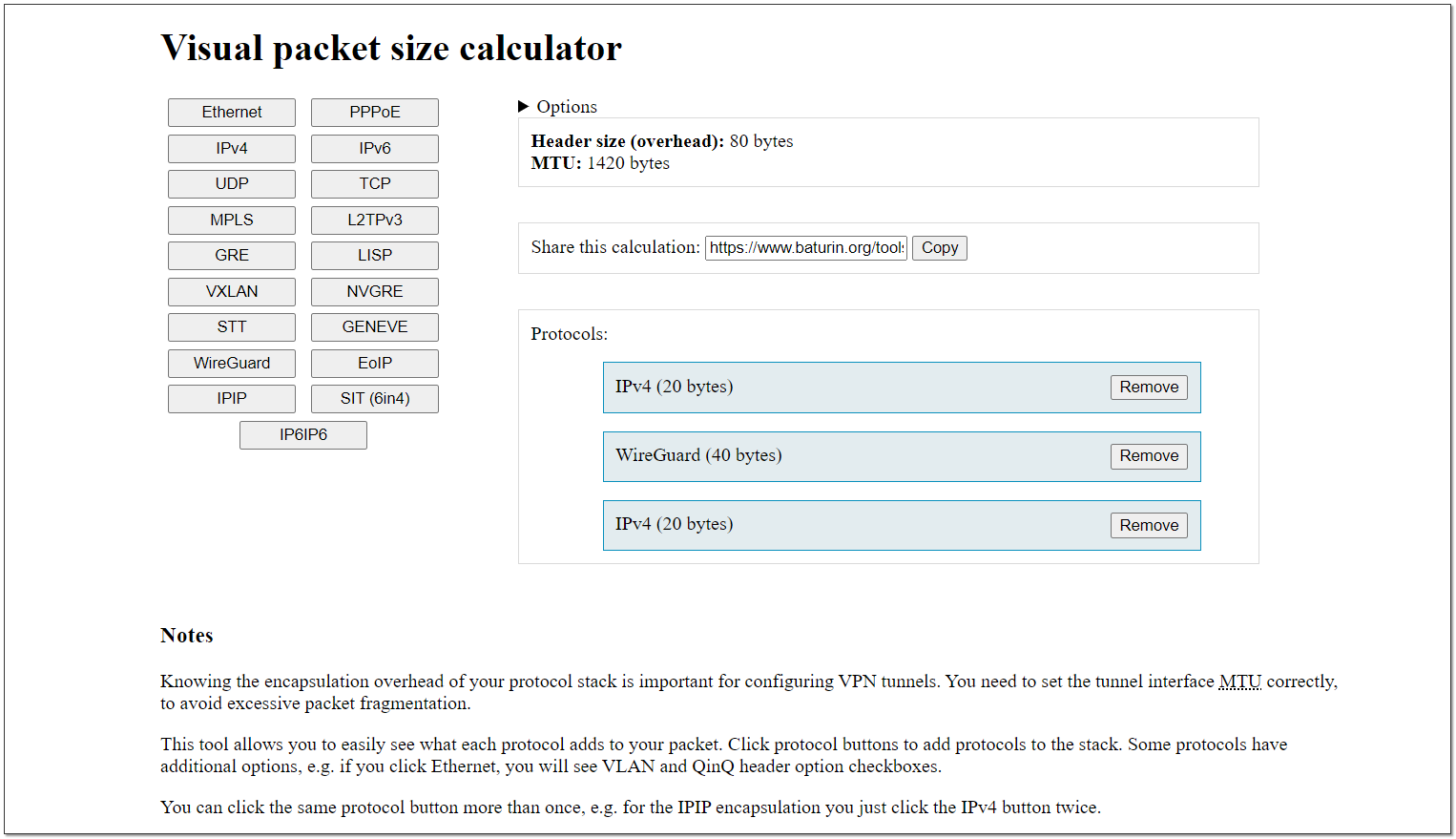
Правильно выбрать размер MTU можно с помощью готового калькулятора - Visual packet size calculator. Его автор, кстати, Даниил Батурин, который иногда ведёт бесплатные вебинары Rebrain, которые я периодически рекламирую. Рекомендую послушать, интересно.
К сожалению, в калькуляторе нет OpenVPN. И я как-то сходу не смог найти информацию, сколько места занимают служебные заголовки этого протокола. Покажу пример для WireGuard, если я всё правильно понимаю. Если ошибаюсь, прошу поправить.
Мы устанавливаем туннель WireGuard, чтобы гонять по нему ipv4 трафик. Идём в калькулятор и выстраиваем там цепочку:
IPv4 (20 bytes) ⇨ WireGuard (40 bytes) ⇨ IPv4 (20 bytes)
Имея на родительском интерфейсе MTU 1500, внутри туннеля нам необходимо установить его 1420. Если не ошибаюсь, это как раз значение по умолчанию для WireGuard.
Тема MTU довольно сложная. Если вы не сетевой инженер и специально ей не интересовались, то вникнуть непросто. На практике я сталкивался с подобными проблемами. Решал их в меру своих сил и способностей - просто уменьшал MTU до некоторых значений, когда проблем пропадала. Если вы не разбираетесь детально в этой теме, рекомендую поступать так же. И важно знать, что если у вас PPPoE соединение от провайдера, то оно дополнительно 8 байт занимает на заголовки. Часто дефолтные значения различного софта не учитывают этого нюанса и нужно будет поправить вручную.
#vpn #network
Если ошибиться с размером MTU, то пакеты начнут разбиваться на несколько, чтобы передать полезный блок с данными. Это очень сильно снижает скорость передачи данных. Минимум в 2 раза, но на деле гораздо больше.
Правильно выбрать размер MTU можно с помощью готового калькулятора - Visual packet size calculator. Его автор, кстати, Даниил Батурин, который иногда ведёт бесплатные вебинары Rebrain, которые я периодически рекламирую. Рекомендую послушать, интересно.
К сожалению, в калькуляторе нет OpenVPN. И я как-то сходу не смог найти информацию, сколько места занимают служебные заголовки этого протокола. Покажу пример для WireGuard, если я всё правильно понимаю. Если ошибаюсь, прошу поправить.
Мы устанавливаем туннель WireGuard, чтобы гонять по нему ipv4 трафик. Идём в калькулятор и выстраиваем там цепочку:
IPv4 (20 bytes) ⇨ WireGuard (40 bytes) ⇨ IPv4 (20 bytes)
Имея на родительском интерфейсе MTU 1500, внутри туннеля нам необходимо установить его 1420. Если не ошибаюсь, это как раз значение по умолчанию для WireGuard.
Тема MTU довольно сложная. Если вы не сетевой инженер и специально ей не интересовались, то вникнуть непросто. На практике я сталкивался с подобными проблемами. Решал их в меру своих сил и способностей - просто уменьшал MTU до некоторых значений, когда проблем пропадала. Если вы не разбираетесь детально в этой теме, рекомендую поступать так же. И важно знать, что если у вас PPPoE соединение от провайдера, то оно дополнительно 8 байт занимает на заголовки. Часто дефолтные значения различного софта не учитывают этого нюанса и нужно будет поправить вручную.
#vpn #network
{kind=link}
Несколько полезных команд из использования GIT. Накопилось на небольшую заметку, поэтому решил опубликовать. Тут ничего особенного, если это можно сказать про GIT. Реально, это довольно сложная система с кучей всяких параметров, ситуаций, вариантов действия и т.д. Эта система контроля версий, про которую можно книги писать. И, наверное, пишут (я не читал).
Простая команда, про которую я узнал случайно. Она объединяет добавление изменённых файлов и коммит. Удобно и пригодится всем:
Заменяет:
Можно сразу алиас сделать, чтобы ещё упростить команду:
Если регулярно используете git, то можно добавить в алиасы наиболее часто используемые команды. Status так точно можно добавить:
Если чего-то понаделали локально в репозитории, хотите сохранить эти изменения, но не хотите пушить их куда-то, то можно воспользоваться командой stash. Она удалит все изменения в файлах, но сохранит их отдельно, чтобы можно было вернуться к ним, если понадобится.
Файлы вернулись в первоначальный вид, а все изменения сохранены отдельно. Если захотите вернуть их, то выполните:
Все изменения вернулись в файлы. У stash много дополнительных параметров. Если будете пользоваться, то почитайте.
Если посмотреть изменения большого репозитория, то в консоли всё это не очень читаемо, так как много информации. Можно немного упростить:
Так читается намного лучше.
📌 Теперь краткая инструкция, как перенести репозиторий из одного удалённого сервера в другой.
Перенесли полностью репозиторий со всеми коммитами на новое место и настроили на него локальный репозиторий. Последнее можно не делать, если вам это не нужно. Вот подробная инструкция github по теме дубликатов репозиториев.
#git
Простая команда, про которую я узнал случайно. Она объединяет добавление изменённых файлов и коммит. Удобно и пригодится всем:
# git commit -am "changed two files"Заменяет:
# git add .# git commit -m "changed two files"Можно сразу алиас сделать, чтобы ещё упростить команду:
# git config --global alias.cam "commit -am" # git cam "changed two files"Если регулярно используете git, то можно добавить в алиасы наиболее часто используемые команды. Status так точно можно добавить:
# git config --global alias.st status # git stЕсли чего-то понаделали локально в репозитории, хотите сохранить эти изменения, но не хотите пушить их куда-то, то можно воспользоваться командой stash. Она удалит все изменения в файлах, но сохранит их отдельно, чтобы можно было вернуться к ним, если понадобится.
# git stashФайлы вернулись в первоначальный вид, а все изменения сохранены отдельно. Если захотите вернуть их, то выполните:
# git stash popВсе изменения вернулись в файлы. У stash много дополнительных параметров. Если будете пользоваться, то почитайте.
Если посмотреть изменения большого репозитория, то в консоли всё это не очень читаемо, так как много информации. Можно немного упростить:
# git log --onelineТак читается намного лучше.
📌 Теперь краткая инструкция, как перенести репозиторий из одного удалённого сервера в другой.
# git clone --bare git@server01.local:testrepo.git# cd testrepo.git && git fetch origin# git remote add new-origin git@server02.local:testrepo.git# git push --mirror new-origin# git remote rm origin && git remote rename new-origin originПеренесли полностью репозиторий со всеми коммитами на новое место и настроили на него локальный репозиторий. Последнее можно не делать, если вам это не нужно. Вот подробная инструкция github по теме дубликатов репозиториев.
#git
GitHub Docs
Duplicating a repository - GitHub Docs
To maintain a mirror of a repository without forking it, you can run a special clone command, then mirror-push to the new repository.
Недавно была публикация про централизованную установку дистрибутивов по сети с помощью технологии PXE. В комментариях посоветовали интересный проект - LTSP (Linux Terminal Server Project). Это софт из этой же оперы, только с упором на простое создание собственных преднастроенных образов. Проект open source, так что можно бесплатно пользоваться. При этом он старый и известный продукт, который одно время продвигал AltLinux. Много статей нашёл, правда довольно старых. Возможно уже отказались от него.
LTSP поддерживает 2 режима работы: тонкий и толстый клиенты. Тонкий полностью грузит ОС по сети. Вся работа выполняется на терминальном сервере. Толстый клиент устанавливает систему на свой жёсткий диск, а с терминала подключает пользовательские файлы и программы.
В принципе, LTSP ничего особенного не делает и всю его функциональность можно реализовать самостоятельно: поднять tftp сервер, подготовить загрузочный образ, настроить его загрузку через dhcp, положить систему и пользовательские файлы на nfs сервер, подключать их на системе, которая грузится по сети. LTSP всё это упрощает, предоставляя инструменты для управления.
После загрузки системы на тонком клиенте, пользователю необходимо пройти аутентификацию по SSH, ему пробрасываются иксы. Он попадает в своё рабочее окружение. В случае толстого клиента ему подключается его домашний каталог и затем запускается окружение.
Установить и настроить LTSP сервер относительно просто, особенно если есть понимание работы используемых технологий. В качестве DHCP сервера не обязательно должен выступать линуксовый сервер. Подойдёт и Mikrotik. Есть репозитории для Ubuntu и Debian. Вот пример установки на Debian 12:
Дальше необходимо подготовить клиентскую систему. Тут есть три варианта:
1️⃣ Использовать локальную систему как эталон для загрузки клиентам.
2️⃣ Собрать свой raw образ виртуальной машины.
3️⃣ Выбрать отдельную директорию и там собирать необходимую систему, чрутясь туда с помощью chroot.
Мне видится третий вариант наиболее удобным. Я сам его использовал, когда настраивал подобное. Хотел пойти по этому пути и показать его вам, но узнал, что в последней версии LTSP этот вариант признан устаревшим. Разработчики рекомендую использовать первый или второй вариант. Если хочется третий, то вот инструкция.
Полное руководство по настройке не уместить в заметке. Покажу только основные этапы, чтобы было понятно, как LTSP настраивается. Готовим образ для загрузки по сети на основе текущей системы:
В результате работы команды получите образ системы /srv/ltsp/images/x86_64.img и образы для tftp в /srv/tftp/ltsp/x86_64. Добавляем в эти образы iPXE меню:
Настраиваем NFS сервер для экспорта созданных образов:
Эта команда просто добавляет в /etc/exports.d настройки:
Далее вы либо локально, либо на внешнем dhcp сервере настраиваете tftp сервер и путь к загрузке образа. LTSP поддерживает загрузку через UEFI. В зависимости от того, какие клиенты у вас будут, выбираете образ для загрузки.
LTSP хранит все свои настройки в конфигурационном файле, которые используются во время генерации образа. В этих настройках, к примеру, можно указать автологин для каких-то MAC адресов, сетевые настройки, hostname и т.д. После изменения этих настроек, загрузочные образы надо пересобирать.
В общем, LTSP простая и надёжная система для создания и управления загрузочными образами. По своей сути это набор shell и немного python скриптов.
⇨ Сайт / Исходники
#pxe
LTSP поддерживает 2 режима работы: тонкий и толстый клиенты. Тонкий полностью грузит ОС по сети. Вся работа выполняется на терминальном сервере. Толстый клиент устанавливает систему на свой жёсткий диск, а с терминала подключает пользовательские файлы и программы.
В принципе, LTSP ничего особенного не делает и всю его функциональность можно реализовать самостоятельно: поднять tftp сервер, подготовить загрузочный образ, настроить его загрузку через dhcp, положить систему и пользовательские файлы на nfs сервер, подключать их на системе, которая грузится по сети. LTSP всё это упрощает, предоставляя инструменты для управления.
После загрузки системы на тонком клиенте, пользователю необходимо пройти аутентификацию по SSH, ему пробрасываются иксы. Он попадает в своё рабочее окружение. В случае толстого клиента ему подключается его домашний каталог и затем запускается окружение.
Установить и настроить LTSP сервер относительно просто, особенно если есть понимание работы используемых технологий. В качестве DHCP сервера не обязательно должен выступать линуксовый сервер. Подойдёт и Mikrotik. Есть репозитории для Ubuntu и Debian. Вот пример установки на Debian 12:
# wget https://ltsp.org/misc/ltsp-ubuntu-ppa-focal.list -O /etc/apt/sources.list.d/ltsp-ubuntu-ppa-focal.list# wget https://ltsp.org/misc/ltsp_ubuntu_ppa.gpg -O /etc/apt/trusted.gpg.d/ltsp_ubuntu_ppa.gpg# apt update# apt install --install-recommends ltsp ltsp-binaries dnsmasq nfs-kernel-server openssh-server squashfs-tools ethtool net-tools epoptesДальше необходимо подготовить клиентскую систему. Тут есть три варианта:
1️⃣ Использовать локальную систему как эталон для загрузки клиентам.
2️⃣ Собрать свой raw образ виртуальной машины.
3️⃣ Выбрать отдельную директорию и там собирать необходимую систему, чрутясь туда с помощью chroot.
Мне видится третий вариант наиболее удобным. Я сам его использовал, когда настраивал подобное. Хотел пойти по этому пути и показать его вам, но узнал, что в последней версии LTSP этот вариант признан устаревшим. Разработчики рекомендую использовать первый или второй вариант. Если хочется третий, то вот инструкция.
Полное руководство по настройке не уместить в заметке. Покажу только основные этапы, чтобы было понятно, как LTSP настраивается. Готовим образ для загрузки по сети на основе текущей системы:
# ltsp image /# ltsp initrdВ результате работы команды получите образ системы /srv/ltsp/images/x86_64.img и образы для tftp в /srv/tftp/ltsp/x86_64. Добавляем в эти образы iPXE меню:
# ltsp ipxeНастраиваем NFS сервер для экспорта созданных образов:
# ltsp nfsЭта команда просто добавляет в /etc/exports.d настройки:
/srv/ltsp *(ro,async,crossmnt,no_subtree_check,no_root_squash,insecure)/srv/tftp/ltsp *(ro,async,crossmnt,no_subtree_check,no_root_squash,insecure)Далее вы либо локально, либо на внешнем dhcp сервере настраиваете tftp сервер и путь к загрузке образа. LTSP поддерживает загрузку через UEFI. В зависимости от того, какие клиенты у вас будут, выбираете образ для загрузки.
LTSP хранит все свои настройки в конфигурационном файле, которые используются во время генерации образа. В этих настройках, к примеру, можно указать автологин для каких-то MAC адресов, сетевые настройки, hostname и т.д. После изменения этих настроек, загрузочные образы надо пересобирать.
В общем, LTSP простая и надёжная система для создания и управления загрузочными образами. По своей сути это набор shell и немного python скриптов.
⇨ Сайт / Исходники
#pxe
{kind=link}
Вчера бился часа 3-4 над одной проблемой. Уже спать пора было ложиться, но не могу уснуть, когда не доделано дело. Не даст спокойно спать, а на следующий день всё равно придётся доделывать. Не могу бросить нерешённые задачи, даже если они не очень важные. Особенно, когда кажется, что ещё чуть-чуть и всё заработает.
Мне нужно было настроить aws-cli для работы со сторонними S3 сервисами. В целом, проблем особых нет. У Yandex.Cloud или Selectel есть для этого инструкции. Важная особенность в том, что эта утилита заточена на использование с сервисами AWS. Для подключения к сторонним сервисам есть консольный ключ
Мне нужно было настроить работу без этого ключа. Для этого нужно правильно настроить
Я пробовал и на локальном WSL под Ubuntu, и на виртуалке под Debian 12. Никак не получалось настроить. Не буду вас утомлять дальнейшем рассказом. Сразу скажу, в чём было дело. Есть параметр для файла credentials:
Но появился он не так давно. Версии aws-cli на обоих системах, что я настраивал, были старее, где этого параметра ещё не было. При этом утилита на него не ругалась. Я такого накрутил в настройках и переменных, что даже когда обновил утилиту до последней версии, не заработало.
Потом всё обнулил, начал с самого начала с новой версией и всё получилось. Поначалу даже мысли не было, что версия слишком старая. Обычно на неподдерживаемые параметры программы ругаются. А тут тишина. Тупо не принимает его, хоть ты что делай. Я уже не знал, что и думать. Всё перепробовал.
Вот описание настроек в документации. Тут и намека нет на версию, начиная с которой это поддерживается. В версии 2.9.19 не работает, в последней 2.13.39 - работает. Появилось это только в июле этого года в версии 2.13.0. А обсуждение этой фичи есть аж с 2015 года.
Обидно потерять столько времени на такой ерунде.
#s3
Мне нужно было настроить aws-cli для работы со сторонними S3 сервисами. В целом, проблем особых нет. У Yandex.Cloud или Selectel есть для этого инструкции. Важная особенность в том, что эта утилита заточена на использование с сервисами AWS. Для подключения к сторонним сервисам есть консольный ключ
--endpoint-url=https://s3.ru-1.storage.selcloud.ru. Это вариант для Selectel. Он работает нормально.Мне нужно было настроить работу без этого ключа. Для этого нужно правильно настроить
~/.aws/config и ~/.aws/credentials. Начал гуглить решение задачи. Наткнулся на множество вопросов, где люди спрашивают, как подобное настроить. Где-то есть инструкции, как это предположительно может работать, как обойти этот вопрос, например добавлением алиаса с уже настроенным эндпоинтом, чтобы его не набирать. Можно использовать переменные окружения типа export AWS_ENDPOINT_URL=https://s3.ru-1.storage.selcloud.ru, но у меня они почему-то никак не работали.Я пробовал и на локальном WSL под Ubuntu, и на виртуалке под Debian 12. Никак не получалось настроить. Не буду вас утомлять дальнейшем рассказом. Сразу скажу, в чём было дело. Есть параметр для файла credentials:
endpoint_url = https://s3.ru-1.storage.selcloud.ruНо появился он не так давно. Версии aws-cli на обоих системах, что я настраивал, были старее, где этого параметра ещё не было. При этом утилита на него не ругалась. Я такого накрутил в настройках и переменных, что даже когда обновил утилиту до последней версии, не заработало.
Потом всё обнулил, начал с самого начала с новой версией и всё получилось. Поначалу даже мысли не было, что версия слишком старая. Обычно на неподдерживаемые параметры программы ругаются. А тут тишина. Тупо не принимает его, хоть ты что делай. Я уже не знал, что и думать. Всё перепробовал.
Вот описание настроек в документации. Тут и намека нет на версию, начиная с которой это поддерживается. В версии 2.9.19 не работает, в последней 2.13.39 - работает. Появилось это только в июле этого года в версии 2.13.0. А обсуждение этой фичи есть аж с 2015 года.
Обидно потерять столько времени на такой ерунде.
#s3
{kind=link}
Хочу напомнить про 2 очень полезные утилиты Linux, с помощью которых удобно в скриптах делать проверки наличия подключенных и примонтированных блочных устройств и файловых систем. Речь пойдёт про findmnt и findfs.
Про первую я уже когда-то рассказывал. Findmnt удобна и полезна сама по себе, без привязки к скриптам. Просто запустите её и посмотрите вывод. Она выводит в консоль подробную информацию о всех точках монтирования. А ключ
А если в чём-то ошибётесь, то получите ошибку:
Findfs сама по себе ничего не выводит. Она умеет искать файловые системы по заданными параметрами В качестве аргумента принимает значение LABEL, UUID, PARTLABEL и PARTUUID. Например так:
Нашли файловую систему на /dev/sda2 с заданным UUID. При этом код выхода будет 0:
Если файловая система не будет найдена, код будет 1:
Соответственно, подобную проверку мы может использовать в скриптах перед тем, как выполнять какие-то действия. Это актуально для каких-нибудь бэкапов или синхронизаций на сетевых или внешних дисках. Делаем простую проверку, типа такой:
Вместо echo можно сразу выполнять какое-то действие. Оно будет выполнено, если указанный скрипту UUID подключен. То есть сам скрипт работает так:
И точно так же по аналогии можно сделать проверку точек монтирования с помощью findmnt:
Проверяем:
Внешнее хранилище для бэкапов не смонтировано, ничего не делаем. Очень важно делать такие проверки, когда копируете что-то на примонтированные устройства. Если запустить процесс копирования при отмонтированном устройстве, то вы просто забьёте весь диск локальной системы, так как все файлы польются на неё.
Я и сам с таким сталкивался, и много раз видел вопросы людей на тему того, что не могут понять, что происходит. Обычно это выглядит так. В момент бэкапа сетевой диск не был примонтирован и мы забили весь корень файлами. А потом в какой-то момент этот диск примонтировался и мы больше не видим те файлы, что были скопированы в точку монтирования в тот момент, когда там не было диска. Его надо отмонтировать и удалить локальные файлы. Если это сразу не просечёшь, то можно много времени потратить на поиск того, что занимает всё свободное место на разделе.
Так что назначайте метки внешним дискам, проверяйте их, делайте проверки монтирования сетевых дисков и т.д. Не выполняйте копирования и синхронизации без этих проверок. А то можно сильно удивиться из-за какой-нибудь неожиданной ошибки. Я реально сталкивался сам с этим не раз, пока не начал постоянно добавлять проверки. Вроде думаешь в локалке всё стабильно, сервера и сеть никто не дёргает, всё в одной стойке стоит. А потом оказалось, что после выключения электричества сервера поднялись не равномерно и сервер с бэкапами поднялся позже остальных. В итоге куда-то не примонтировался сетевой диск для бэкапов и они начали литься локально, пока там место не кончится.
#bash #script
Про первую я уже когда-то рассказывал. Findmnt удобна и полезна сама по себе, без привязки к скриптам. Просто запустите её и посмотрите вывод. Она выводит в консоль подробную информацию о всех точках монтирования. А ключ
-x ещё и позволяет проверить отредактированный файл fstab на наличие в нём ошибок. Рекомендую запомнить эту возможность и использовать:# findmnt -xSuccess, no errors or warnings detectedА если в чём-то ошибётесь, то получите ошибку:
# findmnt -x/mnt/backup [E] unreachable on boot required source: UUID=151ea24d-977a-412c-818f-0d374baa5012Findfs сама по себе ничего не выводит. Она умеет искать файловые системы по заданными параметрами В качестве аргумента принимает значение LABEL, UUID, PARTLABEL и PARTUUID. Например так:
# findfs "UUID=151ea24d-977a-412c-818f-0d374baa5013"/dev/sda2Нашли файловую систему на /dev/sda2 с заданным UUID. При этом код выхода будет 0:
# echo $?0Если файловая система не будет найдена, код будет 1:
# findfs "UUID=151ea24d-977a-412c-818f-0d374baa5012"findfs: unable to resolve 'UUID=151ea24d-977a-412c-818f-0d374baa5012'# echo $?1Соответственно, подобную проверку мы может использовать в скриптах перед тем, как выполнять какие-то действия. Это актуально для каких-нибудь бэкапов или синхронизаций на сетевых или внешних дисках. Делаем простую проверку, типа такой:
if findfs "UUID=$1" >/dev/null; then echo "$1 connected."elseecho "$1 not connected."fiВместо echo можно сразу выполнять какое-то действие. Оно будет выполнено, если указанный скрипту UUID подключен. То есть сам скрипт работает так:
# ./check-fs.sh 151ea24d-977a-412c-818f-0d374baa5013151ea24d-977a-412c-818f-0d374baa5013 connected.И точно так же по аналогии можно сделать проверку точек монтирования с помощью findmnt:
if findmnt -rno TARGET "$1" >/dev/null; then echo "$1 mounted."elseecho "$1 not mounted."fiПроверяем:
# ./check-mnt.sh /mnt/extbackup/mnt/extbackup not mounted.Внешнее хранилище для бэкапов не смонтировано, ничего не делаем. Очень важно делать такие проверки, когда копируете что-то на примонтированные устройства. Если запустить процесс копирования при отмонтированном устройстве, то вы просто забьёте весь диск локальной системы, так как все файлы польются на неё.
Я и сам с таким сталкивался, и много раз видел вопросы людей на тему того, что не могут понять, что происходит. Обычно это выглядит так. В момент бэкапа сетевой диск не был примонтирован и мы забили весь корень файлами. А потом в какой-то момент этот диск примонтировался и мы больше не видим те файлы, что были скопированы в точку монтирования в тот момент, когда там не было диска. Его надо отмонтировать и удалить локальные файлы. Если это сразу не просечёшь, то можно много времени потратить на поиск того, что занимает всё свободное место на разделе.
Так что назначайте метки внешним дискам, проверяйте их, делайте проверки монтирования сетевых дисков и т.д. Не выполняйте копирования и синхронизации без этих проверок. А то можно сильно удивиться из-за какой-нибудь неожиданной ошибки. Я реально сталкивался сам с этим не раз, пока не начал постоянно добавлять проверки. Вроде думаешь в локалке всё стабильно, сервера и сеть никто не дёргает, всё в одной стойке стоит. А потом оказалось, что после выключения электричества сервера поднялись не равномерно и сервер с бэкапами поднялся позже остальных. В итоге куда-то не примонтировался сетевой диск для бэкапов и они начали литься локально, пока там место не кончится.
#bash #script
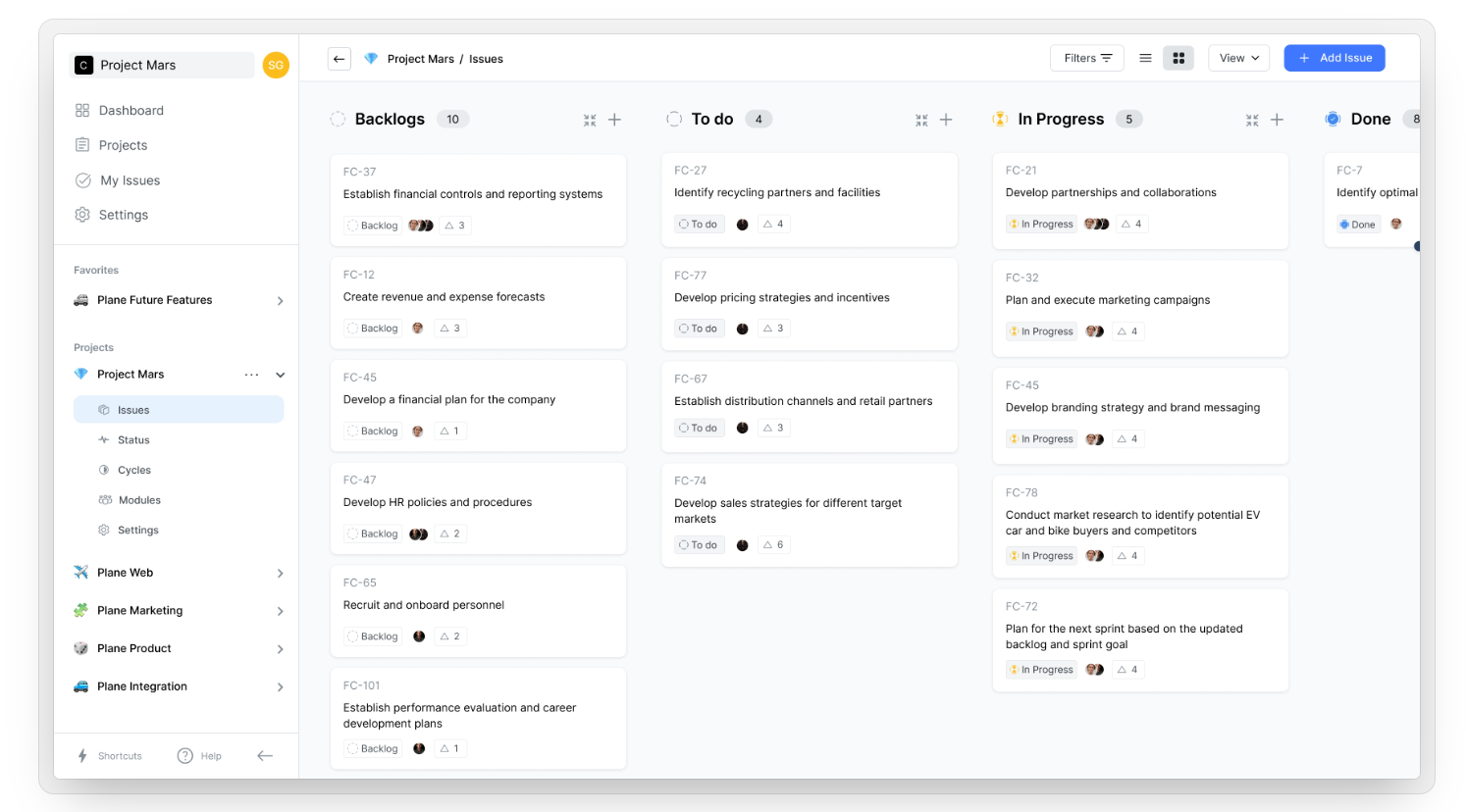
В заметке к системе управления проектам Taiga в комментариях порекомендовали продукт Plane.so. Я посмотрел, он у меня давно уже в todo листе стоит, ещё с лета. Решил развернуть его и попробовать.
Plane — open-source аналог Jira. Бэкенд написан на Python, фронт на JavaScript. Данные хранит в PostgreSQL, файлы в локальном Minio, кэш в Redis, веб сервер использует Nginx. В общем, стандартный современный стек. Всё это упаковано в Docker, так что установка в несколько простых действий:
И можно идти в веб интерфейс. Настройки можно поменять в
Система выглядит очень приятной, шустрой, удобной. Мне понравился интерфейс. Возможности там стандартные для такого рода продуктов. Создаёте проекты и ведёте их. Фиксируете проблемы, отслеживаете исправление, создаёте Kanban доски и т.д. Попробовать можно в бесплатном тарифном плане в облаке.
Монетизируется вся эта штука облачным сервисом и расширенной версией self-hosted установки. Так что это не поделка энтузиастов, а продукт коммерческой компании. Судя по звездам на гитхабе, Plane весьма популярна. Я так сходу в голове всё не припомню, что знаю, но навскидку мне понравилось Plane больше, чем всё, что я видел раньше. Но сразу уточню, что конкретно я никогда не работал с навороченными и большими установками, поэтому мне чем проще и лаконичнее интерфейс, тем лучше. Тот же YouTrack очень навороченный. Его употеешь настраивать, прежде чем запустишь. Он мне нравится, но функциональность там избыточная для небольших команд.
⇨ Сайт / Исходники
#управление_проектами
Plane — open-source аналог Jira. Бэкенд написан на Python, фронт на JavaScript. Данные хранит в PostgreSQL, файлы в локальном Minio, кэш в Redis, веб сервер использует Nginx. В общем, стандартный современный стек. Всё это упаковано в Docker, так что установка в несколько простых действий:
# git clone --depth 1 -b master https://github.com/makeplane/plane.git# cd plane# ./setup.sh# docker compose -f docker-compose-hub.yml upИ можно идти в веб интерфейс. Настройки можно поменять в
.env файлах перед запуском. По умолчанию учётка будет captain@plane.so / password123. Система выглядит очень приятной, шустрой, удобной. Мне понравился интерфейс. Возможности там стандартные для такого рода продуктов. Создаёте проекты и ведёте их. Фиксируете проблемы, отслеживаете исправление, создаёте Kanban доски и т.д. Попробовать можно в бесплатном тарифном плане в облаке.
Монетизируется вся эта штука облачным сервисом и расширенной версией self-hosted установки. Так что это не поделка энтузиастов, а продукт коммерческой компании. Судя по звездам на гитхабе, Plane весьма популярна. Я так сходу в голове всё не припомню, что знаю, но навскидку мне понравилось Plane больше, чем всё, что я видел раньше. Но сразу уточню, что конкретно я никогда не работал с навороченными и большими установками, поэтому мне чем проще и лаконичнее интерфейс, тем лучше. Тот же YouTrack очень навороченный. Его употеешь настраивать, прежде чем запустишь. Он мне нравится, но функциональность там избыточная для небольших команд.
⇨ Сайт / Исходники
#управление_проектами
{kind=link}
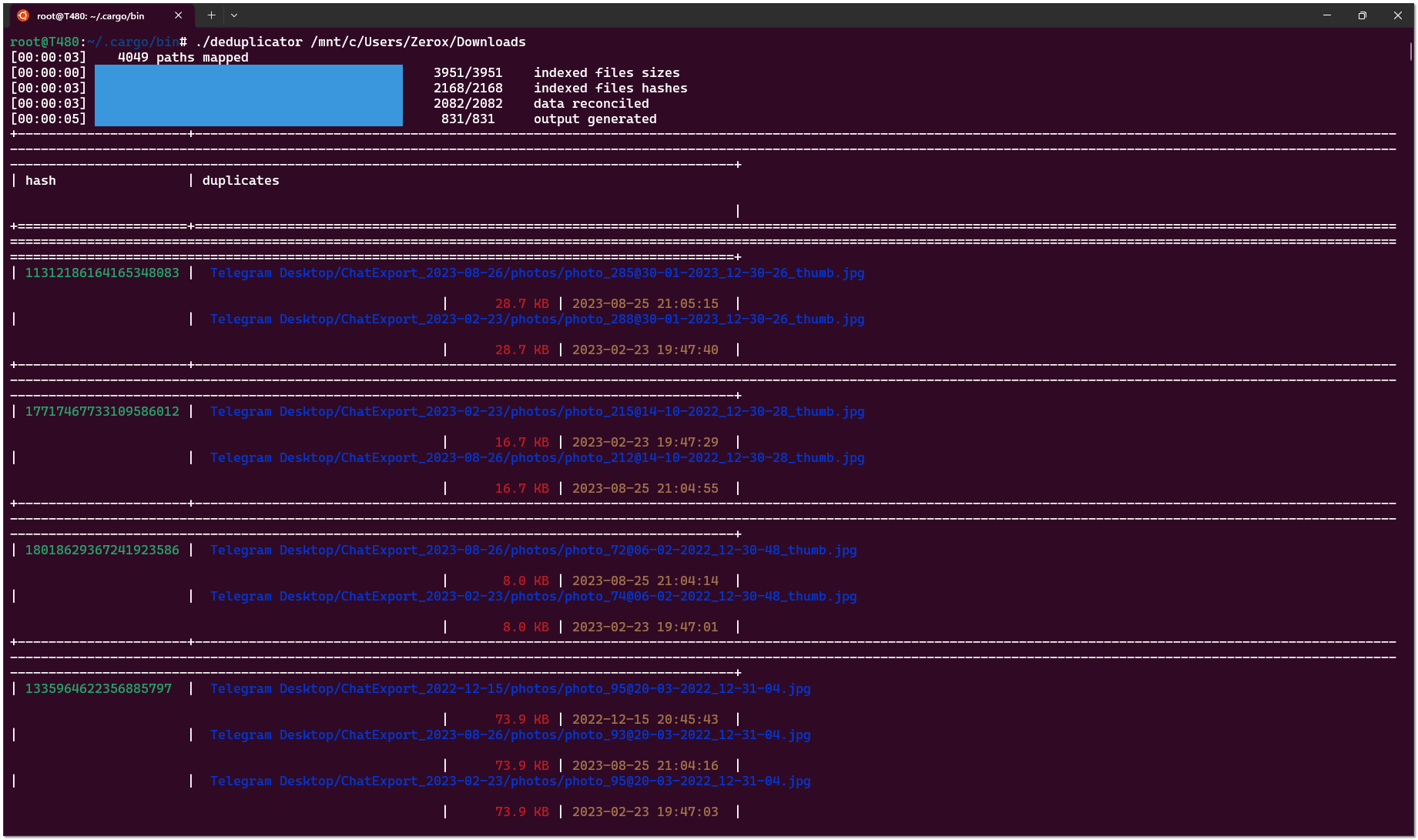
Мне неизвестны какие-то простые и эффективные способы поиска дубликатов файлов в Linux с использованием стандартного набора системных программ и утилит. Если встаёт такая задача, то приходится искать какие-то сторонние средства. Я предлагаю один из них - Deduplicator.
Deduplicator - небольшая open source программа, написанная на Rust. Написана в основном силами одного человека. Им же и поддерживается. Пока регулярно. Автор, судя по всему, любит свой продукт, поэтому старается обновлять.
Основная особенность Deduplicator - очень быстрая работа. Используется сравнение по размеру и хешам, полученных с помощью растовского алгоритма fxhash (впервые слышу о таком).
Использовать лучше самую свежую версию, потому что там появился вывод результата в json, плюс в одной из недавних версий стали выводиться полные пути дубликатов. До этого выводились обрезанные и было неудобно. Есть проблема с тем, что в репозитории собранная под Linux версия есть только годовой давности. Более свежие предлагается собирать самостоятельно. Не знаю, зачем так сделано, но я в итоге собрал сам, благо сделать это не трудно через растовый пакетный менеджер:
На выходе получаем одиночный бинарник, который можно скопировать на целевой сервер. Сразу скажу про ещё один момент, с которым столкнулся. Deduplicator хочет свежую версию glibc. Не понял точно, какую именно, но на Centos 7 не заработал. Не получилось прогнать на месте. В итоге проверку сделал на бэкап сервере. Там более свежая система - Debian 12, уже успел обновить. На Ubuntu 22 тоже завелась, почистил на своём ноуте дубликаты и домашнем медиасервере. Там дубликатов море было.
Вывод удобно направить сразу в текстовый файл и там уже смотреть:
Он будет в табличном виде. Удобен для ручного просмотра. А если нужна автоматизация, то есть вывод в
Сразу скажу, что на файловых серверах проверил дубликаты чисто для информации. Я не знаю, как системно решать проблемы с дубликатами и надо ли. Можно заменять дубликаты символьными ссылками, но в какой-то момент это может выйти боком.
⇨ Исходники
#fileserver
Deduplicator - небольшая open source программа, написанная на Rust. Написана в основном силами одного человека. Им же и поддерживается. Пока регулярно. Автор, судя по всему, любит свой продукт, поэтому старается обновлять.
Основная особенность Deduplicator - очень быстрая работа. Используется сравнение по размеру и хешам, полученных с помощью растовского алгоритма fxhash (впервые слышу о таком).
Использовать лучше самую свежую версию, потому что там появился вывод результата в json, плюс в одной из недавних версий стали выводиться полные пути дубликатов. До этого выводились обрезанные и было неудобно. Есть проблема с тем, что в репозитории собранная под Linux версия есть только годовой давности. Более свежие предлагается собирать самостоятельно. Не знаю, зачем так сделано, но я в итоге собрал сам, благо сделать это не трудно через растовый пакетный менеджер:
# apt install cargo# cargo install deduplicatorНа выходе получаем одиночный бинарник, который можно скопировать на целевой сервер. Сразу скажу про ещё один момент, с которым столкнулся. Deduplicator хочет свежую версию glibc. Не понял точно, какую именно, но на Centos 7 не заработал. Не получилось прогнать на месте. В итоге проверку сделал на бэкап сервере. Там более свежая система - Debian 12, уже успел обновить. На Ubuntu 22 тоже завелась, почистил на своём ноуте дубликаты и домашнем медиасервере. Там дубликатов море было.
Вывод удобно направить сразу в текстовый файл и там уже смотреть:
# ./deduplicator /mnt/backup/design > deduplicator.txtОн будет в табличном виде. Удобен для ручного просмотра. А если нужна автоматизация, то есть вывод в
--json с помощью соответствующего ключа.Сразу скажу, что на файловых серверах проверил дубликаты чисто для информации. Я не знаю, как системно решать проблемы с дубликатами и надо ли. Можно заменять дубликаты символьными ссылками, но в какой-то момент это может выйти боком.
⇨ Исходники
#fileserver
{kind=link}
Вчера вечером проскочила интересная новость на opennet. Я их обычно не комментирую, если они напрямую не касаются меня. В данном случае это не так. Компания Nextcloud GmbH объявила о присоединении почтового клиента Roundcube. Я этот веб клиент использую по умолчанию для всех настроенных почтовых серверов последние лет 10. Может даже больше. До этого пользовался Squirrelmail. Roundcube один из самых популярных, если не самый популярный, автономный веб клиент для почтовых серверов.
Новость на Opennet:
⇨ https://www.opennet.ru/opennews/art.shtml?num=60197
Оригинал:
⇨ https://nextcloud.com/blog/open-source-email-pioneer-roundcube-comes-aboard-nextcloud/
Что по факту будет, пока не понятно. Заявляют, что веб клиент так и будет обособленным, развитие продолжится, команда останется и даже увеличится, слияния кодовых баз не будет. Тогда не понятно, зачем покупали. Надеюсь, что продукт получит новый виток развития, а не заглохнет, как конкурент собственной разработки Nextcloud Mail.
Я ещё почему обратил внимание и подсветил эту новость. В opennet показали недавние проблемы с безопасностью у Roundcube. Там регулярно находят критические уязвимости. Я очень не люблю оставлять веб почту в открытый доступ. Это всегда риск её компрометации. А если начинаешь ограничивать доступ, то сильно падает удобство использования.
Если в условном postfix и dovecot критические уязвимости я вообще не припоминаю, и их можно спокойно оставлять в открытом доступе, то с веб клиентами это не так. C Roundcube всё время приходится следить за обновлениями и своевременно обновлять. Если есть возможность, я закрываю доступ к веб почте либо vpn, либо basic_auth. Пользователям это не нравится. Иногда руководство в приказном порядке настаивает на открытом прямом доступе, принимая риски.
В общем, если у вас веб почта в открытом доступе, уделяйте ей пристальное внимание и по возможности изолируйте от остальных сервисов. Это прям реальная дыра в инфраструктуру. Почтовые сервера чаще всего компрометируют через веб клиенты.
#mailserver
Новость на Opennet:
⇨ https://www.opennet.ru/opennews/art.shtml?num=60197
Оригинал:
⇨ https://nextcloud.com/blog/open-source-email-pioneer-roundcube-comes-aboard-nextcloud/
Что по факту будет, пока не понятно. Заявляют, что веб клиент так и будет обособленным, развитие продолжится, команда останется и даже увеличится, слияния кодовых баз не будет. Тогда не понятно, зачем покупали. Надеюсь, что продукт получит новый виток развития, а не заглохнет, как конкурент собственной разработки Nextcloud Mail.
Я ещё почему обратил внимание и подсветил эту новость. В opennet показали недавние проблемы с безопасностью у Roundcube. Там регулярно находят критические уязвимости. Я очень не люблю оставлять веб почту в открытый доступ. Это всегда риск её компрометации. А если начинаешь ограничивать доступ, то сильно падает удобство использования.
Если в условном postfix и dovecot критические уязвимости я вообще не припоминаю, и их можно спокойно оставлять в открытом доступе, то с веб клиентами это не так. C Roundcube всё время приходится следить за обновлениями и своевременно обновлять. Если есть возможность, я закрываю доступ к веб почте либо vpn, либо basic_auth. Пользователям это не нравится. Иногда руководство в приказном порядке настаивает на открытом прямом доступе, принимая риски.
В общем, если у вас веб почта в открытом доступе, уделяйте ей пристальное внимание и по возможности изолируйте от остальных сервисов. Это прям реальная дыра в инфраструктуру. Почтовые сервера чаще всего компрометируют через веб клиенты.
#mailserver
{kind=link}
🔝 Очередной ТОП постов за прошедший месяц. Все самые популярные публикации можно почитать со соответствующему хэштэгу #топ.
Дабы не делать отдельную публикацию, хочу одну мысль донести тут. Чат к заметкам существует для того, чтобы дополнить, дать полезную информацию по теме заметки. Это делается не для того, чтобы поболтать, а чтобы дать дополнительную пользу читателям. Многие заметки из прошлого читают вместе с комментариями. Пустая болтовня в них только зря тратит время читателей.
У меня был отдельный чат для разговоров. Он вырос до нескольких тысяч пользователей, но я понял, что это не мой формат и продал его. Текущий чат к заметкам я не хочу превращать в болталку. Так что прошу использовать его по назначению.
📌 Больше всего просмотров:
◽️Случай на конференции с iftop (11700)
◽️Утилита CFSSL для управления собственным CA (10947)
◽️Прикольный мем про Linux (10776)
📌 Больше всего комментариев:
◽️Новый тип DNS записи - HTTPS (117)
◽️Заметка про замену IE для старых устройств (98)
◽️Бесплатный сервис для хранения 1024 ГБ (97)
📌 Больше всего пересылок:
◽️Ресурс с материалами по Mikrotk (541)
◽️Утилита CFSSL для управления собственным CA (277)
◽️Универсальный ISO образ для установки от netboot.xyz (296)
◽️Статический кэш средствами Nginx (236)
📌 Больше всего реакций:
◽️Заметка про продуктивность с личными примерами (312)
◽️Прикольный мем про Linux (261)
◽️Инфантильность в IT (250)
◽️Ресурс с материалами по Mikrotk (211)
◽️Особенности копирования в Linux с cp (185)
#топ
Дабы не делать отдельную публикацию, хочу одну мысль донести тут. Чат к заметкам существует для того, чтобы дополнить, дать полезную информацию по теме заметки. Это делается не для того, чтобы поболтать, а чтобы дать дополнительную пользу читателям. Многие заметки из прошлого читают вместе с комментариями. Пустая болтовня в них только зря тратит время читателей.
У меня был отдельный чат для разговоров. Он вырос до нескольких тысяч пользователей, но я понял, что это не мой формат и продал его. Текущий чат к заметкам я не хочу превращать в болталку. Так что прошу использовать его по назначению.
📌 Больше всего просмотров:
◽️Случай на конференции с iftop (11700)
◽️Утилита CFSSL для управления собственным CA (10947)
◽️Прикольный мем про Linux (10776)
📌 Больше всего комментариев:
◽️Новый тип DNS записи - HTTPS (117)
◽️Заметка про замену IE для старых устройств (98)
◽️Бесплатный сервис для хранения 1024 ГБ (97)
📌 Больше всего пересылок:
◽️Ресурс с материалами по Mikrotk (541)
◽️Утилита CFSSL для управления собственным CA (277)
◽️Универсальный ISO образ для установки от netboot.xyz (296)
◽️Статический кэш средствами Nginx (236)
📌 Больше всего реакций:
◽️Заметка про продуктивность с личными примерами (312)
◽️Прикольный мем про Linux (261)
◽️Инфантильность в IT (250)
◽️Ресурс с материалами по Mikrotk (211)
◽️Особенности копирования в Linux с cp (185)
#топ
▶️ Недавно вышел необычный сериал по кибербезопасности под названием «Невидимая война». Я и на хабре видел анонс, и тут в комментариях давали ссылку. В нём собраны некоторые истории об угрозах, озвученные довольно известными в индустрии людьми. Да и не только. Там и депутаты, криминалисты, какие-то прочие личности засветились. Больше всего там Кибердеда (Масалович) будет.
Я посмотрел первые две серии. Не могу сказать, что он мне прям понравился. Досматривать не стал. Сделан неплохо, атмосферно. Может для технически несильно подкованной аудитории будет интересно. Но мне показалось повествование каким-то размытым, неконкретным, в основном состоящим из общих слов. В общем, рассказали всё то, что я и так знаю и понимаю. Поэтому интереса особо не было.
Делюсь с вами, может кому-то понравится в выходные посмотреть необычное тематическое видео. Это документальный сериал с художественными вставками. Как я уже сказал, качество исполнения неплохое, так что на любителя.
⇨ Трейлер
⇨ Невидимая война. Серия 1. Что такое кибербезопасность?
⇨ Невидимая война. Серия 2. Кто такие хакеры?
⇨ Невидимая война. Серия 3. Методы работы киберпреступников и киберзащитников.
⇨ Невидимая война. Серия 4. Виды шпионских атак
⇨ Невидимая война. Серия 5. Финансовые киберпреступления и безопасность детей в киберпространстве.
⇨ Невидимая война. Серия 6. Контроль развития нейросетей.
#видео
Я посмотрел первые две серии. Не могу сказать, что он мне прям понравился. Досматривать не стал. Сделан неплохо, атмосферно. Может для технически несильно подкованной аудитории будет интересно. Но мне показалось повествование каким-то размытым, неконкретным, в основном состоящим из общих слов. В общем, рассказали всё то, что я и так знаю и понимаю. Поэтому интереса особо не было.
Делюсь с вами, может кому-то понравится в выходные посмотреть необычное тематическое видео. Это документальный сериал с художественными вставками. Как я уже сказал, качество исполнения неплохое, так что на любителя.
⇨ Трейлер
⇨ Невидимая война. Серия 1. Что такое кибербезопасность?
⇨ Невидимая война. Серия 2. Кто такие хакеры?
⇨ Невидимая война. Серия 3. Методы работы киберпреступников и киберзащитников.
⇨ Невидимая война. Серия 4. Виды шпионских атак
⇨ Невидимая война. Серия 5. Финансовые киберпреступления и безопасность детей в киберпространстве.
⇨ Невидимая война. Серия 6. Контроль развития нейросетей.
#видео
{kind=link}