
Я на днях затрагивал тему, где нужно было держать в идентичном виде несколько веб серверов. Есть много решений, которые позволяют синхронизировать файлы в режиме онлайн или почти онлайн, так как на самом деле не всегда нужно синхронизировать каталоги в тот же момент, как они изменились. Можно это делать и с периодичностью в 1-2 минуты.
Одним из самых простых и эффективных решений по синхронизации файлов практически в режиме реального времени - Lsyncd. Он работает на базе rsync, есть в базовых репозиториях большинства дистрибутивов. Имеет стандартные конфигурационные файлы и небольшой набор базовых настроек. Работает на базе подсистемы ядра inotify (Linux) или fsevents (MacOS).
Сразу сделаю важную ремарку. С помощью Lsyncd и других подобных утилит можно гарантированно настроить только одностороннюю онлайн синхронизацию. Это архитектурное ограничение и в рамках синхронизации сырых файлов не имеет простого решения, если не использовать специализированный софт на обоих устройствах. Допустим, вы синхронизируете большой файл с источника на приёмник. Приёмник не знает ничего об этом файле и как только он появится, будет пытаться его тоже синхронизировать в обратную сторону, если синхронизация двусторонняя. В итоге файл побьётся и будет испорчен с обоих сторон. Я рассмотрю на этой неделе также софт для двусторонней синхронизации. Самое надёжное решение для этого - DRBD, которое я уже описывал и использовал.
Покажу сразу на примере, как Lsyncd настраивается и работает. Синхронизировать каталоги будем между двумя серверами по SSH.
Устанавливаем Lsyncd:
Он автоматически подтянет за собой rsync. На сервере приёмнике нужно будет rsync установить отдельно:
Копировать файлы будем по SSH, так что источник должен ходить на приёмник с настроенной аутентификацией по ключам. Не буду на этом останавливаться, настройка стандартная. Пакет почему-то не создал никаких каталогов и конфигов. Утилита по старинке использует для запуска скрипты инициализации init.d, так что просто заглянул в
Настроил синхронизацию директории
Теперь можете положить файл в директорию
По своей сути Lsyncd это удобная обёртка вокруг rsync, которая позволяет быстро настроить нужную конфигурацию и запустить по ней синхронизацию в режиме службы по событиям от inotify. Это отличное решение для поддержания каталогов с сотнями тысяч и миллионов файлов. Лучше я даже не знаю.
⇨ Сайт / Исходники
#rsync
Одним из самых простых и эффективных решений по синхронизации файлов практически в режиме реального времени - Lsyncd. Он работает на базе rsync, есть в базовых репозиториях большинства дистрибутивов. Имеет стандартные конфигурационные файлы и небольшой набор базовых настроек. Работает на базе подсистемы ядра inotify (Linux) или fsevents (MacOS).
Сразу сделаю важную ремарку. С помощью Lsyncd и других подобных утилит можно гарантированно настроить только одностороннюю онлайн синхронизацию. Это архитектурное ограничение и в рамках синхронизации сырых файлов не имеет простого решения, если не использовать специализированный софт на обоих устройствах. Допустим, вы синхронизируете большой файл с источника на приёмник. Приёмник не знает ничего об этом файле и как только он появится, будет пытаться его тоже синхронизировать в обратную сторону, если синхронизация двусторонняя. В итоге файл побьётся и будет испорчен с обоих сторон. Я рассмотрю на этой неделе также софт для двусторонней синхронизации. Самое надёжное решение для этого - DRBD, которое я уже описывал и использовал.
Покажу сразу на примере, как Lsyncd настраивается и работает. Синхронизировать каталоги будем между двумя серверами по SSH.
Устанавливаем Lsyncd:
# apt install lsyncd Он автоматически подтянет за собой rsync. На сервере приёмнике нужно будет rsync установить отдельно:
# apt install rsyncКопировать файлы будем по SSH, так что источник должен ходить на приёмник с настроенной аутентификацией по ключам. Не буду на этом останавливаться, настройка стандартная. Пакет почему-то не создал никаких каталогов и конфигов. Утилита по старинке использует для запуска скрипты инициализации init.d, так что просто заглянул в
/etc/init.d/lsyncd и увидел, что конфиг должен быть в /etc/lsyncd/lsyncd.conf.lua. Создал каталог и файл конфигурации следующего содержания:settings { logfile = "/var/log/lsyncd.log", statusFile = "/var/log/lsyncd.stat", statusInterval = 5, insist = true, nodaemon = false,}sync { default.rsyncssh, source="/mnt/sync", host = "syncuser@1.2.3.4", targetdir = "/mnt/sync", ssh = { port = 22777 }}Настроил синхронизацию директории
/mnt/sync с локального сервера на удалённый 1.2.3.4. Сразу для примера показал, как указать нестандартный порт SSH. В данном случае 22777. Примерно так же можно передать какие-то ключи rsync:rsync = {compress = true,archive = true,_extra = {"--bwlimit=50000"}}Теперь можете положить файл в директорию
/mnt/sync. Через 2-3 секунды он приедет на приёмник. Информация о всех передачах отражается в log файле. По своей сути Lsyncd это удобная обёртка вокруг rsync, которая позволяет быстро настроить нужную конфигурацию и запустить по ней синхронизацию в режиме службы по событиям от inotify. Это отличное решение для поддержания каталогов с сотнями тысяч и миллионов файлов. Лучше я даже не знаю.
⇨ Сайт / Исходники
#rsync
{kind=link}
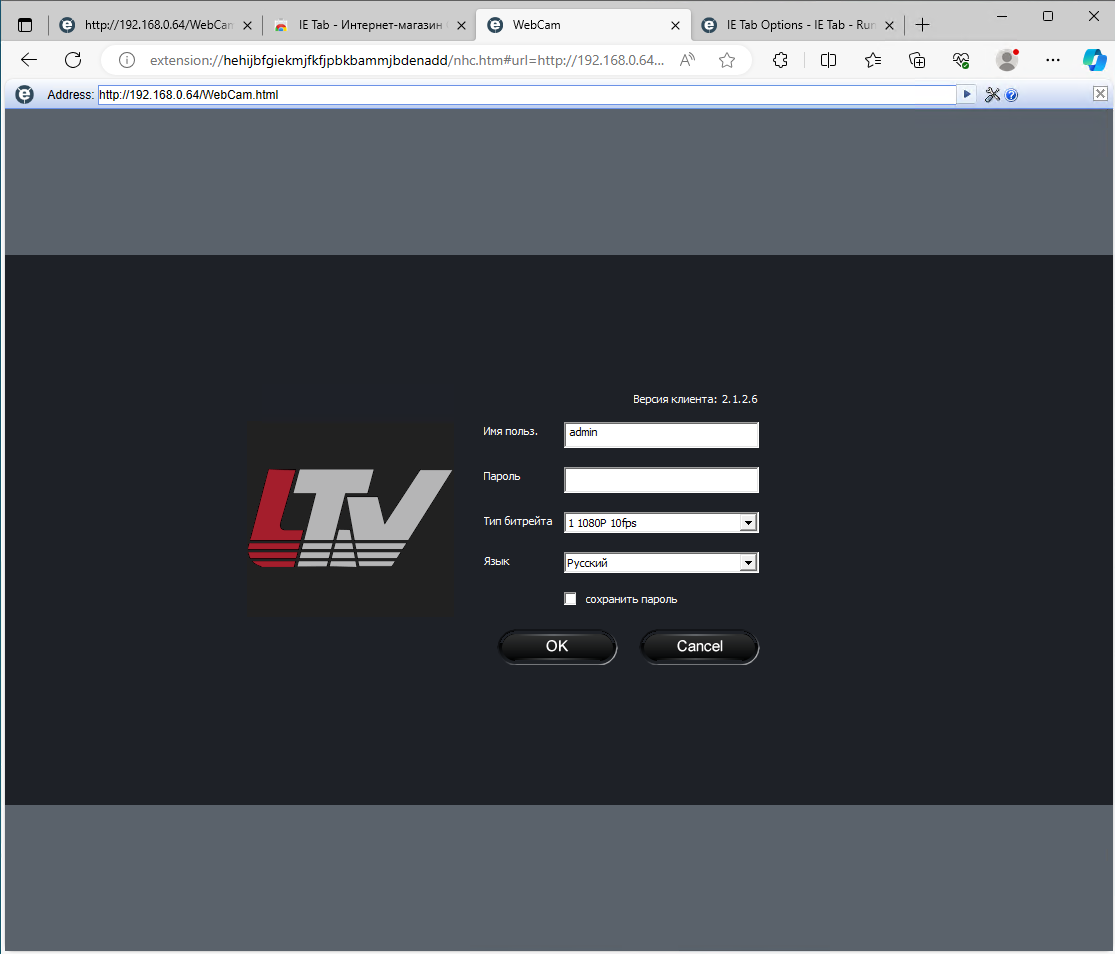
Понадобилось зайти на старую камеру LTV, которая просит установить какой-то плагин при входе по IP адресу и работает только в Internet Explorer, с которым в современных системах стало туго. У меня для всякого мусора есть отдельная виртуалка с виндой, но оттуда каким-то обновлением выпили IE.
Я знаю, что есть удобное решение таких проблем - плагин IE Tab для хромоподобных браузеров. Раньше я им уже пользовался. Решил воспользоваться и в этот раз. Без проблем поставил в Edge и с удивлением обнаружил, что это расширение стало платным. Он мне сообщил, что проработает в режиме trial 2 недели, а потом надо платить. Раньше он вроде бы бесплатным был.
При этом работает он отлично. Я без проблем зашёл на эту камеру. Всё работает, как и должно. Хотя live картинку не показал, но в настройки зашёл и сделал всё, что надо было.
А вы как сейчас выкручиваетесь в таких ситуациях?
Я знаю, что есть удобное решение таких проблем - плагин IE Tab для хромоподобных браузеров. Раньше я им уже пользовался. Решил воспользоваться и в этот раз. Без проблем поставил в Edge и с удивлением обнаружил, что это расширение стало платным. Он мне сообщил, что проработает в режиме trial 2 недели, а потом надо платить. Раньше он вроде бы бесплатным был.
При этом работает он отлично. Я без проблем зашёл на эту камеру. Всё работает, как и должно. Хотя live картинку не показал, но в настройки зашёл и сделал всё, что надо было.
А вы как сейчас выкручиваетесь в таких ситуациях?
{kind=link}
Продолжу тему синхронизации файлов. На этот раз расскажу про утилиту Unison, которая позволяет выполнять двухстороннюю синхронизацию, в отличие от Lsyncd, которая выполняет только одностороннюю.
Unison я знаю и использую очень давно. Статья про её использование написана в далёком 2015 году. Там ничего интересного нет, так как она планировалась как вводная для дальнейшего развития темы, но почему-то не срослось, хотя я помню, что тогда активно использовал её, поэтому и планировал написать. Это одна из старых статей, которую я написал вскоре после того, как с FreeBSD переехал в Linux.
🟢 Основные возможности Unison:
◽Кроссплатформенная программа. Поддерживает Linux, Windows, MacOS, FreeBSD и прочие *BSD. Соответственно, между ними возможна синхронизация.
◽Честная двухсторонняя синхронизация. Конфликтующие файлы обнаруживаются и отображаются.
◽Синхронизирует на уровне файлов как обычная пользовательская программа, не требует прав суперпользователя.
◽Для передачи больших файлов использует тот же подход, что и rsync, то есть передаёт только изменения, а не весь файл.
◽Работает как поверх SSH, так и напрямую по TCP (без шифрования, так что не рекомендуется использовать).
◽Использует такую же реализацию передачи данных, как и rsync. Насколько я понял, реализация написана самостоятельно, а не через использование готовой библиотеки, как в других похожих программах.
В Debian живёт в базовых репозиториях, поэтому установка очень простая:
Установить нужно на обе машины одну и ту же версию. А также настроить аутентификацию по SSH с помощью ключей в обе стороны.
Далее с любой машины тестируем подключение к другой:
Сразу показал пример с использованием нестандартного порта SSH. В данном случае я проверяю возможность синхронизации локального и удалённого каталога
Если всё ОК, то дальше можно пробовать запускать непосредственно синхронизацию:
При первой синхронизации вам выдадут некоторое предупреждение с информацией о синхронизации. А потом попросят подтвердить синхронизацию каждого файла. Понятное дело, что нам это не подходит.
После синхронизации в директории
Каталоги на обоих сторонах будут приведены к единому содержанию. Запускать Unison достаточно на каком-то одном хосте. По умолчанию для него нет готовой службы, так что настраивать запуск придётся вручную либо с помощью cron, либо с помощью systemd timers. В заметке как раз приведён пример, который хорошо подходит для ситуации с Unison.
Если на обоих хостах появится файл с одним и тем же именем, но разным содержанием, то синхронизирован он не будет. В результатах синхронизации будет отображено, что файл был пропущен.
Хорошее руководство по unison с примерами есть в arch wiki. А вот прямая ссылка на официальную документацию. У программы очень много возможностей. Например, можно указать, куда будут бэкапиться изменённые файлы. Работает примерно так же, как ключ
⇨ Исходники
#rsync
Unison я знаю и использую очень давно. Статья про её использование написана в далёком 2015 году. Там ничего интересного нет, так как она планировалась как вводная для дальнейшего развития темы, но почему-то не срослось, хотя я помню, что тогда активно использовал её, поэтому и планировал написать. Это одна из старых статей, которую я написал вскоре после того, как с FreeBSD переехал в Linux.
🟢 Основные возможности Unison:
◽Кроссплатформенная программа. Поддерживает Linux, Windows, MacOS, FreeBSD и прочие *BSD. Соответственно, между ними возможна синхронизация.
◽Честная двухсторонняя синхронизация. Конфликтующие файлы обнаруживаются и отображаются.
◽Синхронизирует на уровне файлов как обычная пользовательская программа, не требует прав суперпользователя.
◽Для передачи больших файлов использует тот же подход, что и rsync, то есть передаёт только изменения, а не весь файл.
◽Работает как поверх SSH, так и напрямую по TCP (без шифрования, так что не рекомендуется использовать).
◽Использует такую же реализацию передачи данных, как и rsync. Насколько я понял, реализация написана самостоятельно, а не через использование готовой библиотеки, как в других похожих программах.
В Debian живёт в базовых репозиториях, поэтому установка очень простая:
# apt install unisonУстановить нужно на обе машины одну и ту же версию. А также настроить аутентификацию по SSH с помощью ключей в обе стороны.
Далее с любой машины тестируем подключение к другой:
# unison -testServer /mnt/sync ssh://syncuser@1.2.3.4:22777//mnt/sync Unison 2.51.3 (ocaml 4.11.1): Contacting server...Connected [//1.2.3.4:22777//mnt/sync -> //debian11//mnt/sync]Сразу показал пример с использованием нестандартного порта SSH. В данном случае я проверяю возможность синхронизации локального и удалённого каталога
/mnt/sync. Если всё ОК, то дальше можно пробовать запускать непосредственно синхронизацию:
# unison /mnt/sync ssh://syncuser@1.2.3.4:22777//mnt/syncПри первой синхронизации вам выдадут некоторое предупреждение с информацией о синхронизации. А потом попросят подтвердить синхронизацию каждого файла. Понятное дело, что нам это не подходит.
После синхронизации в директории
~/.unison появится файл конфигурации default.prf, в котором можно настроить поведение программы при синхронизации. Чтобы вам не задавали никаких вопросов, достаточно добавить туда:auto=truebatch=trueКаталоги на обоих сторонах будут приведены к единому содержанию. Запускать Unison достаточно на каком-то одном хосте. По умолчанию для него нет готовой службы, так что настраивать запуск придётся вручную либо с помощью cron, либо с помощью systemd timers. В заметке как раз приведён пример, который хорошо подходит для ситуации с Unison.
Если на обоих хостах появится файл с одним и тем же именем, но разным содержанием, то синхронизирован он не будет. В результатах синхронизации будет отображено, что файл был пропущен.
Хорошее руководство по unison с примерами есть в arch wiki. А вот прямая ссылка на официальную документацию. У программы очень много возможностей. Например, можно указать, куда будут бэкапиться изменённые файлы. Работает примерно так же, как ключ
-backup у rsync, только настроек больше. ⇨ Исходники
#rsync
{kind=link}
Смотрите, какая прикольна штука есть для подключения по SSH из консоли - sshto. Это небольшой bash скрипт, который позволяет через псевдографическое меню управлять преднастроенными SSH подключениями. Хорошее решение для самодельного jumphost.
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
Ставим sshto:
Запускаем:
Видим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
~/.ssh/config и выводит список серверов оттуда в псевдографическое меню. Вот пример такого файла:#Host DUMMY #Moscow#Host server-number-one #First ServerHostName 1.2.3.4port 22777user rootHost server-number-two #Second serverHostName 4.3.2.1port 22888user username#Host DUMMY #Saint Petersburg#Host server-number-three #Third serverHostName 5.6.7.8port 22user user01Host server-number-four #Fourth serverHostName 9.8.7.6port 22user user02Ставим sshto:
# git clone https://github.com/vaniacer/sshto# cd sshto/# cp sshto /usr/bin/Запускаем:
# sshtoВидим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
{kind=link}
В рамках темы по синхронизации файлов расскажу про необычный инструмент на основе git - git-annex. Это система управления файлами без индексации содержимого. С помощью git индексируются только имена, пути файлов и хэш содержимого. Для использования необходимо понимание работы git. Эта система больше всего подойдёт для индивидуального или семейного хранения файлов в разных хранилищах.
Я не буду расписывать, как эта штука работает, так как она довольно заморочена, а сразу покажу на примере. Так будет понятнее. Программа есть под все популярные ОС, но под Windows всё ещё в бете, так что запускать лучше Linux версию в WSL. В Debian и Ubuntu ставим стандартно из базовой репы:
Переходим в директорию
Добавляем файлы в репу:
Все файлы превратились в символьные ссылки, а их содержимое уехало
Скопируем этот репозиторий на условный ноутбук, который будет периодически забирать нужные файлы с сервера и пушить туда какие-то свои новые или изменения старых. Для этого он должен ходить на сервер по SSH с аутентификацией по ключу.
На ноутбуке копируем репозиторий с сервера и сразу синхронизируем:
Мы получили на ноутбуке копию репозитория, но вместо файлов у нас битые ссылки. Так и должно быть. Если вы хотите синхронизировать все реальные файлы, то сделать это можно так:
А если только один файл, то так:
Когда у вас несколько устройств работают с репозиторием, то узнать, где физически находится файл можно так:
Вернёмся на сервер и добавим в него информацию о ноуте:
Теперь репозитории знают друг о друге. На ноутбук он был клонирован с сервера, а на сервер мы вручную добавили ноутбук. Добавим новый файл в репозиторий с ноутбука:
Проверим его местонахождение:
Он только на ноутбуке. Идём на сервер, делаем там синхронизацию и поверяем местонахождение файла:
Теперь он располагается в двух местах.
Надеюсь, у меня получилось хоть немного показать, как эта штука работает. У неё много настроек. Можно очень гибко указать какие файлы по весу, количеству копий, типу папок, имени, типу содержимого нужны в каждом репозитории. Есть преднастроенные группы: backup, archive, client, transfer. Например, можно принудительно скачивать все файлы при синхронизации:
Git-annex удобен для хранения нескольких копий файлов в разных репозиториях. Вы можете подключать внешние носители и периодически синхронизировать файлы с ними, обозвав каждый носитель своим именем. В репозитории будет храниться информация о том, где какой файл лежит и сколько копий файла имеется. Вся информация о всех файлах хранится в одном общем репозитории, а физически файлы могут располагаться выборочно в разных местах.
И не забываем, что у нас все преимущества git в виде версионирования. Более подробно о работе можно почитать в документации. На первый взгляд кажется, что система слишком сложная. Для тех, кто не знаком с git, да. Но я не раз видел восторженные отзывы о системе тех, кто в ней разобрался и активно пользуется.
⇨ Сайт / Обучалка
#git #fileserver
Я не буду расписывать, как эта штука работает, так как она довольно заморочена, а сразу покажу на примере. Так будет понятнее. Программа есть под все популярные ОС, но под Windows всё ещё в бете, так что запускать лучше Linux версию в WSL. В Debian и Ubuntu ставим стандартно из базовой репы:
# apt install git-annexПереходим в директорию
/mnt/annex, где хранятся какие-то файлы и инициализируем там репозиторий, пометив его как server:# git config --global user.email "root@serveradmin.ru"# git config --global user.name "Serveradmin"# git init .# git annex init 'server'Добавляем файлы в репу:
# git annex add .# git commit -m "Добавил новые файлы"Все файлы превратились в символьные ссылки, а их содержимое уехало
.git/annex/objects.Скопируем этот репозиторий на условный ноутбук, который будет периодически забирать нужные файлы с сервера и пушить туда какие-то свои новые или изменения старых. Для этого он должен ходить на сервер по SSH с аутентификацией по ключу.
На ноутбуке копируем репозиторий с сервера и сразу синхронизируем:
# git clone ssh://user@1.2.3.4/mnt/annex# git annex init 'notebook'# git annex syncМы получили на ноутбуке копию репозитория, но вместо файлов у нас битые ссылки. Так и должно быть. Если вы хотите синхронизировать все реальные файлы, то сделать это можно так:
# git annex get .А если только один файл, то так:
# git annex get docker-iptables.shКогда у вас несколько устройств работают с репозиторием, то узнать, где физически находится файл можно так:
# git annex whereis file.txtwhereis file.txt (2 copies) 01f4d93-480af476 -- server [origin] 13f223a-e75b6a69 -- notebook [here]Вернёмся на сервер и добавим в него информацию о ноуте:
# git remote add notebook ssh://user@4.3.2.1/mnt/annex# git annex syncТеперь репозитории знают друг о друге. На ноутбук он был клонирован с сервера, а на сервер мы вручную добавили ноутбук. Добавим новый файл в репозиторий с ноутбука:
# git annex add nout.txt# git commit -m "add nout.txt"Проверим его местонахождение:
# git annex whereis nout.txtwhereis nout.txt (1 copy) 637597c-3f54f8746 -- notebook [here]Он только на ноутбуке. Идём на сервер, делаем там синхронизацию и поверяем местонахождение файла:
# git annex sync# git annex get nout.txt# git annex whereis nout.txtwhereis nout.txt (2 copies) 6307597c-3f54f5ff8746 -- [notebook] edeab032-7091559a6ca4 -- server [here]Теперь он располагается в двух местах.
Надеюсь, у меня получилось хоть немного показать, как эта штука работает. У неё много настроек. Можно очень гибко указать какие файлы по весу, количеству копий, типу папок, имени, типу содержимого нужны в каждом репозитории. Есть преднастроенные группы: backup, archive, client, transfer. Например, можно принудительно скачивать все файлы при синхронизации:
# git annex sync --contentGit-annex удобен для хранения нескольких копий файлов в разных репозиториях. Вы можете подключать внешние носители и периодически синхронизировать файлы с ними, обозвав каждый носитель своим именем. В репозитории будет храниться информация о том, где какой файл лежит и сколько копий файла имеется. Вся информация о всех файлах хранится в одном общем репозитории, а физически файлы могут располагаться выборочно в разных местах.
И не забываем, что у нас все преимущества git в виде версионирования. Более подробно о работе можно почитать в документации. На первый взгляд кажется, что система слишком сложная. Для тех, кто не знаком с git, да. Но я не раз видел восторженные отзывы о системе тех, кто в ней разобрался и активно пользуется.
⇨ Сайт / Обучалка
#git #fileserver
{kind=link}
Вчера посмотрел новое видео на канале RomNero про open source сервис Planka. Я все видео у него смотрю, потому что интересно и полезно. Про Guacamole у него пару месяцев назад хорошее видео вышло.
Planka - очень близкий аналог Trello. Он пытается повторить как функциональность, так и внешний вид. И получается неплохо. Можете сами оценить в публичном Demo. Написана Planka на React (библиотека JavaScript).
Акцент на этом видео я сделал потому, что оно поучительно записано. Там внимание не только на самом сервисе, но и на том, как его запустить с помощью docker-compose, как дебажить ошибки. Автор разбирает файл композа, дописывает настройки, разделяет сервисы на подсети и т.д. В общем интересно и поучительно.
Плюс, лично мне всегда любопытно посмотреть на рабочее окружение других специалистов. Какой у них терминал, консоль, в каком редакторе предпочитают работать и как.
⇨ Сайт / Исходники
#заметки
Planka - очень близкий аналог Trello. Он пытается повторить как функциональность, так и внешний вид. И получается неплохо. Можете сами оценить в публичном Demo. Написана Planka на React (библиотека JavaScript).
Акцент на этом видео я сделал потому, что оно поучительно записано. Там внимание не только на самом сервисе, но и на том, как его запустить с помощью docker-compose, как дебажить ошибки. Автор разбирает файл композа, дописывает настройки, разделяет сервисы на подсети и т.д. В общем интересно и поучительно.
Плюс, лично мне всегда любопытно посмотреть на рабочее окружение других специалистов. Какой у них терминал, консоль, в каком редакторе предпочитают работать и как.
⇨ Сайт / Исходники
#заметки
YouTube
Planka (docker) - управлять задачами и проектами просто. Kanban Board для себя и для работы.
Planka - это интуитивно понятное и эффективное приложение для управления задачами и проектами. Он обеспечивает удобство использования досок Kanban для отслеживания задач, организации проектов и управления рабочим процессом.
https://planka.app/
~~~~~~~~…
https://planka.app/
~~~~~~~~…
В комментариях к заметкам про синхронизацию файлов не раз упоминались отказоустойчивые сетевые файловые системы. Прямым представителем такой файловой системы является GlusterFS. Это условный аналог Ceph, которая по своей сути не файловая система, а отказоустойчивая сеть хранения данных. Но в целом обе эти системы используются для решения одних и тех же задач. Про Ceph я писал (#ceph) уже не раз, а вот про GlusterFS не было ни одного упоминания.
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
На все 3 сервера устанавливаем glusterfs-server:
Запускаем также на всех серверах:
На server1 добавляем в пул два других сервера:
На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
На каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
Создаём на этой точке монтирования том glusterfs:
Если получите ошибку:
то проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
Если всё пошло без ошибок, то можно запускать том:
Смотрим о нём информацию:
Теперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
Можете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
/etc/hosts на каждый сервер примерно такие записи:server1 10.20.1.1server2 10.20.1.2server3 10.20.1.3На все 3 сервера устанавливаем glusterfs-server:
# apt install glusterfs-serverЗапускаем также на всех серверах:
# service glusterd startНа server1 добавляем в пул два других сервера:
# gluster peer probe server2# gluster peer probe server3На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
# gluster peer statusНа каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
/mnt/gv0.# mkfs.ext4 /dev/sdb1# mkdir /mnt/gv0# mount /dev/sdb1 /mnt/gv0Создаём на этой точке монтирования том glusterfs:
# gluster volume create gv0 replica 3 server1:/mnt/gv0 server2:/mnt/gv0 server3:/mnt/gv0Если получите ошибку:
volume create: gv0: failed: Host server1 is not in 'Peer in Cluster' stateто проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
/var/lib/glusterd.Если всё пошло без ошибок, то можно запускать том:
# gluster volume start gv0Смотрим о нём информацию:
# gluster volume infoТеперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
# mkdir /mnt/gluster-test# mount -t glusterfs server1:/gv0 /mnt/gluster-testМожете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
/mnt/gv0. По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
{kind=link}
Я не раз делал заметки про различные способы создания загрузочных флешек с набором необходимых дистрибутивов. К примеру, сделать это можно с помощью:
◽Ventoy
◽YUMI – Multiboot USB Creator
◽Easy2Boot (внутри в том числе Ventoy)
Сейчас почти все рабочие места оснащены доступом в интернет. И чаще всего он вполне скоростной, особенно домашний. Есть бесплатный проект netboot.xyz, который позволяет создать загрузочную флешку с возможностью установить систему через интернет. Достаточно загрузиться с этой флешки и выбрать нужную систему. При этом также есть возможность развернуть сервис у себя в локальной сети и выполнять установку с него.
По умолчанию, скачанный с сайта образ содержит набор ОС Linux с возможностью загрузки из официальных репозиториев. Windows системы тоже можно устанавливать через netboot, но для этого нужна собственная Служба развертывания Windows (Windows Deployment Services). Это отдельная серверная роль. Также в стандартном образе есть набор бесплатных программ и утилит, которые можно использовать для диагностики (memtest, system rescue cd и д.р.) или копирования информации (Rescuezilla, Clonezilla).
Для создания собственного меню с системами в загрузочном диске можно использовать отдельный репозиторий с инструкцией. А для настройки своего сервера есть ansible palybook или docker-образ. Управление сервером через веб интерфейс. Настройка простая и быстрая.
Сервис весьма популярен, в сети много материалов по нему. Просто знайте, что он такой есть. Я узнал о нём случайно буквально недавно. Потребности в нём не было, так что информация проходила мимо меня. Подобный образ удобно использовать в том числе в гипервизорах для установки различных систем. Вместо того, чтобы вручную качать образы для разных ОС, можно обновлять один единственный netboot.xyz.iso.
⇨ Сайт / Исходники / Список всех ОС
◽Ventoy
◽YUMI – Multiboot USB Creator
◽Easy2Boot (внутри в том числе Ventoy)
Сейчас почти все рабочие места оснащены доступом в интернет. И чаще всего он вполне скоростной, особенно домашний. Есть бесплатный проект netboot.xyz, который позволяет создать загрузочную флешку с возможностью установить систему через интернет. Достаточно загрузиться с этой флешки и выбрать нужную систему. При этом также есть возможность развернуть сервис у себя в локальной сети и выполнять установку с него.
По умолчанию, скачанный с сайта образ содержит набор ОС Linux с возможностью загрузки из официальных репозиториев. Windows системы тоже можно устанавливать через netboot, но для этого нужна собственная Служба развертывания Windows (Windows Deployment Services). Это отдельная серверная роль. Также в стандартном образе есть набор бесплатных программ и утилит, которые можно использовать для диагностики (memtest, system rescue cd и д.р.) или копирования информации (Rescuezilla, Clonezilla).
Для создания собственного меню с системами в загрузочном диске можно использовать отдельный репозиторий с инструкцией. А для настройки своего сервера есть ansible palybook или docker-образ. Управление сервером через веб интерфейс. Настройка простая и быстрая.
Сервис весьма популярен, в сети много материалов по нему. Просто знайте, что он такой есть. Я узнал о нём случайно буквально недавно. Потребности в нём не было, так что информация проходила мимо меня. Подобный образ удобно использовать в том числе в гипервизорах для установки различных систем. Вместо того, чтобы вручную качать образы для разных ОС, можно обновлять один единственный netboot.xyz.iso.
⇨ Сайт / Исходники / Список всех ОС
{kind=link}
В Linux есть подсистема ядра, которая позволяет получать уведомления о событиях, связанных с файлами и каталогами файловой системы. Называется Inotify. Я упоминал о ней недавно, когда рассказывал про Lsyncd, которая получает информацию от inotify и запускает синхронизацию при изменениях в файлах.
На основе inotify можно организовать простой мониторинг за изменениями файлов. Реализовать это можно, к примеру, с помощью утилиты fswatch, которая есть в базовых репозиториях практически всех популярных систем (GNU/Linux, *BSD, Mac OS X, Solaris). В каждой системе она выбирает свой механизм ядра для уведомлений. В Linux это inotify.
Устанавливаем fswatch:
Для наблюдения за файлом или каталогом достаточно просто запустить fswatch в консоли:
Всё, что будет происходить с файлами и директориями в /tmp, будет выводиться в консоль. Но в таком виде утилита малоинформативна и на практике бесполезна. Запускать лучше сразу с парочкой дополнительных ключей:
◽
◽
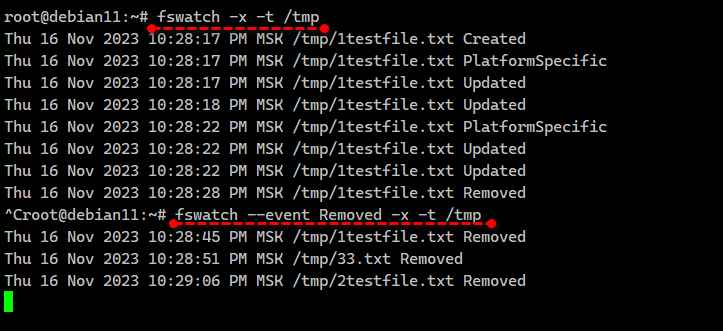
Откроем рядом ещё одну консоль, создадим, обновим и удалим в директории
В логе при этом будет следующее:
Это уже более прикладное решение. Можно запустить fswatch в фоне, вывод направить, например, в текстовый файл и анализировать его с помощью Zabbix, реагируя на какие-то события. В статье рассказано в том числе как настроить триггеры. Первое, что приходит в голову, это сделать вот так:
Утилита будет работать в фоне и писать в файл изменения. Можно добавить запуск через cron по событию @reboot, чтобы запускать при старте системы.
Надёжнее написать запуск через systemd, создав файл /etc/systemd/system/fswatch.service:
Запускаем:
Это самый простой вариант. Лог будет писаться сюда же, в journald. Смотреть можно так:
И дальше обрабатывать как обычные systemd логи. Можно вывести эти логи в отдельный namespace и отправить в централизованное хранилище.
Простой и эффективный способ решения задачи минимальными сторонними средствами. Можно обернуть в любую логику с помощью bash и использовать по потребностям. Например, на почту что-то слать при удалении файла, или сразу в Telegram. Тип событий указывается отдельным ключом:
#linux #bash
На основе inotify можно организовать простой мониторинг за изменениями файлов. Реализовать это можно, к примеру, с помощью утилиты fswatch, которая есть в базовых репозиториях практически всех популярных систем (GNU/Linux, *BSD, Mac OS X, Solaris). В каждой системе она выбирает свой механизм ядра для уведомлений. В Linux это inotify.
Устанавливаем fswatch:
# apt install fswatchДля наблюдения за файлом или каталогом достаточно просто запустить fswatch в консоли:
# fswatch /tmpВсё, что будет происходить с файлами и директориями в /tmp, будет выводиться в консоль. Но в таком виде утилита малоинформативна и на практике бесполезна. Запускать лучше сразу с парочкой дополнительных ключей:
◽
-x - отображать тип событий◽
-t - отображать временные метки# fswatch -x -t /tmpОткроем рядом ещё одну консоль, создадим, обновим и удалим в директории
/tmp файл:# echo '123' > file.txt# rm file.txtВ логе при этом будет следующее:
Thu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt CreatedThu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt PlatformSpecificThu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt UpdatedThu 16 Nov 2023 09:14:25 PM MSK /tmp/file.txt RemovedЭто уже более прикладное решение. Можно запустить fswatch в фоне, вывод направить, например, в текстовый файл и анализировать его с помощью Zabbix, реагируя на какие-то события. В статье рассказано в том числе как настроить триггеры. Первое, что приходит в голову, это сделать вот так:
# fswatch -x -t /tmp >> /var/log/fswatch.log &Утилита будет работать в фоне и писать в файл изменения. Можно добавить запуск через cron по событию @reboot, чтобы запускать при старте системы.
Надёжнее написать запуск через systemd, создав файл /etc/systemd/system/fswatch.service:
[Unit]Description=Start fswatch file monitorWants=fswatch.service[Service]ExecStart=fswatch -x -t /tmp[Install]WantedBy=multi-user.targetЗапускаем:
# systemctl start fswatch.serviceЭто самый простой вариант. Лог будет писаться сюда же, в journald. Смотреть можно так:
# journalctl -u fswatch.serviceИ дальше обрабатывать как обычные systemd логи. Можно вывести эти логи в отдельный namespace и отправить в централизованное хранилище.
Простой и эффективный способ решения задачи минимальными сторонними средствами. Можно обернуть в любую логику с помощью bash и использовать по потребностям. Например, на почту что-то слать при удалении файла, или сразу в Telegram. Тип событий указывается отдельным ключом:
# fswatch --event Removed -x -t /tmp#linux #bash
{kind=link}
Сел сегодня подготовить какой-то мемчик, но когда увидел такую картинку, понял, что к ней не требуется редактирование. Можно в таком виде брать и публиковать к каждой второй моей статье на сайте или заметке тут.
Эту картинку можно смело публиковать вот к этим комментариям:
https://t.me/srv_admin/2536
https://t.me/srv_admin/2604
https://t.me/srv_admin/362
Удивительно, конечно, как сейчас некоторые люди не способны воспринимать написанное. Буквально вчера делал заметку про netboot.xyz, где в самом начале упомянул про Ventoy и сделал ссылку на заметку про него. А человек мне пишет и спрашивает, что я могу сказать про Ventoy? Я ему говорю, так я же написал об этом в самом начале заметки, на что он попросил прислать ему ссылку 🤦.
Сталкиваюсь с подобным регулярно. Пишешь заметку, где явно отвечаешь на какой-то вопрос. А тебе в комментариях его задают. Я в целом не негативлю по этому поводу. Воспринимаю как факт. Странно просто, как у других так получается. Сам в такую ситуацию не попадал.
#мем
Эту картинку можно смело публиковать вот к этим комментариям:
https://t.me/srv_admin/2536
https://t.me/srv_admin/2604
https://t.me/srv_admin/362
Удивительно, конечно, как сейчас некоторые люди не способны воспринимать написанное. Буквально вчера делал заметку про netboot.xyz, где в самом начале упомянул про Ventoy и сделал ссылку на заметку про него. А человек мне пишет и спрашивает, что я могу сказать про Ventoy? Я ему говорю, так я же написал об этом в самом начале заметки, на что он попросил прислать ему ссылку 🤦.
Сталкиваюсь с подобным регулярно. Пишешь заметку, где явно отвечаешь на какой-то вопрос. А тебе в комментариях его задают. Я в целом не негативлю по этому поводу. Воспринимаю как факт. Странно просто, как у других так получается. Сам в такую ситуацию не попадал.
#мем
Тема выходного дня по IT, но на самом деле про людей. Давно хотел написать, но всё откладывал. Неоднократно сталкивался с тем, что взрослые люди иногда ведут себя как дети или подростки.
Я как-то раз ввязался в один проект, условия которого по ходу дела начали меняться в сторону существенного увеличения масштаба и объёма работ, которые я уже тянуть не мог и не хотел. Не вижу смысла в таких случаях межеваться и морозиться, сразу об этом прямо сказал заказчику и предложил варианты, как я должен из него выйти.
Он в целом нормально на это отреагировал и мы стали работать. Он начал искать других людей, я готовил свои дела к передаче. Заказчик нашёл человека. К моему удивлению, это был тоже публичный и немного известный в узких кругах человек. Я обрадовался, думаю, что отлично, передам дела ответственному человеку.
Созвонились, всё обсудили. Я честно как есть расписал весь проект со всеми плюсами и минусами, передал дела. Человек по мере того, как вник во все дела понял, что не тянет, не хочет или не может. Это не знаю. Но, вместо того, чтобы прямо об этом сказать, начал морозиться. Через какое-то время заявил, что надо ехать в командировку, времени нет, проект вести не может.
Заказчик опять вышел на меня и попросил помочь передать всё новому исполнителю. Я проделал всю процедуру ещё раз. Нашли человека, всё рассказали, расписали и т.д. Он немного поработал и тоже отморозился. Уже не помню, чем именно. То ли заболел, то ли ещё что-то. Факт в том, что не сказал прямо, что я отказываюсь работать по такой-то причине. Зачем соглашался, не понятно.
При этом заказчик адекватный. У меня с ним не было проблем ни с оплатой, ни с чем-то ещё. Встречался лично. Он в итоге плюнул и нанял уже компанию, с которой проект и завершил в итоге. Хотел просто отделаться меньшими затратами по времени, деньгам, бюрократии, работая напрямую, но не вышло.
И вот с такими историями я сталкивался не раз. У меня вообще сложилось впечатление, что у людей из сферы IT много какого-то инфантилизма, боязни говорить правду, спорить, не в комментариях к постам, а по рабочим делам. Вроде всё обсудили, обо всём договорились, всех всё устроило. А потом начинаются отговорки, оправдания, переносы сроков и т.д. Не знаю, может это везде так, но я такие вещи замечал постоянно в том числе со стороны своих знакомых.
У меня как-то была ситуация, когда мой небольшой косяк привёл к большим проблемам. Первая мысль в голове была, как придумать отмазку, чтобы как-бы не я был виноват. Вот реально, первое, что пришло в голову. Но понимаю, что это контрпродуктивно. Позвонил директору и сказал, всё как есть. Смысл в том, что директор умный человек и в том числе с его помощью получилось быстро и относительно безпроблемно решить вопрос. Он сразу сориентировался и выдал нужные указания. А если бы я морозился и оправдывался, прикрывая себя, то всё равно бы остался виноват, но последствия были бы хуже.
Даже не знаю, чем подвести итог сказанному. Наверное так. Мужчины, будьте мужчинами. Держите слово, отвечайте за себя и свои поступки. Будьте прямолинейны. Оправдания некоторых людей выглядят так же, как оправдывается школьник перед учителем, или ребёнок перед родителем. Один мой знакомый вообще провернул финт. Он мне как-то рассказал, как ловко придумал историю, чтобы уволиться с одной работы, где у него были обязательства. А потом через несколько лет по похожей схеме обманул меня, когда нужно было съехать с одной темы. Он либо забыл, либо не догадался, что я банально прочитаю эту историю на основании того, что мы давно знакомы. Выглядит глупо, конечно. Общение с ним прекратил.
Опытные и умные люди вот так же читают оправдания других. Лучше прямо обо всём рассказать. В плюсе останутся все ☝.
#мысли
Я как-то раз ввязался в один проект, условия которого по ходу дела начали меняться в сторону существенного увеличения масштаба и объёма работ, которые я уже тянуть не мог и не хотел. Не вижу смысла в таких случаях межеваться и морозиться, сразу об этом прямо сказал заказчику и предложил варианты, как я должен из него выйти.
Он в целом нормально на это отреагировал и мы стали работать. Он начал искать других людей, я готовил свои дела к передаче. Заказчик нашёл человека. К моему удивлению, это был тоже публичный и немного известный в узких кругах человек. Я обрадовался, думаю, что отлично, передам дела ответственному человеку.
Созвонились, всё обсудили. Я честно как есть расписал весь проект со всеми плюсами и минусами, передал дела. Человек по мере того, как вник во все дела понял, что не тянет, не хочет или не может. Это не знаю. Но, вместо того, чтобы прямо об этом сказать, начал морозиться. Через какое-то время заявил, что надо ехать в командировку, времени нет, проект вести не может.
Заказчик опять вышел на меня и попросил помочь передать всё новому исполнителю. Я проделал всю процедуру ещё раз. Нашли человека, всё рассказали, расписали и т.д. Он немного поработал и тоже отморозился. Уже не помню, чем именно. То ли заболел, то ли ещё что-то. Факт в том, что не сказал прямо, что я отказываюсь работать по такой-то причине. Зачем соглашался, не понятно.
При этом заказчик адекватный. У меня с ним не было проблем ни с оплатой, ни с чем-то ещё. Встречался лично. Он в итоге плюнул и нанял уже компанию, с которой проект и завершил в итоге. Хотел просто отделаться меньшими затратами по времени, деньгам, бюрократии, работая напрямую, но не вышло.
И вот с такими историями я сталкивался не раз. У меня вообще сложилось впечатление, что у людей из сферы IT много какого-то инфантилизма, боязни говорить правду, спорить, не в комментариях к постам, а по рабочим делам. Вроде всё обсудили, обо всём договорились, всех всё устроило. А потом начинаются отговорки, оправдания, переносы сроков и т.д. Не знаю, может это везде так, но я такие вещи замечал постоянно в том числе со стороны своих знакомых.
У меня как-то была ситуация, когда мой небольшой косяк привёл к большим проблемам. Первая мысль в голове была, как придумать отмазку, чтобы как-бы не я был виноват. Вот реально, первое, что пришло в голову. Но понимаю, что это контрпродуктивно. Позвонил директору и сказал, всё как есть. Смысл в том, что директор умный человек и в том числе с его помощью получилось быстро и относительно безпроблемно решить вопрос. Он сразу сориентировался и выдал нужные указания. А если бы я морозился и оправдывался, прикрывая себя, то всё равно бы остался виноват, но последствия были бы хуже.
Даже не знаю, чем подвести итог сказанному. Наверное так. Мужчины, будьте мужчинами. Держите слово, отвечайте за себя и свои поступки. Будьте прямолинейны. Оправдания некоторых людей выглядят так же, как оправдывается школьник перед учителем, или ребёнок перед родителем. Один мой знакомый вообще провернул финт. Он мне как-то рассказал, как ловко придумал историю, чтобы уволиться с одной работы, где у него были обязательства. А потом через несколько лет по похожей схеме обманул меня, когда нужно было съехать с одной темы. Он либо забыл, либо не догадался, что я банально прочитаю эту историю на основании того, что мы давно знакомы. Выглядит глупо, конечно. Общение с ним прекратил.
Опытные и умные люди вот так же читают оправдания других. Лучше прямо обо всём рассказать. В плюсе останутся все ☝.
#мысли
В предпоследнем обновлении веб сервера Angie, которое я из-за занятости пропустил, была анонсирована удобная веб панель наблюдения за сервером - Console Light. Только в последнем обновлении заметил это и решил навести справки.
Сразу покажу как поставить, потому что сам это проделал для того, чтобы оценить. Пример для Debian 12:
Добавляем в конфиг виртуального хоста:
Доступ лучше ограничить списком адресов. Я убрал ограничение для локального теста. Набор доступных виджетов и метрик в них зависит от настроек панели. К примеру, если хотите видеть через веб интерфейс конфигурационные файлы Angie с красивым форматированием и подсветкой синтаксиса, добавьте в location /console/api/ параметр api_config_files:
Удобное новшество. Можно быстро оценить всю рабочую конфигурацию, собранную из всех присоединённых файлов. Очень удобно для окружения Bitrix, где этих конфигов десятки.
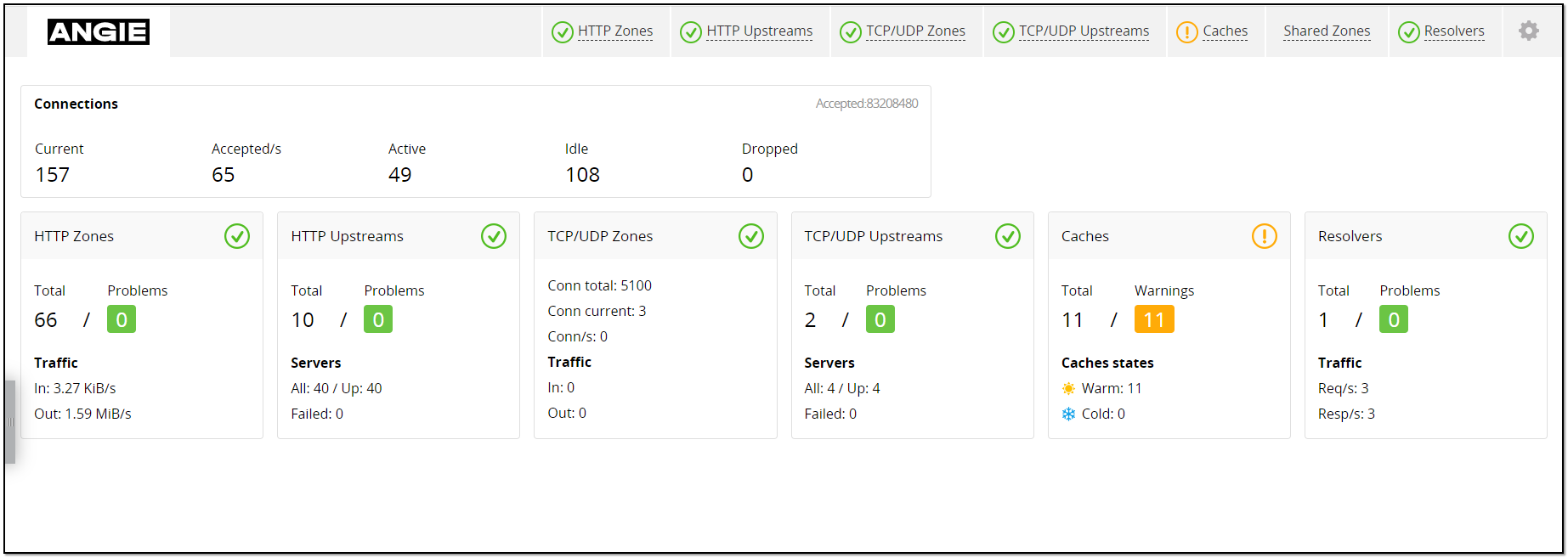
На тестовом сервере смотреть особо не на что, кроме базовых метрик по соединениям. Оценить функциональность панели можно в публичном демо:
⇨ https://console.angie.software
Статья с подробным описанием этой панели и всего мониторинга в целом есть на хабре:
⇨ Многогранный мониторинг Angie
И там же свежее интервью с руководителем отдела разработки:
⇨ Интервью с Валентином Бартеневым: как бывшие сотрудники Nginx разрабатывают отечественный веб-сервер Angie
В принципе, в панели представлена та же информация, что и во встроенном модуле метрик для Prometheus, который был анонсирован в более старых обновлениях. Особенность встроенной панели в том, что там метрики можно смотреть практически в режиме реального времени, без задержки попадания метрик в привычный мониторинг.
Мне немного лениво работающие сервера переводить на Angie, но если что-то новое придётся настраивать, буду делать на нём. Плюсы относительно Nginx очевидны и наглядны. Готовый мониторинг и веб панель - это прям самый сок.
#angie #webserver #отечественное
Сразу покажу как поставить, потому что сам это проделал для того, чтобы оценить. Пример для Debian 12:
# curl -o /etc/apt/trusted.gpg.d/angie-signing.gpg https://angie.software/keys/angie-signing.gpg# echo "deb https://download.angie.software/angie/debian/ `lsb_release -cs` main" | tee /etc/apt/sources.list.d/angie.list > /dev/null# apt update && apt install angie angie-console-lightДобавляем в конфиг виртуального хоста:
location /console { #allow 127.0.0.1; #deny all; alias /usr/share/angie-console-light/html; index index.html; location /console/api/ { api /status/; } }Доступ лучше ограничить списком адресов. Я убрал ограничение для локального теста. Набор доступных виджетов и метрик в них зависит от настроек панели. К примеру, если хотите видеть через веб интерфейс конфигурационные файлы Angie с красивым форматированием и подсветкой синтаксиса, добавьте в location /console/api/ параметр api_config_files:
location /console/api/ { api /status/; api_config_files on; }Удобное новшество. Можно быстро оценить всю рабочую конфигурацию, собранную из всех присоединённых файлов. Очень удобно для окружения Bitrix, где этих конфигов десятки.
На тестовом сервере смотреть особо не на что, кроме базовых метрик по соединениям. Оценить функциональность панели можно в публичном демо:
⇨ https://console.angie.software
Статья с подробным описанием этой панели и всего мониторинга в целом есть на хабре:
⇨ Многогранный мониторинг Angie
И там же свежее интервью с руководителем отдела разработки:
⇨ Интервью с Валентином Бартеневым: как бывшие сотрудники Nginx разрабатывают отечественный веб-сервер Angie
В принципе, в панели представлена та же информация, что и во встроенном модуле метрик для Prometheus, который был анонсирован в более старых обновлениях. Особенность встроенной панели в том, что там метрики можно смотреть практически в режиме реального времени, без задержки попадания метрик в привычный мониторинг.
Мне немного лениво работающие сервера переводить на Angie, но если что-то новое придётся настраивать, буду делать на нём. Плюсы относительно Nginx очевидны и наглядны. Готовый мониторинг и веб панель - это прям самый сок.
#angie #webserver #отечественное
{kind=link}
В выходные прочитал любопытную статью про новый тип DNS записей - HTTPS и SVCB. Речь о них ведётся давно. Я вроде раньше уже слышал что-то подобное, но не разбирался, как это работает. Каким образом новая DNS запись HTTPS должна улучшить нашу жизнь? Посмотрел подробности. Расскажу вам простыми словами.
Новая DNS запись HTTPS призвана уменьшить такой параметр, как time-to-first-packet. В общем случае он не сильно знаком админам, но лично я его хорошо знаю с точки зрения SEO. Это один из факторов ранжирования у поисковиков. Чем быстрее сервер отвечает клиенту, тем лучше.
Принцип работы этой записи довольно простой. Она содержит в себе следующую информацию:
◽доменное имя;
◽версия HTTP протокола;
◽IP адрес сервера.
Выглядит это примерно так:
Запрос на получение этой DNS записи делает браузер. В итоге он сразу же получает всю нужную информацию, чтобы выполнить подключение к целевому веб серверу и конкретному урлу без необходимости дополнительных согласований.
Если нет этой записи, то браузер действует следующим образом:
1️⃣ Запрашивает А запись, чтобы выполнить преобразование доменного имени в IP.
2️⃣ Обращается к веб серверу по IP, передав в заголовке имя домена. Выполняет привычные TLS согласования, возможно в процессе изменяет версию протокола HTTP.
3️⃣ Если на сервере настроен редирект, то идёт по этому редиректу. В HTTPS записи можно сразу указать нужный url, на которой пойдёт браузер при обращении к конкретному домену.
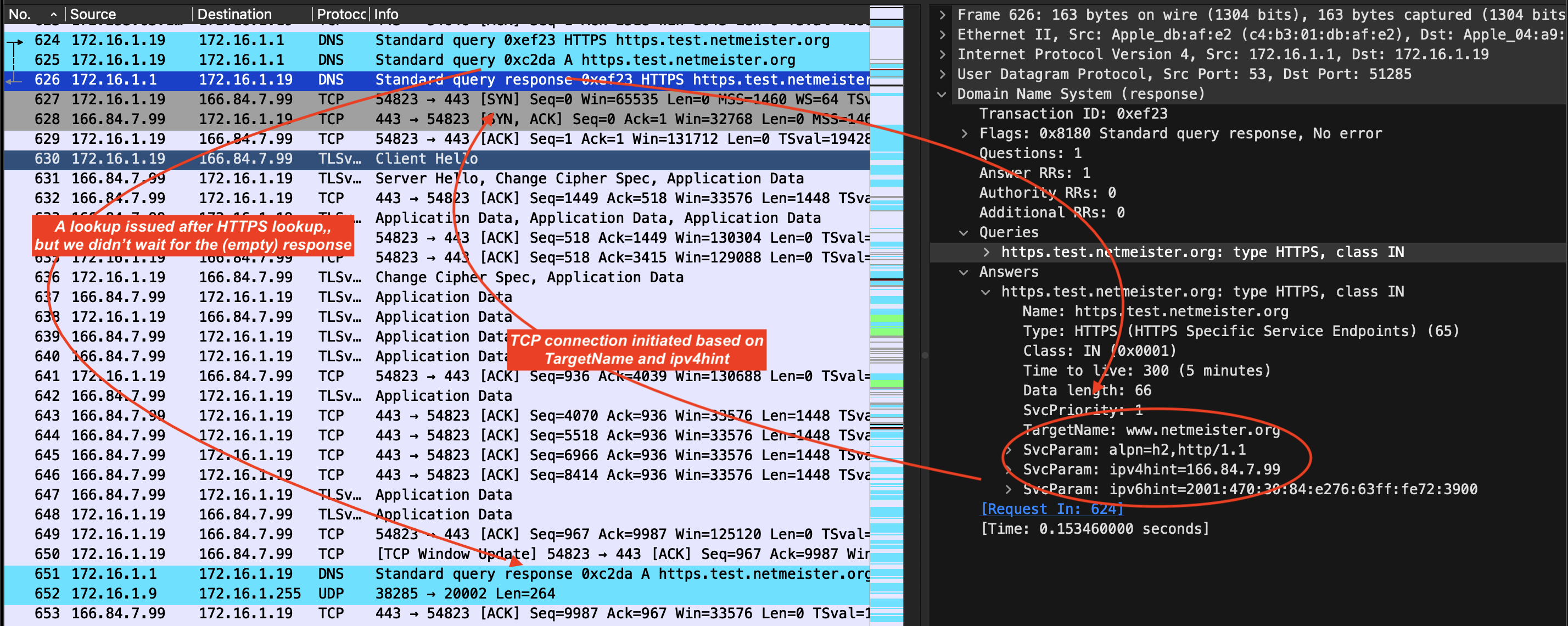
В статье приведён пример с доменом https.test.netmeister.org и соответствующей HTTPS записью:
Браузер при обращении к урлу https.test.netmeister.org сразу же идёт на сервер 166.84.7.99 по протоколу h2 и просит урл www.netmeister.org, не дожидаясь редиректа веб сервера. При этом A записи нет вообще. При наличии HTTPS записи она становится не нужна. В статье в том числе показан сетевой дамп при выполнении подобного запроса.
В целом, поддержка HTTPS записей уже принята и описана в RFC. Например, утилита
Может кто-то уже использует эти записи и знает хостеров, которые их поддерживают?
#dns
Новая DNS запись HTTPS призвана уменьшить такой параметр, как time-to-first-packet. В общем случае он не сильно знаком админам, но лично я его хорошо знаю с точки зрения SEO. Это один из факторов ранжирования у поисковиков. Чем быстрее сервер отвечает клиенту, тем лучше.
Принцип работы этой записи довольно простой. Она содержит в себе следующую информацию:
◽доменное имя;
◽версия HTTP протокола;
◽IP адрес сервера.
Выглядит это примерно так:
example.com. 1800 IN HTTPS 1 . alpn=h3,h2 ipv4hint=1.2.3.4 ipv6hint=2001:470:30:84:e276:63ff:fe72:3900 Запрос на получение этой DNS записи делает браузер. В итоге он сразу же получает всю нужную информацию, чтобы выполнить подключение к целевому веб серверу и конкретному урлу без необходимости дополнительных согласований.
Если нет этой записи, то браузер действует следующим образом:
1️⃣ Запрашивает А запись, чтобы выполнить преобразование доменного имени в IP.
2️⃣ Обращается к веб серверу по IP, передав в заголовке имя домена. Выполняет привычные TLS согласования, возможно в процессе изменяет версию протокола HTTP.
3️⃣ Если на сервере настроен редирект, то идёт по этому редиректу. В HTTPS записи можно сразу указать нужный url, на которой пойдёт браузер при обращении к конкретному домену.
В статье приведён пример с доменом https.test.netmeister.org и соответствующей HTTPS записью:
www.netmeister.org. alpn="h2,http/1.1" ipv4hint=166.84.7.99Браузер при обращении к урлу https.test.netmeister.org сразу же идёт на сервер 166.84.7.99 по протоколу h2 и просит урл www.netmeister.org, не дожидаясь редиректа веб сервера. При этом A записи нет вообще. При наличии HTTPS записи она становится не нужна. В статье в том числе показан сетевой дамп при выполнении подобного запроса.
В целом, поддержка HTTPS записей уже принята и описана в RFC. Например, утилита
dig их поддерживает. Я проверил. Современные браузеры тоже поддерживают. Зашёл к DNS хостингам, которыми пользуюсь. Там возможности добавить HTTPS запись нет. То есть на практике пока не получается ими пользоваться. А так удобно сделано. Как только появится поддержка у хостеров, надо будет настроить.Может кто-то уже использует эти записи и знает хостеров, которые их поддерживают?
#dns
{kind=link}
Решил не откладывать в долгий ящик и перевести один из веб серверов на Angie. Как и обещали разработчики, с конфигами Nginx полная совместимость. Установил Angie и скопировал основной конфиг сервиса, а также виртуальных хостов. Виртуальные хосты вообще не трогал, а основной конфиг немного подредактировал, изменив в include пути с
Остановил Nginx, запустил Angie. Никаких проблем. Всё мгновенно подхватилось новым веб серверов. Простой пару секунд.
Заметку пишу не про переход, а про мониторинг. Согласно документации настроил передачу метрик сервера через API, веб консоль и метрики Prometheus. С прометеусом пока не разбирался, веб консоль просто для красоты включил, а внимание уделил API. Настроил шаблон Zabbix для сбора метрик через API. Сделал по аналогии с Nginx, но кое-что изменил по своему усмотрению. Шаблон можно скачать тут. Это первая версия. Немного попользуюсь и надеюсь, что оформлю всё это в полноценную статью с какими-то правками, которые наверняка накопятся по мере использования.
В шаблоне используются 2 макроса:
◽{$STATUS_HOST} - ip адрес сервера
◽{$STATUS_PATH} - часть урла для API.
У меня доступ к API настроен по IP, а полный путь выглядит так: http://1.2.3.4/status/. Соответственно, первый макрос - 1.2.3.4, второй - /status/.
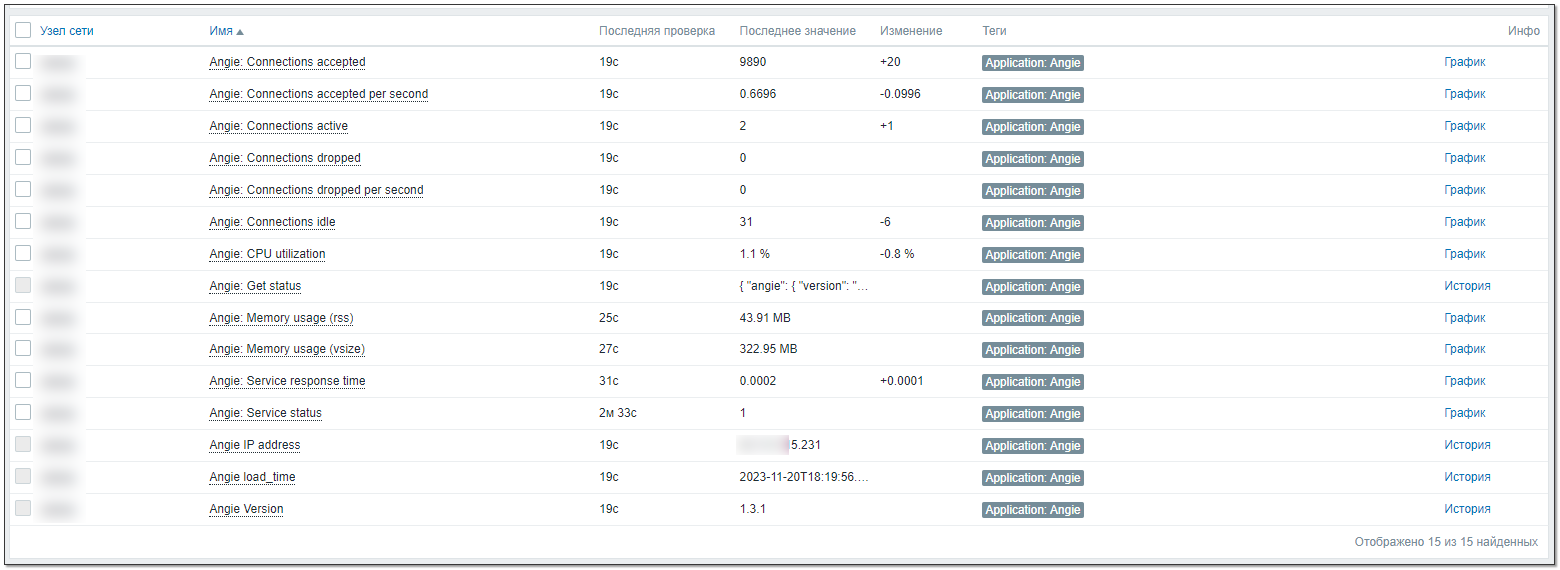
На картинке ниже метрики, которые я посчитал полезными и добавил в шаблон. Триггера сделал три: не отвечает внешний порт веб сервера, нет ни одного процесса angie на сервере, не поступают данные от API в мониторинг. Также добавил 4 графика и оформил всё в панель. Картинку панели покажу в комментариях.
#angie #zabbix
/etc/nginx на /etc/angie. Ещё параметр pid изменил с /var/run/nginx.pid на /run/angie.pid. Больше ничего не менял. Остановил Nginx, запустил Angie. Никаких проблем. Всё мгновенно подхватилось новым веб серверов. Простой пару секунд.
Заметку пишу не про переход, а про мониторинг. Согласно документации настроил передачу метрик сервера через API, веб консоль и метрики Prometheus. С прометеусом пока не разбирался, веб консоль просто для красоты включил, а внимание уделил API. Настроил шаблон Zabbix для сбора метрик через API. Сделал по аналогии с Nginx, но кое-что изменил по своему усмотрению. Шаблон можно скачать тут. Это первая версия. Немного попользуюсь и надеюсь, что оформлю всё это в полноценную статью с какими-то правками, которые наверняка накопятся по мере использования.
В шаблоне используются 2 макроса:
◽{$STATUS_HOST} - ip адрес сервера
◽{$STATUS_PATH} - часть урла для API.
У меня доступ к API настроен по IP, а полный путь выглядит так: http://1.2.3.4/status/. Соответственно, первый макрос - 1.2.3.4, второй - /status/.
На картинке ниже метрики, которые я посчитал полезными и добавил в шаблон. Триггера сделал три: не отвечает внешний порт веб сервера, нет ни одного процесса angie на сервере, не поступают данные от API в мониторинг. Также добавил 4 графика и оформил всё в панель. Картинку панели покажу в комментариях.
#angie #zabbix
{kind=link}
Я вроде бы уже когда-то упоминал про англоязычную рассылку devopsweekly.com, но не могу найти этой записи. Возможно и нет. В общем, это такая олдскульная рассылка на почту в текстовом формате раз в неделю с некоторыми новостями. Я её давно уже читаю, более двух лет.
Мне нравится такой формат, когда раз в неделю, в воскресенье, приходят новости по определённой тематике. Читаю я там далеко не всё, но просматриваю регулярно. Я как раз в воскресенье вечером сажусь за компьютер, проверить и подготовить список основных дел на неделю. Заодно читаю эту рассылку.
Вчерашнюю заметку про HTTPS записи DNS как раз там повстречал. Было бы круто, если бы кто-то ещё начал вести подобные рассылки по разным направлениям: безопасность, сети, обновления, Windows, Linux и т.д. Можно в Telegram. А лучше и здесь, и по почте.
Дарю готовую идею 😀 Я сам когда-то думал подобное вести, но у меня нет на это времени. Данный канал всё занимает. В таких подборках важно, чтобы они выходили не чаще раза в неделю. В качестве монетизации можно одну новость делать рекламную.
Если кто-то знает похожие рассылки, не обязательно на русском языке, поделитесь.
#devops
Мне нравится такой формат, когда раз в неделю, в воскресенье, приходят новости по определённой тематике. Читаю я там далеко не всё, но просматриваю регулярно. Я как раз в воскресенье вечером сажусь за компьютер, проверить и подготовить список основных дел на неделю. Заодно читаю эту рассылку.
Вчерашнюю заметку про HTTPS записи DNS как раз там повстречал. Было бы круто, если бы кто-то ещё начал вести подобные рассылки по разным направлениям: безопасность, сети, обновления, Windows, Linux и т.д. Можно в Telegram. А лучше и здесь, и по почте.
Дарю готовую идею 😀 Я сам когда-то думал подобное вести, но у меня нет на это времени. Данный канал всё занимает. В таких подборках важно, чтобы они выходили не чаще раза в неделю. В качестве монетизации можно одну новость делать рекламную.
Если кто-то знает похожие рассылки, не обязательно на русском языке, поделитесь.
#devops
{kind=link}
Если у вас есть потребность в автоматизации сетевой установки операционных систем на компьютеры или виртуальные машины, то решить эту задачу можно с помощью бесплатного сервера Cobbler. С его помощью можно организовать единый сервер сетевой установки Linux и Windows систем, которые будут загружаться с помощью технологии PXE (Preboot eXecution Environment).
Работает это следующим образом. Распишу сразу наиболее продвинутую конфигурацию. Вы разворачиваете сервер Cobbler вместе с DHCP (isc-dhcp-server) и DNS (bind) серверами. Cobbler имеет шаблоны и инструменты для автоматического управления этими службами. Готовите на сервере образ системы либо для ручной установки, либо сразу с файлами ответов для полностью автоматического разворачивания.
Когда сервер готов, запускаете машину с настроенной загрузкой по PXE. Если это реальное железо, то настройки выполняются в BIOS, в свойствах сетевой карты и опциях загрузки. Если речь идёт про виртуальную машину, то в boot меню виртуалки выбирается загрузка по PXE. Машина стартует, запускается PXE, на основе MAC адреса по DHCP получает соответствующие настройки с указанием адреса загрузочного образа. Загружается с этого образа по сети и запускается установка основной ОС в зависимости от её настроек. Можно сразу настроить установку сетевых параметров и имени машины с автоматическим добавлением этих данных в DNS.
С помощью подобной технологии можно не только выполнять установку ОС, но и создавать образы для бездисковой работы на рабочих станциях. Например, когда-то давно я лично настраивал бездисковые рабочие станции с загрузкой по PXE, для того, чтобы они могли подключиться по RDP к терминальному серверу. Готовилась простая сборка системы с загрузкой в оперативную память и автоматическим подключением с помощью FreeRDP. Локальные диски вообще не использовались (были вынуты).
Сразу могу сказать, что настройка подобной системы сложна. Без понимания работы всех смежных технологий настроить будет трудно. Это инструмент для тех, кто понимает и знает, зачем ему всё это нужно. Изначально Cobbler ориентирован на rpm дистрибутивы, но так как написан на Python, с некоторыми правками запускается и на Debian. Я использовал официальную инструкцию и статью под Debian. Статья уже устарела и простым копипастом не настроить, но основные моменты где и что нужно будет поправить можно посмотреть. Также список пакетов под Debian там актуальный, не хватает только
Когда я настраивал Cobbler, усиленно пытался вспомнить, на что он похож. Я подобный софт уже видел. В конце вспомнил. Это аналог FOG Project. Он решает схожую задачу, используя те же технологии, но при этом проще в настройках, но и возможностей в нём поменьше. Cobbler более функциональный, так как может работать в связке с DHCP и DNS сервером, да и других более тонких настроек в нём больше.
⇨ Сайт / Исходники
#pxe
Работает это следующим образом. Распишу сразу наиболее продвинутую конфигурацию. Вы разворачиваете сервер Cobbler вместе с DHCP (isc-dhcp-server) и DNS (bind) серверами. Cobbler имеет шаблоны и инструменты для автоматического управления этими службами. Готовите на сервере образ системы либо для ручной установки, либо сразу с файлами ответов для полностью автоматического разворачивания.
Когда сервер готов, запускаете машину с настроенной загрузкой по PXE. Если это реальное железо, то настройки выполняются в BIOS, в свойствах сетевой карты и опциях загрузки. Если речь идёт про виртуальную машину, то в boot меню виртуалки выбирается загрузка по PXE. Машина стартует, запускается PXE, на основе MAC адреса по DHCP получает соответствующие настройки с указанием адреса загрузочного образа. Загружается с этого образа по сети и запускается установка основной ОС в зависимости от её настроек. Можно сразу настроить установку сетевых параметров и имени машины с автоматическим добавлением этих данных в DNS.
С помощью подобной технологии можно не только выполнять установку ОС, но и создавать образы для бездисковой работы на рабочих станциях. Например, когда-то давно я лично настраивал бездисковые рабочие станции с загрузкой по PXE, для того, чтобы они могли подключиться по RDP к терминальному серверу. Готовилась простая сборка системы с загрузкой в оперативную память и автоматическим подключением с помощью FreeRDP. Локальные диски вообще не использовались (были вынуты).
Сразу могу сказать, что настройка подобной системы сложна. Без понимания работы всех смежных технологий настроить будет трудно. Это инструмент для тех, кто понимает и знает, зачем ему всё это нужно. Изначально Cobbler ориентирован на rpm дистрибутивы, но так как написан на Python, с некоторыми правками запускается и на Debian. Я использовал официальную инструкцию и статью под Debian. Статья уже устарела и простым копипастом не настроить, но основные моменты где и что нужно будет поправить можно посмотреть. Также список пакетов под Debian там актуальный, не хватает только
python3-schema. И вот это обсуждение ошибки пригодится, если будете пакет под debian собирать. Когда я настраивал Cobbler, усиленно пытался вспомнить, на что он похож. Я подобный софт уже видел. В конце вспомнил. Это аналог FOG Project. Он решает схожую задачу, используя те же технологии, но при этом проще в настройках, но и возможностей в нём поменьше. Cobbler более функциональный, так как может работать в связке с DHCP и DNS сервером, да и других более тонких настроек в нём больше.
⇨ Сайт / Исходники
#pxe
{kind=link}
Казалось бы, что может быть проще копирования файлов из одной директории в другую. Тем не менее в консоли Linux это не всегда простая и очевидная процедура. Для этого существует небольшая утилита
Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
Но так скопируются только файлы, без вложенных директорий. Добавляем ключ
По моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
На длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
Ещё засаду с
Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
Тут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
cp, которая обычно присутствует во всех дистрибутивах. Лично у меня сложности возникают с тем, что я начинаю вспоминать, нужно ли использовать *, ставить или нет слеш на конце директории и т.д. Всё это влияет на конечный результат. Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
# cp /dir_a/* /dir_bНо так скопируются только файлы, без вложенных директорий. Добавляем ключ
-r или сразу -a, чтобы и все атрибуты скопировать:# cp -a /dir_a/* /dir_bПо моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
# cp -a /dir_a/file1 /dir_a/file2 /dir_a/file3 ...... /dir_bНа длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
* в командах, запускаемых в bash, работает именно так.Ещё засаду с
cp можно получить, если в директории будут файлы, начинающиеся с точки. Те же .htaccess. Если скопируем предложенной выше командой со *, то все файлы с точкой в начале имени потеряем. Будет неприятно. Это опять же особенность bash, которая по умолчанию трактует такие файлы как скрытые. Такое поведение можно изменить.Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
* :# cp -aT /dir_a /dir_bТут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
Вчера в заметке про копирование с помощью
Мы всё содержимое директории
В Linux, как и в DOS кстати, существуют некие псевдопапки-ссылки на текущую и вышестоящую директории. Точка - это, соответственно, текущая директория, а две точки - вышестоящая по отношению к текущей. Обращаться к ним можно так же, как и к обычным папкам. Они, собственно, на вид ничем от остальных и не отличаются. Если сделать
Можно сделать:
и остаться в текущем каталоге, либо:
и перейти в вышестоящий, родительский каталог для текущего.
Отсюда становится понятно, почему для запуска скрипта в текущем каталоге, мы используем точку:
Явно указываем на скрипт, который запускаем. Иначе оболочка проверит
Две точки часто используют в скриптах, чтобы обращаться в родительский каталог, когда надо оперировать файлами не только текущего. А так как мы не можем точно знать без дополнительных проверок, как называется родительский каталог, то две точки это удобный вариант.
Создали файл в вышестоящем каталоге, ничего не зная про него. Без двух точек нам сначала пришлось бы выяснить, где мы находимся, чтобы определить родительский каталог. А так всё делаем сразу.
Если я не ошибаюсь, то точка и две точки это просто ссылки на inode конкретных директорий. Так что их наличие будет зависеть от файловой системы. В наиболее популярных они присутствуют.
#bash
cp в комментариях справедливо привели ещё один вариант копирования. Причём самый простой и удобный. Я про него знал, но не стал упоминать, потому что нужны будут пояснения для тех, кто не знает про некоторые особенности псевдопапок в виде точки или двух точек. Речь идёт о примерно такой конструкции:# cp -a /dir_a/. /dir_bМы всё содержимое директории
dir_a со всеми скрытыми файлами скопировали в dir_b. В Linux, как и в DOS кстати, существуют некие псевдопапки-ссылки на текущую и вышестоящую директории. Точка - это, соответственно, текущая директория, а две точки - вышестоящая по отношению к текущей. Обращаться к ним можно так же, как и к обычным папкам. Они, собственно, на вид ничем от остальных и не отличаются. Если сделать
ls -la, то мы их увидим вместе с остальными директориями:# ls -latotal 56drwx------ 8 root root 4096 Nov 22 21:37 .drwxr-xr-x 18 root root 4096 Oct 13 12:30 ..-rw------- 1 root root 6115 Nov 22 16:02 .bash_history-rw-r--r-- 1 root root 571 Apr 10 2021 .bashrcdrwx------ 3 root root 4096 Dec 9 2022 .cachedrwx------ 4 root root 4096 Nov 16 21:22 .config-rw-r--r-- 1 root root 56 Nov 15 00:19 .gitconfigdrwx------ 3 root root 4096 Dec 9 2022 .local-rw-r--r-- 1 root root 161 Jul 9 2019 .profile-rw-r--r-- 1 root root 72 Dec 9 2022 .selected_editordrwx------ 2 root root 4096 Nov 15 00:21 .sshМожно сделать:
# cd .и остаться в текущем каталоге, либо:
# cd .. и перейти в вышестоящий, родительский каталог для текущего.
Отсюда становится понятно, почему для запуска скрипта в текущем каталоге, мы используем точку:
# ./script.shЯвно указываем на скрипт, который запускаем. Иначе оболочка проверит
$PATH, там не окажется текущего каталога и скрипт не будет выполнен. Так что надо написать либо полный путь, либо использовать точку, если скрипт в текущем каталоге. Точно помню, что вот эту тему с точкой я очень долго не понимал и просто использовал. Даже мысли не было, что это я текущий каталог указываю. Думал, это какой-то признак исполняемого файла.Две точки часто используют в скриптах, чтобы обращаться в родительский каталог, когда надо оперировать файлами не только текущего. А так как мы не можем точно знать без дополнительных проверок, как называется родительский каталог, то две точки это удобный вариант.
# touch ../file.nameСоздали файл в вышестоящем каталоге, ничего не зная про него. Без двух точек нам сначала пришлось бы выяснить, где мы находимся, чтобы определить родительский каталог. А так всё делаем сразу.
Если я не ошибаюсь, то точка и две точки это просто ссылки на inode конкретных директорий. Так что их наличие будет зависеть от файловой системы. В наиболее популярных они присутствуют.
#bash
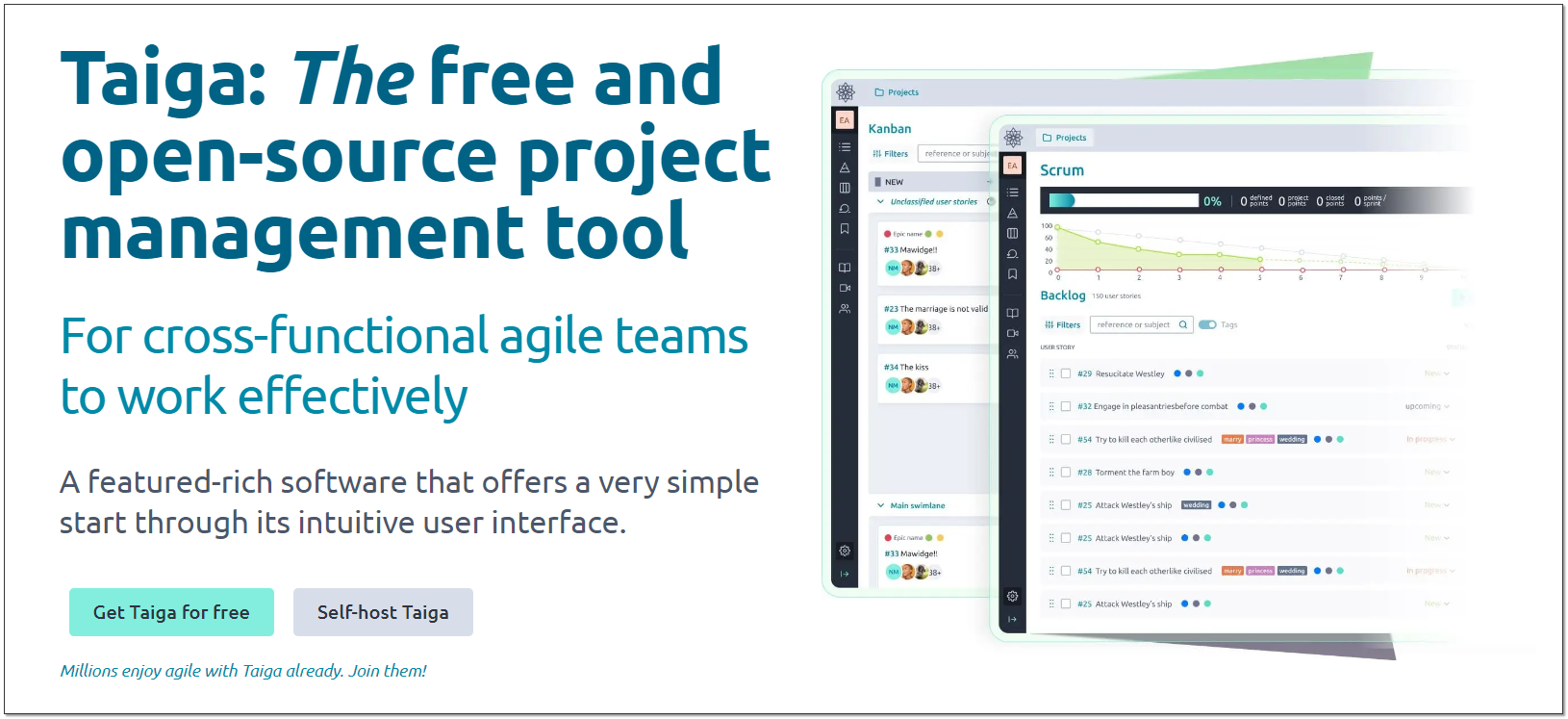
Знакомы ли вам такие современные понятия как Agile, Kanban, Scrum? Если совсем не знакомы, то у вас есть отличный шанс погрузиться в эту замечательную прогрессивную и развитую среду современной разработки и управления проектами с помощью бесплатного инструмента Taiga. Впрочем, если знакомы, то шанс тоже есть. Это open source проект для поднятия собственного self-hosted движка по управлению проектами. Условно можно назвать его современным аналогом Redmine или Youtrack. Условно, потому что по возможностям они сильно различаются, но в целом направлены на решение схожих задач.
Название Taiga меня сначала сбило с толку. Я думал, это что-то с корнями из России, Сибири, тайги. Но нет, это продукт испанской компании Kaleidos Ventures. Попробовать её можно разными способами: установить себе self-hosted версию или воспользоваться бесплатным тарифным планом облачной версии. Я покажу, как Тайгу установить у себя. Под капотом там следующий стек технологий:
◽Python - бэк, JavaScript - фронт.
◽СУБД PostgreSQL
◽RabbitMQ
Можно считать, что стандартный набор.
Ставить будем Docker версию из репозитория разработчиков:
В файле
Создаём пользователя. После этого идём по адресу сервера на порт 9000 и логинимся под созданной учёткой. Это вариант тестовой установки. Если будете ставить в прод, то в этой статье даны все необходимые рекомендации по настройке, в том числе по размещению за nginx proxy, использованию https, отправки почты и т.д.
Система прикольная. Выглядит современно, работает шустро. Есть youtube канал, где можно посмотреть, как она вживую выглядит. Раньше вроде бы было какое-то неофициальное приложение для смартфона на Android, но сейчас оно заброшено. Как я понял, интерфейс и так нормально адаптирован под смартфоны, так что большой нужды в приложении нет.
Немного почитал отзывы и статьи о Taiga. В основном положительные. Её называют бесплатной альтернативой Trello или Jira. Проект существует давно. Как минимум с 2014 года есть упоминания.
#управление_проектами
Название Taiga меня сначала сбило с толку. Я думал, это что-то с корнями из России, Сибири, тайги. Но нет, это продукт испанской компании Kaleidos Ventures. Попробовать её можно разными способами: установить себе self-hosted версию или воспользоваться бесплатным тарифным планом облачной версии. Я покажу, как Тайгу установить у себя. Под капотом там следующий стек технологий:
◽Python - бэк, JavaScript - фронт.
◽СУБД PostgreSQL
◽RabbitMQ
Можно считать, что стандартный набор.
Ставить будем Docker версию из репозитория разработчиков:
# git clone https://github.com/kaleidos-ventures/taiga-docker# cd taiga-docker/# git checkout stableВ файле
.env в переменной TAIGA_DOMAIN замените localhost на IP адрес сервера, если запускаете не на своей машине.# ./launch-all.sh# ./taiga-manage.sh createsuperuserСоздаём пользователя. После этого идём по адресу сервера на порт 9000 и логинимся под созданной учёткой. Это вариант тестовой установки. Если будете ставить в прод, то в этой статье даны все необходимые рекомендации по настройке, в том числе по размещению за nginx proxy, использованию https, отправки почты и т.д.
Система прикольная. Выглядит современно, работает шустро. Есть youtube канал, где можно посмотреть, как она вживую выглядит. Раньше вроде бы было какое-то неофициальное приложение для смартфона на Android, но сейчас оно заброшено. Как я понял, интерфейс и так нормально адаптирован под смартфоны, так что большой нужды в приложении нет.
Немного почитал отзывы и статьи о Taiga. В основном положительные. Её называют бесплатной альтернативой Trello или Jira. Проект существует давно. Как минимум с 2014 года есть упоминания.
#управление_проектами
{kind=link}
Выбирая между софтовым или железным рейдом, я чаще всего выберу софтовый, если не будет остро стоять вопрос быстродействия дисковой подсистемы. А в бюджетном сегменте обычно и выбирать не приходится. Хотя и дорогой сервер могу взять без встроенного рейд контроллера, особенно если там быстрые ssd или nvme диски.
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
и выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
Получаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
То же самое с mdadm. Смотрим состояние:
Добавляем утилиту jc:
Выгружаем полную информацию о массиве в формате json:
И отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
# apt install smartmontoolsи выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
# smartctl -i /dev/sdd -j# smartctl -A /dev/sdd -jПолучаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
То же самое с mdadm. Смотрим состояние:
# mdadm -Q --detail /dev/md1Добавляем утилиту jc:
# apt install jcВыгружаем полную информацию о массиве в формате json:
# mdadm -Q --detail /dev/md1 | jc --mdadm -pИ отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
{kind=link}